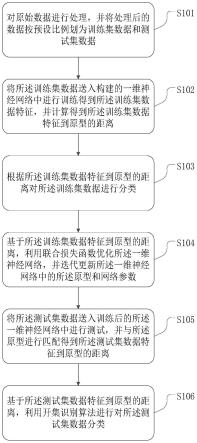
1.本发明涉及一种用于生成用于训练机器学习计算机视觉模型的合成训练数据集的计算机实现方法和系统。
背景技术:
2.人工智能和机器学习可以很快解决许多日常问题。无论是物体检测、物体分类还是训练机器人等等。大量的时间和金钱仅用于数据生成、数据收集和数据准备的过程,这涉及到手动标记数据的过程。硬件(包括摄像头)的可用性或环境因素(如室内灯光或室外天气)等因素也起着重要作用。这需要几天、几周甚至几个月的时间,然后传递给计算机视觉工程师。计算机视觉工程师不断花费数小时来生成和收集大量数据,以创建和训练神经网络。
3.一旦收集到这些数据,计算机视觉工程师就必须编写机器学习算法来训练这些图像。这需要计算机视觉方面的经验和知识来编写这些算法和训练神经网络。这个过程中最大的挑战是时间和精力的消耗,以及编写机器学习算法和训练神经网络的高要求和知识。
4.其目的是尽可能减少这一耗时和繁琐的过程,同时使神经网络的生成和训练过程非常容易,即使对于不具备计算机视觉知识的个人也是如此。因此,需要消耗更少时间和更少人工努力的替代方案,同时使人工智能的工作易于访问和使用,而无需该领域的专门知识。
5.目前市场上的解决方案提供手动标记图像数据。这些解决方案来自一些公司,例如谷歌(检索自《https://cloud.google.com/ai-platform/data-labeling/pricing#labeling_costs》)、scale.ai(检索自《https://scale.com/》)或understand.ai(检索自《https://understand.ai/》)。一些公司还在基于3d数据创建合成数据。例如ai.reverie(检索自《https://aireverie.com/》)或cvedia(检索自《https://www.cvedia.com/》)基于三维虚拟环境创建图像。
6.这些解决方案可以在短时间内创建带标签的图像,但需要建模的3d环境,这也很耗时。此外,unity 3d还宣布创建基于云的解决方案,该解决方案可以获取cad文件并渲染二维图像,这些图像也会被标记(请参见检索自《https://unity.com/de/products/unity-simulation》)。另一方面,英伟达数据集合成器(nvidia dataset synthesizer)是用于虚幻引擎的附加组件(检索自《https://github.com/nvidia/dataset_synthesizer》)。它使用unreal studio渲染cad文件,除rgb图像外,它还能够创建深度图、分割遮罩和其他用于机器学习(ml)应用程序的有用信息。
7.众所周知的训练神经网络的解决方案还包括使用类似谷歌的tensor flow库,这简化了编写神经网络和训练数据的过程。但这仍然需要python等编程语言的知识,若没有这些知识这通常很难使用。对于要用于培训的通用数据集,有相当多的来源提供了密集型数据集,其中包含常用数据的图像和注释,如地理数据、来自kaggle等来源的车辆数据。
8.众所周知的解决方案是手动生成照片和手动进行时间密集型标记,用于训练神经
网络(用于零件检测)。编写用于训练神经网络的算法也是一个耗时费力的过程。有效使用数据还需要计算机视觉和神经网络方面的知识和经验。手动拍摄500张图像需要几个小时,然后再花费几天来手动标记。有一些工具可以帮助标记过程,但这仍然需要手动工作来识别图像中的对象,这不会减少很多所需的时间。包括创建神经网络和/或编写神经网络训练算法在内的训练过程需要花费数周的时间,这是整个过程中需要花费的大量时间和精力。
9.尽管人工生成和单击真实对象的图像并手动标记这些图像这一耗时过程的缺点在某种程度上已被nvidia数据合成器(data synthesizer)等合成数据生成器所克服,但这仍然需要大量的计算机视觉技术知识和经验才能使用。其他构建在unity和unreal等平台上的应用程序也需要用户进行额外安装,了解如何使用这些平台,并熟悉unity/unreal等工具。对于没有使用先验知识可用的用户来说,这些方法并不简单。最终,完成这一过程所花费的时间和精力几乎与多年的教育和学习所需的时间和精力相同。
10.如果不需要先验的知识或技能,最简单的过程就是通过手动单击照片来生成数据。人们通常倾向于用matlab、python等编写自己的标记过程工具,以帮助加快过程。人们还试图安装和学习新的平台,如unity或unreal,它提供了一些库来生成数据。但是,没有一个著名的易于使用的解决方案,用户可以使用非常基本的用户界面来渲染所需的图像和标签数据。
11.根据de 10 2008 057 979 b4,已知用于待分析图像中未知测试对象定位和分类的对象检测系统的学习单元。学习单元包括图像生成单元,用于通过在虚拟背景条件之前通过比较对象的虚拟3d模型生成虚拟3d场景来生成比较对象的训练图像。生成的训练图像的每个像素被分配到虚拟3d场景中的相应3d点。此指定用于选择比较对象特征。
12.根据us 2020/0167161 a1,已知通过增强从3d模型渲染的模拟图像来生成真实深度图像的系统。为此,提供了一种渲染引擎,该引擎被配置为通过渲染关于目标3d cad模型的各种姿势来渲染无噪的2.5d图像。此外,噪声传输引擎配置为将真实噪声应用于无噪声2.5d图像。此外,噪声传递引擎被配置为通过无噪声2.5d图像到目标传感器生成的真实2.5d扫描的第一生成对抗网络,基于映射来学习噪声传递。此外提供了一种背景传输引擎,其被配置为向无噪2.5d图像添加伪现实场景相关背景,并被配置为基于对第一生成对抗网络的输出数据作为输入数据和相应的真实2.5d扫描作为目标数据的处理来学习背景生成。
13.根据us 10489683 b1,已知用于生成用于训练深度学习网络的大型数据集的系统和方法,用于从使用移动设备相机拍摄的图像中提取3d测量。为此,从单个3d基本网格模型(例如,通过单体扫描生成的人体模型)加上例如皮肤增强、面部增强、头发增强和/或多个虚拟背景开始,生成多个数据集。然后从三维模型中提取空间特征作为一维人体测量值。通过聚集空间特征和多个增强的2d图像,训练深度学习网络进行空间特征提取。
技术实现要素:
14.因此,本发明的目的是提供一种用户友好的方法和系统,用于生成用于训练机器学习计算机视觉模型的合成训练数据集(或称为综合训练数据集),以及用于提供经过训练的机器学习计算机视觉模型,这可以加快生成训练数据的过程,并为专业知识或先验知识较少的用户训练一个机器学习计算机视觉模型。
15.上述技术问题通过一种用于生成用于训练机器学习计算机视觉模型的合成训练
数据集的计算机实现方法解决,该机器学习计算机视觉模型用于执行至少一个用户定义的计算机视觉任务,在计算机视觉任务中空间分辨传感器数据针对至少一个用户定义的感兴趣对象被处理和评估,所述方法包括:基于用户输入数据接收用户定义的感兴趣对象的至少一个模型,特别是2d或3d模型;基于用户输入数据确定至少一个渲染参数并且优选地确定多个渲染参数;通过基于至少一个渲染参数渲染感兴趣对象的至少一个模型来生成训练图像集;生成关于至少一个感兴趣对象的训练图像集的注释数据;提供包括训练图像集和注释数据的训练数据集,训练数据集用于输出给用户和/或用于训练计算机视觉模型。
