1.本公开涉及数据处理
技术领域:
:,尤其涉及一种数据多维度交叉分析方法和装置。
背景技术:
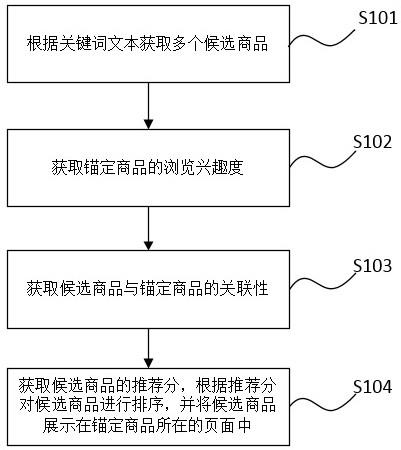
::2.数据多维度交叉分析是指对数据在不同维度进行交叉展现,进行多角度结合分析的方法。数据多维度交叉分析方法是商业、金融、社会科学等研究中最常用的数据分析方式。目前,excel的数据透视表、网页的数据透视表以及pandas的pivot功能可以实现对数据的多维度交叉分析,但是由于受内存大小的限制,难以支持大体量数据的多维交叉分析。技术实现要素:3.有鉴于此,本公开提出了一种数据多维度交叉分析方法和装置,可以支持大数据量的多维交叉分析。4.根据本公开的第一方面,提供了一种数据多维度交叉分析方法,包括:获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;基于所述数据源、所述行维度、所述列维度和所述度量生成数据库查询语句,并基于所述数据库查询语句从数据库中加载待分析数据;将所述待分析数据中的列维度由行转换为列,得到所述行维度和所述列维度关于所述度量的交叉分析结果。5.在一种可能的实现方式中,所述数据库查询语句为sql语句;在基于所述数据源、所述行维度、所述列维度和所述度量生成sql语句时,包括:获取预设的sql语句拼接模板,其中,所述sql语句拼接模板中包括查询参数;基于所述数据源、所述行维度、所述列维度和所述度量获取所述查询参数,并将所述查询参数填充至所述sql语句拼接模板中,得到所述sql语句。6.在一种可能的实现方式中,在获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量时,还包括获取汇总方式、筛选条件、排序方式以及展示数量配置中至少一种配置信息。7.在一种可能的实现方式中,所述汇总方式包括行分组汇总、列分组汇总、列汇总、行汇总和总计中的至少一种,其中,所述行分组汇总为对组内的数据进行行汇总,所述列分组汇总为对组内的数据进行列汇总;在获取到所述汇总方式的情况下,在得到所述交叉分析结果之后,还包括计算所述汇总方式的汇总数据,并将所述汇总数据添加至所述交叉分析结果中的操作。8.在一种可能的实现方式中,所述筛选条件包括指定维度的筛选条件和不指定维度的筛选条件中的至少一种;在获取到所述筛选条件的情况下,在得到所述交叉分析结果之后,还包括由所述交叉分析结果中筛选出满足所述筛选条件的交叉分析结果的操作。9.在一种可能的实现方式中,所述排序方式包括按照排序字段排序、按照字母表排序和按照度量值排序中的至少一种,其中,按照排序字段排序即按照字段的预设顺序进行排序;在获取到所述排序方式的情况下,在得到所述交叉分析结果之后,还包括按照所述排序方式对所述交叉分析结果进行排序,得到满足所述排序方式的交叉分析结果的操作。10.在一种可能的实现方式中,所述展示数量配置包括指定数量显示配置、展开折叠显示配置和分页显示配置中的至少一种;在获取到所述展示数量配置的情况下,在得到所述交叉分析结果之后,还包括根据所述展示数量配置对所述交叉分析结果进行显示的操作。11.在一种可能的实现方式中,在获取到所述汇总方式、所述筛选条件、所述排序方式的情况下,还包括对所述待分析数据、添加汇总数据的交叉分析结果、满足所述筛选条件的交叉分析结果以及满足所述排序方式的交叉分析结果进行分级缓存的操作。12.在一种可能的实现方式中,还包括基于所述分级缓存结果对所述交叉分析结果进行筛选的操作。13.根据本公开的第二方面,提供了一种数据多维度交叉分析装置,包括:数据配置模块,用于获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;数据加载模块,用于基于所述数据源、所述行维度、所述列维度和所述度量生成数据库查询语句,并基于所述数据库查询语句从数据库中加载待分析数据;数据展示模块,用于将所述待分析数据中的列维度由行转换为列,得到所述行维度和所述列维度关于所述度量的交叉分析结果。14.在本公开中,在对大数据量进行交叉分析时,先获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;然后,基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据;最后,将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。本公开在面对大数据量的多维交叉分析时,并不需要将大数据量的数据源全部加载至内存中,仅需要通过生成的数据库查询语句将待分析的数据加载至内存即可实现待分析数据的多维交叉分析,这样就避免了受内存大小限制而不能支持大数据量数据的多维交叉分析的问题。15.根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。附图说明16.包含在说明书中并且构成说明书的一部分的附图与说明书一起示出了本公开的示例性实施例、特征和方面,并且用于解释本公开的原理。17.图1示出根据本公开一实施例的数据多维度交叉分析方法的流程图;图2示出根据本公开一实施例的数据多维度交叉分析的前端页面界面图;图3示出根据本公开另一实施例数据多维度交叉分析方法的流程图;图4示出根据本公开一实施例数据多维度交叉分析装置的示意性框图。具体实施方式18.以下将参考附图详细说明本公开的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。19.在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。20.另外,为了更好的说明本公开,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本公开同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本公开的主旨。21.《方法实施例》在执行本公开的数据多维交叉分析时,需要前端页面、后端服务器以及数据库三端交互实现。其中,前端页面用于获取数据多维交叉分析的的配置信息发送至后端服务器,并显示后端服务器推送的交叉分析结果。后端服务器用于根据前端设置的配置信息由数据库中加载待分析数据,根据前端设置的配置信息计算出待分析数据的交叉分析结果,并将计算出的交叉分析结果推送显示至前端页面。数据库用来存储待分析数据的数据源。22.下面以后端服务器为实施主体,对本公开中的数据多维度交叉分析方法进行说明。如图1所示后端服务器在执行该数据多维交叉分析方法时包括步骤s1100-s1300。23.s1100,获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量。24.在执行步骤s1100之前,需要先通过前端页面对待分析数据的数据源、进行交叉分析的行维度、列维度和度量进行配置。25.在一种可能的实现方式中,前端页面可以包括如图2中右侧所示的数据配置区。该数据配置区包括数据源配置区、数据维度选择区、列维度配置区、行维度配置区以及度量配置区(即图2中的值配置区)中的至少一种。26.该数据源配置区用于配置待分析数据的数据源的主题,在数据源的主题选定的情况下,将在数据维度选择区中显示与该主题相关联的维度和度量,这样便可以根据需求在数据维度选择区中选择对应的维度拖拽至行维度配置区和列维度配置区,选择对应的度量拖拽至度量配置区,以完成待分析数据的数据源、行维度、列维度和度量的配置。27.举例来说,数据库中存储由面部护肤的数据源,该面部护肤数据源关联的分析维度包括渠道、子渠道、店铺、年度、季度、月份、价格区间等,度量包括销售额之和,销售量之和等。在用户需要对数据库中的面部护肤数据进行分析时,可以在数据源配置区中输入或者选择面部护肤,此时,将在数据维度选择区中显示出与面部护肤数据源关联的分析维度和度量。进一步地,在用户需要分析各渠道在各季度下的销售额之和的情况下,可以在数据维度选择区中选取渠道拖拽至行维度配置区,选取季度拖拽至列维度配置区,选取销售额之和拖拽至度量配置区,点击前端页面中的应用控件,便可以完成待分析数据的数据源、行维度、列维度和度量的配置。