1.本发明一种基于人工智能的情绪分类算法,属于融合领域的人工智能模型,涉及语音情感信息的声纹提取、特征融合及深度学习等方法。
背景技术:
2.情绪是指主观引起的一种强烈的情感状态,并且经常伴有心理上的变化。人们的情绪状态通常包含在人类的语言中。在人机交互中,通过人的语音识别出情绪状态是十分重要的环节。在心理情感分析领域,若能在谈话过程中及时的对人的情绪进行分类,将有助于对心理情绪的诊断和治疗。因此,需要一种可以通过输入语音数据来判断情绪分类的方法。
技术实现要素:
3.有鉴于此,本发明为了解决现有技术存在的缺陷和不足,提供了一种基于人工智能的情绪分类算法,通过语音数据样本输入构建的神经网络模型迭代学习后得到特征模型,特征模型可对待预测样本进行预测,得到预测标签和情绪分类结果。
4.本发明一种基于人工智能的情绪分类方法,包括以下步骤,步骤1:对多个语音数据样本按照情绪特征的实际标签分类并对其中的每个语音数据样本分别进行预处理和特征提取,得到多个语音数据样本的特征向量;步骤2:将多个语音数据样本的特征向量均输入神经网络训练模型,进行反复迭代学习后,得到特征模型;步骤3:将获取的待预测语音数据进行预处理和特征提取,得到待预测语音数据的特征向量,并将其输入至特征模型;步骤4:特征模型对待预测语音数据的特征向量进行提取,得到统计学概率分布,输出预测标签,得到情绪分类结果。
5.本发明的进一步改进在于:步骤1中,预处理和特征提取的过程如下:步骤11:获取语音数据样本的音频采样率和信号值,并统一语音数据样本的时间序列长度;步骤12:利用librosa音频处理库,提取统一时间序列长度的语音数据样本的第一类特征;所述第一类特征为统计学特征,包括语音过零率、均方根能量、频谱质心;步骤13:利用librosa音频处理库,对统一时间序列长度的语音数据样本执行快速傅里叶变换,计算每个频率区间能量,进行离散余弦变换之后,提取得到语音数据样本的第二类特征;所述第二类特征为音频数据特征,包括梅尔频率特征、谱对比度特征、色度频率特征;步骤14:将语音数据样本的第一类特征以矩阵拼接的方式进行部分融合,之后再通过concatenate函数与对应的第二类特征进行特征融合,形成语音数据样本的特征向量。
6.本发明的进一步改进在于:步骤1得到的特征向量为多维矩阵,其中存储了情绪特
征的数学形式。
7.本发明的进一步改进在于:步骤2中,神经网络训练模型反复迭代学习,依据特征向量中的情绪特征的数学形式得到的预测结果与对应的实际标签之间的预测误差,调整神经网络训练模型的参数;当情绪特征的数学形式与对应的实际标签拟合时,迭代学习后的神经网络训练模型即为特征模型。
8.本发明的进一步改进在于:调整神经网络训练模型的参数有损失函数和超参数,其中损失函数是loss_function;超参数是hyper_para。
9.本发明的进一步改进在于:所述特征模型包括记忆网络单元、门控循环单元、全连接神经网络单元;所述步骤4包括以下步骤:步骤40:待预测语音数据的特征向量输入至特征模型的记忆网络单元处理后,进入门控循环单元,使得待预测语音数据的特征向量的情绪特征数据显化;步骤41:显化的情绪特征数据再输入至全连接神经网络单元,进行权重更迭,使得显化的情绪特征数据得到具象;步骤42:使用分类器归一化情绪特征数据,得到统计学概率分布,输出预测标签。
10.本发明的进一步改进在于:在步骤40中,当特征向量进入门控循环单元之后,其输出结果由优化器接收,进行优化后,再进入步骤41。