16.一种计算机实现的方法,其用于生成、尤其是自动地生成用于训练机器学习计算机视觉模型的合成训练数据集,该机器学习计算机视觉模型执行至少一个用户定义(尤其是计算机实现)的计算机视觉任务,在该计算机视觉任务中,针对至少一个用户定义的感兴趣对象处理和评估空间分辨率传感器数据,所述方法包括基于用户输入数据(其优选由至少一个用户输入和/或其由系统基于由至少一个用户输入的用户输入数据接收)接收(通过特定的基于处理器的系统,具体在下面一节中描述)至少一个(尤其是2d或3d)用户定义的感兴趣对象的模型。
17.换言之,在至少一个用户定义的计算机视觉任务中,针对至少一个用户定义的感兴趣对象处理和评估空间分辨传感器数据。优选地,提供空间分辨传感器数据以在计算机视觉任务中进行处理和评估。优选地,空间分辨传感器数据由至少一个传感器设备生成,特别是用于环境感知,例如由相机生成。优选地,空间分辨传感器数据是或来自(尤其是二维)图像(优选地由相机拍摄)。优选地,机器学习计算机视觉模型包括训练参数集。
18.优选地,至少一个用户定义和/或打算执行至少一个用户定义的计算机视觉任务,该任务可以是任何计算机视觉任务,例如对象检测、对象分类、分割、异常检测、质量控制(例如在生产设施中)、姿势估计、目标感知任务,检测和/或跟踪手势,和/或机器人或类似物中的计算机视觉任务。
19.该方法还包括(由特定的基于处理器的系统)基于用户输入数据(由用户输入)确定至少一个渲染参数和优选多个渲染参数。
20.根据本发明的方法还包括,尤其是自动地,通过(尤其是自动)基于至少一个渲染参数渲染感兴趣对象的至少一个模型,生成(由特定的基于处理器的系统和/或特定的在计算机实现的方法步骤中)训练图像集(或者说一组训练图像)。优选地,渲染感兴趣对象的至少一个模型以生成感兴趣对象的渲染图像。优选地,训练图像包括渲染图像和(渲染的)背景图像。
21.根据本发明的方法还特别包括(通过基于特定处理器的系统和/或特别是在计算机实现的方法步骤中)自动生成(关于至少一个感兴趣的对象)训练图像集的注释数据。尤其地,为每个训练图像生成注释数据(关于场景中存在的每个感兴趣对象)。特别地,对于场景和/或(训练图像)中存在的每个感兴趣对象,生成(并提供)注释数据。因此,对于场景中存在的每个感兴趣的对象,存在特定的注释数据。
22.根据本发明的方法还包括(特别是自动地)提供(通过基于特定处理器的系统和/或特别是在计算机实现的方法步骤中)训练数据集,该训练数据集包括训练图像和注释数据集,用于输出给用户和/或用于训练计算机视觉模型。优选地,训练数据集用作计算机视觉模型的训练过程的输入(作为训练数据集)。
23.优选地,(生成的)训练数据集(由特定的基于处理器的系统)传输到用户界面,以输出到用户和/或(基于处理器的)机器学习单元,用于训练机器学习计算机视觉模型(用于执行至少一个用户定义的计算机视觉任务)。优选地,用户和/或机器学习单元获取和/或接收(训练)图像和/或(注释)数据(文件),尤其是包含标签、边界框和/或相机参数的数据(文件)。
24.具体而言,该方法涉及用于训练机器学习计算机视觉模型,尤其是用于训练(人工)神经网络的照片级真实的合成数据的生成。
25.与现有技术的传统方法相比,所建议的方法提供了显著的优势,在现有技术中,数据处理通常是时间和精力密集型的,其中通过从不同角度拍摄对象并手动标记对象来手动收集数据花费了大量的时间。此现有技术过程通常需要几周才能成功完成,然后需要几天来测试数据,以便为网络测试过程培训网络。在此之后,仍需对模型进行测试,以检查数据是否足以用于各种用例。如果没有,则需要再次收集数据并重复整个周期,需要最大程度地优化此过程。对于数据科学家来说,收集受保护和保密的数据也很困难,从而使数据收集过程更加困难。
26.相反,所建议的生成合成训练数据的方法有利地提供了现有技术方法的优化。建议的合成数据生成器工具可以实现自动化的数据生成和/或创建过程,只需很少的人力和时间。这有利于在数据生成、培训和测试过程中节省90%以上的时间。
27.优选地,用户定义的感兴趣对象由至少一个用户定义和/或确定(优选地通过,尤其是由至少一个用户输入和/或预设的感兴趣对象的二维或三维模型)。
28.基于用户输入数据接收用户定义的感兴趣对象的至少一个模型,尤其是2d或3d模型,尤其应理解为通过有线和/或无线通信连接或网络接收模型。接收事件可能与(用户)导入和/或生成和/或输入用户输入数据的地方保持本地距离。
29.优选地,用户输入数据是感兴趣对象的至少一个模型的特征。具体而言,模型(尤其是感兴趣对象的三维结构和/或形状)可以(仅)从用户输入数据(无需进一步存储关于模型的数据和/或信息)导出。模型可以由用户输入和/或传输(到系统),例如以cad(计算机辅助设计)格式或类似格式(作为.glb、.gltf、.obj、.stp、.fbx和/或用于虚拟产品开发的其他应用程序的其他数据格式)。优选地,模型的输入格式是灵活的。
30.使用模型作为cad模型进行训练,尤其是生成训练数据集,也有助于实现神经网络或机器学习计算机视觉模型的数据集,这有时很难通过手动摄影获得。
31.就要导入的3d模型的类型而言,该合成数据生成器工具有利地是非常模块化的,并且优选地可以支持多种3d和2d数据类型,从而不限制用户。
32.然而,可以想象的是,该方法包括提供至少一个(2d和/或3d,特别是3d)模型(特别是由系统提供)并且优选地提供多个模型,例如通过访问存储有至少一个模型的存储设备(优选是系统的一部分)。在这种情况下,优选地,用户能够选择(由系统)提供的至少一个模型,优选地,从提供的多个模型(例如,至少三个、优选至少四个、优选至少五个、优选至少十个、优选至少20个模型提供和/或存储在可(由系统)评估的存储设备上)。在这种情况下,通过用户选择所提供的模型中的至少一个来启动基于用户输入数据的用户定义的感兴趣对象的至少一个模型的接收。
33.提供用户可选择的型号提供了优势,用户经常请求的感兴趣的一般对象,例如人
和/或建筑物和/或手(例如,用于检测手势)等,不必由用户构建,但可以选择,从而为用户创建用户定义的训练数据集提供非常高效的方式。
34.在线提供的一些合成数据生成器解决方案非常通用,例如提供标准的公共环境,如道路或机场,用于检测汽车或其他车辆。
35.优选地,基于用户输入数据确定和/或接收(由系统)不同用户定义的感兴趣对象的多个(尤其是2d或3d)模型(尤其是成对的)。这提供了机器学习计算机视觉模型可以针对多个感兴趣的对象进行训练的优点,因此有利地可以模拟具有更多感兴趣对象的更复杂的环境。优选地,感兴趣的对象是物理对象。
36.在优选实施例中,所述方法包括与用户界面通信,其中所述用户界面被配置为用户输入设备,用于用户输入数据,所述用户输入数据是关于所述至少一个模型、所述至少一个渲染参数和优选多个渲染参数、所述要生成的训练图像输入的,生成的训练图像和/或要输出的训练图像的数量,和/或要生成的注释数据(例如,对于给定的感兴趣对象使用哪个标签名称来标记训练图像)。优选地,用户界面是图形界面。优选地,用户输入数据(由用户经由用户输入设备输入)存储在(系统的)存储器设备中,或者存储在(系统可以访问的)存储器设备中。因此,优选地,可以(由用户和/或基于用户经由接口输入的数据)设置标签名称和/或图像计数等。训练数据生成单元被配置为
