1.本发明涉及水资源优化配置和调度技术。尤其是一种跨省江河流域初始水权分配方法和系统。
背景技术:
2.随着经济的发展和生态环保意识的提高,我国发展过程中面临的水资源瓶颈问题越发凸显。明晰水资源权利对于解决水资源利用的公地悲剧,以及遏制水资源超载、提高水资源利用效益具有良好的作用。为了更好地服务经济发展,从严从细管好水资源,全面实行最严格的水资源管理制度,健全初始水资源分配制度,是当前重要的工作内容。
3.跨省江河流域初始水权分配是当前一个重要的课题,其涉及省际之间的利益分配,涉及到自然、社会、经济等因素,因此初始水权分配是一个多地区、多目标、多属性、多层次的决策过程,参数和约束条件较多,权重设置主观性强,计算相对非常复杂,目前尚无较好的解决方案。
4.因此,需要研究新的技术方案。
技术实现要素:
5.发明目的:一方面,提供一种跨省江河流域初始水权分配方法,以解决现有技术存在的上述问题。另一方面,提供一种实现上述方法的系统。
6.技术方案:跨省江河流域初始水权分配方法,包括如下步骤:步骤s1、读取跨省江河流域的水资源调查数据,获得并分析能够反映丰枯变化和当前下垫面条件下的代表性水文系列;步骤s2、采集跨省江河流域的基础数据,所述基础数据包括水资源开发利用数据、经济社会数据和生态环境数据;获取用于构建跨省江河流域的初始水资源分配的评价指标体系的评价指标,并对所述评价指标进行约简;步骤s3、构建smaa-vikor初始水权分配模型,并求解,获得每一省级行政区域的初始水权分配比例。
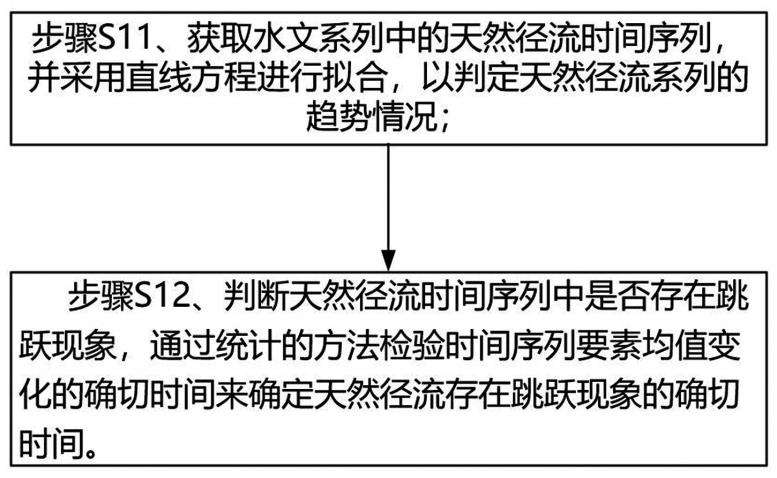
7.根据本技术的一个方面,所述步骤s1中获得并分析能够反映丰枯变化和当前下垫面条件下的代表性水文系列的过程进一步为:步骤s11、获取水文系列中的天然径流时间序列,并采用直线方程进行拟合,以判定天然径流系列的趋势情况;步骤s12、判断天然径流时间序列中是否存在跳跃现象,通过统计的方法检验时间序列要素均值变化的确切时间来确定天然径流存在跳跃现象的确切时间。
8.根据本技术的一个方面,所述步骤s11中,采用直线方程进行拟合的过程具体为:x
t
'≈a0 a1t;a1表示天然径流量x的趋势倾向,a0为回归常数,x
t
'为天然径流量估计值,天然径流量x与时间t之间线性相关的密切程度用相关系数r表示;
;式中,xb为第b年的天然径流量,xm为径流量时间序列均值,tm=(n 1)/2,n年然径流的系列长度,r值为正时,表示天然径流时间序列中的天然径流量在所计算的n年内有线性递增的趋势。
9.根据本技术的一个方面,所述步骤s12中,判断天然径流时间序列中是否存在跳跃现象的过程进一步为:步骤s12a、针对k个天然径流量的时间序列组成的数组x(x1,x2,
…
xi,
…
xj,
…
xk),构造秩序列sk,sk=r1 r2
…
, ri,
…
rk;当xi>xj时,ri=1,当xi=xj时,ri=0,当xi<xj时,ri=﹣1,步骤s12b、判断在t时刻,max丨sk丨是否等于预定值,若等于,则此时刻t为突变点时刻;步骤s12c、计算突变点时刻的概率p,p=2exp[﹣6k
t2
/(n3 n2)];当p≤0.5时,检测出的突变点在统计意义上是显著的。n的含义同上。
[0010]
