1.本技术涉及计算机技术领域,特别涉及一种音频处理方法、装置、系统、终端及计算机可读存储介质。
背景技术:
2.现实生活中,噪声无处不在,以语音会议场景为例,在采集主讲人音频信号时,会采集到其他人的音频信号以及主讲人所处环境的环境噪声,这些都属于语音会议场景中的噪声,这些噪声的存在使得采集到的音频信号的质量严重降低,从而影响后续的音频信号处理过程,使得音频信号的处理效果较差。
3.相关技术中,在采集到音频信号后,通常会对采集到的音频信号进行降噪处理,以提高音频信号的质量,进而提高音频信号的处理效果。
4.其中,在对音频信号进行降噪处理时,主要是基于声音强度,来区分噪声和主讲人音频信号,从而实现噪声和主讲人音频信号的分离。然而,在低信噪比情况下,噪声和主讲人音频信号的声音强度基本相同,从而使得无法基于声音强度来区分噪声和主讲人音频信号,进而使得降噪效果较差。
技术实现要素:
5.本技术提供了一种音频处理方法、装置、系统、终端及计算机可读存储介质,能够提高低信噪比情况下的降噪效果。本技术提供的技术方案如下:
6.第一方面,提供了一种音频处理方法,由第一终端执行,该方法包括:
7.获取第一音频信号,该第一音频信号通过该第一终端采集得到;
8.确定该第一音频信号的气流特征,该气流特征用于指示呼吸的气流速度随时间的变化情况;
9.若该气流特征指示该第一音频信号不包括鼻子呼吸声,则基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号。
10.本技术提供的方案,通过确定能够指示呼吸的气流速度随时间的变化情况的气流特征,进而在第一音频信号的气流特征指示第一音频信号不包括鼻子呼吸声时,以气流特征作为分离目标用户的音频信号的依据,从第一音频信号中分离出目标用户的音频信号,实现对第一音频信号的降噪,而信噪比的高低不会对气流特征造成影响,从而能够保证低信噪比情况下的降噪效果。
11.在一种可能的实现方式中,确定该第一音频信号的气流特征包括:
12.基于该第一音频信号的频谱,确定该第一音频信号的气流特征。
13.由于第一音频信号的频谱是由多个音频信号混叠而成的,而这多个音频信号中即包括目标用户的呼吸所产生的音频信号,而基于呼吸所产生的音频信号对应的频谱,即能确定出相应的气流特征,因而通过基于第一音频信号的频谱,能够确定出第一音频信号的气流特征,而目标用户说话和不说话时的气流特征是不同的,因而能够基于第一音频信号
的气流特征来确定目标用户是否正在说话。
14.在一种可能的实现方式中,基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号包括:
15.在该第一音频信号的频谱中,基于该气流特征进行对比;
16.将与该气流特征的相似度大于或等于参考相似度的频谱,确定为该目标用户的音频信号对应的频谱;
17.基于该目标用户的音频信号对应的频谱,确定该目标用户的音频信号。
18.由于目标用户(也即是主讲人)说话时通过嘴进行呼吸,而不会通过鼻子进行呼吸,因而在目标用户说话的场景下,第一终端不会采集到目标用户的鼻子呼吸声,而会采集到目标用户说话时的口呼吸声,而口呼吸声的频率与人说话的频率基本一致,因而通过基于该气流特征进行对比,以确定频谱中与气流特征的相似度大于或等于参考相似度的频谱,这个频谱也即是目标用户的音频信号对应的频谱,从而实现目标用户的音频信号的确定,正是由于是基于频率来区分目标用户的声音和其他人的声音的,而低信噪比不会对信号的频率造成影响,从而能够保证区分的准确性,进而提高低信噪比条件下的降噪效果。
19.在一种可能的实现方式中,确定该第一音频信号的气流特征之后,该方法还包括:
20.若该气流特征指示该第一音频信号包括鼻子呼吸声,则过滤该第一音频信号。
21.人在说话时是通过嘴来进行呼吸的,而不会通过鼻子呼吸,因此,在气流特征指示该第一音频信号包括鼻子呼吸声的情况下,能够确定目标用户此时并没有在说话,此时直接过滤掉第一音频信号,也就过滤掉了其他人说话的声音和环境噪音,实现了降噪处理,使得后续无需再对第一音频信号进行处理,从而减少了第一终端的处理压力。
22.在一种可能的实现方式中,该方法还包括:
23.获取至少一个第二音频信号,该至少一个第二音频信号通过该第一终端所关联的至少一个第二终端采集得到;
24.该基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号之后,该方法还包括:
25.基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号。
26.通过获取第一终端所关联的至少一个第二终端所采集到的至少一个第二音频信号,进而基于至少一个第二音频信号,来对目标用户的音频信号进行重采样,能够实现音频信号的增强,从而获取到质量更高的目标音频信号。
27.在一种可能的实现方式中,基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号包括:
28.对该至少一个第二音频信号采样,得到多个采样点的第一幅值;
29.对该多个采样点的第一幅值进行增益,得到该多个采样点的第二幅值,将该多个采样点以及对应的第二幅值插入该目标用户的音频信号,得到该目标音频信号。
30.通过对至少一个第二音频信号采样后进行增益,从而能够增强第二音频信号的强度,进而,将采样得到的多个采样点以及增益后得到的多个采样点的第二幅值,插入到目标用户的音频信号中,能够提高音频信号的采样精度,从而提高音频信号的质量。
31.在一种可能的实现方式中,该至少一个第二音频信号为该至少一个第二终端所采
集的原始音频信号中符合对应衰减规律的音频信号。
32.上述符合对应衰减规律的音频信号,也即是至少一个第二终端采集到的目标用户的音频信号,也就能够基于至少一个第二终端采集到的目标用户的音频信号,来对第一终端处理得到的目标用户的音频信号进行增强,从而提高音频信号的质量。
33.在一种可能的实现方式中,该衰减规律与距离相关,该距离为第二终端和该第一终端之间的距离。
34.不同的距离对应于不同的衰减规律,这样能够利用所采集到的信号和对应的衰减规律,来从第二终端所采集到的信号中,分离出相应的音频信号,来对目标用户的音频信号进行增强。
35.在一种可能的实现方式中,该方法还包括:
36.该第一终端和该第二终端上均运行有目标应用程序,或,该第一终端上运行有该目标应用程序,该第二终端的电话号码为该第一终端的关联号码。
37.上述过程提供了两种不同的终端关联方式,从而使得第一终端和第二终端能够在音频采集过程中执行相应步骤。
38.在一种可能的实现方式中,该方法还包括:
39.显示目标应用程序的关联设备配置界面,该关联设备配置界面用于提供能够进行音频信号采集的第二终端;
40.基于与该至少一个第二终端之间的连接,传输音频信号。
41.通过提供一个目标应用程序的关联设备配置界面,以便相关人员能够通过关联设备配置界面,来选择要关联的第二终端,进而通过与第二终端建立连接,来进行音频信号的传输。
42.在一种可能的实现方式中,该方法还包括:
43.获取该第一终端和该至少一个第二终端之间的至少一个第一距离;
