1.本发明属于数字图像处理领域,具体讲,涉及基于深度学习和计算机视觉的事件相机视频重建方法。
背景技术:
2.事件相机是一种生物视网膜视觉启发的新型传感器,工作原理和底层电路设计范式与传统的相机完全不同。事件相机具有高动态范围、高时间分辨率和低功耗的特点,在自动驾驶、无人机视觉导航和安防监控等涉及高速运动或极端光照场景的领域具有广阔的应用空间。
3.相对于强度相机在曝光时间内整个像素平面同步输出像素位置的强度值,事件相机在各个像素位置的数据输出是异步的,并且只输出亮度的相对变化值。由于事件相机的输出并非是人们所正常观测的灰度或彩色图像,将事件相机输出的事件点重建为人们能正常观测的视觉友好图像和视频是事件相机的视觉应用之一。事件的异步触发传输特性决定了它是一种非欧几里得数据,我们难以将现有的图像重建方法直接应用到事件相机的真实图像重建中,因此我们需要针对事件相机的特性研究新的图像和视频重建算法。
4.目前的事件相机图像或视频重建算法主要分为两类:基于传统图像处理的方法和基于深度学习的方法。基于传统图像方法主要是针对事件相机的差分特性进行建模,通过积分或滤波器估计图像上各个像素位置的强度值。基于深度学习的方法取得了比传统图像方法更好的效果。这类方法通常使用convlstm引入对图像强度的长时估计,较好的建模了事件的差分特性。但是,convlstm的引入以及事件的空间稀疏性导致了事件相机的视频重建算法需要几帧到几十帧的初始化时间,即在视频重建初期的几帧到几十帧内,算法重建出的图像质量较差,通常具有较差的纹理细节和全局对比度。
技术实现要素:
5.本发明的目的在于弥补现有技术的不足,在保证视频整体成像质量的前提下,增强视频初期的成像质量,减少初始化时间进而提出了一种基于深度学习的事件相机视频重建方法。
6.为了实现上述目的,本发明采用了如下技术方案:
7.基于深度学习的事件相机视频重建方法,基于深度神经网络,设计了一个由convlstm、时空transformer、时空特征对齐单元和2d/3d卷积等模块组合而成的编码器-解码器深度神经网络,利用多个相邻时间段内(对应于强度相机的多段曝光时间)未对齐时空事件的信息来共同生成一帧灰度图像;具体方法包括以下内容:
8.s1、获取事件并预处理为事件帧;
9.s2、将预处理后的原始尺度事件帧输入共享特征提取模块提取主特征和子特征;
10.s3、将主特征输入特征偏移估计模块,得到相邻帧特征偏移量;
11.s4、将主特征输入convlstm的时空transformer模块进行特征编码和解码;
12.s5、将编码后的主特征根据特征偏移量进行复位,实现特征对齐;
13.s6、将复位后的主特征输入spadenormalization模块;
14.s7、将主特征输入3d cnn模块进行特征解码,同时加入子特征补充损失的信息;
15.s8、将特征下采样为1/2尺度和1/4尺度,获得1/2尺度和1/4尺度下的主特征,同时通过共享特征提取模块提取1/2尺度和1/4尺度事件的子特征,然后重复s3~s7操作;
16.s9、将1/2尺度和1/4尺度解码后的主特征经过pixel shuffle上采样至原尺度后融合得到重建后的图像;
17.s10、将s9中所得的重建结果与原始环境真实图像计算网络的损失函数,进行反向传播。
18.优选地,所述s1中提到的事件预处理具体包括以下内容:选取两帧参考图像之间的事件点堆叠为时空体素网格;对于一段时间
△
t=t
k-t0内包含k个事件的事件流将每个事件点映射到对应的时空体素网格中,公式如下:
[0019][0020]
其中,ti表示第i个事件的时间戳;c表示时空体素网格的通道数;(xi,yi)表示第i个事件的坐标;pi=
±
1,表示事件极性;tn表示时空体素网格的通道索引时间;
[0021]
选取奇数t个相邻时间段内的事件流堆叠为时空体素网格i`∈rb×
t
×c×h×w,t包含中间位置的1个中间帧,和与中间位置相邻的t-1个相邻帧。
[0022]
优选地,所述共享特征提取模块由两个普通卷积层组合而成,四个共享特征提取模块分别提取出原始尺度的主特征、原始尺度的子特征、1/2尺度的子特征和1/4尺度的子特征。
