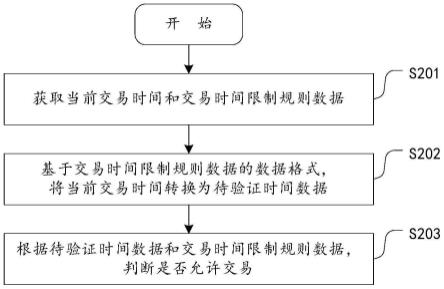
1.本发明涉及大数据处理系统和面向大规模数据处理的内存优化技术,具体说是一种 计算资源受限下大数据处理的细粒度缓存替换算法。
背景技术:
2.基于内存计算的大数据处理系统的缓存过程存在受限内存下的缓存需求。具体表 现为:大数据处理系统将数据处理的所有中间数据写入内存,利用内存资源加速数据处 理,这使得在内存资源有限的场景下,大规模数据处理应用的内存缓存决策问题尤为重 要。基于内存的缓存方式将应用产生的中间数据直接写入内存,得益于无需从磁盘中重 新加载数据的优势,该方式能够进一步减少大规模数据处理应用的完成时间。由于内存 资源往往是大数据处理系统的瓶颈,数据处理框架无法在应用执行过程中将所有中间数 据缓存到内存,而需在应用运行时动态替换需缓存数据。高效的缓存替换决策能够提高 内存使用效率,大幅减少大数据处理应用的执行时间,因此正受到越来越多研究关注。
3.在典型的大数据处理系统中,由于抽象数据集和内存数据块均可被缓存,因此,在 大数据处理应用中存在多粒度的缓存需求。计算资源与缓存数据的粒度存在关联。当计 算资源充足时,仅缓存抽象数据集的部分数据块并不会加速数据处理应用的整体运行, 这意味着在该场景下,应当考虑算子级别的粗粒度缓存替换问题。而在计算资源有限的 场景下,仅缓存抽象数据集的部分数据块即可加速数据处理应用的整体运行,因此在该 场景下,考虑数据块级别的细粒度缓存替换算法能进一步提升缓存性能。
4.针对大数据处理应用的缓存替换问题,已有研究工作的不足可总结为两点。首先, 已有缓存替换策略缺乏分析大数据处理应用中的并行执行模式,将数据处理阶段、任务 视为串行执行,这与大数据处理系统的真实缓存过程不符。其次,已有工作仅研究计算 资源充足场景下面向数据处理算子的粗粒度缓存替换问题,缺乏计算资源受限场景下的 相关缓存替换研究。
5.基于这样的技术背景,我们提出了一种计算资源受限大数据处理的细粒度缓存替换 算法,该算法考虑了计算资源对缓存性能产生的影响。针对计算资源受限场景下多阶段 并行式大数据处理应用的数据块级缓存替换问题,本发明提出了基于动态规划思想的细 粒度缓存替换算法。
技术实现要素:
6.针对大数据处理应用的缓存替换问题,本发明的目的是提供一种计算资源受限下大 数据处理的细粒度缓存替换算法,该算法同时考虑数据处理过程中的并行执行模式和计 算资源对缓存过程的影响,旨在提高大数据处理应用的缓存过程中内存资源使用效率, 进一步提升缓存性能,从而大幅减少数据处理应用的执行时间。
7.为实现上述目的,本发明的技术方案如下:
8.本发明首先为多任务并行式大数据处理应用中的并行执行模式建立数学形式模
型, 研究面向多任务并行式大数据处理应用的缓存替换问题。而后,本发明在计算资源受限 场景下考虑计算资源对缓存过程的影响,提出数据块级别的细粒度缓存替换算法。本发 明包括如下步骤:
9.一种计算资源受限下大数据处理的细粒度缓存替换算法,其特征在于:首先为多任 务并行式大数据处理应用中的并行执行模式建立数学形式模型,而后,在计算资源受限 场景下考虑计算资源对缓存过程的影响,提出数据块级别的细粒度缓存替换算法。包括 如下步骤:
10.(1)分析计算资源对缓存过程的影响:在面向大数据处理系统的缓存替换问题中, 得到计算资源与缓存粒度的关系,具体总结为:当计算资源充足时,仅缓存抽象数据 集的部分数据块无法加速数据处理过程,此时将缓存对象设为抽象数据集,考虑粗粒度 缓存替换算法;当计算资源受限时,仅缓存抽象数据集的部分数据块即可加快数据处理 应用的执行,此时将缓存对象设为内存数据块,考虑细粒度缓存替换算法;
11.(2)为细粒度缓存替换问题建立数学模型:首先以任务调度的方式在缓存替换问 题中对计算资源进行建模,而后通过大数据处理应用抽象而成的有向无环图g=(v,e) 蕴含的数据处理模式,分别对典型大数据处理中应用、作业、阶段、任务的执行时延和 待缓存数据块进行建模;在此基础上,细粒度缓存替换问题被定义为:在每个数据块b
t
