1.本发明涉及生物信息学领域,具体涉及一种甲基化标志物分层筛选的方法及装置。
背景技术:
2.根据国家癌症中心统计,2016年我国新发癌症比例406.4万,世标发病率为186.46/10万。其中,新发病例排名前五的是:肺癌、结直肠癌、胃癌、肝癌以及乳腺癌。早筛、早诊、及时治疗是降低癌症死亡率的有效途径。欧洲医学肿瘤学会(esmo)指出:西方国家的癌症发病率和致死率在逐年降低,主要是归功于癌症的早期筛查,早期良性腺瘤切除以及癌症病灶的早期治疗。
3.目前,临床上虽然有不少的肿瘤标志物,如癌胚抗原(cea)、甲胎蛋白(afp)、癌抗原125(ca125)、糖类抗原19-9(ca19-9)、前列腺特异抗原(psa)等,但是其敏感性或特异性通常不能满足对临床诊断的需求。特别地,某些肿瘤标志物在某些生理情况下或者良性病变也会升高;如:月经期、妊娠早期,肝硬化和慢性活动性肝炎等,可能会使血清ca125升高;胆汁淤积可能导致血清ca19-9升高。因此,通常临床医生们通常会一次同时检测多种标志物,并结合临床症状、影像学检查等其他手段综合考量。所以,就肿瘤标志物本身而言,对健康人群的广泛筛查可推广性不高。然而,发现和利用肿瘤特异性生物标记物,并且能够在肿瘤发生早期,发现其发生器官并实施治疗,是提升肿瘤治疗效果,延长患者寿命的关键因素。
4.dna甲基化是一种重要的表观遗传学修饰,在真核生物中,甲基化仅发生在胞嘧啶,即在dna甲基化转移酶的作用下,5’胞嘧啶转化为5’甲基胞嘧啶。大量研究表明dna甲基化在癌症的发生发展中扮演着重要作用,其异常改变是癌症发展发展过程中的标志性事件之一。人类基因启动子区域的cpg岛通常是处于非甲基化状态,在癌症中则会发生高甲基化,可能导致一些重要的抑癌基因、dna修复基因的转录沉默,同时全基因组通常呈现为去甲基化状态与基因组的稳定性有较大的关联。现有的一些研究指出肿瘤dna甲基化图谱可用于肿瘤分类、诊断和治疗,因此dna甲基化可能是健康人血浆成分解析、器官损伤、免疫应答监测、癌症早筛、复发检测、器官移植监测以及定位转移癌的原发部位的潜在生物标志物。
5.然而,现有的基于dna甲基化的筛选方法不能进行一对多筛选,且准确率较低。
技术实现要素:
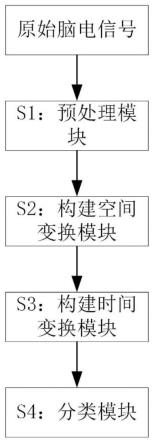
6.根据第一方面,在一实施例中,提供一种对样本进行分层的方法,包括:
7.数据获取步骤,包括获取样本的甲基化修饰数据;
8.预处理步骤,包括对所述甲基化修饰数据进行预处理,获得预处理后的各个类型样本;
9.降维处理步骤,包括对预处理后的各个类型样本分别进行降维处理;
10.分层步骤,包括对经过降维处理之后的样本进行聚类,并确定最佳聚类数目,实现对样本的分层。
11.根据第二方面,在一实施例中,提供一种分层筛选甲基化标志物的方法,包括:
12.第一层筛选步骤,包括根据第一方面任意一项的方法获得的样本的n个分组,筛选n个分组之间的甲基化标志物,即为第一层甲基化标志物;
13.第二层筛选步骤,包括根据第一方面任意一项的方法获得的样本的n个分组,分别筛选各个分组内部不同类型样本的甲基化标志物,即为第二层甲基化标志物。
14.根据第三方面,在一实施例中,提供一种对样本进行分层的装置,包括:
15.数据获取模块,用于获取数据库中的样本的甲基化修饰数据;
16.预处理模块,用于对所述甲基化修饰数据进行预处理,获得预处理后的各个类型样本;
17.降维处理模块,用于对预处理后的各个类型样本分别进行降维处理;
18.分层模块,用于对经过降维处理之后的样本进行聚类,并确定最佳聚类数目,实现对样本的分层。
19.根据第四方面,在一实施例中,提供一种分层筛选甲基化标志物的装置,包括:
20.第一层筛选模块,用于根据第一方面任意一项的方法获得的样本的n个分组,筛选n个分组之间的甲基化标志物,即为第一层甲基化标志物;
21.第二层筛选模块,用于根据第一方面任意一项的方法获得的样本的n个分组,分别筛选各个分组内部不同类型样本的甲基化标志物,即为第二层甲基化标志物。
22.根据第五方面,在一实施例中,提供一种对样本进行分层的装置,包括:
23.存储器,用于存储程序;
24.处理器,用于通过执行所述存储器存储的程序以实现第一方面任意一项的方法。
25.根据第六方面,在一实施例中,提供一种分层筛选甲基化标志物的的装置,包括:
26.存储器,用于存储程序;
27.处理器,用于通过执行所述存储器存储的程序以实现第二方面任意一项的方法。
28.根据第七方面,在一实施例中,提供一种计算机可读存储介质,所述介质上存储有程序,所述程序能够被处理器执行以实现如第一方面或第二方面任意一项的方法。
29.依据上述实施例的甲基化标志物分层筛选的方法及装置,本发明是一对多的方法,可以同时筛选多种类型样本的甲基化标志物,高效且可靠。
30.在一实施例中,不仅适用于单个甲基化位点甲基化水平,同时也适用于区域的甲基化水平。甲基化水平的衡量指标包括不限于平均甲基化率、甲基化熵(methylation entropy)、表观多态性(epi-polymorphism)、甲基化单倍体负荷(methylation haplotype load,mhl)以及单倍体数目(haplotypes counts)等。
31.在一实施例中,甲基化区域相比于单个甲基化位点而言,可以降低单个甲基化位点的假阳性,即更不容易受到检测技术的影响;在测序数据的应用中,一些甲基化位点可能没有被测到产生缺失值,若使用区域甲基化水平则可以避免缺失值的出现。
附图说明
32.图1为一种实施例中分层筛选的流程示意图;
33.图2为一种实施例中的样本分层结果图;
