1.本发明涉及人工智能、机器学习领域。
背景技术:
2.强化学习近来被应用到解决许多挑战性问题上去,比如玩游戏和机器人上。也有很多重要的应用场景牵涉到多个智能体之间的交互,在这种共同的交互演化过程中,会有新的行为出现,问题也会变得更加复杂。传统的强化学习方法不适用于多智能体方法,因此,多智能体深度强化学习应运而生。
3.对于复杂的多对多攻守博弈场景,在数学上无法求得解析的纳什均衡解,因此需要使用多智能体深度强化学习方法。ryan lowe等人在2017年提出了多智能体演员-评论家算法和多智能体深度确定性策略梯度算法(multi-agent deep deterministic policy gradient,下文简称maddpg),采用集中式训练的框架,分散式执行的方式,在一些合作、竞争混合的环境下取得了优越的效果。针对随机马尔科夫博弈:在攻防对抗博弈中,我们需要控制攻防双方多个智能体完成各自目标。此过程可描述为随机马尔科夫博弈。n个智能体的随机马尔科夫博弈γ可表示为其中s为状态空间;aj为第j个智能体动作空间;第j个智能体的奖励函数为rj:状态转移概率p为s
×
a1×…×an
→
ω(s),描述状态随时间的随机变化,其中ω(s)为整个状态空间s上的概率分布集合;折扣因子γ∈[0,1)。每个智能体的目标是最大化自身的总预期回报
[0004]
但是现有的多智能体深度确定性策略梯度算法(maddpg)存在的弊端是,无法应用于智能体可坠毁的场景下,也即:无法处理训练过程中智能体数量变化的情况;由于在获取训练样本的过程中,当智能体由于碰撞坠毁导致智能体数量变化时,经验回放池中得到的同一时刻下所有智能体的数据缺失,当从经验回放池中抽取出数据缺失的样本时,使得输入至深度神经网络中数据维度变小,使得现有深度神经网络无法继续进行训练学习、整个训练过程被迫终止。
技术实现要素:
[0005]
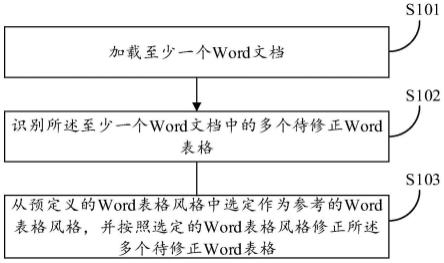
本发明目的是为了解决多智能体深度确定性策略梯度算法(maddpg),无法应用于智能体可坠毁的场景下的问题,本发明提供了一种基于深度强化学习的多智能体攻防决策方法。
[0006]
基于深度强化学习的多智能体攻防决策方法,该攻防决策方法基于同一场景下的n个智能体和目标地标实现;智能体为飞行器,且每个智能体内嵌入深度神经网络,n为大于或等于5的整数;该攻防决策方法包括如下过程:
[0007]
s1、根据场景构建攻防环境;
[0008]
攻防环境中n个智能体被划分为两组,分别为进攻方和防守方,且进攻方内各智能
体独立进攻,防守方所对应的所有智能体协同合作;
[0009]
s2、将n个智能体与攻防环境进行交互,交互过程中每个智能体最大化自身奖励,构建适用于深度神经网络的数据集知识库;
[0010]
所述数据集知识库内所有样本的数据维度相同,且每个样本中的数据为由同一采样轮次下的n个智能体的当前状态、动作、奖励和新状态构成;所述智能体的动作包括由水平面内的x轴方向和y轴方向的期望加速度构成的合成期望加速度;
[0011]
s3、从数据集知识库中随机抽取一批样本,利用同批样本同时对每个智能体的深度神经网络进行训练,获得训练后的智能体;其中,每个样本中的当前状态、奖励和新状态作为深度神经网络的输入,每个样本中的动作作为深度神经网络的输出;
[0012]
s4、在当前攻防环境和预设攻防轮次下,使训练后的各智能体进行攻防决策。
[0013]
优选的是,s2、构建适用于深度神经网络的数据集知识库的实现方式包括:
[0014]
s21、设置数据集知识库内的样本数量为m;每个采样批次下包括多次采样;
[0015]
s22、在第p个采样批次下,进行第l次采样,使攻防环境中n个智能体中每个智能体根据自身观测空间、当前状态和剩余n-1智能体的动作,并生成相应动作与攻防环境进行交互,获得相应的奖励、新状态;p的初始值为1,且每个采样批次下,l的初始值为1;
