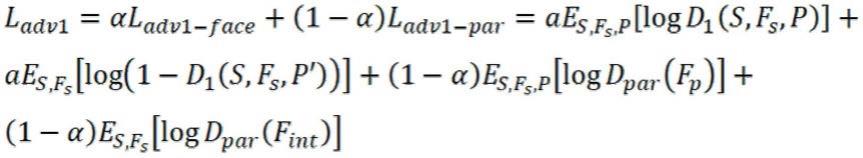
1.本发明属于计算机视觉领域,具体的说是涉及一种基于中间语义增强的 人脸素描-照片合成方法。
背景技术:
2.基于素描的人脸异质图像合成技术在数字语义中具有重要的意义和应用 价值,同时,素描-照片合成技术在数字娱乐领域也占有重要的一席之地。
3.目前人脸素描-照片合成方法主流是采用神经网络来拟合素描图像和照片 图像之间复杂的非线性映射关系,利用生成对抗网络可以生成较为逼真的照 片图像,但由于模态的差异生成的照片图像仍存在人脸不准确的问题。现有 方法利用语义分割算法提取人脸语义结构对生成人脸照片的结构进行约束, 但忽略了素描语义和照片语义之间仍存在一定差异。直接利用素描语义进行 人脸照片的合成会导致合成人脸结构不够准确,合成图像质量不高的问题。
4.综上所述,当前人脸素描-照片合成方法由于模态差异存在人脸不准确的 问题,并且忽略了素描语义和照片语义之间仍存在一定差异。
技术实现要素:
5.为了解决,当前人脸素描-照片合成方法由于模态差异存在人脸不准确的 问题,并且忽略了素描语义和照片语义之间仍存在一定差异的技术缺陷,本 发明提供了一种基于中间语义增强的人脸素描-照片合成方法,通过构建两阶 段生成对抗网络,在第一合成阶段合成人脸中间语义,并构建语义判别器进 行合成语义的判别,在总体损失函数中增加语义匹配损失,进而在合成过程 中修正人脸的语义结构,使得人脸语义结构更加接近真实的人脸照片语义, 减小由于模态差异带来的语义结构差异,并利用合成的中间语义对合成的人 脸照片进行成分损失的计算,以提高合成照片的准确性和质量。
6.为了达到上述目的,本发明是通过以下技术方案实现的:
7.本发明是一种基于中间语义增强的人脸素描-照片合成方法,该方法包括 如下步骤:
8.步骤1:对素描成对人脸素描-照片进行预处理,使得人脸图像的尺寸一 致、内容对齐,得到数据集,表示为t:其中人脸素描数据集表示 为s={s1,s2,...,s
t
,...,sn},人脸素描数据集表示为p={p1,p2,...,p
t
,...,pn};
9.步骤2:利用预训练的人脸解析模型bisenet模型分别对人脸素描和人脸 照片进行语义分割,得到人脸素描和照片的语义分割图,分别表示为 fs={f
s1
,f
s2
,...,f
st
,...,f
sn
}和f
p
={f
p1
,f
p2
,...,f
pt
,...,f
pn
},将数据 集{s,fs,p,f
p
}进行插值,并将所有图像插值到256
×
256的分辨率,并进行归一 化处理;
10.步骤3:构建两阶段的生成对抗网络合成模型,包含第一阶段的dip-gan 网络和第二阶段的se-gan网络;
11.步骤4:将素描图像s和根据素描图像s进行语义分割得到素描语义fs输入步骤3第一阶段的dip-gan网络,同时得到初始合成照片p’和中间语 义f
int
;
12.步骤5:进行第一阶段的合成判别,包括初始合成照片p’的判别以及合成 步骤4得到的中间语义f
int
的判别d
par
,并计算第一阶段的对抗损失l
adv1
、 风格损失l
per1
、成分损失l
cmp1
以及语义匹配损失l
pm1
;
13.步骤6:将第一阶段初始合成照片p’的合成结果和中间语义f
int
输入到第 二阶段的se-gan网络中的生成器g2,分别经过8个编码层,进行特征融合 之后,再经过8个解码层,得到最终的合成照片p”,并计算第二阶段的损失 函数;
14.步骤7:以最大最小化目标函数为目标,利用反向传播算法,进行网络参 数更新和迭代训练,优化网络结构中的g1、d1、d
par
、g2、d2,采用迭代更 新的方式进行训练,训练的顺序为d1、d
par
→
d2→
g1→
g2;
15.步骤8:在测试阶段,只需将人脸素描图像,经过bisenet网络,提取语 义图像,然后进行标准化,并缩放到统一尺寸256
×
256,直接连续输入到两个 生成器g1、生成器g2中,最终的输出结果即为合成的可见光照片图像。
16.本发明的有益效果是:本发明首次注意到由于模态的差异,素描图像语 义和照片图像语义也存在一定的差异,利用素描人脸的语义结构直接进行照 片的合成会导致合成结果的不准确,因此本发明创新性提出中间语义的概念, 在合成过程中修正语义结构信息,解决合成人脸照片结构不准确的问题。
17.本发明通过构建两阶段合成网络,在第一合成阶段同时合成中间语义结 构,并利用对抗的思想利用语义判别器进行语义结构的修正,同时利用修正 后的语义结构来进行合成照片成分损失的计算,实现了对合成照片语义修正 的自监督。
