1.本发明涉及声学诊断领域,尤其涉及一种可迁移的特征自动选取声学诊断方法及系统。
背景技术:
2.基于声学特征的诊断主要包含特征提取和分类识别两个部分。当某一设备在运行的过程中,会由振动产生声信号,声信号中包含着设备的状态信息。当设备的某一状态发生变化时,其声信号的某些特征也会发生相应的变化。特征提取,是声学诊断中最具难点的部分,其任务在于利用一系列有目的的数据运算方式对信号进行处理,使信号更加接近纯粹本质的信息。
3.而声音信号的特征参数一般可以分为时域特征、频域特征等类型,特征的种类繁多,如何使提取的特征更有利于后续的分类识别是整个声学诊断的核心。因此,声学特征选择技术在声学诊断领域尤为重要。
4.目前,声学诊断领域选取声学信号的特征大多是凭借专家经验进行选取,而特征选择对模型性能有着直接的影响。如果选取的特征不合适或者特征选取不足,可能不能准确的涵盖故障信息,如果选取的特征过多又会使数据包含许多无关特征和冗余特征,直接使用这样的训练数据不但会消耗大量的计算资源,而且可能给模型带来过拟合的风险。
5.所以需要研究合适的特征选择方法来优选特征。由于单一的特征选择方法在空间中搜索的能力有限,不同的特征选择方法可能产生不同的选择结果。
6.因此,单一的特征选择方法可能会在筛选特征过程中忽略一些潜在信息,存在容易陷入局部最优,鲁棒性较差的问题。
7.上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
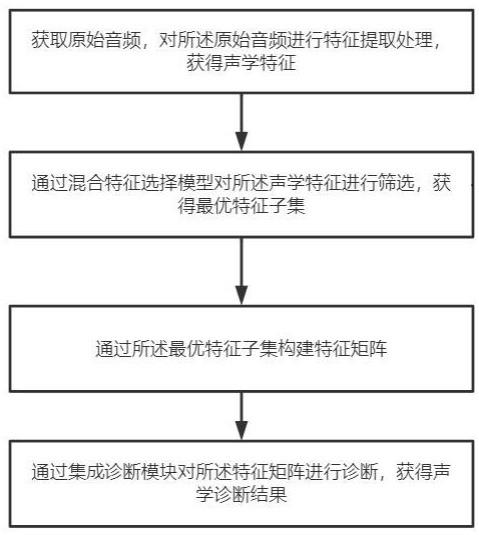
8.为解决上述技术问题,本发明提供一种可迁移的特征自动选取声学诊断方法,包括:s1:获取原始音频,对所述原始音频进行特征提取处理,获得声学特征;s2:通过混合特征选择模型对所述声学特征进行筛选,获得最优特征子集;s3:通过所述最优特征子集构建特征矩阵;s4:通过集成诊断模块对所述特征矩阵进行诊断,获得声学诊断结果。
9.优选的,步骤s1具体为:s11:对所述原始音频依次进行预加重处理、分帧处理和加窗处理,获得预处理后的音频;s12:从所述预处理后的音频中提取声学特征,所述声学特征包括:时域特征、频域特征、小波域特征和波形特征。
10.优选的,所述混合特征选择模型包括:sfs-svm模型、sfs-knn模型、rfe-rf模型、rfe-xgb模型和mic模型。
11.优选的,步骤s2具体为:s21:通过sfs-svm模型计算获得sfs-svm模型准确率达到最高时所用的特征集合f
t1
,通过sfs-knn模型计算获得sfs-knn模型准确率达到最高时所用的特征集合f
t2
;s22:通过rfe-rf模型计算获得rfe-rf模型准确率达到最高时所用的特征集合f
t3
,通过rfe-xgb模型计算获得rfe-xgb模型准确率达到最高时所用的特征集合f
t4
;s23:通过mic模型计算获得mic模型的最优特征的排序rank
mic
;s24:计算获得最优特征子集的最大集合f
max
和最优特征子集的最小集合f
min
;,;s25:构建新排名,获取新排名下前t个特征集合f
t
,f
t
满足条件:;s26:计算获得最优特征子集fa,;为最小特征子集选取函数。
12.优选的,步骤s21具体为:s211:设置svm特征集合、knn特征集合和计数k,将svm特征集合初始化为空集f
(svm,0)
,将knn特征集合初始化为空集f
(knn,0)
,将k的值初始化为1;s212:判断计数k的值,若k≤m则进入步骤s213,否则进入步骤s218;m为提取的声学特征集合中的特征数量;s213:计算获得第k次sfs-svm模型的最优特征f
tk
,计算公式为:其中,为最优特征选取函数,f
(svm,k-1)
为第k-1次更新后的svm特征集合,g
svm
()为sfs-svm模型的评价函数,x为声学特征数据,f为声学特征集合,fj为声学特征集合中的第j个特征,j为特征的编号;s214:将f
tk
添加至svm特征集合中,获得第k次更新后的svm特征集合f
(svm,k)
,计算公式为:;通过第k次svm的评价函数获得第k次更新后的svm特征集合的准确率,计算公式为:s215:计算获得第k次sfs-knn模型的最优特征f
pk
,计算公式为:
其中,f
(knn,k-1)
为第k-1次更新后的knn特征集合,g
knn
()为sfs-knn模型的评价函数;s216:将f
pk
添加至knn特征集合中,获得第k次更新后的knn特征集合f