34.图3为一种实施例中分层筛选甲基化标志物的流程示意图;
35.图4为一种实施例中的甲基化标志物评估流程示意图;
36.图5为一种实施例中的预测准确率结果图。
具体实施方式
37.下面通过具体实施方式结合附图对本发明作进一步详细说明。在以下的实施方式中,很多细节描述是为了使得本技术能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他材料、方法所替代。在某些情况下,本技术相关的一些操作并没有在说明书中显示或者描述,这是为了避免本技术的核心部分被过多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。
38.另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
39.本文中为部件所编序号本身,例如“第一”、“第二”等,仅用于区分所描述的对象,不具有任何顺序或技术含义。
40.根据第一方面,在一实施例中,提供一种对样本进行分层的方法,包括:
41.数据获取步骤,包括获取样本的甲基化修饰数据;
42.预处理步骤,包括对所述甲基化修饰数据进行预处理,获得预处理后的各个类型样本;
43.降维处理步骤,包括对预处理后的各个类型样本分别进行降维处理;
44.分层步骤,包括对经过降维处理之后的样本进行聚类,并确定最佳聚类数目,实现对样本的分层。
45.在一实施例中,所述预处理步骤中,所述预处理包括探针过滤、样本过滤。
46.在一实施例中,所述降维处理步骤中,针对每一类型样本进行降维处理的方法包括:计算每个探针在目标类型样本中的离散程度,将探针按离散程度从大到小排序,取离散程度排位在预设排名前的探针作为有效特征,对样本进行聚类,根据指标确定最佳聚类数目,实现对各个类型样本的降维。
47.在一实施例中,所述降维处理步骤中,取离散程度排位在预设排名前的探针作为有效特征时,预设排名(k)可以根据实际应用设置,包括但不限于10%、20%、30%等等。
48.在一实施例中,所述降维处理步骤中,所述指标包括但不限于方差比准则(variance rat io criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)、轮廓系数(average silhouette method)等等中的至少一种。
49.在一实施例中,所述降维处理步骤中,所述指标包括但不限于方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)、轮廓系数(average silhouette method)等等中的至少两种。
50.在一实施例中,所述降维处理步骤中,如果有两种或者两种以上的指标的最佳聚类数目一致,则将该最佳聚类数目为最终的最佳聚类数目;否则选取以轮廓系数确定的最佳聚类数目作为最终的最佳聚类数目,实现对各个类型样本的降维。
51.在一实施例中,所述降维处理步骤中,对样本进行聚类的方法包括但不限于基于层次的聚类算法、基于密度的聚类算法中的至少一种。
52.在一实施例中,所述降维处理步骤中,还包括分别计算各类中所有样本在每个探针捕获区域的甲基化水平;
53.在一实施例中,所述甲基化水平包含平均甲基化率、甲基化熵(methylation entropy)、表观多态性(epi-polymorphism)、甲基化单倍体负荷(methylation haplotype load,mhl)或单倍体数目(haplotypes counts)。
54.在一实施例中,所述甲基化水平包含beta值的均值。
55.在一实施例中,所述降维处理步骤中,还包括分别计算各类中所有样本在每个探针捕获区域的beta值的均值。
56.beta值=m/(m u offset),u代表非甲基化信号强度,m代表甲基化的信号强度,offset为偏移量。offset是为了防止分母为0的情况出现。beta值即为甲基化信号强度的百分比。
57.beta值适用于芯片数据。如果是测序数据,可以用其他的指标来替代beta值,包括但不限于甲基化熵(methylation entropy)、表观多态性(epi-polymorphism)、甲基化单倍体负荷(methylation haplotype load,mhl)或单倍体数目(haplotypes counts)。
58.在一实施例中,所述分层步骤中,计算每个探针在所有样本中的离散程度,将探针按离散程度从大到小排序,取离散程度排位在预设排名前的探针作为有效特征,对样本进行聚类,根据指标确定最佳聚类数目。
59.在一实施例中,所述分层步骤中,计算每个探针在所有样本中的离散程度,将探针按离散程度从大到小排序,取离散程度排位在预设排名前的探针作为有效特征,对样本进行聚类,根据指标确定最佳聚类数目。
60.在一实施例中,所述分层步骤中,对样本进行聚类的方法包括如下方法中的至少一种:非加权组平均法(unweighted pair-group method with arithmetic means,upgma)、系统发育树邻接法、基于划分的聚类算法、基于层次的聚类算法、基于网络的聚类算法。
61.在一实施例中,所述分层步骤中,所述指标包括但不限于方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)、轮廓系数(average silhouette method)等等中的至少两种。
62.在一实施例中,所述分层步骤中,若有两种或者两种以上的指标的最佳聚类数目一致,则将该最佳聚类数目为最终的最佳聚类数目;否则取以轮廓系数确定的最佳聚类数目n作为最终的最佳聚类数目。