根据本技术的一个方面,所述评价指标体系包括目标层、准则层和指标层,其中所述目标层为流域水资源总量,准则层包括公平原则、高效原则和可持续原则;与所述公平原则相关的指标包含现状用水量、人口数量、gdp总量、流域面积和灌溉面积;与高效原则相关的指标包括人均gdp、人均用水量、万元gdp用水量、万元工业增加值用水量、农田灌溉水有效利用系数和工业用水重复率;与可持续原则相关的指标包括森林覆盖率、人口增长率、gdp增长率、城镇化率、劣v类水排放比例、工业废水排放达标率和水功能区水质达标率。
[0011]
根据本技术的一个方面,所述步骤s2中,对所述评价指标进行约简的过程具体包括:步骤s21、构建xgboost模型,采集若干评价指标作为xgboost模型的输入,以综合评价指标值作为xgboost模型的输出,对模型进行训练;步骤s22、从训练好的xgboost模型的连接权值中提取各个评价指标的相对重要程度信息,对评价指标进行筛选;步骤s23、采用训练好的xgboost模型对各个评价指标进行敏感性分析,定量计算各个评价指标的变化对决策结果变化的相对贡献率;步骤s24、基于评价指标的相对重要程度信息和相对贡献率,构建评价指标筛选的综合判别准则,基于所述综合判别准则对评价指标进行筛选;其中,构建评价指标筛选的综合判别准则的过程为,针对每一评价指标,逐一计算相对重要程度信息和相对贡献率的乘积,获得第一综合评价指标;接着计算第一综合评价指标的平均值,用各个评价指标与平均值作商,然后计算该商的十进对数值,逐一判断评价指标的十进对数值是否符合阈值。
[0012]
根据本技术的一个方面,训练xgboost模型的过程为:步骤s21a、生成满足约束条件的调度方案集,计算所有指标值达到最优时的正理
想点和所有指标值达到最劣时的负理想点,得到方案优劣的上下极限状态;步骤s21b、采用随机模拟法生成xgboost模型训练样本的输入项,随机生成预定数量个服从均匀分布的随机数,在正理想点和负理想点之间对指标值进行离散化计算,产生预定数量个训练样本输入项;步骤s21c、计算各个样本距离正理想点和负理想点的欧式距离和贴进度,将所述贴进度归一化处理。
[0013]
根据本技术的一个方面,所述步骤s3进一步为:步骤s31、构建备选方案的决策矩阵并进行标准化,得到标准化决策矩阵;步骤s32、确定可行权重空间的分布,并基于其概率密度函数进行抽样,随机生成可行权重;步骤s33、构建vikor模型并计算得到各个备选方案的排名;步骤s34、存储计算过程中得到备选方案的排名,计算排序可接受性指标、全局可接受性指标和中心权重向量;得出各个省级行政区的初始水权分配比例。
[0014]
根据本技术的另一方面,提供一种跨省江河流域初始水权分配系统,包括:至少一个处理器;以及与至少一个所述处理器通信连接的存储器;其中,所述存储器存储有可被所述处理器执行的指令,所述指令用于被所述处理器执行以实现上述任一项技术方案所述的跨省江河流域初始水权分配方法。
[0015]
有益效果:通过对评价指标体系的降维和优选,以及smaa-vikor初始水权分配模型的构建,克服了现有技术中权重设置主观性强的问题,本技术能够提高跨省江河流域的水资源分配精度和公平度。
附图说明
[0016]
图1是本发明的整体实现过程流程图。
[0017]
图2是本发明获得并分析能够反映丰枯变化和当前下垫面条件下的代表性水文系列的流程图。
[0018]
图3是本发明评价指标进行约简的流程图。
[0019]
图4是本发明训练xgboost模型的流程图。
[0020]
图5是本发明步骤s3的详细过程示意图。
具体实施方式
[0021]
