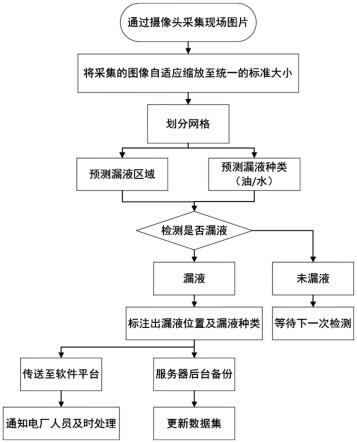
1.本发明涉及室内场景理解技术领域,尤其涉及一种面向室内鱼眼图像的场景结构深度估计方法。
背景技术:
2.单幅rgb图像的深度估计作为视觉研究的基础任务,广泛应用于机器人室内导航、三维地图重建和三维场景理解等视觉任务中。室内场景的深度估计是从深度图中估计出室内物体到拍摄相机间的距离,确定物体的三维空间位置,其中包括床、桌和凳等可移动物体和地面、墙面、天花板等固定不可移动结构。基于单幅rgb透视图像的室内场景深度估计已经取得了显著的进步,采用的方法大致分为两类,一类是传统的机器学习算法包括马尔科夫随机场mrfs、条件随机场crfs等。另一类为主流的深度学习算法通过卷积神经网络学习图像逐像素与对应深度值间的映射关系,包括fcrn、omnidepth、ldpn、bifuse等网络模型。为捕获更多的场景的信息,出现了越来越多的便携式和消费型鱼眼相机,与此同时鱼眼图像深度估计的研究也备受关注。
3.从全方向图像中提取深度信息与透视图的深度估计类似,但是全方向图像中存在的畸变问题使得难以直接使用透视图的深度估计方法。最初的解决措施是将全方向图像进行切分,将透视图深度估计方法迁移到切分小图来估计其深度值,将透视深度图合成获得相应的全方向深度图。但是该类方法仍未充分利用全局的上下文信息且耗时低效。为了平衡全方向中的畸变和视场角,研究人员考虑投影融合的方式,将全方向图像的全向投影图和立体投影图联合训练,解决深度估计中的畸变问题,但是该类方法训练设置较多,训练难度大且时间成本都较高。
技术实现要素:
4.本发明的技术解决问题:克服鱼眼图像存在一定畸变以及现有方法深度估计不准确,提出一种面向室内鱼眼图像的场景结构深度估计方法,针对现有面向鱼眼图像存在几何畸变、深度估计模型精度较低、物体边缘处深度估计模糊的问题,通过鱼眼畸变卷积模块学习鱼眼图像中的畸变特征,设计基于残差思想的网络模块,增加了网络模型的复杂度,同时设计了基于梯度的目标损失函数,优化边缘处的深度估计效果,提高了鱼眼图像的深度估计精度。
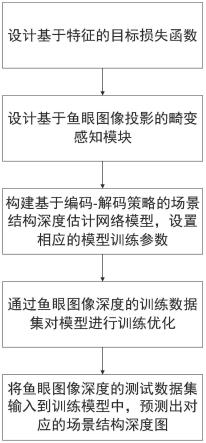
5.本发明的技术解决方案如下:一种面向室内鱼眼图像的场景结构深度估计方法,包括以下内容:
6.(1)构建基于编码-解码策略的场景结构深度估计网络模型,设置所述网络模型的训练参数;在编码器中采用鱼眼畸变卷积模块,利用可变形卷积学习鱼眼图像中的几何畸变信息,对鱼眼图像进行局部卷积操作,提高鱼眼图像中特征信息的提取准确率;在解码器中采用向上映射层模块加深所述网络结构深度;同时在编码器解码器之间添加跳跃连接,提高所述网络模型的场景结构深度估计准确度;并在所述网络模型训练过程中采用基于图
像特征的目标损失函数;
7.(2)通过鱼眼图像深度的训练数据集对场景结构深度估计网络模型进行训练优化;
8.(3)将鱼眼图像深度的测试数据集输入到训练场景结构深度估计网络模型中,预测出输入鱼眼图像的场景结构深度。
9.进一步,所述步骤(1)中,基于图像特征的目标损失函数l如下:
10.l=ω1l
depth
ω2l
grad
ω3l
normal
11.l
depth
为根据图像中物体远近的特性设计的深度损失项,计算公式如下:
[0012][0013]
其中,n为样本数,di表示预测的结构深度值,gi为真实的结构深度值,α为可调节参数,经验值设置为0.5;i表示像素个数;
[0014]
l
grad
为根据图像中边缘梯度结构特点设计的梯度损失项,计算公式为:
[0015][0016]
其中,和为向量表示的边缘梯度大小,分别表示深度误差在(x,y)方向的偏导;x为水平梯度,y为垂直深度;
[0017]
l
normal
为根据图像中物体形状特征设计的法向量损失项l
