1.本发明属于人流统计技术领域,本发明涉及一种基于深度学习的电梯人流视觉统计方法,增强了对小目标的检测能力,同时提高了对遮挡目标的检测识别能力。
背景技术:
2.随着城市化的快速发展,安全性问题尤为突出,场所的监控越来越多,高空视角下的视频数据量急剧增加,一些封闭空间的人流检测越来越重要,例如公交车、地铁、电梯等等,如果能够实时地对电梯或公交等的人流进行有效的统计监控,使电梯或公交等运行时能够均衡分配客货流,为智能调度、层间调控、安全预警等提供重要的参考依据。
3.目前电梯或公交等中乘员数量的统计方法主要通过经典图像处理算法或卷积神经网络目标检测算法进行,这两种方法通过电梯或公交等内的成像设备获取电梯轿厢内部的当前图像,然后通过算法处理确定内部的当前人数。经典的图像处理算法拥有较高的运行速度,同时对硬件的要求较低,但是其检测识别的准确性不高、鲁棒性较差;基于卷积神经网络算法的统计方法虽然有较高的准确性,但其硬件成本较高。同时,上述两种方法对小目标、遮挡目标的检测识别能力有限,容易出现漏报、误报的情况,导致统计结果失真,达不到理想的统计效果。
4.申请号2022105434355公开了一种群控电梯交通模式识别的方法,在yolov5的原有模型框架中加入了ca注意力机制来优化模型,在common中写入ca函数,完成ca的模型结构;在yolo中进行对ca模型的修改;改写yolov5s模型的backbone主干网络,将ca加入到主干网络模型中。该优化的模型的小目标的检测能力还有待提高。
技术实现要素:
5.本发明的目的在于提供一种基于深度学习的电梯人流视觉统计方法、系统及存储介质,通过改进神经网络模型,并结合目标跟踪算法,保证了电梯内成员数量统计的准确性,特别是增强了对小目标的检测能力。并且对遮挡目标进行判断,使电梯人流检测的准确性更高。
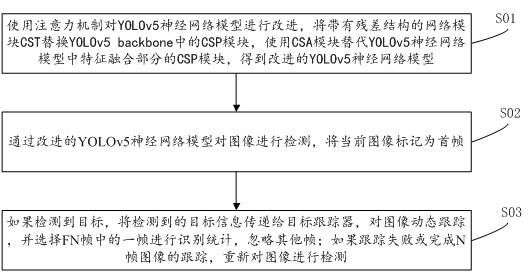
6.实现本发明目的的技术解决方案为:一种基于深度学习的电梯人流视觉统计方法,包括以下步骤:s01:使用注意力机制对yolov5神经网络模型进行改进,将带有残差结构的网络模块cst替换yolov5 backbone中的csp模块,使用csa模块替代yolov5神经网络模型中特征融合部分的csp模块,得到改进的yolo-el神经网络模型;s02:通过改进的yolo-el神经网络模型对图像进行检测,将当前图像标记为首帧;s03:如果检测到目标,将检测到的目标信息传递给目标跟踪器,对图像动态跟踪,并选择fn帧中的一帧进行识别统计,忽略其他帧;如果跟踪失败或完成n帧图像的跟踪,重新对图像进行检测。
7.优选的技术方案中,所述步骤s01中cst模块包括第一卷积层、第二卷积层、第三卷
积层和transformer层,第一卷积层和第二卷积层用于接收上层网络的输出,第一卷积层的输出用作transformer层的输入,第二卷积层作为残差结构,其输出端与transformer层的输出进行拼接,得到的结构输入第三个卷积层中进行处理;所述transformer层中数据首先进入扁平化层,经过处理后由多维转换为1维,然后经归一化层进行归一化处理,随后经过多头注意力层的处理后再次进行归一化运算,最后通过多层感知机进行处理。
8.优选的技术方案中,所述步骤s01中csa模块包括第四卷积层、第五卷积层、第六卷积层、第七卷积层、注意力层和bottleneck层,其中bottleneck层为1
×
1的卷积运算,用于减少网络参数数量;所述第四卷积层、第五卷积层用于接收上层网络的输出,所述第四卷积层的输出用作注意力层的输入,注意力层的输出经过第六卷积层的处理后,其结果输入bottleneck层,经bottleneck层处理后与该第六卷积层的输出进行拼接,拼接结果与第五卷积层的结果继续拼接,所述第五卷积层构成残差结构,得到的结果通过第七卷积层进行处理得到最后的结果。
