1.本发明涉及图像处理领域,具体涉及一种基于人工智能的大数据图文识别系统。
背景技术:
2.随着物联网、大数据、移动云计算等技术的迅猛发展,使人类社会中的数据种类和规模得到了前所未有的增长,标志着大数据时代已经正式到来。大数据背后蕴含巨大的商业价值,如何有效地组织和利用大数据,已引起产业界和学术界的高度重视。
3.数据挖掘技术是实现数据资源利用和价值增值的方法与手段,通过对数据资源进行分析、处理、利用,可以挖掘数据资源背后的隐藏的高额价值。但纷杂的大数据中往往会存在较多的不良图文信息,需要人为花费较多的时间去筛选,一定程度上降低了大数据的“质量”。
技术实现要素:
4.为解决上述问题,本发明提供了一种基于人工智能的大数据图文识别系统,可以实现图文数据的定向挖掘,且可以实现广告等无效图文数据以及不良图文数据的自动剔除。
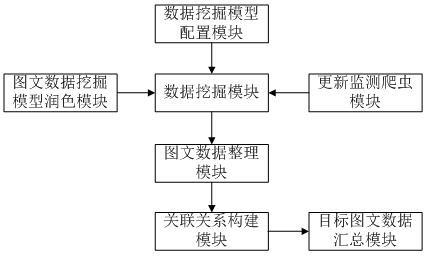
5.为实现上述目的,本发明采取的技术方案为:一种基于人工智能的大数据图文识别系统,包括:数据挖掘模型配置模块,用于为不同的公开网站配置不同的图文数据挖掘模型;数据挖掘模块,用于基于所述图文数据挖掘模型实现各公开网站所发布的图文数据的采集;图文数据整理模块,用于实现各图文数据的整理,剔除不良图文数据和存在重叠特征的图文数据;更新监测爬虫模块,不同的公开网站配置有不同的数据更新监测爬虫,用于实现网站更新的监测,每监测到一次数据更新,图文数据挖掘模型启动一次;关联关系构建模块,用于构建各图文数据之间的关联关系,并基于所述关联关系搭建对应的搜索引擎。
6.进一步地,每完成一次图文数据挖掘,图文数据挖掘模型内载的时间规则更新一次,初始图文数据挖掘模型内载的时间规则为无/企业所需的图文数据区间。
7.进一步地,图文数据整理模块在发现存在重叠特征的图文数据时,选择保留包含数据特征相对较多的图文数据,并剔除与之存在重叠特征的其他的图文数据。
8.进一步地,通过随机挖掘不同的公开网站公布的100条数据的方式分析获取不同的公开网站的图文数据发布特征,从而构建可以实现感兴趣的图文数据定向采集,并自动剔除广告等无效图文数据的图文数据挖掘模型。
9.进一步地,图文数据整理模块基于不良文本数据识别模型和不良图像识别模型实现不良图文数据的识别,其中,不良文本数据识别模型基于词典内载的污秽词语等训练构
建,不良图像识别模型采用dssd inception v3模型。
10.进一步地,每一个图像数据挖掘模型对应一图文数据模板,所挖掘到的图像数据均自动填入对应的图文数据模板。
11.进一步地,还包括:图文数据挖掘模型润色模块,用于根据不同的数据挖掘需求,为对应的图文数据挖掘模型串联上对应的数据筛选次模型。
12.进一步地,还包括:目标图文数据汇总模块,用于根据用户录入的数据需求基于hadoop运行对应的图文数据挖掘处理算法组实现目标图文数据的同步挖掘汇总。
13.本发明具有以下有益效果:可以实现图文数据的定向挖掘,且可以实现广告等无效图文数据以及不良图文数据的自动剔除;可以快速的获取到更新的图文数据,并可以有效的避免数据的重复;可以快速满足各种图文数据挖掘发布需求,同时可以满足各种目标图文数据汇总需求。
附图说明
14.图1为本发明实施例一种基于人工智能的大数据图文识别系统的系统框图。
15.图2为本发明实施例一种基于人工智能的大数据图文识别系统的工作流程图。
具体实施方式
16.为了使本发明的目的及优点更加清楚明白,以下结合实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
17.如图1所示,一种基于人工智能的大数据图文识别系统,包括:数据挖掘模型配置模块,用于为不同的公开网站配置不同的图文数据挖掘模型;不同的公开网站的数据发布模式是不同的,为了适应不同的公开网站,从而缩短数据模型在数据挖掘过程中所花费的时间,在进行图文数据挖掘模型配置前,需先通过随机挖掘不同的公开网站公布的100条数据的方式分析获取不同的公开网站的图文数据发布特征,从而构建可以实现感兴趣的图文数据定向采集,并自动剔除广告等无效图文数据(通过随机挖掘不同的公开网站公布的20条广告数据的方式获取各公开网框所发布的广告数据的特征参数,从而实现广告等无效图文数据的剔除)的图文数据挖掘模型。
