1.本发明涉及地面雨量站网布局优化方法技术领域,特别涉及无资料地区山洪小流域地面雨量站网布局优化方法
背景技术:
2.我国地处东亚季风区,暴雨频发,加之地质地貌复杂,人类活动影响强烈,山洪灾害频繁发生且预测预防难度大,已成为防灾减灾和影响山丘区经济社会可持续发展的突出障碍之一。研究表明,短时间强降水是山洪灾害的主要诱发因子,降雨信息的准确获取对流域山洪灾害预报预警至关重要。然而,由于山区降雨具有较强的空间异质性,地面雨量站网的布局合理与否对获得精准的降雨数据以及预警信息发布尤为关键。根据水文站网规划技术导则,国内的山洪小流域雨量站网规划与优化主要采取雨量站网密度分析方法中的抽站法和流域水文模型法,且多针对大中尺度流域,山区小流域地面雨量监测站点的布局多依赖经验方法确定,带有很大的不确定性,给山洪预警信息的拟定带来困难。
3.山洪雨量站网优化的准则是选择站点的最优数量和位置,并使站网获取的信息量最大。目前,雨量站网优化研究已得到广泛关注,信息熵方法逐步在一些领域监测站点的优化布设方案中得到应用。mishra和coulibaly对水文站网的多种方法进行比较后得出信息熵法的雨量站网优化是最有前景的方法。li和singh提出了最大信息最小冗余准则(maximum information minim-um redundancy,mimr),将复杂的多目标问题转化为单目标问题。多数基于信息熵理论的水文站网优化方法的研究,都是在已有的地面雨量站网的基础上进行优化,而我国山洪灾害多发区多属无资料地区,在进行山洪灾害非工程措施规划布局时缺少地面雨量站点监测信息,无法确定最合理的地面雨量站网密度和位置,给山洪灾害监测预警和防治工作带来很大困难。如何科学布设地面雨量站点,准确获取流域降雨信息,对山洪灾害及时准确预警具有重要意义。
4.因此,有必要提供无资料山洪小流域雨量站网布局优化方法解决上述技术问题。
技术实现要素:
5.为解决上述技术问题,本发明提供山洪小流域雨量站网布局优化方法。
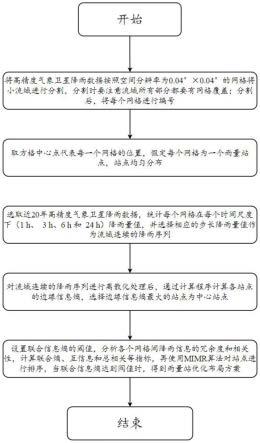
6.本发明提供的山洪小流域雨量站网布局优化方法,包括:
7.(1)将高精度气象卫星降雨数据按照空间分辨率为0.04
°×
0.04
°
的网格将小流域进行分割,分割时要注意流域所有部分都要有网格覆盖;分割后,将每个网格进行编号;
8.(2)取方格中心点代表每一个网格的位置,假定每个网格为一个雨量站点,站点均匀分布;
9.(3)选取近20年高精度气象卫星降雨数据,统计每个网格在每个时间尺度下(1h、3h、6h和24h)降雨量值,并选择相应的步长降雨量值作为流域连续的降雨序列;
10.(4)对流域连续的降雨序列进行离散化处理后,通过计算程序计算各站点的边缘信息熵,选择边缘信息熵最大的站点为中心站点;
11.(5)设置联合信息熵的阈值,分析各个网格间降雨信息的冗余度和相关性,计算联合熵、互信息和总相关等指标,再使用mimr算法对站点进行排序,当联合信息熵达到阀值时,得到雨量站优化布局方案。
12.优选的,所述边缘信息熵计算公式为:
[0013][0014]
其中k为任意正常数,本发明为1。底数b取不同值时信息熵的量纲不同,当b分别取2、e和10时,其对应量纲分别为bit、nat和dit,本发明b取2。
[0015]
优选的,所述联合信息熵的计算公式为:
[0016][0017]
所述互信息计算公式为:
[0018][0019]
所述总相关计算公式为:
[0020][0021]
优选的,所述步骤(4)假设共有n个站点,k是已选站点的数量,用s表示,m是待选站点的数量,用f表示,k m=n,则信息熵公式可以表示为:
[0022][0023]
为了规避多目标优化的复杂性,将多目标问题转为单目标问题:
[0024][0025]
式中,λ1,λ2为权重,两者之和为1,λ1通常大于λ2。对权重λ1,λ2进行敏感性分析后发现权重λ1在0.5到1之间变化时,站点信息保持稳定,本发明中,λ1,λ2分别取0.9和0.1时。
[0026]
优选的,所述步骤五中,用公式表示为为:
[0027][0028]
其中η中为阈值,当η≥95%时,即得到了水文网络站点的优化最终决策。
[0029]
优选的,对步骤(3)中的降雨序列的数值进行检测,具体方法为:
[0030]
1、将降雨序列的降水数据中的各个数值与对应的实测的降水数据各个数值作差后求绝对值;并将该绝对值与预设值比较,若该绝对值大于该预设值,则将所述降雨序列降水数据中的对应数值作为异常值;
[0031]
2、获取该异常值对应的站点及周围最近的至少三个站点;
[0032]
3、判断该周围最近的至少三个站点对应的第一降雨序列降水数据是否为异常值;若至少两个最近站点对应的第一时间序列降水数据为异常值,则重新选择相应的步长降雨量值作为降雨序列。
[0033]
优选的,所述述s5中得到雨量站优化布局方案的前还包括获得目标监测区域的地形信息、雨量站的覆盖标准信息,进而得到雨量站布局有限候选点集,当达到阀值时,结合雨量站布局有限候选点集,得到最终雨量站优化布局方案。
[0034]
所述雨量站的覆盖标准信息包括雨量站密度标准以及雨量站的最大服务距离
[0035]