[0023]
优选地,所述特征偏移估计模块应用于真实场景上预训练好的光流估计模型,在网络训练过程中该模块同时进行参数的更新,使该模块经过训练后迁移至特征偏移估计空间,从而实现事件的特征偏移估计。
[0024]
优选地,所述s4具体包括以下内容:
[0025]
s4.1、将提取的主特征应用两个分组卷积分别提取出q值和k值,具体公式如下:
[0026]
q=wq*fmꢀꢀ
(2)
[0027]
k=wk*fmꢀꢀ
(3)
[0028]
其中,*表示卷积操作;
[0029]
s4.2、应用convlstm提取主特征的v值特征,具体公式如下:
[0030][0031]
其中,σ表示sigmoid函数,[
·
,
·
]表示对两个特征进行拼接;
[0032]
s4.3、将提取的q、k和v值展开后依次通过自注意力模块和多层感知机模块进行特征编码,具体公式如下:
[0033][0034]fo
=mlp(sa)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0035]
其中,d表示特征维度;mlp表示含有多个卷积或全连接层的多层感知机。
[0036]
优选地,所述s5中提到的特征对齐具体为:根据s3中得到的相邻帧特征偏移量,将相邻帧对应位置特征复位至与中间帧相对应的位置,实现特征对齐。
[0037]
优选地,所述s6具体包括以下内容:
[0038]
s6.1、对输入的复位后的主特征进行无参数的batchnormalization标准化,具体公式如下:
[0039][0040]
其中,表示均值,表示标准差;
[0041]
s6.2、令上一帧的重建结果为应用卷积ws对主特征进行维度拓展,具体计算公式如下:
[0042][0043]
s6.3、应用卷积w
γ
、w
β
生成主特征标准化的系数和偏置项,具体公式如下:
[0044][0045]
优选地,所述s7具体包括以下内容:将原始输出提取出的子特征与上述输出的特征进行拼接,首先使用一个2d卷积模块进行融合,然后使用若干个3d卷积堆叠成一个模块对特征进行解码,每个3d卷积模块之间使用一个leaky relu进行非线性化,具体公式如下:
[0046][0047]
优选地,所述s9具体包括以下内容:将1/2尺度和1/4尺度下经过s2~s7输出的主特征使用pixel shuffle操作上采样至原始尺度,使用一个convlstm和若干个卷积层将所有主特征进行融合,最终得到重建的灰度图像
[0048]
优选地,将s10中所提到的损失函数包括有l1损失函数、感知损失函数和时间一致性损失函数,将上述三个损失函数的总和作为网络的最终损失,具体公式如下:
[0049][0050]
其中,γ
tc
设置为5;感知损失选择经过imagenet数据集预训练后的vgg-19的前五个隐藏层输出计算l1距离,即取l0=5;每个隐藏层所占权重设置为1,即w
l
=1,=1,表示将前一帧根据特征偏移两对齐至当前帧的结果。
[0051]
与现有技术相比,本发明提供了基于深度学习的事件相机视频重建方法,具备以下有益效果:
[0052]
本发明方法避免了对成像设备硬件上的改变,采用后处理方法,通过多个模块之间的优势互补对事件相机进行视频重建;具体包括以下内容:
[0053]
1、本发明将convlstm对长时依赖较好的建模特性、2d/3d卷积对局部特征较好的聚合性和时空transformer对相邻时段内的中期依赖性和图像内全局信息的建模能力结合到一起,优势互补,将事件重建为符合真实场景的灰度图像。
[0054]
2、本发明实现了事件相机的视频重建,重建出的视频整体上具有较好的效果。
[0055]
3、本发明成像初始化时间较短,初始化期间成像质量较高。
附图说明
[0056]
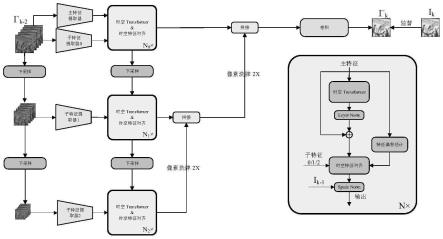
图1为本发明提出的基于深度学习的事件相机视频重建方法的总体流程图;
[0057]
图2为本发明提出的基于深度学习的事件相机视频重建方法的细节流程图;
[0058]