44.若任一个第二终端的该第一距离不属于参考距离区间,发出移动提示,该移动提示用于指示对该任一个第二终端进行移动。
45.通过对第一终端和至少一个第二终端之间的第一距离进行检测,进而在任一个第二终端的第一距离不属于参考距离区间时,提示相关人员来对任一个第二终端进行移动,以便各个终端能够位于用于实现本技术所提供方法的位置上。
46.在一种可能的实现方式中,若该第二终端为手机,则该连接为蓝牙连接;
47.若该第二终端为ip电话,则该连接为该第一终端和该第二终端之间的有线连接。
48.通过为不同类型的第二终端,提供不同的连接方式,以使第一终端和第二终端能够实现彼此之间的连接,以保证后续的音频信号传输过程的顺利实现。
49.在一种可能的实现方式中,该方法还包括:
50.响应于对该第一终端的采集启动操作,触发该至少一个第二终端进行音频信号采集。
51.通过在第一终端启动音频信号采集后,启动至少一个第二终端的音频信号采集过程,以使第一音频信号和至少一个第二音频信号对应的开始采集时刻相同,以便基于至少一个第二音频信号来对第一音频信号进行处理。
52.第二方面,提供了一种音频处理装置,该音频处理装置具有实现上述第一方面或
第一方面任一种可能的实现方式中的音频处理方法的功能。该音频处理装置包括至少一个模块,至少一个模块用于实现上述第一方面或第一方面任一种可能的实现方式所提供的音频处理方法。第二方面所提供的音频处理装置的具体细节可参见上述第一方面或第一方面任一种可能的实现方式,此处不再赘述。
53.第三方面,提供了一种音频处理系统,该音频处理系统包括:
54.第一终端,用于进行音频信号采集,得到第一音频信号;
55.至少一个第二终端,用于进行音频信号采集,得到至少一个第二音频信号;
56.该第一终端,还用于基于获取该第一终端所采集的第一音频信号和该至少一个第二终端所采集的至少一个第二音频信号;确定该第一音频信号的气流特征,该气流特征用于指示呼吸的气流速度随时间的变化情况;若该气流特征指示该第一音频信号不是呼吸声,基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号;基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号。
57.在一种可能的实现方式中,该第一终端,还用于基于该第一音频信号的频谱,确定该第一音频信号的气流特征。
58.在一种可能的实现方式中,该第一终端,还用于在该第一音频信号的频谱中,基于该气流特征进行对比;将与该气流特征的相似度大于或等于参考相似度的频谱,确定为该目标用户的音频信号对应的频谱;基于该目标用户的音频信号对应的频谱,确定该目标用户的音频信号。
59.在一种可能的实现方式中,该第一终端,还用于若该气流特征指示该第一音频信号包括鼻子呼吸声,则过滤该第一音频信号。
60.在一种可能的实现方式中,该第一终端,还用于获取至少一个第二音频信号,该至少一个第二音频信号通过该第一终端所关联的至少一个第二终端采集得到;基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号。
61.在一种可能的实现方式中,该第一终端,还用于对该至少一个第二音频信号采样,得到多个采样点的第一幅值;对该多个采样点的第一幅值进行增益,得到该多个采样点的第二幅值,将该多个采样点以及对应的第二幅值插入该目标用户的音频信号,得到该目标音频信号。
62.在一种可能的实现方式中,该至少一个第二音频信号为该至少一个第二终端所采集的原始音频信号中符合对应衰减规律的音频信号。
63.在一种可能的实现方式中,该衰减规律与距离相关,该距离为第二终端和该第一终端之间的距离。
64.在一种可能的实现方式中,该第一终端和该第二终端上均运行有目标应用程序,或,该第一终端上运行有该目标应用程序,该第二终端的电话号码为该第一终端的关联号码。
65.在一种可能的实现方式中,该第一终端,还用于显示目标应用程序的关联设备配置界面,该关联设备配置界面用于提供能够进行音频信号采集的第二终端;基于与该至少一个第二终端之间的连接,传输音频信号。
66.在一种可能的实现方式中,该第一终端,还用于获取该第一终端和该至少一个第二终端之间的至少一个第一距离;若任一个第二终端的该第一距离不属于参考距离区间,
发出移动提示,该移动提示用于指示对该任一个第二终端进行移动。
67.在一种可能的实现方式中,若该第二终端为手机,则该连接为蓝牙连接;
68.若该第二终端为ip电话,则该连接为该第一终端和该第二终端之间的有线连接。
69.在一种可能的实现方式中,该第一终端,还用于响应于对该第一终端的采集启动操作,触发该至少一个第二终端进行音频信号采集。
70.第四方面,提供了一种终端,该终端包括处理器和存储器,该存储器中存储有至少一条指令,该指令由处理器读取以使该终端执行上述第一方面或第一方面任一种可能的实现方式中的音频处理方法。
71.第五方面,提供了一种计算机可读存储介质,该计算机可读存储介质中存储有至少一条指令,该指令由终端的处理器读取,以使该终端执行上述第一方面或第一方面任一种可能的实现方式中的音频处理方法。
72.第六方面,提供了一种计算机程序产品,当该计算机程序产品在终端上运行时,使得终端执行上述第一方面或第一方面任一种可能的实现方式中的音频处理方法。
73.第七方面,提供了一种芯片,该芯片包括处理电路和与该处理电路内部连接通信的输入输出接口,该处理电路和该输入输出接口分别用于实现上述第一方面或第一方面任一种可能的实现方式中的音频处理方法。
附图说明
74.图1是本技术实施例提供的一种音频处理系统的系统架构图;
75.图2是本技术实施例提供的一种终端200的结构示意图;
76.图3是本技术实施例提供的一种音频处理方法的流程图;
77.图4是本技术实施例提供的一种鼻息气流特征的示意图;
78.图5是本技术实施例提供的一种采用线性插值算法所得到的频谱示意图;
79.图6是本技术实施例提供的一种采用余弦插值算法所得到的频谱示意图;
80.图7是本技术实施例提供的一种音频处理过程的简要流程示意图;
81.图8是本技术实施例提供的一种音频处理过程的具体流程示意图;
82.图9是本技术实施例提供的一种音频处理方法的组网图;
83.图10是本技术实施例提供的一种音频处理装置的结构示意图。
具体实施方式
84.本技术中术语“第一”、“第二”等字样用于区分作用和功能基本相同的相同项或相似项,应理解,“第一”、“第二”、“第n”之间不具有逻辑或时序上的依赖关系,也不限定数量和执行顺序。还应理解,尽管以下描述使用术语第一、第二等来描述各种元素,但这些元素不应受术语的限制。这些术语只是用于将一元素与另一元素区别分开。例如,在不脱离各种示例的范围的可能情况下,第一终端被称为第二终端,并且类似地,第二终端被称为第一终端。第一终端和第二终端都是终端,并且在某些可能的情况下,第一终端和第二终端是单独且不同的终端。
85.还应理解,术语“若”被解释为意指“当...时”(“when”或“upon”)或“响应于确定”或“响应于检测到”。
86.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
87.图1是本技术实施例提供的一种音频处理系统的系统架构图,参见图1,该音频处理系统包括:第一终端101和至少一个第二终端102。
