一种基于点云时空记忆网络的4d目标分割方法
技术领域
1.本发明涉及计算机视觉领域,具体是涉及一种基于点云时空记忆网络的4d目标分割方法。
背景技术:
2.近年来,基于图像的视频对象分割(vos)因其在视频编辑分析方面的广泛应用引起了广泛的关注,这个任务的目的是在连续的视频片段中分割目标。尽管最近2d vos算法取得了很好的效果,但在处理低光条件或无纹理物体时,他们仍然面临着巨大的挑战。相比之下,激光雷达对纹理不敏感,对光线变化不敏感,这使它们成为相机的合适补充。另一方面,随着近十年来3d激光雷达传感器的快速发展,由于点云在自动驾驶、运动规划和机器人等领域的巨大应用潜力,利用点云解决各种视觉问题已成为热门话题。然而,基于激光雷达的vos任务还没有明确和探索,这主要是由于缺乏合适的数据集。
3.基于激光雷达的3d视频目标分割或者说4d目标分割是一个新的任务,它分割点云视频中特定的3d激光雷达目标(第一帧给定),4d目标分割最相关的任务是三维跟踪、三维场景流。具体来说,三维跟踪提供了物体的边界和方向信息,它要比逐点分割提供的信息密度小。由于lidar点云只存在于物体表面,通常很难通过区边界框内的点云来生成高质量的目标形状。此外,由于边界框的不精确或不同物体或背景之间的紧密相邻,所生成的目标形状通常包含大量的噪声点。三维场景流估计两个连续的点云帧之间的逐点运动,为动态场景中物体的运动提供了低级和基本的理解。逐点运动信息当然可以被用来传播目标掩模,就像用于2d光流一样,然而,它通常包含很多不必要的运动计算比如背景,并且缺乏对遮挡和漂移的鲁棒性,现有技术中也缺乏准确性高、鲁棒性好的4d目标分割方法。
技术实现要素:
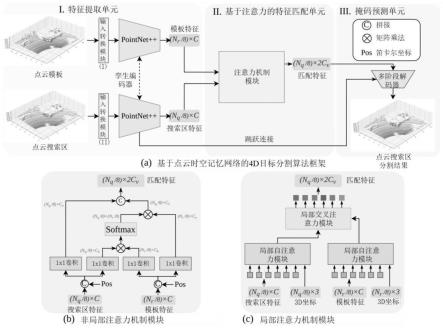
4.针对上述问题,本发明提出了一种简单、灵活的端到端基准方法,用于进行4d目标分割。具体地说,本发明利用点云时空记忆网络计算当前帧中每个点与历史帧中的每个点的时空注意。设计了两个输入转换模块来将两种类型的输入映射到统一的特征空间。然后利用一个基于pointnet 的孪生编码器对模板特征和搜索特征进行编码。在经过一个注意力机制模块之后,匹配特征通过基于pointnet 分割头的多阶段解码器来预测最终的点云搜索区分割结果。
5.为了实现上述目的,本发明提供一种基于点云时空记忆网络的4d目标分割方法,包括以下步骤:
6.s1、构建4d目标分割任务数据集;
7.s2、基于点云时空记忆网络并结合非局部/局部注意力机制构建4d目标分割网络;
8.s3、对所述4d目标分割网络模型进行训练,通过降低网络损失函数优化网络参数直至网络收敛,获得基于点云时空记忆网络的4d目标分割方法;
9.s4、利用所述基于点云时空记忆网络的4d目标分割方法对新的lidar视频序列分
割给定目标。
10.优选的,所述步骤s1具体包括以下步骤:
11.s11、统计kitti数据集中属于移动目标的目标id,并使用所述目标id提取出各个类别的lidar数据得到粗糙的数据集;
12.s12、统计每个lidar序列的长度以及第一帧中各个目标的点云数,过滤掉长度小于50帧的lidar序列以及第一帧目标点云数小于50的lidar序列,得到最终的4d目标分割数据集。
13.优选的,所述步骤s2具体包括以下步骤:
14.s21、将两类不同的输入(即点云模板pr及其目标掩码mr和点云搜索区pq)通过输入转换模块映射到统一的特征空间,得到模板特征er和搜索特征eq;
15.s22、利用以pointnet 为骨干网络构建的孪生编码器分别对模板特征er和搜索特征eq下采样,得到层次化特征fr和fq;
16.s23、利用非局部注意力机制模块和局部注意力机制模块对所述层次化特征fr和fq计算匹配特征o;
17.s24、以pointnet 的分割头为基础构建多阶段解码器,初始以所述匹配特征o为输入之后以上一阶段的输出和来自孪生编码器相同层次的特征为输入,逐步进行上采样,得到最终输出mq。
18.优选的,所述输入转换模块具体分为模板转换模块和搜索转换模块,所述模板转换模块和搜索转换模块都是由3层全连接网络组成,隐藏层的神经元数目分别为[64,128],每层隐藏层后接relu层和bn层;所述模板转换模块和搜索转换模块的区别是它们的输入,搜索转换模块以lidar帧的点云搜索区pq为输入,输出搜索特征eq,而模板转换模块则以lidar帧的点云模板pr及其目标掩码mr为输入,输出模板特征er。