28.前端页面在应用控件被触发的情况下,将会将用户配置的待分析数据的数据源、行维度、列维度和度量发送至后端服务器,这样后端服务器便可以获取到待分析数据的数据源、行维度、列维度和度量。29.s1200,基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据。30.在一种可能的实现方式中,数据库查询语句可以是sql语句,也就是说后端服务器在获取到待分析数据的数据源、行维度、列维度和度量时,将基于待分析数据的数据源、行维度、列维度和度量生成sql语句,以通过sql语句从数据库中加载待分析数据。31.在一种可能的实现方式中,后端服务器在基于数据源、行维度、列维度和度量生成sql语句时,可以包括以下步骤:第一,获取预设的sql语句拼接模板,其中,sql语句拼接模板中包括多个查询参数。第二,基于数据源、行维度、列维度和度量生成各个查询参数,并将查询参数填充至sql语句拼接模板中,得到sql语句。32.在一种可能的实现方式中,预设的sql语句拼接模板采用双层结构,该双层结构的sql语句拼接模板可以如下所示:select[sqldimensionouter],[sqlmeasureouter]from(ꢀꢀselect[sqldimensioninner],[sqlmeasureinner]ꢀꢀfrom[subjecttable]aꢀꢀleftjoin[sqljoininner]ꢀꢀwhere[where]ꢀꢀgroupby[sqldimensiongroup])aaleftjoin[sqljoinouter]其中,该sql语句拼接模板中的查询参数包括:外层sql维度展示sqldimensionouter,外层sql度量展示sqlmeasureouter,内层sql维度展示sqldimensioninner,内层sql度量展示sqlmeasureinner,主题表subjecttable,内层sql关联条件sqljoininner,主题表过滤条件where,sql聚合字段sqldimensiongroup以及外层sql关联条件sqljoinouter。[0033]在获取到sql语句拼接模板后,后端服务器将基于前端页面中配置的待分析数据的数据源、行维度、列维度和度量生成以上查询参数。[0034]具体地,后端服务器在获取到数据源、行维度、列维度和度量后,分别查询数据源对应的主题配置表、行维度对应的维度配置表,列维度对应的维度配置表以及度量对应的度量配置表。读取主题配置表中的主题表和主题过滤条件,分别生成主题表subjecttable和主题表过滤条件where。读取维度配置表中维度表名,维度表中的键,维度表中的值,维度的名称可以拼接生成外层sql维度展示sqldimensionouter,内层sql维度展示sqldimensioninner,sql聚合字段sqldimensiongroup。另外,通过维度配置表中的是否先关联后聚合字段,可以配置内层sql关联条件sqljoininner,以及外层sql关联条件sqljoinouter,如果是先关联后聚合那么维度的关联条件会出现在内层sql关联条件sqljoininner,否则会出现在外层sql关联条件sqljoinouter。读取度量配置表中的度量名和度量的计算函数,来拼接外层sql度量展示sqlmeasureouter,内层sql度量展示sqlmeasureinner。[0035]在生成sql语句拼接模板中所有的查询参数后,将查询参数填充至sql语句拼接模板中,即可得到sql语句。这样,后端服务器便可以利用生成的sql语句从数据库中加载出待分析数据。[0036]下面以行维度为渠道,列维度为月份,度量为销售额之和为例,对整个sql语句的生成过程进行进一步说明。由于渠道维度设置了先关联后聚合字段为是,而月份维度设置了先关联和聚合维度为否,所以渠道维度出现在外层,月份维度出现在内层。整个sql的伪代码如下:selectisnull(cast(aa.《渠道维度的值字段》asvarchar(100)),'其他')《渠道维度的标签》,ꢀꢀꢀꢀꢀꢀꢀcasewhenaa.《时间维度的主题字段》isnullthen'其他'ꢀꢀꢀꢀꢀꢀꢀwhen《时间维度的名称》.《时间维度的值字段》isnullthen'code_' cast(aa.《时间维度的键字段》asvarchar(100))ꢀꢀꢀꢀꢀꢀꢀelsecast(《时间维度的名称》.《时间维度的值字段》asvarchar(100))end《时间维度的标签》,ꢀꢀꢀꢀꢀꢀꢀaa.《销售额度量的名称》from(ꢀꢀꢀꢀꢀꢀꢀꢀselecta.《时间维度的主题字段》,《渠道维度的名称》.《渠道维度的值字段》,ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ《销售额度量的函数》/1.0《销售额度量的名称》ꢀꢀꢀꢀꢀꢀꢀꢀfrom《主题表名》aꢀꢀꢀꢀꢀꢀꢀꢀleftjoin《渠道维度的表名》《渠道维度的名称》ona.《渠道维度的主题字段》=《渠道维度的名称》.《渠道维度的键字段》ꢀꢀꢀꢀꢀꢀꢀꢀwhere《主题表筛选条件》ꢀꢀꢀꢀꢀꢀꢀꢀgroupbya.《时间维度的主题字段》,《渠道维度的名称》.《渠道维度的值字段》)aaleftjoin《时间维度的表名》《时间维度的名称》onaa.《时间维度的主题字段》=《时间维度的名称》.《时间维度的键字段》生成的详细sql如下:selectisnull(cast(aa.medianameasvarchar(100)),'其他')渠道,ꢀꢀꢀꢀꢀꢀꢀcasewhenaa.monthidisnullthen'其他'ꢀꢀꢀꢀꢀꢀꢀwhendim_month.monthnameisnullthen'code_' cast(aa.monthidasvarchar(100))ꢀꢀꢀꢀꢀꢀꢀelsecast(dim_month.monthnameasvarchar(100))end月份,ꢀꢀꢀꢀꢀꢀꢀaa.销售额from(ꢀꢀꢀꢀꢀꢀꢀꢀselecta.monthid,table_dim_media.medianame,ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀsum(itemsalesvalue)/1.0销售额ꢀꢀꢀꢀꢀꢀꢀꢀfromjahwa_data_subjectaꢀꢀꢀꢀꢀꢀꢀꢀleftjointable_mediadim_mediaona.mediaid=dim_media.channelidꢀꢀꢀꢀꢀꢀꢀꢀwhere1=1anda.monthid》=202001anda.monthid《=202206ꢀꢀꢀꢀꢀꢀꢀꢀgroupbya.monthid,dim_media.medianame)aaleftjointable_monthdim_monthonaa.monthid=dim_month.monthids1300,将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。[0037]在待分析数据中,配置的列维度也是以行维度的形式进行展示的,因此,在获取到待分析数据之后,需要将列维度由行维度展示的形式转为列维度展示的形式,以得到最终的交叉分析结果。[0038]表1渠道子渠道季度total天m天m超市2020q1#天m天m超市2020q2#天m天m超市2020q3#天m天m超市2020q4#天m天m超市2021q1#天m天m超市2021q2#天m天m超市2021q3#天m天m超市2021q4#天m天m国际2020q1#天m天m国际2020q2#天m天m国际2020q3#天m天m国际2020q4#天m天m国际2021q1#天m天m国际2021q2#天m天m国际2021q3#天m天m国际2021q4#举例来说,在数据源为面部护肤,行维度为渠道和子渠道,列维度为季度,度量为销售额之和的情况下,基于生成的sql语句从数据库中加载出的待分析数据的节选数据如表1所示。[0039]从表1中可以看出,季度作为列维度也是以行维度的形式进行展示的,因此,需要将待分析数据中的季度由行维度的展示形式转换成列维度的展示形式,以得到对应的交叉分析结果,其中,交叉分析结果节选数据可以如表2所示。