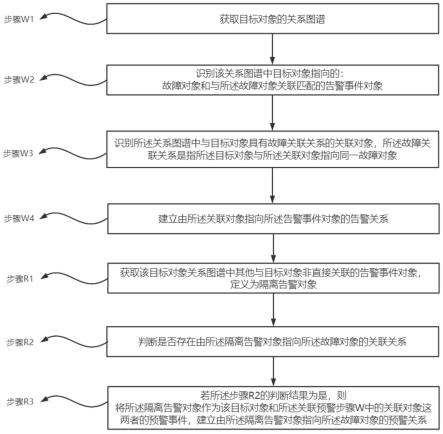
1.本发明属于图像重建技术领域,涉及一种高效多注意力特征融合的超分辨率重建模型、方法、设备及存储介质。
背景技术:
2.单幅图像的超分辨率重建(single image super-resolution,sisr)技术是指将将给定的一幅低分辨率(low-resolution,lr)图像通过特定算法恢复成相应的高分辨率(high-resolution,hr)图像,旨在克服或补偿由于图像采集系统或采集环境本身限制,导致的成像图像质量低下、感兴趣区域不显著等问题。传统的图像超分辨率重建算法主要依靠基本的数字图像处理技术进行重建,计算复杂且不能有效恢复图像的原始信息。
3.随着深度学习在图像超分辨率重建中的广泛应用并逐渐取得了较好的结果,受到越来越多研究人员的关注。dong等首次将卷积神经网络应用于超分辨率重建技术中,提出的srcnn利用三个卷积层以像素映射的方式生成重建的图像,详见“c.dong,c.c.loy, k.he,x.tang,image super-resolution using deep convolutional networks,in proc.ieeeconf.comput.vis.pattern recognit.(cvpr),2014,pp.184-199”;dong等基于srcnn提出了fsrcnn,其内部采用了更小卷积层,并在网络末端通过反卷积层放大尺寸,详见“c.dong,c.c.loy,x.tang,accelerating the super-resolution convolutional neuralnetwork,computer vision-eccv workshops,2016,pp.391-407”;shi等提出的高效的亚像素卷积神经网络espcn在重建模块使用重新排列后的亚像素层实现上采样操作,详情见“w.shi,j.caballero,f.huszar,et al.,real-time single image and video super-resolutionusing an efficient sub-pixel convolutional neural network,in proc.ieee conf comput vis. pattern recognit(cvpr),2016,pp.1874-1883”。以上的超分辨率重建方法比较轻量但重建效果不达预期。
4.于是人们开始通过增加网络深度来提高模型性能。kim等提出20层的深层网络 vdsr,它利用残差学习的思想加快网络训练的收敛速度,详情见“j.kim,k.j.lee,m.k. lee,accurate image super-resolution using very deep convolutional networks,in proc. ieee conf comput.vis.pattern recognit(cvpr),2016,pp.1646-1654”;ahn等提出一种在残差网络(resnet)上实现级联机制的架构carn,其中间部分基于resnet,网络的全局和局部使用级联机制以更好融合各层网络的特征,详见“n.ahn,b.kang,a.k.sohn, fast,accurate,and lightweight super-resolution with cascading residual network, computer vision-eccv workshops,2018,pp.252-268”;zhao等提出像素注意力的超分辨率重建网络pan,通过引入轻量的像素注意力机制来提升网络的重建性能,详见“h. zhao,x.kong,j.he,et al.,efficient image super-resolution using pixel attention,computervision-eccv workshops,2020,pp.56-72”;tian等提出的cfsrcnn利用特征提取模块学习长短路径特征,通过将网络浅层的信息扩展到深层来融合学习到的特
