1.本发明属于人工智能与能耗预测技术领域,尤其涉及一种基于权重邻域粗糙集快速约简的滚动时域能耗预测方法。
背景技术:
2.能耗预测是实现建筑能耗精细化管理,从而支撑建筑运行优化管理的基础,科学精准的能耗预测可使建筑节能评估工作得以顺利开展,从而达到节能减排目的,在商业与环保领域均具有重要意义。传统的能耗预测系统大多为黑箱系统,这些系统无法进行模块化观测与拆分,难以结合关联因素的内部影响关系进行预测,缺乏通用性与实时性。
3.粗糙集理论被视为机器学习、模式识别、知识发现等领域的强大数学分析工具。经典的pawlak粗糙集理论需要严格的等价关系,因此只能挖掘具有类别属性的信息系统中的知识。为了挖掘具有实值属性的信息系统中的知识,研究人员将邻域关系引入,形成邻域粗糙集模型。样本之间的相似性可以很好地用邻域关系来描述,并且邻域关系在具有实值属性的信息系统中易于计算并进行属性约简。然而,邻域粗糙集模型并没有考虑属性权重,在实际应用中,每个属性对学习任务的贡献可能并不同等重要。
4.另外,在深度学习进行能耗预测中,传统的预测方式为将完整的数据集随机划分为训练集与测试集,该做法忽略了在一年中由于时间变化导致的用能相关影响因素(如季节与天气)的变化,缺乏实时性。
技术实现要素:
5.鉴于上述问题,本发明的目的在于提供一种基于权重邻域粗糙集快速约简的滚动时域能耗预测方法,旨在解决现有能耗预测方法的预测时间和预测精度均不高的技术问题。
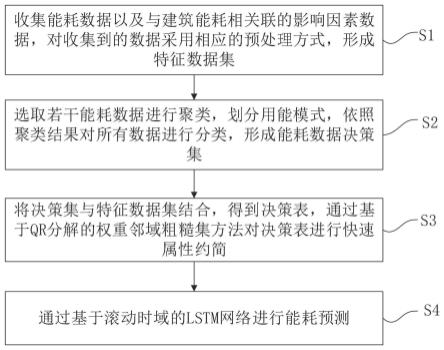
6.本发明采用如下技术方案:所述基于权重邻域粗糙集快速约简的滚动时域能耗预测方法,包括下述步骤:步骤s1、收集能耗数据以及与建筑能耗相关联的影响因素数据,对收集到的数据采用相应的预处理方式,形成特征数据集;步骤s2、选取若干能耗数据进行聚类,划分能耗模式,依照聚类结果对所有数据进行分类,形成能耗数据决策集;步骤s3、将决策集与特征数据集结合,得到决策表,通过基于qr分解的权重邻域粗糙集方法对决策表进行快速属性约简;步骤s4、通过基于滚动时域的lstm网络进行能耗预测。
7.本发明的有益效果是:本发明提供了一种基于权重邻域粗糙集快速属性约简的滚动时域能耗预测方法对建筑能耗进行预测,首先通过对不同样本数据依据其特征进行分类别处理,能够更好保留数据的属性特征;另外采取先聚类再分类的方法自动化生成决策集,避免人工分类方法存在的误判问题;第三通过给不同特征属性分配不同权重,形成基于权
重的邻域粗糙集模型,大大减少冗余属性对能耗预测的影响;第四,同时引入滚动时域的方法更新动态深度学习模型的架构和结构,能够捕捉建筑物能耗负荷的最新特征模式;本发明结合快速属性约简与滚动时域的能耗预测在预测时间上有所减少,在预测精度上有所提高,相对传统能耗预测方法具有更加丰富的应用价值,在预测时间与预测精度上都具有更好效果。
附图说明
8.图1是本发明实施例提供的基于权重邻域粗糙集快速约简的滚动时域能耗预测方法的流程图;图2是本发明实施例提供的步骤s3的一种具体实现流程图;图3是本发明实施例提供的以一年半数据为例的滚动时域训练集、测试集划分示意图;图4是本发明实施例提供的滚动时域能耗预测lstmn模型与预测时域表图。
具体实施方式
9.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
10.本发明提供了一种基于权重的邻域粗糙集约简的滚动时域能耗预测方法,用于快速精准预测建筑能耗,为建筑能耗精细化管理、建筑节能减排提供理论依据与数据支撑。为了说明本发明所述的技术方案,下面通过具体实施例来进行说明。
11.图1示出了本发明实施例提供的基于权重邻域粗糙集快速约简的滚动时域能耗预测方法的流程,为了便于说明仅示出了与本发明实施例相关的部分。
12.如图1所示,本实施例提供基于权重邻域粗糙集快速约简的滚动时域能耗预测方法包括下述步骤:步骤s1、收集能耗数据以及与建筑能耗相关联的影响因素数据,对收集到的数据采用相应的预处理方式,形成特征数据集。