9.优选的技术方案中,所述步骤s03中跟踪器的建立包括:构建kcf跟踪器,通过使用轮转矩阵生成样本,训练一个判别式分类器,引入循环矩阵,采用快速傅里叶变换对kcf算法进行加速计算;训练kcf跟踪器,找到一个非线性映射函数使映射后的结果在线性空间下是可分的,即找到一个回归函数,给定样本和对应的标签,为目标模板,目标是优化最大平方和误差;使用高斯核函数对跟踪器进行训练。
10.优选的技术方案中,所述训练kcf跟踪器的方法包括以下步骤:由训练样本的非线性变换的线性组合构成: (16)其中,为权重参数,为样本,此时实际为所有样本的加权平均,新样本的预测值为:(17)记称为核函数,得:(18)其中,、,为样本数量,为权重参数构成的向量,中的第t个元素为训练样本和测试样本的核函数值;
使用线性函数的优化方法求解: (19)其中,是所有训练样本的核相关矩阵,,为单位矩阵,为正则项系数,为对应的目标值,为的集合;使用高斯核函数对跟踪器进行训练:记循环矩阵的初始向量为,根据式(19)可得:(20)经傅里叶变换得:(21)化简后得: (22)对同样利用循环矩阵加速,对于高斯核函数,核相关矩阵的初始向量为:(23)其中,为径向基函数,、为样本向量。上式向量化后得: (24)其中,为高斯核函数,为样本向量的傅里叶变换,为样本向量的傅里叶变换的复共轭将式(23)代入(24)后得:
ꢀ
(25)则高斯核函数对应的初始向量为: (26)其中,是初始样本经傅里叶变换后得到的值,是常离散傅里叶矩阵,为经傅里叶变换后的复共轭;kcf算法的检测结果是一个标量,表示某一个样本的回归值: (27)对待检测的图像进行循环化: (28)其中,表示训练样本与候选样本之间的核相关矩阵,为其初始向量,则: (29)傅里叶变换后: (30)化简后得:(31)此时检测结果是一个向量,维度和训练时的一样,其中最大元素对应的偏移量即为检测到的目标的位置。
11.优选的技术方案中,所述步骤s03之后还包括:当跟踪器跟踪失败,判断目标出现重叠,检测近景目标的深度信息,判断被遮挡目
标是否还在电梯内;如果近景目标的深度大于电梯自身的深度,不进行统计,如果近景目标的深度小于电梯自身的深度,对其进行统计。
12.优选的技术方案中,所述检测目标的深度信息的方法包括:计算相机镜头光心到目标的距离:其中,为相机焦距;是乘员头部物理尺度,是电梯轿厢的内部固定物理尺度,为融合后的实际目标物理尺度,为异域像素特征,与表示不同类型特征的数量,和通过成像数据得出;以相机镜头的光心为坐标系原点建立右手三维坐标系,竖直向下为x轴,垂直于电梯后立面向外为z轴,相机光轴与三个坐标轴x、y、z的夹角分别为,则目标的深度d:。
13.本发明又公开了一种基于深度学习的电梯人流视觉统计系统,包括:yolo-el神经网络模型构建模块,使用注意力机制对yolov5神经网络模型进行改进,将带有残差结构的网络模块cst替换yolov5 backbone中的csp模块,使用csa模块替代yolov5神经网络模型中特征融合部分的csp模块,得到改进的yolo-el神经网络模型;目标检测模块,通过改进的yolo-el神经网络模型对图像进行检测,将当前图像标记为首帧;跟踪统计模块,如果检测到目标,将检测到的目标信息传递给目标跟踪器,对图像动态跟踪,并选择fn帧中的一帧进行识别统计,忽略其他帧;如果跟踪失败或完成n帧图像的跟踪,重新对图像进行检测。
