1.本发明涉及数字信息传输技术领域,尤其涉及的是最小和算法的优化参数配置方法、装置、终端及存储介质。
背景技术:
2.ldpc码(low density parity check code,低密度奇偶校验码)一类由gallager于1962年最早提出,并经由luby等人改进的线性分组码,通常由相应的稀疏校验矩阵h进行描述。由于其不但具备门限性能优异、吞吐能力高的优势,而且具有码长可变、码率兼容等特点,近年来始终是信道编码领域炙手可热的研究对象。目前,无论是通信还是广播领域,许多传输标准中均有对ldpc码的采用,例如通信领域的无线局域网标准ieee 802.16e,广播领域的dvb-s2/t2/c2/ngh、dtmb/dtmba标准和atsc3.0标准等。
3.第三代合作伙伴计划(3gpp)也选择低密度奇偶校验(ldpc)码作为其中一种信道编码方案,以应对5g新型空口技术(5g-nr)涉及的各种应用场景。在过去的半个世纪中,ldpc曾被认为是一种对运算量有极高需求的编码方案,但事实上,随着新兴的信息技术,特别是计算能力的快速发展,这一缺点已经不再制约其应用。相应地,对译码算法的改进成为其优化的主要方向之一。
4.对于译码过程中的运算单元,ldpc码被提出的同时,用于译码的置信度传播(belief propagation,bp)迭代译码算法也相应被提出。和积算法(spa),正是这样一种基于置信度传播(bp)的迭代译码算法。其可以在实现复杂度远小于map算法的基础上,达到接近容量的性能。但是在实际应用中,由于其较高的计算复杂度和对信道参数估计的高度敏感性,在实际应用中存在较大的局限性。因此,针对spa的简化主要有两个方向,即最小和算法(msa)和经调整的最小和算法(adjspa)。
5.然而,由于adjspa继承了spa中所采用的tanh运算,因此其仍然没有解决对信道参数估计高度敏感的特点;msa算法在水平译码器中利用最小值运算取代了spa所采用的高度复杂的tanh运算,因此针对每一次迭代,每一行相应水平运算的输出仅仅包含最小值和次最小值两种不同的取值。一方面,由于相对于spa,msa所采用的最小值运算简化了输出值,另一方面,即使是取了最小值,相对spa的输出值仍然存在过高的估计,因此msa的性能相对于spa有较大的性能损失。
6.因此,现有技术还有待改进。
技术实现要素:
7.本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种最小和算法的优化参数配置方法、装置、终端及存储介质,以解决现有的msa的性能低的技术问题。
8.本发明解决技术问题所采用的技术方案如下:
9.第一方面,本发明提供一种最小和算法的优化参数配置方法,应用于通信设备的5g-nr ldpc的译码过程,包括:
10.在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,得到优化后的msa及改进译码算法;
11.根据预设的初始化归一化因子查找表,获取目标误码率条件下的译码门限,并将所述译码门限作为参考门限;
12.从预设测试集中选择满足条件的归一化因子的测试例,并通过优化后的msa及改进译码算法对所述测试例的译码性能进行预测;
13.根据所述测试例的预测结果将所述测试例的译码门限与所述参考门限进行对比,并根据对比结果更新及输出所述初始化归一化因子查找表。
14.在一种实现方式中,所述在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,之前包括:
15.根据预设信道传输模型及预设等效信噪比条件,获得等效信道解映射单元输出的编码比特软信息的概率密度函数;
16.利用所述编码比特软信息的概率密度函数,对变量节点输出软信息的概率密度函数进行初始化,并对校验节点输出软信息的概率密度函数进行初始化。
17.在一种实现方式中,所述在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,之前还包括:
18.按照第一顺序对所述编码比特软信息的概率密度函数与前次迭代校验节点输出软信息的概率密度函数进行卷积运算,更新所述变量节点输出软信息的概率密度函数。
19.在一种实现方式中,所述在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,包括:
