1.本发明涉及一种对象追踪算法,且特别是涉及一种影像识别方法。
背景技术:
2.手势与手姿态相关的研究与应用是一种与计算机系统沟通的方式。随着增强现实(augmented reality,ar)、虚拟现实(virtual reality,vr)、大屏显示系统等计算机视觉技术的发展,市面上关于手的应用渐渐从以往的手势辨识(hand gesture recognition)朝向手姿态估测与追踪(hand pose estimation and tracking)发展。比起单纯的辨识手势,如果可以知道整个手的状态,例如每个指节(joint)点的位置,将可利用双手来进行更自然、更流畅的操作,并进一步提高应用范围。
3.一般而言,传统的手姿态追踪系统需经过至少两个阶段的模型处理,即,手部检测模型以及指节检测模型。先利用手部检测模型检测各图像中的手部位置,接着,利用指节检测模型计算各个手的指节点在二维或三维空间中的实际位置,之后将其结果传送给系统做后续的辨识或操作的动作。
4.然而,由于计算机视觉技术的要求越来越高,既要有实时性,还要兼顾高帧频(frames per second,fps)的分析辨识。因此,现有两阶段处理的手姿态追踪系统可能会造成高延迟性且降低使用者的用户体验(quality of experience,qoe),且其过程也涉及一些复杂的前处理或后处理,难以应用于手机或vr/ar眼镜等消费者终端上。
[0005]“背景技术”部分只是用来帮助了解本
技术实现要素:
,因此在“背景技术”部分所公开的内容可能包含一些没有构成所属技术领域中普通技术人员所知道的现有技术。在“背景技术”部分所揭露的内容,不代表该内容或者本发明一个或多个实施例所要解决的问题,在本发明申请前已被所属技术领域中普通技术人员所知晓或认知。
发明内容
[0006]
本发明提供一种影像识别方法,可通过一个阶段来找出影像中之目标物所包括的子目标的位置。
[0007]
本发明的实施例的影像识别方法包括:输入影像至检测模型而获得热图张量、参考深度张量、权重张量以及子目标张量;自热图张量获得k个位置索引值;基于权重张量以及子目标张量,获得融合张量;基于融合张量与参考深度张量,获得预测深度张量;参考k个位置索引值,自预测深度张量中取出k个向量;以及对所述k个向量执行投影矩阵的转换,以获得真实空间中的k个坐标向量。在此,热图张量包括用以预测影像的多个位置索引值对应的多个区块中出现目标物的多个机率值,目标物中包括多个子目标。参考深度张量包括每一区块对应的第一深度值,其为预测拍摄所述影像的取像装置与每一区块之间的距离。权重张量包括用以对所述子目标进行优化的多个权值。子目标张量包括用以预测所述子目标在影像中的多个坐标位置及所述子目标的第二深度值。所述融合张量包括基于所述权值与所述第二深度值而获得的多个融合深度值。所述预测深度张量包括基于所述融合深度值与
所述第一深度值而获得的多个预测深度值。
[0008]
利用上述实施例的方法能够通过一次性的推理同时完成两种任务,分别为检测目标物以及检测目标物中所包括的子目标,而无需基于个别的任务来建立模型。
附图说明
[0009]
图1是依照本发明一实施例的电子装置的方块图。
[0010]
图2是依照本发明一实施例的影像识别方法的流程图。
[0011]
图3是依照本发明一实施例的影像识别模型的架构图。
[0012]
图4是依照本发明一实施例的手的指节点的示意图。
[0013]
图5a及图5b是依照本发明一实施例的检测结果的示意图。
[0014]
附图标记说明
[0015]
100:电子装置
[0016]
110:处理器
[0017]
120:存储器
[0018]
300:影像
[0019]
310:检测模型
[0020]
320:热图张量
[0021]
330:参考深度张量
[0022]
340:权重张量
[0023]
350:子目标张量
[0024]
360:位置索引清单
[0025]
370:融合张量
[0026]
380:预测深度张量
[0027]
390:目标清单
[0028]
j01~j21:指节点
[0029]
s205~s230:影像识别方法的步骤
具体实施方式
[0030]
有关本发明之前述及其他技术内容、特点与功效,在以下配合附图之较佳实施例的详细说明中,将可清楚的呈现。以下实施例中所提到的方向用语,例如:上、下、左、右、前或后等,仅是参考附图的方向。因此,使用的方向用语是用来说明并非用来限制本发明。
[0031]
本发明提出一种影像识别方法,其可通过电子装置来实现。为了使本发明之内容更为明了,以下特举实施例作为本发明确实能够据以实施的范例。
[0032]
图1是依照本发明一实施例的电子装置的方块图。请参照图1,电子装置100包括处理器110以及存储器120。处理器110耦接至存储器120。
[0033]
处理器110可以是具备运算处理能力的硬件(例如芯片组、处理器等)、软件组件(例如操作系统、应用程序等),或硬件及软件组件的组合。处理器110例如是中央处理单元(central processing unit,cpu)、图形处理单元(graphics processing unit,gpu),或是其他可编程的微处理器(microprocessor)、数字信号处理器(digital signal processor,
