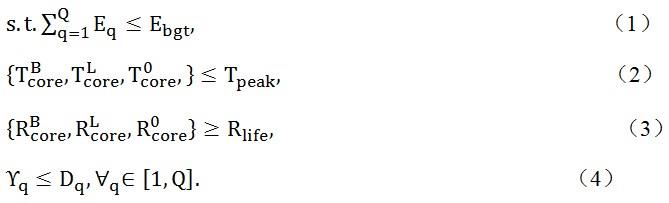
一种使用寿命驱动的opencl应用调度方法及系统
技术领域
1.本发明涉及cpu-gpu多处理器片上系统中使用寿命驱动的opencl应用调度技术领域,具体涉及一种使用寿命驱动的opencl应用调度方法及系统。
背景技术:
2.随着半导体技术的快速发展以及对应用性能要求的日益提高,多处理器已经取代单处理器,成为当代和下一代处理器的设计规范。在多处理器设计方法中,集成中央处理器(central processing unit, cpu)和图形处理器(graphics processing unit, gpu)的多处理器片上系统可以充分发挥gpu核心的并行计算能力和cpu核心的通用计算能力。开放计算语言(open computing language, opencl)支持多级别的线程并行化,可以将应用高效地映射到同构或异构、单个或多个cpu或gpu核心。对于一个opencl应用,存在一个使该应用获得最优性能的cpu负载,当更多的cpu核心参与到应用程序的执行时,应用的性能不会进一步的提升,反而会产生额外的能量和延迟开销。同时,对于配备有限冷却技术的cpu-gpu多处理器片上系统,迫切需要使用有效的热管理技术,以实现将芯片的峰值温度保持在指定的温度范围内。因此,在峰值温度限制条件下,最大程度地提高系统的效率,最小化应用的平均延迟,已经成为一个非常重要的研究课题。
3.在如何优化opencl应用在cpu-gpu多处理器片上系统的性能上,现有的研究大多数集中在设计优化算法、静态算法、或是动态和静态混合算法,以及对系统的峰值温度、应用的能耗和延迟进行优化。但是在相关的研究中,考虑了应用能耗、应用延迟、系统温度、以及系统寿命,目前,几乎没有对opencl应用同时考虑到这四个因素的研究工作。因此,迫切需要对使用寿命驱动的opencl应用调度研究,在满足应用能耗、系统温度和寿命的约束下,最小化opencl应用的平均延迟。
技术实现要素:
4.为解决上述问题,本发明提出了一种使用寿命驱动的opencl应用调度方法及系统,能够在满足时序、能耗、峰值温度以及使用寿命的约束下,最小化cpu-gpu多处理器片上系统的平均延迟。
5.为实现上述目的,本发明提供了一种使用寿命驱动的opencl应用调度方法,包括以下步骤:s1:获取cpu-gpu多处理器片上系统中的应用参数和处理器参数;s2:基于所述应用参数和所述处理器参数,对任务队列中的应用生成静态调度表;s3:基于所述静态调度表,对任务队列中的应用生成动态调度表;s4:基于所述动态调度表,定期调用主控制算法生成应用调度表;s5:基于所述应用调度表,执行应用,调度结束。
6.优选的,所述s2中,对任务队列中的应用生成静态调度表的方法包括:s21:初始化概率向量和迭代计数器,并利用样本生成函数生成若干个拉丁超立方
采样样本;s22:调用应用选择函数,从应用合集中随机选择若干个应用对若干个所述拉丁超立方采样样本进行微调操作;s23:计算每个微调操作后的所述拉丁超立方采样样本对应的性能,按照性能递减排序所述拉丁超立方采样样本,选取若干个预设精英样本的下标集合;s24:计算若干个所述预设精英样本的下标集合迭代的阈值;s25:根据所述预设精英样本,更新迭代概率向量;s26:基于满足迭代条件的所述阈值和所述概率向量,生成静态调度表。
7.优选的,所述s3中,对任务队列中的应用生成动态调度表的方法包括:s31:输入一个预先设定的违背率阈值至pid控制算法中;s32:若当前的约束条件违背等级大于所述违背率阈值,则迭代地优化所述cpu-gpu多处理器片上系统的资源利用率控制变量,并使用pid控制器对应用执行状态采样并更新约束条件违背等级;s33:若当前的约束条件违背等级小于所述违背率阈值,则输出所述cpu-gpu多处理器片上系统的资源利用率控制变量,并将所述资源利用率控制变量、准入队列里的应用个数和等待队列中的应用个数输入至应用准入控制算法;s34:若所述资源利用率控制变量大于0,则根据edf算法对等待队列里的应用排序,并对等待队列中的队头应用分配,获得资源