1.本发明涉及视频图像处理技术以及深度学习技术,具体涉及一种基于连续视频流的使用于深度图补全的深度学习技术。
背景技术:
2.现有用于解决室外场景的深度补全问题的方法可以分为两类,一类是以手工设计的特征进行补全的传统机器学习方法,另一类是基于卷积神经网络编解码器结构的深度学习方法。两类方法虽然可以在一定程度上解决室外场景的深度补全问题,但是由于两类方法存在的固有缺陷,实际补全效果不佳,难以满足实际使用需求。
3.以手工设计特征的深度补全算法,基于传统的机器学习技术,通过手工设计的特征算子对图像以及深度图进行特征提取,最终形成一个室外场景的深度补全算法模型。该类方法的实际预测效果不佳,主要原因如下:首先是手工设计三维描述符对于不同场景会有着不同的效果,具有一定的局限性;其次是基于手工设计特征的模型的泛化能力效果较差。
4.基于深度卷积神经网络的算法在一定程度上解决了上述方法的问题,该算法主流方式均为基于卷积神经网络编解码器结构。然而由于深度图为三维点云二维投影,其中有效的深度值十分稀疏,深度图中无效的深度值,使用传统卷积对深度图进行特征提取会遇到种种困难。针对上述问题,可以使用改进的卷积算子进行特征提取,通过一个额外的通道作为深度图是否具有有效值进行标记,或是将深度值的空间进行编码进深度图,通过引入这些位置信息,模型能够更有效捕捉三维特征信息。另一种方法通过导向滤波的方式进行深度补全,以图像作为单独的分支,通过图像生成导向图,再利用导向图对深度图进行补全。该类方法相对于手工设计特征的方式较好,但实际预测效果仍然不理想。
技术实现要素:
5.本发明的发明所要解决的技术问题是,申请人发现导致利用导向图对深度图进行补全的实际预测效果不理想的原因在于,用于室外场景的深度补全的输入通常是连续的视频流,现有方法中通常将数据流打乱后输入模型进行训练,未能充分挖掘连续视频流的图像与深度图之间的时序关系。因此,本发明针对连续的视频流中关于时序的信息未被利用的缺点,提出一种解决现有基于深度学习的室外场景的深度补全方法中未能利用连续视频流中上下文关系的技术问题,最终实现准确深度补全的方法。
6.本发明为解决上述技术问题所采用的技术方案是,一种基于连续视频流的室外场景深度补全方法,包括以下步骤:
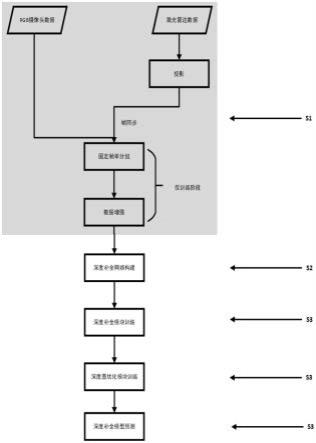
7.步骤1、对传感器输入的数据进行预处理:
8.先根据外参矩阵将点云数据投影至图像上,生成稀疏深度图d,再通过帧同步将稀疏深度图d与rgb摄像头采集的图像数据rgb一起形成rgb-d数据;
9.步骤2、深度补全模块处理步骤:完成训练的深度补全模块的图像分支接收rgb-d
数据中的图像数据rgb,通过图像分支的编解码器提取图像特征,图像分支解码器的输出与深度分支的相同尺寸的编码器的输入对应级联;深度补全模块的深度分支接收rgb-d数据中的稀疏深度图d以及数据流中前一帧的导向图,通过深度分支的编解码器输出初始补全深度图、当前帧的导向图以及亲和度矩阵;通过将rgb-d数据流中前一帧的导向图应用到当前帧的初始补全深度图生成中,使得连续视频流中的上下文信息得到充分利用;
10.步骤3、深度图优化模块处理步骤:完成训练的深度图优化模块接收深度分支的编解码器输出的初始补全深度图以及亲和度矩阵,基于亲和度矩阵对初始补全深度图进行迭代优化,输出优化后的补全深度图用于室外场景深度补全。
11.本发明有益的效果是:有效利用连续视频流中的上下文信息,弥补了现有方法仅利用卷积神经网络进行预测的不足,从而提高了预测的效果;通过深度图优化模块对模型输出进行进一步优化,再次提升了深度补全预测的准确性。
附图说明
12.图1为本发明的深度补全算法原理图;
13.图2为本发明的深度补全模块结构图;
14.图3为本发明的深度图优化模块示意图;
15.图4为本发的集合卷积结构示意图。
具体实施方式
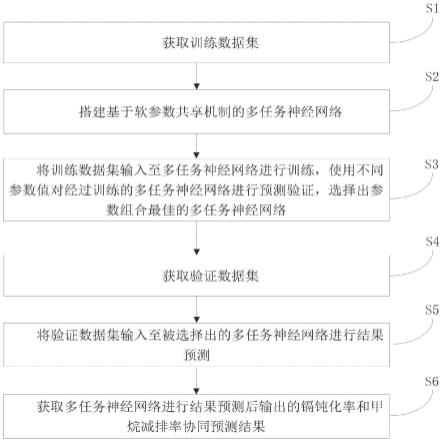