为了解决现有技术存在的问题,申请人研究了现有文献,在现有专利和论文中,对于指标的定义和选择是不统一的,不同的文献中,给出了不同的指标组合,主观性较大,导致分水结果的公平性常常受到质疑。技术人员也进行了一些探索,例如采用topsis模型确定分水比例,但是这种方法得到的分水比例的公平性还有待深入研究。
[0022]
对于复杂的评价指标,相互之间具有复杂的非线性关系,如何对评价指标体系进行降维,同时实现输入向量和输出数据之间的相对精确的非线性映射,是评价指标体系构建和指标权重构建的重要基础。为此,申请人进行了探索,给出了下述的技术方案。
[0023]
如图1所示,跨省江河流域初始水权分配方法,包括如下步骤:
步骤s1、读取跨省江河流域的水资源调查数据,获得并分析能够反映丰枯变化和当前下垫面条件下的代表性水文系列。通过选取具有代表性的水文序列,在后续获初始水权分配比例后,根据比例调整代表性水文序列的调控参数,从而实现对水资源的分配。在某些实施例中,可以通过调整各个区域的平年、丰年、枯年的径流量来实现对水资源的分配。
[0024]
步骤s2、采集跨省江河流域的基础数据,所述基础数据包括水资源开发利用数据、经济社会数据和生态环境数据;获取用于构建跨省江河流域的初始水资源分配的评价指标体系的评价指标,并对所述评价指标进行约简;步骤s3、构建smaa-vikor初始水权分配模型,并求解,获得每一省级行政区域的初始水权分配比例。
[0025]
在本实施例中,首先对研究流域进行调查,然后采集基础数据,从中获得代表性的水文系列。然后先采集一系列的指标作为评价指标的备选项,通过构建指标评价体系对指标进行梳理和降维,从中挑选出合适的评价指标,构建评价指标体系。最后构建初始水权分配模型,将上述数据作为输入数据之一,对模型进行求解,获得初始水权分配比例数据。具体的实现过程将在下文详细描述。
[0026]
如图2所示,在本技术的另一实施例中,所述步骤s1中获得并分析能够反映丰枯变化和当前下垫面条件下的代表性水文系列的过程进一步为:步骤s11、获取水文系列中的天然径流时间序列,并采用直线方程进行拟合,以判定天然径流系列的趋势情况;采用直线方程进行拟合的过程具体为:x
t
'≈a0 a1t;a1表示天然径流量x的趋势倾向,a1>0,则表示x随着时间t的增加而呈上升的趋势,反之,则呈下降的趋势,a1又称为倾向值,a0为回归常数,x
t
'为天然径流量估计值。
[0027]
天然径流量x与时间t之间线性相关的密切程度用相关系数r表示;;式中,xb为第b年的天然径流量,xm为径流量时间序列均值,tm=(n 1)/2,n年然径流的系列长度,r值为正时,表示天然径流时间序列中的天然径流量在所计算的n年内有线性递增的趋势。r为负值时,表示天然径流时间序列中的天然径流量在所计算的n年内有线性递减的趋势。r=0时,回归系数为0,说明天然径流量x的变化与时间无关。r的绝对值越大,线性相关就越小,反之就越大,线性相关就越密切。
[0028]
通过查询系数检验表得到置信度α,当r的绝对值小于γ
0.05
时,天然径流量序列线性变化趋势不显著;当r的绝对值在γ
0.05
和γ
0.01
之间时,天然径流量序列线性变化趋势显著,当r的绝对值大于γ
0.01
时,认为天然径流量序列线性变化趋势特别显著。
[0029]
步骤s12、判断天然径流时间序列中是否存在跳跃现象,通过统计的方法检验时间序列要素均值变化的确切时间来确定天然径流存在跳跃现象的确切时间。
[0030]
所述步骤s12中,判断天然径流时间序列中是否存在跳跃现象的过程进一步为:步骤s12a、针对k个天然径流量的时间序列组成的数组x(x1,x2,
…
xi,
…