图3为本发明提出的基于深度学习的事件相机视频重建方法重建的视频中,前四帧或五帧图像与其他方法重建结果的对比图,其中1)是henri rebecq等人在发表于2020年ieee transactions on pattern analysis and machine intelligence的论文high speed and high dynamic range video with an event camera中提出方法的重建结果;2)是pablo rodrigo gantier cadena等人在发表于2021年ieee transactions on image processing的论文spade-e2vid:spatially-adaptive denormalization for event-based video reconstruction中提出方法的重建结果;3)是由普通相机拍摄的原始场景的真实图像结果。
具体实施方式
[0059]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0060]
本发明设计了一个嵌入convlstm的时空transformer模块,通过convlstm捕捉整个视频序列周期内的长时依赖性,通过时空transformer捕捉相邻时段内的中期依赖性和图像的全局信息,通过卷积学习图像的局部特征,利用多个模块之间的优势互补完成图像重建工作。具体方法包括以下步骤:
[0061]
实施例1:
[0062]
请参阅图1和图2,本发明具体包含如下步骤:
[0063]
1)构造输入数据:
[0064]
11)采用从苏黎世大学robotics and perception group网站上公开的事件相机实拍数据作为实验数据,使用其中的仿真数据集对网络进行训练和验证,使用其中的真实数据集进行网络性能的测试。仿真数据和真实数据都包含事件相机输出的事件流和对应的原始场景真实图像。
[0065]
12)为了能将深度学习技术应用于事件相机的图像重建之中,首先需要对事件形态的非欧几里得数据进行结构化,本发明使用固定时间段的堆叠方式,通过将一段时间内累计产生的事件点堆叠为事件帧的形式适配深度神经网络的输入形式。具体来说,选取两帧参考图像之间(对应于普通相机的曝光时间)的事件点堆叠为时空体素网格。对于一段时间δt=t
k-t0内包含k个事件的事件流内包含k个事件的事件流我们将每个事件点映射到对应的时空体素网格中,公式如下:
[0066][0067]
其中,ti表示第i个事件的时间戳;c表示时空体素网格的通道数;(xi,yi)表示第i个事件的坐标;pi=
±
1,表示事件极性;tn表示时空体素网格的通道索引时间;本发明选取t个(t为奇数)相邻时间段内的事件流堆叠为时空体素网格i、∈rb×
t
×c×h×w,t包含中间位置的1个中间帧,和与中间位置相邻的t-1个相邻帧。
[0068]
2)我们使用共享特征提取器通过多个共享权重的卷积层将连续帧表示映射到同一个特征空间中。
[0069]
21)首先使用主共享特征提取器在原始尺度对i`提取出主特征用于在后续网络中作为主信息流通。
[0070]
22)随后在三个尺度上分别使用共享特征提取器提取多尺度子特征22)随后在三个尺度上分别使用共享特征提取器提取多尺度子特征用于后续在不同尺度尺度对主信息进行补充。
[0071]
3)将处于同一特征空间内的各时段特征输入特征偏移估计模块,使用在真实场景
上预训练好的光流估计模型,在网络训练过程中该模块同时进行参数的更新,使该模块经过训练后迁移至特征偏移估计空间,从而实现事件的特征偏移估计。
[0072]
4)将提取出的主特征输入嵌入convlstm的时空transformer模块。
[0073]
41)将提取的主特征应用两个分组卷积提取出q值和k值,应用convlstm提取v值,具体公式如下:
[0074]
q=wq*fmꢀꢀ
(2)
[0075]
k=wk*fmꢀꢀ
(3)
[0076][0077]
其中,*表示卷积操作,σ表示sigmoid函数,[
·
,
·