[0040]表2此处需要说明的是,本公开中所有的#均指代行维度和列维度关于度量的交叉分析结果值。[0041]在本公开中,在对大数据量进行交叉分析时,先获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;然后,基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据;最后,将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。本公开在面对大数据量的多维交叉分析时,并不需要将大数据量的数据源全部加载至内存中,仅需要通过生成的数据库查询语句将待分析的数据加载至内存即可实现数据的多维交叉分析,这样就避免了受内存大小限制不能支持大数据量数据的多维交叉分析的问题。[0042]在一种可能的实现方式中,前端页面中还可以包括如图2中所示的展示配置区(位于左侧区域顶端)和数据筛选配置区(位于展示配置区与数据展示区之间)。[0043]该展示配置区中包括图形类型配置区、度量展示配置区、汇总方式配置区、展示数量配置(图中未示出)。其中,该图像类型配置区可以选择的图行类型包括可以包括表格、柱形图、柱形堆积图、条形图、条形堆积图、折线图、散点图、面积图、扇形图、环形图中的至少一种。该度量展示配置区可以选择的度量展示方式可以包括数据值、总计百分比,行百分比,列百分比中的至少一种。其中,总计百分比为度量值占所有度量值之和的百分比,行百分比为度量值占行度量值之和的百分比,列百分比为度量占列度量值之和的百分比。该汇总方式配置区可以选择的汇总方式可以包括行分组汇总、列分组汇总、列汇总、行汇总和总计中的至少一种。该行分组汇总为对组内的数据进行行汇总,该列分组汇总为对组内的数据进行列汇总。该展示数量配置区可以选择的展示数据配置可以包括指定数量显示配置、展开折叠显示配置和分页显示配置中的至少一种。[0044]该数据筛选配置区包括筛选条件配置区、搜索条件配置区(图中未示出)。其中,该筛选条件配置区可以配置的筛选条件可以包括指定维度的筛选条件和不指定维度的筛选条件中的任一种,以满足用户对不同筛选精度的需求。该指定维度的筛选条件适用于对指定维度的数据进行筛选,不指定维度的筛选条件适用于对所有维度下的数据进行筛选。在一种可能的实现方式中,指定维度的筛选条件又可以包括指定维度的精确搜索和指定维度的模糊搜索中的任一种。[0045]在如图2所示的前端页面中,用户在配置待分析数据的数据源、行维度、列维度、度量的同时,还可以实现对图行类型、度量展示方式、汇总方式、筛选条件、搜索条件以及展示数量配置等配置信息中的至少一种配置信息的配置,这样在前端页面中的应用控件被触发的情况下,就可以将待分析数据的数据源、行维度、列维度和度量,以及图行类型、度量展示方式、汇总方式、筛选条件、搜索条件以及展示数量配置中至少一种配置信息发送至后端服务器,以便后端服务器可以获取到前端页面中配置的各种配置信息。[0046]在后端服务器获取到图形类型的情况下,在得到交叉分析结果之后,将按照图形类型调整交叉分析结果的可视化效果。[0047]在后端服务器获取到度量展示方式的情况下,在得到交叉分析结果之后,将按照度量展示方式调整交叉分析结果中的度量展示。[0048]在后端服务器获取到汇总方式的情况下,在得到交叉分析结果之后,将计算出汇总方式对应的汇总数据,并将计算出的汇总数据添加至交叉分析结果中。例如,在汇总方式选择了行分组汇总、列分组汇总、行汇总、列汇总和总计5种汇总方式的情况下,后端服务器分别计算出5种汇总方式对应的汇总数据,并将5种汇总方式对应的汇总数据添加至交叉分析结果中,生成的汇总数据的数量为(行维度数量 1)*(列维度数量 1)-1。如果维度中只存在累加指标,那么通过汇总主数据就可以得到所有的汇总数据;否则就需要生成(行维度数量 1)*(列维度数量 1)-1条sql语句从数据库中追加抽取数据。添加了5种汇总方式的交叉分析结果可以如表3所示。[0049]表3在后端服务器获取到筛选条件的情况下,在得到交叉分析结果之后,由交叉分析结果中筛选出满足筛选条件的交叉分析结果。[0050]举例来说,后端服务器接收到的行维度为渠道和子渠道、列维度为季度、度量为销售额之和。[0051]在接收到的筛选条件为“渠道=天m 季度=2020q2”(即指定维度的精确筛选条件)的情况下,后端服务器的得到交叉分析结果之后,将在交叉分析结果中筛选出天m渠道下各子渠道在2020q2季度的销售额之和,作为满足指定维度的精确筛选条件的交叉分析结果。实现方式为指定维度字符串等于条件的“且”逻辑运算。[0052]在接收到的筛选条件为“渠道问号京 季度=2020q2”(即指定维度的模糊筛选条件)的情况下,后端服务器在得到交叉分析结果之后,将从交叉分析结果中筛选出包含京字的渠道下各子渠道在2020q2季度的销售额之和,作为满足指定维度的模糊筛选条件的交叉分析结果。实现方式为指定维度字符串正则表达式匹配条件的“且”逻辑运算。[0053]在接收到的筛选条件为“天m,京”(即不指定维度的筛选条件)的情况下,后端服务器在得到交叉分析结果之后,将从交叉分析结果中筛选出包括天m或京字的渠道或子渠道在各季度的销售额之和,作为最终的交叉分析结果。实现方式为所有维度字符串正则表达式匹配条件的“或”逻辑运算。[0054]搜索条件参照筛选条件在此不在赘述。[0055]在后端服务器获取到展示数量配置的情况下,在得到交叉分析结果之后,后端服务器将按照展示数量配置调整交叉分析结果的可视化效果。举例来说,在后端获取到的展示数量配置为显示前5条(即指定数量显示配置)的情况下,后端服务器将从得到的交叉分析结果中筛选出前5条推送显示至如图2所示的前端页面的数据展示区(位于前端页面的左下端即图2中表格所在的区域)。在后端获取到的展示数量配置为分页显示(即分页显示配置)的情况下,后端服务器将按照前端页面展示区中能展示的最大数据条数从得到的交叉分析结果中进行数据筛选,并将筛选出的结果推送显示至如图2所示的前端页面的数据展示区,这样可以防止数据过载。在后端获取到的展示数量配置展开折叠显示配置的情况下,后端服务器将在得到的交叉分析结果中添加展开折叠控件,并将带有展开折叠控件的交叉分析结果推送显示至如图2所示的前端页面的数据展示区。这样,用户便可以根据需求点击展开折叠控件,以实现对交叉分析结果中的数据进行展开和折叠的操作。[0056]需要说明的是,对于配置的每个维度,在后端服务器中均配置有对应的维表,在维表中可以配置该维度可以支持的排序方式。这样,后端服务器在生成交叉分析结果之后,便可以根据选定排序维度对应的排序方式对交叉分析结果进行排序,以得到满足选定排序维度对应的排序方式的交叉分析结果。[0057]在一种可能的实现方式中,维表中可以支持的排序方式可以包括按照排序字段排序、按照字母表排序和按照度量值排序中的至少一种,其中,按照排序字段排序即按照字段的预设顺序进行排序。[0058]此处需要说明的是,对于一些特殊维度通常不能按照度量值或者按照字母排序进行排序,因此,对于这些特殊的维度需要在数据库中预先配置该维度下各维度值的排序信息并进行存储,这样,在选定的排序维度为特殊维度的情况下,后端服务器将通过sql语句从数据库中加载该维度下各维度值的排序信息,然后根据该维度下各维度值的排序信息对该维度进行排序。[0059]举例来说,对于价格区间这个维度的维度值为数值区间,例如,[0-20),[20,40),[40,60),[60,80)等,该数值区间是无法按照度量值或者字母排序进行排序的,因此,需要先配置该价格区间维度下各价格区间值的排序值并存储至数据中,这样,在选定的排序维度为价格区间的情况下,后端服务器将通过sql语句从数据库中加载该价格区间维度下各价格区间值的排序值,并根据各价格区间值的排序值对价格区间维度进行排序。[0060]在一种可能的实现方式中,后端服务器在得到待分析数据、添加汇总数据的交叉分析结果、满足筛选条件的交叉分析结果、满足排序方式的交叉分析结果之后,将对得到的各结果进行分级缓存,这样,便可以基于分级缓存结果交叉分析结果执行搜索条件,以提高数据的查询效率。