1.本发明属于化学反应信息提取的技术领域,具体涉及一种化学反应信息提取方法、系统、存储介质以及设备。
背景技术:
2.在过去十年,化学领域的信息提取得到了越来越多的关注,现有工作主要集中在命名实体识别及其相关属性的提取,只有少部分针对文本中化学反应信息提取。
3.传统的化学反应信息提取主要是基于语法的短语解析器来识别动作短语和实体之间的关系,专门用来从专利中提取信息。除此之外,还存在使用一组自定义规则提取基本的化学角色,但是严重依赖于手动设计的规则,并对语言使用或预处理步骤带来的干扰非常敏感,使得对期刊文章等非专利数据的可伸缩性受到了限制。
4.由于在化学文本描述信息中一个句子可以描述多个反应,或者一个反应在不同的条件下有不同的产物/产率,这种更为复杂的文本信息需要具有更高能力、更高级的自然语言模型进行处理。
技术实现要素:
5.基于此,本发明实施例当中提供了一种化学反应信息提取方法、系统、存储介质以及设备,旨在解决现有技术中,化学反应信息提取准确度差的问题。
6.本发明实施例的第一方面提供了一种化学反应信息提取方法,所述方法包括:
7.获取目标文件中的文本和所述文本对应的图片,并将所述文本按预设标识分割为多个待识别语句;
8.获取所述待识别语句,并将所述待识别语句输入标注模型,输出所述待识别语句中各单词的标签,所述标签至少包括化合物标签和化学反应标签;
9.判断所述图片是否为预设图片;
10.若是,则根据目标识别图形,将所述图片分割为多个子图片,并对所述子图片进行识别,得到目标化学结构式数据;
11.根据所述目标化学结构式数据,获取对应的化学结构式,并判断所述化学结构式是否与所述化合物标签匹配;
12.若是,则将所述化学结构式和所述化合物标签结合,并匹配对应的所述化学反应标签,确定所述待识别语句的化学反应信息。
13.进一步的,所述获取所述待识别语句,并将所述待识别语句输入标注模型,输出所述待识别语句中各单词的标签,所述标签至少包括化合物标签和化学反应标签的步骤之前包括:
14.获取历史待识别语句,将所述历史待识别语句进行数据预处理,得到所述历史待识别语句中各历史单词的历史标签;
15.将所述历史单词进行向量转换,得到对应的向量值;
16.将所述向量值进行上下文关系训练,并输出所述向量值对应的所述历史标签的第一分数值,根据所述第一分数值,确定所述历史单词对应的所述历史标签,以完成所述标注模型的训练。
17.进一步的,所述将所述向量值进行上下文关系训练,并输出所述向量值对应的所述历史标签的第一分数值,根据所述第一分数值,确定所述历史单词对应的所述历史标签,以完成所述标注模型的训练的步骤之后包括:
18.将各所述第一分数值进行优化处理,得到第二分数值,根据所述第二分数值确定最优标签序列,以优化所述标注模型。
19.进一步的,所述获取历史待识别语句,将所述历史待识别语句进行数据预处理,得到所述历史待识别语句中各历史单词的历史标签的步骤包括:
20.根据预设标注规格,将所述历史待识别语句中各历史单词的所述历史标签进行手动标注。
21.进一步的,所述将所述历史单词进行向量转换,得到对应的向量值的步骤中,设所述历史待识别语句x中由n个所述单词组成,则可表示为x={x1,x2,x3,...xn},所述向量转换公式为x
t
=w
embrt
,其中,w
emb
∈rd×
|v|
,w
em
b为向量查询表,需要训练得到,rd×
|v|
为d
×
|v|维的向量空间,r为向量空间,d为所述单词的向量维度,v为字典,|v|为独热编码表示下字典的大小,r
t
∈r
|v|
,r
t
为第t个单词的独热编码,r
|v|
为|v|维的向量空间,x
t
∈rd,xt为第t个单词的向量值,rd为d维的向量空间。
22.进一步的,所述将所述向量值进行上下文关系训练,并输出所述向量值对应的所述历史标签的第一分数值,根据所述第一分数值,确定所述历史单词对应的所述历史标签,以完成所述标注模型的训练的步骤中,计算所述第一分数值的公式为:
23.f
t
=σ(wfh
t-1
ufx
t
bf);
24.i
t
=σ(w
iht-1
uix
t
bi);
[0025][0026][0027]ot
=σ(w
oht-1
uox
t
bo);
[0028]ht
=o
t
⊙
tanh(c
t
);
[0029][0030]
其中,σ为sigmoid函数,g为softmax函数,