(knn,k)
,计算公式为:;通过第k次knn的评价函数获得第k次更新后的knn特征集合的准确率,计算公式为:s217:令k=k 1,返回步骤s212;s218:计算获得svm的最终排序,计算公式为:;其中,rank
(svm,f)
为svm特征集合中最优特征的排序,为svm特征集合中准确率的排序;计算获得knn的最终排序,计算公式为:;其中,rank
(knn,f)
为knn特征集合中最优特征的排序,为knn特征集合中准确率的排序;s219:计算获得sfs-svm模型准确率达到最高时所用的特征集合f
t1
,计算公式为:其中,t1为sfs-svm模型达到最高准确率时所用特征个数;计算获得sfs-knn模型准确率达到最高时所用的特征集合f
t2
,计算公式为:其中,t2为sfs-knn模型达到最高准确率时所用特征个数。
13.优选的,步骤s22具体为:s221:设置rf特征集合、xgb特征集合和计数k,将rf特征集合初始化为满集,将xgb特征集合初始化为满集,将k的值初始化为1;s222:判断计数k的值,若k≤m则进入步骤s223,否则进入步骤s228;m为提取的声学特征特征数量;s223:计算获得第k次rfe-rf模型的贡献度最小特征f
qk
,计算公式为:其中,d
rf
()为rfe-rf模型的建模函数,f
(rf,k-1)
为第k-1次更新后的rf特征集合,x为声学特征数据,f为声学特征集合,fj为声学特征集合中的第j个特征,j为特征的编号;s224:将f
qk
从rf特征集合中剔除,获得第k次更新后的rf特征集合f
(rf,k)
,计算公式为:;
通过第k次rf的评价函数获得第k次更新后的rf特征集合的准确率,计算公式为:s225:计算获得第k次rfe-xgb模型的贡献度最小特征f
zk
,计算公式为:其中,f
(xgb,k-1)
为第k-1次更新后的xgb特征集合,d
xgb
()为rfe-xgb模型的建模函数;s226:将f
zk
从xgb特征集合中剔除,获得第k次更新后的xgb特征集合f
(xgb,k)
,计算公式为:;通过第k次xgb的评价函数获得第k次更新后的xgb特征集合的准确率,计算公式为:s227:令k=k 1,返回步骤s222;s228:计算获得rf的最终排序,计算公式为:;其中,rank
(rf,f)
为rf特征集合中最优特征的排序,为rf特征集合中准确率的排序;计算获得xgb的最终排序,计算公式为:;其中,rank
(xgb,f)
为xgb特征集合中最优特征的排序,为xgb特征集合中准确率的排序;s229:计算获得rfe-rf模型准确率达到最高时所用的特征集合f
t3
,计算公式为:其中,t3为rfe-rf模型达到最高准确率时所用特征个数;计算获得rfe-xgb模型准确率达到最高时所用的特征集合f
t4
,计算公式为:其中,t4为rfe-xgb模型达到最高准确率时所用特征个数。
14.优选的,步骤s25中所述新排名的表达式为:其中,rerank(f)为新排名;li依次代表sfs-svm模型,sfs-knn模型,rfe-rf模型,
rfe-xgb模型和mic模型对应的最优特征的排序,其中i=1,
…
,n,n=5。
15.优选的,所述集成诊断模块包括:svm学习器、knn学习器、随机森林学习器和xgboost学习器;通过所述svm学习器对所述特征矩阵进行诊断,获得svm诊断结果;通过所述knn学习器对所述特征矩阵进行诊断,获得knn诊断结果;通过所述随机森林学习器对所述特征矩阵进行诊断,获得随机森林诊断结果;通过所述xgboost学习器对所述特征矩阵进行诊断,获得xgboost诊断结果;通过所述xgboost学习器对所述svm诊断结果、所述knn诊断结果、所述随机森林诊断和所述xgboost诊断结果进行结合,获得声学诊断结果。
16.一种可迁移的特征自动选取声学诊断系统,包括:声学特征获取模块,用于获取原始音频,对所述原始音频进行特征提取处理,获得声学特征;最优特征子集获取模块,用于通过混合特征选择模型对所述声学特征进行筛选,获得最优特征子集;矩阵构建模块,用于通过所述最优特征子集构建特征矩阵;诊断模块,用于通过集成诊断模块对所述特征矩阵进行诊断,获得声学诊断结果。
17.本发明具有以下有益效果:本发明通过sfs-svm模型、sfs-knn模型、rfe-rf模型、rfe-xgb模型和mic模型综合构建的混合特征选择模型,可以将多种特征选择方法获得的选择结果进行综合分析,获得最佳的声学诊断,极大的提高了声学诊断结果的鲁棒性。
