1.本发明涉及个性化联邦学习技术领域,尤其涉及个性化联邦学习的训练效率与个性化效果量化评估方法。
背景技术:
2.联邦机器学习(federated machine learning/federated learning),又名联邦学习、联合学习、联盟学习。是一种先进的机器学习框架,能有效帮助多个客户端在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。
3.联邦学习作为分布式的机器学习范式,可以有效解决数据孤岛问题,让参与方在不共享数据的基础上联合建模,从技术上打破数据孤岛,实现人工智能(ai)中的协作。
4.联邦学习的一大挑战便是异质性,异质性主要分三种,分别是数据异质性和设备异质性和模型异质性。
5.数据异质性主要是由参与训练的各客户端的数据虽独立分布但不服从同一采样方法(non-iid)所导致的,传统的联邦学习算法在数据异构(non-iid)的情况下很容易产生client-drift的现象,即本地更新和全局更新的不一致,这种不一致会导致系统的收敛不稳定或者缓慢。
6.设备异质性主要是各个客户机(设备)在存储、计算和通信能力方面存在异构性,这种设备的异质性会导致本地模型在收敛速率和通信时间方面有很大的差异性。
7.模型异构性主要是指成功收敛的全局模型不能满足各个客户机的实际场景,导致不能为客户端提供具有个性化的内容和服务。
8.为了解决这些异构性挑战,一种有效的方法是在设备、数据和模型级别上进行个性化处理,以减轻异构性并为每个设备获得高质量的个性化模型,即个性化联邦学习。
9.此外,在现存的研究通常使用测试的准确性和损失函数的收敛时间作为联邦学习的评价指标,但很少有合适的方法对个性化联邦学习的训练效率和个性化指标做出定性的评价。
技术实现要素:
10.本发明的目的是为了解决现有技术中存在的缺点,而提出的个性化联邦学习的训练效率与个性化效果量化评估方法。
11.为了实现上述目的,本发明采用了如下技术方案:
12.个性化联邦学习的训练效率与个性化效果量化评估方法,包括以下步骤:
13.s1、创建一个non-iid的跨域数据集,作为评测数据集;
14.s2、选择合适的模型,作为个性化联邦学习的初始全局模型;
15.s3、进行联邦学习的全局神经网络训练,聚合出一个收敛的全局神经网络模型;
16.s4、各个客户端利用本地的数据集对下发的全局模型进行优化,收敛并形成个性化的本地神经网络模型;
17.s5、进行全局模型训练效率和个性化效果指标设计。
18.优选的,所述s1中,创建一个non-iid的跨域数据集,作为评测数据集,具体步骤包括:
19.采用跨域数据集:office-home数据集,作为评测数据集,对于该数据集,使用原始测试数据集的一半作为公共数据集,其余的作为最终测试数据集,使用dirichlet分布来模拟各方之间的异构数据分区,假设有k个客户端,根据pk~dirn(β)进行采样,并将标签m的比例为p
k,j
的样本分配客户端j,作为本地数据集dj,其中dir(.)代表狄利克雷分布,参数β=0.5。
20.优选的,所述s2中,选择合适的模型,作为个性化联邦学习的初始全局模型,具体步骤包括:
21.使用resnet18作为全局模型,模型由1个卷积层和8个残差块以及1个全连接层组成。
22.优选的,所述s3中,进行联邦学习的全局神经网络训练,聚合出一个收敛的全局神经网络模型,具体步骤包括:
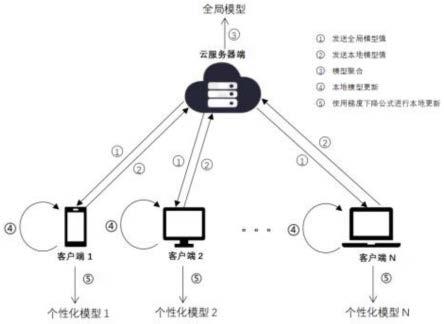
23.步骤4-1,服务器随机挑选异质客户端,并将全局模型参数进行广播;
24.步骤4-2,客户端根据全局模型参数,利用本地测试数据进行训练,将所得的本地模型参数传回服务器;
25.步骤4-3,服务器聚合这些参数得到下一轮初始参数,重复步骤4-1,4-2,4-3直至全局模型收敛。
26.优选的,步骤4-1,服务器随机挑选一批客户端,并将全局模型参数进行广播,具体步骤包括:
27.步骤5-1,假设所有客户端达到模型优化拟合状态需要的整体通信次数为t,对于其中的第t轮模型联合训练,t=1,2,
…
,t;
28.步骤5-2,确定客户端总数为k,客户端设备异质,如手机、平板、监控摄像头等,被选中的客户端个数为n,第k个客户端被选中的概率为pk;
29.步骤5-3,服务器首先根据概率pk随机选出一批客户端,它们的集合为s
t
;
30.步骤5-4,服务器将当前的参数w
t
发送给被选中的客户端。
31.优选的,客户端根据全局模型参数,利用本地测试数据进行训练,将所得的本地模型参数传回服务器,具体步骤包括:
32.客户端n收到全局模型信息w
t
,并利用本地数据集进行训练,得到本地模型并将本地模型参数传递给服务器。
