1.本发明涉及运动健康技术领域,具体涉及一种基于机器视觉骨骼追踪术的多人评测系统。
背景技术:
2.随着生活水平的提升,人们对生活的追求也变得多元化。人们更加注重自身的健康,而运动健康也更加受到人们的关注。更多的人去学习各种运动,例如武术、广场舞等等,但大部分的人没有意识到练习动作的同时姿势做得是否标准,这样收获的效果也会大打折扣。因此,针对这样的一个现状设计出一个能够纠正姿势的平台,有利于我们更好地运动学习,达到更好的效果。
3.现在的解决方案只是针对部分模块提出相应的方法。针对训练问题,不同的体系有着不同的训练标准,只能给予相对标准的纠正指导。针对分析报告问题,不同的人体有着不同的身体素质,同时包括各种不同因素的影响,给予的分析报告需要根据具体情况看待。
4.因此,本发明将提供一种基于机器视觉骨骼追踪术的多人评测系统意在解决以上问题。
技术实现要素:
5.本技术实施例提供了一种基于机器视觉骨骼追踪术的健美操、广场舞多人评测系统,旨在解决现有技术不能针对用户运动时的体态进行纠正的问题,包括姿势识别模块、中央处理模块和动作智能匹配及评价模块;
6.所述姿势识别模块包括摄像头拍摄单元、视频预处理单元和视频上传单元;
7.所述动作智能匹配及评价模块包括智能分析模块、视频处理模块、数据处理模块和数据反馈模块;
8.所述摄像头拍摄单元,用于拍摄运动视频;所述视频上传单元用于上传所述上传运动视频;所述视频预处理单元用于对所述运动视频进行预处理,包括获取用户运动时骨骼节点的变化信息,然后将变化信息发送至所述中央处理模块;
9.所述中央处理模块用于根据用户运动时骨骼节点的变化信息,搭建力学模型,分析关节间运动数据,将关节的具体位置数据发送至所述动作智能匹配及评价模块;
10.所述动作智能匹配及评价模块用于将关节的具体位置数据与标准的运动关键节点相关信息进行对比,获得相关动作差别信息,基于相关动作差别信息对该次运动的结果进行评价,并根据评价结果生成动作纠正方案。
11.优选的,本系统还包括视频模块,所述视频模块包括信息录入单元和信息显示单元,所述视频模块用于为用户提供标准化的运动视频,所述运动视频包括武术教学视频、广场舞视频、体操教学视频和专业运动姿势教学视频。
12.优选的,所述预处理包括对拍摄运动视频获取连续帧图像并进行关于人体骨骼的关键点检测,获取各关键点的二维图像坐标并将关键点与人体关联;
13.判断运动视频中的关键点的个数是否超出预定值,若未超过,则不进行姿态识别;若超过预定值,则将获取的各关键点的二维图像坐标转换为三维坐标。
14.更优的,基于所述三维坐标,获取关键点映射的肢体的相对位置特征,所述相对位置特征包括关键点之间表征的肢体距离、肢体夹角及关键点在x、y、z各方向上的距离差。
15.更优的,所述中央处理模块收到变化信息后,计算关键点的置信度累加权重,将置信度累加权重与预设阈值相比较,判断检测出表征姿态的人体关键点的信息是否足够;若置信度累加权重大于预设阈值,表示表征姿态的人体关键点的信息足够,利用肢体的相对位置关系判定法进行姿态识别,输出检测结果;
16.所述肢体的相对位置关系判定法包括预设的各种人体姿态,获取各姿态下的肢体的相对位置特征,将不同姿态下获取的肢体的相对位置特征的范围作为设定的阈值;将肢体的相对位置特征与设定的阈值进行比对,若处于设定的阈值范围内,则对应为预设姿态;若处于设定的阈值范围外则不属于预设姿态。
17.更优的,若所述累加权重小于预设阈值,表示表征姿态的人体关键点信息不足,采用神经网络姿态识别技术进行姿态识别,输出检测结果;所述的神经网络姿态识别技术具体包括如下步骤:
18.采用图像处理技术,提取人体目标轮廓的特征,特征包括面积、周长、宽高比和离心率;