[0061]下面结合图3,对本公开的数据多维度交叉分析方法进行进一步的说明。[0062]后端服务器在执行数据多维交叉分析前,用户需要先根据需求在前端页面中完成数据源、进行交叉分析的列维度、行维度、度量、汇总方式、筛选条件、排序方式、搜索条件以及展示数据量等配置信息的配置,前端页面在应用控件被触控的情况下,将以上配置信息通过http协议发送至后端服务器。[0063]后端服务器在接收到以上配置信息后,将执行以下操作步骤:步骤s0,config配置。具体地,基于接收到的数据源、列维度、行维度、度量将对应的主题配置信息、维度配置信息、度量配置信息、主题与维度映射关系以及主题与度量的映射关系等配置信息加载至后端服务器,在拼接sql,获取排序信息,滞后维度数据等过程中直接读取配置信息,这样在后续运算中就可以不用从数据库中读取对应的配置信息,从而提高运算效率。其中,配置的列维度或行维度中包括滞后维。[0064]此处需要说明的是,对于滞后维在运算过程中通过滞后为的id进行表示,在最后生成交叉分析结果时,再将滞后维的id替换成滞后维的维度值。[0065]步骤s1,init初始化。具体地,根据接收到的数据源、列维度、行维度、度量生成sql语句。生成sql语句的方法参照上文,在此不再赘述。[0066]步骤s2,lazy加载滞后维。具体地,提前将滞后维的id与维度值的映射关系存储至一个字典中。[0067]步骤s3,load加载数据。具体地,根据初始化生成的sql语句,从数据库中加载数据待分析数据,如果待分析数据为空,则增加一条虚拟空数据。在加载到待分析数据后,先判断该待分析数据是否已经缓存至预设的一级缓存,在未缓存至一级缓存时,先执行将待分析数据存入一级缓存的步骤,在执行步骤s4;在已经存入至一级缓存时,直接执行步骤s4。[0068]步骤s4,agg汇总数据。具体地,根据前端配置的汇总方式,对待分析数据进行汇总,得到对应的汇总数据,并将对应的汇总数据添加至待分析数据中。在得到汇总后的待分析数据后,先判断汇总后的待分析数据是否已经缓存至预设的二级缓存中,在为缓存至二级缓存的情况下,先将汇总后的待分析数据缓存至二级缓存中,在执行步骤s5;在已经缓存至二级缓存的情况下,直接执行步骤s5。[0069]步骤s5,filter筛选数据。具体地,根据前端页面配置的筛选条件生成对应的筛选字典,然后筛选字典由汇总后的待分析数据中筛选出满足筛选条件的待分析数据。其中,前端配置的筛选条件可以是指定维度的精确筛选条件、指定维度的模糊筛选条件以及不指定维度的筛选条件中任一种。在得到满足筛选条件的待分析数据后,判断满足筛选条件的待分析数据是否已经缓存至预设的三级缓存中,在未存入三级缓存的情况下,先将满足筛选条件的待分析数据存入三级缓存中,在执行步骤s6;在已经存入三级缓存的情况下,直接执行步骤s6。[0070]此处需要说明的是,在进行数据筛选时,筛选的是维度的名称,因此,在维度中涉及滞后维时,需要先根据字典将滞后维的id替换为滞后为的名称,然后在进行数据的筛选。[0071]步骤s6,pivot数据变换。具体地,将满足筛选条件的待分析数据中展示在行上的列维度数据转换至列上进行显示。[0072]步骤s7,sort排序数据。具体地,根据前端页面配置的排序方式生成对应的排序字典,根据排序字典对步骤s6输出的结果进行排序,得到满足排序方式的待分析数据。判断满足排序方式的待分析数据是否存入预设的四级缓存,在未存入四级缓存的情况下,先将满足排序方式的待分析数据存入四级缓存,再执行步骤s8;在已存入四级缓存的情况下,直接执行步骤s8。[0073]步骤s8,index索引数据。具体地,分别生成满足排序方式的待分析数据中行维度数据和列维度数据的索引数据,并根据生成的索引数据生成交叉分析结果。[0074]步骤s9,search搜索数据。具体地,根据前端配置的搜索条件在上述四级缓存中查找对应的数据,以提高数据的查询效率。[0075]步骤s10,前n条数据。具体地,根据前端配置的展示数量配置,调整交叉分析结果中数据数量的展示效果,并将最终调整后的交叉分析结果推送显示至前端页面的数据展示区中。其中,展示数据配置可以是指定数量显示(top前多条)、展开折叠显示(expand展开)和分页显示(page分页)中的任一种。[0076]步骤s11,导出数据。具体地,在前端页面中配置了导出方式的情况下,可以按照前端页面配置的导出方式导出最终的交叉分析结果。其中,导出方式可以是html、json、excel、csv四种导出方式中的至少一种。[0077]另外,在日志模块在对象初始化的开始生成日志对象,记录执行过程和执行时间,可以用来优化分析过程。[0078]《装置实施例》图4示出根据本公开一实施例数据多维度交叉分析装置的示意性框图。如图4所示,数据多维度交叉分析装置100包括:数据配置模块110,用于获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;数据加载模块120,用于基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据;数据展示模块130,用于将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。[0079]在一种可能的实现方式中,数据库查询语句为sql语句;数据加载模块120包括sql语句生成子模块,用于基于数据源、行维度、列维度和度量生成sql语句;sql语句生成子模块包括模板获取单元和语句拼接单元;模板获取单元,用于获取预设的sql语句拼接模板,其中,sql语句拼接模板中包括查询参数;语句拼接单元,用于基于数据源、行维度、列维度和度量生成查询参数,并将查询参数填充至sql语句拼接模板中,得到sql语句。[0080]在一种可能的实现方式中,数据配置模块110还用于获取汇总方式、筛选条件、排序方式以及展示数量配置中至少一种配置信息。[0081]在一种可能的实现方式中,汇总方式包括行分组汇总、列分组汇总、列汇总、行汇总和总计中的至少一种,其中,行分组汇总为对组内的数据进行行汇总,列分组汇总为对组内的数据进行列汇总;数据多维度交叉分析装置100,还包括数据汇总模块,用于在获取到汇总方式的情况下,在得到交叉分析结果之后,还计算汇总方式的汇总数据,并将汇总数据添加至交叉分析结果中。[0082]在一种可能的实现方式中,筛选条件包括指定维度的筛选条件和不指定维度的筛选条件中的至少一种;数据多维度交叉分析装置100,还包括数据筛选模块,用于在获取到筛选条件的情况下,在得到交叉分析结果之后,由交叉分析结果中筛选出满足筛选条件的交叉分析结果。[0083]在一种可能的实现方式中,排序方式包括按照排序字段排序、按照字母表排序和按照度量值排序中的至少一种,其中,按照排序字段排序即按照字段的预设顺序进行排序;数据多维度交叉分析装置100,还包括数据排序模块,用于在获取到排序方式的情况下,在得到交叉分析结果之后,按照排序方式对交叉分析结果进行排序,得到满足排序方式的交叉分析结果。[0084]在一种可能的实现方式中,展示数量配置包括指定数量显示配置、展开折叠显示配置和分页显示配置中的至少一种;数据多维度交叉分析装置100,还包括数据展示数量调整模块,用于在获取到展示数量配置的情况下,在得到交叉分析结果之后,根据展示数量配置对交叉分析结果进行调整。[0085]在一种可能的实现方式中,数据多维度交叉分析装置100,还包括数据缓存模块,用于在获取到汇总方式、筛选条件、排序方式的情况下,对待分析数据、添加汇总数据的交叉分析结果、满足筛选条件的交叉分析结果以及满足排序方式的交叉分析结果进行分级缓存。[0086]在一种可能的实现方式中,数据多维度交叉分析装置100,还包括数据搜索模块,用于基于分级缓存结果对交叉分析结果进行筛选。[0087]以上已经描述了本公开的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本
技术领域:
:的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的技术改进,或者使本
技术领域:
:的其它普通技术人员能理解本文披露的各实施例。当前第1页12当前第1页12
技术领域:
:,尤其涉及一种数据多维度交叉分析方法和装置。
背景技术:
::2.数据多维度交叉分析是指对数据在不同维度进行交叉展现,进行多角度结合分析的方法。数据多维度交叉分析方法是商业、金融、社会科学等研究中最常用的数据分析方式。目前,excel的数据透视表、网页的数据透视表以及pandas的pivot功能可以实现对数据的多维度交叉分析,但是由于受内存大小的限制,难以支持大体量数据的多维交叉分析。技术实现要素:3.有鉴于此,本公开提出了一种数据多维度交叉分析方法和装置,可以支持大数据量的多维交叉分析。4.根据本公开的第一方面,提供了一种数据多维度交叉分析方法,包括:获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;基于所述数据源、所述行维度、所述列维度和所述度量生成数据库查询语句,并基于所述数据库查询语句从数据库中加载待分析数据;将所述待分析数据中的列维度由行转换为列,得到所述行维度和所述列维度关于所述度量的交叉分析结果。5.在一种可能的实现方式中,所述数据库查询语句为sql语句;在基于所述数据源、所述行维度、所述列维度和所述度量生成sql语句时,包括:获取预设的sql语句拼接模板,其中,所述sql语句拼接模板中包括查询参数;基于所述数据源、所述行维度、所述列维度和所述度量获取所述查询参数,并将所述查询参数填充至所述sql语句拼接模板中,得到所述sql语句。6.在一种可能的实现方式中,在获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量时,还包括获取汇总方式、筛选条件、排序方式以及展示数量配置中至少一种配置信息。7.在一种可能的实现方式中,所述汇总方式包括行分组汇总、列分组汇总、列汇总、行汇总和总计中的至少一种,其中,所述行分组汇总为对组内的数据进行行汇总,所述列分组汇总为对组内的数据进行列汇总;在获取到所述汇总方式的情况下,在得到所述交叉分析结果之后,还包括计算所述汇总方式的汇总数据,并将所述汇总数据添加至所述交叉分析结果中的操作。8.在一种可能的实现方式中,所述筛选条件包括指定维度的筛选条件和不指定维度的筛选条件中的至少一种;在获取到所述筛选条件的情况下,在得到所述交叉分析结果之后,还包括由所述交叉分析结果中筛选出满足所述筛选条件的交叉分析结果的操作。9.在一种可能的实现方式中,所述排序方式包括按照排序字段排序、按照字母表排序和按照度量值排序中的至少一种,其中,按照排序字段排序即按照字段的预设顺序进行排序;在获取到所述排序方式的情况下,在得到所述交叉分析结果之后,还包括按照所述排序方式对所述交叉分析结果进行排序,得到满足所述排序方式的交叉分析结果的操作。10.在一种可能的实现方式中,所述展示数量配置包括指定数量显示配置、展开折叠显示配置和分页显示配置中的至少一种;在获取到所述展示数量配置的情况下,在得到所述交叉分析结果之后,还包括根据所述展示数量配置对所述交叉分析结果进行显示的操作。11.在一种可能的实现方式中,在获取到所述汇总方式、所述筛选条件、所述排序方式的情况下,还包括对所述待分析数据、添加汇总数据的交叉分析结果、满足所述筛选条件的交叉分析结果以及满足所述排序方式的交叉分析结果进行分级缓存的操作。12.在一种可能的实现方式中,还包括基于所述分级缓存结果对所述交叉分析结果进行筛选的操作。13.根据本公开的第二方面,提供了一种数据多维度交叉分析装置,包括:数据配置模块,用于获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;数据加载模块,用于基于所述数据源、所述行维度、所述列维度和所述度量生成数据库查询语句,并基于所述数据库查询语句从数据库中加载待分析数据;数据展示模块,用于将所述待分析数据中的列维度由行转换为列,得到所述行维度和所述列维度关于所述度量的交叉分析结果。14.在本公开中,在对大数据量进行交叉分析时,先获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;然后,基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据;最后,将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。本公开在面对大数据量的多维交叉分析时,并不需要将大数据量的数据源全部加载至内存中,仅需要通过生成的数据库查询语句将待分析的数据加载至内存即可实现待分析数据的多维交叉分析,这样就避免了受内存大小限制而不能支持大数据量数据的多维交叉分析的问题。15.根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。附图说明16.包含在说明书中并且构成说明书的一部分的附图与说明书一起示出了本公开的示例性实施例、特征和方面,并且用于解释本公开的原理。17.图1示出根据本公开一实施例的数据多维度交叉分析方法的流程图;图2示出根据本公开一实施例的数据多维度交叉分析的前端页面界面图;图3示出根据本公开另一实施例数据多维度交叉分析方法的流程图;图4示出根据本公开一实施例数据多维度交叉分析装置的示意性框图。具体实施方式18.以下将参考附图详细说明本公开的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。19.在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。20.另外,为了更好的说明本公开,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本公开同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本公开的主旨。21.《方法实施例》在执行本公开的数据多维交叉分析时,需要前端页面、后端服务器以及数据库三端交互实现。其中,前端页面用于获取数据多维交叉分析的的配置信息发送至后端服务器,并显示后端服务器推送的交叉分析结果。后端服务器用于根据前端设置的配置信息由数据库中加载待分析数据,根据前端设置的配置信息计算出待分析数据的交叉分析结果,并将计算出的交叉分析结果推送显示至前端页面。数据库用来存储待分析数据的数据源。22.下面以后端服务器为实施主体,对本公开中的数据多维度交叉分析方法进行说明。如图1所示后端服务器在执行该数据多维交叉分析方法时包括步骤s1100-s1300。23.s1100,获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量。24.在执行步骤s1100之前,需要先通过前端页面对待分析数据的数据源、进行交叉分析的行维度、列维度和度量进行配置。25.在一种可能的实现方式中,前端页面可以包括如图2中右侧所示的数据配置区。该数据配置区包括数据源配置区、数据维度选择区、列维度配置区、行维度配置区以及度量配置区(即图2中的值配置区)中的至少一种。26.该数据源配置区用于配置待分析数据的数据源的主题,在数据源的主题选定的情况下,将在数据维度选择区中显示与该主题相关联的维度和度量,这样便可以根据需求在数据维度选择区中选择对应的维度拖拽至行维度配置区和列维度配置区,选择对应的度量拖拽至度量配置区,以完成待分析数据的数据源、行维度、列维度和度量的配置。27.举例来说,数据库中存储由面部护肤的数据源,该面部护肤数据源关联的分析维度包括渠道、子渠道、店铺、年度、季度、月份、价格区间等,度量包括销售额之和,销售量之和等。在用户需要对数据库中的面部护肤数据进行分析时,可以在数据源配置区中输入或者选择面部护肤,此时,将在数据维度选择区中显示出与面部护肤数据源关联的分析维度和度量。进一步地,在用户需要分析各渠道在各季度下的销售额之和的情况下,可以在数据维度选择区中选取渠道拖拽至行维度配置区,选取季度拖拽至列维度配置区,选取销售额之和拖拽至度量配置区,点击前端页面中的应用控件,便可以完成待分析数据的数据源、行维度、列维度和度量的配置。28.