33.优选的,每个客户端将得到的不精确解传递回服务器,服务器聚合这些参数得到下一轮初始参数,重复步骤4-1,4-2,4-3直至全局模型收敛,其具体步骤包括:
34.步骤7-1,服务器在第t个通信轮次中接收到第k个客户端所提交的本地模型信息
35.步骤7-2,服务器通过对得到的所有的本地模型参数进行加权平均,聚合为全局模型;
36.步骤7-3,重复步骤4-1、4-2、4-3,直至全局模型收敛。
37.优选的,所述s4中,各个客户端利用本地的数据集对下发的全局模型进行优化,收敛并形成个性化的本地神经网络模型,具体步骤包括:
38.步骤8-1,在第i轮前向计算 反向传播过程的第b批中,每个客户端k求解步骤6-2中的最优个性化问题以获得其个性化模型;
39.步骤8-2,客户端k利用梯度下降的公式进行本地更新,具体公式为
[0040][0041]
其中η是学习率,是客户端n数据批次为b时本地模型的梯度。
[0042]
优选的,所述s5中,进行全局模型训练效率和个性化效果指标设计,具体步骤包括:
[0043]
步骤9-1,我们将训练效率s
global
作为全局模型训练效率指标,具体定义为集中式训练时的全局准确率与训练周期t的加权值即:
[0044][0045]
f1
center
是初始全局模型resnet18使用初始最终测试数据集进行训练时的f1分数是进行全局训练时,客户端n
[0046]
其中,
[0047]
p为测试的精确率,可定义为:
[0048]
r为召回率,可定义为:
[0049]
tp即true positive,真阳性,指模型预测为正的正样本;
[0050]
fp,fn为计算错误的结果数,其中fp即false positive,假阳性,指被模型预测为正的负样本;fn即false negative,假阴性,指模型预测为负的正样本;
[0051]
t
center
是联邦全局训练时所需收敛周期;
[0052]
μ1 μ2=1,默认都取可根据实际情况进行修改;
[0053]
根据常规的定义,假设优化算法的目标是其中,w是参数空间,f(ω)是目标函数;记算法在迭代第t步输出的模型参数是ω
t
,最优的模型参数为如果两者在参数空间的距离或者对于的目标函数值有以下上界:
[0054]
e||ω
t-ω
*
||2≤ε(t)or ef(ω
t
)-f(ω
*
)≤ε(t)
[0055]
并且ε(t)随t
→
∞收敛到0,那么称这个算法是收敛的,此时称logε(t)关于t的阶数为算法的收敛速率,
[0056]
步骤9-2,我们将训练效果e
indivi
作为个性化效果指标,具体可定义为个性化f1分
数相比全局f1分数的提升,即:
[0057][0058]
其中,为个性化训练阶段时,使用本地测试集训练更新后的本地模型所得到的f1分数。
[0059]
本发明中,所述个性化联邦学习的训练效率与个性化效果量化评估方法的有益效果:
[0060]
本发明充分考虑了跨域异质的场景,实现了模型的个性化功能,在现有研究的基础上,针对个性化联邦学习训练效率和个性化效果给出定性定量的评价指标,为在跨域异质场景下,为衡量不同个性化联邦学习算法与架构提供了一种具体方法。
附图说明
[0061]
图1为本发明提出的个性化联邦学习的训练效率与个性化效果量化评估方法的算法结构图;
[0062]
图2为本发明提出的个性化联邦学习的训练效率与个性化效果量化评估方法的算法流程图;
[0063]
图3为本发明提出的个性化联邦学习的训练效率与个性化效果量化评估方法的resnet18结构图。
具体实施方式
[0064]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0065]
参照图1-3,个性化联邦学习的训练效率与个性化效果量化评估方法,包括以下步骤:
[0066]
s1、创建一个non-iid的跨域数据集,作为评测数据集;
[0067]
s2、选择合适的模型,作为个性化联邦学习的初始全局模型;
[0068]
s3、进行联邦学习的全局神经网络训练,聚合出一个收敛的全局神经网络模型;
[0069]
s4、各个客户端利用本地的数据集对下发的全局模型进行优化,收敛并形成个性化的本地神经网络模型;
[0070]
s5、进行全局模型训练效率和个性化效果指标设计。
[0071]
本实施例中,s1中,创建一个non-iid的跨域数据集,作为评测数据集,具体步骤包括:
[0072]
采用跨域数据集:office-home数据集,作为评测数据集,对于该数据集,使用原始测试数据集的一半作为公共数据集,其余的作为最终测试数据集,使用dirichlet分布来模拟各方之间的异构数据分区,假设有k个客户端,根据pk~dirn(β)进行采样,并将标签m的比例为p
k,j