附图说明
18.图1为本发明实施例方法流程图;图2为本发明实施例系统结构图;本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
19.应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
20.参照图1,本发明提供一种可迁移的特征自动选取声学诊断方法,包括:s1:获取原始音频,对所述原始音频进行特征提取处理,获得声学特征;s2:通过混合特征选择模型对所述声学特征进行筛选,获得最优特征子集;s3:通过所述最优特征子集构建特征矩阵;s4:通过集成诊断模块对所述特征矩阵进行诊断,获得声学诊断结果。
21.本实施例中,步骤s1具体为:s11:对所述原始音频依次进行预加重处理、分帧处理和加窗处理,获得预处理后的音频;s12:从所述预处理后的音频中提取声学特征,所述声学特征包括:时域特征(mean value、variance、mean amplitude、short time energy、root mean square、square root amplitude、standard deviation、zero crossing rate);
频域特征(mfcc、mel spectrogram、spectral centroid、spectral bandwidth、spectral contrast、spectral flatness、spectral rolloff);小波域特征(wavelet mean frequency、wavelet entropy);和波形特征(crest factor、shape factor、skewness factor、impulse factor、margin factor、kurtosis、kurtosis factor);和一些其它特征(tonnetz、chroma stft、chroma cqt、chroma cens)。
22.本实施例中,所述混合特征选择模型(hfs)包括:sfs-svm模型、sfs-knn模型、rfe-rf模型、rfe-xgb模型和mic模型。
23.具体的,通过多种模型构建的混合特征选择模型能有效减少无关特征和冗余特征,优选出最优特征子集;在hfs算法中,为了让特征选择方法具有代表性,一共选取了5种基于不同原理的特征选择方法,涵盖了过滤法、包装法和嵌入法。
24.包装法(wrapper)是一种特征选择过程与学习算法结合的特征选择方法,wrapper将选用的学习器封装成黑盒,根据它在特征子集上的预测精度评价所选特征的优良,并采用搜索策略调整子集,最终获得近似的最优子集。
25.包装式特征选择方法每每由两部分组成,即搜索策略和学习算法,学习算法主要用来评判特征子集的优劣,学习算法的选取不受限制,分类问题可使用支持向量机(svm)、k 近邻(knn)等。这里我们选用序列前向搜索(sfs)作为搜索策略,svm和knn作为学习算法。序列前向搜索(sfs)是每次贪心地把得分最高的特征加入到已选特征子集当中。构建sfs-svm模型和sfs-knn模型,每个模型依次不停地选择单个特征加入上一步骤刚开始为空集的特征子集中,每次加入的单个特征是使得评估器准确率在当前特征个数下取得最优特征;嵌入式特征选择算法嵌入在学习算法当中,当分类算法训练过程结束就可以得到特征子集。嵌入式特征选择算法没有统一的流程框架图,不同的算法框架各异。分类树模型是经典的嵌入式特征选择算法。
26.随机森林(rf)和xgboost(xgb)是目前以树模型为结构的具有代表性的特征选择算法,因此嵌入法选用随机森林(rf)和xgboost(xgb),为了能反映特征子集影响分类器性能的变化,使用去除冗余特征较好的递归消除法(rfe)结合随机森林和xgboost,构建rfe-rf和rfe-xgb模型,模型通过多轮训练,每轮剔除掉一个特征贡献度最小的特征重新建模。
27.过滤法是利用各特征的数理特性来对特征进行选择,可以反映特征与标签之间的相关性。具有很强的普适性,可识别任何函数关系,对复杂的声学特征具有很好的识别效果。因此过滤法中采用mic。
28.本实施例中,步骤s2具体为:s21:通过sfs-svm模型计算获得sfs-svm模型准确率达到最高时所用的特征集合f
t1
,通过sfs-knn模型计算获得sfs-knn模型准确率达到最高时所用的特征集合f
t2