37.提供易于使用的用户界面(ui)以自动化数据收集过程,有利的是,生成和培训可以在无需任何经验、额外安装依赖项、知识或学位的情况下完成。用户界面非常直观,用户友好。由于ui易于使用,每个人都可以轻松地使用人工智能和/或机器学习计算机视觉模型,而无需专门知识或设置。使用此ui,用户可以使用数据生成、标记和神经网络训练等高级功能,而无需担心后端发生了什么。
38.优选地,用户界面被配置为输出设备,用于向用户输出并尤其显示信息和/或生成的训练数据集。优选地,用户界面被配置为可选地预览训练图像(优选地实时预览),尤其是预览将根据至少一个渲染参数,特别是多个(设置和/或用户定义的)渲染参数(如照明、旋转等)实时渲染的训练图像,尤其是用户当前在用户界面上设置的多个渲染参数。
39.优选地,该方法和/或系统在包括后端组件和/或前端组件的分布式计算系统中实现。例如,后端组件可以是服务器,尤其是外部服务器,可以在其上执行计算机实现的方法。例如,外部服务器是(例如车辆)制造商或服务提供商的后端。后端或外部服务器的功能可以在(外部)服务器场上执行。(外部)服务器可以是分布式系统。外部服务器和/或后端可能基于云。
40.前端组件例如可以是客户端计算机和/或用户终端,如平板电脑或智能手机,具有特定的图形用户界面、用户可以通过其进行交互(与后端组件)的web浏览器和/或传输设备的其他图形用户界面。优选地,后端组件和/或外部服务器可以(尤其安全地)托管在特定(优选地,任选地,用户定义的)区域中,例如在欧盟中。
41.有利的是,用户可以生成复杂的数据集并训练不同类型的对象,而不必担心它在后端如何使用ui。
42.优选地,该方法允许端到端(训练)数据生成。
43.在另一优选实施例中,为了基于用户输入数据确定至少一个渲染参数和优选多个渲染参数,考虑到用户输入数据,随机确定至少一个渲染参数和优选多个渲染参数。
44.使用合成数据生成和训练用户界面,这使过程更容易、更快,只需有限的体力和脑力即可提供大量随机性和多样性的训练数据。如果零件的放置方式不是由相机手动捕捉的,这种随机化也会有所帮助。当使用合成数据来训练网络时,随机化使网络能够了解人类观察不到的情况和环境。这是因为,在应用程序中可以非常快速地生成大量具有所需数据注释的训练数据并进行训练。通过建议的解决方案和用于训练网络(或机器学习计算机视觉模型)的自动化管道(或系统),实现了一键完成数据渲染和训练过程的目标,从而使任何人都能够为各种应用工作和使用人工智能。
45.在以随机方式确定的同时,将渲染参数调整为用户特定设置的组合,有利地导致相对快速且高度随机地生成训练数据,该训练数据被调整为训练数据和/或应执行的计算机视觉任务的用户的预期用途。
46.优选地,用户可以为至少一个渲染参数、优选地为至少两个渲染参数设置至少一个且优选地至少两个边界值(并且优选地,系统提供该边界值以接收关于用户设置的用户输入数据),优选用于多个渲染参数,尤其优选用于所有渲染参数。优选地,该方法包括分别考虑至少一个(用户集)边界值来确定至少一个参数的随机值。优选地,该方法包括在由用户设置和/或确定的至少一个边界值和/或由用户设置和/或确定的至少两个边界值定义的范围内确定随机值。
47.更优选地,该方法包括(和/或系统被配置为提供)改变至少一个渲染参数,并且优选地改变多个渲染参数,这些参数涉及(感兴趣对象的)旋转和/或(感兴趣对象的)位置和/或背景和/或照明(用于生成训练图像和/或注释数据).优选地,(在计算机实现的方法步骤中),至少一个渲染参数和优选地多个渲染参数基于用户输入数据,特别是基于边界值(具体由用户设置)而变化。这有利地提供了旋转、位置、背景、照明是变化的(在计算机实现的方法步骤中和/或由特定的基于处理器的系统)并且尤其依赖于设置的渲染参数的优点。优选地,多个渲染参数是可变的(尤其是在计算机实现的方法步骤中和/或通过特定的基于处理器的系统)。
48.优选地,用户界面指示和/或输出和/或显示和/或可视化可由用户输入数据确定的至少一个渲染参数和优选所有渲染参数的预设(边界)值。
49.优选地,通信包括交换数据(接收数据和/或发送数据),尤其是通过有线和/或无线和/或优选通过加密通信连接,优选地,为了向用户界面(和/或用户输入设备提供数据)和/或从用户界面和/或用户输入设备接收(用户输入)数据。
50.更优选地,该方法提供用户界面和/或通信连接和/或通信方法(用于在用户界面和/或用户与系统和/或训练数据生成单元之间交换数据),以安全地导入和/或上传(尤其是)3d模型(至少一个感兴趣的对象)或cad数据(由用户,尤其是通过用户界面)。
51.优选地,该方法(和/或系统)提供用户界面和/或通信连接和/或通信方法(用于在用户界面和/或用户与系统和/或训练数据生成单元之间交换数据),用于生成的训练数据集的安全输出。有利的是,该方法提供(a)训练数据(集)的安全生成,特别是针对神经网络。
52.在一种优选的实施方式中,为了生成训练图像集,基于用户输入数据确定至少一个背景图像和优选多个(自定义)背景图像。这提供了一个优势,即用户可以更精确地将训练数据的生成适应于一个环境,在该环境中,可以拍摄本地解析的传感器数据,这些数据输入到(预期的)计算机视觉任务中,该任务将由机器学习计算机视觉模型执行。例如,如果计
算机视觉任务是监视室内区域,则用户可以导入至少一个或多个室内图像。因此,机器学习计算机视觉模型的训练通过将背景图像近似为真实背景来优化,真实背景是为执行(预期的)计算机视觉任务而拍摄的局部分辨率传感器数据的一部分。
53.在另一种优选的实施方式中,基于用户输入数据接收至少一个(自定义)背景图像,尤其是多个(自定义)背景图像,其中至少一个背景图像用于生成至少一个训练图像。优选地,该方法包括为用户提供添加和/或上载和/或导入至少一个且优选多个(自定义)图像的可能性,这些图像尤其优选地用作生成训练图像的背景图像。
54.换言之,优选地,用户可以上传自己的背景图像,也可以上传特定环境下的背景图像,例如工厂或道路或纯白色墙壁。这些环境可以是二维和/或三维数据。
55.优选地,用户界面包括交互元件,其允许用户导入和/或添加至少一个背景图像和/或三维环境数据,并且优选多个背景图像。优选地,由用户导入和/或添加的背景图像存储在存储器设备和/或后端服务器中。优选地,可以基于背景图像和/或基于渲染三维环境数据生成训练图像(尤其是生成训练图像的背景部分)。
56.在另一优选实施例中,为了生成训练图像集,从多个背景图像中(尤其是随机地)选择背景图像集(或者说一组背景图像)。优选地,背景图像集是基于用户输入数据和/或用户添加和/或导入的背景图像的集合,尤其是用户定义的、(自定义)背景图像集。
57.优选地,该方法包括提供多个,尤其是独立于用户的(默认)背景图像,这些背景图像存储在(系统的)存储设备上和/或可由系统访问。这提供了一个优点,即用户可以启动(尤其是自动)生成训练数据集,而无需提供和/或上传所需的图像。优选地,基于多个(默认)背景图像选择随机选择的训练图像集。
58.优选地,用户可以(通过用户界面)选择(随机)选择的背景图像集是否是从特定用户定义的、(自定义)背景图像集(由用户上传和/或导入)和/或特定用户独立的背景图像集中选择的,(默认)背景图像(由系统提供)。
59.优选地,使用5个以上、优选10个以上、优选100个以上、优选500个以上、优选800个以上、优选1000个以上和特别优选2000个以上背景图像的集合来生成训练图像。优选地,提供超过2000个的随机集,尤其是独立于用户的,(自定义)背景图像。