计算完毕的时刻t,决策该时刻的待缓存数据块集合从而最小化数据块b
t
所在 的数据处理作业及后续所有作业的整体执行时延;
12.(3)基于大数据处理特征对缓存替换问题进行转换:由于面向计算资源受限场景 的细粒度缓存替换问题为np难问题,基于大数据处理算子的计算特征与面向数据块的 贪心缓存策略,将已建模的缓存替换问题转换为经典np完全问题的变种;考虑到已有 大量研究工作对经典np完全问题进行求解,因此我们可结合问题特征选择相应的求解 算法,从而降低了问题求解的难度。
13.(4)基于动态规划设计细粒度缓存替换算法:基于算子的计算特征与面向数据块 的贪心缓存策略将问题转化为有界背包问题的变种;该算法包含两大模块,分别为基于 数据处理特征的预处理模块和基于动态规划思想的细粒度缓存替换模块;其中,前者包 含基于算子计算特征的问题转换步骤和基于数据块贪心缓存策略的问题转换步骤;
14.(5)分析细粒度缓存替换算法的计算复杂度:基于动态规划思想的数据块级缓存 替换算法的计算复杂度由其包含的三大模块决定,与大数据处理应用中出现的数据块总 数量|b|、缓存空间的内存上限l相关,细粒度缓存替换算法的计算复杂度为o(|b|2×
l)。
15.进一步,步骤(1)中,计算资源对缓存过程的影响包括如下特征:
16.(11)在计算资源充足时,考虑算子级缓存替换算法:在计算资源充足的场景下, 同一数据处理阶段中多个数据处理任务的起始执行时刻和结束时刻均相同;此时,仅缓 存抽象数据集的部分数据块只能减少阶段中部分任务的执行时间,无法降低阶段整体执 行时延,因此无法加速数据处理应用的执行;在该场景下,在缓存数据时,要么不缓存 某个抽象数据集,要么缓存该抽象数据集的所有数据块,由于抽象数据集对应着数据处 理算子的计算结果,因此在计算资源充足时考虑算子级别的缓存替换算法;
17.(12)在计算资源有限时,应考虑数据块级别的缓存替换算法:在计算资源受限场 景下,系统会根据任务的计算资源需求对任务进行调度;同一阶段中多个任务的起始执 行
时刻存在差异,导致其结束时刻有所不同;此时,仅缓存抽象数据集的部分数据块也 能加快数据处理应用的执行;在该场景下,由于任务调度的影响,应考虑数据块级缓存 替换算法,因为该算法相较于算子级缓存替换算法粒度更细,存在更大优化空间;
18.步骤(2)中,面向多任务并行式大数据处理应用的细粒度缓存替换问题的数学形 式模型有如下特征:
19.(21)问题描述:在某个确定的大数据处理应用中,存在大量数据块的计算过程, 数据块被定义为b
i,j,k,q
;在时刻t,当数据块b
t
计算完毕时,大数据处理系统根据当前缓 存状态决定是否缓存该数据块,并在缓存空间即将溢出时对已缓存数据块进行替换;在 大数据处理应用的执行过程中,对已缓存数据块的每次替换等价于决策当前需缓存数据 将该决策问题定义为面向多任务并行式大数据处理应用的细粒度缓存替换问题;
20.(22)问题输入:大数据处理应用抽象而成的有向无环图g=(v,e),大数据处理 任务的起始执行时间集合{t
i,j,k
},在t时刻系统当前已缓存数据块集合在t时刻 待加入缓存空间的数据块b
t
,缓存空间的内存上限l;
21.(24)决策变量:在t时刻需缓存的数据块集合
22.(24)优化目标:最小化t时刻执行的作业即后续所有未执行作业的整体完成时间, 形式化表述为其中变量p
t
表示在t时刻执行的作业的下标, 变量|j|为大数据处理应用的作业集合,变量s
i,j
表示应用中第i个执行的作业ji的第j 个执行的数据处理阶段,变量mi为应用中第i个执行的作业ji包含的阶段数量,函数 z(s
i,j
,cs)表示在缓存数据块集合cs情况下,作业ji中阶段s
i,j
计算完成的时刻与作业ji开始执行时刻的差值,由输入数据g=(v,e)和{t
i,j,k
}计算而来;
23.(25)约束:面向大数据处理应用的细粒度缓存替换问题对决策变量、优化目标考 虑的作业集合及待缓存数据的内存上限均具有约束,具有如下特征:
24.d)在任意数据块b
t
计算完毕的时刻t,本发明使用决策变量表示,在时刻t 缓存空间中应缓存的数据块;假设表示,在时刻t未考虑数据块b