利用率的阈值;s35:若所述资源利用率控制变量大于所述资源利用率的阈值,则更新资源当前利用率和所述资源利用率控制变量;并从等待队列中删除队头应用,使用edf算法对等待队列里的应用重新进行排序并更新准入队列里应用的个数;s36:若所述资源利用率控制变量小于所述资源利用率的阈值,则输出资源利用率的阈值集合,并输入至应用执行控制算法;s37:调用函数coreldlecheck(),若所述cpu-gpu多处理器片上系统中存在处于空闲状态的核心,则所述函数coreldlecheck()的返回值为1,当所述返回值为1并且所述资源利用率的阈值大于0,则随机分配一个空闲核心给应用,并计算资源利用率增量;s38:基于所述资源利用率增量,更新所述资源利用率的阈值,当所述资源利用率的阈值耗尽时,返回下一个应用的调度方案,并输出准入队列里的应用调度表,即动态调度表。
8.优选的,所述s4中,定期调用主控制算法生成应用调度表的方法包括:s41:将应用集合输入至主控制算法;s42:基于所述应用集合,调用所述pid控制算法获取资源利用率控制变量;s43:基于所述资源利用率控制变量,调用所述应用准入控制算法获取准入队列里应用并输出资源利用率的阈值集合;s44:若所述阈值集合不为空,调用所述应用执行控制算法生成应用调度表。
9.本发明还提供了一种使用寿命驱动的opencl应用调度系统,包括:参数获取模块、静态调度表生成模块、动态调度表生成模块、应用调度表生成模块和调度执行模块;所述参数获取模块用于,获取cpu-gpu多处理器片上系统中的应用参数和处理器参数;
所述静态调度表生成模块用于,基于所述应用参数和所述处理器参数,对任务队列中的应用生成静态调度表;所述动态调度表生成模块用于,基于所述静态调度表,对任务队列中的应用生成动态调度表;所述应用调度表生成模块,基于所述动态调度表,定期调用主控制算法生成应用调度表;所述调度执行模块用于,基于所述应用调度表,执行应用,调度结束。
10.优选的,所述静态调度表生成模块包括采样单元、计算单元、迭代输出单元;所述采样单元用于初始化概率向量和迭代计数器,并利用样本生成函数生成若干个拉丁超立方采样样本;所述计算单元用于调用应用选择函数,从应用合集中随机选择若干个应用对若干个所述拉丁超立方采样样本进行微调操作,并计算每个微调操作后的所述拉丁超立方采样样本对应的性能,按照性能递减排序所述拉丁超立方采样样本,选取若干个预设精英样本的下标集合;所述迭代输出单元用于计算所述预设精英样本的下标集合迭代的阈值,并根据所述预设精英样本,更新迭代概率向量,当所述阈值和所述概率向量满足迭代条件时,生成所述静态调度表。
11.优选的,所述动态调度表生成模块包括假定单元、约束计算单元、资源利用率计算单元、调度表输出单元;所述假定单元用于设定的违背率阈值;所述约束计算单元用于分析当前的约束条件违背等级与所述违背率阈值的关系,当前的约束条件违背等级大于所述违背率阈值,则迭代地优化所述cpu-gpu多处理器片上系统的资源利用率控制变量,并使用pid控制器对应用执行状态采样并更新约束条件违背等级;当前的约束条件违背等级小于所述违背率阈值,则输出所述cpu-gpu多处理器片上系统的资源利用率控制变量,并将所述资源利用率控制变量、准入队列里的应用个数和等待队列中的应用个数输入至应用准入控制算法;所述资源利用率计算单元用于对所述资源利用率控制变量进行分析,若所述资源利用率控制变量大于0,则根据edf算法对等待队列里的应用排序,并对等待队列中的队头应用分配,获得资源利用率的阈值;若所述资源利用率控制变量大于所述资源利用率的阈值,则更新资源当前利用率和所述资源利用率控制变量;并从等待队列中删除队头应用,使用edf算法对等待队列里的应用重新进行排序并更新准入队列里应用的个数;若所述资源利用率控制变量小于所述资源利用率的阈值,则输出资源利用率的阈值集合,并输入至应用执行控制算法;所述调度表输出单元用于调用函数coreldlecheck(),若所述cpu-gpu多处理器片上系统中存在处于空闲状态的核心,则所述函数coreldlecheck()的返回值为1,当所述返回值为1并且所述资源利用率的阈值大于0,随机分配一个空闲核心给应用,并计算资源利用率增量;基于所述资源利用率增量,更新所述资源利用率的阈值,当所述资源利用率的阈值耗尽时,返回下一个应用的调度方案,并输出准入队列里的应用调度表,即动态调度表。