11.本发明的进一步改进在于:记忆网络单元为128维的单层长短期记忆网络单元;门控循环单元为1152维的多层门控循环单元。
12.本发明的进一步改进在于:所述分类器为softmax函数;所述预测标签为4维预测标签。
13.本发明的进一步改进在于:步骤3中,待预测语音数据通过预处理和特征提取,得到待预测语音数据的第一类特征和第二类特征,待预测语音数据的第一类特征进行部分融合后,再与第二类特征进行融合,得到待预测语音数据的特征向量。
14.与现有技术相比,本发明的有益效果:语音数据样本无法直接输入神经网络训练模型进行训练,利用特征提取,将语音数据样本转换为特征向量的形式,即多维矩阵然后将特征向量传入神经网络训练模型,神经网络训练模型经迭代学习,得到特征模型。
15.本发明先对第一类特征以特征堆叠的方式进行部分融合,再与第二类特征进行进一步的特征融合,使得语音中的情绪特征数据更为显著,提升了融合与拼接效率。
16.本发明结合了长短期记忆网络与门控循环单元网络,相较单层长短期记忆网络具有明显的准确率提升优势。同时,使用优化器(sigmoid)作为激活函数,也对提升预测的准确率有明显帮助。
附图说明
17.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
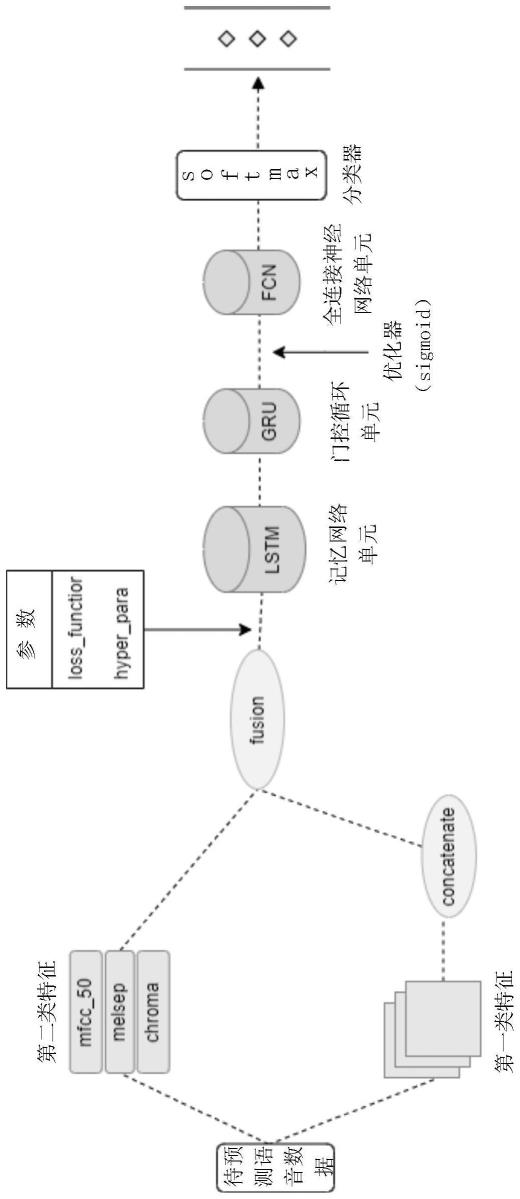
18.图1是待预测语音数据输入特征模型的流程图。
具体实施方式
19.为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
20.本发明提供了一种基于人工智能的情绪分类算法,通过语音数据样本输入构建的神经网络模型迭代学习后得到特征模型,特征模型可对待预测样本进行预测,得到预测标签和情绪分类结果。
21.本发明一种基于人工智能的情绪分类方法,包括以下步骤:步骤1:对多个语音数据样本按照情绪特征的实际标签分类并对其中的每个语音数据样本分别进行预处理和特征提取,得到多个语音数据样本的特征向量。
22.更具体的,预处理和特征提取的过程如下:步骤11:获取语音数据样本的音频采样率和信号值,并统一语音数据样本的时间序列长度;步骤12:利用librosa音频处理库,提取统一时间序列长度的语音数据样本的第一类特征。第一类特征为统计学特征,统计学特征是指无法从语音数据样本中直接输出的数据,需要通过提取模型的输出,从而计算统计值(如均值,标准差等)得到的特征数据。第一类特征为统计学特征,包括语音过零率、均方根能量、频谱质心;步骤13:利用librosa音频处理库,对统一时间序列长度的语音数据样本执行快速傅里叶变换,计算每个频率区间能量,进行离散余弦变换之后,提取得到语音数据样本的第二类特征;所述第二类特征为音频数据特征,包括梅尔频率特征、谱对比度特征、色度频率特征;步骤14:将语音数据样本的第一类特征以矩阵拼接的方式进行部分融合,之后再通过concatenate函数与对应的第二类特征进行特征融合,形成语音数据样本的特征向量。特征向量即多维矩阵,其中存储了情绪特征的数学形式。
23.预处理和特征提取过程,使每个语音数据样本均可得到一对应的特征向量。
24.步骤2:将多个语音数据样本的特征向量均输入神经网络训练模型,进行反复迭代学习后,得到特征模型。
25.神经网络模型包括记忆网络单元、门控循环单元、全连接神经网络单元、优化器、损失函数、超参数等,以序列化形式搭建多层网络。
26.多个语音数据样本的特征向量进入记忆网络单元之后,然后进入门控循环单元,再经过优化器进行优化之后进入全连接神经网络单元,然后经分类器进行分类,输出预测结果。