t
时,缓 存空间中已缓存的数据,变量t
*
为数据处理应用中所有数据块计算完毕的时 间集合;决策变量有如下约束关系:
[0025][0026]
e)优化目标仅考虑最小化应用的第p
t
个作业及后续未执行作业的整体完成时间, 变量p
t
的取值范围不超过应用中的数据处理作业的总数量,约束有如下约束关 系:
[0027][0028]
f)保证缓存决策中已缓存的数据集合不会超出缓存空间的内存上限;其中,函数 s
*
(b)表示数据块b所占内存空间,由大数据处理应用抽象而成的有向无环图 g=(v,e)提供,变量l表示缓存空间的内存上限,与待缓存数据的内存上限 相关的约束如下所示:
[0029]
[0030]
步骤(3)中,基于大数据处理特征对缓存替换问题的转换过程有如下特征:将面 向多任务并行式大数据处理应用的细粒度缓存替换问题定义为c1,假设大数据处理应用 中每个作业包含的阶段数量、每个阶段包含的抽象数据集的数量和每个阶段包含的任务 数量均为1,在此假设下问题c1的特例被定义为问题问题与0-1背包问题等价, 将0-1背包问题规约至问题c1,进而证明面向大数据处理应用的细粒度缓存替换问题为 np难问题;由于问题的复杂性,基于数据处理算子的计算特征与面向数据块的贪心缓 存策略对问题c1进行转换,使其更易于求解,问题转换步骤如下所示:
[0031]
(31)在数据处理算子的计算特征中,由于“作业关键路径”的时延可近似替代作 业整体时延,且“作业关键路径”中阶段均为串行执行;因此,将应用中每 个作业的所有阶段替换为“作业关键路径”后,数据处理阶段的执行模式从 并行变为串行,问题c1可转换为问题c2;
[0032]
(32)在数据处理算子的计算特征中,由于“热点访问数据”的缓存收益可近似替 代所有数据的缓存收益,且“热点访问数据”之间可近似视为串行计算;因 此,将每个阶段中计算的抽象数据集替换为“热点访问数据”后,数据处理 阶段中数据计算模式由并行变为串行,问题c2被转换为问题c3;
[0033]
(33)在数据处理算子的计算特征中,数据处理阶段中最终计算的数据所表示的算 子被称为“阶段代表性计算”;“阶段代表性计算”可近似替代阶段整体计 算;因此,将每个数据处理阶段中的“热点访问数据”替换为“阶段代表性 计算”的执行结果,即“阶段代表性数据”后,问题c3被转换为问题c4;
[0034]
(34)在数据块的计算特征中,同一阶段中优先定义的任务会被优先调度,因此同 一抽象数据集中优先定义的数据块会被优先计算;基于此特征,在给定某个 抽象数据集的可选数据块数量的情况下,由于阶段的执行时延由较晚定义的 任务决定,因此贪心选取该抽象数据集中较晚定义的数据块能够使缓存该数 据所节省的时间最大;基于上述面向数据块的贪心缓存策略,缓存收益的计 算复杂度由指数级别变为线性级别,问题c4可被转换为问题c5;更进一步地, 证明了问题c5是有界背包问题的变种。
[0035]
步骤(4)中,基于动态规划的细粒度缓存算法具有如下特征:基于数据处理特征 转换后的细粒度缓存替换问题c5是有界背包问题的变种,由于问题c5具有最优子结构, 该算法由基于数据处理特征的预处理模块和基于动态规划的细粒度缓存替换模块组成, 具体内容如下:
[0036]
(41)基于数据处理特征的预处理模块:该模块接受参数作业集合j、在t时刻缓 存空间中已有数据块和在t时刻待加入缓存空间的数据块b
t
;通过基于数据处理算 子的计算特征和基于数据块贪心缓存策略的问题转换步骤,该模块返回已分组的待缓存 数据块集合x
t
及其缓存收益v;而后,该模块将上述返回值作为基于动态规划思想的细 粒度缓存替换模块的输入;
[0037]
(42)基于动态规划思想的细粒度缓存替换模块:该模块接受基于数据处理特征的 预处理模块的输出,即已分组的待缓存数据块集合x
t
及其缓存收益v,并结合缓存空间 的内存上限l作为其输入;随着对区间[0,l]的每个整数和已分组的待缓存数据块集合 x
t
中每个元素的遍历,该模块通过动态规划将问题c5分解为多个子问题,从而得到最 优缓存决