[0016]
s23、判断第p个采样批次下的第l次采样,是否出现智能体坠毁,结果为是,执行步骤s24;结果为否,执行步骤s25;
[0017]
s24、将第p个采样批次下第l次采样获得的所有数据删除,令p=p 1,再对第p个采样批次下的所有智能体的当前状态重新初始化,执行步骤s22;
[0018]
s25、将第p个采样批次下第l次采样获得的攻防环境中所有智能体的当前状态、动作、奖励和新状态,作为当前第p个采样批次下的一个样本存入数据集知识库,执行步骤s26;
[0019]
s26、判断数据集知识库内的样本数量是否达到m,结果为否,执行步骤s27,结果为是,执行步骤s28;
[0020]
s27、当当前第p个采样批次下样本数量达到45或进攻方内的智能体撞击目标地标时,令p=p 1,执行步骤s22;否则,令l=l 1,执行步骤s22;
[0021]
s28、结束,完成数据集知识库的构建。
[0022]
优选的是,防守方的智能体的目标为:阻止进攻方的智能体撞击目标地标、合作拦截进攻方的智能体、以及同时避免与进攻方的智能体撞击;
[0023]
进攻方的智能体的目标为:撞击目标地标、同时躲避防守方的智能体的拦截。
[0024]
优选的是,s2中、交互过程中每个智能体最大化自身奖励的实现方式包括:
[0025]
(三)当当前智能体为进攻方的智能体时,该当前智能体的奖励函数ri为:
[0026]ri
=r
idis
r
icol
;
[0027][0028][0029]
其中,r
idis
为进攻方的第i个智能体的距离奖励,r
icol
为进攻方的第i个智能体的撞击奖励,d(i,goal)为进攻方的第i个智能体与目标地标的距离,d(i,goodj)为进攻方的第i
个智能体与防守方的第j个智能体的距离;
[0030]
(四)当当前智能体为防守方的智能体时,该当前智能体的奖励函数ri为:
[0031]ri
=r
iadv
r
igood
;
[0032][0033][0034]
其中,r
iadv
为防守方的第i个智能体的第一距离奖励,r
igood
为防守方的第i个智能体的第二距离奖励,d(goal,advj)为进攻方的第j个智能体与目标地标的距离;d(i,advj)为防守方的第i个智能体与进攻方的第j个智能体的距离。
[0035]
优选的是,s4、在当前攻防环境和预设攻防轮次下,使训练后的各智能体进行攻防决策的实现方式包括:
[0036]
在每个攻防轮次下,使训练后的各智能体根据自身观测空间做出相应的动作。
[0037]
一种计算机可读的存储设备,所述存储设备存储有计算机程序,所述计算机程序被执行时实现如所述基于深度强化学习的多智能体攻防决策方法。
[0038]
一种基于深度强化学习的多智能体攻防决策装置,包括存储设备、处理器以及存储在所述存储设备中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序实现如所述基于深度强化学习的多智能体攻防决策方法。
[0039]
本发明带来的有益效果是:
[0040]
现有的多智能体深度强化学习方法大多用于追逃博弈的场景下,然而对于攻防博弈问题却很少有人研究。相较追逃博弈,攻防博弈对智能体提出了更严格的要求。
[0041]
本发明所述基于深度强化学习的多智能体攻防决策方法,考虑了场景中智能体会因碰撞而坠毁,导致智能体数量变化的问题,避免了因智能体数量变化而导致的样本维度缺失的问题,本发明可应用于复杂的多对多攻防场景下,并展现出了很好的效果。
[0042]