14.优选的技术方案中,还包括遮挡目标检测模块:当跟踪器跟踪失败,判断目标出现重叠,检测近景目标的深度信息,判断被遮挡目标是否还在电梯内;如果近景目标的深度大于电梯自身的深度,不进行统计,如果近景目标的深度小于电梯自身的深度,对其进行统计。
15.本发明还公开了一种计算机存储介质,其上存储有计算机程序,所述计算机程序被执行时实现上述的基于深度学习的电梯人流视觉统计方法。
16.本发明与现有技术相比,其显著优点为:采用基于人工智能的目标检测方法,提出了“检测-跟踪”的电梯乘员检测统计方法,通过对神经网络模型进行改进,提出了yolo-el神经网络模型,提高了目标检测的效果,
提高了对目标特别是小目标的检测识别效率。
17.将神经网络与跟踪算法深度融合,并采取丢帧的处理方式,进一步降低运算量,提高目标检测的速度,使系统的成本进一步降低。
18.基于异域特征的单目测距方法对目标深度进行实时计算,改善了对遮挡目标的检测效果,使电梯乘员检测统计的结果更准确,为电梯的智能调度、层间调控、安全评估、维护周期等提供重要的数据依据;同时也可以改进商业效益,基于电梯客流统计数据,智能地投放各类广告、信息、通知等,将使人们的生活更为丰富、便捷。同时本专利也可以延拓到公交车、超市入口以及客运站检票口等场所,实现对流动人员数量的监控与统计。
附图说明
19.图1为实施例的基于深度学习的电梯人流视觉统计方法的流程图;图2为现有yolov5网络结构图;图3为实施例的yolo-el网络结构图;图4为实施例的cst模块结构图;图5为实施例的csa模块结构图;图6为实施例的电梯内人员目标检测示意图;图7为实施例的电梯人员检测流程图;图8为实施例的单目相机测距示意图;图9为实施例的相机在电梯内安装示意图;图10为实施例的基于深度学习的电梯人流视觉统计系统的原理图;图11为实施例的场景1的传统方法的检测效果图;图12为实施例的场景1的本发明方法的检测效果图;图13为实施例的场景2的传统方法的检测效果图;图14为实施例的场景2的本发明方法的检测效果图;图15为实施例的场景3的传统方法的检测效果图;图16为实施例的场景3的本发明方法的检测效果图;图17为实施例的模型检测性能对比图。
具体实施方式
20.本发明的原理是:通过改进神经网络模型,并结合目标跟踪算法,保证了电梯内成员数量统计的准确性,特别是增强了对小目标的检测能力。同时为了提高对遮挡目标的检测识别能力,使用单目相机测距技术,对遮挡目标进行判断,使电梯人流检测的准确性更高。
21.实施例1:如图1所示,一种基于深度学习的电梯人流视觉统计方法,包括以下步骤:s01:使用注意力机制对yolov5神经网络模型进行改进,将带有残差结构的网络模块cst替换yolov5 backbone中的csp模块,使用csa模块替代yolov5神经网络模型中特征融合部分的csp模块,得到改进的yolov5神经网络模型;s02:通过改进的yolov5神经网络模型对图像进行检测,将当前图像标记为首帧;
s03:如果检测到目标,将检测到的目标信息传递给目标跟踪器,对图像动态跟踪,并选择fn帧中的一帧进行识别统计,忽略其他帧;如果跟踪失败或完成n帧图像的跟踪,重新对图像进行检测。
22.步骤一:针对电梯这一特定场景,采用注意力机制(attention)对yolov5卷积神经网络模型进行改进,提高目标检测性能和准确率,增强对目标特别是小目标的检测能力。
23.步骤11:使用注意力机制对yolov5神经网络模型进行改进,提出yolo-el网络模型,yolov5和yolo-el的网络结构图分别如图2和图3所示。其中,使用带有残差结构的网络模块cst替换yolov5 backbone中的csp模块,增强对小目标的特征提取,使用csa模块替代yolov5模型中特征融合部分的csp模块,实现更好的特征融合功能,cst和csa模块的结构图如图4、5所示。