normal
,它利用表面法向量的约束提升场景结构深度图在全局和局部细节上的估计精度,计算公式为:
[0018][0019]
其中,分别表示在预测的结构深度图和真实的结构深度图中计算得到的法向量,表示预测法向量和真实法向量的内积操作;
[0020]
ω1、ω2和ω3分别为三个损失项对应的权重系数。本发明取值三个权重系数均为1,表示每一项都同等重。
[0021]
进一步,所述步骤(1)中,构建基于编码-解码策略的场景结构深度估计网络模型中,编码器以resnet-50作为主干网络提取输入鱼眼图像的语义特征,学习图像像素点之间的依赖关系,输出包含低维语义信息和高维语义信息的特征图;所述resnet-50中第三个至第五个瓶颈块采用鱼眼畸变卷积模块,增强场景结构深度估计模型对鱼眼图像畸变的学习能力;所述鱼眼畸变卷积模块采用鱼眼图像投影模型设计。
[0022]
进一步,所述步骤(1)中,构建基于编码-解码策略的场景结构深度估计网络模型中,解码器的实现为:
[0023]
以编码器得到的特征图为输入,基于向上映射层模块构建对特征解码;解码器中包含四个向上映射层模块,负责增大特征图的分辨率并实现对语义特征的解码,通过有监督的端到端的学习方式,将学习到的分布式特征表示映射到样本标记空间,输出预测的结构深度图;所述每个向上映射层模块采用残差结构设计。
[0024]
本发明与现有技术相比的优点在于:
[0025]
(1)为了解决现有鱼眼图像超大几何畸变、场景结构深度估计模型存在的物体边缘深度模糊、深度估计效果差的问题,本发明基于鱼眼畸变卷积模块,进行鱼眼全方向的特性信息采集,减弱畸变的干扰。此外本发明基于残差思想设计了一个向上映射层模块,使用该模块构建了网络层次更深、精度更高的结构深度估计网络;同时提出一个基于梯度的目标损失函数,使用该目标损失函数端到端的训练深度网络,实现了对鱼眼图像更好的深度估计效果。
[0026]
(2)损失函数的设计在神经网络的训练过程中起着重要的作用。深度估计属于机器学习中的回归任务,目前回归任务中常用的损失函数包括均方误差和绝对值损失函数。其中绝对值损失函数不满足连续可导的条件,而均方损失函数对异常点敏感,可能会对训练造成影响。所以本发明采用基于图像特征的损失函数指导网络的训练,能够更好的估计物体边缘处的深度信息,通过端到端的有监督学习方式,提高了深度估计网络的精度。
[0027]
(3)常规卷积核采样点的分布是固定不变的,一个卷积核只能在输入特征图的固定位置上进行采样,感受野始终是矩形形状,这导致卷积神经网络对几何变换建模的能力较差。本发明处理的鱼眼图像中存在形态、尺寸不一的物体,且鱼眼相机非线性的正交投影模型使得图像中存在严重的畸变,本发明提出鱼眼畸变卷积模块采用鱼眼图像投影模型设计,提升深层神经网络的几何变换建模能力。
[0028]
(4)面向鱼眼图像的场景结构深度估计方法研究较少,由于鱼眼图像大视角、存在畸变的特点,现有深度估计网络在鱼眼数据集上的精度较差,因此本发明设计了一个面向鱼眼图像的结构深度估计网络。该网络整体遵循编码器-解码器策略,以鱼眼图像和对应的掩码图像作为网络的输入,通过编码器提取图像特征,学习图像像素点之间的依赖关系,输出包含低维语义信息和高维语义信息的特征图。以特征图为输入,基于向上映射层模块构建的解码器对特征解码,以有监督的端到端的学习方式,将学习到的分布式特征表示映射到样本标记空间,输出预测的深度图。为了充分利用不同尺度的特征图,在编码器和解码器之间引入了跳跃连接结构,进一步提升了深度估计的精度。
附图说明
[0029]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0030]
图1为本发明的面向室内鱼眼图像的场景结构深度估计的总体流程示意图;
[0031]
图2为本发明的向上映射层模块示意图;