征,详见“c. tian,y.xu,w.zuo,et al.,coarse-to-fine cnn for image super-resolution,ieeetransactions on multimedia,vol.23,2021,pp.1489-1502”。上述方法通过增加网络层数使模型性能得到提升,但随之激增的参数量导致训练难度大幅度增加,有些模型降参后重建性能会明显下降。可见参数和性能很难达到很好的平衡。
5.经发明人研究发现,现有的基于深度学习的单幅图像超分辨率重建方法的重建效果不佳,主要存在以下问题:(1)基于cnn的一部分超分辨率重建网络较为轻量,但性能不达预期。(2)越来越多的模型为追求重建效果而增加网络深度,尽管性能有所提升但庞大的参数量导致训练的时间复杂度增大,同时特征信息在深层次网络传递过程中的丢失也会影响重建效果。如何充分利用图像的特征信息,使有限的特征实现更好的传递和重用,高效恢复图像的边缘轮廓和纹理细节,在保证性能的同时使模型尽可能的轻量化成为当前急需解决的问题。
技术实现要素:
6.为了解决上述问题,本发明提供一种高效多注意力特征融合的图像超分辨率重建模型,能够改善图像质量,提升观测效果,解决现有超分辨率重建算法由于网络层数过深导致的信息丢失、参数量大的问题。
7.本发明的第二目的是,提供一种高效多注意力特征融合的图像超分辨率重建方法。
8.本发明的第三目的是,提供一种电子设备。
9.本发明的第四目的是,提供一种计算机存储介质。
10.本发明所采用的技术方案是,一种高效多注意力特征融合的超分辨率重建模型,包括特征提取模块和重建模块;
11.所述特征提取模块分为浅层特征提取模块和深层特征提取模块,
12.浅层特征提取模块为一个3*3卷积层,对输入的低分辨率lr图像在低维空间进行初始特征提取,有效减少其计算量;
13.深层特征提取模块包含8个渐进式特征融合块(pffb),pffb采用渐进式融合的连接方式逐步提取图像的深层次特征信息以加强特征传递,同时结合其内部的高效多注意力块(emab)对提取到的特征信息进行加权使网络更多的关注高频信息;
14.所述重建模块由多尺度感受野块rfb_x、一个3*3卷积和一个亚像素卷积层组成, rfb_x利用多分支结构对pffb块提取的特征进一步增强,并融合多尺度的特征信息来提升模型的重建性能,
15.随后将低分辨率lr图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加得到重建后的图像。
16.进一步地,所述深层特征提取模块包含8个渐进式特征融合块(pffb);
17.所述pffb中采用四个高效多注意力块(emab)层层递进,逐步提取图像的深层次信息;
18.所述pffb通过多次通道随机混合(c shuffle),实现对emab块中卷积层结果的“信息交互”,将输出的通道进行重新分组,然后混合不同通道的信息,解决卷积层之间的信息流通不畅,不增加计算量的同时使通道充分融合;
19.所述pffb对每个经emab块提取到的特征进行c shuffle,随后连接相邻两个经c shuffle处理的特征再次进行c shuffle以提高网络的泛化能力,使用1*1卷积移除冗余信息,产生的结果与下一个经c shuffle操作的信息进行特征融合;在pffb内的emab块间重复此操作,逐步收集局部信息并进行特征融合,加强特征传递,有助于提升重建图像的精度;最后采用残差学习将输入特征xi与融合后的特征叠加得到第i(i=0,1,
…
,7)个 pffb块的输出特征x
i 1
,最大限度的利用了lr图像信息来缓解特征在传递过程中的丢失;
20.所述pffb通过“渐进式”特征融合的连接方式,加强特征提取并对提取到的多层信息进行融合,方便每一层充分利用前面层数学习到的所有特征,使有限的特征实现更好的传递和重用。
21.进一步地,所述pffb中采用四个高效多注意力块(emab)逐层提取特征;
22.所述emab充分利用通道和空间的特征信息逐步对图像的浅层特征去噪,使网络侧重于关注图像中高频细节,有助于增强重建后图像的纹理细节信息;
23.所述emab在两个3*3卷积核后使用1*1卷积层缩减通道尺寸,通过步长为2的步长卷积扩大感受野并结合2*2的最大池化层进一步降低网络的空间维数;之后使用空洞卷积层进一步聚合感受野的上下文信息,降低内存的同时提升网络性能,将得到的特征进行上采样操作恢复空间维度,并通过1*1卷积恢复通道维度;