;s22:通过rfe-rf模型计算获得rfe-rf模型准确率达到最高时所用的特征集合f
t3
,通过rfe-xgb模型计算获得rfe-xgb模型准确率达到最高时所用的特征集合f
t4
;s23:通过mic模型计算获得mic模型的最优特征的排序rank
mic
;s24:计算获得最优特征子集的最大集合f
max
和最优特征子集的最小集合f
min
;,;
具体的,表示两个集合合并,表示两个集合相交;s25:构建新排名,获取新排名下前t个特征集合f
t
,f
t
满足条件:;具体的,t=max(t1,t2,t3,t4),即t选取t1,t2,t3,t4中的最大值;s26:计算获得最优特征子集fa,;为最小特征子集选取函数。然后取其中的最大值个数t为阈值,输出新特征排名下的前t个数为最优特征子集fa。
29.本实施例中,步骤s21具体为:s211:设置svm特征集合、knn特征集合和计数k,将svm特征集合初始化为空集f
(svm,0)
,将knn特征集合初始化为空集f
(knn,0)
,将k的值初始化为1;s212:判断计数k的值,若k≤m则进入步骤s213,否则进入步骤s218;m为提取的声学特征集合中的特征数量;s213:计算获得第k次sfs-svm模型的最优特征f
tk
,计算公式为:其中,为最优特征选取函数,f
(svm,k-1)
为第k-1次更新后的svm特征集合,g
svm
()为sfs-svm模型的评价函数,x为声学特征数据,f为声学特征集合,fj为声学特征集合中的第j个特征,j为特征的编号;具体的,最优特征选取函数的运算过程为:在特征集合中选取特征fj,fj能使评价函数g
svm
()的值取得最大,此时将特征fj作为最优特征f
tk
;声学特征集合f用于存放各声学特征数据;s214:将f
tk
添加至svm特征集合中,获得第k次更新后的svm特征集合f
(svm,k)
,计算公式为:;通过第k次svm的评价函数获得第k次更新后的svm特征集合的准确率,计算公式为:s215:计算获得第k次sfs-knn模型的最优特征f
pk
,计算公式为:其中,f
(knn,k-1)
为第k-1次更新后的knn特征集合,g
knn
()为sfs-knn模型的评价函数;具体的,最优特征选取函数的运算过程为:在特征集合中选取特征fj,fj能使评价函数g
knn
()的值取得最大,此时将特征fj作为最优特征f
pk
;s216:将f
pk
添加至knn特征集合中,获得第k次更新后的knn特征集合f
(knn,k)
,计算公式为:;通过第k次knn的评价函数获得第k次更新后的knn特征集合的准确率,计算公式为:s217:令k=k 1,返回步骤s212;s218:计算获得svm的最终排序,计算公式为:;其中,rank
(svm,f)
为svm特征集合中最优特征的排序,为svm特征集合中准确率的排序;计算获得knn的最终排序,计算公式为:;其中,rank
(knn,f)
为knn特征集合中最优特征的排序,为knn特征集合中准确率的排序;s219:计算获得sfs-svm模型准确率达到最高时所用的特征集合f
t1
,计算公式为:其中,t1为sfs-svm模型达到最高准确率时所用特征个数;计算获得sfs-knn模型准确率达到最高时所用的特征集合f
t2
,计算公式为:其中,t2为sfs-knn模型达到最高准确率时所用特征个数。
30.本实施例中,步骤s22具体为:s221:设置rf特征集合、xgb特征集合和计数k,将rf特征集合初始化为满集,将xgb特征集合初始化为满集,将k的值初始化为1;s222:判断计数k的值,若k≤m则进入步骤s223,否则进入步骤s228;m为提取的声学特征集合中的特征数量;s223:计算获得第k次rfe-rf模型的贡献度最小特征f
qk
,计算公式为:其中,d
rf
()为rfe-rf模型的建模函数,f
(rf,k-1)
为第k-1次更新后的rf特征集合,x为声学特征数据,f为声学特征集合,fj为声学特征集合中的第j个特征,j为特征的编号;具体的,最差特征选取函数的运算过程为:将fj从f
(rf,k-1)
中剔除,使用rfe-rf模型的建模函数drf()从剔除后的f
(rf,k-1)
中获取此次最差特征f
qk
;s224:将f
qk
从rf特征集合中剔除,获得第k次更新后的rf特征集合f
(rf,k)
,计算公式
为:;通过第k次rf的评价函数获得第k次更新后的rf特征集合的准确率,计算公式为:s225:计算获得第k次rfe-xgb模型的贡献度最小特征f
zk
