1.本发明专利涉及一种基于图神经网络的会话推荐方法,在推荐系统领域具有重要的应用前景和实用价值。
背景技术:
2.随着互联网的飞速发展,信息过载的问题也越来越突出。为了缓解web上的信息过载,推荐系统已经被广泛部署,并用于进行个性化的信息过滤。推荐系统的核心是预测用户是否会与某项商品进行交互,例如,点击、加购物车、购买等形式的交互。在许多现实世界的网络应用中也扮演着非常重要的角色,例如电子商务、短视频平台和音乐平台等。推荐系统取得巨大成功的原因在于它可以通过为每个用户提供个性化的推荐来缓解信息超载的问题。传统的推荐系统基于用户的个人资料和他们所有的历史活动来提供建议。然而,在某些情况下,这些信息是不能被访问的,在这种情况下,只有匿名用户在短时间内的行为可用。为了提高匿名用户的推荐质量,提出了基于会话的推荐,旨在基于匿名会话更好地预测下一个点击动作。基于会话的推荐作为一种基础的推荐任务,在学术界和产业界都得到了广泛的研究,它根据给定的匿名行为序列,按时间顺序预测下一个感兴趣的项目。基于会话的推荐的一个常见范例是学习会话中各个项目的向量表示(即项目嵌入),然后根据序列中的项目表示生成会话表示,最后基于会话表示和所有商品嵌入之间的相似性执行top-k推荐。与大多数其他需要明确用户人口统计信息的推荐任务不同,会话推荐系统只依赖于正在进行的会话中的匿名用户操作日志(例如,点击)来预测用户的下一个操作。
技术实现要素:
3.现有的基于图神经网络的会话推荐的方法虽然取得了很好的效果,但是仍存在着一些问题。首先,利用其他会话的项目转导信息虽然能够丰富当前会话序列中的项目表示,以便更好地推断当前会话的用户偏好,但不可避免的会引入不相关项(噪声),从而对模型性能产生影响。其次,通过翻转会话序列的方式来利用反向位置编码进行项目表示的聚合,虽然能够更直观地衡量会话序列中每个项目的贡献,但一定程度上破坏了会话序列中项目的顺序转导关系。此外,现有的方法通常侧重于从空间结构信息的角度进行信息聚合,但对会话序列中相邻节点的时间信息的研究却不够深入。因此,针对上述这些问题,本发明提出一种基于双通道信息融合的图神经网络会话推荐方法。
4.本发明主要包括四个部分:(1)数据预处理。(2)会话图和全局图的构造。(3)基于转导信息增强门控图神经网络的会话推荐模型。(4)项目推荐。
5.(1)数据预处理和数据增强。长度为1的会话和出现次数少于5次的条目在所有三个数据集中都被过滤。此外,还对数据进行增强。对于一个会话序列s={v
s,1
,v
s,2
,...,v
s,n
},将其分割处理成序列和相应的标签,即([v
s,1
],v
s,2
),([v
s,1
,v
s,2
],v
s,3
),...,([v
s,1
,v
s,2
,...,v
s,n-1
],v
s,n
)。
[0006]
(2)会话图和全局图的构造。由于采用的是图神经网络,因此需要将会话序列转换
成图的形式。将图的构造分成两个部分:
[0007]
1)会话图构造。对于一个会话序列可以将其建模成一个有向图gs=(vs,es),其中vs表示会话s中的节点,es代表会话s中边的集合,每条边表示为会话中两个相邻时间点点击的项目。把每个会话序列建模成两个有向图:一个顺序图和一个逆序图。对于顺序图,将边划分成输入边和输出边,并且分配一个归一化的权重,它的计算方法是该边的出现次数除以该边的起始节点的出度。对于逆序图,首先将序列翻转即变成[v3,v2,v3,v4,v2,v1],然后为每个项目添加一条自连接边,并将边分成四种类型,分别为e
in
,e
out
,e
in-out
,e
self
。e
in
表示输入边,e
out
表示输出边,,即一条从vi到vj的单向边,e
in-out
表示双向边,即两个项目之间的转导是双向的。e
self
表示自连接。
[0008]