88.第一终端101和至少一个第二终端102均为用户设备(user equipment,ue)、接入终端、用户单元、用户站、移动站、移动台、远方站、远程终端、移动设备、用户终端、终端、无线通信设备、用户代理或用户装置等。可选地,接入终端是蜂窝电话、无绳电话、会话启动协议(session initiation protocol,sip)电话、无线本地环路(wireless local loop,wll)站、个人数字处理(personal digital assistant,pda)、具有无线通信功能的手持设备、计算设备或连接到无线调制解调器的其它处理设备、车载设备、可穿戴设备以及未来5g网络中的终端设备或者未来演进的公共陆地移动网络(public land mobile network,plmn)中的终端设备等,本技术实施例对此不加以限定。
89.作为示例而非限定,在本技术实施例的其他可能实现方式中,该终端101和至少一个第二终端102均为可穿戴设备。可穿戴设备或称为穿戴式智能设备,是应用穿戴式技术对日常穿戴进行智能化设计、开发出的能够穿戴的设备的总称,如眼镜、手套、手表、服饰及鞋等。可穿戴设备即直接穿在身上,或是整合到用户的衣服或配件的一种便携式设备。可穿戴设备不仅仅是一种硬件设备,还能够通过软件支持以及数据交互、云端交互来实现强大的功能。广义穿戴式智能设备包括功能全、尺寸大、可不依赖智能手机实现完整或者部分功能的设备,例如:智能手表或智能眼镜等,以及只专注于某一类应用功能、需要和其它设备(如智能手机)配合使用的设备,如各类监测体征的智能手环、智能首饰等。
90.可选地,第一终端101和至少一个第二终端102为相同类型的终端,或者,第一终端101和至少一个第二终端102为不同类型的终端,本技术实施例对此不加以限定。第一终端101和至少一个第二终端102通过有线或无线通信方式连接,本技术实施例对此不加以限定。
91.第一终端101获取第一音频信号,并对第一音频信号进行降噪处理,得到目标用户的音频信号。可选地,至少一个第二终端102获取至少一个第二音频信号,并将获取到的至少一个第二音频信号发送给第一终端101,以便第一终端101基于至少一个第二音频信号,来对目标用户的音频信号继续进行处理,以得到目标音频信号。
92.在更多可能的实现方式中,该音频处理系统还包括服务器103。
93.服务器103为一台服务器、多台服务器、云计算平台和虚拟化中心中的至少一种。服务器103通过有线或无线通信方式与第一终端101连接,本技术实施例对此不加以限定。可选地,上述服务器的数量更多或更少,本技术实施例对此不加以限定。在更多可能的实现方式中,服务器103还包括其他功能服务器,以便提供更全面且多样化的服务。
94.本技术实施例提供的方案,能够用于多种场景中,以将本技术实施例提供的方案用在语音会议场景中为例,若第一终端101通过对第一音频信号进行降噪处理,得到了目标用户的音频信号,则第一终端101将目标用户的音频信号发送给服务器103,通过服务器103将目标用户的音频信号发送给参与会议的其他终端。可选地,若第一终端101在获取到目标用户的音频信号后,还对目标用户的音频信号进行了进一步处理,得到了目标音频信号,则第一终端101将目标音频信号发送给服务器103,通过服务器103将目标音频信号发送给参
与会议的其他终端。
95.图2是本技术实施例提供的一种终端200的结构示意图,参见图2,终端200包括射频(radio frequency,rf)电路210、包括有一个或一个以上计算机可读存储介质的存储器220、输入单元230、显示单元240、传感器250、音频电路260、无线保真(wireless fidelity,wifi)模块270、包括有一个或者一个以上处理核心的处理器280、以及电源290等部件。本领域技术人员能够理解,图2中示出的终端结构并不构成对终端的限定,在更多可能的实现方式中,该终端200包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。其中:
96.rf电路210用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,交由一个或者一个以上处理器280处理;另外,将涉及上行的数据发送给基站。通常,rf电路210包括但不限于天线、至少一个放大器、调谐器、一个或多个振荡器、用户身份模块(sim)卡、收发信机、耦合器、低噪声放大器(low noise amplifier,lna)、双工器等。此外,rf电路210通过无线通信与网络和其他设备通信。其中,无线通信使用任一通信标准或协议,包括但不限于全球移动通讯系统(global system of mobile communication,gsm)、通用分组无线服务(general packet radio service,gprs)、码分多址(code division multiple access,cdma)、宽带码分多址(wideband code division multiple access,wcdma)、长期演进(long term evolution,lte)、电子邮件、短消息服务(short messaging service,sms)等。
97.存储器220用于存储软件程序以及模块,处理器280通过运行存储在存储器220的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器220主要包括存储程序区和存储数据区,其中,存储程序区能够存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区能够存储根据终端200的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器220包括高速随机存取存储器,还包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。相应地,存储器220还包括存储器控制器,以提供处理器280和输入单元230对存储器220的访问。
98.输入单元230用于接收输入的数字或字符信息,以及产生与用户设置以及功能控制有关的键盘、鼠标、操作杆、光学或者轨迹球信号输入。具体地,输入单元230包括触敏表面231以及其他输入设备232。触敏表面231,也称为触摸显示屏或者触控板,用于收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触敏表面231上或在触敏表面231附近的操作),并根据预先设定的程式驱动相应的连接装置。可选地,触敏表面231包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器280,并能接收处理器280发来的命令并加以执行。可选地,采用电阻式、电容式、红外线以及表面声波等多种类型实现触敏表面231。除了触敏表面231,输入单元230还包括其他输入设备232。具体地,其他输入设备132包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
