1.本发明涉及一种基于多智能体深度强化学习的水厂取水泵站节能调度方法,属于水厂取水泵站调度与人工智能交叉领域。
背景技术:
2.水是经济社会可持续发展的基础,但由于工艺、设备或者水处理系统的落后,净水厂综合电耗较大,其中取水泵站的电耗占主要部分。传统泵站调度主要依靠工程经验调整泵组搭配、调节变频泵频率。这种调节是定性调节,人力成本高,节能水平不稳定甚至增加能耗。此外,泵组的频繁启闭会对管道造成很大冲击,压力的急剧变化容易造成水锤现象。因此在保障供水安全、满足供水需求的条件下降低取水泵站的能耗,对于降低水厂运行成本、节约城市电耗、减少二氧化碳排放具有重要意义。
3.针对取水泵站的节能优化调度研究,现有研究提出了若干方法,如非线性规划、动态规划、遗传算法等。尽管上述方法有一定优势,但这些方法需要知晓取水泵站的明确调度模型(如总能耗与取水泵站状态和调度决策之间的明确关系表达式)。由于取水泵站性能取决于许多因素(如内部参数(扬程,轴功率,电机转速,电机频率,电机效率)、外部环境(如取水量,供水量)、以及水泵中的液体因有限叶片数、摩擦、冲击和泄露造成损耗等),建立既精确且易于控制的取水泵站调度模型非常困难。此外,考虑上述方法的研究工作未考虑到频繁切换泵组对水泵的损耗。
4.随着物联网技术和人工智能技术的发展,水厂取水泵站的大量历史运行数据容易获得并可以被有效利用。例如:一些工作提出了基于数据驱动的水厂取水泵站调度方法,如结合粒子群算法与支持向量回归算法的取水泵站调度方法。但该方法需要对未来24小时的供水量等进行预测并进行滚动生成泵组调度推荐表,因而容易引入误差和导致较大的计算任务量。此外,部分工作提出了基于强化学习和深度强化学习的水配送系统的控制方法,采用的算法包括:q-learning、决斗深度q网络、具有知识辅助的近端策略梯度。虽然上述基于强化学习和深度强化学习的水泵站调度方法无需知晓取水泵站的明确调度模型,但它们并未针对取水泵站的节能问题开展研究,而且采用单个智能体控制水泵的方式。当联合考虑定频泵和变频泵的节能调度时,直接采用单个智能体进行取水泵控制将导致智能体动作空间急剧增加,进而导致学习效率低下并无法实现在维持取水泵安全工作和满足供水需求的前提下有效节省能耗。
技术实现要素:
5.针对现有技术存在的不足,本发明提供了基于多智能体深度强化学习的水厂取水泵站节能调度方法,其目的在于维护系统运行安全的条件下降低取水泵站能源消耗。该发明方法采用了将变频泵的连续动作空间进行低维度离散化,并用多个智能体对取水泵组进行控制。为了实现多智能体的高效训练,利用历史运行数据构建取水泵站调度环境模型(该模型为黑盒模型,无需知晓现有研究中的白盒模型),并采用多智能体行动者-注意力-评论
家强化学习算法作为训练算法,最终获得具有高可扩展性和高效性的取水泵站节能调度方法。该发明方法无需预测任何不确定性参数、无需知晓取水泵站的明确调度模型、具有计算复杂度低和节能效果明显等优势。
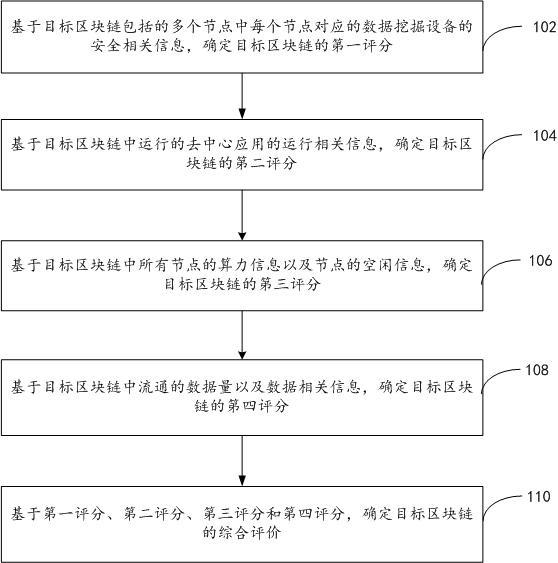
6.本发明公开了一种基于多智能体深度强化学习的取水泵站节能调度方法,其特征是,包括如下步骤:(1)在维持蓄水池液位、总管压强差、水泵切换次数在安全范围的前提下,将取水泵站总能耗最小化问题建模为马尔可夫博弈,并设计马尔可夫博弈相应的环境状态、行为、以及奖励函数,构建关于取水泵站系统的多智能体。
7.(2)利用历史运行数据和长短期记忆网络构建取水泵站调度环境模型。
8.(3)基于取水泵站调度环境模型和多智能体行动者-注意力-评论家强化学习算法对多智能体进行深度强化学习训练。