24.如图4所示,cst模块包括第一卷积层、第二卷积层、第三卷积层和transformer层,第一卷积层和第二卷积层用于接收上层网络的输出,第一卷积层的输出用作transformer层的输入,第二卷积层作为残差结构,其输出端与transformer层的输出进行拼接,得到的结构输入第三个卷积层中进行处理;transformer层中数据首先进入扁平化层,经过处理后由多维转换为1维,然后经归一化层进行归一化处理,随后经过多头注意力层的处理后再次进行归一化运算,最后通过多层感知机进行处理。
25.如图5所示,csa模块包括第四卷积层、第五卷积层、第六卷积层、第七卷积层、注意力层和bottleneck层,其中bottleneck层为1
×
1的卷积运算,用于减少网络参数数量;所述第四卷积层、第五卷积层用于接收上层网络的输出,第四卷积层的输出用作注意力层的输入,注意力层的输出经过第六卷积层的处理后,其结果输入bottleneck层,经bottleneck层处理后与该第六卷积层的输出进行拼接,拼接结果与第五卷积层的结果继续拼接,第五卷积层构成残差结构,得到的结果通过第七卷积层进行处理得到最后的结果。
26.步骤12:模型训练。大部分人员检测统计算法使用面部作为识别的目标区域,但在电梯中,由于相机视角为从上向下,此时无法对人脸进行有效成像,因此在本技术中,我们使用“头”部作为目标区域,完成对人员的检测识别,如图6所示。
27.步骤二:采用“检测-跟踪”两阶段识别方式对电梯成员统计进行改进。在步骤一中,我们使用改进的yolo-el神经网络模型进行电梯乘员的检测,但是神经网络存在运算量大、需要较多训练数据的问题。为了克服上述矛盾,我们通过增加目标跟踪算法,构成“检测-跟踪”两阶段方法对成员进行识别检测,同时基于短时间内电梯内人员不会出现快速运动这一假设,我们在跟踪阶段采取丢帧的方法,即选择在多帧中跟踪一帧、其它帧忽略的方法,来进一步提高系统运行速度。系统工作后,首先完成初始化,设定摄像机的参数和其他必要条件,随后对目标连续成像,不断重复“检测-跟踪”这一工作循环,完成末端目标的高速、高精度识别定位,如图7所示,检测与定位过程如下:(1) 通过改进的yolo-el神经网络对图像进行检测,此时将当前图像标记为首帧;(2) 如果检测到目标,进行乘员数量的统计;如果未检测到目标,则回到(1);(3) 将(2)中检测到的目标信息传递给目标跟踪器,对图像动态跟踪,并选择数量fn帧中的一帧进行识别统计,其他帧则忽略;如果跟踪失败,或完成n帧图像的跟踪,回到步骤(1);(4) 重复上述过程,直到结束。
28.另一实施例中,步骤三:估算目标深度改善遮挡目标的检测。电梯乘员检测统计问题中,遮挡目标的检测是一个难点,为此本技术通过估算目标深度的方法来对遮挡目标进行检测统计,通过判断目标与电梯后墙的距离,判断目标相互之间的关系。
29.步骤31:基于异域特征的单目相机视觉测距原理。单目测距是通过目标在图像中的大小去估算目标距离,如图8所示为采用异域特征的视觉测距示意图,其中为融合后的实际目标物理尺度,为异域像素特征,为相机镜头光心到目标的距离,为相机焦距,距离的计算如式(1)所示。
[0030] (1)在式(1)中,相机焦距可通过相机参数标定获取;是乘员头部物理尺度,是电梯轿厢的内部固定物理尺度,二者属于先验数据信息。其中,与表示不同类型特征的数量。和可通过成像数据求出,而融合后的实际目标物理尺度必须是先验数据信息。根据统计数据,我国成年人头长范围约为15.5cm~18.6cm,均值为17.5cm,为增加适应性我们取头长15cm作为基准值对电梯乘员的距离进行估计。