xj,
…
xk),
构造秩序列sk,sk=r1 r2
…
, ri,
…
rk;当xi>xj时,ri=1,当xi=xj时,ri=0,当xi<xj时,ri=﹣1,步骤s12b、判断在t时刻,max丨sk丨是否等于预定值,若等于,则此时刻t为突变点时刻;步骤s12c、计算突变点时刻的概率p,p=2exp[﹣6k
t2
/(n3 n2)];当p≤0.5时,检测出的突变点在统计意义上是显著的。
[0031]
具体而言,经过处理后,获得如下的评价指标体系。所述评价指标体系包括目标层、准则层和指标层,其中所述目标层为流域水资源总量,准则层包括公平原则、高效原则和可持续原则;与所述公平原则相关的指标包含现状用水量、人口数量、gdp总量、流域面积和灌溉面积;与高效原则相关的指标包括人均gdp、人均用水量、万元gdp用水量、万元工业增加值用水量、农田灌溉水有效利用系数和工业用水重复率;与可持续原则相关的指标包括森林覆盖率、人口增长率、gdp增长率、城镇化率、劣v类水排放比例、工业废水排放达标率和水功能区水质达标率。
[0032]
在本实施例中,公平原则主要考虑到不同地区现状用水、人口分布、自然条件以及生产力布局等,在初始水权分配中,需要做到公平合理。高效原则主要考虑到水资源既是自然资源又是经济资源,在初始水权分配中,需要兼顾水资源的经济效益。可持续原则主要考虑到水资源是经济社会可持续发展的重要支撑,在初始水权分配中,要遵循水资源与经济社会和谐发展的原则,流域水资源开发利用不能超过其承载力。基于本实施例的评价指标体系,构建与之对应的权重矩阵。
[0033]
具体而言,评价指标的约简过程是相对复杂的,将在下文描述。在本文中,采取指标逐个删减的思路,围绕xgboost模型训练样本生成、xgboost模型拓扑结构设计、指标重要度辨识、指标敏感度辨识、指标筛选的综合判别准则五个方面提出基于xgboost模型的指标体系降维方法。
[0034]
如图3和图4所示,在本技术的另一实施例中,所述步骤s2中,对所述评价指标进行约简的过程具体包括:步骤s21、构建xgboost模型,采集若干评价指标作为xgboost模型的输入,以综合评价指标值作为xgboost模型的输出,对模型进行训练。
[0035]
训练xgboost模型的过程为:步骤s21a、生成满足约束条件的调度方案集,计算所有指标值达到最优时的正理想点和所有指标值达到最劣时的负理想点,得到方案优劣的上下极限状态。
[0036]
步骤s21b、采用随机模拟法生成xgboost模型训练样本的输入项,随机生成预定数量个服从均匀分布的随机数,在正理想点和负理想点之间对指标值进行离散化计算,产生预定数量个训练样本输入项。
[0037]
步骤s21c、计算各个样本距离正理想点和负理想点的欧式距离和贴进度,将所述贴进度归一化处理。
[0038]
在本步骤中,贴进度是反映水权分配方案优劣的综合评价指标。贴进度的取值范围为[0, 1],反映了训练样本与正、负理想点的相对距离。贴进度越大,表明距负理想点越远,距正理想点越近,该样本越优;反之则越差。以各训练样本归一化后的指标值作为xgboost模型输入,以贴近度系数作为xgboost模型输出,最终生成的xgboost模型训练样本
集可以表示为:{x
id
,c
t
丨t=1,2,
…
,d;d=1,2,
…
,n}。
[0039]
步骤s22、从训练好的xgboost模型的连接权值中提取各个评价指标的相对重要程度信息,对评价指标进行筛选。
[0040]
令输入层的输入向量为(x1,x2,