前端页面在应用控件被触发的情况下,将会将用户配置的待分析数据的数据源、行维度、列维度和度量发送至后端服务器,这样后端服务器便可以获取到待分析数据的数据源、行维度、列维度和度量。29.s1200,基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据。30.在一种可能的实现方式中,数据库查询语句可以是sql语句,也就是说后端服务器在获取到待分析数据的数据源、行维度、列维度和度量时,将基于待分析数据的数据源、行维度、列维度和度量生成sql语句,以通过sql语句从数据库中加载待分析数据。31.在一种可能的实现方式中,后端服务器在基于数据源、行维度、列维度和度量生成sql语句时,可以包括以下步骤:第一,获取预设的sql语句拼接模板,其中,sql语句拼接模板中包括多个查询参数。第二,基于数据源、行维度、列维度和度量生成各个查询参数,并将查询参数填充至sql语句拼接模板中,得到sql语句。32.在一种可能的实现方式中,预设的sql语句拼接模板采用双层结构,该双层结构的sql语句拼接模板可以如下所示:select[sqldimensionouter],[sqlmeasureouter]from(ꢀꢀselect[sqldimensioninner],[sqlmeasureinner]ꢀꢀfrom[subjecttable]aꢀꢀleftjoin[sqljoininner]ꢀꢀwhere[where]ꢀꢀgroupby[sqldimensiongroup])aaleftjoin[sqljoinouter]其中,该sql语句拼接模板中的查询参数包括:外层sql维度展示sqldimensionouter,外层sql度量展示sqlmeasureouter,内层sql维度展示sqldimensioninner,内层sql度量展示sqlmeasureinner,主题表subjecttable,内层sql关联条件sqljoininner,主题表过滤条件where,sql聚合字段sqldimensiongroup以及外层sql关联条件sqljoinouter。[0033]在获取到sql语句拼接模板后,后端服务器将基于前端页面中配置的待分析数据的数据源、行维度、列维度和度量生成以上查询参数。[0034]具体地,后端服务器在获取到数据源、行维度、列维度和度量后,分别查询数据源对应的主题配置表、行维度对应的维度配置表,列维度对应的维度配置表以及度量对应的度量配置表。读取主题配置表中的主题表和主题过滤条件,分别生成主题表subjecttable和主题表过滤条件where。读取维度配置表中维度表名,维度表中的键,维度表中的值,维度的名称可以拼接生成外层sql维度展示sqldimensionouter,内层sql维度展示sqldimensioninner,sql聚合字段sqldimensiongroup。另外,通过维度配置表中的是否先关联后聚合字段,可以配置内层sql关联条件sqljoininner,以及外层sql关联条件sqljoinouter,如果是先关联后聚合那么维度的关联条件会出现在内层sql关联条件sqljoininner,否则会出现在外层sql关联条件sqljoinouter。读取度量配置表中的度量名和度量的计算函数,来拼接外层sql度量展示sqlmeasureouter,内层sql度量展示sqlmeasureinner。[0035]在生成sql语句拼接模板中所有的查询参数后,将查询参数填充至sql语句拼接模板中,即可得到sql语句。这样,后端服务器便可以利用生成的sql语句从数据库中加载出待分析数据。[0036]下面以行维度为渠道,列维度为月份,度量为销售额之和为例,对整个sql语句的生成过程进行进一步说明。由于渠道维度设置了先关联后聚合字段为是,而月份维度设置了先关联和聚合维度为否,所以渠道维度出现在外层,月份维度出现在内层。整个sql的伪代码如下:selectisnull(cast(aa.《渠道维度的值字段》asvarchar(100)),'其他')《渠道维度的标签》,ꢀꢀꢀꢀꢀꢀꢀcasewhenaa.《时间维度的主题字段》isnullthen'其他'ꢀꢀꢀꢀꢀꢀꢀwhen《时间维度的名称》.《时间维度的值字段》isnullthen'code_' cast(aa.《时间维度的键字段》asvarchar(100))ꢀꢀꢀꢀꢀꢀꢀelsecast(《时间维度的名称》.《时间维度的值字段》asvarchar(100))end《时间维度的标签》,ꢀꢀꢀꢀꢀꢀꢀaa.《销售额度量的名称》from(ꢀꢀꢀꢀꢀꢀꢀꢀselecta.《时间维度的主题字段》,《渠道维度的名称》.《渠道维度的值字段》,ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ《销售额度量的函数》/1.0《销售额度量的名称》ꢀꢀꢀꢀꢀꢀꢀꢀfrom《主题表名》aꢀꢀꢀꢀꢀꢀꢀꢀleftjoin《渠道维度的表名》《渠道维度的名称》ona.《渠道维度的主题字段》=《渠道维度的名称》.《渠道维度的键字段》ꢀꢀꢀꢀꢀꢀꢀꢀwhere《主题表筛选条件》ꢀꢀꢀꢀꢀꢀꢀꢀgroupbya.《时间维度的主题字段》,《渠道维度的名称》.《渠道维度的值字段》)aaleftjoin《时间维度的表名》《时间维度的名称》onaa.《时间维度的主题字段》=《时间维度的名称》.《时间维度的键字段》生成的详细sql如下:selectisnull(cast(aa.medianameasvarchar(100)),'其他')渠道,ꢀꢀꢀꢀꢀꢀꢀcasewhenaa.monthidisnullthen'其他'ꢀꢀꢀꢀꢀꢀꢀwhendim_month.monthnameisnullthen'code_' cast(aa.monthidasvarchar(100))ꢀꢀꢀꢀꢀꢀꢀelsecast(dim_month.monthnameasvarchar(100))end月份,ꢀꢀꢀꢀꢀꢀꢀaa.销售额from(ꢀꢀꢀꢀꢀꢀꢀꢀselecta.monthid,table_dim_media.medianame,ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀsum(itemsalesvalue)/1.0销售额ꢀꢀꢀꢀꢀꢀꢀꢀfromjahwa_data_subjectaꢀꢀꢀꢀꢀꢀꢀꢀleftjointable_mediadim_mediaona.mediaid=dim_media.channelidꢀꢀꢀꢀꢀꢀꢀꢀwhere1=1anda.monthid》=202001anda.monthid《=202206ꢀꢀꢀꢀꢀꢀꢀꢀgroupbya.monthid,dim_media.medianame)aaleftjointable_monthdim_monthonaa.monthid=dim_month.monthids1300,将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。[0037]在待分析数据中,配置的列维度也是以行维度的形式进行展示的,因此,在获取到待分析数据之后,需要将列维度由行维度展示的形式转为列维度展示的形式,以得到最终的交叉分析结果。[0038]表1渠道子渠道季度total天m天m超市2020q1#天m天m超市2020q2#天m天m超市2020q3#天m天m超市2020q4#天m天m超市2021q1#天m天m超市2021q2#天m天m超市2021q3#天m天m超市2021q4#天m天m国际2020q1#天m天m国际2020q2#天m天m国际2020q3#天m天m国际2020q4#天m天m国际2021q1#天m天m国际2021q2#天m天m国际2021q3#天m天m国际2021q4#举例来说,在数据源为面部护肤,行维度为渠道和子渠道,列维度为季度,度量为销售额之和的情况下,基于生成的sql语句从数据库中加载出的待分析数据的节选数据如表1所示。[0039]从表1中可以看出,季度作为列维度也是以行维度的形式进行展示的,因此,需要将待分析数据中的季度由行维度的展示形式转换成列维度的展示形式,以得到对应的交叉分析结果,其中,交叉分析结果节选数据可以如表2所示。