12.优选的,所述应用调度表生成模块包括资源利用率控制变量获取单元和调度表生
成单元;所述资源利用率控制变量获取单元用于将应用集合输入至主控制算法,并基于所述应用集合,调用所述pid控制算法获取资源利用率控制变量;所述调度表生成单元用于基于所述资源利用率控制变量,调用所述应用准入控制算法获取准入队列里应用并输出资源利用率的阈值集合,若所述阈值集合不为空,调用所述应用执行控制算法生成应用调度表。
13.与现有技术相比,本发明具有如下优点和技术效果:本发明公开了一种使用寿命驱动的opencl应用调度方法及系统,通过读取cpu-gpu多处理器片上系统中的应用参数和处理器参数;对任务队列中的应用生成静态调度表;对任务队列中的应用生成动态调度表;定期调用主控制算法生成应用调度表;调度结束。使用本发明能够在满足时序、能耗、峰值温度以及使用寿命的约束下,最小化cpu-gpu多处理器片上系统的平均延迟。
附图说明
14.构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:图1为本发明一种使用寿命驱动的opencl应用调度方法流程示意图;图2为基准应用运用本发明与etrr、tpso算法在hardkernel odroid-xu3 硬件平台上执行的延迟示意图;图3为基准应用在exynos 9810 mpsoc硬件平台上执行的延迟示意图;图4为基准应用在hardkernel odroid-xu3硬件平台上执行的能耗示意图;图5为本发明静态算法的应用能耗与两种基准算法的应用能耗比较示意图;图6为本发明静态算法和基准算法etrr、tpso取得的处理器核心峰值温度比较示意图;图7为本发明静态算法和基准算法etrr、tpso取得的系统生命周期比较示意图;图8为本发明三种动态算法在hardkernel odroid-xu3硬件平台上执行6个基准应用km、pb、ase、be、ch、bs时的应用延迟比较示意图;图9为本发明三种动态算法在exynos 9810 mpsoc硬件平台上执行6个基准应用km、pb、ase、be、ch、bs时的应用延迟比较示意图;图10为本发明三种动态算法在hardkernel odroid-xu3硬件平台上执行基准应用km、pb、ase、be、ch、bs时的能耗比较示意图;图11为本发明三种动态算法在exynos 9810 mpsoc硬件平台上执行基准应用km、pb、ase、be、ch、bs时的能耗比较示意图;图12为本发明动态算法和基准算法logfit、emin取得的处理器核心峰值温度比较示意图;图13为本发明动态算法和基准算法logfit、emin取得的系统生命周期比较示意图。
具体实施方式
15.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
16.需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
17.实施例一:如图1所示,本发明提供了一种使用寿命驱动的opencl应用调度方法,包括以下步骤:s1:获取cpu-gpu多处理器片上系统中的应用参数和处理器参数;s2:基于应用参数和处理器参数,对任务队列中的应用生成静态调度表;s3:基于静态调度表,对任务队列中的应用生成动态调度表;s4:基于动态调度表,定期调用主控制算法生成应用调度表;s5:基于应用调度表,执行应用,调度结束。