2)全局图构造。构建全局图来利用所有会话中的项转换提取全局信息,提高模型的泛化性。gg=(vg,εg)表示全局图,vg表示构成全局图的节点即为v中的所有项目,εg代表所有会话序列中相邻项构成的边,用邻居项在所有会话的出现频率作为相应边的权值。出于效率考虑,对于每个项目只保留边权重最高的n条边。
[0009]
(3)基于转导信息增强门控图神经网络的会话推荐模型。该模型主要由图注意力网络和图门控网络构成,分别利用这两个网络来学习不同层次的会话表示,以便更好的进行推荐。该阶段为本发明的重点,分为三个部分:
[0010]
1)全局信息增强会话表示学习(global information enhances session presentation learning)。在这一部分,利用会话图和全局图分别学习项目内的局部项目表示以及项目间的全局项目表示,然后通过反向位置编码和软注意机制把两个层次学习到的项目表征进行聚合形成全局级会话表示。
[0011]
2)转导信息增强会话表示学习(transduction information enhances session presentation learning)。在这一部分,采用位置编码将时间信息嵌入到会话序列中的项目表示中,增强会话序列的顺序转导关系。然后使用门控图卷积网络来学习会话序列的项目转导关系并生局部级会话表示。
[0012]
3)预测(prediction)。通过前两个部分(通道)的学习,得到了一个全局级会话表示和一个局部级会话表示。通过将全局级会话表示和局部级会话表示输入到预测层,可以得到两个概率向量,之后使用一个可调节的超参数k将两个概率向量相加来得到最终的预测概率。
[0013]
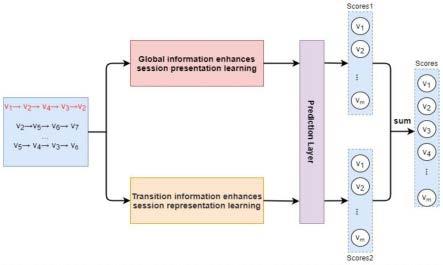
(4)项目推荐。根据会话推荐模型得到的最终预测概率来进行项目推荐。基于转导信息增强门控图神经网络的会话推荐模型的总览图如图1所示。首先我们通过全局信息增强会话表示学习层和转导信息增强会话表示学习层两个通道来学习不同层次的会话嵌入,全局信息增强会话表示学习层利用翻转后的当前会话序列和其他会话信息来学习会话级的项目表示和全局级的项目表示,并利用反向位置编码和软注意机制将项目表示聚合成一个全局级的会话嵌入。转导信息增强会话表示学习层只利用当前会话序列的项目来学习一个会话嵌入,以补充全局信息增强会话表示学习层忽略的对会话序列的顺序转导关系的学习,并将时间信息融入到会话序列中的项目表示中用于邻居嵌入学习。接下来我们使用这两个会话表示分别进行预测,得到其对应的概率,最后我们将两个得分进行求和,得到最终的预测结果。
[0014]
本发明一种基于双通道信息融合的图神经网络会话推荐方法的详细实施步骤如下:
[0015]
步骤1:数据预处理和数据增强。长度为1的会话和出现次数少于5次的条目在所有三个数据集中都被过滤。此外,还对数据进行增强。对于一个会话序列s={v
s,1
,v
s,2
,...,v
s,n
},将其分割处理成序列和相应的标签,即([v
s,1
],v
s,2
),([v
s,1
,v
s,2
],v
s,3
),...,([v
s,1
,v
s,2
,...,v
s,n-1
],v
s,n
)。
[0016]
步骤2:会话图和全局图的构造,将其他类型的数据转换成图是图神经网络必不可少的一步。在这里将会话序列转换成会话图和全局图。其具体构建过程在步骤2.1、2.2进行说明:
[0017]
步骤2.1:构建会话图,包括顺序图和逆序图的构造。对于一个会话序列步骤2.1:构建会话图,包括顺序图和逆序图的构造。对于一个会话序列可以将其建模成一个有向图gs=(vs,es),其中vs表示会话s中的节点,es代表会话s中边的集合,每条边表示为会话中两个相邻时间点点击的项目。以会话[v1,v2,v4,v3,v2,v3]为例,介绍如何将每个会话序列建模成两个有向图:一个逆序图和一个顺序图。对于逆序图,首先将序列翻转即变成[v3,v2,v3,v4,v2,v1],然后为每个项目添加一条自连接边,并将边分成四种类型,分别为e