…
,xd,
…
,xn)
t
,中间层的输出向量为(y1,y2,
…
,yd,
…
,yn)
t
。z为xgboost模型的实际输出值。输入层节点d和中间层节点s之间的连接权值记为w
ds
,中间层节点s和输出层节点间的连接权值记为ws,θs和θ分别为中间层和输出层的阈值。
[0041]
xgboost模型连接权值w
ds
和ws反映了某个指标值被引入xgboost模型的信息量的大小,决定了指标对xgboost模型输出的贡献程度。因此,定义第d个指标的相对重要度rd为:,rd的值越大,表明该指标对防洪调度多属性决策的作用越显著,在原始指标体系中的地位也越为重要。
[0042]
步骤s23、采用训练好的xgboost模型对各个评价指标进行敏感性分析,定量计算各个评价指标的变化对决策结果变化的相对贡献率。
[0043]
以某样本的各指标值为输入向量(x1,x2,
…
,xj,
…
,xn)
t
,其xgboost模型输出值记为z’。对于第j个指标值xj,在保持其它指标不变的条件下,设定其9个不同的变化场景,即x
j*
=xj×
(1
∆
xj),
∆
x
j =0,
±
5%,
±
10%,
±
15%,
±
20%,以(x1,x2,
…
,xj,
…
,xn)
t
作为xgboost模型的输入来预测xgboost模型实际输出值的相对变化,据此分析xgboost模型实际输出值对各个指标的敏感性。
[0044]
为了定量分析各个指标的敏感性,当
∆
x
j =
±
20%时,xgboost模型输出值z的绝对变化量为
∆
zj=丨z-zm丨,计算其相对变化量:
∆zj*
=
∆
zj/z,进一步计算第j个指标的变化对xgboost模型输出值z变化的相对贡献率gj:gj=
∆zj*
/(
∆z1*
∆z2*
…
,
∆zj*
)
×
100%。
[0045]
步骤s24、基于评价指标的相对重要程度信息和相对贡献率,构建评价指标筛选的综合判别准则,基于所述综合判别准则对评价指标进行筛选。
[0046]
其中,构建评价指标筛选的综合判别准则的过程为,针对每一评价指标,逐一计算相对重要程度信息和相对贡献率的乘积,获得第一综合评价指标;接着计算第一综合评价指标的平均值,用各个评价指标与平均值作商,然后计算该商的十进对数值,逐一判断评价指标的十进对数值是否符合阈值。
[0047]
相对重要度和相对贡献率定量表征了各指标的相对重要性和敏感性信息,能够为决策者筛选指标提供参考依据。然而,在实际的指标筛选过程中,对于最终删除和保留哪些指标仍然存在较大的主观任意性和模糊不确定性。为了更加有效地结合相对重要度和相对贡献率信息进行指标筛选,定义能够同时兼顾两者大小的综合指标fj:fj=rj×gj
;式中,rj和gj分别为第j个指标的相对重要度和相对贡献率,其取值范围为[0, 1],上式采用乘积运算能够使fj具有较好的数值区分度。
[0048]
当第j个指标的相对重要度和相对贡献率rj、gj同时取较大值时,fj取值也较大;当第j个指标的相对重要度和相对贡献率rj、gj中一者较大而另一者较小时,fj取值适中;当第j个指标的相对重要度和相对贡献率rj、gj同时取较小值时,fj取值值较小。因此,可以根据各指标的fj取值大小确定指标删除的先后顺序,即fj越小的指标应该越先考虑删除。当某指标的fj取值比全体指标fj的均值小一个量级以上时,认为该指标的相对重要度和相对贡献率显著低于全体指标的平均水平,可以将该指标删除。为了定量描述这一判别过程,进一步定义综合判别指标pj:pj=lg(fj/ f