24.所述emab在3个卷积层后使用激活函数frelu来加快收敛速度、防止梯度爆炸;
25.所述emab采用高效通道注意力块,避免维度缩减带来的问题,通道注意力由快速的一维卷积生成,通过通道维数的非线性映射自适应确定内部卷积核的尺寸;
26.所述一维卷积可以高效实现局部跨通道交互,通过捕获局部跨通道的信息,完成其间的相互交流,学习有效的通道注意力。
27.进一步地,所述重建模块中的多尺度感受野块rfb_x由1*1、3*3、1*3和3*1卷积核组合而成;
28.所述rfb_x位于顺序连接的8个pffb之后,负责增强提取到的深层次特征,多尺度的融合特征并重建,保留了深度丰富的特征、恢复了图像细节;
29.具体来说,将第8个pffb块的输出特征x8作为rfb-x块的输入,使用不同大小的多分支卷积层进行多尺度特征提取,同时引入不同空洞率的空洞卷积,空洞卷积的空洞率越大则采样点离中心点越远,感受野就越大,有助于在更大的区域捕获信息以生成效果更好的特征图,同时不增加参数量;
30.最后连接多个分支的输出以多尺度的融合不同特征,得到rfb_x提取的特征xe。
31.一种高效多注意力特征融合的超分辨率重建方法,按照以下步骤进行:
32.s1、将低分辨率lr图像输入高效多注意力特征融合的超分辨率重建模型;
33.s2、超分辨率重建模型的特征提取模块,完成对lr图像的浅层特征的提取后,经过8个渐进式特征融合块(pffb)实现深层特征提取,并送入重建模块;
34.s3、重建模块利用rfb_x增强提取到的深层次特征,并多尺度的融合特征得到融合后的多维特征xe;
35.s4、将rfb_x输出的特征xe进行3*3卷积并通过亚像素卷积层放大,同时对输入 lr特征进行双三次上采样,并将lr图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加得到重建的超分辨率图像。
36.进一步地,所述s2的特征提取模块实现深层特征提取的过程如下,
37.x0=f
ife
(i
lr
)(1)
[0038][0039]
其中,i
lr
是输入的lr图像,f
ife
为一个3*3大小的卷积操作,x0为提取到的初始特征,为第i(i=0,1,
…
,7)个渐进式特征融合块pffb的映射函数,x
i 1
为特征提取模块第i个pffb提取的深层特征。
[0040]
进一步地,所述s3的重建模块利用rfb_x增强提取到的深层次特征的过程为,
[0041]
xe=f
rfb_x
(x8)(3)
[0042]
其中,f
rfb_x
为使用rfb_x对经过8个pffb块提取到的深层特征x8进行增强的函数,xe为增强结果,即rfb_x输出的多维特征。
[0043]
进一步地,所述s4按照以下公式完成重建,
[0044]isr
=f
p
(xe) f
up
(i
lr
)(4)
[0045]
其中,f
p
是对增强结果xe进行3*3卷积和亚像素卷积操作,f
up
是将输入的低分辨率lr图像进行双三次上采样操作,i
sr
是最后得到的超分辨率sr图像。
[0046]
一种电子设备,采用上述的方法实现图像重建。
[0047]
一种计算机存储介质,所述存储介质中存储有至少一条程序指令,所述至少一条程序指令被处理器加载并执行以实现上述的图像重建方法。
[0048]
本发明的有益效果是:
[0049]
本发明为改善图像质量,提升观测效果,针对现有超分辨率重建算法由于网络层数过深导致的信息丢失、参数量大的问题,提出一种高效多注意力特征融合的图像超分辨率重建算法(emaffn)。该算法通过渐进式特征融合块(pffb)逐步提取图像的特征信息,减少特征信息在深层次网络传递过程中的丢失,同时结合pffb内部的高效多注意力块(emab)在通道和空间两个分支作用,自适应的对提取到的特征进行加权,使网络更多的关注高频信息,最后使用多尺度感受野块(rfb_x)对提取到的特征进行增强、并多尺度融合特征来提升重建模块的性能。本发明重建后的图像能恢复更多的高频信息,纹理细节丰富,更接近于原始图像。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0051]
图1是本发明实施例重建模型的结构示意图。
[0052]
图2是本发明实施例重建模型中的渐进式特征融合块pffb的结构示意图。
[0053]
