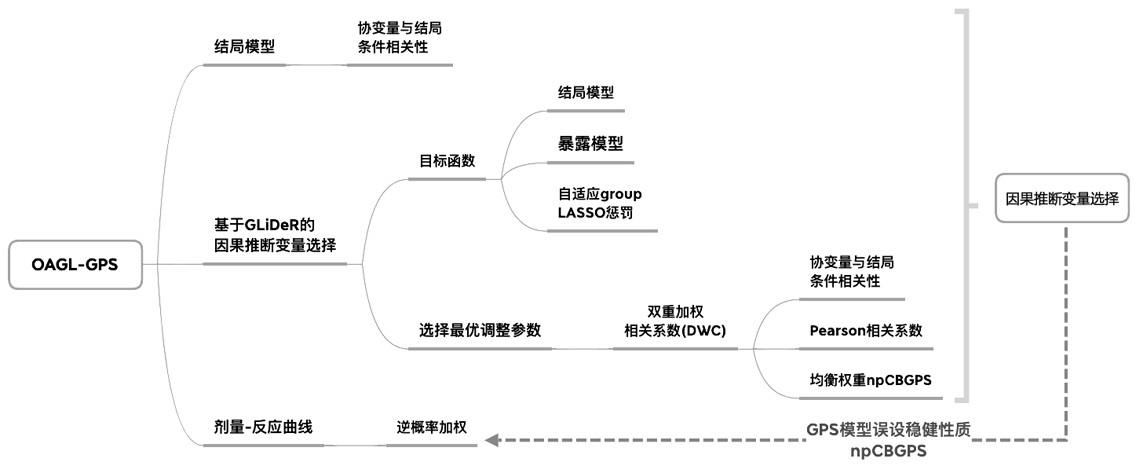
基于group lasso的高维广义倾向性评分方法
技术领域
1.本发明属于生物技术和数据分析技术领域,具体是一种基于group lasso 的高维广义倾向性评分方法。
背景技术:
2.在观察性研究中,如何有效地控制混杂因素,以实现处理(或暴露)效应的 无偏有效估计,是当今研究者广泛探讨的问题。广义倾向性评分方法 (generalized propensity score,gps)可控制已测量的混杂因素,估计连续型 暴露因素与健康结局间的剂量-反应函数(dose-response function,drf)。gps 定义为给定协变量x时暴露因素t在特定取值处的条件概率密度。利用gps的均 衡特性,可通过匹配、分层、回归调整、逆概率加权等方式实现处理效应的无偏 估计。gps方法的发展主要围绕避免gps模型或暴露因素的条件密度函数误设展 开,可分为两类:基于模型的gps方法和基于均衡性的gps方法。其中,基于 均衡性的gps方法因有明确的机制确保协变量在不同暴露水平间实现均衡且可 绕过gps模型和条件密度函数设定的难题而在近年来备受青睐。代表性的方法有 cbgps、npcbgps和ebct。然而这些方法并没有考虑变量选择的问题,因此不适 用于含有高维协变量的因果推断。
3.gps方法得到因果结论需要满足不存在未测量混杂假设。由于这一假设无法 检验,研究者们提倡尽可能多的考虑协变量使其合理。健康医疗大数据的涌现使 得这一假设成立的可能性变大,但同时也引入了高维协变量的问题。考虑到gps 方法对模型中纳入的协变量敏感,如纳入工具变量(与暴露因素有关但与健康结 局无关的协变量)会导致效应估计值的方差膨胀而不会降低偏倚等,因果推断变 量选择方法由此而得到发展。因果推断变量选择方法以针对性地选出混杂变量和 预后协变量(与健康结局有关但与暴露因素无关的协变量)为目的,代表性的方 法有oal和glider。模拟研究发现glider方法在模型误设和正确设定时表现均 较稳定,可以准确识别重要协变量同时效应估计值的偏倚小、精度高。然而, glider和oal是针对二分类暴露的因果推断方法,因此不适用于连续型暴露的 情况。
4.目前,只有少量研究探讨当连续型暴露因素和高维协变量同时存在时如何使 用gps方法进行因果推断,包括antonelli等(antonelli j,papadogeorgou g, dominici f.causal inference in high dimensions:a marriage betweenbayesian modeling and good frequentist properties.biometrics.2022 mar;78(1):100-114.)提出的贝叶斯方法和su等(su l,ura t,zhang y. non-separable models with high-dimensional data.journal of econometrics 2019,212(2):646-677.)提出的non-separable models。但这两个方法都没有 考虑工具变量对效应估计值方差的影响。
技术实现要素:
5.本发明的目的是针对上述现有技术的不足,而提供一种基于group lasso 的高维广义倾向性评分方法。该方法是考虑到npcbgps对gps模型及误差项分布 正确指定的依赖
性较小,glider能够准确识别出混杂变量和预后变量,通过将 npcbgps均衡协变量的思想和group lasso变量选择的思想结合构建高维gps方 法以期实现在高维情况下无偏有效地估计连续型暴露因素对健康结局的因果效 应。
6.本发明是通过如下技术方案实现的:
7.一种基于group lasso的高维广义倾向性评分方法,包括如下步骤:
8.1)基于glider构建新的目标函数实现降维
9.首先构建结局模型和暴露模型,两个模型对应的损失函数均为残差平方和, 以二者的线性组合作为新的损失函数并引入修正的自适应group lasso惩罚函数 实现因果推断的变量选择;
10.结局模型为:e(y|t,x)=α1x1
…
α
p
x
p
α
p 1
α
p 2
t
ꢀꢀ
(1);
11.暴露模型为:e(t|x)=γ1x1
…
γ
p
x
p
γ
p 1
ꢀꢀ
(2);
12.目标函数为:
[0013][0014][0015]
其中,β=(α,γ)是p 3维的向量:β1=(α1,γ1)、
…
、β
p
=(α
p
,γ
p
)、 β
p 1
=α
p 1
、β
p 2
=γ
p 1
、β
p 3
=α
p 2