dsp)、可编程控制器、专用集成电路(application specific integrated circuits,asic)、可编程逻辑器件(programmable logic device,pld)或其他类似装置。
[0034]
存储器120例如是任意型式的固定式或可移动式随机存取存储器、只读存储器、闪存、安全数字卡、硬盘或其他类似装置或这些装置的组合。存储器120中储存有多个程序代码段,而上述程序代码段在被安装后,由处理器110来执行,藉此来执行显示影像识别方法。
[0035]
图2是依照本发明一实施例的影像识别方法的流程图。图3是依照本发明一实施例的影像识别模型的架构图。本实施例的影像识别模型为一阶段的神经网络(neural network,nn)模型。影像识别模型的输入为二维的任意类型的影像300,输出的目标清单390包括根据机率值排名的多个子目标组合。
[0036]
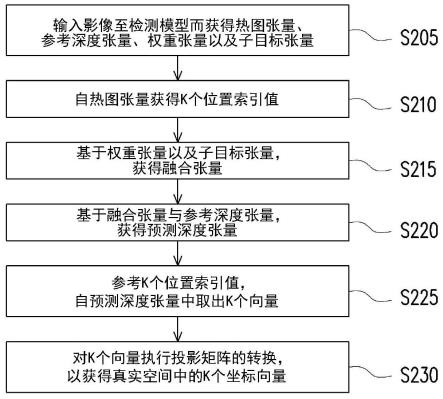
请参照图2及图3,在步骤s205中,输入影像300至检测模型310而获得热图(heat-map)张量320、参考深度张量330、权重张量340以及子目标张量350。在此,影像300的张量维度例如为[h,l,c]。其中,h是影像的高度(height),l是影像的宽度(length),c是影像的通道数(channel)。例如,倘若输入来源是彩色影像(rgb-based image),则c=3。倘若输入来源是深度影像(depth-based image),则c=1。
[0037]
热图张量320包括用以预测影像300的多个位置索引值对应的多个区块中出现目标物的多个机率值。所述目标物还包括多个子目标。参考深度张量330包括影像300的每一区块对应的第一深度值(作为参考深度)。所述第一深度值为预测拍摄影像300的取像装置与各区块之间的距离。权重张量340包括用以对多个子目标进行优化的多个权值。子目标张量350包括用以预测各子目标在影像300中的坐标位置及对应于各子目标的第二深度值。
[0038]
检测模型310为基于卷积神经网络(convolutional neural network,cnn)的特征提取器。检测模型310的架构部分类似于yolo第四版(yolov4)算法。检测模型310是单一输入多个输出的模型架构,且多个输出的张量均会缩小整数s倍。例如,以影像300的分辨率为h
×
l而言,所获得的热图张量320、参考深度张量330、权重张量340以及子目标张量350的分辨率皆为h/s
×
l/s。
[0039]
如果输入(影像300)的装置来源是彩色取像装置(彩色相机),就使用彩色影像的数据集来训练检测模型310。如果输入(影像300)的装置来源是深度取像装置,就用深度影像的数据集来训练检测模型310。每个数据集包含多个目标物的三维位置以及取像装置的投影矩阵(projection matrix)。
[0040]
在此,检测的目标物为手,子目标为手的指节点。图4是依照本发明一实施例的定义手的指节点的示意图。手的指节点的定义可如图4所示的21个指节点j01~j21。利用本实施例的影像识别模型可在影像300中检测出k只手及其各自对应的21个指节点。
[0041]
热图张量320包括用以预测出现手的机率值,参考深度张量330包括用以预测拍摄影像300的取像装置距离手的距离(第一深度值),权重张量340包括用以对指节点进行优化的权值,子目标张量350包括用以预测各指节点在影像300中的坐标位置及对应于各指节点的第二深度值。对应于各指节点的第二深度值指的是各个指节点到手腕的距离。
[0042]
热图张量320的张量维度为[h/s,l/s,2],其中,第1、2个维度代表区块的位置索引值(i,j),i={1,2,...,h/s},j={1,2,...,l/s},第3个维度“2”代表每一个位置索引值(i,j)对应至两种目标物(即“左手”和“右手”)出现的机率值。即,影像300被输入至检测模型310而被切分成等大小为h/s
×
l/s的区块,并对每一个区块估测两个机率值,即,出现左手
的机率值及出现右手的机率值。故,热图张量320包括h/s
×
l/s
×
2个区块数据。所述机率值位于为0~1之间。
[0043]
参考深度张量330的张量维度为[h/s,l/s,1],其中,第1、2个维度代表区块的位置索引值(i,j),第3个维度“1”代表每一个位置索引值(i,j)代表的区块对应至1个第一深度值。参考深度张量330包括h/s
×
l/s
×
1个第一深度值。
[0044]
权重张量340的张量维度为[h/s,l/s,n],其中,第1、2个维度代表区块的位置索引值(i,j),第3个维度“n”代表每一个位置索引值(i,j)代表的区块所包括的n个指节点对应的优化用的权值。权重张量340包括h/s