9.(4)将训练得到的多智能体策略部署到实际取水泵站系统中。
10.进一步地,所述取水泵站总能耗最小化问题的表达式如下:式中,为时隙(,表示优化时隙总数)取水泵站的总能源消耗;为期望算子,其操作主要针对不确定性参数(如供水量);为时隙取水泵站的工作频率(针对变频泵)或状态(针对定频泵);为时隙蓄水池液面高度,和为蓄水池安全范围的最低和最高液位;为时隙取水泵站总管压强,为时隙取水泵站总管压强,为安全范围内的最高总管压强差,为表示截止到时隙取水泵站在一天内的切换次数,为取水泵站在一天内安全范围内的最高切换次数。
11.进一步地,所述马尔可夫博弈中环境状态的表达式如下:式中,,取1,2,
…
,,表示需要控制的水泵数目,同时也为马尔可夫博弈中智能体的总个数(每个智能体负责控制1个取水
泵)。其中:为多智能体在时隙的环境状态,表示第个定频泵智能体或变频泵智能体的本地观测状态,为时隙的当前绝对时间在一天内的相对时间序号,为时隙蓄水池液面高度,为时隙取水泵站总管压强,为时隙蓄水池借水量(即从其他水厂调入蓄水池的水量),为时隙蓄水池供水量(即从蓄水池调出的水量),为截止到时隙取水泵站在一天内的切换次数,为智能体所控制的水泵在时隙开关状态。
12.进一步地,所述马尔可夫博弈中行为的表达式如下:的表达式如下:式中,表示需要控制的水泵数目,为整数,取1,2,
…
,。其中,当时,为小于的整数,智能体为定频泵,为定频泵在时隙的开关状态,当时,定频泵智能体关闭,定频泵智能体开启。当时,智能体为变频泵,,为变频泵在时隙的频率的增减情况,表示频率泵关闭,和分别表示变频泵频率减少和增大,,表示变频泵频率不变。
13.进一步地,所述马尔可夫博弈中奖励函数表达式如下:式中,为时隙末用于控制每个取水泵的智能体所接收到的奖励,其中:
为时隙与取水泵站能耗相关的惩罚成本,为时隙与蓄水池液位违背安全范围相关的惩罚成本,为时隙与违背取水泵站总管压强差安全范围相关的惩罚成本,为时隙与取水泵站组合切换代价相关的惩罚成本,为时隙与取水泵站组合切换次数违背安全范围导致的惩罚。为蓄水池液位违背安全范围导致的惩罚相对于能耗相关的惩罚成本的重要性系数,为总管压强差违背安全范围导致的惩罚相对于能耗相关的惩罚成本的重要性系数,为切换取水泵站导致的惩罚相对于能耗相关的惩罚成本的重要性系数,为取水泵站切换次数违背安全范围导致的惩罚相对于能耗相关的惩罚成本的重要性系数。
14.进一步地,所述取水泵站调度环境模型构建如下:式中,为时隙蓄水池液面高度,为时隙取水泵站总管压强, 为时隙取水泵站的能源消耗,为时隙蓄水池借水量,为时隙蓄水池供水量,为利用真实历史运行数据训练得到的能源消耗预测长短期记忆(lstm)网络,为利用真实历史运行数据训练得到的液位预测长短期记忆(lstm)网络,为利用真实历史运行数据训练得到的总管压强预测长短期记忆(lstm)网络。
15.进一步地,所述关于取水泵站系统的多智能体包括:智能体数量与水泵数量相等,每个水泵由1个智能体进行控制。每个智能体内部包含1个行动者网络、1个目标行动者网络、1个评论家网络、1个目标评论家网络、1个注意力网络。每个智能体的行动者网络和目标行动者网络的结构相同,每个智能体的评论者网络和目标评论者网络的结构相同。
16.具体而言,智能体(即与水泵对应的智能体)的行动者网络为多层深度神经网络,行动者网络输入为,行动者网络输出为,深度神经网络隐藏层所采用的激活函数为带泄露整流函数,深度神经网络输出层采用的激活函数为归一化指数函数。每个智能体内部的评论家网络包含3个感知机模块,分别为第一感知机模块、第二感知机模块和