20.通过更新后的变量节点输出软信息的概率密度函数,获得译码结果;
21.判断当前的迭代次数是否已达到预设迭代次数;
22.若当前的迭代次数已达到所述预设迭代次数,则计算所述译码结果对应的误码率;
23.根据计算的误码率调整预设的等效信噪比条件或输出本次等效信噪比的取值;
24.按照第二顺序,对更新后的变量节点输出软信息的概率密度函数进行新定义的卷积运算,更新校验节点输出软信息的概率密度函数;
25.根据更新后的校验节点输出软信息的概率密度函数,校正校验节点连接的每个边的输出软信息的概率密度函数。
26.在一种实现方式中,所述根据计算的误码率调整预设的等效信噪比条件或输出本次等效信噪比的取值,包括:
27.判断计算的误码率是否达到目标误码率;
28.若计算的误码率达到所述目标误码率,则输出本次等效信噪比的取值;
29.若计算的误码率未达到所述目标误码率,则调整预设的等效信噪比条件,并根据调整后的等效信噪比条件继续优化译码结果。
30.在一种实现方式中,所述根据更新后的校验节点输出软信息的概率密度函数,校正校验节点连接的每个边的输出软信息的概率密度函数,包括:
31.根据更新后的校验节点输出软信息的概率密度函数,计算对应的校验节点的对数似然比;
32.利用所述对数似然比对原校验节点输出软信息的概率密度函数进行校正。
33.在一种实现方式中,所述利用对数似然比对原校验节点输出软信息的概率密度函数进行校正,包括:
34.利用所述对数似然比及第一算法对软信息为离散随机变量的概率密度函数进行校正;
35.利用所述对数似然比及第二算法对软信息为连续随机变量的概率密度函数进行校正。
36.在一种实现方式中,所述根据预设的初始化归一化因子查找表,获取目标误码率条件下的译码门限,并将所述译码门限作为参考门限,包括:
37.从预设的初始化归一化因子查找表中选择满足条件的归一化因子,代入校验节点运算,对校验节点输出进行校正;
38.获得校正后的输出软信息的概率密度函数。
39.在一种实现方式中,所述从预设测试集中选择满足条件的归一化因子的测试例,并通过优化后的msa及改进译码算法对所述测试例的译码性能进行预测,包括:
40.获取预设测试集l;
41.调整第m个边类别中第n个索引对应的归一化因子的取值,以使测试例遍历所述预设测试集l中的每一个元素;
42.当第n个校验方程失败比例对应的归一化因子的测试例完成对所述预设测试集l的遍历后,将对应的归一化因子取值更新为所存储的归一化因子查找表中的对应值,并对第n 1个索引对应的归一化因子进行调整;
43.当第m个边类别所有的n个归一化因子调整完成时,对第m 1个边类别对应的归一化因子进行调整;
44.根据调整后的归一化因子输出预测结果。
45.在一种实现方式中,所述获取预设测试集l,包括:
46.设定针对边的分类数和归一化因子索引集的大小;
47.确定生成的归一化查找表的尺寸,并预设查找表中每个因子的测试例集合l的尺寸;
48.根据所述归一化查找表的尺寸和每个因子的测试例集合l的尺寸,得到所述预设测试集l。
49.第二方面,本发明提供一种最小和算法的优化参数配置装置,包括:
50.调整模块,用于在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,得到优化后的msa及改进译码算法;
51.参考模块,用于根据预设的初始化归一化因子查找表,获取目标误码率条件下的译码门限,并将所述译码门限作为参考门限;
52.预测模块,用于从预设测试集中选择满足条件的归一化因子的测试例,并通过优化后的msa及改进译码算法对所述测试例的译码性能进行预测;
53.输出模块,用于根据所述测试例的预测结果将所述测试例的译码门限与所述参考门限进行对比,并根据对比结果更新及输出所述初始化归一化因子查找表。
54.第三方面,本发明提供一种终端,包括:处理器以及存储器,所述存储器存储有最
小和算法的优化参数配置程序,所述最小和算法的优化参数配置程序被所述处理器执行时用于实现如第一方面所述的最小和算法的优化参数配置方法的操作。
55.第四方面,本发明还提供一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有最小和算法的优化参数配置程序,所述最小和算法的优化参数配置程序被处理器执行时用于实现如第一方面所述的最小和算法的优化参数配置方法的操作。