时刻均相同。此时,仅缓存抽象数据集的部分数据块只能减少阶段中部分任 务的执行时间,无法降低阶段整体执行时延,因此无法加速数据处理应用的 执行。在该场景下,我们在缓存数据时,要么不缓存某个抽象数据集,要么 缓存该抽象数据集的所有数据块,由于抽象数据集对应着数据处理算子的计 算结果,因此我们在计算资源充足时应考虑算子级缓存替换算法。
[0049]
(2)在计算资源有限时,应考虑数据块级别的缓存替换算法:在计算资源受限场 景下,系统会根据任务的计算资源需求对任务进行调度。同一阶段中多个任 务的起始执行时刻存在差异,导致其结束时刻有所不同。此时,仅缓存抽象 数据集的部分数据块也能加快数据处理应用的执行。在该场景下,由于任务 调度的影响,应考虑数据块级缓存替换算法,因为该算法相较于算子级缓存 替换算法粒度更细,存在更大优化空间。
[0050]
基于计算资源与缓存粒度存在的联系,本发明将计算资源对缓存过程的影响概 括为在受限计算资源场景下存在细粒度缓存替换需求。由于已有工作已考虑计算资 源充足场景下面向算子的粗粒度缓存替换问题,为了填补计算资源受限场景下缓存 替换研究的空白,本发明在该场景下考虑计算资源对大数据处理应用中缓存过程的 影响,提出数据块级别的细粒度缓存替换算法。
[0051]
2、为细粒度缓存替换问题建立数学模型。
[0052]
细粒度缓存替换问题的数学模型包含对计算资源、待缓存数据块、任务执行时延、 阶段执行时延、作业执行时延及缓存替换问题的形式化描述,主要步骤如下:
[0053]
(1)计算资源建模:本发明观察到,计算资源对缓存问题产生的影响来源于调度 算法决策的任务起始时刻。本发明对调度算法进行抽象,仅关注在计算资源 受限场景下的调度结果——任务起始时刻{t
i,j,k
},以此考虑计算资源对缓存 过程的影响。相关符号如表1所示。
[0054]
符号定义t
i,j,k
任务t
i,j,k
的起始时刻(由任务调度算法提供)t
i,j,k
应用中阶段s
i,j
的第k个任务s
i,j
应用中作业ji的第j个阶段ji应用中第i个执行的作业
[0055]
表1.计算资源建模相关符号表
[0056]
(2)待缓存数据块建模:表1-表2展示了相关符号表,用于形式化为描述待缓存 数据块的缓存可选范围与缓存收益。
[0057]
a)对于某个确定的大数据处理应用,本发明假设在每个时刻t,数据块b
t
计 算完毕时,我们需决策缓存空间在考虑数据块b
t
后,应放入的数据块集 合该集合与t时刻缓存空间中未考虑b
t
前已缓存数据块集合 的关系应满足下式:
[0058][0059]
b)对于每个在任务t
i,j,k
中的数据块b,本发明定义了其计算时间—— λ(b,t
i,j,k
)与缓存收益(缓存该数据块所节省的时间)——δ(b,t
i,j,k
)。 用于描述在缓存不同数据块情况下的任务执行时延,进而为缓存决策提 供指导信息。数据块的计算时间与缓存收益的关系如下所示:
[0060][0061][0062]
表2.待缓存数据块建模相关符号表
[0063]
(3)任务执行时延建模:在应用的每个任务中,存在一个不被该任务中任何其他 数据块依赖的数据块,被称为该任务的最终计算数据块。在此基础上,任务 的执行时延可与该任务的最终计算数据块相关联。任务t
i,j,k
在缓存数据块集 合cs下的执行时延等于任务t
i,j,k
中最终计算数据块计算完成的时刻 与任务t
i,j,k
开始执行时刻的差值,形式化表述为相关符 号如表1-表3所示,递归函数k(t
i,j,k
,b
i,j,k,q
,cs)用于建模任务内的多数据块 并行计算现象,其形式化描述如下所示:
[0064][0065][0066][0067]
表3.任务执行时延建模相关符号表
[0068]
(4)阶段执行时延建模:本发明通过表1-表4的相关符号对阶段执行时延进行建 模。阶段执行时延可与阶段内任务起始时刻与执行时间相关联。阶段s
i,j
在缓 存数据块集合cs下的执行时延等于该阶段中最大任务结束执行时刻与该阶 段中最小任务起始时刻的差值,形式化表述为γ(s
i,j