19.将目标轮廓的特征与关键点映射的肢体的相对位置特征组合归一化后作为特征向量,形成训练模式库;
20.通过神经网络模型训练,构建神经网络姿态分类器对姿态进行识别。
21.更优的,所述骨骼关键点检测包括关键点置信图预测、关键点亲和场预测和关键点聚类;所述关键点置信图预测通过下式确定:
[0022][0023]
其中,表示第k个人的第j个关键点存在于p像素的置信度;x
j,k
表示第k个人的第j个关键点的空间坐标;σ表示高斯分布的扩散程度。
[0024]
更优的,整个人体的置信度为该人体所有组成部分的置信度中的最大值,如下式:
[0025][0026]
其中k表示当前检测总人数。
[0027]
本技术提出的一种基于机器视觉骨骼追踪术的多人评测系统,其有益效果包括:
[0028]
将所获取到的运动视频的动作信息与录入的标准数据库中相对应体态的各项指标信息进行对比分析,得到用户的体态信息与标准数据库中相对应的动作的各项指标评估结果;通过智能评价系统将其正确和错误动作的数据变为直观的数字,那么练习者可以通过相应的信息平台自主选择查看自己的动作体态质量信息,直观了解到自己体态中存的缺点,教练员或教师可以根据其信息反馈单元快速的给出相应的运动建议,并纠正其动作。
附图说明
[0029]
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
[0030]
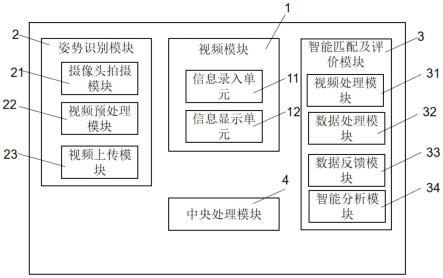
图1为本技术实施例提供的一种基于机器视觉骨骼追踪术的多人评测系统框架结构图;
[0031]
图2为技术流程图;
[0032]
图3为yolov5网络模型。
具体实施方式
[0033]
以下结合具体实施例对一种基于机器视觉骨骼追踪术的多人评测系统作进一步的详细描述,这些实施例只用于比较和解释的目的,本发明不限定于这些实施例中。
[0034]
如图1所示的一种基于机器视觉骨骼追踪术的多人评测系统,包括姿势识别模块、中央处理模块和动作智能匹配及评价模块;
[0035]
所述姿势识别模块包括摄像头拍摄单元、视频预处理单元和视频上传单元;
[0036]
所述动作智能匹配及评价模块包括智能分析模块、视频处理模块、数据处理模块和数据反馈模块;
[0037]
所述摄像头拍摄单元,用于拍摄运动视频;所述视频上传单元用于上传所述上传运动视频;所述视频预处理单元用于对所述运动视频进行预处理,包括获取用户运动时骨骼节点的变化信息,然后将变化信息发送至所述中央处理模块;
[0038]
所述中央处理模块用于根据用户运动时骨骼节点的变化信息,搭建力学模型,分析关节间运动数据,将关节的具体位置数据发送至所述动作智能匹配及评价模块;
[0039]
所述动作智能匹配及评价模块用于将关节的具体位置数据与标准的运动关键节点相关信息进行对比,获得相关动作差别信息,基于相关动作差别信息对该次运动的结果进行评价,并根据评价结果生成动作纠正方案。
[0040]
优选的,本系统还包括视频模块,所述视频模块包括信息录入单元和信息显示单元,所述视频模块用于为用户提供标准化的运动视频,所述运动视频包括武术教学视频、广场舞视频、体操教学视频和专业运动姿势教学视频。
[0041]
优选的,所述预处理包括对拍摄运动视频逐帧进行关于人体骨骼的关键点检测,获取各关键点的二维图像坐标并将关键点与人体关联;
[0042]
判断运动视频中的关键点的个数是否超出预定值,若未超过,则不进行姿态识别;若超过预定值,则将获取的各关键点的二维图像坐标转换为三维坐标。
[0043]
更优的,基于所述三维坐标,获取关键点映射的肢体的相对位置特征,所述相对位置特征包括关键点之间表征的肢体距离、肢体夹角及关键点在x、y、z各方向上的距离差。