27.神经网络训练模型反复迭代学习,依据语音数据样本的特征向量中的情绪特征的数学形式得到的预测结果与对应的实际标签之间的预测误差,调整神经网络训练模型的参数。调整神经网络训练模型的参数有损失函数、优化器、超参数,其中损失函数是loss_function;超参数是hyper_para函数,优化器为sigmoid函数。
28.优化器是指在训练过程中,调整参数使得最后输出结果最好,并优化调整参数的时间。损失函数可以衡量优化器最后输出结果的好坏程度。优化器每次将语音数据样本的特征向量迭代之后,会计算出一个结果,利用该结果与实际标签的真实值进行比对,产生的差值由优化器反向传播,逐层调整训练参数,使得下一轮迭代损失值降低。
29.当预测结果与对应的实际标签尽可能的拟合时,迭代学习后的神经网络训练模型即为特征模型。
30.步骤3:将获取的待预测语音数据进行处理,得到待预测语音数据的特征向量,并将其输入至特征模型。
31.待预测语音数据通过预处理和特征提取,得到待预测语音数据的第一类特征和第二类特征,待预测语音数据的第一类特征进行部分融合后,再与第二类特征进行融合,得到待预测语音数据的特征向量。
32.步骤3中待预测语音数据进行预处理和特征提取的过程与语音数据样本预处理和特征提取过程一致。
33.步骤4:特征模型对待预测语音数据的特征向量进行提取,得到统计学概率分布,输出预测标签。
34.特征模型包括记忆网络单元(lstm)、门控循环单元(gru)、全连接神经网络单元(fcn)。记忆网络单元为128维的单层长短期记忆网络单元;门控循环单元为1152维的多层门控循环单元。
35.具体的,步骤4包括以下步骤:如图1所示,步骤40:待预测语音数据的特征向量输入至特征模型的记忆网络单元处理后,进入门控循环单元,使得待预测语音数据的特征向量的情绪特征数据显化;当待预测语音数据的特征向量进入门控循环单元之后,其输出结果由优化器进行接收,之后进入下一步骤;此处,优化器为sigmoid函数。
36.步骤41:显化的情绪特征数据再输入至全连接神经网络单元,进行权重更迭,使得显化的情绪特征数据得到具象,步骤42:使用分类器(softmax函数)归一化情绪特征数据,得到统计学概率分布,扩大结果差距,输出4维预测标签。4维标签为抑郁、双重抑郁、焦虑、正常。
37.在实际应用场景下,如心理诊疗室辅助进行语音情绪识别时,通过具有语音获取功能的硬件设备(麦克风)获得音频数据。通过对音频数据进行预处理,得到该音频数据的第一类特征和第二类特征,然后第一类特征进行部分融合后,再与第二类特征融合,之后输入到特征模型得到情绪分类的结果,来辅助理疗师判断情绪分类。
38.本发明先对第一类特征以特征堆叠的方式进行部分融合,再与第二类特征进行进一步的特征融合,使的语音中的情绪特征数据更为显著,提升了融合与拼接效率。
39.本发明结合了长短期记忆网络与门控循环单元网络,相较单层长短期记忆网络具有明显的准确率提升。同时,使用sigmoid作为激活函数,也对提升预测的准确率有明显帮助。
40.本发明以序列的形式输入,以长短期记忆网络、卷积神经网络等训练模型进行特征训练,训练效果优于支持向量机等其他传统分类模型。
41.以上实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例
对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。