63.在一实施例中,所述分层步骤中,多个类型的样本最终被分为n个分组,每个分组中包含至少一个类型的样本。此处的“多个”是指两个或两个以上。
64.在一实施例中,所述类型包括癌种、发育谱系、组织类型或细胞类型。
65.在一实施例中,所述分层步骤中,多个癌种最终可以分为n个分组,每个分组中可
能包含一个或者多个癌种。
66.在一实施例中,所述数据获取步骤中,所述样本的甲基化修饰数据来源于数据库。
67.在一实施例中,所述数据获取步骤中,所述数据库包括公共数据库。
68.在一实施例中,所述数据获取步骤中,所述样本的甲基化修饰数据也可以来源于自测的数据。
69.在一实施例中,所述数据获取步骤中,所述样本包括但不限于组织样本、体液样本中的至少一种。
70.在一实施例中,所述数据获取步骤中,所述组织样本包括但不限于癌组织、正常组织中的至少一种。
71.在一实施例中,所述数据获取步骤中,所述体液样本包括但不限于血浆样本。
72.在一实施例中,所述数据获取步骤中,所述样本包括但不限于正常细胞样本。
73.在一实施例中,所述数据获取步骤中,所述样本包括但不限于癌样本。
74.在一实施例中,所述数据获取步骤中,所述癌样本包括但不限于泛癌队列原发肿瘤组织样本。
75.在一实施例中,所述数据获取步骤中,所述肿瘤包括但不限于肝细胞癌、胆管癌、肺腺癌、肺鳞癌、胃癌、食管癌、结肠癌、直肠腺癌、胰腺癌、乳腺癌、卵巢癌、宫颈癌、子宫内膜癌、子宫肉瘤、前列腺癌、膀胱尿路上皮癌、肾上腺皮质癌、肾嫌色细胞癌、肾透明细胞癌、肾乳头状细胞癌、头颈部鳞状细胞癌、甲状腺癌、胸腺瘤、间皮瘤、肉瘤、皮肤黑色素瘤、眼黑色素瘤、嗜铬细胞瘤、副神经节瘤、脑低级别胶质瘤、胶质母细胞瘤中的至少一种。
76.在一实施例中,所述预处理步骤中,所述探针过滤规则包括:如果探针上下游10bp内含有snp位点,则剔除该探针;同时剔除性染色体上的探针以及样本缺失值比例超过预设阈值的探针。
77.样本缺失值比例是指在某一探针上没有检测到信号的样本数占总样本数的比例,例如,对于一个探针而言,如果100个样本中有30个样本在该探针上没有检测到信号,即会用缺失值na表示。此处,该探针的样本缺失值比例=30/100。
78.在一实施例中,所述预处理步骤中,所述样本过滤规则包括:采用至少一种算法识别异常样本,如果采用的算法中至少一种算法的识别结果显示样本是异常的,则剔除该样本。
79.在一实施例中,如果有两种或者两种以上的算法的识别结果显示样本是异常的,则剔除该样本。
80.原则上可以只使用一种算法识别异常样本,但如果一个样本被多种方法皆判定为异常样本,会更加可靠。如果定为一种算法,可能会剔除更多的样本。通常可以根据实际需要对算法进行调整,可以根据最终纳入分析的样本数,选择算法的数量。
81.在一实施例中,所述用于识别异常样本的算法包括但不限于孤立森林(isolation forest)、局部异常因子检测算法(local outlier factor,lof)、基于密度的聚类算法(density-based spatial clustering of applications with noise,dbscan)、基于划分的聚类算法、基于层次的聚类算法、基于网络的聚类算法中的至少一种,优选为前述算法中的至少两种。
82.根据第二方面,在一实施例中,提供一种分层筛选甲基化标志物的方法,包括:
83.第一层筛选步骤,包括根据第一方面任意一项的方法获得的样本的n个分组,筛选n个分组之间的甲基化标志物,即为第一层甲基化标志物;
84.第二层筛选步骤,包括根据第一方面任意一项的方法获得的样本的n个分组,分别筛选各个分组内部不同类型样本的甲基化标志物,即为第二层甲基化标志物。
85.在一实施例中,第一层筛选步骤包括:
86.样本选择步骤,包括获取用于第一层甲基化标志物筛选的n个分组的样本;
87.甲基化区域划分步骤,将任意相邻两个cpg位点之间的相关系数大于预设值,以及cpg位点的数量大于预设数量的甲基化区域作为同一甲基化区域;
88.甲基化标志物筛选步骤,包括检验各个甲基化区域在n个分组之间是否存在显著统计学差异,如果是,则对n个分组中任意两个分组的甲基化水平进行两两比较,判断该甲基化区域的甲基化水平在两个分组之间是否存在显著统计学差异;若一甲基化区域,一个特定分组样本与其他m个分组样本的甲基化水平均存在显著统计学差异,则判断该甲基化区域为该特定分组的特异甲基化标志物,m为小于n的任意自然数。如果否,则不再进行后续步骤。
89.在一实施例中,甲基化区域划分步骤中,所述相关系数包括但不限于皮尔森相关系数(pearson correlation coefficient)或斯皮尔曼相关系数(spearman correlation coefficient)。
90.在一实施例中,甲基化标志物筛选步骤中,根据实际应用,m可以设置为n-1、n-2等,并且当m为n-1时,甲基化标志物的特异性最好。
91.在一实施例中,甲基化标志物筛选步骤中,检验方法包括但不限于方差分析、克鲁斯卡尔-沃利斯检验中的至少一种。
92.在一实施例中,甲基化标志物筛选步骤中,采用多重比较法对p值进行校正,获得校正后的p值(padj),若校正后的p值小于预设阈值,则判断该甲基化区域的甲基化水平在n个分组之间存在显著统计学差异。
93.在一实施例中,甲基化标志物筛选步骤中,当两两比较的p值小于预设阈值且甲基化水平差值的绝对值大于预设阈值时,判断该甲基化区域的甲基化水平在两个分组之间存在显著统计学差异。
