1.本发明属于语义图像生成网络模型算法技术领域,具体涉及一种基于对抗生成网络的语义图像生成方法,为图像生成等计算机视觉任务提供了重要的理论研究和技术支持。
背景技术:
2.拍照是日常获取物体真实图像的主要方式。获取的图像是客观世界的真实反映。然而,这项技术无法凭空创建不存在物体。由于深度学习的进步,近年来图像合成技术有了很大的进步。现在我们可以使用人工合成技术创建逼真的虚拟图像。它不仅节省了时间和成本,而且极大地丰富了图像内容,因此图像合成已成为计算机视觉中的一项重要技术。
3.现在图像合成技术广泛已经应用于数据增强、艺术创作、犯罪侧写等领域。图像合成技术可分为随机图像合成和条件图像合成;前者是通过随机变量合成不确定的图像,后一种方法是通过外部条件引导图像合成。引导图像合成的条件可以有多种形式,包括文本描述、人类姿态、类别标签和语义分割掩码等。
4.其中,基于语义分割掩码的图像合成技术称为语义图像合成。由于其可控性的优势,引起了人们的广泛关注。虽然目前的方法在这方面做了大量的研究,但合成的图像中仍然存在模糊和伪影。并且这些方法在图像合成过程中忽略了位置感知信息。具体来说,应该向相似区域提供相似的调制信息,并且应该向关键区域提供更多的调制信息。此外,大多数方法的批次归一化方法都受到批次大小的约束;批量越小,批量归一化效果越差;批量越大,硬件要求越高。
技术实现要素:
5.本发明为解决上述技术问题,提出了一种用于语义图像合成的位置感知对抗生成网络模型la-gan,其核心是位置感知条件组规范化块lacgn,它根据当前生成的图像特征预测位置感知信息,并把从语义分割掩码中学习调制参数作为组规范化的条件信息,实现条件组规范化。本发明中的la-gan网络模型通过图像生成过程深化了与语义分割掩码的融合,保证了图像生成的真实性;并结合组规范化使得模型的训练减少对batch size大小的依赖性。
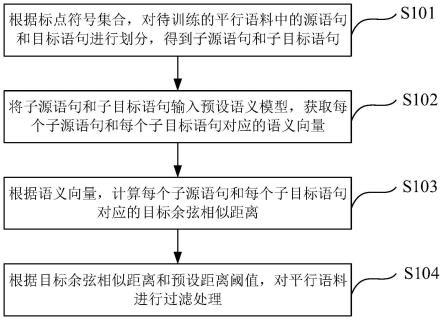
6.本发明的技术方案为:
7.一种基于位置感知对抗生成网络的语义图像合成方法,包括以下步骤:
8.一、la-gan网络模型构建
9.s1:将语义分割掩码m和从正态分布中采样的256维噪声向量z∈r
256
作为输入;首先,通过全连接(fc)层将噪声向量z投影到视觉域,然后对其进行变形,使噪声向量变成1024
×4×
4的特征图f0,将f0作为首层lacgn resblks模块的起始输入,并逐层传递;其次,针对不同深度的lacgn resblks模块,对语义分割掩码m进行不同分辨率的下采样,与特征图同时作为每个lacgn resblks模块的输入。
10.s2:将位置感知预测模块lapm、指导抽样模块gsm和组规范化模块gn融合构成具有位置感知能力的条件组规范化模块lacgn block;lacgn block的具体实现过程包括:
11.s2.1:接受步骤s1中由第i层lacgn resblks模块传递输入的特征图fi,在位置感知预测模块lapm中计算各个像素之间的相关性,具体包括在空间维度上将其进行average pooling和max pooling操作,生成两个新的特征映射;然后再将两个新的特征映射相连,进行卷积运算,并应用s(
·
)激活函数计算空间感知映射图pi。该过程用以下公式来表示:
12.pi=s(conv(concat(avepool(fi),maxpool(fi))))
13.其中,fi表示输入的特征图;avepool()、maxpool()分别表示在通道维度的平均池化和最大池化;concat()表示通道连接;conv()表示卷积;s()表示sigmoid函数激活。
14.s2.2:将步骤s1接受的语义分割掩码m输入到指导抽样模块gsm中计算得到规范化激活调制参数γi和βi。表示为:
15.γi=s
γ
(m)
16.βi=s
β
(m)
17.s2.3:将特征图fi输入到组规范化模块gn中,进行组规范化得到将空间感知映射图pi分别与调制参数γi和βi相乘后得到两个新的调制参数作为条件信息;然后与进行如下运算,得到新的特征图f
i 1
。
[0018][0019]
s3:将两个lacgn block与两个relu激活函数层、两个卷积层、一个跳跃连接和一个上采样层组合构成lacgn resblks;将6个lacgn resblks串联起来再加上一层卷积层和一层tanh激活层最终形成la-gan网络。
[0020]
二、la-gan网络模型训练
[0021]
s4:噪声向量z和语义分割掩码m在la-gan网络中进行语义融合,得到生成的图像i。将生成的图像i和数据集中的真实图像输入到判别器中进行训练,按照gan损失、特征匹配损失和感知损失对la-gan网络模型进行优化训练,保存最优模型mode_best。
[0022]
s5:加载步骤s4中得到的模型model_best,输入噪声和语义分割掩码生成真实感图像。
[0023]
本发明的有益效果:本发明所述方法相比于现有方法可以生成更加清晰真实的图像,同时在训练时也消除了对批大小batch size的依赖。这对于图像生成算法在实际当中应用是很有意义的。
附图说明
[0024]
图1为本发明的la-gan网络模型框架图。
[0025]
图2为本发明中所用lacgn block模块图。
[0026]
图3为la-gan和输入的语义图input、原图像groud true、spade模型、sc-gan模型在cityscapes数据集生成图像的对比图。
[0027]