60.优选地,至少一个(自定义和/或默认)背景图像用于生成一个以上、优选两个以上、优选5个以上、优选20个以上、优选100个以上的训练图像。例如,如果渲染的训练图像多于提供的背景图像,则可以重复使用给定的背景图像。
61.优选地,在渲染(训练)图像中使用用户定义(自定义)背景图像和用户独立(默认)背景图像。这种变化使得训练数据集更加多样化,因此,经过训练的机器学习计算机视觉模型对于不同的背景更加鲁棒。
62.然而,也可以想象,仅使用一个背景图像来基于该背景图像生成所有训练图像。例如,如果(预期)使用发生在背景始终为黑色的环境中,则只需要一个(黑色)背景图像。
63.优选地,用户指示和/或设置用于生成训练图像的(不同)背景图像的数量。这允许根据用户特定的应用程序调整培训数据集。
64.在另一优选实施例中,基于照片级真实感的背景图像生成每个训练图像。优选地,仅使用照片级真实感的背景图像。这提供的优势在于,生成的训练图像更接近真实(也即照片级真实感)。这将有助于模式的领域适应(从虚拟到现实)。
65.在另一个优选实施例中,从一组渲染参数中选择至少一个渲染参数,该组渲染参数是感兴趣对象的视图、尤其是用于渲染过程的相机的视野、感兴趣对象的大小和/或缩放范围的特征,对于训练图像中至少一个感兴趣渲染对象的方向和/或位置,对于视角,对于渲染模型的滚动和/或对于至少一个感兴趣对象的旋转和/或平移,对于至少一个感兴趣对象的裁剪,对于感兴趣对象的遮挡,和/或多个模型实例和/或类似实例和/或其组合。
66.这提供了一个优势,即模型和视图可以非常接近预期的用户特定训练任务(以及传感器设备拍摄的环境,以生成局部解析的训练图像)。例如,通过设置图像中渲染的模型实例数,可以非常精确地对环境进行建模。例如,如果拥挤市场的环境与(用户预期的)由经过训练的机器学习计算机视觉模型执行的计算机视觉任务有关,则如果在图像中渲染多个人体模型,则训练结果可能更接近现实。
67.优选地,用户可以设置和/或修改一个以上、优选两个以上、优选5个以上、优选10个以上、尤其优选所有上述渲染参数(以生成训练图像)。
68.尤其是“视野”为渲染图像设置摄影机的视野(例如以度为单位)。特别是,提供了缩放参数来调整渲染对象时离摄影机的距离。优选地,用户界面可以显示缩放范围滑块,以便可视化当前设置的缩放范围。
69.优选地,视角可以由用户控制(尤其是在0-360
°
之间)。视角为零尤其意味着渲染图像的视角始终固定在面向相机的一侧,而视角为360
°
则意味着图像是从对象周围渲染的。这有利地提供了将感兴趣对象的至少三维模型(由用户定义)相对于相机(基于其渲染图像)的方向调整为现实中发生的感兴趣对象的方向的可能性(关于拍摄本地解析传感器数据的传感器设备)。因此,可以以更精确的方式对计算机视觉任务的用户特定应用进行建模。
70.优选地,可以(由用户)特别通过用户界面控制(渲染模型的)滚动和滚动角度。
71.优选地,可以(由用户)特别通过用户界面来控制(由用户)裁剪参数,该裁剪参数是图像中渲染的模型百分比的特征。优选地,在0和设置的裁剪值之间(随机)选择裁剪百分比(用于渲染模型)。
72.优选地,可以(由用户)特别通过ui来确定(由用户)用于在渲染图像中引入遮挡效果的特征性遮挡参数。
73.能够使用室内和室外环境的照明和其他环境条件以及许多其他参数设置渲染环境,因此不受天气条件的影响。
74.在另一个优选实施例中,从一组渲染参数中选择至少一个渲染参数,该组渲染参数包括:有关干扰对象的数量、尤其是最大数量的参数特征;有关训练图像的照明条件的参数特征;有关训练图像中对象和/或背景的照明的参数特征;有关对于光源数量的参数特征;有关光强度的变化的参数特征;有关颜色的变化的参数特征;有关包含阴影、模糊和/或噪声、尤其是对于渲染图像和/或训练图像中的噪声强度(和/或噪声强度变化)和/或噪声大小(和/或噪声大小变化)的参数特征,以及类似和/或其组合。
75.在另一优选实施例中,至少一个干扰对象(尤其是从多个干扰对象中随机选择的)包括在至少一个训练图像中,并且优选多个训练图像中。优选地,对于每一代训练图像,确定随机数量的干扰对象(介于0和最大值之间,该值尤其是由用户设置的或可以由用户设置的),并且渲染(在训练图像中)确定的随机数量的干扰对象。特别是,不会针对任何这些分
散注意力的对象生成注释数据。这样做的好处是,在机器学习计算机视觉模型的训练过程中,该模型学习关注至少一个感兴趣对象的细节(而不是随机出现的干扰对象)。
76.优选地,用户界面包含多个选项,优选许多(或多个)选项,用于随机化渲染参数,例如处理遮挡参数、添加干扰对象、自定义背景。
77.优选地,渲染随机数目的光源(在1和最大值之间,尤其是可调节和/或由用户设置的)。
78.优选地,用户可以改变和/或调整和/或控制至少一个感兴趣对象和/或背景图像和/或背景场景的照明条件,以照明至少一个感兴趣对象和/或训练图像的背景。
79.优选地,可以在训练图像中引入由用户通过设置最大百分比来控制的光强度的特定随机变化。
80.优选地,引入渲染图像中介于0和百分比(由用户设置)之间的噪声的特定随机变化。
81.在另一优选实施例中,确定作为用户定义的感兴趣对象的纹理特征的至少一个纹理参数,并且基于所确定的至少一个纹理参数来调整要包括在至少一个训练图像中的至少一个干扰对象的(尤其是纹理)。尤其是,将至少一个干扰对象的视觉外观调整为至少一个感兴趣对象的视觉外观和/或感兴趣对象的(渲染)模型。
82.这样做的好处是,在机器学习计算机视觉模型的训练过程中,计算机视觉模型更关注感兴趣对象的形状和/或大小。这有利地使计算机视觉任务的结果更加准确。
83.优选地,生成的(训练)图像包括渲染图像和/或分割贴图和/或uvw贴图。
84.优选地,注释数据(可以是每个(训练)图像的注释xml文件)可以包括从一组参数中选择的至少一个参数,这些参数包括边界框、相机参数、视野(fov)、6dof值(6个自由度值)、图像标签等和组合。
85.优选地,用户可以导入一个或多个三维模型(在应用中),尤其是通过用户界面,并单独控制每个模型,尤其是在用户需要和/或希望的情况下。
86.优选地,基于用户输入数据生成注释数据。例如,用户可以通过输入用户数据来确定是否应由系统执行分割和/或是否应输出分割图(尤其是通过用户界面向用户)。
87.本发明还涉及一种计算机实现的方法,用于(尤其是自动地)训练机器学习计算机视觉模型以执行至少一个用户定义的计算机视觉任务,其中,由至少一个传感器设备生成的空间分辨传感器数据、尤其用于(尤其室内和/或室外的)环境感知、针对至少一个用户定义的感兴趣对象被处理和评估,其中机器学习计算机视觉模型包括一组可训练参数。
88.根据本发明,用于训练机器学习计算机视觉模型的方法包括根据上述方法生成训练数据集(用于生成用于训练机器学习计算机视觉模型以执行至少一个用户定义的计算机视觉任务的合成训练数据集)(和/或优选所述优选实施例之一)和/或接收由上述方法生成的训练数据集(用于生成用于训练机器学习计算机视觉模型以执行至少一个用户定义的计算机视觉任务的合成训练数据集)(和/或优选所述优选实施例之一)。优选地,该方法包括基于训练数据集训练机器学习计算机视觉模型。
89.优选地,用于训练的方法包括接收和/或获取(训练)图像和/或(训练)数据文件,这些文件包括和/或包含标签和/或边界框和/或相机参数(尤其用于自动渲染图像)。