⊙
为点对乘积,i,f和o分别为输入门,忘记门和输出门,ft表示第t个单词的遗忘门,it表示第t个单词记忆门,c表示所述上下文关系训练中每个记忆单元的状态,ct表示第t个单词的记忆单元状态,表示第t个单词的临时细胞状态,ot表示第t个单词的输出门,ht表示第t个单词的隐层状态,b为偏置项,w和u为权重矩阵,wf、uf表示遗忘门的权重矩阵,bf表示遗忘门的偏置项,h
t-1
表示第t-1个单词的隐层状态,xt表示第t个单词的向量值,wi、ui表示输入门的权重矩阵,bi表示输入门的偏置项,wc、uc表示细胞状态的权重矩阵,bc表示细胞状态的偏置项,wo、uo表示输出门的权重矩阵,bo表示输出门的偏置项,c
t-1
表示上一时刻的细胞状态,by为标签序列y的偏置项,代表前馈层和反馈层在第t个单词的输出向量连接,p(y
t
|x
t
)为所述第一分数值,表示为第t个单词的向量值转化为对应的第t个单词的标签的概率。
[0031]
进一步的,所述将各所述第一分数值进行优化处理,得到第二分数值,根据所述第二分数值确定最优标签序列,以优化所述标注模型的步骤中,所述优化处理的计算公式为:
[0032][0033][0034]
其中,y为标签序列,且y∈{y1,y2,...,yn},y为{y1,y2,...,yn},y代表所有可能的标签序列,n表示单词的总个数,yn表示第n个单词的标签,s(x,y)为标签序列y的得分,为标签y
i-1
转移到标签yi的概率值,表示第i个单词被标记为标签yi的概率,p(y|x)为所述历史待识别语句x标注为标签序列y的概率,logp(y|x)为所述第二分数值。
[0035]
本发明实施例的第二方面提供了一种化学反应信息提取系统,所述系统包括:
[0036]
文本分割模块,用于获取目标文件中的文本和所述文本对应的图片,并将所述文本按预设标识分割为多个待识别语句;
[0037]
标签输出模块,用于获取所述待识别语句,并将所述待识别语句输入标注模型,输出所述待识别语句中各单词的标签,所述标签至少包括化合物标签和化学反应标签;
[0038]
第一判断模块,用于判断所述图片是否为预设图片;
[0039]
目标化学结构式数据获取模块,用于当判断所述图片为预设图片时,则根据目标识别图形,将所述图片分割为多个子图片,并对所述子图片进行识别,得到目标化学结构式数据;
[0040]
第二判断模块,用于根据所述目标化学结构式数据,获取对应的化学结构式,并判断所述化学结构式是否与所述化合物标签匹配;
[0041]
化学反应信息确定模块,用于当判断所述化学结构式与所述化合物标签匹配时,则将所述化学结构式和所述化合物标签结合,并匹配对应的所述化学反应标签,确定所述待识别语句的化学反应信息。
[0042]
本发明实施例的第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方案提供的化学反应信息提取方法。
[0043]
本发明实施例的第四方面提供了一种化学反应信息提取设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方案提供的化学反应信息提取方法。
[0044]
本发明的有益效果为:通过获取目标文件中的文本和文本对应的图片,并将文本按预设标识分割为多个待识别语句;获取待识别语句,并将待识别语句输入标注模型,输出待识别语句中各单词的化合物标签和化学反应标签;判断图片是否为预设图片;若是,则根据目标识别图形,将图片分割为多个子图片,并对子图片进行识别,得到目标化学结构式数据;根据目标化学结构式数据,获取对应的化学结构式,并判断化学结构式是否与化合物标签匹配;若是,则将化学结构式和化合物标签结合,并匹配对应的化学反应标签,确定待识别语句的化学反应信息,其中,本发明主要基于文本和图片,除对文本进行信息提取外,还对相关图片中的化学反应式进行识别,增加信息提取的准确性。
附图说明
[0045]
图1是本发明第一实施例提供的一种化学反应信息提取方法的实现流程图;
[0046]
图2是本发明第三实施例提供的一种化学反应信息提取系统的结构框图;
[0047]
图3是本发明第四实施例提供的一种化学反应信息提取设备的结构框图。
[0048]
以下具体实施方式将结合上述附图进一步说明本发明。
具体实施方式
[0049]