第三感知机模块。其中:第一感知机模块的输入是本地观测状态,经过第一感知机模块后输出得到观测状态编码值;第二感知机模块的输入是本地观测状态和行为,输出是观测状态和行为的联合编码值;所有智能体的评论家网络中第二感知机模块输出作为注意力网络的输入;注意力网络返回其他智能体对当前智能体的贡献,所述贡献和第一感知机模块的输出作为第三感知机模块的输入,第三感知机模块的输出是当前所有智能体的状态行为值函数,表示所有智能体评论家网络的共享权重参数,表示智能体的多层感知机。
17.注意力网络内部具有个结构相同的子网络,对应个智能体;以子网络为例,其输入包含所有智能体评论家网络中第二感知机模块的输出,所述子网络输出为所有其他智能体对智能体的贡献值,所述贡献值是其他所有智能体的评论家网络中第二感知机模块的输出值经过线性变换送入到单层感知机后所得输出的加权和,即:,其中:加权系数反映了智能体的评论家网络中第二感知机模块输出值和其他智能体的评论家网络中第二感知机模块输出值之间的相似性,是一个共享矩阵,是leaky relu激活函数。
18.,和是共享矩阵,并分别对和做线性变换,。
19.进一步地,多智能体的深度强化学习训练过程包含如下步骤:(1)根据取水泵站的历史运行数据,获得当前环境状态。
20.(2)每个智能体的行动者网络根据所述当前环境状态,输出每个取水泵的当前行为。
21.(3)根据所述当前环境状态和当前行为,利用取水泵站调度环境模型得到该状态与行为下的能耗,下一时隙液位和下一时隙总管压强,并利用这些信息重新构建下一时隙的环境状态和奖励。
22.(4)将当前环境状态、当前行为、下一时隙环境状态、下一时隙奖励发送至经验池
中。
23.(5)如果需要对智能体内部深度神经网络的权重参数进行更新,则从经验池中提取小批量训练样本,利用多智能体行动者-注意力-评论家强化学习算法先对评论家网络进行权重更新,然后对行动者网络进行更新。
24.具体而言,评论家网络参数更新根据如下联合损失函数最小化进行,即:其中:为联合损失函数,为经验池,用于存储;代表期望运算,表示折扣系数;表示所有目标行动者网络的参数矢量,即:,其中:表示智能体的目标行动者网络参数;和表示所有智能体评论家网络和目标评论家网络的共享权重参数,是平衡最大化熵和最大化奖励之间的温度参数。代表选取的动作服从目标行动者网络策略时的期望值,代表目标行动者网络的策略。
25.行动者网络更新采用梯度上升法进行,具体的梯度更新公式为:式中:表示智能体行动者网络的策略函数(即从观测状态到的概率分布映射),为除了以外其他智能体行为的平均价值。代表行动者网络的梯度,代表选取的动作服从行动者网络策略时的期望值,表示对对数函数求偏导。
26.(6)智能体深度神经网络权重参数更新完毕后判断训练过程是否结束,如果未结束,则流程跳转至步骤(1),否则,训练过程终止,并将训练得到的各个行动者网络将作为对应智能体的最优策略(即从本地观测状态到水泵控制动作的函数映射)用于实际取水泵站
的控制部署。
27.有益效果:一种基于多智能体深度强化学习的取水泵站节能调度方法,与现有技术相比,本发明所达到的有益效果如下:(1)与基于非线性规划、动态规划等调度方法相比,本发明方法无需知晓取水泵站的明确动态性模型。不同于基于预测的调度方法,本发明方法得到的多智能体策略仅仅根据当前时隙的观测状态输出取水泵站的控制决策,故无需预测任何不确定性参数。此外,由于多智能体策略的输出过程仅仅涉及多层深度神经网络的前向传导,执行时间为毫秒级,故具有极低的计算复杂度。因此,本发明方法具有强通用性。