94.在一实施例中,所述甲基化水平包含平均甲基化率、甲基化熵(methylation entropy)、表观多态性(epi-polymorphism)、甲基化单倍体负荷(methylation haplotype load,mhl)或单倍体数目(haplotypes counts)。
95.在一实施例中,所述甲基化水平包含beta值的均值。
96.在一实施例中,甲基化水平差值包括区域内各cpg位点的甲基化水平,在两组样本间的差值。
97.在一实施例中,所述甲基化水平包括甲基化区域包含的所有cpg位点beta值的均值。
98.在一实施例中,甲基化标志物筛选步骤中,对n个分组中任意两个分组进行两两比较时,采用的统计学方法包括但不限于tukey's honest significant difference(tukey's hsd)、最小显著差异法(least significance difference,lsd)、dunnett-t检验、复极差法(student new man keuls,snk法)、新复极差法(duncan's new multiple range test)
等等中的至少一种。
99.在一实施例中,第二层筛选步骤参照第一层筛选步骤进行。
100.在一实施例中,第二层筛选步骤包括:
101.样本选择步骤,包括根据癌种对每一个分组内的样本进行分类,癌种的数量x与样本的类别数一致,例如,某一分组的样本如果涉及x个癌种,则将该分组内的样本分为x个类别;
102.甲基化区域划分步骤,包括将任意相邻两个cpg位点之间的皮尔森相关系数大于预设值,以及cpg位点的数量大于预设数量的甲基化区域划分为同一甲基化区域;
103.甲基化标志物筛选步骤,包括检验各个甲基化区域的甲基化水平在x个类别之间是否存在显著统计学差异,如果是,则对各个类别中任意两个类别的甲基化水平进行比较,判断该甲基化区域的甲基化水平在两个类别之间是否存在显著统计学差异;若一甲基化区域,某一个特定类别样本与其他y个类别样本均存在差异,则判断该甲基化区域为该特定类别样本的特异甲基化标志物,y为小于x的自然数。
104.在一实施例中,甲基化标志物筛选步骤中,根据实际应用y,可以设置为x-1、x-2等,并且当y为x-1时,甲基化标志物的特异性最好。
105.在一实施例中,甲基化标志物筛选步骤中,检验方法包括但不限于方差分析、克鲁斯卡尔-沃利斯检验中的至少一种。
106.在一实施例中,甲基化标志物筛选步骤中,采用多重比较法对p值进行校正,获得校正后的p值(padj),若校正后的p值小于预设阈值,则判断该甲基化区域的甲基化水平在x个类别之间存在显著统计学差异。
107.在一实施例中,甲基化标志物筛选步骤中,当两两比较的p值小于预设阈值且beta差值的绝对值大于预设阈值时,判断该甲基化区域的甲基化水平在两个类别之间存在显著统计学差异。
108.在一实施例中,所述甲基化水平包括甲基化区域包含的所有cpg位点beta值的均值。
109.根据第三方面,在一实施例中,提供一种对样本进行分层的装置,包括:
110.数据获取模块,用于获取数据库中的样本的甲基化修饰数据;
111.预处理模块,用于对所述甲基化修饰数据进行预处理,获得预处理后的各个类型样本;
112.降维处理模块,用于对预处理后的各个类型样本分别进行降维处理;
113.分层模块,用于对经过降维处理之后的样本进行聚类,并确定最佳聚类数目,实现对样本的分层。
114.根据第四方面,在一实施例中,提供一种分层筛选甲基化标志物的装置,包括:
115.第一层筛选模块,用于根据第一方面任意一项的方法获得的样本的n个分组,筛选n个分组之间的甲基化标志物,即为第一层甲基化标志物;
116.第二层筛选模块,用于根据第一方面任意一项的方法获得的样本的n个分组,分别筛选各个分组内部不同类型样本的甲基化标志物,即为第二层甲基化标志物。
117.根据第五方面,在一实施例中,提供一种对样本进行分层的装置,包括:
118.存储器,用于存储程序;
119.处理器,用于通过执行所述存储器存储的程序以实现第一方面任意一项的方法。
120.根据第六方面,在一实施例中,提供一种分层筛选甲基化标志物的的装置,包括:
121.存储器,用于存储程序;
122.处理器,用于通过执行所述存储器存储的程序以实现第二方面任意一项的方法。
123.根据第七方面,在一实施例中,提供一种计算机可读存储介质,所述介质上存储有程序,所述程序能够被处理器执行以实现如第一方面或第二方面任意一项的方法。
124.根据第八方面,在一实施例中,提供一种甲基化标志物评估方法,包括:
125.验证步骤,包括根据第二方面任意一项的方法筛选得到的第一层甲基化标志物,构建第一层分类模型,并采用独立数据集进行验证,数据包括n个分组样本。
126.样本选择步骤,包括将数据分为训练集和验证集,训练集数据用于模型构建,验证集数据用于模型性能验证;
127.特征选择步骤,包括根据筛选到的第一层甲基化标志物,利用递归消除法(recursive feature elimination,rfe)对其进一步筛选,将得到的部分甲基化标志物作为最终特征;
128.分类模型构建步骤,包括根据特征选择步骤获得的最终特征,进行机器学习模型训练,得到最佳的甲基化分类模型;
129.模型预测步骤,包括根据分类模型构建步骤构建的所述甲基化分类模型,对验证集数据进行预测,并评估模型的性能;
130.根据之前筛选的各个分组的甲基化标志物,针对各个分组分别构建第二层分类模型,并采用独立数据集进行验证。
131.在一实施例中,模型预测步骤中,模型性能评价指标包括但不限于准确率、精度、召回率等等中的至少一种。
