技术特征:
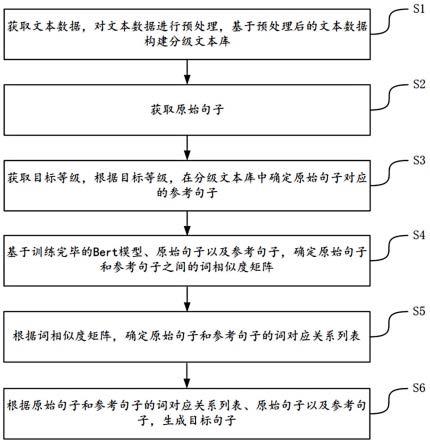
1.一种中文文本智能分级改编方法,其特征在于,所述方法包括:s1、获取文本数据,对所述文本数据进行预处理,基于预处理后的文本数据构建分级文本库;s2、获取原始句子;s3、获取目标等级,根据目标等级,在所述分级文本库中确定所述原始句子对应的参考句子;s4、基于训练完毕的bert模型、原始句子以及参考句子,确定所述原始句子和参考句子之间的词相似度矩阵;s5、根据所述词相似度矩阵,确定所述原始句子与参考句子的词对应关系列表;s6、根据所述原始句子与参考句子的词对应关系列表、所述原始句子以及所述参考句子,生成目标句子。2.根据权利要求1所述的方法,其特征在于,所述s1中的对所述文本数据进行预处理,基于预处理后的文本数据构建分级文本库,包括:s11、对所述文本数据进行分句处理,得到多个待归类句子;s12、对多个待归类句子分别进行分级处理;s13、将分级处理后的待归类句子按照等级存入到分级文本库的分级子库中。3.根据权利要求2所述的方法,其特征在于,所述s12中的对多个待归类句子分别进行分级处理,包括:s121、根据预设的分级标准,分别确定多个待归类句子中的每个待归类句子的每个音节的等级、每个字的等级、每个词的等级以及语法等级;s122、将所述每个待归类句子的每个音节的等级、每个字的等级、每个词的等级以及语法等级中的最高等级,确定为待归类句子的等级。4.根据权利要求1所述的方法,其特征在于,所述s3中的获取目标等级,根据目标等级,在所述分级文本库中确定所述原始句子对应的参考句子,包括:s31、获取目标等级,根据所述目标等级,在所述分级文本库中确定所述目标等级对应的目标分级子库,将所述目标分级子库中与所述原始句子的词数相同的多个句子确定为参考句子候选集合;s32、将所述原始句子输入到训练完毕的bert模型中,获取所述原始句子的每个词对应的词向量,对所有词对应的词向量进行平均池化操作,得到所述原始句子的向量表征;s33、将所述参考句子候选集合中的每个候选句子输入到训练完毕的bert模型中,获取所述每个候选句子的每个词对应的词向量,对所述每个候选句子的所有词对应的词向量进行平均池化操作,得到所述每个候选句子的向量表征;s34、根据所述原始句子的向量表征以及所述每个候选句子的向量表征,确定所述原始句子与所述每个候选句子的相似度,将相似度最大的候选句子确定为所述原始句子的参考句子。5.根据权利要求1所述的方法,其特征在于,所述s4中的基于训练完毕的bert模型、原始句子以及参考句子,确定所述原始句子和参考句子之间的词相似度矩阵,包括:s41、将所述原始句子输入训练完毕的bert模型中,得到所述原始句子的每个词对应的词向量;
s42、将所述参考句子输入训练完毕的bert模型中,得到所述参考句子的每个词对应的词向量;s43、计算原始句子的每个词对应的词向量与所述参考句子的每个词对应的词向量之间的相似度,得到所述原始句子和参考句子之间的词相似度矩阵。6.根据权利要求1所述的方法,其特征在于,所述s5中的根据所述词相似度矩阵,确定所述原始句子与参考句子的词对应关系列表,包括:s51、设定k=1;s52、判断k是否大于n,如果k大于n,则转去执行s56,如果k小于或等于n,则执行s53;其中,n表示所述原始句子的词数量;s53、在所述词相似度矩阵中遍历所有非零元素,将相似度值最大的元素确定为目标元素,将所述目标元素所在的行数赋值给x,将所述目标元素所在的列数赋值给y;s54、将所述词相似度矩阵的第x行元素均置为0,将所述词相似度矩阵的第y列元素均置为0;s55、将(x,y)记入词对应关系列表中;k=k 1,x=0,y=0,转去执行s52;s56、停止循环,生成词对应关系列表。