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的若干实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。
[0050]
需要说明的是,当元件被称为“固设于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
[0051]
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
[0052]
实施例一
[0053]
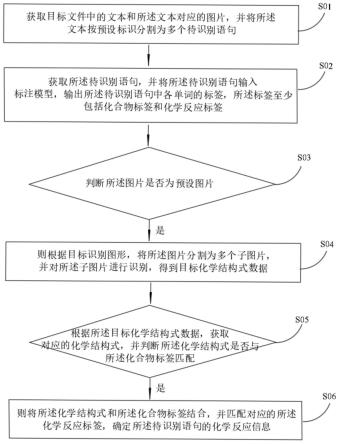
请参阅图1,图1示出了本发明第一实施例提供的一种化学反应信息提取方法的实现流程图,所述方法具体包括步骤s01至步骤s06。
[0054]
步骤s01,获取目标文件中的文本和所述文本对应的图片,并将所述文本按预设标识分割为多个待识别语句。
[0055]
在本实施例当中,目标文件中的内容为英文书写,首先对非结构化文本进行第一预处理,具体的,使用pdfminner库从pdf格式的化学文献中提取文字部分,其中,提取的文本内容较为杂乱,含有参考文献、作者等信息,因此,使用正则表达式对文本进行第二预处理,匹配后筛选出无关的文字信息并将其删除,可以理解的,第二预处理后的文本内容仅含有文献正文内容,另外,还需提取文本对应的图片,即将文本中的段落或语句与图片进行关联。
[0056]
需要说明的是,预设标识为句号,具体的,句号可以为全角句号和半角句号,通过识别句号,将文本中的文献正文内容分割为多个待识别语句,目的在于将若干待识别语句分别进行处理。
[0057]
步骤s02,获取所述待识别语句,并将所述待识别语句输入标注模型,输出所述待识别语句中各单词的标签,所述标签至少包括化合物标签和化学反应标签。
[0058]
具体的,将各待识别语句依次输入标注模型中,以获取该待识别语句中各单词的标签,其中,标签至少包括化合物标签和化学反应标签,通过标签,可以将该待识别语句进行提炼,以知悉该待识别语句中的化学反应信息,需要说明的是,标注模型的建立步骤为,获取历史待识别语句,将历史待识别语句进行数据预处理,得到历史待识别语句中各历史单词的历史标签;将历史单词进行向量转换,得到对应的向量值;将向量值进行上下文关系
训练,并输出向量值对应的历史标签的第一分数值,根据第一分数值,确定历史单词对应的历史标签。
[0059]
其中,使用yedda工具手动对化学句子进行标签标注,即告知所要建立的标注模型需要关注的特征点,并根据特征点进行训练,具体的,使用bio标注法,共标记9种标签,分别是反应物、生成物、催化剂、萃取剂、温度、时间、产率、溶剂、反应类型,对应的,按照b-reactants,i-reactants,b-products,i-products,b-catalysts,i-catalysts,b-extractants,i-extractants,b-temperature,i-temperature,b-time,i-time,b-yield,i-yield,b-prod,i-prod,b-solvent,b-reaction,o共19种标注标签逐行对单词进行标注,例如,历史待识别语句为“we initiated a catalyst screening for the carbonylation of 6-bromo-1,4-benzodioxane with sodium tert-butoxide using a slight excess(1.5 equiv)of carbon monoxide(co).”,需要说明的是,“b-x”表示此单词所在的语句属于x类型并且此单词在此语句的开头,“i-x”表示此单词所在的语句属于x类型并且此单词在此语句的中间位置,“o”表示不属于任何类型,那么,可以将该历史待识别语句进行手动标注,标注结果为,[@we#o*]、[@initiated#o*]、[@a#o*]、[@catalyst#o*]、[@screening#o*]、[@for#o*]、[@the#o*]、[@carbonylation#b-reaction*]、[@of#o*]、[@6-bromo-1,4-benzodioxane#b-reactants*]、[@with