,cs),如下所示:
[0069]
[0070]
符号定义r
i,j
应用中阶段s
i,j
包含的任务数量γ(s
i,j
,cs)缓存数据块集合cs情况下,阶段s
i,j
执行所需时间
[0071]
表4.阶段执行时延建模相关符号表
[0072]
(5)作业执行时延建模:在缓存不同数据块情况下,本发明通过表1-表5相关符 号对作业执行时延进行建模。首先,我们将作业执行时延与该作业的最终执 行阶段相关联,作业ji在缓存数据块集合cs下的执行时延等于阶段的 完成时刻与作业ji开始执行时刻的差值,形式化表述为其中, 递归函数z(s
i,j
,cs)被用于建模作业内的多阶段并行执行现象,其形式化描述 如下所示:
[0073][0074][0075]
表5.作业执行时延建模相关符号表
[0076]
(6)细粒度缓存替换问题建模
[0077]
问题描述:在计算资源有限的场景下,基于大数据处理应用的缓存过程中计算资源、 数据块、任务、阶段、作业的建模,本发明通过表1-表6中相关符号,对数据块级别的 细粒度缓存替换问题进行建模。对于某个确定的大数据处理应用,假设数据块b
t
在时刻 t计算完成,而在时刻t使用数据块b
t
的作业为大数据处理应用的第p
t
个作业。那么,在 计算资源有限场景下,面向数据处理应用的数据块级别缓存替换问题c1可被表述为在每 个数据块计算完成的时刻t决策存入缓存空间的数据块集合以最小化该应用自 第p
t
个作业起后续作业的总体完成时间(包括第p
t
个作业)。问题c1的形式化描述如 下:
[0078]
c1:
[0079][0080][0081][0082]
符号定义s
*
(b)数据块b所占用的内存大小l缓存空间的总内存上限p
t
在时刻t执行的作业的下标
[0083]
表6.细粒度缓存替换问题c1相关符号表
[0084]
问题输入:大数据处理应用抽象而成的有向无环图g=(v,e)、大数据处理任务的 起始执行时间集合{t
i,j,k
}(该两项输入用于计算作业时延),在t时刻系统当前已缓存 数据块集合在t时刻待加入缓存空间的数据块b
t
,缓存空间的内存上限l。
[0085]
决策变量:在t时刻需缓存的数据块集合
[0086]
优化目标:最小化t时刻执行的作业即后续所有未执行作业的整体完成时间,形式 化表述为函数z(s
i,j
,cs)表示在缓存数据块集合cs情况下, 作业ji中阶段s
i,j
计算完成的时刻与作业ji开始执行时刻的差值,由输入数据g=(v,e)和{t
i,j,k
}计算而来。
[0087]
问题约束:面向多任务并行式大数据处理任务的细粒度缓存替换问题对决策变量、 优化目标考虑的作业集合及待缓存数据的内存上限均具有约束,具有如下特征:
[0088]
1)在任意数据块b
t
计算完毕的时刻t,本发明使用决策变量表示在时刻t缓 存空间中应缓存的数据块。决策变量有如下约束关系:
[0089][0090]
2)优化目标仅考虑最小化应用的第p
t
个作业及后续未执行作业的整体完成时间, 变量p
t
的取值范围不超过应用中的数据处理作业的总数量,变量p
t
有如下约束关系:
[0091][0092]
需保证缓存决策中已缓存的数据集合不会超出缓存空间的内存上限。与待缓存数据 的内存上限相关的约束如下所示:
[0093][0094]
3、基于数据处理特征对缓存替换问题进行转换。
[0095]
假设大数据处理应用中每个作业包含的阶段数量、每个阶段包含的抽象数据集数量 和每个阶段包含的任务数量均为1,在此假设下,本发明观察到问题c1的特例问题与 0-1背包问题等价,因此可将0-1背包问题规约至问题c1,进而证明问题c1为np难问 题。由于问题的复杂性,我们基于数据处理算子的计算特征与面向数据块的贪心缓存策 略对问题c1进行转换,使其更易于求解,问题转换步骤如下所示:
[0096]
(1)在数据处理算子的计算特征中,“作业关键路径”被定义为该作业中执行时 间最长的阶段计算链。由于“作业关键路径”的时延可近似替代作业整体时 延,且“作业关键路径”中阶段均为串行执行。因此,我们将应用中每个作 业ji的阶段集合替换为“作业关键路径”后,阶段 执行模式从并行变为串行,问题c1可转换为问题c2,如下所示:
[0097]
c2:
[0098][0099][0100][0101]
(2)在数据处理算子的计算特征中,“热点访问数据”被定义为应用抽象而成的 有向无环图中出度大于1的节点所表示的抽象数据集。由于“热点访问数据
”ꢀ
的缓存收益可近似替代所有数据的缓存收益,且“热点访问数据”之间可近 似视为串行计算。因此,将每个阶段中计算的抽象数据集替换为“热点访问 数据”后,数据处理阶段中数据计算模式由并行变为串行。为了便于问题的 形式化,我们将优化目标中的“最小化作业整体完成时间”等价替换为“最 大化缓存数据所节省的时间”。在此基础上,问题c2被转换为问题c3,如 下所示:
[0102]
c3:
[0103][0104][0105][0106]
在问题c3中,相关符号定义如表7所示。表达式可 等价转换为变 量定义了任务t
′
i,j,k
的结束时刻,详细内容为函数 与定义了任务t
′
i,j,k
中“热点访问数据块”的下 标组成的集合,如下所示:
[0107][0108][0109][0110]
[0111]
表7.细粒度缓存替换问题c3相关符号表
[0112]
(3)在数据处理算子的计算特征中,数据处理阶段中最终计算的数据所表示的算 子被称为“阶段代表性计算”。本发明观察到,“阶段代表性计算”可近似 替代阶段整体计算。本发明将变量定义为阶段s
′
i,j
的结束执行时间,即阶 段s
′
i,j
中所有任务结束执行时间的最大值,将函数η
*
(b,cs) 定义为数据块b是否为数据块集合cs的元素之一(1为是,0为否),变量r
′
i,j
表示阶段s
′
i,j
包含的任务数量。在此基础上,本发明将数据处理阶段中的“热 点访问数据”替换为“阶段代表性计算”的执行结果,即“阶段代表性数据
”ꢀ
后,问题c3被转换为问题c4,如下所示:
[0113]
c4:
[0114][0115][0116][0117]
(4)在数据块的计算特征中,同一阶段中优先定义的任务会被优先调度,因此同 一抽象数据集中优先定义的数据块会被优先计算。基于此特征,在给定某个 抽象数据集可选数据块数量的情况下,由于阶段的执行时延由较晚定义的任 务决定,因此贪心选取该抽象数据集中较晚定义的数据块能够使缓存该数据 所节省的时间最大。基于上述面向数据块的贪心缓存策略,缓存收益的计算 复杂度由指数级别变为线性级别,问题c4可被转换为问题c5,如下所示:
[0118]
c5:
[0119][0120][0121][0122][0123][0124]
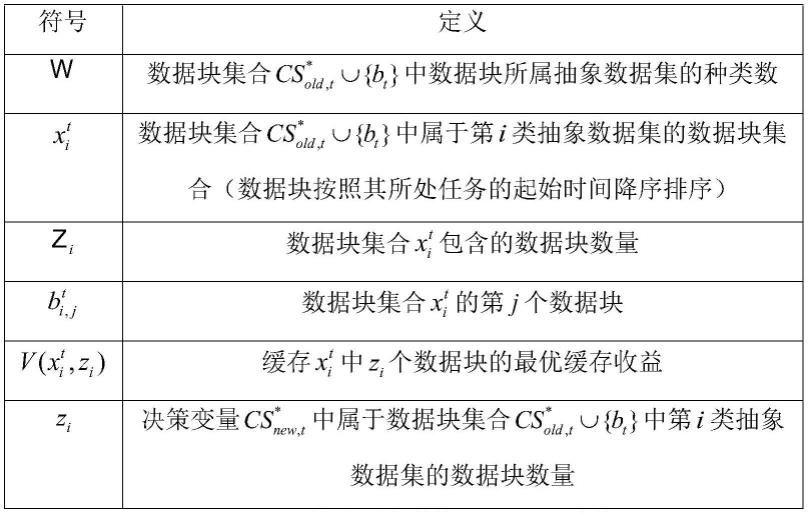
其中,是 问题c5中函数的详细定义,在给定变量和zi后,为确定 值。相关符号见表8所示:
[0125][0126]
表8.细粒度缓存替换问题c5相关符号表
[0127]
在有界背包问题中,假设存在n种物品与一个可承受重量为w的背包,每 种物品j的重量、价值和最大可选取件数分别为wj、pj和yj。我们使用决 策变量yj表示每种物品j放入背包的件数。基于此,该问题的目标是在背包 可承载范围内,最大化放入背包的物品总价值,形式化表述如下:
[0128][0129][0130][0131]
我们发现有界背包问题的优化目标可转换成问题c5中优化目标 的形式,即其中函数v
′
(pj,yj)=pj×
yj。此外, 有界背包问题的约束条件问题c5的约束条件相对应,每种物品j与问题c5中数据集合的第i类抽象数据集相对应。因此,问题是有 界背包问题的变种,其与有界背包问题的区别在于函数
[0132][0133]
4、基于动态规划思想设计细粒度缓存替换算法。
[0134]
基于数据处理特征转换后的细粒度缓存替换问题c5是有界背包问题的变种,由于问 题c5具有最优子结构,本发明设计了基于动态规划思想的细粒度缓存替换算法。该算 法由基于数据处理特征的预处理模块和基于动态规划思想的细粒度缓存替换模块组成, 具体内容如下所示:
[0135]