[0044]
更优的,所述中央处理模块收到变化信息后,计算关键点的置信度累加权重,将置信度累加权重与预设阈值相比较,判断检测出表征姿态的人体关键点的信息是否足够;若置信度累加权重大于预设阈值,表示表征姿态的人体关键点的信息足够,利用肢体的相对位置关系判定法进行姿态识别,输出检测结果;
[0045]
所述肢体的相对位置关系判定法包括预设的各种人体姿态,获取各姿态下的肢体
的相对位置特征,将不同姿态下获取的肢体的相对位置特征的范围作为设定的阈值;将肢体的相对位置特征与设定的阈值进行比对,若处于设定的阈值范围内,则对应为预设姿态;若处于设定的阈值范围外则不属于预设姿态。
[0046]
更优的,若所述累加权重小于预设阈值,表示表征姿态的人体关键点信息不足,采用神经网络姿态识别技术进行姿态识别,输出检测结果;所述的神经网络姿态识别技术具体包括如下步骤:
[0047]
采用图像处理技术,提取人体目标轮廓的特征,特征包括面积、周长、宽高比和离心率;
[0048]
将目标轮廓的特征与关键点映射的肢体的相对位置特征组合归一化后作为特征向量,形成训练模式库;
[0049]
通过神经网络模型训练,构建神经网络姿态分类器对姿态进行识别。
[0050]
更优的,所述骨骼关键点检测包括关键点置信图预测、关键点亲和场预测和关键点聚类;所述关键点置信图预测通过下式确定:
[0051][0052]
其中,表示第k个人的第j个关键点存在于p像素的置信度;x
j,k
表示第k个人的第j个关键点的空间坐标;σ表示高斯分布的扩散程度。
[0053]
更优的,整个人体的置信度为该人体所有组成部分的置信度中的最大值,如下式:
[0054][0055]
其中k表示当前检测总人数。
[0056]
本发明提供的一种基于机器视觉骨骼追踪术的多人评测系统具体操作流程如图2所示,包括:
[0057]
(1)通过视频数据获取连续帧图像并进行预处理;
[0058]
(2)对获取的图像进行人体骨骼的关键点检测,获取各关键点的二维图像坐标并将关键点与人体关联;
[0059]
(3)设置一个预定值,判断检测出的人体关键点的个数是否超出预定值,若未超过,则不进行姿态识别;若超过预定值,则将获取的各关键点的二维图像坐标转换为三维坐标;
[0060]
(4)基于各关键点的三维坐标,获取关键点映射的肢体的相对位置特征,所述的相对位置特征包括关键点之间表征的肢体距离、肢体夹角及关键点在x、y、z各方向上的距离差;
[0061]
(5)计算关键点置信度累加权重,将累加权重与预设阈值相比较,判断检测出表征姿态的人体关键点信息是否足够;若累加权重大于预设阈值,表示表征姿态的人体关键点信息足够,利用肢体的相对位置关系判定法进行姿态识别,输出检测结果;所述肢体的相对位置关系判定法包括步骤:
[0062]
(5.1)通过预设的各种人体姿态,获取各姿态下的肢体的相对位置特征,将不同姿态获取的肢体的相对位置特征的范围作为设定的阈值;
[0063]
(5.2)根据步骤(4)获取的肢体的相对位置特征与设定的阈值进行比对,若处于设定的阈值范围内,则对应为预设姿态;否则不属于预设姿态。
[0064]
(6)若累加权重小于预设阈值,表示表征姿态的人体关键点的信息不足,采用神经网络姿态识别技术进行姿态识别,输出检测结果;步骤(6)所述的神经网络姿态识别技术具体包括如下步骤:
[0065]
(6.1)采用图像处理技术,提取人体目标轮廓的特征,特征包括面积、周长、宽高比和离心率;
[0066]
(6.2)目标轮廓特征与关键点映射的肢体的相对位置特征组合归一化后作为特征向量,形成训练模式库;
[0067]
(6.3)通过神经网络模型训练,构建神经网络姿态分类器对姿态进行识别。
