1.本技术涉及数字人技术领域,尤其涉及一种基于不同中之人驱动数字人的方法及系统。
背景技术:
2.随着互联网的不断发展,网络直播技术也得到了飞速提升,而随着技术的发展,当前已经出现了虚拟数字人的直播表演。而在虚拟数字人的操控中会出现不同的中之人,中之人主要指操纵vtuber(虚拟主播)进行直播的演员。
3.众所周知,当前的数字人演出需要中之人进行动捕驱动,然而由于中之人的档期限制,无法实现每次都是同一个中之人。不同的中之人的脸型、身材各不相同,所以每次演出之前需要针对此数字人进行参数调整,这就是面部参数预设值。然而在官方工具没有提供参数预设功能,所以需要用户在ue蓝图中针对不同的中之人进行修改,操作繁琐,且捕捉驱动品质欠佳。
4.因此,如何针对不同的中之人完成动捕,并驱动数字人,实现较好的画面效果,以及提高驱动效率是目前亟需解决的技术问题。
技术实现要素:
5.本技术的目的在于提供一种基于不同中之人驱动数字人的方法及系统,实现对不同的中之人完成动捕,并驱动数字人,实现较好的画面效果,以及提高驱动效率。
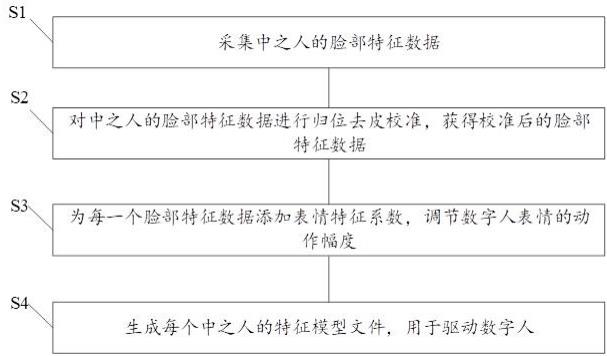
6.为达到上述目的,本技术提供一种基于不同中之人驱动数字人的方法,该方法包括如下步骤:采集中之人的脸部特征数据;对中之人的脸部特征数据进行归位去皮校准,获得校准后的脸部特征数据;为每一个脸部特征数据添加表情特征系数,调节数字人每个表情的动作幅度;生成每个中之人的特征模型文件,用于驱动数字人。
7.如上所述的基于不同中之人驱动数字人的方法,其中,脸部特征数据包括眉毛特征值、眼睛特征值、脸颊特征值、鼻子特征值、下巴特征值和嘴巴特征值。
8.如上所述的基于不同中之人驱动数字人的方法,其中,对中之人的脸部特征数据进行归位去皮校准,获得校准后的脸部特征数据的方法包括:预先采集中之人面部放松状态下的基础脸部特征数据;将当前采集到的中之人的脸部特征数据减去基础脸部特征数据,作为校准后的脸部特征数据。
9.如上所述的基于不同中之人驱动数字人的方法,其中,为每一个脸部特征数据添加表情特征系数,调节数字人表情的动作幅度的方法包括:使用校准后的脸部特征数据驱动数字人展示可视化画面;基于可视化画面,为每一个脸部特征数据添加表情特征系数,获得调节后的特征值;使用调节后的特征值,驱动数字人。
10.如上所述的基于不同中之人驱动数字人的方法,其中,为每一个脸部特征数据添加表情特征系数,获得调节后的特征值的方法为:将校准后的脸部特征数据中的每个特征值乘以表情特征系数,获得调节后的特征值。
11.如上所述的基于不同中之人驱动数字人的方法,其中,生成每个中之人的特征模型文件的方法包括:基于添加表情特征系数后的脸部特征数据,生成每个中之人的特征模型文件,并将特征模型文件存档到数据库中。
12.如上所述的基于不同中之人驱动数字人的方法,其中,根据中之人的类别,从数据库中读取该中之人对应的特征模型文件,使用读取的特征模型文件来驱动数字人。
13.如上所述的基于不同中之人驱动数字人的方法,其中,通过面部工具实时驱动数字人。
14.本技术还提供一种基于不同中之人驱动数字人的系统,该系统包括:数据采集模块,用于采集中之人的脸部特征数据;校准模块,用于对中之人的脸部特征数据进行归位去皮校准,获得校准后的脸部特征数据;调节模块,用于为每一个脸部特征数据添加表情特征系数,调节数字人每个表情的动作幅度;生成模块,用于生成每个中之人的特征模型文件,用于驱动数字人。
15.如上所述的基于不同中之人驱动数字人的系统,其中,该系统还包括:调用模块,用于根据中之人的类型,调用该中之人对应的特征模型文件;驱动模块,用于根据调用的特征模型文件,驱动数字人。
16.本技术实现的有益效果如下:(1)本技术根据不同的中之人具有不同的数据模型,并且生成每个中之人的特征模型文件,用来驱动数字人,使得后续不同的中之人驱动数字人时,直接调用对应的特征模型文件即可达到驱动数字人的最佳效果。
17.(2)本技术调节每个特征表情的动作幅度,从而解决不同的中之人驱动数字人能达到相同的最佳效果,此外调节后的表情特征系数配置还可存档,以便后续不同的中之人无需二次调节即可直接使用,提高数字人驱动效率。