in
,e
out
,e
in-out
,e
self
。e
in
表示输入边,e
out
表示输出边,,即一条从vi到vj的单向边,e
in-out
表示双向边,即两个项目之间的转导是双向的。e
self
表示自连接。逆序图的构造示例如图2所示。对于顺序图,将边划分成输入边和输出边,并且分配一个归一化的权重,它的计算方法是该边的出现次数除以该边的起始节点的出度。顺序图的构造示例如图3所示。
[0018]
步骤2.2:全局图构造。由于会话图只能提取当前会话内的项目转导信息,为了能够更好的提取项目的转导关系,通过构建全局图来利用所有会话中的项转换提取全局信息,提高模型的泛化性。gg=(vg,εg)表示全局图,vg表示构成全局图的节点即为v中的所有项目,εg代表所有会话序列中相邻项构成的边,用邻居项在所有会话的出现频率作为相应边的权值。出于效率考虑,对于每个项目只保留边权重最高的n条边。全局图的构造示例如图4所示。
[0019]
步骤3:构建转导信息增强门控图神经网络的会话推荐模型。详细的网络模型构建分为三个步骤,其具体构建过程在步骤3.1、3.2和步骤3.3进行说明:
[0020]
步骤3.1:构建全局信息增强会话表示学习层,包括构建局部项目表示学习模块、全局项目表示学习模块和会话表示生成模块。这三个模块的具体实现细节在步骤3.1.1、3.1.2和3.1.3进行详细说明:
[0021]
步骤3.1.1:构建局部项目表示学习模块。利用图注意力网络来学习局部项目表示,利用注意力机制聚合邻居,以学习不同邻居节点的重要性。通过元素积和非线性转换来计算和之间的注意力分数α
ij
,对于不同的关系,训练不同的权重向量,即a
in
,a
out
,a
in-out
,a
self
。为了使不同节点之间的系数具有可比性,通过softmax函数将注意力权重进行标准化:
[0022][0023]
在该公式中,是和之间的关系r的权重向量,这里使用leakyrelu作为激活函数,是vi的一阶邻居。接下来,根据之前计算得到的注意力分数对特征进行线性组合来获得每个节点的输出特征:
[0024][0025]
步骤3.1.2:构建全局项目表示学习模块。利用图注意力网络的思想,根据每个连接的重要性来生成注意力权重。采用注意力机制区分当前项的不同邻居的重要性。在这里,全局项目表示学习模块由两个组件组成:信息传播和信息聚合。
[0026]
信息传播:一个项目可能涉及到多个项目,从其他会话序列中获得更丰富的项目转换信息来帮助预测当前会话的兴趣。由于不同的邻居项有不同的重要性,所以考虑利用会话感知的注意力分数来区分当前项的邻居(n
ε
(v))的重要性。因此,当前项的邻居n
ε
(v)根据会话感知的注意力分数线性组合。
[0027][0028]
其中π(vi,vj)估计不同邻居的重要性权重,采用softmax函数对其进行归一化。直观地说,一个项目越接近当前会话的偏好,这个项目就越接近用户的兴趣。因此,实现π(vi,vj)如下:
[0029][0030][0031]
这里选择leakyrelu作为激活函数,
⊙
表示元素乘积,||表示级联操作,w
ij
∈r1是全局图中边(vi,vj)的权值,w1∈r
d 1
和q1∈r
d 1
是可训练参数,s是当前会话的项目表示的平均值,
[0032][0033]
借助当前会话的项目表示的均值来计算相关项的重要性权重,这意味着跟当前会话更相似的邻居将拥有更重要的地位。
[0034]
信息聚合:最终需要聚合项目表示hv和它的邻居实现聚合函数如下:
[0035][0036]