132.在一实施例中,提供一种用于分层甲基化标志物分层筛选的方法,该方法应用的领域包括不限于器官损伤、癌症早筛、组织溯源以及器官移植。就癌症早筛而言,目前临床上使用的一些肿瘤标志物,敏感性特异性较低,不能很好地满足临床需求;分子标志物也许可以辅助癌症早筛。本发明提出一种分层筛选甲基化标志物的方法,可以用于细胞特异、组织特异以及癌种特异甲基化标志物的筛选。同时,这些标志物可以辅助健康人血浆成分解析、器官损伤评估、免疫应答监测、癌症早筛、复发检测、器官移植监测以及定位转移癌的原发部位等。
133.在一实施例中,提供一种用于分层甲基化标志物分层筛选的方法,能够应用于健康人血浆成分解析、器官损伤、免疫应答监测、癌症早筛、复发检测、器官移植监测以及定位转移癌的原发部位等。
134.在一实施例中,本发明提供了一种用于多个类型样本分层的方法,如可以对多个癌种分层。特别地,样本可以是血浆、组织样本,具体包括但不限于癌组织、正常细胞以及正常组织。以癌样本分层为例,流程包括:
135.获取公共数据库中收录的泛癌队列原发肿瘤组织的甲基化修饰数据。
136.其中,肿瘤组织包括:肝细胞癌、胆管癌、肺腺癌、肺鳞癌、胃癌、食管癌、结肠癌、直肠腺癌、胰腺癌、乳腺癌、卵巢癌、宫颈癌、子宫内膜癌、子宫肉瘤、前列腺癌、膀胱尿路上皮癌、肾上腺皮质癌、肾嫌色细胞癌、肾透明细胞癌、肾乳头状细胞癌、头颈部鳞状细胞癌、甲
状腺癌、胸腺瘤、间皮瘤、肉瘤、皮肤黑色素瘤、眼黑色素瘤、嗜铬细胞瘤和副神经节瘤、脑低级别胶质瘤以及胶质母细胞瘤。
137.对下载得到的甲基化修饰数据进行预处理操作,包括探针过滤、样本过滤等。探针过滤规则:如果探针上下游10bp内含有snp位点,则剔除该探针;同时剔除性染色体上的探针以及样本缺失值比例超过预设阈值的探针,预设阈值可以设置为10%,20%,30%等。样本过滤规则:采用不同的算法识别异常样本,如孤立森林(isolation forest)、局部异常因子检测算法(local outlier factor,lof)、基于密度的聚类算法(density-based spatial clustering of applications with noise,dbscan)、基于划分的聚类算法、基于层次的聚类算法、基于网络的聚类算法;如果有两种或者两种以上的算法认为样本是异常的,则剔除该样本。
138.对经过预处理之后的各个类型样本,分别进行降维处理。例如,针对一类型样本进行降维处理的方法包括:首先,计算每个探针在目标类型样本中的离散程度,将探针按离散程度从大到小排序,取离散程度排位在预设排名(k)前的探针作为有效特征,预设排名k可以根据实际应用设置为10%、20%、30%等;然后,对样本进行层次聚类;接着,根据指标确定最佳聚类数目,指标包括但不限于方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)和轮廓系数(average silhouette method)等。如果有两种或者两种以上的指标的最佳聚类数目一致,则将该最佳聚类数目为最终的最佳聚类数目;否则选取以轮廓系数确定的最佳聚类数目作为最终的最佳聚类数目。最后,根据上一步确定的最佳聚类数目,从而实现对各个类型样本的降维;分别计算各类中所有样本在每个探针捕获区域的甲基化水平指标(包括但不限于beta值)的均值。将多个样本用一个值表示(即降维),用于后续的样本分层。
139.在一实施例中,针对特定的样本类型,先确定该类型样本的类别,然后计算每个类别样本的beta均值。
140.对经过降维处理的样本进行聚类,并确定最佳聚类数目,实现对样本分层。首先,计算每个探针捕获区域在所有样本中的离散程度,取离散程度最大的前10%(top 10%)探针作为有效特征;然后,利用非加权组平均法(unweighted pair-group method with arithmetic means,upgma)对样本进行聚类;最后,根据指标确定最佳聚类数目,指标包括:方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)和轮廓系数(average silhouette method)等。若有两种或者两种以上的指标的最佳聚类数目一致,则为最终的最佳聚类数目;当最佳聚类数目不一致时,取以轮廓系数确定的最佳聚类数目n。特别地,多个癌种最终可以分为n个分组,每个分组中可能包含一个或者多个癌种。
141.在另一实施例中,本发明还提供了一种分层筛选甲基化标志物的方法,以癌样本分层甲基化标志物筛选为例,包括:
142.根据上一步确定好的n个分组,首先筛选n个分组之间的甲基化标志物,即第一层甲基化标志物。
143.样本选择:将数据分为训练集和验证集,同时确定用于第一层甲基化标志物筛选的n个分组的样本。
144.甲基化区域划分:将任意相邻两个cpg位点之间的皮尔森相关系数大于预设值,以
significance difference,lsd)、dunnett-t检验、复极差法(student newman keuls,snk法)以及新复极差法(duncan's new multiple range test)等。当两两比较的p值小于预设阈值且beta差值的绝对值大于预设阈值时,判断该甲基化区域在两个类别之间存在显著统计学差异。两两比较的p值的预设阈值可以根据实际应用设置为0.01、0.05等,beta差值的绝对值的预设阈值可以根据实际应用设置为0.15、0.2、0.25、0.3、0.35等。若一甲基化区域,一个特定类别样本与其他y个类别样本均存在差异,则判断该甲基化区域为该特定类别的特异甲基化标志物。根据实际应用y可以设置为x-1、x-2等,并且当y为x-1时,甲基化标志物的特异性最好。