[0019]
优选的,所述孪生编码器具体为:使用pointnet 前三个阶段作为共享的编码器,每个阶段对输入进行局部聚合以及2倍下采样,输出的特征通道数分别为128,128和256。
[0020]
优选的,所述非局部注意力机制模块具体为:先将fr/fq和笛卡尔坐标拼接,然后使用两个并行卷积将特征映射到键值特征对(kq,vq),(kr,vr),之后以非局部的方式进行特征匹配,对搜索点和模板点之间的关系进行建模,在匹配过程中,首先计算搜索键特征kq和模板键特征kr的所有点特征之间的相似度作为权值;然后,将权值作为亲和力矩阵乘以模板值特征vr,并将结果与搜索值特征vq拼接,作为最终的匹配特征o。
[0021]
优选的,所述局部注意力机制模块具体为:使用两个局部自注意力块分别对fq和fr进行特征增强和一个与局部自注意力块具有相似设计的局部交叉注意块进行特征匹配。
[0022]
优选的,所述多阶段解码器具体为3个阶段,每个阶段进行2倍的上采样。
[0023]
优选的,所述步骤s3具体包括以下步骤:
[0024]
s31、利用服务器执行训练点云模板生成单元和点云搜索区生成单元,生成点云模板和点云搜索区
[0025]
s32、利用服务器执行所述输入转换模块,将两类不同的输入(即点云模板pr及其目标掩码mr和点云搜索区pq)映射到统一的特征空间,得到模板特征和搜索特征
[0026]
s33、利用服务器执行所述孪生编码器,将输入的特征er和eq进行降采样,得到层次化特征和
[0027]
s34、利用服务器执行所述非局部注意力机制模块和局部注意力机制模块,根据层次化特征fr和eq得到匹配特征o包含搜索区中的特定目标信息;
[0028]
s35、利用服务器执行所述多阶段解码器,输入匹配特征o,输出关于搜索区的最终的分割结果
[0029]
s36、利用服务器采用端到端的方式进行网络训练;分割损失函数l为交叉熵损失函数,其数学表达为:
[0030][0031]
其中,y表示目标掩码真值;m表示目标掩码预测结果;ω表示目标掩码中所有点的集合;
[0032]
s37、利用服务器优化目标函数,获取局部最优网络参数。
[0033]
优选的,所述步骤s31具体包括以下步骤:
[0034]
s311、从所述4d目标分割任务数据集中抽取lidar视频,然后从所述lidar视频中随机抽取2帧lidar:{x
t-1
,x
t
},t为当前时刻;
[0035]
s312、根据lidar:{x
t-1
,x
t
}及其目标掩码,生成轴对齐边界框{b
t-1
,b
t
};
[0036]
s313、使用参数为(1,1,5
°
)的多元高斯分布生成在x,y轴方向以及旋转方向参数,对边界框b
t-1
进行数据增强,然后取出数据增强后的边界框中的x
t-1
中的3d点云,对其平移旋转操作进行归一化并进行采样,得到点云模板pr;
[0037]
s314、使用参数为(-0.3,0.3,5
°
)的多元均匀分布生成在x,y轴方向以及旋转方向参数,对边界框b
t
进行数据增强,再对数据增强后的边界框进行平移以及放缩以增大搜索区域,之后取变换后的边界框中的x
t
中的3d点云,对其平移旋转操作进行归一化并进行采样,得到点云搜索区pq。
[0038]
优选的,所述步骤s4具体包括以下步骤:
[0039]
s41、对于新的lidar视频序列,使用第一帧和特定目标掩码,调用所述点云模板生成单元,初始化点云模板分割从视频序列的第二帧开始;
[0040]
s42、对于当前lidar帧,利用时间连续性,使用上一帧的目标掩码生成轴对齐边界框,然后进行偏移和缩放,作为当前lidar帧的搜索区,取搜索区内的点云并进行去平移旋转归一化,得到当前lidar帧的点云搜索区pq和搜索区指示掩码;
[0041]
s43、将点云模板pr及其目标掩码mr和点云搜索区pq输入到所述输入转换模块中,得到模板特征和搜索特征eq;
[0042]
s44、将特征er和eq输入到所述孪生编码器中进行降采样,得到层次化特征和fq;
[0043]