在这里,将relu作为激活函数,w2∈rd×
2d
是可训练参数,||表示拼接操作。
[0037]
通过单一的聚合器层,项的表示依赖于它自己和它的近邻。可以从一层扩展到多层以获取高阶连接信息。这使得来自其他会话的更多有用信息合并到当前表示中。通过单一层的信息传播和信息聚合,将项目本身及其邻居的表示聚合起来形成新的项目表示。在第k步,将一个项目的嵌入表示为:
[0038][0039]
代表项目v在第k-1步的项目表示,被设置为hv的初始嵌入。因此,项目的k阶表示是它的初始表示以及它的k阶邻居的聚合,这样使更多更有效的信息被聚合到当前会话中。
[0040]
步骤3.1.3:构建会话表示生成模块。对于会话序列中的每一项,通过合并全局上下文和会话上下文来获得它的表示,把全局级项目表示和会话级项目表示相加来得到最终的项目表示。
[0041][0042][0043][0044]
分别在全局级表示和会话级表示上使用dropout来防止过拟合。
[0045]
现在提出如根据上述学到的项目表示何获得会话表示。根据上述学到的项目表示来学习会话表示用于推荐。将会话序列输入到图神经网络后,可以得到会话中涉及的项目的表示,即l是会话序列的长度。这里引用反向位置编码来保留会话的位置信息。直观的说,越靠近最后一项的项目,越能代表用户的当前兴趣。位置嵌入对应一个可学习的位置嵌入矩阵它们被添加到项目表示以获得最终的项目表示,l表示当前会话序列的长度。具体的说,把位置嵌入与会话序列中的项目嵌入拼接起来,再经过特征变换和非线性激活函数tanh得到最终结果:
[0046][0047]
在这里w3∈rd×
2d
和b∈rd是可训练参数,||表示拼接操作。
[0048]
以前的大多数方法都集中在会话最后一项的重要性上,这间接影响了其他项对当前项的贡献。通过会话序列中项目的平均值来得到会话信息,
[0049][0050]
然后采用一种软注意力机制来计算权重,
[0051][0052]
w4,w5∈rd×d是可训练参数。
[0053]
最后,会话表示由项目表示的线性连接形成,
[0054]
[0055]
会话表示s由当前会话中涉及到的所有项构成,其中每个项的贡献由当前会话中的信息和会话序列中的先后顺序共同决定。
[0056]
步骤3.2:构建转导信息增强会话表示学习层,包括构建项目表示学习模块和生成会话表示模块。这两个模块的构建细节在步骤3.2.1和3.2.2进行详细说明:
[0057]
步骤3.2.1:构建项目表示学习模块。门控图卷积网络(ggnn)已经被广泛应用于基于会话的推荐中,并取得了显著效果。因此,使用ggnn来学习会话序列的项目转导关系,对于图上的节点vi,其更新函数如下所示:
[0058][0059][0060][0061][0062][0063]
h∈rd×
2d
是权重系数,z
s,i
和r
s,i
分别是更新门和重置门,是会话s中加入位置编码后的节点嵌入列表,
⊙
表示元素乘积,σ表示sigmoid激活函数。as∈rn×
2n
是图的邻接矩阵,a
s,i:
∈r1×
2n
是节点v
s,i
在邻接矩阵as中对应的两列。
[0064]
对于每个会话图,门控图神经网络同时处理节点。在矩阵as的约束下,进行不同节点间的信息传播。具体来说,它提取邻域的潜在向量,并将它们作为输入,输入到图神经网络。然后由更新门和重置门两个门分别决定哪些信息需要保留,哪些信息需要丢弃。更新门用于控制前一时刻的状态信息被带入到当前状态的程度。重置门决定如何将新的信息与之前的记忆相结合,从而捕捉时间序列中的短期依赖关系。在此之后,根据前一个状态、当前状态和复位门构造候选状态。最后利用更新门来将前一时刻的状态和候选状态结合起来得到最终状态。更新会话图中的所有节点直到收敛,就可以得到最终的节点向量。
[0065]