[0032]
图3为本发明的端到端神经网络架构图;
[0033]
图4为本发明的网络输入与预测示意图,(a)为网络输入rgb鱼眼图像,(b)为网络输入对应的掩码图,(c)为网络预测出的结果深度图;
具体实施方式
[0034]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
[0035]
如图1所示,本发明方法实现如下:
[0036]
1.设计基于特征的目标损失函数
[0037]
a)根据图像中不同特征对应的损失项设计目标损失函数,主要包括深度损失项、梯度损失项和法向量损失项。
[0038]
b)实际场景图像中最常见的是物体远近不同的特性,若忽略这一特征直接使用同样权重的深度误差值计算深度损失项l
depth
会导致深度估计结果中出现模糊的现象,设计的深度损失项为:
[0039][0040]
c)实际场景图像中除了距离差异的特征,呈现最多的特征为边缘多阶梯的结构特点。上述深度损失项仅对深度变换方向进行平衡,难以处理深度方向的出现的不同偏移情况。为了进一步的优化边缘处不同梯度的深度信息,设计的梯度损失项为:
[0041][0042]
d)深度图作为场景三维模型的一种形式,可表示为有限数量的光滑表面和表面间的阶梯边缘。虽然上述提及的梯度损失能够对边缘不同深度进行优化,但是对于场景中形状上的特征难以进行有效的处理,比如常见的陡峭的边、角和平面结构等主要形状特征。而法向量能够对物体表面的角度信息进行编码,可以对平面特征采用统一的法向量进行全局约束,同时也可以采用其中的角度信息有效的对局部结构特征进行约束,设计的法向量损失项为:
[0043][0044]
e)综上损失项,进行全方向图像结构深度估计的目标损失函数具体定义为:
[0045]
l=ω1l
depth
ω2l
grad
ω3l
normal
[0046]
通过构建的基于图像特征的目标损失函数优化深度估计网络的参数,得到更精确的深度预测结果。
[0047]
2.设计鱼眼畸变卷积模块
[0048]
a)首先是定义一个规则的网络r,用来对输入特征图f
l
进行规则采样,其中网格区域r由卷积核大小和膨胀决定。设定r={(-1,-1),(-1,0),....,(0,1),(1,1)}表示感受野的大小为3
×
3以及膨胀为1。通过加权运算计算出遍历过程中不同位置对应到输出特征图f
l 1
的位置,输出映射关系为:
[0049][0050]
其中,f
l 1
(p0)表示输出特征图中点p0的值,通过求和f
l
中采样值与权重ω间的乘
积计算。f
l
(p0 pn)表示输入特征图中p0 pn个像素,pn是在网格r以f
l
(p0)为中心向外扩散得到的n个采样点,其中网格r的(-1,-1)表示f
l
(p0)的左上角,(1,1)表示f
l
(p0)的右下角。通过上述的计算过程可知,cnn中的标准卷积采样始终是固定不变的,每个采样点的感受野也是固有的矩形结构,难以灵活的处理高层语义信息,这也导致了采用标准卷积的卷积神经网络具有较差的几何变化建模能力。
[0051]
b)本发明在标准卷积基础上,通过预处理提取鱼眼图像中的有效区域以保持上下文的一致性,从鱼眼图像中采样相应的非规则网格,并根据鱼眼畸变投影模型计算原网格畸变像素的位置。
[0052]
c)本发明将设计的鱼眼畸变卷积模块引入到网络结构的编码器中,如图3所示,学习不同位置与不同程度的畸变信息,提取出具有区别性的特征。
[0053]
本发明的鱼眼畸变卷积模块,具体实现如下:
[0054]
(1)计算鱼眼畸变卷积时,通过预处理提取鱼眼图像中的有效区域以保持上下文的一致性,从鱼眼图像中采样相应的非规则网格,并根据原网格计算畸变像素的位置为:
[0055][0056]
其中,为通过鱼眼畸变投影模型计算得到的pn相应的偏移量。p0=(u(p0),v(p0))表示在f