;wk表示惩罚权重,当k>p时, wk=0,当k≤p时,其中γ>1,指结局全模型中协变量xk之前的系数,这时wk的大小与协变量xk跟结局变量间的条件相关性大小成反 比;λ>0是调整参数,设置一组满足和λn
γ/2-1
→
∞两个条件的 λ作为备选值,并据此筛选出一组候选协变量集合;
[0016]
2)结合npcbgps构建双重加权相关系数选择最优λ
[0017]
ipw方法获得drf的无偏估计依赖于协变量分布在不同暴露水平间的均衡程 度,暴露因素为连续型变量时,使用暴露变量与协变量之间的加权相关系数作为 均衡性评价指标;基于此,使用最小化双重加权相关系数(dual-weight correlation,dwc)准则选择最优λ:
[0018][0019]
其中,是调整参数取值为λ时由npcbgps估计的均衡权重
[0020]
3)使用ipw法估计drf
[0021]
基于最优λ筛选出的协变量,使用npcbgps方法估计均衡权垂;在此基础上, 使用ipw方法通过构建y对t的加权线性或非线性(如样条回归、局部线性回归 等)回归模型得到
连续型暴露因素对结局变量的剂量-反应函数。
[0022]
进一步的,步骤1)中,结局模型为结局y对连续型暴露因素t和所有协变 量x的回归模型,暴露模型为t对所有协变量x的回归模型。
[0023]
本发明基于group lasso的高维广义倾向性评分方法是针对健康医疗大数据 中协变量维度高且具有潜在公共卫生学意义的暴露因素大多为连续型变量的特 点而提出的,其实质提供的是一种因果剂量-反应估计器,也称之为oagl-gps 方法,模拟分析表明,oagl-gps方法整体表现与理想方法相近,在结局模型为 线性时,一方面像glider一样可正确识别出混杂和预后协变量,另一方面还保 留了npcbgps对gps模型误设稳健的统计学性质。
附图说明
[0024]
为了更清楚地说明本发明的技术方案,下面将对本发明技术描述中所需要使 用的附图作简单地介绍,此处的附图用来提供对本发明的进一步说明,构成本申 请的一部分。
[0025]
图1为本发明实施例中oagl-gps方法的流程示意图。
[0026]
图2至图7为本发明实施例中在不同模拟情形下oagl-gps模型筛选校正 协变量的表现。
[0027]
图8至图13为本发明实施例中在不同模拟情形下因果参数估计值的分布图。
具体实施方式
[0028]
下面将结合附图对本发明的技术方案作进一步清楚、完整地描述。
[0029]
一种基于group lasso的高维广义倾向性评分方法,包括如下步骤:
[0030]
1)基于glider构建新的目标函数实现降维
[0031]
首先构建结局模型和暴露模型,结局模型为结局y对连续型暴露因素t和所 有协变量x的回归模型,暴露模型为t对所有协变量x的回归模型;两个模型对 应的损失函数均为残差平方和,以二者的线性组合作为新的损失函数并引入修正 的自适应group lasso惩罚函数实现因果推断的变量选择;
[0032]
结局模型为:e(y|t,x)=α1x1
…
α
p
x
p
α
p 1
α
p 2
t
ꢀꢀ
(1);
[0033]
暴露模型为:e(t|x)=γ1x1
…
γ
p
x
p
γ
p 1
ꢀꢀ
(2);
[0034]
目标函数为:
[0035][0036][0037]
其中,β=(α,γ)是p 3维的向量:β1=(α1,γ1)、
…
、β
p
=(α
p
,γ
p
)、 β
p 1
=α
p 1
、β
p 2
设(comt)时,不同样本量(n=200,500)和协变量维度(p=100,200)组合和 不同协变量相关结构(ρ=0,0.2,0.5)下,oagl-gps选出混杂变量(x1、x6、x11 和x16)、预后协变量(x21和x26)、工具变量(x31和x36)和虚假协变量的频 率分布图;图6表示结局模型误设但暴露模型正确设定(moct)时,不同样本量 (n=200,500)和协变量维度(p=100,200)组合和不同协变量相关结构(ρ=0, 0.2,0.5)下,oagl-gps选出混杂变量(x1、x6、x11和x16)、预后协变量(x21 和x26)、工具变量(x31和x36)和虚假协变量的频率分布图;图7表示结局模 型和暴露模型均误设(momt)时,不同样本量(n=200,500)和协变量维度 (p=100,200)组合和不同协变量相关结构(ρ=0,0.2,0.5)下,oagl-gps选 出混杂变量(x1、x6、x11和x16)、预后协变量(x21和x26)、工具变量(x31 和x36)和虚假协变量的频率分布图。通过对上述各图显示的分析,结果表明: 结局模型为线性时,oagl-gps在变量选择方面接近于理想状况,即混杂变量和 预后协变量被选出的频率几乎为1,其他协变量被选出的接近于0。
[0046]