18.具体的,s2中,对任务队列中的应用生成静态调度表的方法包括:s21:初始化概率向量 和迭代计数器,其中表示交叉熵方法的初始概率向量;并利用样本生成函数生成总共z个拉丁超立方采样样本,即样本样本;s22:调用应用选择函数,从应用合集中随机选择个应用进行样本微调操作;s221:在应用合集中任意的一个被选中的应用,调用样本微调函数进行样本微调操作,其中表示为需要进行微调的样本集合,表示为标志位;s222:判断标志位的置位数,当置为1时,表示更多的cpu资源会带来应用的性能提升,即需要增加分配给应用的cpu资源;反之,当置为-1时,表示更多的cpu资源会降低应用的性能,即需要减少分配给应用的cpu资源;s223:判断微调后样本的性能是否优于微调前样本的性能,如果是,将微调后的样本替代微调前的样本,并将当前标志位的置数赋值给用于下次迭代的标志位,即;s224:判断微调后样本的性能是否弱于微调前样本的性能,如果是,将前标
志位的相反值赋值给下一次迭代的标志位;s23:计算每个样本对应的性能,按照性能递减排序样本,选取共个精英样本的下标集合,其中为精英样本的个数;s24:计算第次迭代的阈值,计算公式为:其中为性能最优的个精英样本的下标集合;s25:根据精英样本,更新第次迭代的概率向量,计算公式为:,其中为样本的第个元素,为在第次迭代映射到的概率;s26:基于所述阈值和所述概率向量,判断是否满足终止迭代条件,如果是,输出性能最优的单个样本,生成静态调度表。如果否,跳转至s21。
19.具体的,s3中,对任务队列中的应用生成动态调度表的方法包括:s31:载入一个预先设定的约束条件违背率阈值至pid控制算法中;s32:判断当前的约束条件违背等级是否大于阈值,其中判断公式为:其中,上述公式中(1)为能耗约束条件,表示处理应用的延迟能耗,q个应用的总能耗不能超过预先设定的能量预算公式(2)为峰值温度约束条件,分别表示为系统在执行q个应用时cpu大核集群、cpu小核集群、gpu核心的峰值温度,为给定的峰值温度阈值。公式(3)为使用寿命约束条件,分别表示cpu大核集群、cpu小核集群、gpu核心的寿命,为给定的使用寿命阈值。公式(4)为时序约束条件,即任意一个应用的延迟不可以超过给定的截止期限;s321:判断当前的约束条件违背等级是否大于阈值,如果是,则迭代地优化系统的资源利用率。其中,更新系统资源利用率控制变量的计算公式为:
,在该式中,分别代表pid控制器的比例、积分、微分系数,表示约束条件违背等级和阈值的差值,即表示为在系统运行时发生积分误差的调度窗口个数,dw表示系统运行时发生微分误差的调度窗口个数;s322:使用pid控制器对应用执行状态采样并更新约束条件违背等级;s33:判断约束条件违背等级是否小于阈值,如果是,输出系统资源利用率控制变量;载入系统资源利用率控制变量,准入队列里的应用个数,等待队列中的应用个数至应用准入控制算法;s34:设系统当前的处理器核心的平均利用率为sru,判断系统资源利用率控制变量是否大于0,即,如果是,则根据edf算法对等待队列里的应用排序;对等待队列中的队头应用分配可用于提升系统资源利用率的阈值,其中阈值的计算公式为:为应用的指令周期总数;s35:判断系统资源利用率控制变量与系统资源利用率的阈值的差值是否大于零,即,如果是,更新系统资源当前利用率为,即,并利用更新系统资源利用率控制变量;从等待队列中删除队头应用,使用edf算法对等待队列里的应用重新进行排序并更新准入队列里应用的个数,即;s36:判断系统资源利用率控制变量是否小于0,如果是,输出并退出,否则返回s34;载入准入队列里应用可用于提升系统资源利用率的阈值集合,即至应用执行控制算法;s37:调用函数判断系统中是否存在处于空闲状态的核心,如果存在,函数返回值为1,否则为0,即;当时,判断是否大于0,如果是,随机分配一个空闲核心给应用
,并计算资源利用率增量;s38:更新可用于提升系统资源利用率的阈值,计算公式为:。当可用于提升系统资源利用率的阈值耗尽时,返回生成的调度方案;输出准入队列里的应用调度表并退出。
20.具体的,s4中,定期调用主控制算法生成应用调度表的方法包括:s41:将应用集合输入至主控制算法;s42:基于所述应用集合,调用所述pid控制算法获取资源利用率控制变量;s43:基于所述资源利用率控制变量,调用所述应用准入控制算法获取准入队列里应用并输出资源利用率的阈值集合,即;s44:判断阈值集合是否为空,如果不为空,调用应用执行控制算法生成应用调度表,执行应用,调度结束。