#o*]、[@sodium#b-reactants*]、[@tert-butoxide#i-reactants*]、[@using#o*]、[@a#o*]、[@slight#o*]、[@excess#o*]、[@(#o*]、[1.5@#o*]、[@equiv#o*]、[@)#o*]、[@of#o*]、[@carbon#b-reactants*]、[@monoxide#i-reactants*]、[@(#o*]、[co@#b-reactants*]、[@)#o*],可以理解的,该历史待识别语句中共标注27个标签,其中,除去不属于任何类型“o”标签的以外,具有化学反应信息的标签有[@carbonylation#b-reaction*]、[@6-bromo-1,4-benzodioxane#b-reactants*]、[@sodium#b-reactants*]、[@tert-butoxide#i-reactants*]、[@carbon#b-reactants*]、[@monoxide#i-reactants*]以及[co@#b-reactants*],carbon monoxide为一氧化碳的英文名称,在此被标注为[@carbon#b-reactants*]和[@monoxide#i-reactants*],b-x与i-x用于将carbon与monoxide两个单词组合。
[0060]
进一步的,将标注后的单词进行向量转换,得到对应的向量值,具体的,设历史待识别语句x中由n个单词组成,则可表示为x={x1,x2,x3,...xn},向量转换公式为x
t
=w
embrt
,向量转换公式表示的是权重矩阵w和输入单词向量的独热编码向量乘积,其中,w
emb
∈rd×
|v|
,w
emb
为向量查询表,需要训练得到,rd×
|v|
为d
×
|v|维的向量空间,r为向量空间,d为单词的向量维度,v为字典,|v|为独热编码表示下字典的大小,r
t
∈r
|v|
,r
t
为第t个单词的独热编码,r
|v|
为|v|维的向量空间,x
t
∈rd,xt为第t个单词的向量值,rd为d维的向量空间,需要说明的是,字典是计算机中的一种存储格式,{
″
key
″
:value},比如:{
″
template
″
:1},将
″
template
″
用1代替。
[0061]
更进一步的,在获取到各单词的向量值后,将各向量值进行上下文关系训练,以学习文本的上下文关系,并输出各单词的标签的分数,即第一分数值,也为概率值,并根据第一分数值,确定单词对应的标签,由于之前以对历史待识别语句中的每个单词进行了手动标注,可以理解的,在已知正确的单词的标签的情况下,完成标注模型的训练,具体的,第一分数值的计算公式为:
[0062]ft
=σ(wfh
t-1
ufx
t
bf);
[0063]it
=σ(w
iht-1
uix
t
bi);
[0064][0065][0066]ot
=σ(w
oht-1
uox
t
bo);
[0067]ht
=o
t
⊙
tanh(c
t
);
[0068][0069]
其中,σ为sigmoid函数,g为softmax函数,
⊙
为点对乘积,i,f和o分别为输入门,忘记门和输出门,ft表示第t个单词的遗忘门,it表示第t个单词记忆门,c表示上下文关系训练中每个记忆单元的状态,ct表示第t个单词的记忆单元状态,表示第t个单词的临时细胞状态,ot表示第t个单词的输出门,ht表示第t个单词的隐层状态,b为偏置项,w和u为权重矩阵,wf、uf表示遗忘门的权重矩阵,bf表示遗忘门的偏置项,h
t-1
表示第t-1个单词的隐层状态,xt表示第t个单词的向量值,wi、ui表示输入门的权重矩阵,bi表示输入门的偏置项,wc、uc表示细胞状态的权重矩阵,bc表示细胞状态的偏置项,wo、uo表示输出门的权重矩阵,bo表示输出门的偏置项,c
t-1
表示上一时刻的细胞状态,by为标签序列y的偏置项,代表前馈层和反馈层在第t个单词的输出向量连接,p(y
t
|x
t
)为第一分数值,表示为第t个单词的向量值转化为对应的第t个单词的标签的概率。
[0070]
步骤s03,判断所述图片是否为预设图片,若是,则执行步骤s04。
[0071]
需要说明的是,与文本中的语句或段落对应的图片会存在多张,具体的,预设图片为含有化学反应式的图片,即当识别出图片为含有化学反应式的图片时,则说明该图片中包含化学反应信息。