90.优选地,机器学习计算机视觉模型的训练包括确定一组可训练参数(尤其是在每
个后续训练步骤中)的(每个)可训练参数的值,其中,这些值(优选所有可训练参数的值)基于设定的训练数据(由训练数据生成单元生成)确定。
91.可以想象的是,机器学习计算机视觉模型的类型是基于用户输入的数据来选择的,这些数据与将由机器学习计算机视觉模型执行的计算机视觉任务有关。
92.优选地,可以提供至少一个(预先编写的)特定于用例的机器学习计算机视觉模型,尤其是神经网络,以供选择,尤其是通过单击ui。
93.在优选实施例中,基于用户输入数据确定至少一个用户特定使用参数,其中至少一个使用参数是用户定义的计算机视觉任务的特征,其中机器学习计算机视觉模型基于用户特定使用参数确定。
94.优选地,机器学习计算机视觉模型被设计为(人工)神经网络。优选地,(人工)神经网络被设计为深度人工神经网络,尤其是其中可参数化处理链具有多个处理层。
95.优选地,(人工)神经网络被设计为卷积神经网络(cnn)和/或递归神经网络(rnn)和/或(快速)rcnn(递归卷积神经网络)。
96.优选地,生成大于1000、优选地大于1400、优选地至少1500个、尤其优选地大于2000训练图像和注释数据,并且尤其用于训练机器学习计算机视觉模型。
97.优选地,真实图像(由相机拍摄)和合成生成的训练图像的混合用于训练机器学习计算机视觉模型。优选地,至少800幅图像(包括真实图像和合成训练图像的混合)用于训练机器学习计算机视觉模型。
98.优选地,该方法提供自动结果评估。
99.在另一优选实施例中,该方法(用于训练机器学习计算机视觉模型以执行至少一个用户定义的计算机视觉任务)包括评估使用所提供的训练数据集训练的计算机实现的视觉模型,并确定作为计算机实现的视觉精度特征的评估参数模型
100.优选地,为了确定评估参数,测量机器学习计算机视觉模型(尤其是神经网络)的输出(对于给定参数化)与地面真值(基于生成的注释数据)的偏差(所谓的损失)。优选地,所使用的损失函数的选择方式使得参数以可微的方式依赖于它。作为优化过程的一部分,神经网络的参数在每个训练步骤中根据损失的导数进行调整(根据几个示例确定),以使损失最小化。这些训练步骤频繁重复,直到损失不再减少。
101.在另一优选实施例中,该方法(用于训练机器学习计算机视觉模型以执行至少一个用户定义的计算机视觉任务)包括根据评估参数生成和提供另一组训练数据。特别地,根据评估参数重新生成训练数据。优选地,将评估参数与预设精度值和/或可由用户设置的精度值进行比较。
102.优选地,机器学习计算机视觉模型的训练(因此)在闭环中执行(尤其是直到作为评估参数的机器学习计算机视觉模型的精度。
103.该目标还可由用于生成用于训练机器学习计算机视觉模型以执行至少一个用户定义的计算机视觉任务的合成训练数据集的、特别是基于处理器的系统来实现,其中,特别针对至少一个用户定义的感兴趣对象来处理和评估空间分辨率的传感器数据,该系统包括训练数据生成单元,其被配置为通过基于至少一个渲染参数来渲染感兴趣对象的至少一个模型、特别是2d或3d模型来生成训练图像集,并针对至少一个感兴趣对象为训练图像集生成注释数据。
104.根据本发明,训练数据生成单元被配置为基于用户输入数据接收感兴趣对象和/或(特别是用户定义的)感兴趣对象的至少一个(特别是2d或3d)模型。
105.优选地,训练数据生成单元被配置为使用基于用户输入数据接收的感兴趣对象的模型来渲染感兴趣对象的至少一个,尤其是2d或3d模型(以生成训练图像集)和/或生成用于训练图像集的注释数据。优选地,训练数据生成单元被配置为使用基于用户输入数据接收的感兴趣对象的模型来生成合成训练数据集。具体而言,机器学习计算机视觉模型处理和评估空间分辨传感器数据所涉及的感兴趣对象对应于和/或是训练数据生成单元基于用户输入数据接收感兴趣对象模型的对象。
106.具体而言,用于生成合成训练数据集的系统和/或训练数据生成单元被配置为针对(由训练数据生成单元)接收的(感兴趣对象的模型)生成合成训练数据集(尤其是训练图像和/或注释数据集)。用户定义的计算机视觉任务尤其是(至少也是)用户定义的,因为机器学习计算机视觉模型是使用合成训练数据集训练的,该合成训练数据集是由训练数据生成单元基于训练数据生成单元接收到的感兴趣对象的模型生成的。
107.此外,训练数据生成单元被配置为基于用户输入数据确定至少一个渲染参数和优选多个渲染参数,其中,训练数据生成单元被配置为提供训练数据集,该训练数据集包括训练图像集和注释数据集,用于输出给用户和/或用于训练计算机视觉模型。
108.优选地,系统被配置、适合于和/或旨在在生成用于单独或彼此组合训练机器学习计算机视觉模型的合成训练数据集的方法的上下文中执行上述方法步骤和/或在用于训练计算机视觉模型的方法的上下文中执行上述方法步骤机器学习计算机视觉模型,单独或相互结合。相反,可以为这些方法提供在系统上下文中单独或彼此组合描述的所有特征。此外,在上述方法的上下文中提及的(尤其是基于处理器的)系统可以单独地或彼此组合地具有在系统的上下文中描述的所有特征。
109.优选地,训练数据生成单元被配置、适合于和/或在生成用于单独或彼此组合地训练机器学习计算机视觉模型的合成训练数据集的方法的上下文中执行上述方法步骤。相反,该方法,尤其是在使用该方法的上下文中描述的训练数据生成单元,可以单独地或彼此组合地提供在训练数据生成单元的上下文中描述的所有特征。
110.优选地,该系统包括用于提供用户交互的装置和/或用于提供用户交互的设备。例如,系统可以包括用于提供用户界面的设备(例如,允许与可能是系统的一部分或可能由用户终端提供的用户界面进行通信)。
111.优选地,系统包括,尤其是用户界面,包括和/或提供可由用户操作的交互元件。优选地,通过操作交互元件和/或通过用户界面输入数据,用户可以启动和/或触发(合成)训练数据集的自动生成和/或机器学习计算机视觉模型的自动训练(尤其是通过点击和/或至少一次点击和/或一次点击)。
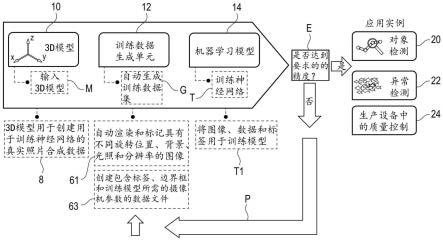
112.优选地,系统包括存储感兴趣对象的至少一个模型以及感兴趣对象的多个模型和/或(默认和/或自定义)背景图像的存储设备,以生成和/或生成训练图像。优选地,该系统包括存储所生成的训练图像和/或注释数据的存储设备。
113.根据本发明,还建议系统能够生成用于对象检测、分类或分割的不同类型用例的数据。因此,不限制用户,并通过使用ui的一个工具提供更大的灵活性。
114.该系统的优点是提供了一个易于使用的界面和用于计算机视觉的合成训练数据
生成系统。它是一个集成解决方案,具有前端用户界面和计算机视觉平台,可在闭环中生成端到端数据和进行培训。该系统允许导入一个或多个3d或2d数据,这些数据可用于在很短的时间内以最小的工作量呈现您喜欢的图像,并且还可以针对对象分类、检测或分割领域的各种用例对这些数据进行培训。该系统简单易用的直观ui使用户能够生成和训练数据,而无需事先了解数据生成。这些数据进一步传递到计算机视觉平台,用户只需单击一下即可继续训练神经网络。用户可以使用用户界面触发整个数据生成和培训过程。
