1.本发明涉及能效预测技术领域,尤其是涉及一种基于卷积神经网络的耙吸船能效预测方法。
背景技术:
2.耙吸船作为目前疏浚工程的主力施工船型,因其具有机动灵活、效率高、抗风浪力强等特点,在港口维护及沿海进港航道的挖掘等任务中有着不可替代的作用。目前,国内疏浚工程需求巨大,且燃料成本不断增高,污染物排放法规日益严格,这些都对提高耙吸船施工效率有着迫切的要求。对耙吸船疏浚能效进行准确预测,能够便于确定工期,减少施工人员操作,对疏浚作业效率的提高具有重要意义。
3.tang等人(j.z.tang,q.f.wang,t.y.zhong,automatic monitoring and control of cutter suction dredger,autom.constr.18(2)(2009)194
–
203)设计了一种绞吸船自动监测系统,通过对泥浆浓度和泥浆流速控制来提高疏浚过程的生产效率,并基于计算机密切关注疏浚过程并准确评估系统状态。然而,由于影响疏浚生产力的众多因素是动态的并以复杂的方式相互关联,且耙吸船工作过程是典型的非线性过程,传统的能效预测方法对于复杂工况下耙吸船挖泥过程无法实现准确的能效预测。
技术实现要素:
4.本发明的目的是提供一种基于卷积神经网络的耙吸船能效预测方法,通过均值滤波方法处理耙吸船工作数据,之后利用卷积神经网络方法提取数据特征并建立准确可靠的能效预测模型,以解决能效预测不准确的问题。
5.为实现上述目的,本发明提供了一种基于卷积神经网络的耙吸船能效预测方法,包括以下步骤:
6.s1、根据耙吸船工作数据进行工况划分;
7.s2、对经过步骤s1处理后的耙吸船工作数据进行滤波处理;
8.s3、根据步骤s2处理后的耙吸船工作数据构建卷积神经网络能效数据的训练集,建立耙吸船能效的卷积神经网络回归预测模型。
9.进一步地,所述步骤s1的具体方法为:
10.根据耙吸船工作原理及实船数据的特征,选取泥泵转速n,航速v以及泥浆浓度γ作为工况划分的判断参数,并设置泥泵转速、航速、泥浆浓度阈值n
thr
,v
thr
和γ
thr
,将同时满足n>n
thr
,v<v
thr
以及γ>γ
thr
的工作数据判定为挖泥工况数据;
11.进一步地,所述步骤s2的具体方法为:
12.s21、均值滤波:采用均值滤波方法用均值代替原耙吸船数据中的各个值,以减少环境噪声对耙吸船工作数据的影响,其公式为:
[0013][0014]
其中,i表示耙吸船的工作参数类别(i=1,2,...,m);m为工作参数的个数,工作参数包括泥浆浓度、泥浆密度、泥泵流速、泥浆流量、航速、耙吸船功率等;ui(j)表示耙吸船第i个工作参数的第j个数据(j=1,2,...,n);n为数据的个数;ui(j)为ui(j)经滤波后的工作数据;k为滤波的步长;
[0015]
其中,耙吸船的工作参数ui表示为:
[0016]
ui=(ui(1),ui(2),...,ui(n))
[0017]
滤波后的耙吸船总工作数据集u即为:
[0018]
u=(u1,u2,...,um)
t
;
[0019]
s22、提取耙吸船能效相关工作参数xi以及能效数据y:
[0020]
根据耙吸船工作参数类型可将耙吸船的工作数据z表示为:
[0021]
z=(x1,x2,...,x
l
,y1,y2,y3,y4)
t
[0022]
其中,x1=u1,x2=u2,...,x
l
=u
l
代表集合u中除耙吸船功率p、泥浆浓度γ、泥浆密度ρ和泥浆流量q以外的耙吸船能效相关的工作参数(l=m-4);y1,y2,y3,y4代表耙吸船能效计算参数,分别为耙吸船功率p、泥浆浓度γ、泥浆密度ρ和泥浆流量q,耙吸船的能效数据y通过上述参数计算,计算公式为:
[0023]
y=p/γρq
[0024]
提取的工作参数xi以及能效数据y作为有效两侧数据集,表示为:
[0025]
xi=(xi(1),xi(2),...,xi(n))
[0026]
y=(y(1),y(2),...,y(n));
[0027]
进一步地,所述步骤s3的具体方法为:
[0028]
s31、滑窗数据序列选取:从有效量测数据集数据获取当前数据点及后p-1个数据点的数据组成滑窗数据序列,p为滑窗序列的步长,获得的滑窗数据序列记作y
(j)
:
[0029][0030]
x
(j)
为有效量测数据集的全部工作数据在第j个数据点的滑窗序列:
[0031][0032]