56.本发明采用上述技术方案具有以下效果:
57.本发明可以分析并预测任何一种基于msa的改进算法自身的译码性能,也能够提供基于msa的所有改进算法所能达到的极限译码性能。同时,利用优异分析性能,可以根据应用场景和实际需求获得一组与之相适应的归一化因子,从而克服传统译码算法应用于met ldpc码时,难以同时兼顾译码性能、鲁棒性和误码平台三方面表现的弊端,保证在译码门限、鲁棒性与误码平台三个方面的优良性能。本发明在保证良好的译码门限的基础上,摆脱了对spa的依赖,有效提高的译码算法的鲁棒性,彻底解决了对信道参数的估计高度敏感的固有问题,同时,所采用的归一化因子在获取方式上具有高度的灵活性和良好的适用性,能够以一种通用的方法针对不用的应用场景分别进行优化,而不必显著增加设计复杂度与硬件实现复杂度。
附图说明
58.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
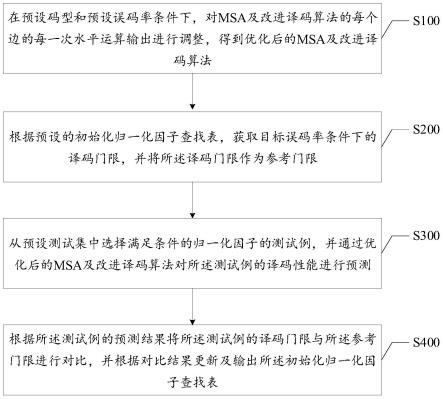
59.图1是本发明的一种实现方式中最小和算法的优化参数配置方法的流程图。
60.图2是本发明的一种实现方式中模板矩阵归一化因子查找表的示意图。
61.图3是本发明的一种实现方式中四种译码算法的译码门限与鲁棒性对比示意图。
62.图4是本发明的一种实现方式中四种主要译码算法的性能对比示意图。
63.图5是本发明的一种实现方式中终端的功能原理图。
64.本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
65.为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
66.示例性方法
67.为了改善msa算法性能下降的问题,最小和算法的各类改进算法陆续被提出。其中最主要的包括:抵消最小和算法(omsa)和归一化最小和算法(nmsa)。由于前者并不能保证良好的鲁棒性,因此,后续的主要改进主要是基于归一化最小和算法,包括:自适应归一化最小和算法、增强的自适应归一化最小和算法等。
68.这些改进型算法均基于归一化的操作。对归一化,其核心目的是调整msa的输出值,使其与spa的输出值相似。即这些算法努力将msa的操作与spa输出的近似值相结合。因
此,当被应用于传统ldpc码时,它们的性能可能会非常优异,但如果涉及met ldpc码,例如5g-nr ldpc,则无法保持接近容量的优势。
69.此外,这些改进算法还始终存在以下两方面的不足:
70.1.msa的改进算法选择以spa的译码性能作为最后的容量限,事实上并没有深刻解释msa性能损失的根本原因;
71.2.这些改进型算法应用于met ldpc码时,难以同时兼顾译码性能、鲁棒性和误码平台三个方面的表现。
72.因此对于5g等应用场景下,迫切需要针对自适应归一化最小和算法的参数配置进行优化,即需要一种更通用的归一化因子获取方式,使其应用于msa译码过程后,能够在保证其良好的译码性能的前提下,具备更好的通用性和鲁棒性。
73.针对上述技术问题,本实施例中提供了一种最小和算法的优化参数配置方法,可以分析并预测任何一种基于msa的改进算法自身的译码性能,也能够提供基于msa的所有改进算法所能达到的极限译码性能。同时,利用优异分析性能,可以根据应用场景和实际需求获得一组与之相适应的归一化因子,从而克服传统译码算法应用于met ldpc码时,难以同时兼顾译码性能、鲁棒性和误码平台三方面表现的弊端,保证在译码门限、鲁棒性与误码平台三个方面的优良性能。在保证良好的译码门限的基础上,摆脱了对spa的依赖,有效提高的译码算法的鲁棒性,彻底解决了对信道参数的估计高度敏感的固有问题,同时,所采用的归一化因子在获取方式上具有高度的灵活性和良好的适用性,能够以一种通用的方法针对不用的应用场景分别进行优化,而不必显著增加设计复杂度与硬件实现复杂度。
74.如图1所示,本发明实施例提供一种最小和算法的优化参数配置方法,包括以下步骤:
75.步骤s100,在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,得到优化后的msa及改进译码算法。
76.在本实施例中,所述最小和算法的优化参数配置方法应用于通信设备的5g-nr ldpc的译码过程,其中,通信设备包括但不限于:基站,中继以及5g移动终端等设备。