[0040]表2此处需要说明的是,本公开中所有的#均指代行维度和列维度关于度量的交叉分析结果值。[0041]在本公开中,在对大数据量进行交叉分析时,先获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;然后,基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据;最后,将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。本公开在面对大数据量的多维交叉分析时,并不需要将大数据量的数据源全部加载至内存中,仅需要通过生成的数据库查询语句将待分析的数据加载至内存即可实现数据的多维交叉分析,这样就避免了受内存大小限制不能支持大数据量数据的多维交叉分析的问题。[0042]在一种可能的实现方式中,前端页面中还可以包括如图2中所示的展示配置区(位于左侧区域顶端)和数据筛选配置区(位于展示配置区与数据展示区之间)。[0043]该展示配置区中包括图形类型配置区、度量展示配置区、汇总方式配置区、展示数量配置(图中未示出)。其中,该图像类型配置区可以选择的图行类型包括可以包括表格、柱形图、柱形堆积图、条形图、条形堆积图、折线图、散点图、面积图、扇形图、环形图中的至少一种。该度量展示配置区可以选择的度量展示方式可以包括数据值、总计百分比,行百分比,列百分比中的至少一种。其中,总计百分比为度量值占所有度量值之和的百分比,行百分比为度量值占行度量值之和的百分比,列百分比为度量占列度量值之和的百分比。该汇总方式配置区可以选择的汇总方式可以包括行分组汇总、列分组汇总、列汇总、行汇总和总计中的至少一种。该行分组汇总为对组内的数据进行行汇总,该列分组汇总为对组内的数据进行列汇总。该展示数量配置区可以选择的展示数据配置可以包括指定数量显示配置、展开折叠显示配置和分页显示配置中的至少一种。[0044]该数据筛选配置区包括筛选条件配置区、搜索条件配置区(图中未示出)。其中,该筛选条件配置区可以配置的筛选条件可以包括指定维度的筛选条件和不指定维度的筛选条件中的任一种,以满足用户对不同筛选精度的需求。该指定维度的筛选条件适用于对指定维度的数据进行筛选,不指定维度的筛选条件适用于对所有维度下的数据进行筛选。在一种可能的实现方式中,指定维度的筛选条件又可以包括指定维度的精确搜索和指定维度的模糊搜索中的任一种。[0045]在如图2所示的前端页面中,用户在配置待分析数据的数据源、行维度、列维度、度量的同时,还可以实现对图行类型、度量展示方式、汇总方式、筛选条件、搜索条件以及展示数量配置等配置信息中的至少一种配置信息的配置,这样在前端页面中的应用控件被触发的情况下,就可以将待分析数据的数据源、行维度、列维度和度量,以及图行类型、度量展示方式、汇总方式、筛选条件、搜索条件以及展示数量配置中至少一种配置信息发送至后端服务器,以便后端服务器可以获取到前端页面中配置的各种配置信息。[0046]在后端服务器获取到图形类型的情况下,在得到交叉分析结果之后,将按照图形类型调整交叉分析结果的可视化效果。[0047]在后端服务器获取到度量展示方式的情况下,在得到交叉分析结果之后,将按照度量展示方式调整交叉分析结果中的度量展示。[0048]在后端服务器获取到汇总方式的情况下,在得到交叉分析结果之后,将计算出汇总方式对应的汇总数据,并将计算出的汇总数据添加至交叉分析结果中。例如,在汇总方式选择了行分组汇总、列分组汇总、行汇总、列汇总和总计5种汇总方式的情况下,后端服务器分别计算出5种汇总方式对应的汇总数据,并将5种汇总方式对应的汇总数据添加至交叉分析结果中,生成的汇总数据的数量为(行维度数量 1)*(列维度数量 1)-1。如果维度中只存在累加指标,那么通过汇总主数据就可以得到所有的汇总数据;否则就需要生成(行维度数量 1)*(列维度数量 1)-1条sql语句从数据库中追加抽取数据。添加了5种汇总方式的交叉分析结果可以如表3所示。[0049]表3在后端服务器获取到筛选条件的情况下,在得到交叉分析结果之后,由交叉分析结果中筛选出满足筛选条件的交叉分析结果。[0050]举例来说,后端服务器接收到的行维度为渠道和子渠道、列维度为季度、度量为销售额之和。[0051]在接收到的筛选条件为“渠道=天m 季度=2020q2”(即指定维度的精确筛选条件)的情况下,后端服务器的得到交叉分析结果之后,将在交叉分析结果中筛选出天m渠道下各子渠道在2020q2季度的销售额之和,作为满足指定维度的精确筛选条件的交叉分析结果。实现方式为指定维度字符串等于条件的“且”逻辑运算。[0052]在接收到的筛选条件为“渠道问号京 季度=2020q2”(即指定维度的模糊筛选条件)的情况下,后端服务器在得到交叉分析结果之后,将从交叉分析结果中筛选出包含京字的渠道下各子渠道在2020q2季度的销售额之和,作为满足指定维度的模糊筛选条件的交叉分析结果。实现方式为指定维度字符串正则表达式匹配条件的“且”逻辑运算。[0053]在接收到的筛选条件为“天m,京”(即不指定维度的筛选条件)的情况下,后端服务器在得到交叉分析结果之后,将从交叉分析结果中筛选出包括天m或京字的渠道或子渠道在各季度的销售额之和,作为最终的交叉分析结果。实现方式为所有维度字符串正则表达式匹配条件的“或”逻辑运算。[0054]搜索条件参照筛选条件在此不在赘述。[0055]在后端服务器获取到展示数量配置的情况下,在得到交叉分析结果之后,后端服务器将按照展示数量配置调整交叉分析结果的可视化效果。举例来说,在后端获取到的展示数量配置为显示前5条(即指定数量显示配置)的情况下,后端服务器将从得到的交叉分析结果中筛选出前5条推送显示至如图2所示的前端页面的数据展示区(位于前端页面的左下端即图2中表格所在的区域)。在后端获取到的展示数量配置为分页显示(即分页显示配置)的情况下,后端服务器将按照前端页面展示区中能展示的最大数据条数从得到的交叉分析结果中进行数据筛选,并将筛选出的结果推送显示至如图2所示的前端页面的数据展示区,这样可以防止数据过载。在后端获取到的展示数量配置展开折叠显示配置的情况下,后端服务器将在得到的交叉分析结果中添加展开折叠控件,并将带有展开折叠控件的交叉分析结果推送显示至如图2所示的前端页面的数据展示区。这样,用户便可以根据需求点击展开折叠控件,以实现对交叉分析结果中的数据进行展开和折叠的操作。[0056]需要说明的是,对于配置的每个维度,在后端服务器中均配置有对应的维表,在维表中可以配置该维度可以支持的排序方式。这样,后端服务器在生成交叉分析结果之后,便可以根据选定排序维度对应的排序方式对交叉分析结果进行排序,以得到满足选定排序维度对应的排序方式的交叉分析结果。[0057]在一种可能的实现方式中,维表中可以支持的排序方式可以包括按照排序字段排序、按照字母表排序和按照度量值排序中的至少一种,其中,按照排序字段排序即按照字段的预设顺序进行排序。[0058]此处需要说明的是,对于一些特殊维度通常不能按照度量值或者按照字母排序进行排序,因此,对于这些特殊的维度需要在数据库中预先配置该维度下各维度值的排序信息并进行存储,这样,在选定的排序维度为特殊维度的情况下,后端服务器将通过sql语句从数据库中加载该维度下各维度值的排序信息,然后根据该维度下各维度值的排序信息对该维度进行排序。[0059]举例来说,对于价格区间这个维度的维度值为数值区间,例如,[0-20),[20,40),[40,60),[60,80)等,该数值区间是无法按照度量值或者字母排序进行排序的,因此,需要先配置该价格区间维度下各价格区间值的排序值并存储至数据中,这样,在选定的排序维度为价格区间的情况下,后端服务器将通过sql语句从数据库中加载该价格区间维度下各价格区间值的排序值,并根据各价格区间值的排序值对价格区间维度进行排序。[0060]在一种可能的实现方式中,后端服务器在得到待分析数据、添加汇总数据的交叉分析结果、满足筛选条件的交叉分析结果、满足排序方式的交叉分析结果之后,将对得到的各结果进行分级缓存,这样,便可以基于分级缓存结果交叉分析结果执行搜索条件,以提高数据的查询效率。