将所有数据点的滑窗序列组合得到新数据集x
new
,y
new
:
[0033]
x
new
=(x
(1)
,x
(2)
,...,x
(n)
)
t
[0034]ynew
=(y
(1)
,y
(2)
,...,y
(n)
)
t
[0035]
数据集x
new
为n
×
l行p列的矩阵,每l行数据都表示耙吸船在一个数据点及其之后的p-1个数据点上的l个工作参数的实时值,这些数据作为神经网络一个样本的输入;数据集y
new
为n行p列的矩阵,每一行数据都表示耙吸船在一个数据点及其之后的p-1个数据点上
的能效值,这些数据作为神经网络一个样本的输出;
[0036]
s32、将样本分为训练集、测试集;其中训练集、测试集占总样本的比例分别为80%、20%,并对其进行归一化处理;
[0037]
s33、构建卷积神经网络模型:所述模型的网络结构由输入层、卷积层、激活函数层以及两个全连接层组成,并设置学习率、激活函数类型、迭代次数、三个超参数;
[0038]
所述输入层输入数据大小为经滤波后的工作参数数量和滑窗序列步长的乘积,即l
×
p;
[0039]
所述卷积层具有16个大小为3
×
3的滤波器,用于提取耙吸船的数据特征;
[0040]
所述激活函数层的激活函数选择relu激活函数,其公式为:
[0041][0042]
所述全连接层作为输出层,其单元数等于滑窗序列步长p;
[0043]
s34、验证模型准确性:利用测试集的样本对卷积神经网络模型进行测试,并通过均方根误差(rmse)验证模型准确性;
[0044][0045]
其中,y(i)为耙吸船的真实能效,ec(x(i))为耙吸船的能效预测值。
[0046]
本发明所述的一种基于卷积神经网络的耙吸船能效预测方法的优点和积极效果是:
[0047]
1、本发明设计的工况划分与滤波方法可以有效提取出与耙吸船能效相关的工作数据,并避免了环境噪声对能效预测产生影响,提高了耙吸船能效预测的准确性。
[0048]
2、本发明运用卷积神经网络提取耙吸船工作数据特征并建立能效预测模型,解决了耙吸船系统能效预测不准确的问题。
[0049]
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
[0050]
图1为本发明一种基于卷积神经网络的耙吸船能效预测方法实施例的流程图;
[0051]
图2为本发明一种基于卷积神经网络的耙吸船能效预测方法实施例的耙吸船能效值与耙吸船能效预测值图;
[0052]
图3为本发明一种基于卷积神经网络的耙吸船能效预测方法实施例的模型的均方根误差图。
具体实施方式
[0053]
以下通过附图和实施例对本发明的技术方案作进一步说明。
[0054]
实施例
[0055]
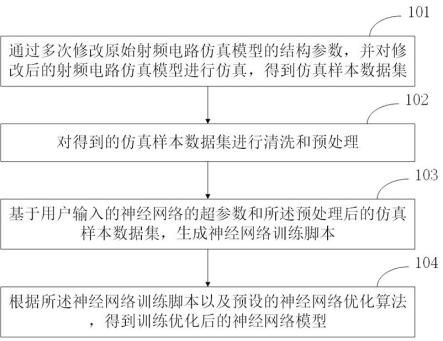
图1为本发明一种基于卷积神经网络的耙吸船能效预测方法实施例的流程图。如图所示,一种基于卷积神经网络的耙吸船能效预测方法,包括以下步骤:
[0056]
s1、根据耙吸船工作数据进行工况划分。
[0057]
步骤s1的具体方法为:
[0058]
s11、挖泥工况数据提取:根据耙吸船工作原理及实船数据的特征,选取泥泵转速n,航速v以及泥浆浓度γ作为工况划分的判断参数,并设置泥泵转速、航速、泥浆浓度阈值n
thr
,v
thr
和γ
thr
,n
thr
=100r/min,v
thr
=4kn,γ
thr
=0.6%,将同时满足n>n
thr
,v<v
thr
以及γ>γ
thr
的工作数据判定为挖泥工况数据。
[0059]
s2、对经过步骤s1处理后的耙吸船工作数据进行滤波处理以剔除环境噪声。
[0060]
s21、均值滤波:采用均值滤波方法用均值代替原耙吸船数据中的各个值,以减少环境噪声对耙吸船工作数据的影响,其公式为:
[0061][0062]
其中,i表示耙吸船的工作参数类别(i=1,2,...,m);m为工作参数的个数,工作参数包括泥浆浓度、泥浆密度、泥泵流速、泥浆流量、航速、耙吸船功率等;ui(j)表示耙吸船第i个工作参数的第j个数据(j=1,2,...,n);n为数据的个数;ui(j)为ui(j)经滤波后的工作数据;k为滤波的步长;
[0063]
其中,耙吸船的工作参数ui表示为:
[0064]
ui=(ui(1),ui(2),...,ui(n))
[0065]
滤波后的耙吸船总工作数据集u即为:
[0066]
u=(u1,u2,...,um)
t
[0067]
此处,工作参数分别为泥浆浓度、泥浆密度、泥泵流速、泥泵真空、泥舱舱容、波浪补偿器压力、泥浆流量、航速、耙吸船功率共9组参数,即m为9;经提取后的工作参数个数n为1002个;滤波步长k设置为10。
[0068]
s22、提取耙吸船能效相关工作参数xi以及能效数据y:
[0069]
根据耙吸船工作参数类型可将耙吸船的工作数据z表示为:
[0070]
z=(x1,x2,...,x
l
,y1,y2,y3,y4)
t
[0071]
其中,x1=u1,x2=u2,...,x
l
=u
l
代表集合u中除耙吸船功率p、泥浆浓度γ、泥浆密度ρ和泥浆流量q以外的耙吸船能效相关的工作参数(l=m-4);y1,y2,y3,y4代表耙吸船能效计算参数,分别为耙吸船功率p、泥浆浓度γ、泥浆密度ρ和泥浆流量q,耙吸船的能效数据y通过上述参数计算,计算公式为:
[0072]
y=p/γρq
[0073]
提取的工作参数xi以及能效数据y表示为:
[0074]
xi=(xi(1),xi(2),...,xi(n))
[0075]
y=(y(1),y(2),...,y(n))。
[0076]
s3、根据步骤s2处理后的耙吸船工作数据构建卷积神经网络能效数据的训练集,建立耙吸船能效的卷积神经网络回归预测模型。
[0077]
步骤s3中卷积神经网络回归预测模型具体构建方法为:
[0078]
s31、滑窗数据序列选取:从有效量测数据集数据获取当前数据点及后p-1个数据
点的数据组成滑窗数据序列,p为滑窗序列的步长,获得的滑窗数据序列记作y
(j)
:
[0079][0080]
x
(j)
为有效量测数据集的全部工作数据在第j个数据点的滑窗序列:
[0081][0082]
将所有数据点的滑窗序列组合得到新数据集x
new
,y
new
:
[0083]
x
new
=(x
(1)
,x
(2)
,...,x
(n)
)
t
[0084]ynew
=(y
(1)
,y
(2)
,...,y
(n)
)
t
[0085]
此处滑窗序列的步长p设置为10,由步骤s2中提取得到的工作参数为l=5组。
[0086]
数据集x
new
为n
×
l行p列的矩阵,每l行数据都表示耙吸船在一个数据点及其之后的p-1个数据点上的l个工作参数的实时值,这些数据作为神经网络一个样本的输入;数据集y
new
为n行p列的矩阵,每一行数据都表示耙吸船在一个数据点及其之后的p-1个数据点上的能效值,这些数据作为神经网络一个样本的输出。
[0087]
s32、将样本分为训练集、测试集;其中训练集、测试集占总样本的比例分别为80%、20%,并对其进行归一化处理。
[0088]
s33、构建卷积神经网络模型:所述模型的网络结构由输入层、卷积层、激活函数层以及两个全连接层组成,并设置学习率、激活函数类型、迭代次数、三个超参数;
[0089]
所述输入层输入数据大小为经相关性分析后筛选的工作参数数量和滑窗序列步长的乘积,即l
×
p,此处输入数据大小为5
×
10;
[0090]
卷积层具有16个大小为3
×
3的滤波器,用于提取耙吸船工作数据的特征;
[0091]
激活函数层的激活函数选择relu激活函数,其公式为:
[0092][0093]
所述全连接层作为输出层,其单元数等于滑窗序列步长p。
[0094]
s34、验证模型准确性:利用测试集的样本对卷积神经网络模型进行测试,并通过均方根误差(rmse)验证模型准确性;
[0095][0096]
其中,y(i)为耙吸船的真实能效,ec(x(i))为耙吸船的能效预测值。
[0097]
图2为本发明一种基于卷积神经网络的耙吸船能效预测方法实施例的耙吸船能效值与耙吸船能效预测值图,图3为本发明一种基于卷积神经网络的耙吸船能效预测方法实施例的模型的均方根误差图。如图所示,耙吸船的真实能效与能效预测值之间的拟合度非常高,误差非常小,说明本发明所述的耙吸船能效预测方法准确度非常高。
[0098]
因此,本发明采用上述基于卷积神经网络的耙吸船能效预测方法,能够解决能效预测不准确的问题。
[0099]
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,
尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。