77.在本实施例中,要解决的问题是,如何确定msa及其改进译码算法可实现的最优性能界限,并针对5g-nr ldpc码的译码过程,在不显著增加复杂度的同时,兼顾译码门限、鲁棒性与误码平台三方面性能表现的情况下,快速给出符合应用场景需求的最优归一化因子。
78.在本实施例中,针对msa及其改进译码算法,在给定码型和预设误码率ber_pre-10-9
条件下,通过所提出的方法,针对每个边的每一次水平运算输出做调整,从而实现对输出值做理想的校正,获得该码型应用msa及其改进译码算法可实现的最优性能界限snr_opt。
79.具体地,在本实施例的一种实现方式中,步骤s100之前包括以下步骤:
80.步骤s001,根据预设信道传输模型及预设等效信噪比条件,获得等效信道解映射单元输出的编码比特软信息的概率密度函数;
81.步骤s002,利用所述编码比特软信息的概率密度函数,对变量节点输出软信息的概率密度函数进行初始化,并对校验节点输出软信息的概率密度函数进行初始化;
82.步骤s003,按照第一顺序对所述编码比特软信息的概率密度函数与前次迭代校验
节点输出软信息的概率密度函数进行卷积运算,更新所述变量节点输出软信息的概率密度函数。
83.在本实施例中,在对msa及改进译码算法的每个边的每一次水平运算输出进行调整之前,需要在预设码型和预设误码率条件下,获取相应的概率密度函数,具体如下:
84.首先根据给定信道传输模型yi=xi noise,预设误码率目标ber_pre及预设的等效信噪比条件snr_pre,获得等效信道解映射单元输出的编码比特软信息的概率密度函数pdf_ch;然后,利用编码比特软信息的概率密度函数pdf_ch,对变量节点输出软信息的概率密度函数pdf_vn进行初始化,同时,对校验节点输出软信息的概率密度函数pdf_cn进行初始化;最后,按照预定顺序(即第一卷积运算的顺序),对编码比特软信息的概率密度函数pdf_ch与前次迭代校验节点输出软信息的概率密度函数pdf_cn进行卷积运算,更新变量节点输出软信息的概率密度函数pdf_vn。
85.具体地,在本实施例的一种实现方式中,步骤s100包括以下步骤:
86.步骤s101,通过更新后的变量节点输出软信息的概率密度函数,获得译码结果;
87.步骤s102,判断当前的迭代次数是否已达到预设迭代次数;
88.步骤s103,若当前的迭代次数已达到所述预设迭代次数,则计算所述译码结果对应的误码率;
89.步骤s104,根据计算的误码率调整预设的等效信噪比条件或输出本次等效信噪比的取值;
90.步骤s105,按照第二顺序,对更新后的变量节点输出软信息的概率密度函数进行新定义的卷积运算,更新校验节点输出软信息的概率密度函数;
91.步骤s106,根据更新后的校验节点输出软信息的概率密度函数,校正校验节点连接的每个边的输出软信息的概率密度函数。
92.在本实施例中,在更新变量节点输出软信息的概率密度函数后,即可通过变量节点输出软信息的概率密度函数pdf_vn获得计算译码结果,并且,判断是否完成译码过程,计算相应的误码率ber_cur。之后,根据条件判断结果,按照预定顺序(即第二卷积运算的顺序),对所获得的变量节点输出软信息的概率密度函数pdf_vn进行新定义的卷积运算,更新校验节点输出软信息的概率密度函数pdf_cn;以及根据所获得的校验节点输出软信息的概率密度函数pdf_cn,计算相应校验节点的对数似然比(llr),并校正校验节点连接的每个边的输出软信息的概率密度函数pdf_cn。
93.具体地,在本实施例的一种实现方式中,步骤s104包括以下步骤:
94.步骤s104a,判断计算的误码率是否达到目标误码率;
95.步骤s104b,若计算的误码率达到所述目标误码率,则输出本次等效信噪比的取值;
96.步骤s104c,若计算的误码率未达到所述目标误码率,则调整预设的等效信噪比条件,并根据调整后的等效信噪比条件继续优化译码结果。
97.在本实施例中,在判断是否完成译码过程时,可通过当前的迭代次数进行判定,若当前已经达到了预设迭代次数,且误码率未达到预设目标ber_pre,则调整预设的等效信噪比条件snr_pre,并根据调整后的等效信噪比条件snr_pre,获得等效信道解映射单元输出的编码比特软信息的概率密度函数pdf_ch,以继续优化,直至误码率达到预设目标ber_
pre。