115.该系统,尤其是训练数据生成单元和/或机器学习单元和/或合成数据生成器ui可用于任何类型的行业,如计算机视觉、汽车、航空航天、运输、生产、机器人、医疗、电子、制造、农业、通信、教育、制药、,食品行业、医疗保健、娱乐等。由于用户可以使用任何类型的数据,此合成数据生成器工具ui不会将用户限制在任何特定行业,因此非常灵活。
116.本发明进一步涉及一种计算机程序或计算机程序产品,包括程序装置,尤其是程序代码,其至少表示或编码根据本发明和优选所述优选实施例之一的两种计算机实现的方法(用于生成合成训练数据集的方法和用于训练机器学习计算机视觉模型的方法)中的每一种的方法步骤,并设计用于由处理器执行装置
117.本发明还涉及一种数据存储器,其中存储了根据本发明的计算机程序或计算机程序的优选实施例的至少一个实施例。
附图说明
118.以下将参考附图以示例的方式描述本发明的其他优点、目标和特征。在附图中,不同实施例中的类似组件可以显示相同的附图标记。
119.在附图中示出:
120.图1是根据本发明实施例的用于生成用于训练机器学习计算机视觉模型的合成训练数据集的方法和用于训练机器学习计算机视觉模型的方法的示意图;
121.图2是根据本发明实施例的系统的用户界面和/或用户界面的示意图;和
122.图3-6根据图2的具有不同用户设置的用户界面。
具体实施方式
123.图1示出了根据本发明实施例的用于生成用于训练机器学习计算机视觉模型的合成训练数据集的方法和用于训练机器学习计算机视觉模型的方法的示意图。
124.附图标记m表示方法的(尤其是第一)步骤,在该步骤中,尤其是将模型10导入(尤其是基于处理器的)系统和/或训练数据生成单元12。用户可以例如导入一个或多个3d模型8,以(由系统和/或训练数据生成单元12)用于创建尤其是真实照片的合成数据,用于训练机器学习计算机视觉模型,在此是神经网络。
125.优选地,用户可以导入至少一个(3d)模型,优选地导入所有(3d)模型,这些模型将用于生成(照片级真实感)合成数据,用于使用用户界面(ui)训练机器学习计算机视觉模型,可以提供(特别是由系统和/或训练数据生成单元12提供)用于与用户交互。
126.训练数据生成单元12接收用户输入数据(或从用户输入数据导出的数据),尤其是(导入的)(3d)模型,最好是用户导入的所有(3d)模型,这些模型将用于生成(照片级真实感的)合成数据,用于训练机器学习计算机视觉模型。
127.训练数据生成单元12被配置并用于自动生成训练数据集,如图1中的附图标记g所示。
128.对于训练数据集的自动生成(由附图标记g表示),图像被自动渲染和标记,特别是具有不同的旋转、位置、背景、照明和/或分辨率(特别是由训练数据生成单元12和/或系统)。该步骤由图1中的附图标记61表示。
129.在由附图标记63表示的方法步骤中,创建包含训练机器学习(计算机视觉)模型所需的标签、边界框和/或相机参数的数据文件(特别是由训练数据生成单元12和/或系统)。
130.附图标记14表示机器学习单元(可能是系统的一部分)。该方法可以包括将(自动)生成的训练数据集发送到机器学习单元14和/或计算机视觉平台。在此,训练数据集优选用于训练机器学习(计算机视觉)模型,例如,通过训练一个或多个神经网络(由附图标记t表示)。优选地,训练数据包括(通过渲染和/或标记)生成的图像(参见步骤61),尤其是注释数据和/或包含标签、边界框和/或相机参数的数据文件(参见步骤63)。
131.对于训练神经网络的步骤t,特别是(特别是自动生成的)图像、(注释)数据和标签用于训练(机器学习计算机视觉)模型,由附图标记t1表示。
132.优选地,提供(机器学习模型的训练过程的)自动评估结果,以检查是否已达到期望和/或所需的精度(特别是由系统和/或评估单元e)。如果没有,则最好自动重新生成数据(见箭头p)并进行训练(由系统和/或机器学习单元14),直到用户在训练过程中获得所需的精度和输出,从而以最少的计算机视觉知识和干预来支持闭式循环。
133.只要达到所需的精度,经过训练的机器学习模型就可以用于各种用例,例如,目标检测20、(智能)机器人、异常检测22和/或生产设施中的质量控制24。
134.优选地,该系统的主要特征是:
[0135]-导入一个或多个2d图像和/或3d模型(最好使用ui)
[0136]-使用系统ui以生成图像和注释数据
[0137]-将生成的数据发送到计算机视觉平台(和/或机器学习单元14)
[0138]-在计算机视觉平台(和/或机器学习单元14)上训练数据
[0139]-自动结果评估
[0140]-如果精度不是最佳的,则重新生成数据,从而为数据生成和培训提供自动闭环,几乎不需要人工干预或计算机视觉知识。
[0141]
图2示出了根据本发明实施例的系统的和/或系统的用户界面30的示意图。具体而言,图2示出了用于与用户交互的易于使用的直观用户界面的示例(用于生成用于训练机器学习(计算机视觉)模型和/或系统的合成训练数据集的方法的示例)。
[0142]
该系统可以包括(基于处理器的)装置和/或(基于处理器的)设备,用于提供用户界面30。用于提供用户界面30的装置和/或设备优选地被配置为分别与至少一个用户界面30(并且优选地与多个用户界面30)通信,尤其是与用户界面30交换数据。通信优选地包括接收用户输入数据和发送用户输入数据(或从用户输入数据导出的数据),这些数据由用户经由用户接口30输入,至训练数据生成单元12和/或将训练数据生成单元12提供的数据和/或来自训练数据生成单元12的数据发送至至少一个用户界面30。
[0143]
用户界面30为用户提供了与系统交互的可能性(参见附图标记32),以便最好除其他外,导入感兴趣对象(由用户定义)的模型10。用户界面30可以包括输出设备,例如作为
(视觉)显示器的光学输出设备,其提供交互元件和/或输入元素,例如图形对象,(在图2中,例如附图标记32、34、36、38,其可设计为按钮等),用户可借助其进行输入和/或输入用户输入数据,所述输入和/或输入用户输入数据优选地(通过用户界面)传输到系统和/或机器学习单元14。
[0144]
具体而言,用户界面30提供交互元件32,通过该交互元件,用户可以在应用中导入一个或多个(3d)模型。此外,用户界面还提供了交互元件,用户可以根据需要单独控制每个模型。
[0145]
此外,图2所示的用户界面30提供了一个交互元件34,该交互元件允许在渲染之前预览图像,以及一个交互元件36,通过该交互元件,用户可以将模型重新居中(相对于图像的边缘),以及交互元件38,用于清除显示给用户的场景(例如,包括用户定义模型和/或用户定义模型的渲染图像和/或背景图像)。
[0146]
此外,用户界面30优选地被配置为在渲染之前提供导入模型和/或图像的预览和/或视图,和/或由系统和/或训练数据生成单元12生成的渲染图像和/或训练图像i1的预览。
[0147]
此合成数据生成应用程序还可以预览图像,其将使用用户当前在ui上设置的渲染设置(如照明、旋转等)被实时渲染。
[0148]
图2所示的用户界面30作为示例示出了基于用户定义对象的模型10生成的训练图像i1,在这种情况下,该模型10是汽车,其中尤其是模型10是由用户导入的。训练图像i1包括汽车模型的渲染图像11和(尤其是)渲染背景图像(11a-11c)。在此,背景图像在背景图像11b的下部描绘了将感兴趣的对象(在此是汽车)放置在其上的平面,并且在背景图像11c的上部描绘了背景图像的背景部分。
[0149]