21.实施例二:本发明还提供了一种使用寿命驱动的opencl应用调度系统,包括:参数获取模块、静态调度表生成模块、动态调度表生成模块、应用调度表生成模块和调度执行模块;参数获取模块用于,获取cpu-gpu多处理器片上系统中的应用参数和处理器参数;静态调度表生成模块用于,基于应用参数和处理器参数,对任务队列中的应用生成静态调度表;动态调度表生成模块用于,基于静态调度表,对任务队列中的应用生成动态调度表;应用调度表生成模块,基于动态调度表,定期调用主控制算法生成应用调度表;调度执行模块用于,基于应用调度表,执行应用,调度结束。
22.具体的,静态调度表生成模块包括采样单元、计算单元、迭代输出单元;采样单元用于,初始化概率向量和迭代计数器,其中表示交叉熵方法的初始概率向量;并利用样本生成函数生成总共z个拉丁超立方采样样本,即样本计算单元用于,调用应用选择函数,从应用合集中随机选择个应用进行样本微调操作;在应用合集中任意的一个被选中的应用,调用样本微调函数进行样本微调操作,其中表示为需要进行微调
的样本集合,表示为标志位;判断标志位的置位数,当置为1时,表示更多的cpu资源会带来应用的性能提升,即需要增加分配给应用的cpu资源;反之,当置为-1时,表示更多的cpu资源会降低应用的性能,即需要减少分配给应用的cpu资源;判断微调后样本的性能是否优于微调前样本的性能,如果是,将微调后的样本替代微调前的样本,并将当前标志位的置数赋值给用于下次迭代的标志位,即;判断微调后样本的性能是否弱于微调前样本的性能,如果是,将前标志位的相反值赋值给下一次迭代的标志位;计算每个样本对应的性能,按照性能递减排序样本,选取共个精英样本的下标集合,其中为精英样本的个数;迭代输出单元用于,计算第次迭代的阈值,计算公式为:,其中为性能最优的个精英样本的下标集合;根据精英样本,更新第次迭代的概率向量,计算公式为:,其中为样本的第个元素,为在第次迭代映射到的概率;基于所述阈值和所述概率向量,判断是否满足终止迭代条件,如果是,输出性能最优的单个样本,生成静态调度表。如果否,跳转至步骤1。
23.具体的,动态调度表生成模块包括假定单元、约束计算单元、资源利用率计算单元、调度表输出单元;假定单元用于,载入一个预先设定的约束条件违背率阈值至pid控制算法中;约束计算单元用于,判断当前的约束条件违背等级是否大于阈值,其中判断公式为:
其中,上述公式中(1)为能耗约束条件,表示处理应用的延迟能耗,q个应用的总能耗不能超过预先设定的能量预算公式(2)为峰值温度约束条件,分别表示为系统在执行q个应用时cpu大核集群、cpu小核集群、gpu核心的峰值温度,为给定的峰值温度阈值。公式(3)为使用寿命约束条件,分别表示cpu大核集群、cpu小核集群、gpu核心的寿命,为给定的使用寿命阈值。公式(4)为时序约束条件,即任意一个应用的延迟不可以超过给定的截止期限;判断当前的约束条件违背等级是否大于阈值,如果是,则迭代地优化系统的资源利用率。其中,更新系统资源利用率控制变量的计算公式为:的计算公式为:,在该式中,分别代表pid控制器的比例、积分、微分系数,表示约束条件违背等级和阈值的差值,即表示为在系统运行时发生积分误差的调度窗口个数,dw表示系统运行时发生微分误差的调度窗口个数;使用pid控制器对应用执行状态采样并更新约束条件违背等级;判断约束条件违背等级是否小于阈值,如果是,输出系统资源利用率控制变量;载入系统资源利用率控制变量,准入队列里的应用个数,等待队列中的应用个数至应用准入控制算法;资源利用率计算单元用于,设系统当前的处理器核心的平均利用率为sru,判断系统资源利用率控制变量是否大于0,即,如果是,则根据edf算法对等待队列里的应用排序;对等待队列中的队头应用分配可用于提升系统资源利用率的阈值,其中阈