151.在另一实施例中,本发明还提供了一种甲基化标志物评估方法,包括:
152.根据之前筛选的第一层甲基化标志物,构建第一层分类模型,并采用独立数据集进行验证。数据包括n个分组样本。
153.样本选择:将数据分为训练集和验证集,训练集数据用于模型构建,验证集数据用于模型性能验证。
154.特征选择:基于筛选到的第一层甲基化标志物,利用递归消除法(recursive feature elimination,rfe)对其进一步筛选,将得到的部分甲基化标志物作为最终特征。递归消除法,即选择一个基准模型,将所有的特征传递进去,在确认模型性能的同时通过对特征的重要性进行排序,剔除不重要的特征保留重要的特征。
155.分类模型构建:基于特征选择步骤获得的最终特征,进行机器学习模型训练,得到最佳的甲基化分类模型。机器学习方法包括不限于支持向量机、逻辑回归、神经网络、随机森林及极致梯度提升(extreme gradient boosting,xgboost)等。
156.模型预测:基于构建的分类模型,对验证集数据进行预测,并评估模型的性能。模型性能评价指标包括:准确率、精度和召回率等。
157.根据之前筛选的各个分组的甲基化标志物,针对各个分组分别构建第二层分类模型并采用独立数据集进行验证。以n个分组中的一个分组为例,模型构建与第一层模型构建和验证的方法类似,包括:
158.样本选择:将一个特定分组中的样本,按照原始的标签对样本进行分类,假设特定分组的样本涉及x个癌种,则可以分为x个类别。
159.特征选择:基于筛选到的第一层甲基化标志物,利用递归消除法(recursive feature elimination,rfe)对其进一步筛选,得到的部分甲基化标志物作为最终特征。递归消除法,即选择一个基准模型,将所有的特征传递进去,在确认模型性能的同时通过对特征的重要性进行排序,剔除不重要的特征,保留重要的特征。
160.分类模型构建:基于特征选择获得的最终特征,进行机器学习模型训练,得到最佳的甲基化分类模型。机器学习方法不限于支持向量机、逻辑回归、神经网络、随机森林及极致梯度提升(extreme gradient boosting,xgboost)等。
161.模型预测:基于构建的分类模型,对验证集数据进行预测,并评估模型的性能。模型性能评价指标包括:准确率、精度和召回率等。
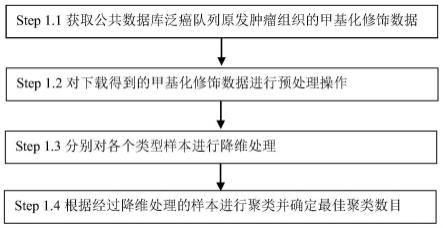
162.实施例1
163.本实施例提供一种用于多个类型样本分层的方法。该实施例对多个癌种进行分层,如图1所示,包括:
164.step 1.1,获取公共数据库泛癌队列原发肿瘤组织的甲基化修饰数据。
165.step 1.2,对下载得到的甲基化修饰数据进行预处理操作,数据预处理包括:探针过滤和样本过滤。
166.step 1.3,分别对各个类型样本进行降维处理。
167.step 1.4,根据经过降维处理的样本进行聚类并确定最佳聚类数目,完成样本分层。
168.在本实施例中,首先在公共数据库中,获取30个癌种样本的甲基化修饰数据,具体数据如表1所示。之后,对数据进行预处理,数据预处理包括:探针过滤和样本过滤。探针过滤规则:如果探针上下游10bp内含有snp位点,则剔除该探针;同时剔除性染色体上的探针以及样本缺失值比例超过20%的探针。样本过滤规则:采用不同的方法识别异常样本,如孤立森林、局部异常因子检测算法、基于密度的聚类算法、基于划分的聚类算法、基于层次的聚类算法、基于网络的聚类算法,如果有两种或者两种以上的算法认为样本是异常的,则剔除该样本。
169.本实施例的数据来源于tcga(the cancer genome atlas)数据库以及geo(gene expression omnibus)数据库。
170.表1
171.[0172][0173]
完成数据预处理之后,分别对各个类型样本进行降维处理。针对一类型样本进行降维:首先,计算每个探针在目标类型样本中的标准差,取标准差最大的前10%(top 10%)探针作为有效特征;然后,对样本进行层次聚类;接着,根据指标确定最佳聚类数目,指标包括:方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)和轮廓系数(average silhouette method)。如果有两种或者两种以上的方法的最佳聚类数目一致,则将该最佳聚类数目作为最终的最佳聚类数目;否则选取以轮廓系数确定的最佳聚类数目。最后,根据上一步确定的最佳聚类数目,从而实现对各个类型样本的降维;分别计算各类中所有样本在每个探针的beta值的均值。
[0174]
最后,对经过降维处理的样本进行聚类并确定最佳聚类数目,从而实现对样本分层。具体步骤包括:首先,计算每个探针在所有样本中的变异系数,比如标准差,将探针按标准差从大到小排序,取标准差位于前10%(top 10%)的探针作为有效特征;然后,利用非加权组平均法(unweighted pair-group method with arithmetic means,upgma)对样本进行聚类;最后,根据指标确定最佳聚类数目,指标包括:方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)和轮廓系数(average silhouette method)等。在本实施例中,30个癌种分成12个分组。具体结果如图2所示。
[0175]
图2所示为样本分层结果图,癌种后面的数字代表癌种降维后的类别数,不同编号表示不同的分组,各个分组由虚线隔开。由于表1列出的癌种样本中,宫颈癌、食管癌各自同时涉及腺癌和鳞癌,故在表2中展示;表1中的其他癌种没有改变类别,此处不再列举。