,计算公式为:其中,f
(xgb,k-1)
为第k-1次更新后的xgb特征集合,d
xgb
()为rfe-xgb模型的建模函数;具体的,最差特征选取函数的运算过程为:将fj从f
(xgb,k-1)
中剔除,使用rfe-xgb模型的建模函数d
xgb
()从剔除后的f
(xgb,k-1)
中获取此次最差特征f
zk
;s226:将f
zk
从xgb特征集合中剔除,获得第k次更新后的xgb特征集合f
(xgb,k)
,计算公式为:;通过第k次xgb的评价函数获得第k次更新后的xgb特征集合的准确率,计算公式为:s227:令k=k 1,返回步骤s222;s228:计算获得rf的最终排序,计算公式为:;其中,rank
(rf,f)
为rf特征集合中最优特征的排序,为rf特征集合中准确率的排序;计算获得xgb的最终排序,计算公式为:;其中,rank
(xgb,f)
为xgb特征集合中最优特征的排序,为xgb特征集合中准确率的排序;s229:计算获得rfe-rf模型准确率达到最高时所用的特征集合f
t3
,计算公式为:其中,t3为rfe-rf模型达到最高准确率时所用特征个数;计算获得rfe-xgb模型准确率达到最高时所用的特征集合f
t4
,计算公式为:
其中,t4为rfe-xgb模型达到最高准确率时所用特征个数。
31.本实施例中,步骤s25中所述新排名的表达式为:其中,rerank(f)为新排名;li依次代表sfs-svm模型,sfs-knn模型,rfe-rf模型,rfe-xgb模型和mic模型对应的最优特征的排序,其中i=1,
…
,n,n=5。
32.本实施例中,所述集成诊断模块包括:svm学习器(持向量机(support vector machine,svm)是corinna cortes和vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。在机器学习中,支持向量机(svm,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析);knn学习器(knn算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别);随机森林学习器(机森林就是用过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支
‑‑‑‑‑‑
集成学习(ensemble learning)方法。集成学习就是使用一系列学习器进行学习,并将各个学习方法通过某种特定的规则进行整合,以获得比单个学习器更好的学习效果。集成学习通过建立几个模型,并将它们组合起来来解决单一预测问题。它的工作原理主要是生成多个分类器或者模型,各自独立地学习和作出预测);和xgboost学习器(xgboost是boosting算法的其中一种。boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为xgboost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是cart回归树模型);通过所述svm学习器对所述特征矩阵进行诊断,获得svm诊断结果;通过所述knn学习器对所述特征矩阵进行诊断,获得knn诊断结果;通过所述随机森林学习器对所述特征矩阵进行诊断,获得随机森林诊断结果;通过所述xgboost学习器对所述特征矩阵进行诊断,获得xgboost诊断结果;通过所述xgboost学习器对所述svm诊断结果、所述knn诊断结果、所述随机森林诊断和所述xgboost诊断结果进行结合,获得声学诊断结果。
33.本发明提供一种可迁移的特征自动选取声学诊断系统,包括:声学特征获取模块,用于获取原始音频,对所述原始音频进行特征提取处理,获得声学特征;最优特征子集获取模块,用于通过混合特征选择模型对所述声学特征进行筛选,获得最优特征子集;
矩阵构建模块,用于通过所述最优特征子集构建特征矩阵;诊断模块,用于通过集成诊断模块对所述特征矩阵进行诊断,获得声学诊断结果。
34.需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
35.上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
36.以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。