优选地,基于渲染参数渲染感兴趣的对象(在此是汽车)以及背景图像。渲染参数可以控制训练图像的照明条件,该训练图像可以从渲染模型11的阴影和较亮部分以及背景图像11b中汽车的阴影11a中看到。
[0150]
附图标记40表示由用户界面30提供的用户交互部分,通过该部分,用户可以控制增强,和/或通过该部分,用户可以控制系统和/或训练数据生成单元12提供的训练数据和/或输出的生成。
[0151]
例如,对于增强,渲染参数可由用户设置(和/或重置),其由附图标记42表示。
[0152]
渲染参数包括不同的选项,例如实例数量、视野56、裁剪64(参见例如图3)、遮挡66(参见例如图3)、添加干扰对象68(参见例如图3)、调整照明条件72、后处理参数80(例如图像中的色调82)(参见例如图5)、噪声强度(变化)86、,图像中的噪声大小(变化)88、图像中的模糊84(参见例如图5)、2000多个背景图像的随机集90(参见例如图5)以及添加自定义图像的可能性。
[0153]
还有一种可能性是引入随机干扰合成对象(random distraction synthetic objects),其具有与焦点中导入对象相似的纹理。这使得神经网络的训练更加鲁棒。要控制渲染图像中模型旋转的随机性,以用于特定用例,如仅需要汽车前部的图像时,也可以针对导入到ui中的每个单独模型进行控制。
[0154]
图2说明,在此,用户界面30为用户可视化交互元件,以便控制模型设置50。例如,用户可以输入参数52“最大实例计数”的值,并由此设置最大值,该最大值给出所选择的随机数量的模型实例的上边界值。设置参数“max instance count”会导致渲染介于1和设置
的最大值之间的随机数的模型实例。
[0155]
此外,为了增强,用户可以针对视图随机化54和/或干扰对象和/或灯光和/或后处理和/或背景设置参数。
[0156]
在设置渲染参数时,还有一个输出部分可用于输入需要渲染的图像数量、所需的图像分辨率和数据标签。还可以选择生成分割图像和uvw贴图,这有助于机器人技术和姿势估计等应用。
[0157]
此外,用户界面30提供交互和/或输入元素,通过该交互和/或输入元素,用户可以控制和/或设置和/或输入图像计数。这由附图标记44表示。
[0158]
附图标记46表示交互元件,通过该交互元件,用户可以添加标签,尤其可以输入表达式或符号或名称,该表达式或符号或名称应用作标签(对于给定和/或特定感兴趣的对象)。
[0159]
此外,图2所示的用户界面30提供交互元件和/或输入元素48,允许用户启动(由系统和/或训练数据生成单元12)渲染图像(自动)。
[0160]
在生成图像和注释文件之后,该数据被传递到计算机视觉平台,在该平台上,用户可以使用ui从各种应用中进行选择,例如检测、分割、分类等(和/或将数据传递到机器学习单元14)。这可以通过一个简单的下拉菜单完成,然后开始培训,这使得即使是非技术人员也可以使用合成数据生成器工具ui以最短的时间和最小的努力轻松地生成数据、标记数据和开始培训。
[0161]
图3-6显示了图2中具有不同用户设置的用户界面30,例如,对于不同的感兴趣对象和/或用户设置的不同(渲染)参数。相同的附图标记是指技术上相同或具有相同效果的元素。
[0162]
图3示出了由系统(和/或用于提供用户界面的装置和/或设备)提供的特征,如果用户想要仅从特定角度捕捉对象进行训练,则该特征提供了(对于用户)控制渲染图像i2中模型的滚动和俯仰的可能性。
[0163]
在此,对于感兴趣的对象,使用具有十字形的三维对象。附图标记13表示该感兴趣对象的渲染模型。在此,3个光源由用户设置(参见附图标记74),其强度变化为25%(参见附图标记75)。这些选择的照明条件导致背景部分13b中的阴影13a和上部背景部分13c中的亮度变化。
[0164]
从图3与图4的比较中可以看出,其中渲染相同的模型,但渲染参数不同,缩放参数58根据图3所示的用户设置被设置为90-100%的范围,而缩放参数58根据图4所示的用户界面30中所示的用户设置,设置为不同的范围51
–
57%。
[0165]
在此,给定的缩放值定义了对象渲染离摄影机有多近。如果渲染图像中需要较小尺寸的模型,请缩小缩放范围。特别是,最大缩放范围为90-100%是可能的。
[0166]
此外,从图3和图4的比较可以看出,在图3的用户界面30中输入的用户设置中,与图4中5
°
的滚动角62相比,滚动角62在图3的设置中的值大360
°
,而图3(23
°
)中视角60的输入值小于图4(43
°
)。
[0167]
滚动角度62的用户输入允许用户在0到360
°
之间控制渲染模型的滚动。
[0168]
优选地,视角60可以控制在0-360
°
之间(通过用户输入)。视角60为零尤其意味着渲染图像的视角始终固定在面向相机的一侧。360
°
的视角60表示从(感兴趣的)对象周围渲
染图像。
[0169]
例如可以从图4中看到,在此所示的用户界面(如其他图2、3、5、6)可视化了特征(由系统提供和/或由用于提供用户界面的装置和/或设备提供),以在用户界面中添加和控制纹理干扰对象的数量70。参考符号68表示可选择用于添加分散注意力对象的参数。
[0170]
干扰对象17(见图5)能够为数据集提供随机性。所建议的用于生成合成训练数据集的方法和/或系统优选地具有将纹理类似于加载模型的随机数量的干扰对象添加到渲染参数集的能力,这取决于所需干扰对象数量的设置最大数量输入值70。
[0171]
图5示出了用于生成合成训练数据集的系统和/或方法的另一优选特征,即具有由参考符号92表示的自定义背景和随机背景(具有ui)。参考符号90表示交互部分40的一部分,其中用户可以设置关于训练图像i4中感兴趣对象(在此是飞行头盔)的渲染模型15的背景19的参数。
[0172]
优选地,提供针对整个数据集随机选择的大量特定内置背景图像(优选地由系统和/或训练数据生成单元12提供)。用户使用自定义图像的选项由参考符号94表示。优选地,用户能够为渲染数据集上载自己的自定义背景。用于上传图像的交互元素由参考符号96表示。
[0173]
图6示出了由用于生成合成训练数据集的系统和/或方法和/或训练数据生成单元12生成的训练图像i5,与训练图像i4相比,对于该系统和/或方法和/或训练数据生成单元12(特别是随机地)(从大量内置背景图像中)选择不同的背景图像作为背景21(见背景19)。
[0174]
如图5所示,在ui的预览模式下显示的生成的训练图像包括相同感兴趣对象(飞行头盔)的渲染模型,但具有不同的滚动和俯仰参数。
[0175]
在此,生成的训练图像i5中不包括干扰对象(与图5中的结果训练图像i4相反)。
[0176]
用户能够输入训练所需的图像和注释文件的数量44、所需的图像分辨率以及要使用的标签(另请参见图2中的参考符号46)。
[0177]
申请人保留其主张保护申请文件中公开的所有特征的权利,所述特征可以以单独或组合形式作为本发明的基本特征,只要这些特征就现有技术而言是新颖的。此外,应注意,在附图中描述了特征,其可以单独有利。本领域技术人员将直接认识到,在图中公开的特定特征也可以是有利的,而无需采用该图的进一步的特征。此外,本领域技术人员将认识到,优势可以从在一个或多个附图中公开的各种特征的组合中获得。
[0178]
附图标记清单
[0179]
10
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