98.若当前已经达到了预设迭代次数,且误码率已经达到预设目标ber_pre,则结束运行,输出本次等效信噪比的取值snr_pre作为snr_opt。若当前未达到预设迭代次数,则按照预定顺序(即第二卷积运算的顺序),对所获得的变量节点输出软信息的概率密度函数pdf_vn进行新定义的卷积运算,更新校验节点输出软信息的概率密度函数pdf_cn。
99.具体地,在本实施例的一种实现方式中,步骤s106包括以下步骤:
100.步骤s106a,根据更新后的校验节点输出软信息的概率密度函数,计算对应的校验节点的对数似然比;
101.步骤s106b,利用所述对数似然比对原校验节点输出软信息的概率密度函数进行校正。
102.在本实施例中,根据所获得的校验节点输出软信息的概率密度函数pdf_cn,计算相应校验节点的对数似然比llr_cn,具体公式为:
[0103][0104]
在计算得到对数似然比llr_cn后,利用所获得的对数似然比llr_cn对原校验节点输出软信息的概率密度函数pdf_cn进行校正。
[0105]
具体地,在本实施例的一种实现方式中,步骤s106b包括以下步骤:
[0106]
步骤s106b-1,利用所述对数似然比及第一算法对软信息为离散随机变量的概率密度函数进行校正;
[0107]
步骤s106b-2,利用所述对数似然比及第二算法对软信息为连续随机变量的概率密度函数进行校正。
[0108]
优选地,步骤s106b的校正操作,即将原校验节点输出软信息的概率密度函数pdf_cn校正为pdf_cn’具体包括:
[0109]
针对软信息为离散随机变量的情况,其校正的公式(即第一算法)为:
[0110][0111][0112]
针对软信息为连续随机变量的情况,其校正的公式(即第二算法)为:
[0113][0114][0115]
通过上述两种情况对应的公式,可将原校验节点输出软信息的概率密度函数pdf_cn校正为pdf_cn’,针对每个边的每一次水平运算输出做调整,从而实现对输出值做理想的校正,进而获得该码型应用msa及其改进译码算法可实现的最优性能。
[0116]
作为本实施例中的一种优选方式,卷积运算具体包括:
[0117]
对于编码比特软信息的概率密度函数pdf_ch与前次迭代校验节点输出软信息的
概率密度函数pdf_cn,所更新的变量节点输出软信息的概率密度函数pdf_vn
ij
为:
[0118][0119]
其中e遍历第i列中除了第j个边以外所有的边,即e∈n(i)\j。
[0120]
作为本实施例中的一种优选方式,新定义的卷积运算具体包括:
[0121]
对于变量节点输出软信息的概率密度函数pdf_vn,所更新校验节点输出软信息的概率密度函数pdf_cn为:
[0122][0123]
其中e遍历第j行中除了第i个边以外所有的边,即e∈m(j)\i。
[0124]
本实施例中应用密度进化算法作为主要分析工具,突破了传统蒙特卡洛仿真算法导致的归一化因子查找表分类数与拟合训练样本数之间的结构性矛盾,且不需要和积算法作为参照。此外,也不必预先训练大量因子样本后再行拟合等操作;通过对每次迭代中每个边的水平译码算法输出均进行校正,从而使得输出值符合对数似然比的定义,进而使得修正后的输出服从对数似然比的概率分布。通过这种方法,最小和译码算法引入取最小值运算使得输出值偏离对数似然比定义所带来的性能损失得以消除,修正后的最小和译码算法成为真正基于置信度传播的译码算法。
[0125]
如图1所示,在本发明实施例的一种实现方式中,最小和算法的优化参数配置方法还包括以下步骤:
[0126]
步骤s200,根据预设的初始化归一化因子查找表,获取目标误码率条件下的译码门限,并将所述译码门限作为参考门限。
[0127]
在本实施例中,在对msa及其改进译码算法的输出值做理想的校正后,利用本实施例所采用的分析方法,针对预设的初始化归一化因子查找表α_prem×n,获得给定误码率ber_pre条件下的译码门限snr_per作为参考门限snr_ref,并存储预设的初始化归一化因子查找表αm×n。
[0128]
具体地,在本实施例的一种实现方式中,步骤s200包括以下步骤:
[0129]
步骤s201,从预设的初始化归一化因子查找表中选择满足条件的归一化因子,代入校验节点运算,对校验节点输出进行校正;
[0130]
步骤s202,获得校正后的输出软信息的概率密度函数。
[0131]