13.能耗数据建筑运行过程中产生的各种能耗集合,建筑能耗相关联的影响因素数据影响建筑能耗的一些外界条件,比如天气、时间等等。本步骤通过对不同种类的数据采用符合其特征的预处理方式形成特征数据集。具体的,本步骤过程如下:s11、获取建筑能耗大数据集得到能耗数据,收集与建筑能耗相关联的影响因素数据,如天气信息等。
14.s12、将收集到的建筑能耗关联影响因素数据与能耗数据进行整合,对整合后的原始数据应用四种方法进行预处理,以某实际工程为例,具体预处理方式有:(1)对于气温t,云层覆盖率ξ,露点温度t
dew
,风速ws,能耗值e,进行线性归一化处理,t标记为α1,ξ标记为α2,t
dew
标记为α3,ws标记为α4,e标记为α5,变量αi与线性归一化处理变换后的α’i
满足:。
15.(2)对于风向wd,以45
°
为一个计量区间,则风向可用8个数字表示:。
16.(3)对于时间变量,包括周几、月、日、是否为节假日,采用onehot编码进行标准化处理,用2位编码表示是否为节假日;用7位编码表示周几,如0000001表示周一、用0000010表示周二等;用12位的二进制数如000000000001表示一月、000000000010表示二月等;同理用31位的编码表示不同的日。
17.(4)对于小时数据,将小时转换为对应的sin与cos值作为输入:,通过上述处理方式,最后得到输入的特征数据集包括天气数据(气温,云层覆盖率,露点温度,风向,风速等),天气数据(时间戳,周几,法定假日,月,日,小时等)和能耗数据能耗值。
18.特征数据集可表示为,m为经过预处理的属性数量,即上述的天气数据、天气数据、能耗数据能耗值的数据种类数量。q为选取特征对象数量,对于大小为q
×
m的特征属性矩阵z
q,m
,。以上述工程为例,属性数量有13个,,x
t
中包含的变量包括:时间戳ts:x
1,t = ts(t),气温t:x
2,t = t(t),云层覆盖率ξ:x
3,t = ξ(t),露点温度t
dew
:x
4,t = t
dew
(t),风向wd:x
5,t = wd(t),风速ws:x
6,t = ws(t),周几d
wd
:x
7,t = d
wd
(t),是否为法定假日d
hd
:x
8,t = d
hd
(t),年月数m:x
9,t = m(t),月天数d:x
10,t = d(t),小时正弦值hs:x
11,t = hs(t),小时余弦值hc:x
12,t = hc(t),能耗值e:x
13,t = e(t)。此时的特征属性矩阵为:其中q为选取特征对象数量,,。
19.步骤s2、选取若干能耗数据进行聚类,划分能耗模式,依照聚类结果对所有数据进行分类,形成能耗数据决策集。
20.本步骤具体过程如下:s21、按照需要对每个设备能耗数据进行抽样。
21.按一定规律对各设备的能耗数据抽样千级或万级样本。
22.s22、利用基于轮廓系数的k-means聚类划分小样本能耗模式。
23.指定聚类簇数k,k∈[2,t],t为结合实际能耗情况能接受最大类别数的值,t过小
会导致聚类结果不准确,t过大则导致后续分析复杂度增加。对不同的k,从特征属性矩阵z
q,m
中取出e行数据(k≤e<n)得到小样本特征属性矩阵;然后进行k-means聚类,得到e行包含k个能耗模式的特征数据m k
,,将m k
与结合得到具有能耗模式特征的小样本特征集;对于不同的k,分别计算对应的轮廓系数,其中d
out
(β)为样本β到同一类中其他样本的平均距离,d
in
(β)为样本β到其他类别所有样本的平均距离,所以,要取类内相似度高,类外相似度低的样本组成一类,即在可接受聚类数k范围内,对应的l(β)越大,聚类效果越好。取lk(β)最大时对应的聚类簇数k与对应的小样本特征集。
[0024]
s23、通过svm算法得到能耗模式,形成决策集d。
[0025]