值的计算公式为:为应用的指令周期总数;判断系统资源利用率控制变量与系统资源利用率的阈值的差值是否大于零,即,如果是,更新系统资源当前利用率为,即,并利用更新系统资源利用率控制变量;从等待队列中删除队头应用,使用edf算法对等待队列里的应用重新进行排序并更新准入队列里应用的个数,即;判断系统资源利用率控制变量是否小于0,如果是,输出并退出,否则返回步骤4;载入准入队列里应用可用于提升系统资源利用率的阈值集合,即,至应用执行控制算法;调度表输出单元用于,调用函数判断系统中是否存在处于空闲状态的核心,如果存在,函数返回值为1,否则为0,即;当时,判断是否大于0,如果是,随机分配一个空闲核心给应用,并计算资源利用率增量;更新可用于提升系统资源利用率的阈值,计算公式为:。当可用于提升系统资源利用率的阈值耗尽时,返回生成的调度方案;输出准入队列里的应用调度表并退出。
24.具体的,应用调度表生成模块包括资源利用率控制变量获取单元和调度表生成单元;资源利用率控制变量获取单元用于,将应用集合输入至主控制算法;基于所述应用集合,调用所述pid控制算法获取资源利用率控制变量;调度表生成单元用于,基于所述资源利用率控制变量,调用所述应用准入控制算法获取准入队列里应用并输出资源利用率的阈值集合,即;判断阈值集合是否为空,如果不为空,调用应用执行控制算法生成应用调度表,执行应用,调度结束。
25.实施例三:实施过程中,采用两种cpu-gpu的多处理器片上系统验证所提出的算法在降低应用延迟方面的有效性。一种是hardkernelodroid-xu3硬件平台,该平台集成了三星exynos 5422 mpsoc,包含4个arm cortex a15核心、4个arm cortex a7核心,以及1个arm mali-t628 mp6 gpu.4个arm cortex a15核心构成了一个高性能的cpu大核集群,每个内核都支持步长为100mhz,从200mhz和2000mhz之间的多种离散频率。4个arm cortex a7核心组成了一个低功耗的cpu小核心集群,每个核心都支持步长为100mhz,从200mhz到1400mhz之间的不同离散频率。对于arm mali-t628 mp6 gpu,它的工作频率从{600, 543, 480, 420, 350, 266, 177}mhz 选取。同时,将三星exynos 9810mpsoc作为测试硬件平台。exynos 9810 mpsoc的cpu大核集群包含4个m3核心,每个核心支持18种离散的工作频率,包括{704, 2652, 2496, 2314z, 2106, 2002, 1924, 1794, 1690, 1586, 1469, 1261, 1170, 1066, 962, 858, 741, 650}mhz;cpu小核集群包含4个arm cortex a55核心,每个核心支持10种不同的离散频率,包括{794, 1690, 1456, 1248, 1053, 949 mhz, 832, 715, 598, 455} mhz;gpu集群由arm mali-g72 mp18 gpu构成,支持6种离散的工作频率,包括{572, 546 mhz, 455, 338, 299, 260}mhz。
26.为了验证算法的性能,本技术将基于交叉熵方法的静态算法与基准算法 etrr、tpso进行对比,将基于反馈控制的动态算法与基准算法 logfit、emin进行比对。
27.图2首先比较fdeb、fir、kun、ep、bsti、ga、c2d、syr2k、bodytrack、ferret共10个基准应用运用本发明与etrr、tpso算法在hardkernel odroid-xu3 硬件平台上执行的延迟。本发明提出的静态算法与基准算法etrr、tpso取得的应用延迟分别为89.41、130.30、109.71。同时,从图1最后一列average数据点可以看出本发明提出的静态方法能够将10个基准应用的平均延迟分别降低29.83%、23.95%相比于基准算法etrr和tpso。
28.图3比较了fdeb、fir、knn、ep、bsti、ga、c2d、syr2k、bodytrack、ferret共10个基准应用在exynos 9810 mpsoc硬件平台上执行的延迟。与图1中的结果相似,本发明提出的静态算法在exynos 9810 mpsoc硬件平台上仍然能够有效地降低基准应用的延迟。从图2最后一列average数据点看出,本文提出的静态算法能够将10个基准应用的平均延迟分别降低34.58%、25.42%。