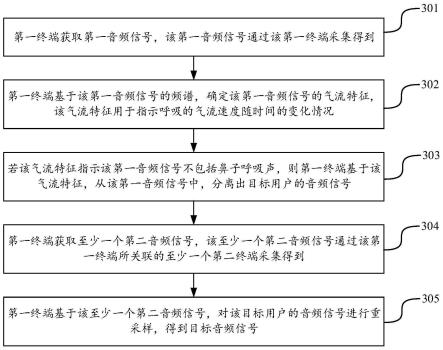
99.显示单元240用于显示由用户输入的信息或提供给用户的信息以及终端200的各种图形用户接口,这些图形用户接口由图形、文本、图标、视频和其任意组合来构成。显示单
元240包括显示面板241,可选地,采用液晶显示器(liquid crystal display,lcd)、有机发光二极管(organic light-emitting diode,oled)等形式来配置显示面板241。进一步的,触敏表面231可覆盖显示面板241,当触敏表面231检测到在其上或附近的触摸操作后,传送给处理器280以确定触摸事件的类型,随后处理器280根据触摸事件的类型在显示面板241上提供相应的视觉输出。虽然在图2中,触敏表面231与显示面板241是作为两个独立的部件来实现输入和输入功能,但是在某些实施例中,将触敏表面231与显示面板241集成而实现输入和输出功能。
100.终端200还包括至少一种传感器250,比如光传感器、运动传感器以及其他传感器。具体地,光传感器包括环境光传感器及接近传感器,其中,环境光传感器根据环境光线的明暗来调节显示面板241的亮度,接近传感器可在终端200移动到耳边时,关闭显示面板241和/或背光。作为运动传感器的一种,重力加速度传感器能够检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,能够用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于终端200还能够配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
101.音频电路260、扬声器261,传声器262提供用户与终端200之间的音频接口。音频电路260将接收到的音频数据转换后的电信号,传输到扬声器261,由扬声器261转换为音频信号输出;另一方面,传声器262将收集的音频信号转换为电信号,由音频电路260接收后转换为音频数据,再将音频数据输出处理器280处理后,经rf电路210以发送给比如另一终端,或者将音频数据输出至存储器220以便进一步处理。音频电路260还可能包括耳塞插孔,以提供外设耳机与终端200的通信。
102.wifi属于短距离无线传输技术,终端200通过wifi模块270帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图2示出了wifi模块270,但是能够理解的是,其并不属于终端200的必须构成,在更多可能的实现方式中,根据需要在不改变发明的本质的范围内而省略。
103.处理器280是终端200的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器220内的软件程序和/或模块,以及调用存储在存储器220内的数据,执行终端200的各种功能和处理数据,从而对手机进行整体监控。可选地,处理器280包括一个或多个处理核心;可选地,处理器280集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可选地,上述调制解调处理器不集成到处理器280中。
104.终端200还包括给各个部件供电的电源290(比如电池),可选地,电源通过电源管理系统与处理器280逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。电源290还包括一个或一个以上的直流或交流电源、再充电系统、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。
105.尽管未示出,终端200还包括摄像头、蓝牙模块等,在此不再赘述。具体在本实施例中,终端的显示单元是触摸屏显示器,终端还包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行。该一个或者一个以上程序包含用于执行终端侧的音频处理方法的指令。
106.图3是本技术实施例提供的一种音频处理方法的流程图,参见图3,该方法流程包括:
107.301、第一终端获取第一音频信号,该第一音频信号通过该第一终端采集得到。
108.在一种可能的实现方式中,第一终端通过麦克风组件采集第一音频信号。
109.其中,该麦克风组件内置或外接于第一终端,本技术实施例对此不加以限定。该麦克风组件的声学腔体结构为对气流敏感的声学腔体结构,可选地,该麦克风组件的声学腔体结构为其他类型,本技术实施例对此不加以限定。
110.本技术实施例中,第一终端配置有对气流敏感的声学腔体结构的麦克风组件,以便能获取到人在说话或呼吸时发出的气流所导致的音频信号,从而能够为后续的语音分离提供参考,进而提高语音分离过程的准确程度,提高了后续的音频处理过程的准确性。
111.302、第一终端基于该第一音频信号的频谱,确定该第一音频信号的气流特征,该气流特征用于指示呼吸的气流速度随时间的变化情况。
112.在一种可能的实现方式中,第一终端采用盲源分离技术,从第一音频信号的频谱中分离出多个频谱信号,在该第一音频信号的频谱中,确定处于相同频率范围内的两个频谱信号,进而将这两个频谱信号中幅值较小的目标频谱信号的变化信息,确定为该第一音频信号的气流特征,该变化信息表示该频谱信号随时间的变化情况。
113.由于第一音频信号的频谱是由多个音频信号混叠而成的,而这多个音频信号中即包括目标用户的呼吸所产生的音频信号,而基于呼吸所产生的音频信号对应的频谱,即能确定出相应的气流特征,因而通过基于第一音频信号的频谱,能够确定出第一音频信号的气流特征,而目标用户说话和不说话时的气流特征是不同的,因而能够基于第一音频信号的气流特征来确定目标用户是否正在说话。
114.其中,该第一音频信号的频谱的确定过程包括:第一终端在获取到该第一音频信号后,对该第一音频信号进行傅里叶变换,从而得到该第一音频在频域上的幅值信息,也即是,得到该第一音频信号的频谱。例如,第一终端对该第一音频信号进行短时傅里叶变换,从而得到该第一音频信号的频谱。
115.可选地,该变化信息为目标频谱信号的能量随时间的变化情况,或者,该变化信息为其他类型,本技术实施例对此不加以限定。以该变化信息为目标频谱信号的能量随时间的变化情况为例,该变化信息的确定过程包括:第一终端基于该目标频谱信号的频谱,确定该频谱中各个频率对应的幅值的平方值,以得到该目标频谱信号的各个频率对应的能量值,从而得到该目标频谱信号的能量谱,并基于该目标频谱信号的能量谱,确定目标频谱信号的能量随时间的变化情况,作为该目标频谱信号的变化信息。
116.上述仅为确定第一音频信号的气流特征的一种示例性方式,在更多可能的实现方式中,采用其他方式来确定第一音频信号的气流特征,本技术实施例对此不加以限定。
117.303、若该气流特征指示该第一音频信号不包括鼻子呼吸声,则第一终端基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号。