18.数据挖掘模块,用于基于所述图文数据挖掘模型实现各公开网站所发布的图文数据的采集;每完成一次图文数据挖掘,图文数据挖掘模型内载的时间规则更新一次,初始图文数据挖掘模型内载的时间规则为无/企业所需的图文数据区间;图文数据整理模块,用于实现各图文数据的整理,剔除不良图文数据和存在重叠特征的图文数据;其中,在图文数据整理模块发现存在重叠特征的图文数据时,选择保留包含数据特征相对较多的图文数据,并剔除与之存在重叠特征的其他的图文数据。
19.更新监测爬虫模块,不同的公开网站配置有不同的数据更新监测爬虫,用于实现网站更新的监测,每监测到一次数据更新,图文数据挖掘模型启动一次;关联关系构建模块,用于构建各图文数据之间的关联关系,并基于所述关联关系搭建对应的搜索引擎;目标
图文数据汇总模块,用于根据用户录入的数据需求基于hadoop运行对应的图文数据挖掘处理算法组实现目标图文数据的同步挖掘汇总。
20.本实施例中,图文数据整理模块基于不良文本数据识别模型和不良图像识别模型实现不良图文数据的识别,其中,不良文本数据识别模型基于词典内载的污秽词语等训练构建,不良图像识别模型采用dssd inception v3模型,该模型采用dssd目标检测算法,用coco数据集预训练inception_v3_深度神经网络,然后用先前准备好的数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于检测存在不积极特征的图像的目标检测模型。
21.本实施例中,每一个图像数据挖掘模型对应一图文数据模板,所挖掘到的图像数据均自动填入对应的图文数据模板,在完成图文数据挖掘的同时,可以完成图文数据的整理,为后续的图文数据之间关联关系构建提供便利。
22.本实施例中,关联关系构建模块在构建关联关系之间,需先基于hadoop运行所有的图文数据特征提取算法实现所有图文数据特征的提取,从而为每一个图文数据标记上其对应的特征标记,然后,在根据这些特征标记之间存在的关联关系构建各图文数据之间的关联关系,并基于所述关联关系搭建对应的搜索引擎。
23.为了适应不同的数据挖掘需求,本系统还配置了:图文数据挖掘模型润色模块,用于根据不同的数据挖掘需求,为对应的图文数据挖掘模型串联上对应的数据筛选次模型,数据筛选次模型用于约束图文数据挖掘模型挖掘的范围(比如作者、所属地等)、约束数据挖掘模型挖掘的时间等。
24.如图2所示,本具体实施工作时,包括如下步骤:s1、配置用于约束图文数据挖掘模型挖掘范围、时间、对象等的数据筛选次模型;s2、基于数据挖掘模型配置模块,为不同的公开网站配置不同的图文数据挖掘模型;具体地,不同的公开网站的数据发布模式是不同的,为了适应不同的公开网站,从而缩短数据模型在数据挖掘过程中所花费的时间,在进行图文数据挖掘模型配置前,需先通过随机挖掘不同的公开网站公布的100条数据的方式分析获取不同的公开网站的图文数据发布特征,从而构建可以实现感兴趣的图文数据定向采集,并自动剔除广告等无效图文数据(通过随机挖掘不同的公开网站公布的20条广告数据的方式获取各公开网框所发布的广告数据的特征参数,从而实现广告等无效图文数据的剔除)的图文数据挖掘模型。
25.s3、基于所述图文数据挖掘模型实现各公开网站所发布的图文数据的采集;每完成一次图文数据挖掘,图文数据挖掘模型内载的时间规则更新一次,初始图文数据挖掘模型内载的时间规则为无/企业所需的图文数据区间;s4、实现各图文数据的整理,剔除不良图文数据和存在重叠特征的图文数据;其中,在图文数据整理模块发现存在重叠特征的图文数据时,选择保留包含数据特征相对较多的图文数据,并剔除与之存在重叠特征的其他的图文数据。
26.s5、基于更新监测爬虫模块实现各公开网站数据更新情况的监测,每监测到一次数据更新,图文数据挖掘模型启动一次;s6、构建各图文数据之间的关联关系,并基于所述关联关系搭建对应的搜索引擎;在构建关联关系之间,需先基于hadoop运行所有的图文数据特征提取算法实现所有图文数据特征的提取,从而为每一个图文数据标记上其对应的特征标记,然后,在根据这些特征标
记之间存在的关联关系构建各图文数据之间的关联关系s7、根据用户录入的数据需求基于hadoop运行对应的图文数据挖掘处理算法组实现目标图文数据的同步挖掘汇总。
27.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。