图3是本发明实施例重建模型中的高效多注意力块emab的结构示意图。
[0054]
图4是本发明实施例重建模型中的多尺度感受野块rfb_x的结构示意图。
[0055]
图5是本发明实施例的重建方法与其他算法对低分辨率图像放大因子
×
4时的重建效果对比图。
具体实施方式
[0056]
下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0057]
实施例1,
[0058]
一种高效多注意力特征融合的超分辨率重建模型,其结构如图1所示,包括特征提取模块和重建模块;
[0059]
其中特征提取模块分为浅层特征提取模块和深层特征提取模块,
[0060]
浅层特征提取模块为一个3*3卷积层,对输入的低分辨率lr图像在低维空间进行初始特征提取,有效减少其计算量;
[0061]
深层特征提取模块包含8个渐进式特征融合块(pffb),
[0062]
如图2,pffb采用渐进式融合的连接方式逐步提取图像的深层次特征信息以加强特征传递,同时结合其内部的高效多注意力块(emab)对提取到的特征信息进行加权使网络更多的关注高频信息;pffb中采用四个高效多注意力块(emab)层层递进,逐步提取图像的深层次信息;pffb通过多次通道随机混合(c shuffle),实现对emab块中卷积层结果的“信息交互”,将输出的通道进行重新分组,然后混合不同通道的信息,解决卷积层之间的信息流通不畅,不增加计算量的同时使通道充分融合;pffb对每个经 emab块提取到的特征进行c shuffle,随后连接相邻两个经c shuffle处理的特征再次进行c shuffle以提高网络的泛化能力,使用1*1卷积移除冗余信息,产生的结果与下一个经c shuffle操作的信息进行特征融合;在pffb内的emab块间重复此操作,逐步收集局部信息并进行特征融合,加强特征传递,有助于提升重建图像的精度;最后采用残差学习将输入特征xi与融合后的特征叠加得到第i(i=0,1,
…
,7)个pffb块的输出特征x
i 1
,最大限度的利用了lr图像信息来缓解特征在传递过程中的丢失;pffb通过“渐进式”特征融合的连接方式,加强特征提取并对提取到的多层信息进行融合,方便每一层充分利用前面层数学习到的所有特征,使有限的特征实现更好的传递和重用。
[0063]
如图3,emab充分利用通道和空间的特征信息逐步对图像的浅层特征去噪,使网络侧重于关注图像中高频细节,有助于增强重建后图像的纹理细节信息;emab在两个 3*3卷积核后使用1*1卷积层缩减通道尺寸,通过步长为2的步长卷积扩大感受野并结合 2*2的最大池化层进一步降低网络的空间维数;之后使用空洞卷积层进一步聚合感受野的上下文信息,降低内存的同时提升网络性能,将得到的特征进行上采样操作恢复空间维度,并通过1*1卷积恢复通道维度;emab在3个卷积层后使用激活函数frelu来加快收敛速度、防止梯度爆炸;emab采用高效通道注意力块,避免维度缩减带来的问题,通道注意力由快速的一维卷积生成,通过通道维数的非线性映射自适应确定内部卷积核的尺寸;一维卷积可以高效实现局部跨通道交互,通过捕获局部跨通道的信息,完成其间的相互交流,学习有效的通道注意力。
[0064]
重建模块,由多尺度感受野块rfb_x、一个3*3卷积和一个亚像素卷积层组成,rfb_x 利用多分支结构对pffb块提取的特征进一步增强,并融合多尺度的特征信息来提升模型的重建性能
[0065]
如图4,重建模块中的多尺度感受野块rfb_x由1*1、3*3、1*3和3*1卷积核组合而成;rfb_x位于顺序连接的8个pffb之后,负责增强提取到的深层次特征,多尺度的融合特征并重建,保留了深度丰富的特征、恢复了图像细节;具体来说,将第8个pffb块的输出特征x8作为rfb-x块的输入,使用不同大小的多分支卷积层进行多尺度特征提取,同时引入不同空洞率的空洞卷积,空洞卷积的空洞率越大则采样点离中心点越远,感受野就越大,有助于在更大的区域捕获信息以生成效果更好的特征图,同时不增加参数量;最后连接多个分支的输出以多尺度的融合不同特征,得到rfb_x提取的特征xe。
[0066]
如图1,最后将rfb_x提取的特征xe、低分辨率lr图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加得到重建后的图像。