模型
[0180]8ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用于训练数据生成的3d模型
[0181]
11,13
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用于感兴趣对象的渲染模型
[0182]
11a,13a
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
阴影
[0183]
11b,c,13a,b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
背景部分
[0184]
13d
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
背景
[0185]
12
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
训练数据生成单元
[0186]
13a
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
阴影
[0187]
14
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
机器学习单元
[0188]
15
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
感兴趣对象的渲染模型
[0189]
17
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
干扰对象
[0190]
19
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
训练图像的背景
[0191]
20
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
对象检测
[0192]
21
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
背景
[0193]
22
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
异常检测
[0194]
24
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
生产设施中的质量控制
[0195]
30
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
用户界面
[0196]
32,34,36,38,44,
ꢀꢀꢀꢀꢀ
交互元件,输入元件46,48
[0197]
40
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
交互部分
[0198]
50
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
模型设置
[0199]
52
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
最大实例计数
[0200]
54
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
视图随机化
[0201]
56
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
视图的视场
[0202]
58
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
缩放参数
[0203]
60
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
视角
[0204]
61
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
渲染和标记图像的步骤
[0205]
62
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
滚动角
[0206]
63
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
创建数据文件
[0207]
64,66,68
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
参数
[0208]
70
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
干扰对象的量
[0209]
72
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
光照条件
[0210]
74
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
光源的数量
[0211]
76
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
光强度
[0212]
80,82,84,86,88
ꢀꢀꢀꢀꢀꢀ
后处理参数
[0213]
90
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
背景
[0214]
92
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
使用默认图像
[0215]
94
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
使用自定义图像
[0216]
96
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
上传图像
[0217]eꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
评估单元
[0218]gꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
自动生成训练数据集
[0219]
i1
–
i5
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
渲染图像,训练图像
[0220]mꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
导入模型的步骤
[0221]
p
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
箭头
[0222]
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
训练神经网络
[0223]
t1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
使用图像、注释训练数据。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。