发明在智能体坠毁后将该智能体冻结,不再与环境交互。对于坠毁的智能体,不对其所在采样批次下继续采样,完成当前采样批次下的采样操作,同时,对下一采样批次下的所有智能体的当前状态重新初始化,继续下一轮采样批次下的采样操作。因此,本发明在构建数据集知识库内样本的过程中,可保证每个采样批次下所有样本数据维度相同;也就是说,智能体坠毁后更新所有神经网络参数时只使用智能体坠毁前的数据,保证了输入至深度神经网络中数据维度相同,使神经网络能正常进行计算。
附图说明
[0043]
图1是本发明所述轴对称矢量偏振光获取装置的结构示意图;
[0044]
图2是场景中进攻方的飞行器、防守方的飞行器和目标地标的相对位置示意图;
[0045]
图3是攻守双方智能体之间未发生碰撞坠毁,本发明方法与传统的maddpg方法对深度神经网络进行训练过程中,获得的两条平均奖励曲线对比图;
[0046]
图4是攻守双方智能体之间发生碰撞坠毁时,本发明方法与传统的maddpg方法在执行阶段中,获得的两条平均奖励曲线对比图。
具体实施方式
[0047]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0048]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0049]
实施例1:
[0050]
参见图1说明本实施例1,本实施例1所述的基于深度强化学习的多智能体攻防决策方法,该攻防决策方法基于同一场景下的n个智能体和目标地标实现;智能体为飞行器,且每个智能体内嵌入深度神经网络,n为大于或等于5的整数;该攻防决策方法包括如下过程:
[0051]
s1、根据场景构建攻防环境;
[0052]
攻防环境中n个智能体被划分为两组,分别为进攻方和防守方,且进攻方内各智能体独立进攻,防守方所对应的所有智能体协同合作;
[0053]
s2、将n个智能体与攻防环境进行交互,交互过程中每个智能体最大化自身奖励,构建适用于深度神经网络的数据集知识库;
[0054]
所述数据集知识库内所有样本的数据维度相同,且每个样本中的数据为由同一采样轮次下的n个智能体的当前状态、动作、奖励和新状态构成;所述智能体的动作包括由水平面内的x轴方向和y轴方向的期望加速度构成的合成期望加速度;
[0055]
s3、从数据集知识库中随机抽取一批样本,利用同批样本同时对每个智能体的深度神经网络进行训练,获得训练后的智能体;其中,每个样本中的当前状态、奖励和新状态作为深度神经网络的输入,每个样本中的动作作为深度神经网络的输出;
[0056]
s4、在当前攻防环境和预设攻防轮次下,使训练后的各智能体进行攻防决策。
[0057]
应用时,每个智能体内嵌入深度神经网络为现有的神经网络,且步骤s4中训练的过程采用现有技术实现。
[0058]
具体的,s2、构建适用于深度神经网络的数据集知识库的实现方式包括:
[0059]
s21、设置数据集知识库内的样本数量为m;每个采样批次下包括多次采样;
[0060]
s22、在第p个采样批次下,进行第l次采样,使攻防环境中n个智能体中每个智能体根据自身观测空间、当前状态和剩余n-1智能体的动作,并生成相应动作与攻防环境进行交互,获得相应的奖励、新状态;p的初始值为1,且每个采样批次下,l的初始值为1;
[0061]
s23、判断第p个采样批次下的第l次采样,是否出现智能体坠毁,结果为是,执行步骤s24;结果为否,执行步骤s25;
[0062]
s24、将第p个采样批次下第l次采样获得的所有数据删除,令p=p 1,再对第p个采样批次下的所有智能体的当前状态重新初始化,执行步骤s22;
[0063]
s25、将第p个采样批次下第l次采样获得的攻防环境中所有智能体的当前状态、动作、奖励和新状态,作为当前第p个采样批次下的一个样本存入数据集知识库,执行步骤s26;
[0064]
s26、判断数据集知识库内的样本数量是否达到m,结果为否,执行步骤s27,结果为
是,执行步骤s28;