[0061]下面结合图3,对本公开的数据多维度交叉分析方法进行进一步的说明。[0062]后端服务器在执行数据多维交叉分析前,用户需要先根据需求在前端页面中完成数据源、进行交叉分析的列维度、行维度、度量、汇总方式、筛选条件、排序方式、搜索条件以及展示数据量等配置信息的配置,前端页面在应用控件被触控的情况下,将以上配置信息通过http协议发送至后端服务器。[0063]后端服务器在接收到以上配置信息后,将执行以下操作步骤:步骤s0,config配置。具体地,基于接收到的数据源、列维度、行维度、度量将对应的主题配置信息、维度配置信息、度量配置信息、主题与维度映射关系以及主题与度量的映射关系等配置信息加载至后端服务器,在拼接sql,获取排序信息,滞后维度数据等过程中直接读取配置信息,这样在后续运算中就可以不用从数据库中读取对应的配置信息,从而提高运算效率。其中,配置的列维度或行维度中包括滞后维。[0064]此处需要说明的是,对于滞后维在运算过程中通过滞后为的id进行表示,在最后生成交叉分析结果时,再将滞后维的id替换成滞后维的维度值。[0065]步骤s1,init初始化。具体地,根据接收到的数据源、列维度、行维度、度量生成sql语句。生成sql语句的方法参照上文,在此不再赘述。[0066]步骤s2,lazy加载滞后维。具体地,提前将滞后维的id与维度值的映射关系存储至一个字典中。[0067]步骤s3,load加载数据。具体地,根据初始化生成的sql语句,从数据库中加载数据待分析数据,如果待分析数据为空,则增加一条虚拟空数据。在加载到待分析数据后,先判断该待分析数据是否已经缓存至预设的一级缓存,在未缓存至一级缓存时,先执行将待分析数据存入一级缓存的步骤,在执行步骤s4;在已经存入至一级缓存时,直接执行步骤s4。[0068]步骤s4,agg汇总数据。具体地,根据前端配置的汇总方式,对待分析数据进行汇总,得到对应的汇总数据,并将对应的汇总数据添加至待分析数据中。在得到汇总后的待分析数据后,先判断汇总后的待分析数据是否已经缓存至预设的二级缓存中,在为缓存至二级缓存的情况下,先将汇总后的待分析数据缓存至二级缓存中,在执行步骤s5;在已经缓存至二级缓存的情况下,直接执行步骤s5。[0069]步骤s5,filter筛选数据。具体地,根据前端页面配置的筛选条件生成对应的筛选字典,然后筛选字典由汇总后的待分析数据中筛选出满足筛选条件的待分析数据。其中,前端配置的筛选条件可以是指定维度的精确筛选条件、指定维度的模糊筛选条件以及不指定维度的筛选条件中任一种。在得到满足筛选条件的待分析数据后,判断满足筛选条件的待分析数据是否已经缓存至预设的三级缓存中,在未存入三级缓存的情况下,先将满足筛选条件的待分析数据存入三级缓存中,在执行步骤s6;在已经存入三级缓存的情况下,直接执行步骤s6。[0070]此处需要说明的是,在进行数据筛选时,筛选的是维度的名称,因此,在维度中涉及滞后维时,需要先根据字典将滞后维的id替换为滞后为的名称,然后在进行数据的筛选。[0071]步骤s6,pivot数据变换。具体地,将满足筛选条件的待分析数据中展示在行上的列维度数据转换至列上进行显示。[0072]步骤s7,sort排序数据。具体地,根据前端页面配置的排序方式生成对应的排序字典,根据排序字典对步骤s6输出的结果进行排序,得到满足排序方式的待分析数据。判断满足排序方式的待分析数据是否存入预设的四级缓存,在未存入四级缓存的情况下,先将满足排序方式的待分析数据存入四级缓存,再执行步骤s8;在已存入四级缓存的情况下,直接执行步骤s8。[0073]步骤s8,index索引数据。具体地,分别生成满足排序方式的待分析数据中行维度数据和列维度数据的索引数据,并根据生成的索引数据生成交叉分析结果。[0074]步骤s9,search搜索数据。具体地,根据前端配置的搜索条件在上述四级缓存中查找对应的数据,以提高数据的查询效率。[0075]步骤s10,前n条数据。具体地,根据前端配置的展示数量配置,调整交叉分析结果中数据数量的展示效果,并将最终调整后的交叉分析结果推送显示至前端页面的数据展示区中。其中,展示数据配置可以是指定数量显示(top前多条)、展开折叠显示(expand展开)和分页显示(page分页)中的任一种。[0076]步骤s11,导出数据。具体地,在前端页面中配置了导出方式的情况下,可以按照前端页面配置的导出方式导出最终的交叉分析结果。其中,导出方式可以是html、json、excel、csv四种导出方式中的至少一种。[0077]另外,在日志模块在对象初始化的开始生成日志对象,记录执行过程和执行时间,可以用来优化分析过程。[0078]《装置实施例》图4示出根据本公开一实施例数据多维度交叉分析装置的示意性框图。如图4所示,数据多维度交叉分析装置100包括:数据配置模块110,用于获取待分析数据的数据源以及进行交叉分析的行维度、列维度和度量;数据加载模块120,用于基于数据源、行维度、列维度和度量生成数据库查询语句,并基于数据库查询语句从数据库中加载待分析数据;数据展示模块130,用于将待分析数据中的列维度由行转换为列,得到行维度和列维度关于度量的交叉分析结果。[0079]在一种可能的实现方式中,数据库查询语句为sql语句;数据加载模块120包括sql语句生成子模块,用于基于数据源、行维度、列维度和度量生成sql语句;sql语句生成子模块包括模板获取单元和语句拼接单元;模板获取单元,用于获取预设的sql语句拼接模板,其中,sql语句拼接模板中包括查询参数;语句拼接单元,用于基于数据源、行维度、列维度和度量生成查询参数,并将查询参数填充至sql语句拼接模板中,得到sql语句。[0080]在一种可能的实现方式中,数据配置模块110还用于获取汇总方式、筛选条件、排序方式以及展示数量配置中至少一种配置信息。[0081]在一种可能的实现方式中,汇总方式包括行分组汇总、列分组汇总、列汇总、行汇总和总计中的至少一种,其中,行分组汇总为对组内的数据进行行汇总,列分组汇总为对组内的数据进行列汇总;数据多维度交叉分析装置100,还包括数据汇总模块,用于在获取到汇总方式的情况下,在得到交叉分析结果之后,还计算汇总方式的汇总数据,并将汇总数据添加至交叉分析结果中。[0082]在一种可能的实现方式中,筛选条件包括指定维度的筛选条件和不指定维度的筛选条件中的至少一种;数据多维度交叉分析装置100,还包括数据筛选模块,用于在获取到筛选条件的情况下,在得到交叉分析结果之后,由交叉分析结果中筛选出满足筛选条件的交叉分析结果。[0083]在一种可能的实现方式中,排序方式包括按照排序字段排序、按照字母表排序和按照度量值排序中的至少一种,其中,按照排序字段排序即按照字段的预设顺序进行排序;数据多维度交叉分析装置100,还包括数据排序模块,用于在获取到排序方式的情况下,在得到交叉分析结果之后,按照排序方式对交叉分析结果进行排序,得到满足排序方式的交叉分析结果。[0084]在一种可能的实现方式中,展示数量配置包括指定数量显示配置、展开折叠显示配置和分页显示配置中的至少一种;数据多维度交叉分析装置100,还包括数据展示数量调整模块,用于在获取到展示数量配置的情况下,在得到交叉分析结果之后,根据展示数量配置对交叉分析结果进行调整。[0085]在一种可能的实现方式中,数据多维度交叉分析装置100,还包括数据缓存模块,用于在获取到汇总方式、筛选条件、排序方式的情况下,对待分析数据、添加汇总数据的交叉分析结果、满足筛选条件的交叉分析结果以及满足排序方式的交叉分析结果进行分级缓存。[0086]在一种可能的实现方式中,数据多维度交叉分析装置100,还包括数据搜索模块,用于基于分级缓存结果对交叉分析结果进行筛选。[0087]以上已经描述了本公开的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本
技术领域:
:的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的技术改进,或者使本
技术领域:
:的其它普通技术人员能理解本文披露的各实施例。当前第1页12当前第1页12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。