[0067]
实施例2,
[0068]
一种高效多注意力特征融合的超分辨率重建方法,按照以下步骤进行:
[0069]
s1、将低分辨率lr图像输入高效多注意力特征融合的超分辨率重建模型;
[0070]
s2、超分辨率重建模型的特征提取模块,完成对lr图像的浅层特征的提取后,经过8个渐进式特征融合块(pffb)实现深层特征提取,并送入重建模块;
[0071]
s3、重建模块利用rfb_x增强提取到的深层次特征,并多尺度的融合特征得到融合后的多维特征xe;
[0072]
s4、将rfb_x输出的特征xe进行3*3卷积并通过亚像素卷积层放大,同时对输入lr特征进行双三次上采样,并将lr图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加得到重建的超分辨率图像。
[0073]
进一步地,所述s2的特征提取模块实现深层特征提取的过程如下,
[0074]
x0=f
ife
(i
lr
)(1)
[0075][0076]
其中,i
lr
是输入的lr图像,f
ife
为一个3*3大小的卷积操作,x0为提取到的初始特征,为第i(i=0,1,
…
,7)个渐进式特征融合块pffb的映射函数,x
i 1
为特征提取模块第i个pffb提取的深层特征。
[0077]
进一步地,所述s3的重建模块利用rfb_x增强提取到的深层次特征的过程为,
[0078]
xe=f
rfb_x
(x8)(3)
[0079]
其中,f
rfb_x
为使用rfb_x对经过8个pffb块提取到的深层特征x8进行增强的函数,xe为增强结果,即rfb_x输出的多维特征。
[0080]
进一步地,所述s4按照以下公式完成重建,
[0081]isr
=f
p
(xe) f
up
(i
lr
)(4)
[0082]
其中,f
p
是对增强结果xe进行3*3卷积和亚像素卷积操作,f
up
是将输入的低分辨率lr图像进行双三次上采样操作,i
sr
是最后得到的超分辨率sr图像。
[0083]
为减小重建误差,使用l1损失函数对网络中的参数进行优化训练。对于给定的n个lr-hr图像对训练集优化目标如下:
[0084][0085]
其中,k表示训练集中的第k对lr-hr图像,k∈[1,n]且k∈z,n取800,θ={wk,bk}为
模型的学习参数,h
sr
即本文模型。通过不断训练优化模型参数使l(θ)达到最小值,使得重建后的图像尽可能接近于真实图像。
[0086]
为了验证本发明实施例的高效多注意力特征融合的图像超分辨率重建方法的有效性,选择超分辨率重建中四个广泛使用的基准数据集:set5,set14,bsd100,urban100作为测试集,将keys的算法(r.keys,cubic convolution interpolation for digital image processing, in ieee transactions on acoustics,speech,and signal processing,vol.29,december 1981, pp.1153-1160.);dong的算法(c.dong,c.c.loy,k.he,x.tang,image super-resolutionusing deep convolutional networks,in proc.ieee conf.comput.vis.pattern recognit. (cvpr),2014,pp.184-199.);dong的算法(c.dong,c.c.loy,x.tang,accelerating thesuper-resolution convolutional neural network,computer vision-eccv workshops,2016,pp. 391-407);shi的算法(w.shi,j.caballero,f.huszar,et al.,real-time single image and videosuper-resolution using an efficient sub-pixel convolutional neural network,in proc.ieee confcomput vis.pattern