[0176]
表2癌种降维后的类别
[0177][0178]
表3样本分层结果(各癌种所属分组情况)
[0179]
癌种英文缩写分层情况skcm、uvmgroup_7lihcgroup_9thymgroup_3acc、gbm、lgg、pcpggroup_6ovgroup_1brca、pradgroup_8ucec、ucsgroup_2meso、sarcgroup_4blca、cesc、esca、hnsc、luscgroup_12kich、kirc、kirp、thcagroup_5chol、luad、paadgroup_10cesc、coad、esca、read、stadgroup_11
[0180]
在本实施例中采用的样本分层策略,当有新的样本类型加入时,可以先判断新增样本属于哪个分组,不会完全推翻新增样本之前的甲基化标志物,可以提高标志物的适用性和稳定性。
[0181]
实施例2
[0182]
本实施例提供一种分层筛选甲基化标志物的方法,包括第一层和第二层甲基化标志物的筛选。以癌样本分层甲基化标志物筛选为例,甲基化标志物的筛选步骤如图3所示,包括:
[0183]
step 2.1,确定用于筛选甲基化标志物的样本。
[0184]
step 2.2,根据预先划分好的甲基化区域计算该区域的甲基化水平。
[0185]
step 2.3,甲基化标志物的筛选。
[0186]
在本实施例中,首先是第一次甲基化标志物的筛选:根据实施例1中的12个分组,将训练集数据中的30个癌种分为12个分组;根据预先划分好的甲基化区域计算甲基化水平。甲基化区域划分规则为:同一甲基化区域中任意相邻两个cpg位点之间的皮尔森相关系数大于0.9以及同一甲基化区域中cpg位点的数量大于3个。接着,利用方差分析检验各个甲基化区域12个分组之间是否存在显著统计学差异,并对方差分析的p值进行bonferroni校正得到padj;若padj小于0.05,则判断该甲基化区域在12个分组之间存在显著统计学差异。
当经过方差分析检验,发现差异具有显著统计学意义时,使用tukey's honest significant difference(tukey's hsd),对12个分组中任意两个分组进一步两两比较。当两两比较的p值小于0.05且beta差值的绝对值大于0.2时,判断该甲基化区域在两个分组之间存在显著统计学差异。若一甲基化区域,一个特定分组样本与其他11个分组样本均存在差异,则该甲基化区域为该特定分组的特异甲基化标志物。以此类推,可以获得12个分组各自的特异甲基化标志物。
[0187]
接着是第二层甲基化标志物的筛选,由于有12个分组,因此第二层甲基化标志物需要分别在12个分组内部进行,特别地,如果分组中仅包括一个类型的样本,则不需要进行第二层甲基化标志物的筛选。以表3中的第三个分组为例,如果该分组包括4个类型的样本,则将第三个分组中的样本分为4个类别。然后,根据预先划分好的甲基化区域计算甲基化水平,利用方差分析检验各个甲基化区域4个类别之间是否存在显著统计学差异,并对方差分析的p值进行bonferroni校正得到padj;若padj小于0.05,则该甲基化区域在4个类别之间存在显著统计学差异。当经过方差分析检验,发现差异具有显著统计学意义,使用tukey's hone st significant difference(tukey's hsd),对4个类别中任意两个类别进一步进行两两比较。当两两比较的p值小于0.05且beta差值的绝对值大于0.2时,判断该甲基化区域在两个类别之间存在显著统计学差异。若一甲基化区域,一个特定类别样本与其他3个类别样本均存在差异,则判断该甲基化区域为该特定类别的特异甲基化标志物。以此类推,可以获得4个类别各自的特异甲基化标志物;从而可以获得各个分组内部的甲基化标志物,即完成第二层甲基化标志物的筛选。
[0188]
在本实施例中,基于样本分层结果进行分层甲基化标志物的筛选。当有新的样本类型加入时,可以先判断新增样本属于哪个分组,不会完全推翻新增样本之前的甲基化标志物,可以保证标志物的适用性和稳定性。
[0189]
实施例3
[0190]
本实施例提供一种甲基化标志物评估方法,如图4所示,包括:
[0191]
step 3.1,确定用于模型训练和预测的样本;
[0192]
step 3.2,模型特征进一步筛选;
[0193]
step 3.3,模型构建;
[0194]
step 3.4,模型预测。
[0195]
在本实施例中,首先是第一层模型的构建:确定用于第一层模型训练的样本,利用递归消除法(recursive feature elimination,rfe)对实施例2中的第一层甲基化标志物进一步筛选,得到模型最终的甲基化标志物。基于特征选择获得的最终特征,构建第一层随机森林分类模型。接着,分别在构建12个分组内部构建第二层模型,最多构建12个第二层模型;特别地,如果分组中仅包括一个类型的样本,则不需要进行该分组的第二层模型构建。以第三个分组为例:模型构建的样本是第三个分组的4个类别的样本,利用递归消除法(recursive feature elimination,rfe)对实施例2中的第三个分组的第二层甲基化标志物进一步筛选,得到模型最终的甲基化标志物。基于特征选择获得的最终特征,构建第三个分组的第二层随机森林分类模型。最后,对验证集数据进行预测,并评估模型预测准确率(预测准确的样本数占该癌种真实样本数的百分比),整体癌种准确率为95.7%,具体性能如图5所示。可见,对子宫肉瘤、食管鳞癌的预测准确率约为70%,对于其他癌种的预测准确