(1)基于数据处理特征的预处理模块:该模块接受参数作业集合j、在t时刻缓 存
空间中已有数据块集合和在t时刻待加入缓存空间的数据块b
t
。通过 基于数据处理算子计算特征和基于数据块贪心缓存策略的问题转换步骤,该 模块返回已分组的待缓存数据块集合x
t
及其缓存收益v。而后,该模块将上 述返回值作为基于动态规划思想的细粒度缓存替换模块的输入,具体步骤如 下:
[0136]
a.接受输入j、和b
t
[0137]
b.初始化“阶段代表性数据块”x'、待缓存数据块的缓存收益v
[0138]
c.根据集合中数据块所属抽象数据集的类别对数据块进行分类, 得到已分组的待缓存数据块集合x
t
[0139]
d.通过最长路径算法计算j的“作业关键路径”cp
[0140]
e.根据j表示的有向无环图统计“热点访问数据”hd
[0141]
f.统计t时刻作业集合j中未完成的作业j
t
[0142]
g.对j
t
中每个作业ji中未执行完毕且属于cp的阶段s'
i,j
执行下列操作
[0143]
a)统计阶段s'
i,j
中所有数据的拓扑序列tp
[0144]
b)获取序列tp∩(cs
old,t
∪{x
t
})∩hd的末尾元素xu[0145]
c)更新x':x'
←
x'∪{xu}
[0146]
h.对x
t
中每种抽象数据集包含的数据块集合执行下列操作
[0147]
a)获取j
t
中每个作业ji中未执行完毕且属于cp的每个阶段s'
i,j
[0148]
b)从k=1到循环执行更新待缓存数据块的缓存收益v: v
i,k
←vi,k
在阶段s
′
i,j
中缓存数据块集合的收益
[0149]
i.输出已分组的待缓存数据块集合x
t
及其缓存收益v
[0150]
(2)基于动态规划思想的细粒度缓存替换模块:该模块接受预处理模块的输出, 即已分组的待缓存数据块集合x
t
及其缓存收益v,并结合缓存空间的内存上 限l作为其输入。随着对区间[0,l]的每个整数和已分组的待缓存数据块集合 x
t
中每个元素的遍历,该模块通过动态规划将问题c5分解为多个子问题,从 而得到最优缓存决策具体步骤如下:
[0151]
a.接受输入:已分组的待缓存数据块集合x
t
、待缓存数据块的缓存收益v及 缓存空间内存上限l
[0152]
b.初始化动态规划数组dp、子问题最优结果集合c、x
t
中数据块所属抽象 数据集种类数n
[0153]
c.从i=1到n、j=1到l循环执行下列操作
[0154]
a)初始化每类抽象数据集缓存的数据块数c为0、变量dp
i,j
为1
[0155]
b)从k=1到循环执行下列操作
[0156]
i.k
←
k 1
[0157]
ii.若执行如下操作:
[0158]
[0159]
c)若c==0,执行如下操作:
[0160]ci,j
←ci-1,j
[0161]
d)否则,执行如下操作:
[0162][0163]
d.输出最优缓存决策:c
n,l
[0164]
5、分析细粒度缓存替换算法的计算复杂度。
[0165]
基于动态规划思想的数据块级缓存替换算法的计算复杂度由基于数据处理特征的预 处理模块和基于动态规划思想的细粒度缓存替换模块共同决定。假设大数据处理应用中
ꢀ“
热点访问数据”的数量为|v|,其包含的数据块总数量为|b|、缓存空间的内存上限为 l。易知,基于数据处理特征的预处理模块包含两项步骤,分别为基于数据处理算子计 算特征和基于数据块贪心缓存策略的问题转换步骤。前者的计算复杂度为o(|v|2),后 者为o(|b|2)。基于动态规划思想的细粒度缓存替换模块的计算复杂度由动态规划算法 的搜索空间决定,具体为o(|b|2×
l)。因此,计算资源受限场景下的数据块级别的细粒 度缓存替换算法的计算复杂度为o(|b|2×
l)。
[0166]