s45、将层次化特征fr和fq输入到注意力机制模块中得到匹配特征o;
[0044]
s46、将匹配特征o输入到所述多阶段解码器中,输出关于搜索区的分割结果mq,最后根据所述搜索区指示掩码将搜索区的分割结果拓展为全局lidar帧,得到最终的分割结
果m;
[0045]
s47、使用第一帧及其目标掩码和当前帧及其分割结果生成新的点云模板,并重复s42-s46直到完成整个lidar视频的分割。
[0046]
与现有技术相比,本发明的有益效果是:
[0047]
本发明提供的提供的基于点云时空记忆网络的4d目标分割方法,通过定义新任务4d目标分割以及构建新任务的数据集4d目标分割数据集,给出了该任务的一个基准;通过使用多层次聚合的孪生编码器充分编码目标信息,使用非局部和局部注意力机制模块增强目标信息,以及特征金字塔上采样结构恢复目标结构,使系统能够在复杂的3d环境中准确地分割目标,在众多困难的实际场景中都可以准确快速地分割目标,在构建的数据集上实现了高性能结果,对实际3d环境中目标遮挡,快速移动等问题具有很好的鲁棒性,对汽车分割的iou为0.33,对卡车分割的iou为0.39,对人分割的iou为0.21,对自行车分割的iou为0.65。
附图说明
[0048]
图1为一种基于点云记忆网络的4d目标分割方法的算法框架图;
[0049]
图2为本发明所设计的非局部/局部注意力机制模块图;
[0050]
图3为本发明一种基于点云记忆网络的4d目标分割方法的分割结果图。
具体实施方式
[0051]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0052]
针对现有技术中存在的问题与不足,本发明一种基于点云时空记忆网络的4d目标分割方法,主要包括4d目标分割任务数据集构建、结合点云时空记忆网络和注意力机制的4d目标分割网络设计、模型训练和模型推断四个阶段的步骤实现。
[0053]
本发明提出的一种基于点云时空记忆网络的4d目标分割方法,包括以下步骤:
[0054]
s1、构建4d目标分割任务数据集;
[0055]
s2、基于点云时空记忆网络并结合非局部/局部注意力机制构建4d目标分割网络;
[0056]
s3、对所述4d目标分割网络模型进行训练,通过降低网络损失函数优化网络参数直至网络收敛,获得基于点云时空记忆网络的4d目标分割方法;
[0057]
s4、利用所述基于点云时空记忆网络的4d目标分割方法对新的lidar视频序列分割给定目标。
[0058]
其中步骤s1中构建4d目标分割任务数据集是以kitti数据集为基础的,
[0059]
下面对每一步骤进行详细的说明介绍。
[0060]
步骤s1、构建4d目标分割任务数据集;通过对kitti数据集进行统计、抽取、过滤等处理获得4d目标分割任务数据集,提供算法测试基准。
[0061]
为了能够更好地研究该任务,本发明构建了一个基于kitti的4d目标分割数据集。构建过程中,选择交通中通常出现的事物,如汽车、人、卡车和自行车作为目标,生成激光雷
达视频,并通过从全景注释中选择相应的目标掩码来生成每个目标的注释,4d目标分割任务数据集可以为这项任务提供一个很好的基准。
[0062]
具体实现过程如下:
[0063]
s11、统计kitti中属于移动目标(汽车、人、卡车、自行车等)的目标id,并使用目标id提取出各个类别的lidar数据,得到粗糙的数据集;
[0064]
s12、统计每个lidar序列的长度以及第一帧中各个目标的点云数,过滤掉长度小于50帧的lidar序列以及第一帧目标点云数小于50的lidar序列,得到最终的4d目标分割数据集;具体为,4d目标分割数据集的数据包含200个lidar序列,共18370帧,其中125个序列包含汽车类别,39个序列包含人类别,18个序列包含卡车类别,18个序列包含自行车类别;详细分布为:
[0065]
表1:4d目标分割数据集数据分布,表示每个类别所有的lidar帧数/序列数
[0066][0067]
步骤s2、基于点云时空记忆网络并结合非局部/局部注意力机制设计4d目标分割网络。如图2所示为本发明的所设计的注意力机制模块图,具体步骤如下:
[0068]