附图说明
18.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域技术人员来讲,还可以根据这些附图获得其他的附图。
19.图1为本技术实施例的一种基于不同中之人驱动数字人的方法流程图。
20.图2为本技术实施例的归位去皮校准的方法流程图。
21.图3为本技术实施例的调节数字人表情的动作幅度的方法流程图。
22.图4为本技术实施例的一种基于不同中之人驱动数字人的系统的结构示意图。
23.附图标记:10-数据采集模块;20-校准模块;30-调节模块;40-生成模块;50-调用模块;60-驱动模块;100-基于不同中之人驱动数字人的系统。
具体实施方式
24.下面结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都
属于本技术保护的范围。
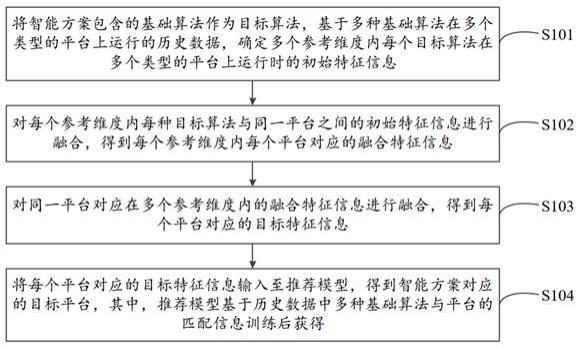
25.实施例一如图1所示,本技术提供一种基于不同中之人驱动数字人的方法,该方法包括如下步骤:步骤s1,采集中之人的脸部特征数据。
26.其中,脸部特征数据为中之人的面部表情数据,脸部特征数据包括眉毛特征值、眼睛特征值、脸颊特征值、鼻子特征值、下巴特征值和嘴巴特征值等。
27.具体的,通过faceid深度传感器实时采集中之人的脸部特征数据。优选的,以每秒60帧的标准实时采集中之人的脸部特征数据,每一帧采集中之人一个状态的表情数据。优选地,每一帧采集中之人的52个面部表情数据。
28.步骤s2,对中之人的脸部特征数据进行归位去皮校准,获得校准后的脸部特征数据。
29.如图2所示,步骤s2包括如下子步骤:步骤s210,预先采集中之人面部放松状态下的基础脸部特征数据。
30.具体的,中之人面部保持放松状态下,采集中之人的基础脸部特征数据,作为校准前的一帧面部表情特征数据,并记录该数据。随后实时采集的每一帧数据都减去校准前的这一帧数据,实现归位去皮校准。
31.作为本发明的一个具体实施例,基础脸部特征数据包括52个面部表情特征数据,例如包括眉毛特征值、眼睛特征值、脸颊特征值、鼻子特征值、下巴特征值和嘴巴特征值等。
32.步骤s220,将当前采集到的中之人的脸部特征数据减去基础脸部特征数据,作为校准后的脸部特征数据。
33.步骤s3,为每一个脸部特征数据添加表情特征系数,调节数字人表情的动作幅度。
34.具体的,为每一个脸部特征数据添加表情特征系数,调节数字人每个表情的动作幅度。
35.如图3所示,步骤s3包括如下子步骤:步骤s310,使用校准后的脸部特征数据驱动数字人展示可视化画面。
36.具体的,根据校准后的脸部特征数据展示基础可视化画面,用于基于此可视化画面调节每个表情的表情特征系数,进而调节可视化画面中每个表情的动作幅度,使得调节后的表情特征数据驱动数字人达到想要的效果。
37.步骤s320,基于可视化画面,为每一个脸部特征数据添加表情特征系数,获得调节后的特征值。
38.具体的,为每一个脸部特征数据添加表情特征系数,获得调节后的特征值的方法为:将校准后的脸部特征数据中的每个特征值乘以表情特征系数,获得调节后的特征值。基于可视化画面,调节表情特征系数的大小,使得数字人的表情的动作幅度达到想要的状态。
39.由于不同的中之人采集面部特征时,面部表情的张和幅度不一致,所以不同中之人驱动数字人后的效果不是很理想,没办法使得不同中之人驱动数字人达到很好的一致性效果,因此,需要调节每个脸部特征数据的表情特征系数,也即张和系数,以使得不同中之人能够驱动数字人达到相同的最佳效果。
40.作为本发明的具体实施例,对不同中之人调节后的特征值配置数据(例如:表情特
征系数)进行存档,以便后续不同的中之人无需二次调节即可使用。
41.步骤s330,使用调节后的特征值,驱动数字人。使得不同类型的表情特征数据都能驱动数字人达到最佳效果。