7.根据权利要求1所述的方法,其特征在于,所述s6中的根据所述原始句子与参考句子的词对应关系列表、所述原始句子与所述参考句子,生成目标句子,包括:s61、设定j=1;s62、判断j是否大于n,如果j大于n,则执行s66;如果j小于或等于n,则执行s63;其中,n表示所述原始句子的词数量;s63、根据所述原始句子与参考句子的词对应关系列表,判断第j个位置处原始句子的词和参考句子的词是否相同;s64、如果第j个位置处原始句子的词和参考句子的词相同,则将原始句子的词确定为目标句子第j位置处的目标词;s65、如果第j个位置处原始句子的词和参考句子的词不相同,则判断所述原始句子的词的等级是否小于或等于目标等级,如果小于或等于目标等级,则将所述原始句子的词确定为目标句子第j位置处的目标词,如果大于目标等级,则将参考句子的词确定为目标句子第j位置处的目标词;j=j 1;转去执行s62;s66、根据目标句子所有位置处的目标词,生成目标句子。8.一种中文文本智能分级改编装置,其特征在于,所述装置包括:构建模块,用于获取文本数据,对所述文本数据进行预处理,基于文本数据以及对应的等级,构建分级文本库;第一确定模块,用于获取原始句子,确定所述原始句子的等级;第二确定模块,用于获取目标等级,根据目标等级,在所述分级文本库中确定所述原始句子对应的参考句子;第三确定模块,用于基于训练完毕的bert模型、原始句子以及参考句子,确定所述原始句子和参考句子之间的词相似度矩阵;第四确定模块,用于根据所述词相似度矩阵,确定所述原始句子与参考句子的词对应关系列表;
生成模块,用于根据所述原始句子与参考句子的词对应关系列表、所述原始句子以及所述参考句子,生成目标句子。9.根据权利要求8所述的装置,其特征在于,所述构建模块,进一步用于:s11、对所述文本数据进行分句处理,得到多个待归类句子;s12、对多个待归类句子分别进行分级处理;s13、将分级处理后的待归类句子存入到分级文本库中对应的分级子库中。10.根据权利要求9所述的装置,其特征在于,所述构建模块,进一步用于:s21、根据预设的分级标准,分别确定多个待归类句子中的每个待归类句子的每个音节的等级、每个字的等级、每个词的等级以及语法等级;s22、将所述每个待归类句子的每个音节的等级、每个字的等级、每个词的等级以及语法等级中的最高等级,确定为待归类句子的等级。
技术总结
本发明涉及自然语言处理技术领域,特别是指一种中文文本智能分级改编方法及装置,方法包括:获取文本数据,对文本数据进行预处理,基于预处理后的文本数据构建分级文本库;获取原始句子;获取目标等级,根据目标等级,在分级文本库中确定原始句子对应的参考句子;基于训练完毕的Bert模型、原始句子以及参考句子,确定原始句子和参考句子之间的词相似度矩阵;根据词相似度矩阵,确定原始句子与参考句子的词对应关系列表;根据原始句子与参考句子的词对应关系列表、原始句子以及参考句子,生成目标句子。采用本发明,可以提高改编效率,减少人为错误。误。误。
技术研发人员:殷晓君
受保护的技术使用者:北京语言大学
技术研发日:2022.12.01
技术公布日:2023/1/13
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。