]表示对两个特征进行拼接;
[0078]
42)将提取的q、k和v值展开后依次通过自注意力模块和多层感知机模块,具体公式如下:
[0079][0080]fo
=mlp(sa)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0081]
其中,d表示特征维度;mlp表示含有多个卷积或全连接层的多层感知机。
[0082]
5)
[0083]
51)根据步骤3)得到的相邻帧特征偏移量,将相邻帧对应位置特征复位至与中间帧相对应的位置,实现特征对齐。
[0084]
52)将对齐后的特征输入spade normalization模块,具体是,首先对输入的特征进行无参数的batch normalization标准化,具体公式如下:
[0085][0086]
其中,为均值,为标准差。
[0087]
随后使用上一帧的重建结果,首先应用一个卷积进行维度拓展,再分别应用两个卷积生成上述标准化的系数和偏置项,具体公式如下:
[0088]
[0089][0090]
53)将上述输入的特征输入3d cnn模块,具体是,首先将原始输出提取出的子特征与上述输出的特征进行拼接,首先使用一个2d卷积模块进行融合后,使用若干个3d卷积堆叠成一个模块对特征进行解码,每个3d卷积模块之间还使用了一个leaky relu进行非线性化,具体公式如下:
[0091][0092]
6)将上述步骤得到的输出经过下采样得到不同尺度的特征图后再次进行一系列相同操作。
[0093]
7)将两个低尺度特征图通过像素洗牌操作上采样至原始尺度,使用一个convlstm和若干个2d卷积层对来自不同尺度的特征图进行融合,得到重建的最终结果
[0094]
8)将网络重建的结果与原始环境真实图像计算网络的损失函数。本发明使用l1损失函数、感知损失函数和时间一致性损失函数,三个损失函数的总和作为网络的最终损失。具体公式如下:
[0095][0096]
实施例2:
[0097]
请参阅图1-2,基于实施例1但有所不同之处在于,下面结合附图和具体实例数据详细说明如下:
[0098]
本发明提出了一种基于深度学习的事件相机视频重建方法(如图1和图2的流程所示),设计了一个嵌入convlstm的时空transformer模块,通过convlstm捕捉整个视频序列周期内的长时依赖性,通过时空transformer捕捉相邻时段内的中期依赖性和图像的全局信息,通过卷积学习图像的局部特征,利用多个模块之间的优势互补完成图像重建工作。具体方法包括以下步骤:
[0099]
1)构造输入数据:
[0100]
11)采用从苏黎世大学robotics and perception group网站上公开的事件相机实拍数据作为实验数据,使用其中的仿真数据集对网络进行训练和验证,使用其中的真实数据集进行网络性能的测试。仿真数据和真实数据都包含事件相机输出的事件流和对应的原始场景真实图像。所用训练集共100个视频序列,验证集共25个视频序列;每个训练迭代过程中,对于每个视频序列从中随机取40个片段长度,重建出对应的40帧视频图像;测试用真实数据集使用davis240c事件相机拍摄,分辨率为240
×
180,该相机能输出对齐的场景事
件流和灰度图,选取7个视频序列进行测试。
[0101]
12)为了能将深度学习技术应用于事件相机的图像重建之中,首先需要对事件形态的非欧几里得数据进行结构化,本发明使用固定时间段的堆叠方式,通过将一段时间内累计产生的事件点堆叠为事件帧的形式适配深度神经网络的输入形式。具体来说,选取两帧参考图像之间(对应于普通相机的曝光时间)的事件点堆叠为时空体素网格。对于一段时间δt=t
k-t0内包含k个事件的事件流内包含k个事件的事件流我们将每个事件点映射到对应的时空体素网格中,公式如下:
[0102][0103]
其中,ti表示第i个事件的时间戳,c表示时空体素网格的通道数;(xi,yi)表示第i个事件的坐标;pi=
±
1,表示事件极性;tn表示时空体素网格的通道索引时间;本发明选取t个(t为奇数)相邻时间段内的事件流堆叠为时空体素网格i`∈rb×