附图说明
18.图1是本发明实施例基于中间语义增强的人脸素描-照片合成方法基于中 间语义增强的人脸素描-照片合成方法整体框架图。
19.图2是本发明实施例中合成方法第一阶段dip-gan的网络结构示意图。
20.图3是本发明实施例中合成方法第二阶段se-gan的网络结构示意图。
具体实施方式
21.以下将以图式揭露本发明的实施方式,为明确说明起见,许多实务上的 细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用 以限制本发明。也就是说,在本发明的部分实施方式中,这些实务上的细节 是非必要的。
22.本发明是一种基于中间语义增强的人脸素描-照片合成方法,该包括如下 步骤:
23.步骤1、下载n个不同人的成对人脸素描-照片图片数据,并对素描图像 和照片图像进行预处理,使得人脸图像的尺寸一致、内容对齐,得到数据集, 表示为t:其中人脸素描数据集表示为s={s1,s2,...,s
t
,...,sn}, 人脸素描数据集表示为p={p1,p2,...,p
t
,...,pn}。本实施例中所采用的数据集 为香港中文大学公布的cufs数据集,艺术家根据人脸照片图像画出对应的 素描画像。cufs数据集公共具有606对素描-照片图像,包含了三个小数据 集:cuhk学生数据集188对、ar数据集123对、xm2vts数据集268对。 其中,
268对人脸图像用于模型的训练,剩余338对用于模型的测试和性能的 评估。所有图像尺寸均为200
×
250。
24.步骤2、利用预训练的人脸解析模型bisenet模型分别对人脸素描和人 脸照片进行语义分割,得到人脸素描和照片的语义分割图,分别表示为 fs={f
s1
,f
s2
,...,f
st
,...,f
sn
}和f
p
={f
p1
,f
p2
,...,f
pt
,...,f
pn
}。
25.所述的语义分割图,含有8个通道的特征,表示人脸分割后的一个组分, 包括头发、皮肤、眉毛、眼睛、鼻子、嘴巴、耳朵和背景。
26.s21、将数据集{s,fs,p,f
p
}进行插值,并将所有图像插值到256
×
256的分辨 率,并进行归一化处理。
27.步骤3:构建两阶段的生成对抗网络合成模型,包含第一阶段的dip-gan 网络和第二阶段的se-gan网络,如图1所示。
28.所述的第一阶段的dip-gan网络基于u-net架构,包含三个基本结构: 生成器g1、照片判别器d1和语义判别器d
par
,其中,所述生成器g1包含8 个编码器块和8个解码器块,所述编码器中的每一层包含1个卷积层(conv)、 1个批正则化层(bn)以及1个leaky relu激活层,解码器中的每一层包含 1个反卷积层、1个批正则化层以及1个leaky relu激活层,如图2中所示。
29.所述的第二阶段的se-gan网络,同样基于u-net架构,包含生成器g2和判别器d2,所述生成器g2有8个编码器块和8个解码器块构成,编码器和 解码器块的每一层与dip-gan网络中一致,生成器g2中对于语义和照片的 编码器的参数不共享,分别具有8个编码层,如图3所示。
30.步骤4:将素描图像s和根据素描图像s进行语义分割得到素描语义fs输入步骤3第一阶段的dip-gan网络,同时得到初始合成照片p’和中间语 义f
int
。
31.s41、dip网络包含网络具有2个输入,在编码器第一层分别将素描语义 fs输入第一个编码层enc1_1,素描s输入第一个编码层enc1_2。
[0032][0033]
s42、将编码器第一层得到的两种特征进行串联。
[0034]fe1
=concat(f
e11
,f
e12
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0035]
s43、将串联得到的特征f
e1
再通过编码器2-8层enc2-8,得到最终的特征 图f
map
。
[0036]fmap
=enc8(enc7(enc6(enc5(enc4(enc3(enc2(f
e1
)))))))
ꢀꢀ
(3)
[0037]
s44、将特征图f
map
再通过解码器第1-7层dec1-7得到f
d7
。
[0038]fd7
=dec7(dec6(dec5(dec4(dec3(dec2(dec1(f
map
),f
e7
),f
e6
),f
e5
),f
e4
),f
e3
),f
e2
)
ꢀꢀ
(4)
[0039]
需要注意的是,每一层的解码器均与对应的编码器进行跳连,即解码器 的输入包含上一层的输出和对应编码器层的输出。