l 1
中的像素位置。
[0057]
(2)为计算偏移量,计算p0在球坐标系中的经纬度坐标为:
[0058][0059][0060]
其中,w为图像宽度,u和v分别表示像素点位置的横坐标值和纵坐标值。
[0061]
(3)采用欧拉-罗德里格斯旋转方程计算旋转矩阵t为:
[0062][0063]
其中,表示先将卷积核围绕x轴逆时针旋转角度ry(θ(p0))围绕y轴逆时针旋转角度θ(p0)。
[0064]
(4)通过旋转矩阵t将卷积核上的任一点pn旋转为:
[0065][0066]
其中,pn=[i,j,d],i,j∈[-kw/2,-kh/2],kw和kh为卷积核的分辨率。
[0067]
(5)d为r到单位球中心的距离,根据视场和卷积核大小计算为:
[0068][0069]
(6)之后将旋转后卷积核的三维空间映射到对应的经纬度坐标为:
[0070][0071][0072]
(7)变换后的经纬度坐标投影到鱼眼图像中对应的像素坐标为:
[0073][0074][0075]
(8)求得偏移量其中u(δp’n
),v(δp’n
)分别为:
[0076]
u(δp’n
)=u(p’n
)-u(pn)
[0077]
v(δp’n
)=v(p’n
)-v(pn)
[0078]
3.构建基于编码-解码策略的场景结构深度估计网络模型
[0079]
(1)采用编码-解码的策略设计有效的鱼眼图像结构深度估计网络,整体网络结构如图3所示。
[0080]
(2)整体网络结构的输入包括两部分,以鱼眼图像和对应的掩码图像作为网络的输入,分别如图4中的(a)和(b)所示。其中掩码图中作为位图,将可移动物体对应的所有像素值设置为0,以黑色呈现,其他结构区域像素值设置为255,以白色呈现。在添加掩码图引导结构深度估计时,采用了两种不同方法,分别将其与rgb图像叉乘后输入到编码结构或将其直接连接到解码结构。通过设计的编解码结构估计出移除可变动物体的场景结构深度图。
[0081]
(3)在编码器中的主干网络仍然选择去除全连接层的resnet50,引入鱼眼畸变卷积模块到resnet50最后的卷积层中,解决全方向中几何畸变导致低效特征学习的问题,学习图像像素点之间的依赖关系,输出包含低维语义信息和高维语义信息的特征图,提高结构深度估计中对几何变换的建模能力。
[0082]
(4)解码器由四个向上映射模块和一个3
×
3卷积层组成,主要是为了能够恢复特征图分辨率到原始图像大小并对编码中获得的语义特征进行解码,其中采用双线性插值的方法进行上采样以增加特征图的分辨率。在此基础上,设计了基于残差结构的向上映射层模块,如图2所示,进一步增加网络结构深度,避免梯度消失和过拟合问题,提高模型的学习能力。
[0083]
如图2所示,基于残差结构设计的向上映射层模块,包含:
[0084]
(a)该模块输入特征图的分辨率为h
×
w,其中h为特征图的高,w为特征图的宽;
[0085]
(b)使用双线性插值的方式进行上采样操作,将特征图的分辨率扩大至原来的两倍,避免扩大后特征图的灰度值不连续导致存在锯齿状现象;
[0086]
(c)上下两个分支中各自采用了5
×
5的卷积层进行平滑处理;
[0087]
(d)然后上层分支使用一个3
×
3的卷积层处理特征信息,将两个分支的输出特征图相加,通过relu激活后作为向上映射层模块的输出。
[0088]
(5)为了能够充分利用不同尺度特征图中的全向语义信息,将编码器和解码器中的多尺度特征进行跳跃连接融合,更进一步的提升网络估计结构深度的精度,以有监督的端到端的学习方式,将学习到的分布式特征表示映射到样本标记空间,输出预测的深度图,
如图4中的(c)所示。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。