t
×c×h×w,t包含中间位置的1个中间帧,和与中间位置相邻的t-1个相邻帧。
[0104]
13)我们选取5个时空体素网格作为网络的输入,每个时空体素网格包含5个通道,设置网络的batch size为2,时空体素网格的分辨率为128
×
128,最终重建出一帧灰度图,即t=5,c=5,b=2,h=w=128,网络的输入i`∈rb×
t
×c×h×w,网络的输出
[0105]
2)我们使用共享特征提取器通过多个共享权重的卷积层将连续帧表示映射到同一个特征空间中。
[0106]
21)首先使用主共享特征提取器在原始尺度对i`提取出主特征用于在后续网络中作为主信息流通,其中cm=64。
[0107]
22)随后在三个尺度上分别使用共享特征提取器提取多尺度子特征22)随后在三个尺度上分别使用共享特征提取器提取多尺度子特征用于后续在不同尺度尺度对主信息进行补充,其中cs=6。
[0108]
3)将处于同一特征空间内的各时段特征输入特征偏移估计模块,使用在真实场景上预训练好的光流估计模型,在网络训练过程中该模块同时进行参数的更新,使该模块经过训练后迁移至特征偏移估计空间,从而实现事件的特征偏移估计。本发明使用spatial pyramid network作为光流估计模型。
[0109]
4)将提取出的主特征输入嵌入convlstm的时空transformer模块。
[0110]
41)将提取的主特征应用两个分组卷积提取出q值和k值,应用convlstm提取v值,具体公式如下:
[0111]
q=wq*fmꢀꢀ
(2)
[0112]
k=wk*fmꢀꢀ
(3)
[0113][0114]
其中,*表示卷积操作,σ表示sigmoid函数,[
·
,
·
]表示对两个特征进行拼接;
[0115]
42)将提取的q、k和v值展开后依次通过自注意力模块和多层感知机模块,具体公式如下:
[0116][0117]fo
=mlp(sa)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0118]
5)后续步骤如下:
[0119]
51)根据步骤3)得到的相邻帧特征偏移量,将相邻帧对应位置特征复位至与中间帧相对应的位置,实现特征对齐。
[0120]
52)将对齐后的特征输入spade normalization模块,具体是,首先对输入的特征进行无参数的batch normalization标准化,具体公式如下:
[0121][0122]
其中,为均值,为标准差。随后使用上一帧的重建结果,首先应用一个卷积进行维度拓展,再分别应用两个卷积生成上述标准化的系数和偏置项,具体公式如下:
[0123][0124][0125]
53)将上述输入的特征输入3d cnn模块,具体是,首先将原始输出提取出的子特征与上述输出的特征进行拼接,首先使用一个2d卷积模块进行融合后,使用若干个3d卷积堆叠成一个模块对特征进行解码,每个3d卷积模块之间还使用了一个leaky relu进行非线性化,具体公式如下:
[0126][0127]
其中,α=0.1。
[0128]
6)将上述步骤得到的输出经过下采样得到不同尺度的特征图后再次进行一系列相同操作。
[0129]
7)将两个低尺度特征图通过像素洗牌操作上采样至原始尺度,使用一个convlstm和若干个2d卷积层对来自不同尺度的特征图进行融合,得到重建的最终结果
[0130]
8)将网络重建的结果与原始环境真实图像计算网络的损失函数。本发明使用l1损失函数、感知损失函数和时间一致性损失函数,三个损失函数的总和作为网络的最终损失。具体公式如下:
[0131][0132]
其中,我们将γ
tc
设置为50,感知损失选择经过imagenet数据集预训练后的vgg-19的前五个隐藏层输出计算l1距离,每个隐藏层所占权重设置为1。
[0133]
9)本发明在深度神经网络训练过程中,初始学习率为0.00002,训练迭代共450次,选择adam优化器优化网络。
[0134]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