[0065]
s27、当当前第p个采样批次下样本数量达到45或进攻方内的智能体撞击目标地标时,令p=p 1,执行步骤s22;否则,令l=l 1,执行步骤s22;
[0066]
s28、结束,完成数据集知识库的构建。
[0067]
传统的maddpg算法在集中式训练框架下,深度神经网络需要所有智能体信息输入,若使坠毁的智能体继续在环境中交互,则必然会影响其他智能体的决策,在智能体坠毁后,其会对其余正常工作智能体的决策产生影响,这种影响不可以忽略。本发明在智能体坠毁后将该智能体冻结,不再与环境交互。对于坠毁的智能体,不对其所在采样批次下继续采样,完成当前采样批次下的采样操作,同时,对下一采样批次下的所有智能体的当前状态重新初始化,实现下一轮采样批次下的采样操作。因此,本发明在构建样本集的过程中,可保证每个采样批次下所有样本数据维度相同;也就是说,智能体坠毁后更新所有神经网络参数时只使用智能体坠毁前的数据。
[0068]
具体的,s4、在当前攻防环境和预设攻防轮次下,使训练后的各智能体进行攻防决策的实现方式包括:
[0069]
在每个攻防轮次下,使训练后的各智能体根据自身观测空间做出相应的动作。
[0070]
例如,场景可由m个防守的智能体,n个进攻的智能体和1个目标地标组成。每个智能体均为同构的四旋翼飞行器,其动力学模型为:
[0071][0072][0073][0074][0075][0076][0077]
其中,分别为滚转、俯仰和偏航角的角加速度;分别为滚转、俯仰和偏航角的角速度;m四旋翼飞行器质量;i
xx
,i
yy
,i
zz
分别为x,y,z三轴的惯性矩;m
x
,my,mz分别为x,y,z三轴的气动力矩;fz是竖直方向的空气动力,g为重力加速度;本发明中假设四旋翼飞行器在固定高度飞行,即为z轴方向的期望加速度,为x轴方向的期望加速度,为y轴方向的期望加速度。通过改进传统的maddpg算法,训练出x轴、y轴方向的期望加速度构成的合成期望加速度,并使用pid控制器控制飞行器移动。
[0078]
进攻智能体的目标是撞击目标地标,同时躲避防守智能体的拦截;防守智能体的目标是合作拦截进攻智能体撞击目标地标。每个智能体不知道其他智能体的动作策略等信
息。上述场景可描述为一个攻防博弈场景,进攻智能体和防守智能体双方的最终目标分别是撞击目标地标和阻止对方撞击目标地标。为达成各自的最终目标,双方在博弈过程中涉及拦截与反拦截,部分智能体可能因碰撞坠毁。
[0079]
奖励的设置是对智能体的有效激励,进攻智能体的目标是撞击目标地标,同时尽量远离防守智能体,避免被撞击坠毁。本发明给出了一种距离-撞击组合奖励形式,第i个进攻智能体的奖励函数由两部分组成,形式如下:
[0080]ri
=r
idis
r
icol
;
[0081][0082][0083]
其中,r
idis
为进攻方的第i个智能体的距离奖励,r
icol
为进攻方的第i个智能体的撞击奖励,d(i,goal)为进攻方的第i个智能体与目标地标的距离,d(i,goodj)为进攻方的第i个智能体与防守方的第j个智能体的距离;
[0084]
防守智能体的目标是阻止进攻智能体撞击目标地标,需要对进攻智能体实施拦截,同时避免与进攻智能体撞击。防守智能体的奖励函数分为两部分,一部分是根据进攻智能体距离目标地标获得的r
iadv
,另一部分是根据防守智能体与进攻智能体的距离获得的r
igood
,第i个防守智能体的奖励函数形式如下
[0085]ri
=r
iadv
r
igood
;
[0086][0087][0088]
其中,r
iadv
为防守方的第i个智能体的第一距离奖励,r
igood
为防守方的第i个智能体的第二距离奖励,d(goal,advj)为进攻方的第j个智能体与目标地标的距离;d(i,advj)为防守方的第i个智能体与进攻方的第j个智能体的距离。可以看到,r