118.气流速度是与音量相关的,气流速度越快,音量越大,气流速度越慢,音量越小,因而,呼吸或说话时的气流导致的音量随时间的变化规律,是与气流特征相似的,相应地,呼吸或说话时的气流对应的音频信号的能量谱,也是与气流特征相似的。
119.而人在用鼻子呼吸时的气流特征满足一定规律,参见图4,图4是本技术实施例提
供的一种鼻息气流特征的示意图,该图展示出了人用鼻子呼吸所导致的2秒(s)内气流速度随时间的变化规律,通过该图能够确定2s内的呼吸气流规律为v=2.57sin(3.14t),其中,v表示气流速度,t表示时间。
120.在一种可能的实现方式中,第一终端将确定出的气流特征与该鼻息气流特征进行对比,若确定出的气流特征与鼻息气流特征不同,则确定第一音频信号不包括鼻子呼吸声,则第一终端在该第一音频信号的频谱中,基于该气流特征进行对比,将与该气流特征的相似度大于或等于参考相似度的频谱,确定为该目标用户的音频信号对应的频谱,进而基于目标用户的音频信号对应的频谱,确定目标用户的音频信号。
121.由于目标用户(也即是主讲人)说话时通过嘴进行呼吸,而不会通过鼻子进行呼吸,因而在目标用户说话的场景下,第一终端不会采集到目标用户的鼻子呼吸声,而会采集到目标用户说话时的口呼吸声,而口呼吸声的频率与人说话的频率基本一致,因而通过将获取到的气流特征对应的频率,作为目标用户的音频信号对应的频率,进而在第一音频信号的频谱中,基于气流特征进行对比,以找到频率与气流特征对应频率近似的频谱,也即是目标用户的音频信号对应的频谱,从而实现目标用户的音频信号的确定,实现目标用户的音频信号的定向拾取,正是由于是基于频率来区分目标用户的声音和其他人的声音的,而低信噪比不会对信号的频率造成影响,从而能够保证区分的准确性,进而提高低信噪比条件下的降噪效果,也就能够更加高效地从第一音频信号中获取到目标用户的音频信号,达到更好的音频信号提取效果,进而解决特定场景(如语音会议场景)下的鸡尾酒会效应问题。
122.可选地,若确定出的气流特征与鼻息气流特征相同,则确定该第一音频信号包括鼻子呼吸声,则第一终端过滤该第一音频信号。人在说话时是通过嘴来进行呼吸的,而不会通过鼻子来进行呼吸。因此,通过鼻息气流特征来反向推断目标用户是否正在讲话,在气流特征指示该第一音频信号包括鼻子呼吸声的情况下,能够确定目标用户此时并没有在说话,能够更加准确地判断目标用户是否处于讲话状态,进而实现更加精准的音频过滤。而且,直接过滤掉第一音频信号,也就过滤掉了其他人说话的声音和环境噪音,实现了降噪处理,使得后续无需再对第一音频信号进行处理,从而减少了第一终端的处理压力。
123.304、第一终端获取至少一个第二音频信号,该至少一个第二音频信号通过该第一终端所关联的至少一个第二终端采集得到。
124.其中,第一终端已预先关联有至少一个第二终端,而在关联第一终端与第二终端时,第一终端和第二终端上均运行有目标应用程序,或,第一终端上运行有目标应用程序,第二终端的电话号码为第一终端的关联号码,从而实现第一终端与第二终端的关联。在更多可能的实现方式中,采用其他方式来实现第一终端和第二终端的关联,本技术实施例对此不加以限定。
125.通过关联第一终端和与第一终端处在同一环境中的第二终端,以使第一终端和第一终端周围的第二终端能够组成异源的信号输入网络,实现了动态利用现有外设,来组成用于音频处理的信号输入网络,进而通过第一终端和第一终端所关联的第二终端来采集同一音源的音频信号,无需在第一终端中增加麦克风组件,也即是,无需改变第一终端的硬件结构,而且也无需额外增设麦克风阵列,降低硬件成本,而且第二终端的位置能够根据需求进行移动,从而提高了音频处理过程的灵活性。
126.在一种可能的实现方式中,关联第一终端与第二终端的过程包括:第一终端显示该目标应用程序的关联设备配置界面,该关联设备配置界面用于提供能够进行音频信号采集的第二终端,以便相关人员从关联设备配置界面所提供的第二终端中,选择要关联的第二终端,第一终端响应于用户对至少一个第二终端的选中操作,关联第一终端与被选中的至少一个第二终端。通过提供一个目标应用程序的关联设备配置界面,以便相关人员能够通过关联设备配置界面,来选择要关联的第二终端,进而通过与第二终端建立连接,来进行音频信号的传输。
127.其中,该目标应用程序为会议软件,或者,该目标应用程序为其他类型的软件等,本技术实施例对此不加以限定。该第一终端通过在目标应用程序的关联设备配置界面中显示能够进行音频信号采集的第二终端的设备名称,从而在该关联设备配置界面中提供能够进行音频信号采集的第二终端。
128.上述过程提供了两种不同的终端关联方式,从而使得第一终端和第二终端能够在音频采集过程中执行相应步骤。
129.上述仅为关联第一终端与第二终端时的操作过程,可选地,不同类型的第二终端对应于不同的关联方式。在一种可能的实现方式中,相关人员在选择了要关联的至少一个第二终端后,第一终端获取该至少一个第二终端的设备类型,进而基于该至少一个第二终端的设备类型,确定第一终端与第二终端的关联方式。例如,若第二终端为手机,则第一终端和第二终端上均运行有目标应用程序,从而通过目标应用程序实现第一终端与第二终端的关联;若第二终端为网际协议地址(internet protocol address,ip)电话,则第二终端的电话号码为第一终端的关联号码,从而实现第一终端与第二终端的关联。上述仅为一种确定关联方式的示例性方式,在更多可能的实现方式中,采用其他方式来确定关联方式,本技术实施例对此不加以限定。
130.此外,不同类型的第二终端还对应于不同的连接方式,也即是,该第一终端与第二终端的连接方式,基于第二终端的设备类型确定。例如,若该第二终端为手机,则该连接为蓝牙连接;若该第二终端为ip电话,则该连接为该第一终端和该第二终端之间的有线连接。上述仅为一种确定连接方式的示例性方式,在更多可能的实现方式中,采用其他方式来确定连接方式,本技术实施例对此不加以限定。
131.在更多可能的实现方式中,为了便于进行音频信号的采集,使得第二终端所采集到的音频信号的强度符合要求,本技术实施例还能够提供一种智能化的操作提示功能。例如,第一终端获取该第一终端和该至少一个第二终端之间的至少一个第一距离;若任一个第二终端的该第一距离不属于参考距离区间,发出移动提示,该移动提示用于指示对该任一个第二终端进行移动。
132.通过对第一终端和至少一个第二终端之间的第一距离进行检测,进而在任一个第二终端的第一距离不属于参考距离区间时,提示相关人员来对任一个第二终端进行移动,以便各个终端能够位于用于实现本技术所提供方法的位置上。
133.其中,第一终端和至少一个第二终端之间的至少一个第一距离的获取过程包括:第一终端向至少一个第二终端发送位置获取指令,至少一个第二终端响应于接收到的位置获取指令,获取自身的位置信息,进而将获取到的位置信息发送给第一终端,以便第一终端基于接收到的至少一个第二终端的位置信息以及第一终端自身的位置信息,确定该第一终
端与该至少一个第二终端之间的第一距离。
134.需要说明的是,上述仅为一种获取第一终端和至少一个第二终端之间的至少一个第二距离的示例性方式,在更多可能的实现方式中,采用其他方式来获取该至少一个第一距离,本技术实施例对此不加以限定。
135.其中,该参考距离区间为0.3米至0.5米,或者,该参考距离区间为其他取值,本技术实施例对此不加以限定。