28.(2)与基于强化学习的单智能体水泵调度方法相比,本发明方法可利用多智能体间的注意力机制实现多个取水泵之间的高效协调调度;可在维持蓄水池液位、总管压强差以及水泵切换次数在安全范围的前提下显著降低能耗。故本发明方法具有高效性。
附图说明
29.图1是本发明提供的取水泵站调度控制方法流程图。
30.图2是本发明方法实施例的训练曲线收敛图。
31.图3是本发明方法实施例与其他方案的平均能源消耗对比图。
32.图4是本发明方法实施例与其他方案的平均液位越限对比图。
33.图5是本发明方法实施例与其他方案的平均总管压强越限对比图。
34.图6是本发明方法实施例与其他方案的平均水泵切换次数对比图。
具体实施方式
35.为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
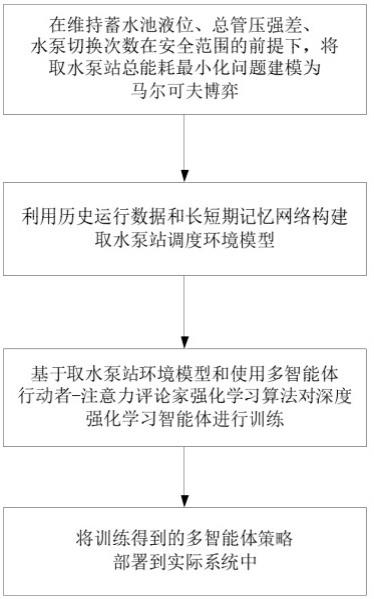
36.如图1所示,本发明提供的基于多智能体深度强化学习的取水泵站节能调度控制方法的设计流程图,包括如下步骤:步骤1:在维持蓄水池液位、总管压强差、水泵切换次数在安全范围的前提下,将取水泵站总能耗最小化问题转化为马尔可夫博弈,并设计相应的环境状态、行为、以及奖励函数。
37.步骤2:利用历史运行数据和长短期记忆网络构建取水泵站调度环境模型。
38.步骤3:基于调度环境模型和多智能体行动者-注意力-评论家强化学习算法对深度强化学习智能体进行训练。
39.步骤4:将训练得到的智能体策略部署到实际系统中。
40.在上述步骤1中,由于需要维持蓄水池液位,总管压强差,水泵切换次数再安全范围以内,因而该马尔可夫博弈的行为包括:频率泵的频率决策和定频泵开关决策;需考虑的约束有:与蓄水池液位有关的约束、与总管压强差有关的约束、与水泵切换次数的约束,具体如下:(1)蓄水池液位处于安全范围,即,其中:和分别
表示蓄水池安全液位的上下限。
41.(2)总管压强差小于压强差的上限,即,其中:表示水泵可以接受的最高总管压强差,表示时刻的总管压强,表示t-1时刻的总管压强。
42.(3)水泵切换次数小于安全切换范围,即,其中:表示一天以内可以接受的最高切换次数。
43.在上述步骤1中,马尔可夫博弈可以由一系列状态、行为、状态转移函数、奖励函数定义。马尔可夫博弈中,每个智能体基于当前状态并选择行为进而最大化自身期望回报(即累积折扣奖励的期望值)。马尔可夫博弈的环境状态、行为、奖励函数分别设计如下:(1)环境状态。为多智能体在时隙的环境状态,多智能体的环境状态设计如下:。时隙水泵频率决策相关的智能体的本地观测状态用表示,其中:,分别表示:为时隙的当前绝对时间在一天内的相对时间序号,为时隙蓄水池液面高度,为时隙取水泵站总管压强,为时隙蓄水池借水量,为时隙蓄水池供水量,为截止到时隙的取水泵站在一天内的切换次数情况。为智能体在时隙的水泵开关情况。
44.(2)行为。时隙的行为用表示,表示,。
45.(3)奖励函数。取水泵站第个水泵相关的智能体在时隙的奖励函数用表示,包括5个组成部分:1. 时隙取水泵站能源消耗相关的惩罚;2. 时隙蓄水池液位越线导致的惩罚
,。
46.3. 时隙违背安全总管压强差范围导致的惩罚,。
47.4. 时隙切换水取水泵站合导致的惩罚,表示水泵在时隙时的开关状态,当表示水泵在时隙时关闭,当表示水泵在时隙时开启;表示水泵在时隙时的开关状态,当表示水泵在时隙时关闭,当表示水泵在时隙时开启。