[0068]
其中,骨骼关键点检测是采用自下而上的关键点检测算法;具体包括以下步骤:
[0069]
(1)构建双分支卷积神经网络将经过预处理后图片输入包含16个卷积层和3个全连接层的双分支深度卷积神经网络vgg-19,神经网络的前10层用于为输入图像创建特征映射,得到特征f;将f分别输入两个分支,第一分支用来预测关键点置信图s,第二分支用来预测关键点亲和场l;其中s=(s1,s2,
…
,sj),j表示要检测的关键点个数;l=(l1,l2,
…
,lc),c表示要检测的关节对数;
[0070]
(2)关键点置信图预测
[0071]
关键点置信图为:
[0072]
其中,表示第k个人的第j个关键点存在于p像素的置信度;x
j,k
表示第k个人的第j个关键点;σ表示高斯分布的扩散程度;
[0073]
设置关键点置信度阈值,若关键点置信度超过阈值,则保留该关键点;整个人体的置信度为该人体所有组成部分的置信度中的最大值,如下式:
[0074][0075]
其中k表示当前检测总人数。
[0076]
(3)关键点亲和场预测
[0077]
关键点亲和场则为:
[0078]
式中,表示第k个人的第c个两两连接的关节上是否存在某像素点p;l
c,k
=||x
j2,k-x
j1,k
||2表示位置j1指向位置j2的单位向量,x
j1,k
x
j2,k
分别为j1、j2的真实坐标;若满足以下条件,则判断像素点p在该关节对连接形成的肢体上:
[0079]
0≤v
·
(p-x
j1,k
)≤l
c,k and v
⊥
·
(p-x
j1,k
)|≤σ
l
[0080]
式中,v是肢体相对图像的比例,l
c,k
为第k个人的第c个关节对两两连接形成肢体的长度,σ
l
为肢体的宽度;v
⊥
表示人体对称关节节点之间的距离与图像之间的比例
[0081]
(4)关键点聚类
[0082]
使用最大边权的匈牙利算法进行二分图匹配,得到最优的多人关键点连接结果,将每个关键点和不同的人对应起来;匈牙利算法的目标是在c个两两连接的关节集合中找
出边权和最大的组合,如下式:
[0083][0084]
式中,zc表示c个两两连接的关节集合中找出边权和最大的组合,ec是最优化的多人关键点为第m个和第n个关键点类型的边权值,d
j1
为j个1类型关键点的集合,d
j2
为j个2类型关键点的集合,用于判断两个关键点是否相连;表示第m个1类关键点和第n个2类关键点是否相连。对于任意两个关键点位置和边权值,通过计算亲和场的积分来表征关键点对的相关性,如下式:
[0085][0086]
式中,d
j1
和d
j2
分别为关键点j1,j2的预测坐标,c为关键点j1,j2相连形成的肢体,p(u)为关键点上的采样,lc(p(u)为肢体c在p(u)点的paf预测值。
[0087]
根据获取到人体姿势的相关信息,与标准动作的相关信息进行比较,获得相应的对比结果的数据处理单元;
[0088]
以及,将获取到的对比结果返回到中央处理模块,中央处理模块接收到对比结果后,对其进行处理,获得数据差异结果。
[0089]
智能匹配及评价模块包括:
[0090]
将数据反馈模块反馈的对比结果进行分析的智能分析模块;智能分析模块主要用yolov5的目标检测算法主要分为以下几步:首先对图像大小进行统一调整,接着用卷积神经网络进行特征提取,然后通过非最大值抑制筛选出重复预测的候选框,最终输出预测的结果。算法先对图像按照规格进行尺寸调整,然后将图像划分为s
×
s个格子。每个格子都会预测内部是否存在目标的位置坐标,如果某个目标的中心坐标在其中某个格子中,那么就由这个格子完成目标识别。
[0091]