s21、设计输入转换模块,将两类不同的输入(即点云模板pr及其目标掩码mr和点云搜索区pq)映射到统一的特征空间,得到模板特征er和搜索特征eq;具体为,转换模块分为模板转换模块和搜索转换模块,两者结构相同,都是由3层全连接网络组成,隐藏层的神经元数目分别为[64,128],每层隐藏层后接relu层和bn层;这两个模块之间的唯一区别是它们的输入:搜索转换模块以lidar帧的点云搜索区pq为输入,输出搜索特征eq,而模板转换模块则以lidar帧的点云模板pr及其目标掩码mr为输入,输出模板特征er;
[0069]
s22、以pointnet 为骨干网络设计孪生编码器,分别对模板特征er和搜索特征eq下采样,得到层次化特征fr和fq;具体为,孪生编码器使用pointnet 前三个阶段作为共享的编码器,每个阶段对输入进行局部聚合以及2倍下采样,输出的特征通道数分别为128,128和256;
[0070]
s23、设计非局部的注意力和局部注意力机制模块,对所述s22中的层次化特征fr和fq计算匹配特征o;非局部注意力机制模块具体为:如图1(b)所示,先将fr/fq和笛卡尔坐标拼接,然后使用两个并行卷积将特征映射到键值特征对(kq,vq),(kr,vr),之后以非局部的方式进行特征匹配,对搜索点和模板点之间的关系进行建模,也可以理解为从模板点检索目标信息;在匹配过程中,首先计算搜索键特征kq和模板键特征kr的所有点特征之间的相似度作为权值;然后,将权值作为亲和力矩阵乘以模板值特征vr,并将结果与搜索值特征vq拼接,作为最终的匹配结果o,数学表达为:
[0071][0072][0073]
[0074]
其中,和分别为层次化特征fq和fr的空间笛卡尔坐标;φ
*
为1
×
1的卷积(φk的输出通道数为64,φv的输出通道数为128),[
·
,
·
]为拼接操作,p和q分别表示搜索区的点索引和模板的点索引,
‘
·’为点积,
‘
σ’为softmax函数;
[0075]
局部注意力机制模块具体为:如图1(c)所示,使用两个局部自注意块(local self-attention block,lsa)分别对fq和fr进行特征增强和一个与lsa具有相似设计设计的局部交叉注意块(local cross-attention block,lca)进行特征匹配;如图2所示,lsa可具体表示为:
[0076]q*
=φq(f
*
),k
*
=φk(f
*
),v
*
=φv(f
*
)
[0077][0078]
o=α(y) f
*
[0079]
其中,*表示q(点云搜索区)或r(点云模板),φ
*
为1
×
1的卷积,p指q
*
的点索引,ν(p)为点p领域的局部区域集合,
‘
·’为点积,
‘
σ’为softmax函数,δ=θ(p
i-pj)为位置编码,pi,pj为3d笛卡尔坐标,α,γ,θ为具有两个线性层和一个relu层的多层感知机(mlp),隐藏层的通道数为256;
[0080]
如图2所示,lca可具体表示为:
[0081]qq
=φq(fq),kr=φk(fr),vr=φv(fr)
[0082][0083]
o=α(y) fq[0084]
其中,ωr为模板点集合。
[0085]
本发明发现基准方法中使用的时空注意模块与非局部匹配机制具有内在相似性,缺乏局部性。而3d点云表现出局部密度的特性,反映了物体的表面结构。此外,在全局注意力的情况下,克服注意力分散和欠分割的问题是具有挑战性的。因此,为了利用激光雷达视频的时序性和局部稠密结构,本发明将基准方法中的非局部注意力机制模块替换为局部注意力机制模块(局部自注意力和局部交叉注意力),它在学习表面聚集点之间的联系方面更有效。在局部注意力机制的帮助下,改进的模型可以更好地学习点云中的目标表示,从而实现更准确的分割预测。
[0086]
s24、以pointnet 的分割头为基础,设计多阶段解码器,初始以匹配特征o为输入之后以上一阶段的输出和来自孪生编码器相同层次的特征为输入,逐步进行上采样,得到最终输出mq;具体为,多阶段解码器具体为3个阶段,每个阶段进行2倍的上采样。
[0087]
步骤s3、对所述4d目标分割网络模型进行训练,通过降低网络损失函数优化网络参数直至网络收敛,获得基于点云时空记忆网络的4d目标分割方法。如图1所示为本发明一种基于点云时空记忆网络的4d目标分割方法的算法框架图,具体步骤如下:
[0088]
s31、利用服务器执行训练点云模板和点云搜索区生成单元,生成点云模板和点云搜索区具体为,从所述步骤s1中所述的4d目标分割数据集中抽取lidar视频,然后从该lidar视频中随机抽取2帧lidar:{x
t-1
,x
t
},其中t为当前时刻;根据lidar帧{x
t-1
,x
t
}及其分割标签,生成轴对齐边界{b
t-1
,b
t
};使用参数为
(1,1,5
°
)的多元高斯分布生成在x,y轴方向以及旋转方向参数,对边界框b
t-1
进行数据增强,然后取出数据增强后的边界框中的x
t-1
中的3d点云,对其平移旋转操作进行归一化并进行采样(1024个点),得到点云模板pr;再使用参数为(-0.3,0.3,5
°
)的多元均匀分布生成在x,y轴方向以及旋转方向参数,对边界框b
t
进行数据增强,再对数据增强后的边界框进行平移(x方向偏移2m)以及放缩(扩大2倍)以增大搜索区域,之后取变换后的边界框中的x
t
中的3d点云,对其平移旋转操作进行归一化并进行采样(512个点),得到点云搜索区pq;
[0089]
s32、利用服务器执行所述步骤s2中所述的输入转换模块,将两类不同的输入(即点云模板pr及其目标掩码mr和点云搜索区pq)映射到统一的特征空间,得到模板特征和搜索特征
[0090]
s33、利用服务器执行所述步骤s2中所述的孪生编码器,将输入的特征er和eq进行降采样,得到层次化特征和
[0091]
s34、利用服务器执行所述步骤s2中所述的注意力机制模块,根据层次化特征fr和fq来得到匹配特征o包含搜索区中的特定目标信息;
[0092]
s35、利用服务器执行所述步骤s2中所述的多阶段解码器,输入匹配特征o,输出关于搜索区的最终的分割结果
[0093]
s36、利用服务器进行网络训练,采用端到端的方式训练;分割损失函数l为交叉熵损失函数,其数学表达为:
[0094][0095]
其中,y表示目标掩码真值;m表示目标掩码预测结果;ω表示目标掩码中所有点的集合;
[0096]
s37、利用服务器优化目标函数,获取局部最优网络参数;具体为,将所述步骤s36中的损失函数l作为目标函数,使用adam优化器迭代更新网络参数,使目标损失函数降低直至收敛到局部最优,至此训练结束,得到训练好的基于点云时空记忆网络的4d目标分割的网络权重。
[0097]
步骤s4、利用所述基于点云时空记忆网络的4d目标分割方法对新的lidar视频序列分割给定目标。具体步骤如下:
[0098]
s41、对于给定lidar视频,使用第一帧和特定目标掩码,调用所述s31中所述的点云模板生成单元,初始化点云模板分割从视频序列的第二帧开始;
[0099]
s42、对于当前lidar帧,利用时间连续性,使用上一帧的目标掩码生成轴对齐边界框,然后进行偏移(x方向偏移2m)和缩放(扩大2倍),作为当前lidar帧的搜索区,取搜索区内的点云并进行去平移旋转归一化,得到当前lidar帧的点云搜索区pq和搜索区指示掩码(用0,1指示lidar帧中属于搜索区的点云);和所述s314不同,该步骤中的点云搜索区的生成不进行采样;
[0100]
s43、将点云模板pr及其目标掩码mr和点云搜索区pq输入到所述步骤s2中所述的输入转换模块,得到模板特征和搜索特征eq;
[0101]
s44、将特征er和eq输入到所述步骤s2中所述的孪生编码器进行降采样,得到层次
化特征和fq[0102]
s45、将层次化特征fr和fq输入到所述步骤s2中所述的注意力机制模块来得到匹配特征o;
[0103]
s46、将匹配特征o输入到所述步骤s2中所述的多阶段解码器,输出关于搜索区的分割结果mq,最后根据所述s42中生成的搜索区指示掩码将搜索区的分割结果拓展为全局lidar帧,得到最终的分割结果m;
[0104]
s47、使用第一帧及其标注和当前帧及其分割结果生成新的点云模板,并重复s42-s46直到完成整个lidar视频的分割,如图3所述为本发明一种基于点云记忆网络的4d目标分割方法的分割结果图。
[0105]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。