136.在第一终端与至少一个第二终端关联成功后,第一终端响应于对该第一终端的采集启动操作,触发该至少一个第二终端进行音频信号采集。例如,第一终端响应于对该第一终端的采集启动操作,向所关联的至少一个第二终端发送信号采集指令,至少一个第二终端响应于接收到的信号采集指令,开始音频信号的采集,以得到至少一个原始音频信号。
137.通过在第一终端启动音频信号采集后,启动至少一个第二终端的音频信号采集过程,以使第一音频信号和至少一个第二音频信号对应的开始采集时刻相同,以便基于至少一个第二音频信号来对第一音频信号进行处理。
138.在一种可能的实现方式中,第一终端在获取到至少一个第二终端发送的至少一个原始音频信号后,对该至少一个原始音频信号进行处理,从而获取到该至少一个第二音频信号。
139.其中,该至少一个第二音频信号为该至少一个第二终端所采集的原始音频信号中符合对应衰减规律的音频信号,该衰减规律与距离相关,该距离为第二终端和该第一终端之间的距离。例如,该衰减规律与距离成正相关,该距离为第二终端和该第一终端之间的距离,也即是,第二终端与第一终端之间的距离越小,该第二音频信号的衰减越少,第二终端与第一终端之间的距离越大,该第二音频信号的衰减越多。例如,当第一终端与第二终端之间的距离为0.3米时,第二音频信号的衰减为8分贝(decibel,db),也即是,第二音频信号为符合8db衰减规律的信号;当第一终端与第二终端之间的距离为0.5米时,第二音频信号的衰减为10db,也即是,第二音频信号为符合10db衰减规律的信号。
140.上述符合对应衰减规律的音频信号,也即是至少一个第二终端采集到的目标用户的音频信号,也就能够基于至少一个第二终端采集到的目标用户的音频信号,来对第一终端处理得到的目标用户的音频信号进行增强,从而提高音频信号的质量。而不同的距离对应于不同的衰减规律,这样能够利用所采集到的信号和对应的衰减规律,来从第二终端所采集到的信号中,分离出相应的音频信号,来对目标用户的音频信号进行增强。
141.其中,对该至少一个原始音频信号进行处理,以得到该至少一个第二音频信号的过程包括:对于该至少一个原始音频信号中的任一个原始音频信号,第一终端对该任一个原始音频信号进行傅里叶变换,得到该任一个原始音频信号的频谱,进而从该第一原始音频信号的频谱中,分离出符合对应衰减规律的第二音频信号,以得到该任一个原始音频信号对应的第二音频信号。
142.上述过程是以第二终端获取到原始音频信号后,向第一终端发送原始音频信号,由第一终端自行处理原始音频信号,以得到第二音频信号为例来进行说明的,在更多可能的实现方式中,对于该至少一个第二终端中的任一个第二终端,该任一个第二终端在获取到原始音频信号后,自行处理所采集的原始音频信号,从而得到该原始音频信号对应的第二音频信号,第二终端会将处理后的第二音频信号发送至第一终端。其中,具体信号处理过
程与第一终端的处理过程同理,此处不再赘述。
143.通过从原始音频信号中分离出符合特定衰减规律的第二音频信号,而衰减规律是与第一终端和第二终端之间的距离相关的,从而保证分离出的第二音频信号为目标用户的音频信号,实现目标用户的音频信号的确定。
144.可选地,至少一个第二终端在获取到音频信号(包括原始音频信号和第二音频信号)后,即向第一终端发送获取到的音频信号;或者,至少一个第二终端在获取到音频信号后,先存储获取到的音频信号,进而在接收到第一终端发送的信号获取指令时,再发送获取到的音频信号,也即是,第一终端向至少一个第二终端发送信号获取指令,至少一个第二终端响应于接收到的信号获取指令,将所存储的音频信号发送给第一终端,本技术实施例对具体采用哪种方式不加以限定。
145.上述步骤304的标号并不构成对该步骤304的执行顺序的限定,可选地,第一终端在执行完步骤301至步骤303后,执行该步骤304,或者,第一终端在执行完步骤301后,先执行该步骤304,再执行步骤302至步骤303,或者,第一终端同时执行步骤301和步骤304后,再执行步骤302至步骤303,等等,本技术实施例对此不加以限定。
146.305、第一终端基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号。
147.在一种可能的实现方式中,第一终端对该至少一个第二音频信号采样,得到多个采样点的第一幅值;进而对该多个采样点的第一幅值进行增益,得到该多个采样点的第二幅值,将该多个采样点以及对应的第二幅值插入该目标用户的音频信号,得到该目标音频信号。
148.通过对至少一个第二音频信号采样后进行增益,从而能够增强第二音频信号的强度,进而,将采样得到的多个采样点以及增益后得到的多个采样点的第二幅值,插入到目标用户的音频信号中,能够提高音频信号的采样精度,从而提高音频信号的质量。
149.其中,对多个采样点的第一幅值进行增益,也即是基于至少一个第二音频信号的衰减,来对多个采样点的第一幅值进行补偿,第二音频信号的衰减越多,则补偿的幅值越多,相应地,第二音频信号的衰减越少,则补偿的幅值越少。
150.可选地,在将多个采样点以及对应的第二幅值插入目标用户的音频信号时,采用线性插值算法,或者,采用余弦插值算法,本技术实施例对此不加以限定。
151.其中,线性插值算法的实现代码如下:
[0152][0153]
参见图5,图5是本技术实施例提供的一种采用线性插值算法所得到的频谱示意图,该图5展示了通过线性插值算法所得到的频谱图。
[0154]
余弦插值算法的实现代码如下:
[0155][0156]
参见图6,图6是本技术实施例提供的一种采用余弦插值算法所得到的频谱示意图,该图6展示了通过余弦插值算法所得到的频谱图。
[0157]
本技术实施例中所涉及的音频处理过程通过数字信号处理(digital signal processing,dsp)芯片实现,对于第一终端和至少一个第二终端,该第一终端和至少一个第二终端所采用的dsp的芯片可能不同,从而可能使得第一终端和至少一个第二终端的采样精度不同,因此,可能会出现不同的采样点对应的频率相同,也即是,采样点重合的情况。因此,在将多个采样点以及对应的幅值插入目标用户的音频信号时,若该多个采样点之间存在重复的采样点,或者,该多个采样点与目标用户的音频信号原有的采样点之间存在重复的采样点,以重复的采样点对应的多个幅值的中值,作为该重复的采样点的幅值,以得到平滑的频谱,从而提高目标音频信号的质量。可选地,在确定重复的采样点的幅值时,以重复的采样点对应的多个幅值的平均值,作为重复的采样点的幅值,或者,采用其他方式,以保证第一终端能够获取到平滑的频谱即可,本技术实施例对具体采用哪种方式不加以限定。
[0158]
通过获取第一终端所关联的至少一个第二终端所采集到的至少一个第二音频信号,进而基于至少一个第二音频信号,来对目标用户的音频信号进行重采样,能够实现音频信号的增强,以及对其他人的音频信号和环境噪声的消减,以得到质量更高的目标音频信号,从而提高音频处理效果。
[0159]
需要说明的是,上述步骤304至步骤305为可选步骤,在更多可能的实现方式中,第一终端通过上述步骤301至步骤303获取到目标用户的音频信号后,直接发送目标用户的音频信号,无需进行后续的处理过程。
[0160]