[0031]
此外,通过引入电梯轿厢的内部固定约束参数到,进一步增强乘员在深度方向移动时测距的稳定性。同时,在步骤一中,我们使用改进的神经网络算法对人的头部进行检测识别,此时可以将检测锚框的长度近似为人头部成像的大小,此时我们便可以完成目标距离的估算。
[0032]
步骤32:基于所建坐标系进行目标深度信息估计。人员与相机的距离需要进一步转化为人员相对于电梯后墙的距离,即深度,才能正确判断多个目标之间的关系。如图9所示为相机在电梯内的安装示意图。以相机镜头的光心为坐标系原点建立右手三维坐标系,竖直向下为x轴,垂直于电梯后立面向外为z轴,相机光轴与三个坐标轴的夹角可以通过相机内置的角度传感器获取,分别设为,则目标的深度d可以通过式(2)计算。
[0033]
(2)步骤33:判断目标关系,完成对遮挡目标的检测统计。本技术对目标连续成像、检测、跟踪,基于电梯内人员位置不会突然大幅变动的假设,当两个目标出现重叠时,我们通过检测近景目标的深度,判断被遮挡目标是否还在电梯内,因为我们采用的kcf跟踪器能在目标丢失后重新出现时继续捕捉到目标,因此能够对被遮挡目标进行连续处理。如果近景目标的深度大于电梯自身的深度,那么说明这两个目标均已出电梯,不需要进行后续统计,如果近景目标的深度小于电梯自身的深度,同时跟踪器未再检测到被遮挡目标,那么此时被遮挡目标仍然处于电梯内,应当对其进行统计。
normalization),基于自注意力机制计算权重向量,得到多头注意力结构的输出,其计算如下式所示: (3)其中,,为输入特征图的维度,分别为特征图经过线性变化后得到空间向量,是由向量构成的矩阵,,,,为特征图向量,分别为权重矩阵,为层标准化运算。随后使用残差结构将多头注意力结构的输出与输入的特征向量进行拼接,并将结果送进多层感知机中,其由relu和一个线性激活函数构成,其计算结果为: (4)其中,为多头注意力结构的输出,分别为两个激活函数的权重矩阵和偏置。
[0042]
csa的运算主要包括注意力模块运算和残差层模块的拼接运算,其注意力模块的运算可参考上述cst模块。csa模块工作在网络结构的特征融合层中,接收上层网络输出的特征数据作为输入,能够使网络的特征融合能力进一步增强,并能提高网络的推理速度和准确性。
[0043]
步骤12:模型训练与检测。大部分人员检测统计算法使用面部作为识别的目标区域,但在电梯中,由于相机视角为从上向下,此时无法对人脸进行有效成像,因此在我们使用“头”部作为目标区域,完成对人员的检测识别,如图6所示。
[0044]
通过改进,本实施例对小目标的检测结果提升明显,如图11-图16所示,可以看出本技术对小目标和遮挡目标的识别检测有着比较明显的提升。与此同时,我们将本技术提出的模型yolo-el与yolo-v4、yolo-v5等检测模型性能进行了对比,如表1和图17所示,可以看出,我们的模型在准确率、召回率、运行速度等方面均有了较明显的提高。
[0045]
表1 本技术模型与其他模型性能对比
步骤二:采用“检测-跟踪”两阶段识别方式对电梯成员统计进行改进。在步骤一中,我们使用改进的yolo-el神经网络模型进行电梯乘员的检测,但是神经网络存在运算量大、需要较多训练数据的问题。为了克服上述矛盾,我们通过增加目标跟踪算法,构成“检测-跟踪”两阶段方法对成员进行识别检测,同时基于短时间内电梯内人员不会出现快速运动这一假设,我们在跟踪阶段采取丢帧的方法,即选择在多帧中跟踪一帧、其它帧忽略的方法,来进一步提高系统运行速度。