在本实施例中,在获取目标误码率条件下的译码门限时,可以参照上述步骤获得参考门限,具体如下:
[0132]
首先,根据给定信道传输模型和等效信噪比条件snr_pre,获得等效信道解映射单元输出的编码比特软信息的概率密度函数pdf_ch。
[0133]
进一步地,利用编码比特软信息的概率密度函数pdf_ch,对变量节点输出软信息的概率密度函数pdf_vn进行初始化,同时,对校验节点外信息的概率密度函数pdf_cn进行初始化。
[0134]
进一步地,按照预定顺序,对编码比特软信息的概率密度函数pdf_ch与前次迭代校验节点输出软信息的概率密度函数pdf_cn进行卷积运算,更新变量节点输出软信息的概率密度函数pdf_vn。
[0135]
进一步地,通过变量节点输出软信息的概率密度函数pdf_vn获得计算译码结果,判断是否完成译码过程,计算相应的误码率ber_cur;若当前已经达到了预设迭代次数,且误码率未达到预设目标ber_pre,则调整给定等效信噪比条件snr_pre,并根据调整后的等效信噪比条件snr_pre,获得等效信道解映射单元输出的编码比特软信息的概率密度函数pdf_ch,以继续优化,直至误码率达到预设目标ber_pre。若当前已经达到了预设迭代次数,且误码率已经达到预设目标ber_pre,则结束运行,输出本次等效信噪比的取值snr_pre作为snr_opt。若当前未达到预设迭代次数,则按照预定顺序(即第二卷积运算的顺序),对所获得的变量节点输出软信息的概率密度函数pdf_vn进行新定义的卷积运算,更新校验节点输出软信息的概率密度函数pdf_cn。
[0136]
进一步地,按照预定顺序,对所获得的变量节点输出软信息的概率密度函数pdf_vn进行新定义的卷积运算,更新校验节点输出软信息的概率密度函数pdf_cn。
[0137]
最后,从预设的初始化归一化因子查找表α_prem×n中选择合适的归一化因子α,代入校验节点运算,对校验节点输出进行校正,相应地,获得校正后的输出软信息的概率密度函数pdf_cn’。
[0138]
如图1所示,在本发明实施例的一种实现方式中,最小和算法的优化参数配置方法还包括以下步骤:
[0139]
步骤s300,从预设测试集中选择满足条件的归一化因子的测试例,并通过优化后的msa及改进译码算法对所述测试例的译码性能进行预测。
[0140]
在本实施例中,从给定测试集l选择相应归一化因子的测试例,若当前已经遍历所有测试例,输出所存储的归一化因子查找表αm×n,否则,按照预定顺序选择下一测试例。
[0141]
具体地,在本实施例的一种实现方式中,步骤s300包括以下步骤:
[0142]
步骤s301,获取预设测试集l;
[0143]
步骤s302,调整第m个边类别中第n个索引对应的归一化因子的取值,以使测试例遍历所述预设测试集l中的每一个元素;
[0144]
步骤s303,当第n个校验方程失败比例对应的归一化因子的测试例完成对所述预设测试集l的遍历后,将对应的归一化因子取值更新为所存储的归一化因子查找表中的对应值,并对第n 1个索引对应的归一化因子进行调整;
[0145]
步骤s304,当第m个边类别所有的n个归一化因子调整完成时,对第m 1个边类别对应的归一化因子进行调整;
[0146]
步骤s305,根据调整后的归一化因子输出预测结果。
[0147]
在本实施例中,按照预定顺序调整操作具体包括:
[0148]
预先设定针对边的分类数m、归一化因子索引集的大小n,获取集合l={(2i-1/2l,i=1,2,...,l};调整第m个边类别中,第n个索引对应的归一化因子的取值,使得测试例遍历l中的每一个元素。
[0149]
当第n个校验方程失败比例对应的归一化因子α_prem×n(m,n)的测试例已经完成对集合l的遍历后,更新该归一化因子取值α_prem×n(m,n)为所存储的归一化因子查找表中的对应值αm×n(m,n),并按照上述流程,开始对第n 1个索引对应的归一化因子α_prem×n(m,n 1)进行调整;当第m个边类别所有的n个归一化因子调整完毕后,按照上述流程对第m 1个边类别对应的归一化因子α_prem×n(m 1,:)进行调整。
[0150]
具体地,在本实施例的一种实现方式中,步骤s301包括以下步骤:
[0151]
步骤s301a,设定针对边的分类数和归一化因子索引集的大小;
[0152]