步骤3.2.2:构建生成会话表示模块。不同于之前的利用会话序列最后一项作为用户的当前兴趣并使用软注意力机制生成会话嵌入方法,直接采用均值聚合的方式来形成会话嵌入。
[0066][0067]
步骤3.3:构建预测层。在步骤3.1和步骤3.2的计算得到的会话表示的基础上,根据每个候选条目的初始嵌入和当前会话表示,首先使用点积,然后应用softmax函数得到输出
[0068][0069][0070]
式中表示项目vi在当前会话中作为下一次点击的概率,是所有项目在下一次被点击的概率。通过将会话嵌入sg和s
t
输入到预测层,可以得到两个概率向量和之
后使用一个超参数k将两个概率向量相加:
[0071][0072]
损失函数被定义为预测结果的交叉熵:
[0073][0074]
式中y表示项目真实值的one-hot编码向量。
[0075]
步骤4:项目推荐。根据会话推荐模型得到的最终预测概率来进行top-k项目推荐。
附图说明
[0076]
图1是本发明中模型的总览图
[0077]
图2是本发明中逆序图的构造示例图
[0078]
图3是本发明中顺序图的构造示例图
[0079]
图4是本发明中全局图的构造示例图
具体实施方式
[0080]
下面通过具体实施方式对本发明进一步说明。
[0081]
为了更好的说明本发明会话推荐方法的优势,本实施例进行了如下实验。
[0082]
一、数据集和预处理
[0083]
使用三个基准数据diginetica,tmall,nowplaying来验证该方法的性能。其中diginetica数据集来自于2016年的cikm cup,由典型的交易数据组成。tmall数据集来自2015年的ijcai大赛,其中包含匿名用户在天猫在线购物平台上的购物日志。nowplaying数据集twitter构建,它描述了用户的音乐收听行为。首先对数据集进行处理。具体来说,长度为1的会话和出现次数少于5次的条目在所有三个数据集中都被过滤了。此外,对于一个会话序列s={v
s,1
,v
s,2
,...,v
s,n
},将其分割处理成序列和相应的标签,即([v
s,1
],v
s,2
),([v
s,1
,v
s,2
],v
s,3
),...,([v
s,1
,v
s,2
,...,v
s,n-1
],v
s,n
)。
[0084]
二、评价指标
[0085]
使用2个在会话推荐中被广泛使用的评测指标p@20和mrr@20来评估所有模型的性能。p@k和mrr@k的值越高,代表模型性能越好。
[0086]
·
p@20(presicion)被广泛用作预测准确性的衡量标准。它代表了前20个项目中正确推荐的项目的比例。
[0087]
·
mrr@20(mean reciprocal rank)是正确推荐项目的平均倒数排名。当排名超过20时,倒数排名设置为0。mrr度量考虑推荐排序的顺序,其中较大的mrr值表示正确的推荐位于排序列表的前面。
[0088]
三、基线模型
[0089]
将该方法与经典方法以及最先进的模型进行比较。对以下九个基线模型进行了评估。
[0090]
·
fpmc:它结合了矩阵分解和一阶马尔可夫链来捕捉序列效应和用户偏好。按照前面的工作,在计算推荐评分时也忽略了用户潜在表示。
[0091]
·
gru4rec:这是一种基于循环神经网络的深度学习模型,它利用会话并行的小批量训练、基于小批量的输出采样和设计良好的top1损失函数来帮助循环神经网络模型适应基于会话的推荐问题。
[0092]
·
narm:这是一种引入注意力机制来捕捉用户主要目的的方法。主要目的是与连续的行为特征相结合,并用作生成下一个项目的最终表示。
[0093]
·
stamp:是一种利用通过注意机制增强的简单多层感知机的方法,可以同时捕捉用户的一般兴趣和当前会话的当前兴趣。
[0094]
·