recognit(cvpr),2016,pp.1874-1883);kim的算法(j.kim,k.j.lee, m.k.lee,accurate image super-resolution using very deep convolutional networks,inproc.ieee conf comput.vis.pattern recognit(cvpr),2016,pp.1646-1654);ahn的算法 (n.ahn,b.kang,a.k.sohn,fast,accurate,and lightweight super-resolution withcascading residual network,computer vision-eccv workshops,2018,pp.252-268);zhao 的算法(h.zhao,x.kong,j.he,et al.,efficient image super-resolution using pixel attention, computer vision-eccv workshops,2020,pp.56-72);tian的算法(c.tian,y.xu,w.zuo, et al.,coarse-to-fine cnn for image super-resolution,ieee transactions on multimedia,vol. 23,2021,pp.1489-1502)和本发明的实验结果进行主客观两个方面对比分析验证。
[0087]
如图5所示,为本发明实施例提供的高效多注意力特征融合的图像超分辨率重建方法与其他算法在测试集urban100上的图像重建实验效果对比图。左边较大的图为高分辨率的原图像,将图像中纹理细节丰富的地方用矩形框标记并放大,右边八幅较小的图按照从左向右、从上向下的顺序,分别为原图像,dong的srcnn方法重建结果图,dong 的fsrcnn方法重建结果图,kim的vdsr方法重建结果图,ahn的carn方法重建结果图,zhao的pan方法重建结果图,tian的cfsrcnn方法重建结果图以及本发明实例方法的重建结果图。能够观察到,本实例方法重建出的图像几乎准确的恢复出条纹的形状,边缘轮廓最为清晰;而其他方法重建出的图像均存在视觉模糊的现象,未能有效还原图像中的真实内容。因此,本发明实例的方法的重建效果优势较为明显,重建后的图像恢复了较多的高频信息,更接近于原始图像。
[0088]
本实例为避免定性分析带来的偏差,使用峰值信噪比(psnr)和结构相似度(ssim)两个客观指标进行客观定量分析,在set5,set14,bsd100,urban100四个测试数据集上,与keys的bicubic算法、dong的srcnn算法、dong的fsrcnn算法、shi的espcn 算法、kim的vdsr算法、ahn的carn算法、zhao的pan算法、tian的cfsrcnn 算法进行放大倍数为2、3、4倍的重建效果比较,如表1所示:
[0089]
表1不同算法在测试集上的psnr和ssim值
[0090][0091]
对于psnr和ssim,其数值越高,表示结果与真实的图像更为相似,图像质量越高。从表1可以看出,在
×
4放大倍数下,本发明实施例的方法在四个测试集上获得了最优的 ssim值。通过比较可以看到除了在部分数据集上pan算法的psnr和ssim值略高于本发明实施例的方法以外,与其他方法比较本发明实施例的方法均取得最优值。其中,本发明实施例的方法的psnr平均值最高达到37.93db,ssim最优达到0.9609。因此,本发明实施例的方法对于重建图像的峰值信噪比和结构相似度有较大的提升,重建后的图像视觉质量得到提高,细节特征更丰富。
[0092]
本发明实施例所述图像的重建方法如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器或者网络设备等)执行本发明实施例所述图像的重建方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、rom、 ram、磁碟或
者光盘等各种可以存储程序代码的介质。
[0093]
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。