率高达90%以上,对于肺腺癌、前列腺癌、甲状腺癌的预测准确率接近于100%。
[0196]
在一实施例中,本发明提出一种多个类型样本分层的方法,特别地,样本可以是血浆、组织样本,包括但不限于正常细胞、癌组织以及正常组织。该方法可以用于人类发育谱系的构建、探究组织/细胞类型发育关系以及癌种谱系等。
[0197]
现有的筛选甲基化标志物的方法基本都是一对一筛选,在一实施例中,本发明提供了一种分层筛选甲基化标志物的方法,是一对多的方法,可以同时筛选多种类型样本的甲基化标志物,高效且可靠。
[0198]“一对一”是指:在两个类型样本之间比较,获得一组标志物。
[0199]“一对多”是指:同时在多个类型(大于2个类型)样本之间进行比较,同时获得多组标志物。
[0200]
在一实施例中,在血浆/组织中检测本发明筛选的甲基化标志物,可以用于健康人血浆成分解析、器官损伤、免疫应答监测、癌症早筛、复发检测、器官移植监测以及定位转移癌的原发部位。
[0201]
在一实施例中,本发明是基于样本分层结果,进一步筛选分层甲基化标志物。当有新的样本类型加入时,可以先判断新增样本属于哪个分组,不会完全推翻新增样本之前的甲基化标志物,可以保证标志物的适用性和稳定性。
[0202]
在一实施例中,本发明的全部方法,不仅适用于单个甲基化位点甲基化水平检测,同时也适用于区域的甲基化水平检测。甲基化水平的衡量指标不限于平均甲基化率、甲基化熵(methylation entropy)、表观多态性(epi-polymorphism)、甲基化单倍体负荷(methylation haplotype load,mhl)以及单倍体数目(haplotypes counts)等。而甲基化区域相比于单个甲基化位点而言,可以降低单个甲基化位点的假阳性,即更不容易受到检测技术的影响;在测序数据的应用中,一些甲基化位点可能没有被测到产生缺失值,若使用区域甲基化水平则可以避免缺失值的出现。
[0203]
在一实施例中,本发明提出一种多个类型样本分层的方法:a.在识别异常样本时,可采用的方法包括不限于孤立森林(isolation forest)、局部异常因子检测算法(local outlier factor,lof)、基于密度的聚类算法(density-based spatial clustering of applications with noise,dbscan)、基于划分的聚类算法、基于层次的聚类算法、基于网络的聚类算法等。b.在对样本进行降维时,评估离散程度的指标包括不限于方差、标准差、平方差以及变异系数等,且聚类方法包括不限于基于层次的聚类和基于密度的聚类的方法。c.在对样本分层聚类时,聚类方法包括不限于非加权组平均法(unweighted pair-group method with arithmetic means,upgma)、系统发育树邻接法等等。d.在确定最佳聚类数目时,指标包括不限于方差比准则(variance ratio criterion,vrc;又称calinsky criterion)、间隔统计量(gap statistic,gs)和轮廓系数(average silhouette method)等等。
[0204]
在一实施例中,本发明提出一种分层筛选甲基化标志物的方法。在确定各组样本是否存在差异时,使用的方法包括不限于方差分析以及克鲁斯卡尔-沃利斯检验(kruskal wallis,kw检验)等等。在进行两两比较时,可以采用的统计学方法包括不限于tukey's honest significant difference(tukey's hsd)、最小显著差异法(least significance difference,lsd)、dunnett-t检验、复极差法(student newman keuls,snk法)以及新复极
差法(duncan's new multiple range test)等等。
[0205]
在一实施例中,本发明在分类模型构建时,可以采用的方法包括不限于支持向量机、逻辑回归、神经网络、随机森林及极致梯度提升(extreme gradient boosting,xgboost)等。
[0206]
在一实施例中,本发明的应用场景包括但不限于如下场景:样本类型包括不限于血浆、组织样本等。样本分层策略包括不限于人类发育谱系的构建、探究组织/细胞类型发育关系以及癌种谱系等等。甲基化标志物的应用包括不限于健康人血浆成分解析、器官损伤、免疫应答监测、癌症早筛、复发检测、器官移植监测以及定位转移癌的原发部位等。
[0207]
本领域技术人员可以理解,上述实施方式中各种方法的全部或部分功能可以通过硬件的方式实现,也可以通过计算机程序的方式实现。当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器、随机存储器、磁盘、光盘、硬盘等,通过计算机执行该程序以实现上述功能。例如,将程序存储在设备的存储器中,当通过处理器执行存储器中程序,即可实现上述全部或部分功能。另外,当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序也可以存储在服务器、另一计算机、磁盘、光盘、闪存盘或移动硬盘等存储介质中,通过下载或复制保存到本地设备的存储器中,或对本地设备的系统进行版本更新,当通过处理器执行存储器中的程序时,即可实现上述实施方式中全部或部分功能。
[0208]
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。