可选地,第一终端在得到目标音频信号后,将该目标音频信号发送给服务器,从而通过服务器来发送该目标音频信号。以将本技术实施例所提供的方案应用在语音会议场景中为例,第一终端将该目标音频信号发送多媒体服务器,通过多媒体服务器将该目标音频信号发送给参与会议的多个终端,从而实现对于语音会议中所采集到的音频信号的处理,使得参与语音会议的各个用户都能获取到目标用户的目标音频信号。
[0161]
上述步骤301至步骤305所示的过程参见图7,图7是本技术实施例提供的一种音频处理过程的简要流程示意图,以该第一终端为个人计算机(personal computer,pc),与第一终端所关联的第二终端包括手机和ip电话为例,pc、手机和ip电话分别采集声音,并通过对应精度的dsp芯片对采集到的声音进行处理,以实现模拟信号到数字信号的转换,从而得到音频信号,进而将pc、手机和ip电话采集到的音频信号都输入作为第一终端的pc中,由pc对pc、手机和ip电话采集到的音频信号进行处理,从而得到目标音频信号,实现对音频信号的降噪处理以及增强处理。
[0162]
上述图7所示的过程仅为本技术实施例的简要流程,参见图8,图8是本技术实施例提供的一种音频处理过程的具体流程示意图,仍以该第一终端为pc,与第一终端所关联的
第二终端包括手机和ip电话为例,目标用户发出声音时,pc采集第一音频信号,进而基于采集到的第一音频信号进行鼻息气流特征分析,以通过确定第一音频信号是否包括鼻子呼吸声,来确定目标用户是否正在说话,若第一音频信号包括鼻子呼吸声,则确定目标用户没有在说话,此时直接过滤第一音频信号即可。若第一音频信号不包括鼻子呼吸声,则确定目标用户正在说话,此时通过对第一音频信号进行说话气流特征分析,以提取出目标用户的说话频率,进而基于目标用户的说话频率,从第一音频信号中分离出目标用户的音频信号,实现第一音频信号的语音分离。在分离出目标用户的音频信号后,基于手机采集到的第二音频信号、ip电话采集到的第二音频信号,也即是,基于第二音频信号经过傅里叶变换分离出各个频率的音频信号,来对目标用户的音频信号进行进一步处理,若分离出的音频信号符合目标用户的说话频率,则基于第二音频信号对目标用户的音频信号进行增强;若分离出的音频信号不符合目标用户的说话频率,则基于第二音频信号对目标用户的音频信号进行消减,进而得到目标音频信号,从而提高音频信号的处理效果。
[0163]
其中,第一终端与至少一个第二终端在网络层面的交互过程参见图9,图9是本技术实施例提供的一种音频处理方法的组网图,以在语音会议场景中,第一终端为pc,与第一终端所关联的第二终端包括手机和ip电话为例,pc硬件麦克风/扬声器接入高级linux声音体系(advanced linux sound architecture,alsa)硬件驱动程序,从而通过alsa源(alsa source)接入声音服务器内核(pulseaudio server core),手机和ip电话通过网络适配器(network adapter)接入网络堆栈(network stack),从而通过实时传输协议接收器(real-time transport protocol sink,rtp sink)接入pulseaudio server core,进而通过pulseaudio server core,基于操作系统/传输控制协议本机协议(unix/tcp native protocols),来调用高级linux声音体系静态库(libalsa pulse)中的类和函数,来实现音频信号的处理,从而得到目标音频信号,进而将目标音频信号传输给高级linux声音体系应用程序(alsa application,alsaapp),以保证线上语音会议的顺利进行。
[0164]
本技术实施例提供的方案,通过确定能够指示呼吸的气流速度随时间的变化情况的气流特征,进而在第一音频信号的气流特征指示第一音频信号不包括鼻子呼吸声时,以气流特征作为分离目标用户的音频信号的依据,从第一音频信号中分离出目标用户的音频信号,实现对第一音频信号的降噪,而信噪比的高低不会对气流特征造成影响,从而能够保证低信噪比情况下的降噪效果。进一步地,通过对至少一个第二音频信号采样后进行增益,从而能够增强第二音频信号的强度,进而将采样得到的多个采样点,以及增益后得到的多个采样点的第二幅值插入到目标用户的音频信号中,能够提高声音音频信号的采样精度,得到更精细的目标音频信号,从而提高音频信号的质量,也就能进一步提高第一音频信号的降噪效果。
[0165]
图10是本技术实施例提供的一种音频处理装置的结构示意图,参见图10,该装置包括:
[0166]
获取模块1001,用于执行步骤301的获取第一音频信号的过程,该第一音频信号通过该第一终端采集得到;
[0167]
确定模块1002,用于执行步骤302的确定该第一音频信号的气流特征的过程,该气流特征用于指示呼吸的气流速度随时间的变化情况;
[0168]
分离模块1003,用于执行步骤303的若该气流特征指示该第一音频信号不包括鼻
子呼吸声,则基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号的过程。
[0169]
本技术实施例提供的装置,通过确定能够指示呼吸的气流速度随时间的变化情况的气流特征,进而在第一音频信号的气流特征指示第一音频信号不包括鼻子呼吸声时,以气流特征作为分离目标用户的音频信号的依据,从第一音频信号中分离出目标用户的音频信号,实现对第一音频信号的降噪,而信噪比的高低不会对气流特征造成影响,从而能够保证低信噪比情况下的降噪效果。
[0170]
在一种可能的实现方式中,该确定模块1002,用于执行步骤302中基于该第一音频信号的频谱,确定该第一音频信号的气流特征的过程。
[0171]
在一种可能的实现方式中,该分离模块1003,用于执行步骤303中在该第一音频信号的频谱中,基于该气流特征进行对比;将与该气流特征的相似度大于或等于参考相似度的频谱,确定为该目标用户的音频信号对应的频谱;基于该目标用户的音频信号对应的频谱,确定该目标用户的音频信号的过程。
[0172]
在一种可能的实现方式中,该装置还包括:
[0173]
过滤模块,用于执行步骤303中若该气流特征指示该第一音频信号包括鼻子呼吸声,则过滤该第一音频信号的过程。
[0174]
在一种可能的实现方式中,该获取模块1001,还用于执行步骤304的获取至少一个第二音频信号的过程,该至少一个第二音频信号通过该第一终端所关联的至少一个第二终端采集得到;
[0175]
该装置还包括:
[0176]
重采样模块,用于执行步骤305的基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号的过程。
[0177]
在一种可能的实现方式中,该重采样模块,用于执行步骤305中对该至少一个第二音频信号采样,得到多个采样点的第一幅值;对该多个采样点的第一幅值进行增益,得到该多个采样点的第二幅值,将该多个采样点以及对应的第二幅值插入该目标用户的音频信号,得到该目标音频信号的过程。
[0178]
在一种可能的实现方式中,该至少一个第二音频信号为该至少一个第二终端所采集的原始音频信号中符合对应衰减规律的音频信号。
[0179]