图8至图13为本发明在不同模拟情形下因果参数估计值的分布图;因果参 数的真值为2,targ指包含所有混杂变量和预后协变量的npcbgps方法,理想状 况下,oagl-gps和targ方法表现一致。图8表示结局模型和暴露模型为线性且 混杂变量与结局和暴露因素强相关(sost)时,不同样本量(n=200,500)和协 变量维度(p=100,200)组合和不同协变量相关结构(ρ=0,0.2,0.5)下,oagl-gps 和targ方法估计因果参数的分布图;图9表示结局模型和暴露模型为线性且混 杂变量与结局变量的相关性大于与暴露因素的相关性(sowt)时,不同样本量 (n=200,500)和协变量维度(p=100,200)组合和不同协变量相关结构(ρ=0, 0.2,0.5)下,oagl-gps和targ方法估计因果参数的分布图;图10表示结局模 型和暴露模型为线性且混杂变量与结局的相关性弱于与暴露因素的相关性(wost) 时,不同样本量(n=200,500)和协变量维度(p=100,200)组合和不同协变量 相关结构(ρ=0,0.2,0.5)下,oagl-gps和targ方法估计因果参数的分布图; 图11表示结局模型正确设定(线性)但暴露模型误设(comt)时,不同样本量 (n=200,500)和协变量维度(p=100,200)组合和不同协变量相关结构(ρ=0, 0.2,0.5)下,oagl-gps和targ方法估计因果参数的分布图;图12表示结局模 型误设但暴露模型正确设定(moct)时,不同样本量(n=200,500)和协变量维 度(p=100,200)组合和不同协变量相关结构(ρ=0,0.2,0.5)下,oagl-gps 和targ方法估计因果参数的分布图;图13表示结局模型和暴露模型均误设 (momt)时,不同样本量(n=200,500)和协变量维度(p=100,200)组合和不 同协变量相关结构(ρ=0,0.2,0.5)下,oagl-gps和targ方法估计因果参数的 分布图。通过对上述各图显示的分析,结果表明:oagl-gps和targ方法整体表 现基本一致,结局模型为线性时,无论暴露模型是否正确设定,因果参数估计值 的准确度和精度均较高。
[0047]
以下列举一个具体实施例,对上述技术方案做更进一步的说明:
[0048]
使用2017-2018年美国国家健康和营养调查(national health andnutrition examination survey,nhanes)数据,应用本发明方法的oagl-gps 模型估计邻苯二甲酸单(羧基异辛酯)酯(mono-(carboxyisoctyl)phthalate, mcop)与超敏c反应蛋白(hypersensitive c-reactive protein,hs-crp)间 的剂量-反应函数。mcop是尿邻苯二甲酸盐代谢物之一,hs—crp是动脉粥样硬化 和心血管疾病的独立预测因子。潜在混杂变量考虑性别、年龄、种族等人口学变 量;访谈前24h内饮食中能量、营养素摄入量等饮食数据;血生化及血尿代谢等 实验室数据;血压、人体测量学、体成分等身体检查数据;健康状况、
行为生活 方式等问卷调查数据共202个。经预处理,最终共纳入2133个研究对象。结果 显示,mcop与hs-crp间不存在统计学显著的线性剂量-反应关系(drf=-0.524, p=0.275),这与ferguson等的研究结果一致(ferguson kk,cantonwine de, rivera-gonz
á
lez lo,loch-caruso r,mukherjee b,anzalota del toro lv, jim
é
nez-v
é
lez b,calafat am,ye x,alshawabkeh an,cordero jf,meeker jd. urinary phthalate metabolite associations with biomarkers ofinflammation and oxidative stress across pregnancy in puerto rico. environ sci technol.2014jun 17;48(12):7018-25.)。
[0049]
上面是对本发明实施例中的技术方案进行了清楚、完整地描述,所描述的实 施例仅仅是本发明一部分实施例,而不是全部的实施例。本发明的实施例及其说 明用来解释本发明,并不构成对本发明的不当限定。基于本发明中的实施例,本 领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属 于本发明保护的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。