利用小样本特征集对剩余行的特征运用svm分类算法,得出完整的包含能耗模式的决策集d,该步骤的具体过程为首先利用小样本特征集训练svm分类器,然后使用训练好的分类器对整体特征数据集进行分类预测。svm分类算法为行业通用技术,不再赘述其算法原理。
[0026]
步骤s3、将决策集与特征数据集结合,得到决策表,通过基于qr分解的权重邻域粗糙集方法对决策表进行快速属性约简。
[0027]
如图2所示,具体实现过程如下:s31、根据所述决策集、特征数据集建立决策表,其中u为论域,at为属性特征集,在上述工程实例中,at = z
q,13
,d={d}为决策集,
∀
x∈u,
∀
ε∈at,f(x,ε)为样本x相对于特征属性ε的值,设特征系数矩阵为g,决策向量矩阵为h。
[0028]
有有。
[0029]
s32、建立约简矩阵re并计算特征分配系数υ:约减矩阵为re,使,设特征分配系数矩阵;由,同时左乘转置矩阵g
t
,得;由于υ的计算涉及到矩阵求逆运算,在特征分配系数矩阵过大的情况下存在计算时间过长的情况,结合实际情况,对矩阵g
t
g采用qr分解方法求逆,计算复杂度,进行快速约
简。
[0030]
对于非稀疏对称矩阵g
t
g,经过householder变换后,转化为正交矩阵q与上三角矩阵r的乘积即,因此,得到。
[0031]
s33、计算每个特征属性ε的权重;其中为的绝对值,越大,特征与决策内部关联度越大。
[0032]
s34、计算加权邻域相似关系:b为at的一个特征子集,,邻域半径阈值为δ,对每一个b,有。
[0033]
s35、计算决策集d对相似关系的依赖度。
[0034]
依赖度可以表示条件与决策的关系程度,因为依赖度表示包含于正区域的特征与论域特征的比例。当时,设,为d关于b在邻域粗糙集下的正区域;,为d对应相似关系的下近似。
[0035]
s36、对于每个处于特征子集外部的特征属性ε,计算在d决策下外部特征属性ε对约简集re的外部重要度:,当时停止计算。当外部重要度取最大值时,将对应的外部特征加入约简集re;s37、对于每个在约简集内部的特征属性μ,计算特征属性μ对约简集re的内部重要度:其中,μ为约简集re的内部特征属性,,当时,从re移除非必要内部特征,得到约简集re。
[0036]
步骤s4、通过基于滚动时域的lstm网络进行能耗预测。
[0037]
本步骤具体过程如下:s41、将属性约简过后的约简集以年为时域间隔mton、月为间隔移动步长划分训练集与测试集,时域间隔数量为n,具体的,对每个时域间隔mton,划分为m个训练集与m-1个测试集,且将接下来一个月的数据作为预测集。若以1个月为间隔移动步长,为数据集总月数,则有:。
[0038]
如图3所示,时域间隔可表示为:
其中 tr
ni
,te
nj
分别为第n个时域间隔的第i个训练集与第j个测试集,为了保证训练精度,需要满足以下条件:例如,图4为从2021年一月至2022年七月共18个月数据的滚动时域划分图。
[0039]
s42、将n个时域间隔mton分别输入lstm网络训练,得到n个lstm模型,记为,并分别用lstmn模型预测接下来的每个月能耗。以2021年一月至2022年六月数据集为例,预测方式如图4所示。lstm1模型预测二月到七月的能耗,lstm2模型预测三月到七月的能耗,依次类推,lstm6模型预测七月能耗。
[0040]
s43、将各模型预测值与实际数据进行对比,并分别计算每个模型在不同预测时域所对应的均方根误差rmse、平均绝对误差mae和r2值,并从中选取最优预测结果。
[0041]
综上,本发明提供了一种基于权重的邻域粗糙集约简的滚动时域能耗预测方法,给不同特征属性分配不同权重,形成基于权重的邻域粗糙集模型,大大减少冗余属性对能耗预测的影响;引入滚动时域的方法更新动态深度学习模型的架构和结构,能够捕捉建筑物能耗负荷的最新特征模式,提高建筑能耗预测准确度。相对传统能耗预测方法具有更加丰富的应用价值,在预测时间与预测精度上都具有更好效果。
[0042]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