步骤s301b,确定生成的归一化查找表的尺寸,并预设查找表中每个因子的测试例集合l的尺寸;
[0153]
步骤s301c,根据所述归一化查找表的尺寸和每个因子的测试例集合l的尺寸,得到所述预设测试集l。
[0154]
在本实施例中,在获取预设测试集l的过程中,可以根据应用场景需求和实现复杂度要求,预先设定针对边的分类数m、归一化因子索引集的大小n,针对5g-nr ldpc码基矩阵2,预设m-2,索引预设为校验方程失败比例,集合大小为n=32,从而确定要生成的归一化查找表的尺寸m
×
n,此外,预设查找表中每个因子的测试例集合l的尺寸l=32,因此,集合l-{(2i-1)/2l,i-1,2,...,l}。
[0155]
本实施例在修正的基础上,可以分析最小和译码算法性能损失的根本原因,并给出这种分析视角下性能损失的组成部分,对于其中可以改善的性能损失部分能够有效消除,达到最小和译码所能达到的渐进最优容量界;可以面向指定码型的归一化因子查找表做优化,首先针对初始化的归一化查找表,快速预测其性能;随后,利用通过边分类和迭代,快速获得渐进最优的归一化因子查找表。这种获取方式对ldpc码具有通用性,仿真结果表明,该方法所获得的归一化因子查找表应用于译码过程中能够保证良好的译码性能,同时具有与最小和译码类似的鲁棒性。
[0156]
如图1所示,在本发明实施例的一种实现方式中,最小和算法的优化参数配置方法还包括以下步骤:
[0157]
步骤s400,根据所述测试例的预测结果将所述测试例的译码门限与所述参考门限进行对比,并根据对比结果更新及输出所述初始化归一化因子查找表。
[0158]
在本实施例中,通过所采用的分析方法预测测试例的译码性能,若测试例门限snr_test优于参考门限snr_ref,则将该测试例门限作为新的参考门限snr_ref,并更新所存储的归一化因子查找表αm×n中的对应元素,并继续从给定测试集l选择相应归一化因子的测试例;若测试例门限snr_test劣于参考门限snr_ref,则直接返回从给定测试集l选择相应归一化因子的测试例。
[0159]
在遍历所有的测试例后,输出所存储的归一化因子查找表αm×n,实现对自适应归一化最小和算法的参数进行优化配置。
[0160]
本实施例中能够针对给定码型,分析应用基于msa的改进算法所能达到的译码性能。此外,这种方法也能够对基于msa的改进算法进行性能预测;在此基础上,可以利用上述方法,对一组初始化的归一化因子查找表进行迭代优化,实现对自适应归一化最小和算法的参数进行优化配置,例如针对5g-nr ldpc码的译码过程,在不显著增加复杂度的同时,可以快速给出一组符合应用场景需求的最优归一化因子,同时兼顾其译码门限、鲁棒性与误码平台三方面的性能表现。
[0161]
以下通过实际应用对本实施例进行说明:
[0162]
本实施例中所提出的归一化因子获取方法,适用于各种信道条件,包括典型加性高斯白噪声(awgn)信道条件和瑞利衰落信道条件,对不同码率、不同码长的ldpc码均具有良好的解码性能。
[0163]
在本实施例中,采用的ldpc码校验矩阵为5g-nr ldpc码中基矩阵2,以1/5码率为基础,获取相应的归一化因子查找表,并应用到ldpc码的不同码率包括1/5,1/4,1/3,1/2,2/3和5/6中,采用的提升矩阵维数为z=384。
[0164]
在本实施例中,译码器预设的针对5g-nr ldpc码中基矩阵2的归一化因子映射表如图2所示,其中边分类类别数为2。
[0165]
如图3所示,spa点线对应和积算法译码方法和译码器,msa点线对应最小和译码方法和译码器,msa
opt
点线对应本发明所获得的最小和算法可达最优译码门限,msa
prac
点线对应应用了本实施例获取的归一化因子查找表的自适应的最小和译码方法和译码器。
[0166]
如图4所示,spa点线对应和积算法译码方法和译码器,adjspa点线对应校正的和积算法译码方法和译码器,msa
opt
点线对应本发明获得的最小和算法可达最优译码门限,msa
prac
点线对应应用本实施例获取的归一化因子查找表的自适应的最小和译码方法和译码器。
[0167]
可以看出,本实施例能够在保证5g-nr ldpc码最小和算法译码方法的误码性能的前提下,显著优化其译码的鲁棒性。如图3所示,在ber=1e-9时,各码率条件下与传统和积算法译码方法信噪比性能差距最大仅为0.26db,但是其在面对信噪比估计误差时,能够保证与最小和译码方法类似的鲁棒性。