16.本具体实施方式中,基于连续视频流的室外场景深度补全算法包含训练和预测两部分,训练部分主要是获得训练好的(即训练完善的)连续视频流的室外场景深度补全方法模型。预测部分基于训练好的模型执行步骤s1-s4。
17.下面结合实施步骤,对数据预处理、深度补全模块的训练、深度图优化模块的训练部分结合图例进行详述。
18.参见图1,对于一个待补全的室外点云,通过下列步骤训练模型并进行深度补全:
19.步骤s1,数据的预处理主要是获得一个作为深度补全模块输入的数据流,数据预处理分为以下步骤:
20.首先需要对传感器传递的点云以及图像数据帧进行同步,帧同步的方式是通过时间进行匹配,对于绝对时间差小于0.02s的图像以及点云帧视为匹配帧;
21.其次使用标定好的外参矩阵对点云数据进行投影,将点云数据投影至图像平面得到稀疏深度图,获得图像数据与稀疏深度图的数据对rgb-d,其中深度d为负数的点以及坐标不在相机范围内的点将会除去;通过帧同步将稀疏深度图数据与rgb摄像头采集的rgb数据一起形成rgb-d数据作为深度补全模块的输入数据。
22.对于训练阶段,接着需要按照固定的帧数进行分组,对视频流进行切片,本发明采用200帧的分组大小进行;最后使用数据增强对方式增加实验数据,可以采用的方式有,随机的旋转、水平翻转、缩放、明暗度调整等。同时投影矩阵也需要进行相应的变换。
23.具体的,投影使用以下方式进行:
[0024][0025]
其中,(u,v)为点云数据的像素坐标,f为rgb摄像头焦距,α,β分别为焦距在相机坐标系x,y方向上的分量,c
x
,cy为相机主轴的偏移量,r是一个用于对齐相机与激光雷达坐标的旋转矩阵,0
t
表示外参旋转矩阵,xc为点云x轴坐标yc为点云y轴坐标,zc为点云z轴坐标,r为外参矩阵。
[0026]
如果是训练阶段,还需要对深度补全模块的输入数据进行帧分组以及数据增强。数据增强的方式有旋转,缩放,图像的明暗调整等。对同一组的数据需要使用同一变换策略。当图像进行旋转缩放变化时,相对应的投影所使用的外参矩阵也需要进行变化。
[0027]
当前帧的前一帧生成的导向滤波矩阵也要作为深度补全模块输入。
[0028]
步骤s2与s3分别是构建模型与深度补全网络训练,将步骤s1所得的稀疏深度图、图像数据以及导向滤波矩阵作为输入,训练深度补全模型。
[0029]
然后通过已训练好的深度补全模型,预测补全后的深度图,基于生成初始的补全深度图,亲和度矩阵,以及下一帧的导向图。
[0030]
训练主要包含两部分,深度补全模块的训练,深度图优化模块的训练。
[0031]
本领域内的技术人员可以理解,深度补全模块的训练主要是获得一个可以输出稠密深度图的骨干网络,如图2所示。深度补全模块模型整体结构为一个两分支的编解码器结构,该模块使用数据预处理中输出的rgb图像、稀疏深度图depth以及上一帧生成的导向矩阵guide作为输入,进行缺失深度值预测。
[0032]
深度补全模块模型整体结构上半部分是图像分支,用于提取图像特征,并与下半部分的深度分支进行级联。在编码器部分每一层网络中的特征通道数都会是上一层的两倍同时缩小特征图,如图2的编码器部分结构的特征通道数依次为32、64、128、256、512,特征图尺寸依次为352*1216、176*608、88*304、44*152、22*76,解码器部分则是相反地逐渐减少通道数,对特征图进行上采样。深度补全模块模型整体结构的下半部分是深度分支,用于输出稠密的深度图。其编码部分会级联图像分支的解码部分实现数据的融合,如图2中图像分支的解码部分的64@176*608模块的输出分支(1)、128@88*304模块的输出分支(2)、256@44*152模块的输出分支(3)分支分别与深度分支的编码部分的64@176*608模块的输入分支(1)、128@88*304模块的输入分支(2)、256@44*152模块的输入分支(3)级联;深度分支的解码部分与图像分支类似,通过不断的减少通道数以及上采样恢复深度值。