图4为la-gan和输入的语义图input、原图像groud true、spade模型、sc-gan模型在aed20k数据集生成图像的对比图。
[0028]
图5为la-gan和输入的语义图input、原图像groud true、spade模型、sc-gan模型在aed20k-outdoor数据集生成图像的对比图。
[0029]
图6为la-gan用bn和gn来测试在不同批大小下生成图像的fid指标的折线图。
具体实施方式
[0030]
为使本发明模型解决的问题、采用的方法和达到的效果更加清楚,下面结合附图和实验对本发明做出进一步的详细说明。
[0031]
如图1为本发明构建的la-gan网络模型框架图;该网络模型主干部分由6重具有最近邻上采样的lacgn resblks组成,用于融合语义分割掩码和提高分辨率。以语义分割掩码m和从正态分布中采样的256维噪声向量z∈r
256
作为输入,输出特定分辨率的真实感图像i。每个lacgn resblks由两个lacgn block、两个卷积层、两个relu激活函数层、一个跳跃连接和一个上采样层组成。上采样层通过双线性插值运算将图像特征映射的宽度和高度提高一倍。由于每个lacgn resblks在不同的尺度下工作,本发明对语义分割掩码进行下采样以匹配空间分辨率。在数据处理过程中,噪声向量z通过全连接(fc)层投影到视觉域,然后对其进行变形得到尺寸为1024
×4×
4的特征图f0;第一个lacgn resblks模块以特征图f0为输入,其后每一个lacgn resblks模块均以前一个lacgn resblks模块输出的特征图作为输入,输出与空间信息进一步融合的特征图其中,ci,wi、hi为第i个lacgn resblks块生成的图像特征图的通道数、宽度和高度。经过6次lacgn resblks上采样后,图像特征图的分辨率由4
×
4变为256
×
256。经过多个lacgn resblks处理,得到最终的特征图,再经过tanh函数处理后,得到合成的真实感图像i。
[0032]
图2为本发明的lacgn block模块图。对于lacgn block,其具体实现过程如下:
[0033]
(1)对输入的特征图进行空间感知预测
[0034]
所提出的位置感知预测模块lapm的结构如图2左上方的虚线框所示。具体来说,对于输入的特征图fi,首先在空间维度上将其进行average pooling和max pooling操作,生成两个新的特征映射;然后再将两个新的特征映射相连,进行卷积运算,并应用sigmoid激活函数计算空间感知映射图pi,可以用下面公式来表示:
[0035]
pi=s(conv(concat(avepool(fi),maxpool(fi))))
[0036]
其中,fi表示输入的特征图;avepool()、maxpool()分别表示在通道维度的平均池化和最大池化;concat()表示通道连接;conv()表示卷积;s()表示sigmoid激活函数。
[0037]
(2)对输入的语义分割掩码进行指导抽样
[0038]
指导抽样模块gsm的结构如图2右上方的实线框所示。具体而言,将输入的语义分割掩码m输入到调制网络,以生成密集的调制参数张量γi和βi,记为:
[0039]
γi=s
γ
(m)
[0040]
βi=s
β
(m)
[0041]
(3)位置感知条件组规范化
[0042]
将输入的特征图fi进行组规范化得到再与调制参数γi和βi以及位置感知信息pi按如下公式进行融合得到新的特征图f
i 1
。
[0043][0044]
本发明的有益效果可以通过以下实验进一步说明。
[0045]
实验环境为windows 10系统,程序语言为python,硬件配置为intel(r)core(tm)i7-8700,主频3.20ghz cpu,内存为16.00gb,显卡为1块nvidia v100。采用的数据集为citysacpes、ade20k、ade20k-outdoor数据集。
[0046]
具体实施步骤为:
[0047]
步骤1:将从正态分布中采样的256维噪声向量z∈r
256
作为输入;
[0048]
步骤2:同时把数据集中的语义分割掩码m随着网络的加深进行降采样操作;
[0049]
步骤3:把输入送入la-gan网络模型中进行处理,得到对应的合成图像;
[0050]
步骤4:把得到的合成图像进行语义分割操作得到新的语义分割图,与原语义分割图计算得到平均交并比miou和像素精度acc。同时把合成图像和原图像对比计算fid。
[0051]
根据以上步骤,在citysacpes、ade20k、ade20k-outdoor数据集上,将本发明所述的la-gan网络模型与crn模型、sims模型、pix2pixhd模型等多个模型进行对比,结果如表1所示。从表1中可以看出,本发明提出的方法在miou、acc和fid上都明显优于其他方法。
[0052]
表1不同模型针语义图像合成结果对比
[0053][0054]
同时,图3-5展示了本发明的合成图片的效果图,可以观察到本发明合成的图像更加清晰真实,拥有更少的伪影,也减少了空间扭曲变形的情况。
[0055]
从图6中可以发现bn随着批大小的改变fid数值的大小有很大幅度的改变,然而gn一直维持在一个稳定的范围内。这说明本发明消除了对batch size大小的依赖,使其训练的更加稳定。
[0056]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。