j’),式中:f
j’为全体指标fj的平均值。
[0049]
综合判别指标pj反映了综合指标fj的取值与f
j’在量级上的差异。若pj>0,表明该指标的fj的取值大于平均水平;若pj<0,表明该指标的fj的取值小于平均水平;特别地,当pj<﹣1时,表明该指标的fj的取值与f
j’相差一个量级以上,显著地低于平均水平,可以将其删除。因此,本技术将pj≤﹣1作为指标筛选的阈值,将指标筛选从主观分析判断过程转变为定量计算过程。
[0050]
申请人发现,现有的vikor模型在计算的过程中,使用的权重是专家设计的相对固定和主观的。权重值的不同,直接影响后续的输出结果,导致初始水权的分配不够客观和准确,为此提供了如下的解决方案。
[0051]
如图5所示,在本技术的另一实施例中,所述步骤s3进一步为:步骤s31、构建备选方案的决策矩阵并进行标准化,得到标准化决策矩阵;步骤s32、采用smaa方法确定可行权重空间的分布,并基于其概率密度函数进行抽样,随机生成可行权重;步骤s33、构建vikor模型并计算得到各个备选方案的排名;步骤s34、存储计算过程中得到备选方案的排名,计算排序可接受性指标、全局可接受性指标和中心权重向量;得出各个省级行政区的初始水权分配比例。
[0052]
在这个实施例中,通过smaa随机生成权重,然后不断重复调用vikor模型进行计算,给出备选方案的排名。克服了现有技术需要通过专家打分给定权重值,导致权重和结果的主观性较强的问题。
[0053]
在进一步的实施例中,对步骤s32进行详细描述。
[0054]
对于m个初始水权分配方案a={am丨m=1,2,
…
,m}和n个属性c={cn丨n=1,2,
…
,n},am表示第m个方案,cn表示第n个属性;属性的权重可以表示为wn。w={wn=丨n=1,2,
…
,n}。0≤wn≤1 ,评价指标矩阵x=[x
mn
]m×n。初始水权分配的问题,属于随机多属性决策问题,其不确定来源于指标评价值和指标权重两个方面。一般地,指标评价值的不确定性来自于随机优化结果的不确定性。指标权重反映了指标自身的重要性程度和决策者主观偏好性两个方面的信息,这也是指标权重的不确定性来源。指标评价值和指标权重的不确定性均可以采用相应的概率密度函数来描述。因此,上式的指标评价值可以用服从概率密度函数f
x
(ζ)的随机变量ζ
mn
来描述。ζ
mn
为第m个方案第n个属性的指标评价值。
[0055]
由于在现有决策过程中,专家对各个指标信息可能不是完全掌握,在给权重时,不能给出合理的权重信息,本技术考虑指标权重值在指定区间服从任意类型的分布。
[0056]
已知指标评价的概率密度函数f
x
(ζ)和指标权重概率密度函数fw(w),进一步地,smaa-2通过下式线性效用函数对每个属性的效用值进行加权求和得到每个方案的综合效用um=u(xm,w),随后通过其加权值um计算各方案的优劣排序,并从中选出满足决策要求的均
衡方案,。
[0057]
式中,可以采用随机变量ζ
mn
代替常量x
mn
反应指标值的不确定性,则上式中的可以x
mn
变换为ζ
mn
。方案排名函数为rank(ζm,w)。
[0058]
式中,方案排名函数rank(ζm,w)取值范围为[1,m],ρ[true]和ρ[false]分别为1和0。
[0059]
进一步地,定义排名倾向权重w
mr
(ζ),对任意的w∈w
mr
(ζ),smaa-2将方案am获得排序为r(r=1,2,
…
,m)的空间定义为排名倾向权重w