[0072]
步骤s04,则根据目标识别图形,将所述图片分割为多个子图片,并对所述子图片进行识别,得到目标化学结构式数据。
[0073]
其中,目标识别图形为化学结构式图形,一般的,当识别出图片为含有化学反应式的图片时,一个化学反应式中含有多个化学结构式,在本实施例当中,使用yolox目标检测模型对化学反应式图片进行检测,并根据检测到的部分进行切割,得到多个子图片,再将子图片逐个使用以cnn为主的神经网络模型对子图片进行识别,得到目标化学结构式数据,其中,该神经网络模型专注于解决化学结构式的识别并转化为对应的smiles等规范分子结构式,具体的,为提高识别化学结构式的准确率,需要对子图片进行预处理,主要包括灰度化、二值化、去噪以及图像倾斜矫正等操作。
[0074]
步骤s05,根据所述目标化学结构式数据,获取对应的化学结构式,并判断所述化学结构式是否与所述化合物标签匹配,若是,则执行步骤s06。
[0075]
在本实施例当中,利用化学文献自带的supportion information文本,其中,supportion information文本中包含化学名称、smiles、产物、温度、实验条件、实验步骤等信息,将supportion information文本中的内容存入数据库中,通过将目标化学结构式数据在数据库中利用模糊匹配查找其对应的化学结构式及名称,并判断该化学结构式是否与所述化合物标签匹配。
[0076]
步骤s06,则将所述化学结构式和所述化合物标签结合,并匹配对应的所述化学反应标签,确定所述待识别语句的化学反应信息。
[0077]
具体的,当判断该化学结构式与所述化合物标签匹配时,则从数据中查询出的化学结构式名称与文本处理步骤中预测出的标签进行结合,构建基于多模态化学文献信息提取,同时,还可以根据化学结构式名称找到与之对应的其他化学信息,如催化剂、温度、生成物等,得到待识别语句的化学反应信息。
[0078]
综上,本发明提出的一种化学反应信息提取方法,通过获取目标文件中的文本和文本对应的图片,并将文本按预设标识分割为多个待识别语句;获取待识别语句,并将待识别语句输入标注模型,输出待识别语句中各单词的化合物标签和化学反应标签;判断图片是否为预设图片;若是,则根据目标识别图形,将图片分割为多个子图片,并对子图片进行识别,得到目标化学结构式数据;根据目标化学结构式数据,获取对应的化学结构式,并判断化学结构式是否与化合物标签匹配;若是,则将化学结构式和化合物标签结合,并匹配对应的化学反应标签,确定待识别语句的化学反应信息,其中,本发明主要基于文本和图片,除对文本进行信息提取外,还对相关图片中的化学反应式进行识别,增加信息提取的准确性。
[0079]
实施例二
[0080]
本发明第二实施例提供了一种化学反应信息提取方法,与第一实施例的区别在于对标注模型进行了优化,所述方法具体包括步骤s20至步骤s25。
[0081]
步骤s20,获取目标文件中的文本和所述文本对应的图片,并将所述文本按预设标识分割为多个待识别语句。
[0082]
步骤s21,获取所述待识别语句,并将所述待识别语句输入标注模型,输出所述待识别语句中各单词的标签,所述标签至少包括化合物标签和化学反应标签。
[0083]
在本实施例当中,将各第一分数值进行优化处理,得到第二分数值,根据所述第二分数值确定最优标签序列,目的在于对第一分数值确定的标签添加一些约束来保证预测的标签的正确性,最终选择预测得分最高的标签序列作为最佳答案,具体的,优化处理的计算公式为:
[0084][0085][0086]
其中,y为标签序列,且y∈{y1,y2,...,yn},y为{y1,y2,...,yn},y代表所有可能的标签序列,n表示单词的总个数,yn表示第n个单词的标签,s(x,y)为标签序列y的得分,为标签y
i-1
转移到标签yi的概率值,表示第i个单词被标记为标签yi的概率,y代表所有可能的标签序列,p(y|x)为历史待识别语句x标注为标签序列y的概率,为使标注为标签序列y的概率最大,具体的,采用对数最大似然估计得到代价函数,最后使用维特比算法,即可求得得分最高的标签序列,为一概率值,即第二分数值log p(y|x)。
[0087]
步骤s22,判断所述图片是否为预设图片,若是,则执行步骤s23。