48.5. 时隙取水泵站安全切换范围导致的惩罚。
49.式中:为蓄水池液位违背安全范围导致的惩罚相对于能耗相关的惩罚成本的重要性系数,为总管压强差违背安全范围导致的惩罚相对于能耗相关的惩罚成本的重要性系数,为切换取水泵站导致的惩罚相对于能耗相关的惩罚成本的重要性系数,为取水泵站切换次数违背安全范围导致的惩罚相对于能耗相关的惩罚成本的重要性系数。
50.在上述步骤2中,取水泵站调度系统的目标是在维持蓄水池液位,总管压强差和水泵切换次数在安全范围的前提下,将取水泵站能源消耗最小化。为了建立取水泵站调度环境模型,采用历史数据和长短期记忆(lstm)网络进行构建。具体而言,通过输入取水泵站的状态与动作,lstm网络输出取水泵站调度的能源消耗,液位,以及总管压强。
51.在步骤3中,利用多智能体行动者-注意力-评论家强化学习算法训练出维持蓄水池液位、总管压强差、取水泵站切换次数在安全范围以内的取水泵站调度系统的最优决策。训练深度强化学习智能体的具体步骤如下:(1)根据取水泵站的历史运行数据,获得当前环境状态;(2)每个智能体的行动者网络根据所述当前环境状态,输出取水泵站的当前行为;(3)根据所述历史环境状态和当前行为,利用调度环境模型得到该状态与行为下的能耗,下一时隙液位和下一时隙总管压强,并利用这些信息重新构建下一时隙的环境状态和奖励;(4)将所述当前环境状态、所述当前行为、所述下一时隙环境状态、所述下一时隙
奖励发送至经验池中;(5)如果需要进行智能体内部深度神经网络的权重参数更新,则从经验池中提取小批量训练样本,利用多智能体行动者-注意力-评论家强化学习算法对深度神经网络进行权重更新,更新完毕后判断训练过程是否结束,如果未结束,则流程跳转至步骤(1),否则,训练过程终止。训练结束后得到的行动者网络将作为各个智能体的最优策略(即从本地观测状态到水泵控制动作的函数映射)用于实际部署。
52.本发明实施例与现有技术相比,能够取得以下有益效果:1)本发明提出的方法具有通用性。提出了基于多智能体行动者-注意力-评论家强化学习算法的取水泵站节能调度方法。由于获得的智能体策略仅仅根据当前时隙的观测状态获得每个取水泵的控制决策,故该方法无需知晓任何不确定性系统参数的先验信息或预测不确定性参数(如供水量),也无需知晓取水泵站的明确调度机理模型;2)本发明提出的方法具有高效性。相比现有调度方法,本发明方法可在维持蓄水池液位、总管压强差和水泵切换次数在安全范围下降低能源消耗12.8%。
53.如图2所示,是本发明方法实施例的训练曲线收敛图。从曲线可知,训练奖励总体上呈现增长趋势,逐步趋于稳定。
54.如图3所示,是本发明方法实施例与其他方案的能源消耗对比图。方案一是取水泵站真实调度方案。本发明所用的取水量、供水量和取水泵站参数数据均来自2020年11月1日至2021年4月30日的水厂实际数据。相比方案一,所提方法可节省平均能耗12.8%。
55.如图4所示,是本发明方法实施例与其他方案的平均液位越限对比图。相比方案一,所提方法下的平均液位越限降低66.2%。
56.如图5所示,是本发明方法实施例与其他方案的平均总管压强差对比图。由图可知:所提出的方法比方案一具有更小的总管压强差,所提方法的总管压强差一直处于安全范围以内。
57.如图6所示,是本发明方法实施例与其他方案的平均水泵切换次数对比图。相比方案一,所提出的方法可降低泵切换次数50%。
58.最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。