下面结合实例和附图对本发明作更进一步的说明。本发明是计算资源受限场景下面 向大数据处理框架的细粒度缓存替换问题研究。如图2所示,左侧表示大数据处理应用 抽象而成的有向无环图,包含由应用、作业、阶段、任务、数据、数据块组成的层次信 息和任务的计算资源需求。当计算资源有限时,系统会根据任务的计算资源需求对任务 进行调度,输出右侧的任务调度结果。在图2示例中,系统总cpu核数为11,任务所 需的cpu核数与执行时间均已在有向无环图中标注。通过dagon调度算法,图2右侧 展示了大数据处理作业的任务调度结果。在图中,横轴为时间线,纵轴为计算资源,带 有形如“sab”的标注的矩形表示数据处理阶段a的第b个任务,矩形的长度表示持 续时间,宽度表示任务所需cpu核数。例如阶段53的第一个任务“s531”的起始执 行时刻为0,其他任务的起始执行时刻以此类推。
[0167]
图2同样展示了细粒度缓存替换问题的数学建模。我们发现,当应用执行时,大数 据处理框架将运行时产生的中间数据块存入缓存空间用于加速应用执行,利用有限内存 执行缓存加速存在取舍问题。例如,在图2中,当阶段56的第三个任务执行,抽象数 据集f的第三个数据块(f3)计算完毕且需要缓存时,若此时缓存空间即将耗尽,则 需决策应当存入缓存空间的数据。在图2中,本发明首先以任务调度的方式引入任务起 始执行时刻,在缓存替换问题中对计算资源进行建模。而后通过大数据处理应用抽象而 成的有向无环图g=(v,e)蕴含的数据处理模式,分别对大数据处理应用、作业、阶段、 任务的执行时延和待缓存数据块进行建模。在此基础上,细粒度缓存替换问题被定义为: 在每个数据块b
t
计算完毕的时刻t,决策该时刻的待缓存数据块集合从而最小 化数据块b
t
所在的数据处理作业及后续所有作业的整体执行时延。
[0168]
由于建模后的缓存替换问题c1是np难问题,针对上述有向无环图,本发明基于数 据处理算子的计算特征——“作业关键路径”、“热点访问数据”和“阶段代表性计算
”ꢀ
中存在的特征,对问题进行转换。图3展示了“作业关键路径”、“热点访问数据”和
ꢀ“
阶段代表性计算”的具体内容。在此基础上,图4展示了基于数据块贪心缓存策略的 问题转换细节。在
给定某个抽象数据集可选数据块数量的情况下,由于阶段的执行时延 由较晚定义的任务决定,因此贪心选取该抽象数据集中较晚定义的数据块能够使缓存该 数据所节省的时间最大。基于上述与数据处理特征相关的问题转换思路,原问题被转换 为有界背包问题的变种。
[0169]
已简化后的问题具有最优子结构,图5展示了基于动态规划思想的细粒度缓存替换 算法流程。经过基于数据处理特征的预处理步骤后,该算法接受已分组的待缓存数据块 集合x
t
及其缓存收益v,同时结合缓存空间的内存上限l作为其输入。随着对缓存空间 的内存上限l的每个值和已分组的待缓存数据块集合x
t
中每个数据块的遍历,该模块通 过动态规划将缓存替换问题分解为多个子问题,从而得到问题c5的最优缓存决策 cs
new,t
。
[0170]
由于内存资源有限,在大数据处理应用中利用内存资源进行缓存加速存在取舍问题。 已有相关研究并未考虑计算资源对缓存过程的影响,因此仅研究算子级缓存替换问题。 为了填补计算资源受限场景下缓存替换研究的空白,本发明在该场景下考虑计算资源对 大数据处理应用中缓存过程的影响。本发明发现,在计算资源有限的场景下,大数据处 理框架会对应用中的任务进行调度,在调度策略影响下,仅缓存某个抽象数据集的部分 数据块可减少该数据所在阶段的执行时间,进而加速数据处理应用的执行。因此本发明 研究了计算资源受限场景下的细粒度缓存替换问题,该问题将缓存对象设置为数据块, 在数据处理应用执行时动态决策需缓存数据。相较于粗粒度的算子级缓存替换问题,细 粒度的数据块级缓存问题更难。因此,本发明利用基于数据处理算子的计算特征与面向 数据块的贪心缓存策略,将已建模的缓存替换问题转换为经典np完全问题的变种。由 于经过简化后的问题具有最优子结构,本发明设计了基于动态规划思想的细粒度缓存替 换算法解决该问题。
[0171]
以上详细描述了本发明的实施方案,但本发明并不限于上述实施方式中的具体细节, 在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变 换均属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。