[0033]
深度补全模块最终的输出有三部分,首先是用于下一帧的导向矩阵,其次是输出的初始补全深度图,最后是用于深度图优化模块的亲和度矩阵。
[0034]
深度补全模块训练时,使用32作为批次大小,采用基于绝对误差的损失函数和批梯度下降优化器。使用预测值与真实标签中的有效深度之间的绝对距离作为损失函数进行训练:
[0035][0036]
其中代表真实深度值,代表预测深度值,代表真实深度值中有效部分。
为预测深度与真实深度的差值。
[0037]
深度分支中卷积使用的是附带几何信息feature的卷积,通过将点云的空间坐标(x,y,z)编码进深度,如图4所示,以达到效果提升的作用。
[0038]
导向滤波操作的三维扩展为:
[0039][0040]
其中i代表输入特征,c为输入特征的通道数,i
′
代表输出特征,c
′
为输出特征的通道数,p代表特征的像素位置,i
′
p,c
′
表示输出特征,m为点总数量,k代表像素p的邻域,i
p k,c
表示输入特征在第c个通道上像素p k处的特征值,代表深度分支生成的导向图,d为深度,为参数。但是该方法计算负载过大。本发明将导向滤波分为两部分,如下所示
[0041][0042][0043]
第一步为对每一个通道的导向滤波得到i
′
p,c
,为第一步的导向图,为导向图中的参数;第二步为利用i
′
p,c
进行普通的卷积得到i
″
p,c
′
,为第二步的导向图,为导向图中的参数。输出i
″
作为下一级的点云特征进行计算。
[0044]
最后,每个分组的第一帧没有前一帧的导向信息,实施例采用深度图本身作为第一帧的导向矩阵。
[0045]
步骤s4将上一步所得的初始补全深度图,亲和度矩阵作为输入数据,通过训练好的深度图优化模块进行迭代,输出最终的补全深度图。
[0046]
本领域内的技术人员可以理解,深度图优化模块的训练主要是获得一个通过亲和度矩阵对初始预测的深度图进行迭代优化的模块,如图3所示。
[0047]
亲和度矩阵说明:以一张h
×
w的深度图,k
×
k的局部邻域为例。初始预测的单通道深度图为d0,通过亲和度网络输出该深度图的亲和度矩阵为a,通道数为k
×
k,尺寸与深度图一致,其中代表像素点(m,n)的邻域每个通道代表该位置像素点的一个邻域的亲和度。深度图优化模块基于如下方式对深度图d0进行循环优化:
[0048][0049]
其中,分别表示第t次、第t-1次跌代得到的像素点(m,n)在深度图中的值,表示第t-1次次迭代得到的像素点(m,n)的邻域中的像素点(m i,n j)在深度图中的值,为当前坐标亲和度,为邻近亲和度,实施例设置深度图优化的迭代次数t为固定为6次。
[0050]
深度图优化模块较为简单,主要是通过亲和度矩阵不断的对深度图进行迭代优
化。本发明采用局部邻域的亲和度矩阵进行深度图优化,其为一个8通道矩阵,用于表示对应元素周围3
×
3区间的亲和度。
[0051]
深度图优化模块的损失函数在深度补全模块基础上加入了平滑损失模块:l=l1 l2,包含预测值与真实标签中的有效深度之间的绝对距离以及一个平滑损失,其中l1与深度补全模块一致:
[0052][0053]
l2为平滑算子:
[0054][0055]
其中代表深度补全模型输出的深度图,代表求梯度,i表示rgb图像,||||1表示1-范数,ns表示深度图中有效点的个数。
[0056]
训练时,采用32作为批次大小,每一次训练,计算模型的损失函数值,基于损失函数值,使用adam优化算法调整模型参数,当本次损失函数值高于前次损失函数值时,模型训练终止。
[0057]
获得训练完善的模型后,使用步骤s5进行预测,输入对应的图像以及稀疏深度的数据流,即可以得到稠密的深度图数据流作为输出。
[0058]
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。