在一种可能的实现方式中,该衰减规律与距离相关,该距离为第二终端和该第一终端之间的距离。
[0180]
在一种可能的实现方式中,该第一终端和该第二终端上均运行有目标应用程序,或,该第一终端上运行有该目标应用程序,该第二终端的电话号码为该第一终端的关联号码。
[0181]
在一种可能的实现方式中,该装置还包括:
[0182]
显示模块,用于执行步骤304中显示目标应用程序的关联设备配置界面的过程,该关联设备配置界面用于提供能够进行音频信号采集的第二终端;
[0183]
传输模块,用于执行步骤304中基于与该至少一个第二终端之间的连接,传输音频信号的过程。
[0184]
在一种可能的实现方式中,该获取模块1001,还用于执行步骤304中获取该第一终端和该至少一个第二终端之间的至少一个第一距离;
[0185]
该装置还包括:
[0186]
提示模块,用于执行步骤304中若任一个第二终端的该第一距离不属于参考距离区间,发出移动提示的过程,该移动提示用于指示对该任一个第二终端进行移动。
[0187]
在一种可能的实现方式中,若该第二终端为手机,则该连接为蓝牙连接;
[0188]
若该第二终端为ip电话,则该连接为该第一终端和该第二终端之间的有线连接。
[0189]
在一种可能的实现方式中,该装置还包括:
[0190]
触发模块,用于执行步骤304中响应于对该第一终端的采集启动操作,触发该至少一个第二终端进行音频信号采集的过程。
[0191]
需要说明的是:上述实施例提供的音频处理装置在处理音频信号时,仅以上述各功能模块的划分进行举例说明,实际应用中,根据需要而将上述功能分配由不同的功能模块完成,即将终端的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的音频处理装置与音频处理方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
[0192]
在示例性实施例中,还提供了一种音频处理系统,该音频处理系统包括第一终端和至少一个第二终端;
[0193]
该第一终端,用于进行音频信号采集,得到第一音频信号;
[0194]
该至少一个第二终端,用于进行音频信号采集,得到至少一个第二音频信号;
[0195]
该第一终端,还用于获取该第一终端所采集的第一音频信号和该至少一个第二终端所采集的至少一个第二音频信号;确定该第一音频信号的气流特征,该气流特征用于指示呼吸的气流速度随时间的变化情况;若该气流特征指示该第一音频信号不是呼吸声,基于该气流特征,从该第一音频信号中,分离出目标用户的音频信号;基于该至少一个第二音频信号,对该目标用户的音频信号进行重采样,得到目标音频信号。
[0196]
在一种可能的实现方式中,该第一终端,还用于基于该第一音频信号的频谱,确定该第一音频信号的气流特征。
[0197]
在一种可能的实现方式中,该第一终端,还用于在该第一音频信号的频谱中,基于该气流特征进行对比;将与该气流特征的相似度大于或等于参考相似度的频谱,确定为该目标用户的音频信号对应的频谱;基于该目标用户的音频信号对应的频谱,确定该目标用户的音频信号。
[0198]
在一种可能的实现方式中,该第一终端,还用于若该气流特征指示该第一音频信号包括鼻子呼吸声,则过滤该第一音频信号。
[0199]
在一种可能的实现方式中,该第一终端,还用于获取至少一个第二音频信号,该至少一个第二音频信号通过该第一终端所关联的至少一个第二终端采集得到。
[0200]
在一种可能的实现方式中,该第一终端,还用于对该至少一个第二音频信号采样,得到多个采样点的第一幅值;对该多个采样点的第一幅值进行增益,得到该多个采样点的第二幅值,将该多个采样点以及对应的第二幅值插入该目标用户的音频信号,得到该目标音频信号。
[0201]
在一种可能的实现方式中,该至少一个第二音频信号为该至少一个第二终端所采集的原始音频信号中符合对应衰减规律的音频信号。
[0202]
在一种可能的实现方式中,该衰减规律与距离相关,该距离为第二终端和该第一
终端之间的距离。
[0203]
在一种可能的实现方式中,该第一终端和该第二终端上均运行有目标应用程序,或,该第一终端上运行有该目标应用程序,该第二终端的电话号码为该第一终端的关联号码。
[0204]
在一种可能的实现方式中,该第一终端,还用于显示目标应用程序的关联设备配置界面,该关联设备配置界面用于提供能够进行音频信号采集的第二终端;基于与该至少一个第二终端之间的连接,传输音频信号。
[0205]
在一种可能的实现方式中,该第一终端,还用于获取该第一终端和该至少一个第二终端之间的至少一个第一距离;若任一个第二终端的该第一距离不属于参考距离区间,发出移动提示,该移动提示用于指示对该任一个第二终端进行移动。
[0206]
在一种可能的实现方式中,若该第二终端为手机,则该连接为蓝牙连接;若该第二终端为ip电话,则该连接为该第一终端和该第二终端之间的有线连接。
[0207]
在一种可能的实现方式中,该第一终端,还用于响应于对该第一终端的采集启动操作,触发该至少一个第二终端进行音频信号采集。
[0208]
在示例性实施例中,还提供了一种计算机可读存储介质,例如包括指令的存储器,上述指令可由处理器执行以完成上述实施例中的音频处理方法。例如,该计算机可读存储介质是只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、只读光盘(compact disc read-only memory,cd-rom)、磁带、软盘和光数据存储设备等,可选地,该计算机可读存储介质为其他类型,本技术实施例对此不加以限定。
[0209]
在示例性实施例中,还提供了一种计算机程序产品,当该计算机程序产品在第一终端上运行时,使得第一终端执行上述图3对应的实施例中的音频处理方法的方法步骤。
[0210]
在示例性实施例中,还提供了一种芯片,该芯片包括处理电路和与该处理电路内部连接通信的输入输出接口,该处理电路和该输入输出接口分别用于实现上述图3对应的实施例中的音频处理方法的方法步骤。
[0211]
在一些可能的实施例中,上述芯片使用下述结构来实现:一个或多个现场可编程门阵列(field-programmable gate array,fpga)、可编程逻辑器件(programmable logic device,pld)、复杂可编程逻辑器件(complex programmable logic device,cpld)、控制器、专用集成电路(application specific integrated circuit,asic)、状态机、门逻辑、分立硬件部件、晶体管逻辑器件、网络处理器(network processor,np)、任何其它适合的电路、或者能够执行本技术通篇所描述的各种功能的电路的任意组合。
[0212]
本领域普通技术人员能够理解实现上述实施例的全部或部分步骤通过硬件来完成,或通过程序来指令相关的硬件完成,上述程序存储于一种计算机可读存储介质中,可选地,上述提到的存储介质是只读存储器,磁盘或光盘等。
[0213]
以上所描述的内容仅为本技术的可选实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。