[0040]
s45、将f
d7
分别通过解码器第8层dec8_1和dec8_2,得到中间语义f
int
和初始合成照片p’。
[0041][0042]
步骤5:进行第一阶段的合成判别,包括初始合成照片p’的判别以及合成 中间语义f
int
的判别d
par
,并计算第一阶段的对抗损失l
adv1
、风格损失l
per1
、 成分损失l
cmp1
以及语义匹配损失l
pm1
。
[0043]
步骤5-1:计算第一阶段的对抗损失l
adv1
:
[0044][0045]
式中,e表示期望,α为权重系数,用以权衡两个判别器的重要性,在本 实施例中设置为0.3。
[0046]
步骤5-2:计算初始合成照片p’的风格损失l
per1
:
[0047][0048]
式中,l表示利用vgg-19网络的第l层特征输出,a是选择的特征层集合, 包括vgg-19网络的conv1-1、conv3-4、conv4-1等,表示经过vgg-19网 络提取特征的操作。
[0049]
步骤5-3:计算初始合成照片p’的成分损失l
cmp1
:
[0050][0051]
式中,h、w是图像宽和高的像素个数,在本实施例中均为256;δ为权重 参数,在本实施例中设置为0.7。表示卷积操作,
⊙
表示点乘运算。
[0052]
步骤5-4:计算语义匹配损失l
pm1
:
[0053][0054]
式中,c为语义分割结构的通道数,β为权重系数,在本实施例中设置为 0.3。
[0055]
步骤5-5:计算第一阶段总体损失,即目标函数为上述损失的加权和:
[0056][0057]
式中,λ、γ、μ为平衡参数,在本实施例中,分别设置为10、5、10。
[0058]
步骤6:将第一阶段初始合成照片p’的合成结果和中间语义f
int
输入到第 二阶段的se-gan网络中的生成器g2,分别经过8个编码层,进行特征融合 之后,再经过8个解码层,得到最终的合成照片p”,并计算第二阶段的损失 函数。
[0059]
步骤6-1:对合成照片p”进行判别,并计算第二阶段的损失 l
adv2
、l
per2
、l
cmp2
。
[0060][0061]
l
per2
、l
cmp2
的计算方法与第一阶段相似,即将式(7)(8)中的初 始合成照片p’替换成最终合成的照片p”[0062][0063][0064]
式中,e表示期望,δ为权重系数;
[0065]
步骤6-2:计算第二阶段的目标函数:
[0066][0067]
式中:λ、γ为平衡参数。
[0068]
步骤7:以最大最小化目标函数为目标,利用反向传播算法,进行网络参 数更新和迭代训练,优化网络结构中的g1、d1、d
par
、g2、d2,采用迭代更 新的方式进行训练,训练的顺序为d1、d
par
→
d2→
g1→
g2;
[0069]
在本实施例中,使用adam优化器进行训练,动量β1=0.5、β2=0.999, batch_size=1。
[0070]
步骤8:在测试阶段,只需将人脸素描图像,经过bisenet网络,提取语 义图像,然后进行标准化,并缩放到统一尺寸256
×
256,直接连续输入到两个 生成器g1、生成器g2中,最终的输出结果即为合成的可见光照片图像。
[0071]
本实施例的实验平台为linux系统下的python3.6.3软件,本发明分析结 果不受操作系统以及python软件版本的影响。本实施例基于pytorch实现, 计算显卡为nvidia rtx2080ti,学习率设置为0.0002,迭代训练700个 epoch,训练结束,保存网络的参数。
[0072]
从实例测试结果可知,通过在第一合成阶段同时合成中间语义结构,并 利用对抗的思想构建语义判别器进行语义结构的修正,同时利用修正后的语 义结构来进行合成照片成分损失的计算,实现了对合成照片语义修正的自监 督。
[0073]
综上所述,本发明基于中间语义增强的人脸素描-照片合成方法解决素描 语义和照片语义之间存在的一定差异,通过在合成过程中修正语义结构信息, 能够合成准确的人脸结构,解决合成照片颜色混杂和结构不准确的问题。
[0074]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领 域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理 的内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范 围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。