[0168]
本实施例通过上述技术方案达到以下技术效果:
[0169]
本实施例可以分析并预测任何一种基于msa的改进算法自身的译码性能,也能够提供基于msa的所有改进算法所能达到的极限译码性能。同时,利用优异分析性能,可以根据应用场景和实际需求获得一组与之相适应的归一化因子,从而克服传统译码算法应用于met ldpc码时,难以同时兼顾译码性能、鲁棒性和误码平台三方面表现的弊端,保证在译码门限、鲁棒性与误码平台三个方面的优良性能。本实施例在保证良好的译码门限的基础上,摆脱了对spa的依赖,有效提高的译码算法的鲁棒性,彻底解决了对信道参数的估计高度敏感的固有问题,同时,所采用的归一化因子在获取方式上具有高度的灵活性和良好的适用性,能够以一种通用的方法针对不用的应用场景分别进行优化,而不必显著增加设计复杂度与硬件实现复杂度。
[0170]
示例性设备
[0171]
基于上述实施例,本发明还提供一种最小和算法的优化参数配置装置,包括:
[0172]
调整模块,用于在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,得到优化后的msa及改进译码算法;
[0173]
参考模块,用于根据预设的初始化归一化因子查找表,获取目标误码率条件下的译码门限,并将所述译码门限作为参考门限;
[0174]
预测模块,用于从预设测试集中选择满足条件的归一化因子的测试例,并通过优化后的msa及改进译码算法对所述测试例的译码性能进行预测;
[0175]
输出模块,用于根据所述测试例的预测结果将所述测试例的译码门限与所述参考门限进行对比,并根据对比结果更新及输出所述初始化归一化因子查找表。
[0176]
基于上述实施例,本发明还提供一种终端,其原理框图可以如图5所示。
[0177]
该终端包括:通过系统总线连接的处理器、存储器、接口、显示屏以及通讯模块;其中,该终端的处理器用于提供计算和控制能力;该终端的存储器包括存储介质以及内存储
器;该存储介质存储有操作系统和计算机程序;该内存储器为存储介质中的操作系统和计算机程序的运行提供环境;该接口用于连接外部设备,例如,移动终端以及计算机等设备;该显示屏用于显示相应的信息;该通讯模块用于与云端服务器或移动终端进行通讯。
[0178]
该计算机程序被处理器执行时用以实现一种最小和算法的优化参数配置方法的操作。
[0179]
本领域技术人员可以理解的是,图5中示出的原理框图,仅仅是与本发明方案相关的部分结构的框图,并不构成对本发明方案所应用于其上的终端的限定,具体的终端可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0180]
在一个实施例中,提供了一种终端,其中,包括:处理器和存储器,存储器存储有最小和算法的优化参数配置程序,最小和算法的优化参数配置程序被处理器执行时用于实现如上的最小和算法的优化参数配置方法的操作。
[0181]
在一个实施例中,提供了一种存储介质,其中,存储介质存储有最小和算法的优化参数配置程序,最小和算法的优化参数配置程序被处理器执行时用于实现如上的最小和算法的优化参数配置方法的操作。
[0182]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,计算机程序可存储于一非易失性存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。
[0183]
综上,本发明提供了一种最小和算法的优化参数配置方法、装置、终端及存储介质,包括:在预设码型和预设误码率条件下,对msa及改进译码算法的每个边的每一次水平运算输出进行调整,得到优化后的msa及改进译码算法;根据预设的初始化归一化因子查找表,获取目标误码率条件下的译码门限,并将译码门限作为参考门限;从预设测试集中选择满足条件的归一化因子的测试例,并通过优化后的msa及改进译码算法对测试例的译码性能进行预测;根据测试例的预测结果将测试例的译码门限与参考门限进行对比,并根据对比结果更新及输出初始化归一化因子查找表。本发明在保证良好的译码门限的基础上,摆脱了对spa的依赖,有效提高译码算法的鲁棒性。
[0184]
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