sr-gnn:是第一个使用图神经网络用于会话推荐的方法,它首先引入了图神经网络(gnn)来捕获复杂的项目转换。为了生成当前会话的下一个条目,它使用了与stamp相同的思想,即利用注意力机制来捕捉用户的一般兴趣和当前兴趣。
[0095]
·
gc-san:首先结合图神经网络和多层自注意力网络,通过建模局部邻近项转换和上下文化非局部表示来提高推荐性能。
[0096]
·
fgnn:提出了一个加权注意图层和一个图级特征提取器来学习项目嵌入和会话的嵌入。
[0097]
·
gce-gnn:利用图注意力网络从局部和全局上下文捕获项目转移关系,并利用反向位置编码来生成会话表示。
[0098]
·
gc-hgnn:使用超图卷积神经网络和图注意力网络获取全局上下文信息和局部信息,并利用注意机制处理融合特征学习会话序列的最终表示。
[0099]
四、参数设置
[0100]
为了进行公平的比较,根据各自论文中提供的数据预处理方法和参数设置以获得最佳性能。使用均值为0、标准差为0.1的高斯分布对所有的参数进行初始化,并且使用l2正则化作为处罚项,其值为10-5
,选择初始学习速率为0.001的adam,每3个epoch后将衰减0.1来优化参数。此外,对于全局图的设置,将邻居数和相邻项的最大距离分别设置为12和1。一些对模型有较大影响的超参数,需要在每个数据集中分别进行调整。
[0101]
五、整体实验
[0102]
为了验证该方法的有效性,在表1中比较了新模型与其他模型的性能。
[0103]
表1新模型与其他模型性能比较
[0104][0105]
[0106]
从表一可以看到传统的基于马尔可夫链的方法fpmc在会话推荐中表现较差,这表明基于马尔可夫链的方法中关于连续项独立性的假设在会话推荐中是不够的。与基于深度学习和图神经网络的方法相比,传统方法的竞争力明显不足。
[0107]
对于基于深度学习的gru4rec方法通过简单堆叠多个门控循环单元来进行预测,因此其与其他基于深度学习的方法相比表现最差。narm探索了一种带有注意机制的混合编码器,来模拟用户的顺序行为,捕捉用户在当前会话中的主要目的,随后将其组合为统一的会话表示从而得到较好的性能。stamp利用注意力机制明确地考虑用户的一般和当前兴趣,与narm相比各有利弊。与传统方法相比,这几个模型的推荐性能相较于传统方法具有明显提升,这表明基于深度学习的方法具有更强大的表示能力。
[0108]
随着图神经网络的发展,会话推荐也开始使用图神经网络来建模会话序列的转导关系。sr-gnn第一次尝试将门控图神经网络用于会话推荐,并取得了优于基于深度学习方法的性能。gc-san动态地构造会话序列的图结构并捕获丰富的本地依赖关系,每个会话通过自注意机制来学习长期依赖。最后,每个会话都表示为全局首选项和该会话当前兴趣的线性组合。fgnn提出了一个加权注意图层和一个图级特征提取器来学习项目嵌入和会话的嵌入。gce-gnn首次通过构建全局图利用会话间的信息来生成项目表示,并使用位置编码来生成会话表示。gc-hgnn提出了一种全局上下文支持的超图增强图神经网络,该网络可以有效地学习全局和局部上下文信息,并通过融合两层信息获得更好的会话特征。与之前的方法相比,这两个模型都在三个公共数据集上取得了比之前的模型更好的结果,表明从会话图和全局图中考虑两个层次的项目嵌入有利于预测。
[0109]
新方法在三个公共数据集上都取得了最优结果,这证明了该方法的优越性。不同于sr-gnn和gce-gnn,该方法不仅仅将全局信息融入到会话序列的项目表示中,还将时间信息加入到会话序列的项目表示中来增强会话序列中的顺序转导关系。并且生成两个层次的会话嵌入以弱化融入全局信息带来的噪声对模型性能的影响。因此,该方法取得了更好的性能。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。