的样本分配客户端j,作为本地数据集dj,其中dir(.)代表狄利克雷分布,参数β=0.5。
[0073]
本实施例中,s2中,选择合适的模型,作为个性化联邦学习的初始全局模型,具体
步骤包括:
[0074]
使用resnet18作为全局模型,模型由1个卷积层和8个残差块以及1个全连接层组成。
[0075]
本实施例中,s3中,进行联邦学习的全局神经网络训练,聚合出一个收敛的全局神经网络模型,具体步骤包括:
[0076]
步骤4-1,服务器随机挑选异质客户端,并将全局模型参数进行广播;
[0077]
步骤4-2,客户端根据全局模型参数,利用本地测试数据进行训练,将所得的本地模型参数传回服务器;
[0078]
步骤4-3,服务器聚合这些参数得到下一轮初始参数,重复步骤4-1,4-2,4-3直至全局模型收敛。
[0079]
本实施例中,步骤4-1,服务器随机挑选一批客户端,并将全局模型参数进行广播,具体步骤包括:
[0080]
步骤5-1,假设所有客户端达到模型优化拟合状态需要的整体通信次数为t,对于其中的第t轮模型联合训练,t=1,2,
…
,t;
[0081]
步骤5-2,确定客户端总数为k,客户端设备异质,如手机、平板、监控摄像头等,被选中的客户端个数为n,第k个客户端被选中的概率为pk;
[0082]
步骤5-3,服务器首先根据概率pk随机选出一批客户端,它们的集合为s
t
;
[0083]
步骤5-4,服务器将当前的参数w
t
发送给被选中的客户端。
[0084]
本实施例中,客户端根据全局模型参数,利用本地测试数据进行训练,将所得的本地模型参数传回服务器,具体步骤包括:
[0085]
客户端n收到全局模型信息w
t
,并利用本地数据集进行训练,得到本地模型并将本地模型参数传递给服务器。
[0086]
本实施例中,每个客户端将得到的不精确解传递回服务器,服务器聚合这些参数得到下一轮初始参数,重复步骤4-1,4-2,4-3直至全局模型收敛,其具体步骤包括:
[0087]
步骤7-1,服务器在第t个通信轮次中接收到第k个客户端所提交的本地模型信息
[0088]
步骤7-2,服务器通过对得到的所有的本地模型参数进行加权平均,聚合为全局模型;
[0089]
步骤7-3,重复步骤4-1、4-2、4-3,直至全局模型收敛。
[0090]
本实施例中,s4中,各个客户端利用本地的数据集对下发的全局模型进行优化,收敛并形成个性化的本地神经网络模型,具体步骤包括:
[0091]
步骤8-1,在第i轮前向计算 反向传播过程的第b批中,每个客户端k求解步骤6-2中的最优个性化问题以获得其个性化模型;
[0092]
步骤8-2,客户端k利用梯度下降的公式进行本地更新,具体公式为
[0093][0094]
其中η是学习率,是客户端n数据批次为b时本地模型的梯度。
[0095]
本实施例中,s5中,进行全局模型训练效率和个性化效果指标设计,具体步骤包括:
[0096]
步骤9-1,我们将训练效率s
global
作为全局模型训练效率指标,具体定义为集中式训练时的全局准确率与训练周期t的加权值即:
[0097][0098]
f1
center
是初始全局模型resnet18使用初始最终测试数据集进行训练时的f1分数是进行全局训练时,客户端n
[0099]
其中,
[0100]
p为测试的精确率,可定义为:
[0101]
r为召回率,可定义为:
[0102]
tp即true positive,真阳性,指模型预测为正的正样本;
[0103]
fp,fn为计算错误的结果数,其中fp即false positive,假阳性,指被模型预测为正的负样本;fn即false negative,假阴性,指模型预测为负的正样本;
[0104]
t
center
是联邦全局训练时所需收敛周期;
[0105]
μ1 μ2=1,默认都取可根据实际情况进行修改;
[0106]
根据常规的定义,假设优化算法的目标是其中,w是参数空间,f(ω)是目标函数;记算法在迭代第t步输出的模型参数是ω
t
,最优的模型参数为如果两者在参数空间的距离或者对于的目标函数值有以下上界:
[0107]
e||ω
t-ω
*
||2≤ε(t)or ef(ω
t
)-f(ω
*
)≤ε(t)
[0108]
并且ε(t)随t
→
∞收敛到0,那么称这个算法是收敛的,此时称logε(t)关于t的阶数为算法的收敛速率,
[0109]
步骤9-2,我们将训练效果e
indivi
作为个性化效果指标,具体可定义为个性化f1分数相比全局f1分数的提升,即:
[0110][0111]
其中,为个性化训练阶段时,使用本地测试集训练更新后的本地模型所得到的f1分数。
[0112]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。