mr
(ζ),具体如下式所示:w
mr
(ζ)={w∈w
mr
(ζ):rank(ζm,w)=r}。
[0060]
排名可接受度指标b
mr
,它是排名倾向权重的期望值,且是在属性值空间和权重向量空间上的一个二重积分,表示备选方案xm排名第r名的可接受度,也可以看作是备选方案xm排名第r名的概率:b
mr
=∫
x f(ζ)∫
wmr(ζ)fw
(w)dwdζ。
[0061]
全局可接受程度b
mh
,它是对备选方案am获得所有排序b
mr
的综合,从整体上描述了方案的总体可接受水平:式中,指标a
mh
的取值范围是[0,1],ar为二级权重,表示备选方案am的某个排序r对于指标a
mh
的贡献度,常见的二级权重有线性权重ar=(m-r)/(m-1),倒数权重ar=1/r和重心权重,其中权重r越小,相应的二级权重越大,表明越看重排名靠前时的可接受度。
[0062]
在进一步的实施例中,smaa-vikor初始水权分配的整体实现流程如下:(1)构建初始评价矩阵。根据待分配初始水权的流域计算该流域不同省区的水资源开发利用、经济社会、生态环境等指标值。假定需要决策的问题由m个省区a={am丨m=1,2,
…
,m}和n个指标c={cn丨n=1,2,
…
,n}构成,其中am表示第m个省区,cn表示第n个指标。则不同省区的初始评价矩阵为x=[x
mn
]m×n(x
mn
为第m个省区的第n个指标值,m为省区数量,n为指标数量)。
[0063]
(2)对初始评价矩阵进行标准化。由于决策过程中公平原则、高效原则以及可持续原则的指标涉及到水资源开发利用、经济社会等不同类型的指标,各个指标之间的量纲和数量级不一样,会导致不同指标数据没有可比性,使用向量标准化公式对决策矩阵x=[x
mn
]m×n进行标准化,得到不同省区标准化后的决策矩阵r=[r
mn
]m×n(r
mn
为第m个省区的第n个标准化后的指标值),(3)确定本次待划分初始水权的流域的正理想点r
=[r
1
,r
2
,
……
,r
n
]和负理想
点r-=[r
1-,r
2-,
……
,r
n-]。
[0064]
(4)计算备选方案m的群体效益sm和个体遗憾度rm;(5)计算备选方案m的综合效益qm,(6)对备选方案进行排序对备选方案i的群体效益si、个体遗憾度ri和综合效益qi进行排序,数值越小越优;条件一:可接受性优势q(a")-q(a')≥ dq,其中,方案a"是qi按升序排名第二的方案,且dq = 1/(m-1),m是方案数;条件二:决策可接受稳定性方案a'必须满足按群体效益体s或个体遗憾度r进行排序也是排序第一的方案;如果上述两个条件有一个不满足,则得到一个妥协解;如果不满足条件二,则方案a'和方案a"均为妥协解;如果不满足条件一,则方案的排序为a', a", am,其中方案am是q(a")-q(a')< dq确定最大化的m值。
[0065]
根据本技术的另一方面,提供一种跨省江河流域初始水权分配系统,包括:至少一个处理器;以及与至少一个所述处理器通信连接的存储器;其中,所述存储器存储有可被所述处理器执行的指令,所述指令用于被所述处理器执行以实现上述任一项实施例所述的跨省江河流域初始水权分配方法。在本实施例中,处理器和存储器等为现有技术,本领域的技术人员能够根据现有知识和本技术公开的内容实施本技术的技术方案,解决本技术提出的技术问题,并获得相应的技术效果。
[0066]
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。