[0088]
步骤s23,则根据目标识别图形,将所述图片分割为多个子图片,并对所述子图片进行识别,得到目标化学结构式数据。
[0089]
步骤s24,根据所述目标化学结构式数据,获取对应的化学结构式,并判断所述化学结构式是否与所述化合物标签匹配,若是,则执行步骤s25。
[0090]
步骤s25,则将所述化学结构式和所述化合物标签结合,并匹配对应的所述化学反应标签,确定所述待识别语句的化学反应信息。
[0091]
实施例三
[0092]
请参阅图2,图2是本发明实施例提供的一种化学反应信息提取系统的结构框图。化学反应信息提取系统300包括:文本分割模块31、标签输出模块32、第一判断模块33、目标化学结构式数据获取模块34、第二判断模块35以及化学反应信息确定模块36,其中:
[0093]
文本分割模块31,用于获取目标文件中的文本和所述文本对应的图片,并将所述文本按预设标识分割为多个待识别语句;
[0094]
标签输出模块32,用于获取所述待识别语句,并将所述待识别语句输入标注模型,输出所述待识别语句中各单词的标签,所述标签至少包括化合物标签和化学反应标签;
[0095]
第一判断模块33,用于判断所述图片是否为预设图片;
[0096]
目标化学结构式数据获取模块34,用于当判断所述图片为预设图片时,则根据目标识别图形,将所述图片分割为多个子图片,并对所述子图片进行识别,得到目标化学结构式数据;
[0097]
第二判断模块35,用于根据所述目标化学结构式数据,获取对应的化学结构式,并判断所述化学结构式是否与所述化合物标签匹配;
[0098]
化学反应信息确定模块36,用于当判断所述化学结构式与所述化合物标签匹配时,则将所述化学结构式和所述化合物标签结合,并匹配对应的所述化学反应标签,确定所述待识别语句的化学反应信息。
[0099]
进一步的,在本发明一些可选实施例当中,所述化学反应信息提取系统300还包括:
[0100]
数据预处理模块,用于获取历史待识别语句,将所述历史待识别语句进行数据预处理,得到所述历史待识别语句中各历史单词的历史标签;
[0101]
向量转换模块,用于将所述历史单词进行向量转换,得到对应的向量值,其中,设所述历史待识别语句x中由n个所述单词组成,则可表示为x={x1,x2,x3,...xn},所述向量转换公式为x
t
=w
embrt
,其中,w
emb
∈rd×
|v|
,w
emb
为向量查询表,需要训练得到,rd×
|v|
为d
×
|v|维的向量空间,r为向量空间,d为所述单词的向量维度,v为字典,|v|为独热编码表示下字典的大小,r
t
∈r
|v|
,r
t
为第t个单词的独热编码,r
|v|
为|v|维的向量空间,x
t
∈rd,xt为第t个单词的向量值,rd为d维的向量空间;
[0102]
上下文关系训练模块,用于将所述向量值进行上下文关系训练,并输出所述向量值对应的所述历史标签的第一分数值,根据所述第一分数值,确定所述历史单词对应的所述历史标签,以完成所述标注模型的训练,其中,计算所述第一分数值的公式为:
[0103]ft
=σ(wfh
t-1
ufx
t
bf);
[0104]it
=σ(w
iht-1
uix
t
bi);
[0105][0106][0107]ot
=σ(w
oht-1
uox
t
bo);
[0108]ht
=o
t
⊙
tanh(c
t
);
[0109][0110]
其中,σ为sigmoid函数,g为softmax函数,
⊙
为点对乘积,i,f和o分别为输入门,忘记门和输出门,ft表示第t个单词的遗忘门,it表示第t个单词记忆门,c表示所述上下文关系训练中每个记忆单元的状态,ct表示第t个单词的记忆单元状态,表示第t个单词的临时细胞状态,ot表示第t个单词的输出门,ht表示第t个单词的隐层状态,b为偏置项,w和u为权重矩阵,wf、uf表示遗忘门的权重矩阵,bf表示遗忘门的偏置项,h
t-1
表示第t-1个单词的隐层状态,xt表示第t个单词的向量值,wi、ui表示输入门的权重矩阵,bi表示输入门的偏置项,wc、uc表示细胞状态的权重矩阵,bc表示细胞状态的偏置项,wo、uo表示输出门的权重矩阵,bo表示输出门的偏置项,c
t-1
表示上一时刻的细胞状态,by为标签序列y的偏置项,代表前馈层和反馈层在第t个单词的输出向量连接,p(y
t
|x
t