yolov5目标检测模型的神经网络主要包括输入端、backbone、neck、prediction四个部分,如图3所示。输入端使用mosaic数据增强,提升了小目标的检测效果,并且使用自适应锚框计算的方法,大大提高了训练和预测的效率。backbone主要包括focus和csp结构,它们用于对不同图像在细粒度上进行聚合,形成图像特征。neck由一系列混合和组合图像的网络层组成,主要作用是将图像特征从backbone传输到prediction。prediction用于对图像进行预测,检测目标种类以及目标所在候选框。
[0092]
在预测中,使用giou
loss
计算预测框回归损失函数均值,使用
[0093][0094]
其中ac是两个框最小闭包面积,u为a∪b。
[0095]
使用二元交叉熵损失函数bce
loss
计算目标分类损失函数均值:
[0096][0097]
其中n为样本总数,yi是第i个样本的类别,pi是第i个样本预测值。将分析好的结果展示给用户的结果展示单元。
[0098]
用户将运动视频上传到姿势识别模块,姿势识别模块对用户上传的运动视频进行处理,获取用户运动时骨骼节点的变化信息,为健身操、广场舞等标准姿态和待评估姿态的差异化对比做准备,然后将差异化信息发送至动作匹配模块;
[0099]
动作匹配模块根据用户运动时骨骼节点的变化信息,搭建力学模型,分析关节间运动数据,并与标准的运动关键节点相关信息进行对比,抽取标准的姿态视频与待匹配的姿态视频中的相似帧进行姿态匹配,然后根据人体姿态的特征选取合适的骨骼点组成特征向量及关键特征姿态,通过对比向量的相似度及特征姿态的角度,结合其标准姿态的相关系数评估与待匹配姿态的准确率,并分析他们之间的差异;
[0100]
智能匹配及评价模块用于将关节的具体位置数据与标准的运动关键节点相关信息进行对比,获得相关动作差别信息,
[0101]
基于相关动作差别信息对该次运动的结果进行评价,并根据评价结果生成动作纠正方案。若肢体的相对位置特征与设定的阈值进行比对结果为不处于预定阈值范围内,则不属于预设姿态,表明当前用户姿态不标准,通过视频模块提供标准动作视频指导。
[0102]
在一实施例中,视频模块1,至少包括有信息录入单元11和信息显示单元12;在本系统中,录入的专业教学视频包括但不限于武术教学视频、广场舞教学视频以及专业运动教学视频。用于为用户提供标准化的运动视频,运动视频包括武术教学视频、广场舞、体操教学视频和专业运动姿势教学视频。
[0103]
在一实施例中,姿势识别模块2至少包括有摄像头拍摄单元21、视频预处理单元22和视频上传单元单元23;
[0104]
其中,摄像头拍摄单元21,用于完成对用户实时运动视频的信息上传;视频预处理单元22,用于对用户上传的运动视频进行预处理,获取用户运动时骨骼节点的变化信息;视频上传单元23,用于获取用户上传的视频信息,通过处理视频获取到人体姿势的基本识别。
[0105]
在一实施例中,智能匹配及评价模块3,至少包括有视频处理单元31、数据处理单元32、数据反馈单元33和智能分析模块34;
[0106]
其中,视频处理单元31,用于对视频进行进一步的处理,包括截取关键图像,分析图像中的骨骼节点等信息;
[0107]
数据处理单元32,用于将用户训练视频的相关信息与标准动作的数据进行比较,从而得到相关的差异信息;
[0108]
数据反馈单元33,用于把得到的差异数据返回给中央处理模块4处理。
[0109]
智能分析模块34,用于对动作匹配模块处理完的数据运动科学的评价方法进行智能分析;通过信息显示单元可展示所需要的关键信息给用户。
[0110]
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。