29.图4比较了fdeb、fir、knn、ep、bsti、ga、c2d、syr2k、bodytrack、ferret在hardkernel odroid-xu3硬件平台上执行的能耗。在本组实验当中,应用的能量预算设置为3000焦耳。从图3中可以看出,本发明提出的静态算法可以满足于应用总能耗的约束。
30.图5给出对于任意一个应用,本发明静态算法的应用能耗大于两种基准算法的应用能耗,其主要原因是因为本发明提出的静态算法充分利用了给定的能耗预算,以实现将基准应用的延迟最小化的优化目标。
31.图6给出了本发明提出的静态算法和基准算法etrr、tpso取得的处理器核心峰值温度。在实验中,将hardkernel odroid-xu3和exynos 9810 mpsoc的峰值温度分别设置为70℃和90℃。由图5所示,使用本发明得到的峰值温度无论是hardkernel odroid-xu3还是exynos 9810 mpsoc硬件平台都能够满足峰值温度的约束。
32.图7给出了本发明提出的静态算法和基准算法etrr、tpso取得的系统生命周期。在实验中,将hardkernel odroid-xu3和exynos 9810 mpsoc最小的生命周期需求分别设置为
16年和18年。从图6中数据可以看出,无论是hardkernel odroid-xu3还是exynos 9810 mpsoc硬件平台,使用本发明的静态算法可以满足使用寿命的约束。
33.图8比较了三种动态算法在hardkernel odroid-xu3硬件平台上执行6个基准应用km、pb、ase、be、ch、bs时的应用延迟。与基准算法logfit、emin相比,使用本发明提出的动态算法可以将6个基准应用平均延迟降低23.47%、24.89%。
34.图9比较了三种动态算法在exynos 9810 mpsoc硬件平台上执行6个基准应用km、pb、ase、be、ch、bs时的应用延迟。与图7中结果相似,本发明提出的动态算法在exynos 9810 mpsoc硬件平台上实现的性能优于基准算法logfit和emin。使用本发明提出的动态算法和基准算法logfit、emin实现的应用平均延迟分别为82.04、110.44、123.60。
35.图10给出了三种动态算法在hardkernel odroid-xu3硬件平台上执行基准应用km、pb、ase、be、ch、bs时的能耗。在本组实验当中,应用的能量预算设置为3000焦耳。从图9中可以看出,本发明提出的动态算法满足给定的能耗约束。
36.图11给出了三种动态算法在exynos 9810 mpsoc硬件平台上执行基准应用km、pb、ase、be、ch、bs时的能耗。在本组实验当中,应用的能量预算e_bgt设置为2000焦耳。图10中可以看出,本发明提出的动态算法仍然满足给定的能耗约束。
37.图12给出了本发明提出的动态算法和基准算法logfit、emin取得的处理器核心峰值温度。在实验中,hardkernel odroid-xu3和exynos 9810 mpsoc的峰值温度阈值仍然设置为70℃和90℃。由图11所示本发明提出的动态算法执行6个基准应用km、pb、ase、be、ch、bs时,均未超过两个硬件平台设定的峰值温度阈值,相反,基准算法logfit和emin都超过了两个硬件平台设定的峰值温度阈值。
38.图13比较了本发明提出的动态算法和基准算法logfit、emin取得的系统生命周期。在实验中,hardkernel odroid-xu3和exynos 9810最小的使用寿命需求仍然设置为16年和18年。由图12所示,本发明提出的动态算法在执行6个基准应用km、pb、ase、be、ch、bs时,始终没有违背系统生命周期约束,而基准算法logfit和emin均不能满足系统的最小使用寿命需求。
39.通过上述的实验数据,能够很清楚的看出本发明在满足时序、能耗、峰值温度以及使用寿命的约束下,最小化系统的平均延迟。
40.以上,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。