与相关技术相比较,本发明提供的山洪小流域雨量站网布局优化方法具有如下有益效果:
[0036]
1、本发明基于高精度persiann-css卫星降雨产品数据,采用信息熵理论,分析无资料山洪小流域不同雨量站点密度和位置条件下卫星降雨数据之间的边缘熵和联合熵变化规律,基于最大信息最小冗余准则(mimr),确定流域最佳的雨量站网密度和位置,为今后无资料地区小流域山洪地面雨量站网布设提供理论依据。
附图说明
[0037]
图1为山洪小流域雨量站网布局优化方法流程示意图;
[0038]
图2为本发明实施例中小河沟流域降雨数据的卫星图像示意图;
[0039]
图3为小河沟流域年平均降雨量分布图;
[0040]
图4为小河沟流域各时间尺度降雨序列的(a)h、(b)t、(c)c随迭代次数变化趋势;
[0041]
图5为小河沟雨量站网位置及雨量分布图。
具体实施方式
[0042]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0043]
以下结合具体实施例对本发明的具体实现进行详细描述。
[0044]
本发明提供的山洪小流域雨量站网布局优化方法,包括:
[0045]
(1)将高精度气象卫星降雨数据按照空间分辨率为0.04
°×
0.04
°
的网格将小流域进行分割,分割时要注意流域所有部分都要有网格覆盖;分割后,将每个网格进行编号;
[0046]
(2)取方格中心点代表每一个网格的位置,假定每个网格为一个雨量站点,站点均匀分布;
[0047]
(3)选取近20年高精度气象卫星降雨数据,统计每个网格在每个时间尺度下(1h、3h、6h和24h)降雨量值,并选择相应的步长降雨量值作为流域连续的降雨序列;
[0048]
(4)对流域连续的降雨序列进行离散化处理后,通过计算程序计算各站点的边缘信息熵,选择边缘信息熵最大的站点为中心站点;
[0049]
(5)设置联合信息熵的阈值,分析各个网格间降雨信息的冗余度和相关性,计算联合熵、互信息和总相关等指标,再使用mimr算法对站点进行排序,当联合信息熵达到阀值时,得到雨量站优化布局方案。
[0050]
对步骤(3)中的降雨序列的数值进行检测,具体方法为:
[0051]
1、将降雨序列的降水数据中的各个数值与对应的实测的降水数据各个数值作差后求绝对值;并将该绝对值与预设值比较,若该绝对值大于该预设值,则将所述降雨序列降水数据中的对应数值作为异常值;
[0052]
2、获取该异常值对应的站点及周围最近的至少三个站点;
[0053]
3、判断该周围最近的至少三个站点对应的第一降雨序列降水数据是否为异常值;若至少两个最近站点对应的第一时间序列降水数据为异常值,则重新选择相应的步长降雨量值作为降雨序列。
[0054]
实施例:
[0055]
以无资料地区的小河沟流域为例,选择时间步长为6h和24h的降雨序列。根据信息熵公式可知,权重λ1,λ2会对站点的选择产生影响。因此取λ1=0.9,λ2=0.1。
[0056]
对小河沟流域连续的降雨序列进行离散化处理后,使用mimr准则,边缘熵、联合信息熵、互信息和总相关为小河沟流域雨量站的选取提供依据,结果见表1、2。
[0057]
小河沟流域24小时和6小时时间尺度的降雨序列,中心站点都为站点15。根据年均降雨量分布图2可知,站点15年平均降雨量最大,所以mimr准则会捕捉年平均降雨量较大的站点为中心站点。
[0058]
表1小河沟24小时尺度mimr准则计算表
[0059][0060]
表2小河沟6小时尺度mimr准则计算表
[0061][0062]
图3反映了h、t、c随着迭代次数的变化情况。联合熵随站点增多逐渐变大,在迭代之后趋向稳定,即总体信息量趋向稳定。不同时间尺度的联合熵达到稳定的迭代次数不同,小河沟流域24h尺度分别在12次,6h尺度分别在13次,时间尺度越大,稳定的越快。互信息先随站点增多而增大,在联合熵达到稳定后有减小的趋势,说明联合熵稳定后,站点之间的信息传递越来越少。站点之间的冗余信息随站点增加一直增大,即随着站点的增加,站点之间的重复信息越来越多。
[0063]
通过步骤5中的公式计算阈值,如图3所示。不同时间尺度在迭代一定次数后,趋势
稳定。小河沟流域24h尺度的站点排序为15、2、12、11、4、5、7、9、14、3、8、6、10、1、13,在迭代10次后,阈值达到95.8%,即选择了10个站点作为新的雨量站网,站网密度为19.6km2/站;6h尺度的站点排序为15、14、12、3、8、5、4、11、2、7、9、6、1、13、10,在迭代12次后,阈值达到95.8%,即选择了12个站点作为新的雨量站网,站网密度为16.33km2/站。结合联合熵、互信息、冗余信息的计算进行分析,在24h尺度间隔对降雨量进行采样后,由于流域面积较小,降雨量出现重复信息较多,使得冗余信息出现了较大增长。在计算阈值时,较大的时间尺度会在迭代次数较少的时候出现稳定,但通过站点排序,不同时间尺度中,小河沟流域站点11、10、3一直排在最后两位。
[0064]
最终以日尺度作为标准,小河沟流域选择了2、3、4、5、7、9、11、12、14、15号站点,如图4所示。
[0065]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。