iadv
和r
igood
都是基于距离的奖励函数。所有防守智能体之间通过合作关系来抵御进攻智能体的撞击,可对防守智能体方设计一个合作奖励,即为所有防守智能体的奖励的平均值:
[0089]
通过以下来验证本发明的技术效果,具体为:
[0090]
假设:总智能体的数量为6,其中,防守方的智能体数量为3,进攻方的智能体数量为3,为了方便描述飞行器之间的碰撞,将飞行器的包络视作二维平面中半径大小相同的圆形,具体参见图2,图2中,黑色圆为目标地标,灰色圆为进攻方的飞行器,白色圆为防守方的飞行器;
[0091]
每个智能体内的深度神经网络可由一个两层relu参数化的mlp组成,每一层有64个神经元,我们使用学习率为0.01的adam优化器和τ=0:01来更新深度神经网络,τ表示滑动平均更新的系数。折扣因子设置为0.95,经验回放池的大小为106(也即:数据集知识库内的样本数量),每次抽取用于更新神经网络的数据容量大小为1024。
[0092]
在训练阶段所有智能体平均奖励曲线如图3所示。对于maddpg算法,为了比较其与
本发明方法的效果,假设在训练过程中智能体碰撞后不不坠毁;而本发明方法在训练过程中智能体碰撞坠毁。从图3中可以看出,在6500次训练后,本发明方法获得的场景中所有智能体的平均奖励曲线,始终位于传统maddpg方法平均奖励曲线的上方,且从本发明方法获得的所有智能体的平均奖励曲线可看出,在5000次至6000次所在的一段曲线更加的平稳,说明本发明对深度神经网络训练的效果更好。
[0093]
若攻守双方智能体之间发生碰撞坠毁,此时,对于现有的maddpg算法,在获得样本的过程中,若攻守双方智能体之间发生碰撞坠毁,仍然继续获得样本,此时,对于现有的maddpg算法所获得的每一样本中由于存在智能体坠毁的情况存在,导致有些样本之中存在数据维度缺失,在后续训练过程中,当输入至智能体内的数据维度缺失时,无法继续执行,训练过程被迫截止。而对于本发明方法当出现智能体碰撞坠毁时,此时的数据不作为样本进行存储,且更新智能体的当前状态,重新进行样本采样,这样使得所采集的所有样本的维度相同,不会导致训练被迫截止,保证了样本维度相同,为后续精确训练提供准确的数据基础。
[0094]
在执行阶段所有智能体平均奖励如图4所示。在执行场景中,分别使用两种算法训练出的结果进行仿真,智能体会碰撞坠毁。图4中,分别使用两种算法各执行50000步仿真,仿真步长为0.05s,执行的奖励曲线,具体参见图4;本发明方法最小平均奖励为-60.97,传统的maddpg算法最小平均奖励为-175.23,本发明相较传统方法在性能上有着显著的优势。预设每个执行轮次中最大执行步数为45步情况下,本发明方法可执行4101个轮次,传统的maddpg算法可执行1917个轮次,由于本发明方法可执行轮次大于传统的maddpg算法的可执行轮次,说明每个执行轮次下,执行的步数少,步数少就说明更高效,即:说明本发明方法相较maddpg算法在每个执行轮次中执行步数更少,本发明方法更为高效,性能更为优越。
[0095]
实施例2:
[0096]
本实施例2所述的一种计算机可读的存储设备,所述存储设备存储有计算机程序,其特征在于,所述计算机程序被执行时所述基于深度强化学习的多智能体攻防决策方法。
[0097]
实施例3:
[0098]
本实施例3所述的一种基于深度强化学习的多智能体攻防决策装置,包括存储设备、处理器以及存储在所述存储设备中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序实现所述基于深度强化学习的多智能体攻防决策方法。
[0099]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。