)为所述第一分数值,表示为第t个单词的向量值转化为对应的第t个单词的标签的概率。
[0111]
进一步的,在本发明一些可选实施例当中,所述化学反应信息提取系统300还包括:
[0112]
优化处理模块,用于将各所述第一分数值进行优化处理,得到第二分数值,根据所述第二分数值确定最优标签序列,以优化所述标注模型,其中,所述优化处理的计算公式为:
[0113][0114][0115]
其中,y为标签序列,且y∈{y1,y2,...,yn},y为{y1,y2,...,yn},y代表所有可能的标签序列,n表示单词的总个数,yn表示第n个单词的标签,s(x,y)为标签序列y的得分,为标签y
i-1
转移到标签yi的概率值,表示第i个单词被标记为标签yi的概率,y代表所有可能的标签序列,p(y|x)为所述历史待识别语句x标注为标签序列y的概率,log p(y|x)为所述第二分数值。
[0116]
进一步的,在本发明一些可选实施例当中,所述数据预处理模块包括:
[0117]
标注单元,用于根据预设标注规格,将所述历史待识别语句中各历史单词的所述历史标签进行手动标注。
[0118]
实施例四
[0119]
本发明另一方面还提出一种化学反应信息提取设备,请参阅图3,所示为本发明第四实施例当中的化学反应信息提取设备的结构框图,包括存储器20、处理器10以及存储在存储器上并可在处理器上运行的计算机程序30,所述处理器10执行所述计算机程序30时实现如上述的化学反应信息提取方法。
[0120]
其中,处理器10在一些实施例中可以是中央处理器(central processing unit,cpu)、控制器、微控制器、微处理器或其他数据处理芯片,用于运行存储器20中存储的程序
代码或处理数据,例如执行访问限制程序等。
[0121]
其中,存储器20至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、磁性存储器、磁盘、光盘等。存储器20在一些实施例中可以是化学反应信息提取设备的内部存储单元,例如该化学反应信息提取设备的硬盘。存储器20在另一些实施例中也可以是化学反应信息提取设备的外部存储装置,例如化学反应信息提取设备上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。进一步地,存储器20还可以既包括化学反应信息提取设备的内部存储单元也包括外部存储装置。存储器20不仅可以用于存储化学反应信息提取设备的应用软件及各类数据,还可以用于暂时地存储已经输出或者将要输出的数据。
[0122]
需要指出的是,图3示出的结构并不构成对化学反应信息提取设备的限定,在其它实施例当中,该化学反应信息提取设备可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。
[0123]
本发明实施例还提出一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述的化学反应信息提取方法。
[0124]
本领域技术人员可以理解,在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,“计算机可读介质”可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。
[0125]
计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(ram),只读存储器(rom),可擦除可编辑只读存储器(eprom或闪速存储器),光纤装置,以及便携式光盘只读存储器(cdrom)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。
[0126]
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或它们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
[0127]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0128]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。