42.作为本发明的一个具体实施例,在系数为1.0倍数下,嘴巴张大后jawopen(张开下颚)的极限值为42%,即没有调整系数前嘴巴张大后jawopen(张开下颚)的极限值无法到达100%,达不到驱动数字人此表情的最佳效果。在调节表情特征系数到 1.9 后,将jawopen的极限值做到100%,可以达到数字人张嘴的最佳效果,其余部分系数参数设置同理。
43.步骤s4,生成每个中之人的特征模型文件,用于驱动数字人。
44.具体的,基于添加表情特征系数后的脸部特征数据,生成每个中之人的特征模型文件,将特征模型文件存档到数据库中。不同的中之人具有不同的数据模型,通过读取调用中之人的特征模型文件来驱动数字人,保证后续不同的中之人驱动数字人都能达到数字人的最佳效果。
45.作为本发明的具体实施例,根据中之人的类别,从数据库中读取该中之人对应的特征模型文件,直接使用读取的特征模型文件来驱动数字人,无需进行二次调节表情特征系数,提高中之人对数字人的驱动效率。
46.作为本发明的具体实施例,通过面部工具实时驱动数字人,并提供参数预设生成模型存档和读档的功能,设定较高的捕捉品质要求,提供校准和面部表情修正功能,能轻松针对不同的中之人完成动捕,以驱动数字人,实现较好的画面效果。
47.作为本发明的具体实施例,根据调用的当前中之人的特征模型文件,获取特征模型文件中的表情特征系数,将采集到的当前中之人的脸部特征数据乘以获取的表情特征系数,获得调节后的特征值,基于调节后的特征值驱动数字人,使得数字人展示的表情效果更好,不同中之人通过为脸部特征数据添加表情特征系数后可以驱动数字人展示相同的表情效果。
48.实施例二如图4所示,本技术提供一种基于不同中之人驱动数字人的系统100,该系统包括:数据采集模块10,用于采集中之人的脸部特征数据。具体的,数据采集模块为深度传感器,用于实时采集中之人的眉毛特征值、眼睛特征值、脸颊特征值、鼻子特征值、下巴特征值和嘴巴特征值等。
49.校准模块20,用于对中之人的脸部特征数据进行归位去皮校准,获得校准后的脸部特征数据。校准模块20采集中之人的基础脸部特征数据,作为校准前的一帧面部表情特征数据,并记录该数据。随后实时采集的每一帧数据都减去校准前的这一帧数据,实现归位去皮校准。
50.调节模块30,用于为每一个脸部特征数据添加表情特征系数,调节数字人每个表情的动作幅度。调节模块30根据数字人每个表情的动作幅度调节表情特征系数的大小,使得数字人每个表情达到想要的动作幅度,记录使数字人每个表情达到想要的动作幅度时的表情特征系数,将该表情特征系数存档后,用于后续直接调用来调节脸部特征数据的值。
51.生成模块40,用于生成每个中之人的特征模型文件,用于驱动数字人。生成模块40为每个中之人生成数据模型,在该数据模型的基础上,将调节后的表情特征系数关联到该数据模块中的脸部特征数据中,用于后续直接调用该表情特征系数,对采集的脸部特征数
据乘以该调节后的表情特征系数获得调节后的特征值。
52.调用模块50,用于根据中之人的类型,调用该中之人对应的特征模型文件。
53.驱动模块60,用于根据调用的特征模型文件,驱动数字人。驱动模块60包括面部工具,通过面部工具实时驱动数字人展示画面效果。
54.具体的,根据调用的当前中之人的特征模型文件,获取特征模型文件中的表情特征系数,将采集到的当前中之人的脸部特征数据乘以获取的表情特征系数,获得调节后的特征值,基于调节后的特征值驱动数字人,使得数字人展示的表情效果更好。
55.本技术实现的有益效果如下:(1)本技术根据不同的中之人具有不同的数据模型,并且生成每个中之人的特征模型文件,用来驱动数字人,使得后续不同的中之人驱动数字人时,直接调用对应的特征模型文件即可达到驱动数字人的最佳效果。
56.(2)本技术调节每个特征表情的动作幅度,从而解决不同的中之人驱动数字人能达到相同的最佳效果,此外调节后的表情特征系数配置还可存档,以便后续不同的中之人无需二次调节即可直接使用,提高数字人驱动效率。
57.以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理内所做的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。