系统工作后,首先完成初始化,设定摄像机的参数和其他必要条件,随后对目标连续成像,不断重复“检测-跟踪”这一工作循环,完成末端目标的高速、高精度识别定位,,如图7所示,检测与定位过程如下:(1) 通过改进的yolo-el神经网络对图像进行检测,此时将当前图像标记为首帧;(2) 如果检测到目标,进行乘员数量的统计;如果未检测到目标,则回到(1);(3) 将(2)中检测到的目标信息传递给目标跟踪器,对图像动态跟踪,并选择数量为fn帧中的一帧进行识别统计,其他帧则忽略;如果跟踪失败,或完成n帧图像的跟踪,回到步骤(1),本技术中,选择fn=3,n=6;(4) 重复上述过程,直到结束。
[0046]
步骤21:构建跟踪器。
[0047]
本技术使用kcf(核相关滤波,kernelized correlation filters)跟踪器,其通过使用轮转矩阵生成样本,训练一个判别式分类器,因为采用快速傅里叶变换对算法进行加速计算,因而在跟踪速度、跟踪精度上均有良好的表现。
[0048]
kcf算法基于岭回归求解一个响应值最大的目标模板,岭回归如下式所示: (5)其中,为训练样本,为对应的目标值,为与目标模板在频域内的点积,为正则项系数,防止目标模板过拟合。将样本的集合用来表示,的集合用来表示,则上式可以表示为: (6)
对求偏导可得并取复共轭可得: (7)其中、分别为和经傅里叶变换后的结果,为单位矩阵。
[0049]
为了简化计算,消除矩阵乘法与求逆运算,以及为了快速生成大量负样本,kcf算法引入循环矩阵,对样本进行处理。以一维向量为例,设,循环矩阵如式(8)所示。
[0050] (8)对依次左乘循环移位矩阵即可得到循环移位后的向量序列。
[0051] (9)最终得到: (10)即为经循环处理后得到的新的样本集,为样本循环处理函数。根据循环矩阵能够在傅氏空间中使用离散傅里叶变换进行对角化这一原理,可以大大简化式(7)中的计算。
[0052]
kcf使用循环矩阵获取的样本得到的也是循环矩阵,因此可对对角化: (11)其中是初始样本经傅里叶变换后得到的值,其中是的复共轭矩阵,是常离散傅里叶矩阵,为对角化函数,如式(12)所示,其中为样本数量。
[0053]
(12)循环矩阵与一个向量的乘积等价于该循环矩阵生成向量的逆序排列与该向量的卷积,并可进一步转化为在傅氏空间相乘,因此有:(13)其中为样本的逆序排列,为卷积运算,
·
为乘积运算。将式(13)代入式(7)可得:(14)其中为经傅里叶变换后的复共轭。经傅里叶变化后得式(15),其中为的傅里叶变换结果。
[0054] (15)此时求解的算法复杂度为,引入循环矩阵,不仅扩充了样本的数量,提高了准确率,而且简化了运算,提高了跟踪速度。
[0055]
步骤22:训练跟踪器。
[0056]
为了提高分类器的准确性,解决“线性不可分”的问题,kcf算法使用“核技巧”对岭回归算法进行处理,即需要找到一个非线性映射函数使映射后的结果在线性空间下是可分的,因此对于非线性回归问题就可以描述为找到一个回归函数
,给定样本和对应的标签,目标是优化最大平方和误差来求出参数。设由训练样本的非线性变换的线性组合构成:(16)其中为权重参数,此时实际为所有样本的加权平均,新样本的预测值为: (17)记称为核函数,可得: (18)其中、,为权重参数构成的向量,中的第t个元素为训练样本和测试样本的核函数值。
[0057]
根据以上论述,是关于的非线性函数,但却是关于的线性函数,可以使用线性函数的优化方法求解: (19)其中,是所有训练样本的核相关矩阵,。
[0058]
线性回归的计算可以被加速,是因为循环矩阵的特殊性质,可以证明,对于循环样本集,当核函数满足时,核相关矩阵也是循环矩阵,其中为任意置换矩阵,则非线性回归的计算同样可以被加速。在本技术中,使用高斯核函数对跟踪器进行训练:记循环矩阵的初始向量为,根据式(19)可得:
(20)经傅里叶变换得: (21)化简后得: (22)此时对于还存在较大的计算量,对同样利用循环矩阵加速,对于高斯核函数,核相关矩阵的初始向量为:(23)其中为径向基函数,、为样本向量。上式向量化后得: (24)其中为高斯核函数,将式(23)代入(24)后得:(25)则高斯核函数对应的初始向量为: (26)kcf算法的检测结果是一个标量,表示某一个样本的回归值:
(27)假设待检测的图像块为,对进行循环化: (28)其中表示训练样本与候选样本之间的核相关矩阵,记其初始向量为,则: (29)傅里叶变换后: (30)化简后得: (31)此时检测结果是一个向量,维度和训练时的一样,其中最大元素对应的偏移量即为检测到的目标的位置。
[0059]
步骤三:估算目标深度改善遮挡目标的检测。
[0060]
步骤31:基于异域特征的单目相机视觉测距原理。单目测距是通过目标在图像中的大小去估算目标距离,如图8所示为采用异域特征的视觉测距示意图,其中为融合后的实际目标物理尺度,为异域像素特征,为相机镜头光心到目标的距离,为相机焦距,距离的计算如式(32)所示:(32)在式(34)中,相机焦距可通过相机参数标定获取;是乘员头部物理
尺度,是电梯轿厢的内部固定物理尺度,二者属于先验数据信息。其中,与表示不同类型特征的数量。和可通过成像数据求出,而融合后的实际目标物理尺度必须是先验数据信息。根据统计数据,我国成年人头长范围约为15.5cm~18.6cm,均值为17.5cm,为增加适应性我们取头长15cm作为基准值对电梯乘员的距离进行估计;此外,通过将电梯轿厢的内部固定约束参数如长宽高以及特殊角点之间的距离引入到,可以作为约束条件,即通过冗余信息进一步增强乘员在深度方向移动时测距的稳定性。同时,在步骤一中,我们使用改进的神经网络算法对人的头部进行检测识别,此时可以将检测锚框的长度近似为人头部成像的大小,此时我们便可以完成目标距离的估算。
[0061]
步骤32:基于所建坐标系进行目标深度信息估计。人员与相机的距离需要进一步转化为人员相对于电梯后墙的距离,即深度,才能正确判断多个目标之间的关系。如图9所示为相机在电梯内的安装示意图。以相机镜头的光心为坐标系原点建立右手三维坐标系,竖直向下为x轴,垂直于电梯后立面向外为z轴,相机光轴与三个坐标轴的夹角可以通过相机内置的角度传感器获取,分别设为,则目标的深度d可以通过式(33)计算:(33)步骤33:判断目标关系,完成对遮挡目标的检测统计。本技术对目标连续成像、检测、跟踪,基于电梯内人员位置不会突然大幅变动的假设,当两个目标出现重叠时,我们通过检测近景目标的深度,判断被遮挡目标是否还在电梯内,因为我们采用的kcf跟踪器能在目标丢失后重新出现时继续捕捉到目标,因此能够对被遮挡目标进行连续处理。如果近景目标的深度大于电梯自身的深度,那么说明这两个目标均已出电梯,不需要进行后续统计,如果近景目标的深度小于电梯自身的深度,同时跟踪器未再检测到被遮挡目标,那么此时被遮挡目标仍然处于电梯内,应当对其进行统计。
[0062]
本技术对电梯内人员检测的效果如图11-图16所示,对于检测到的每个目标,我们在对检测准确率进行标注的同时,对目标的深度信息同时进行了标注。可以看出,本技术在对小目标和遮挡目标的检测方面有着比较明显的提升,同时根据图17所示,本技术所提出的方法的检测性能也有着明显的改善。
[0063]
上述实施例为本发明优选地实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。