×
l/s
×
n个权值。
[0045]
子目标张量350的张量维度为[h/s,l/s,n,3],其中,第1、2个维度代表区块的位置索引值(i,j),第3个维度“n”代表每一个位置索引值(i,j)代表的区块对应至n个指节点,第4个维度“3”代表用以预测各指节点于x、y、z三者的坐标位置。子目标张量350包括h/s
×
l/s
×
n组的坐标位置(x,y,z),其中,x、y代表指节点在影像中的位置,z代表指节点的深度值(即,第二深度值)。
[0046]
接着,在步骤s210中,自热图张量320获得k个位置索引值。例如,根据热图张量320所包括的h/s
×
l/s
×
2个区块数据中,以具有最高机率值的区块数据起,取出k个区块数据对应的k个位置索引值记录至位置索引清单360。其中,k为目标物(例如:手)的数量。例如,位置索引清单360记录有:位置索引值(gx_1,gy_1)、(gx_2,gy_2)、
…
、(gx_k,gy_k)。
[0047]
在步骤s215中,基于权重张量340以及子目标张量350,获得融合张量370。在此,利用下述公式对于权重张量340以及子目标张量350进行卷积,藉此获得融合张量370。融合张量370包括基于所述权值与所述第二深度值而获得的多个融合深度值。
[0048][0049]
其中,ks为核大小(kernel size),w为权重张量340,v为子目标张量350,a={1,2,...,h/s},b={1,2,...,l/s},c={1,2,...,n},n为子目标数量(即,指节点的数量),d={1,2,3}(代表x、y、z三轴)。o(a,b,c,d)为融合张量370。融合张量370的张量维度为[h/s,l/s,n,3]。第4个维度“3”代表用以预测各指节点于x、y、z三轴的坐标位置,z所对应的深度值为经卷积后的融合深度值。
[0050]
之后,在步骤s220中,基于融合张量370与参考深度张量330,获得预测深度张量380。预测深度张量380包括基于所述融合深度值与所述第一深度值而获得的多个预测深度值。具体而言,将融合张量370中各位置索引值对应的融合深度值(即,融合张量370的第4个维度中的z值)与参考深度张量330中各位置索引值对应的第一深度值(即,参考深度张量330的第3个维度的值)相加,而获得预测深度张量380。这是因为,取像装置到指节点的预测深度值会是取像装置与手之间的距离(第一深度值)和各个指节点到手腕的距离(融合深度值)的相加结果。
[0051]
最后,在步骤s225中,参考位置索引值,自预测深度张量380中取出k个向量。根据自热图张量320所获得的位置索引清单360所记载的位置索引值,自预测深度张量380中取出对应的k个向量,进而获得目标清单390。每一个向量中皆记录了n个指节点的位置。例如,
目标清单390包括向量(j_1_1,j_1_2,...j_1_n)、向量(j_2_1,j_2_2,...j_2_n)、
…
、向量(j_k_1,j_k_2,...j_k_n)。
[0052]
以位置索引清单360的第1个位置索引值(gx_1,gy_1)而言,其对应的向量为(j_1_1,j_1_2,...j_1_n),“j_1_1”、“j_1_2”、
…
、“j_1_n”分别表示位置索引值(gx_1,gy_1)的n个指节点的位置。以位置索引清单360的第2个位置索引值(gx_2,gy_2)而言,其对应向量为(j_2_1,j_2_2,...j_2_n),“j_2_1”、“j_2_2”、
…
、“j_2_n”分别表示位置索引值(gx_2,gy_2)的n个指节点的位置。以位置索引清单360的第k个位置索引值(gx_k,gy_k)而言,其对应向量为(j_k_1,j_k_2,...j_k_n),“j_k_1”、“j_k_2”、
…
、“j_k_n”分别表示位置索引值(gx_k,gy_k)的n个指节点的位置。
[0053]
图5a及图5b是依照本发明一实施例的检测结果的示意图。图5a所示为一只手的检测结果。图5b所示为两只手的检测结果。通过上述方式可在影像中确实检测到一个或多个手的指节点。
[0054]
之后,在步骤s230中,对所述k个向量执行投影矩阵(projection matrix)的转换,以获得真实空间中的k个坐标向量。通过上述步骤,可以追踪输入的影像300上所出现的手部姿态。
[0055]
综上所述,本发明的实施例能够通过一次性的推理同时完成两种任务,分别为检测目标物以及检测目标物中所包括的子目标,而无需基于个别的任务来建立模型。据此,将本发明的实施例应用于多手姿态追踪上,将任意类型的影像输入便能够输出多个根据机率值排名后在影像上的手指节组合。
[0056]
此外,本发明的实施例只要知道输入来源是彩色影像及深度影像中其中一种类型,便能够根据输入来源的类型来选定同类型的数据集来重新训练模型,在无须更动cnn模型架构下,本发明的实施例使用的架构依然能一次性完成手部检测和手指节回归。
[0057]
由于本发明的实施例的中间过程不需要对象检测的边界框所撷取出的子图像,因此不会出现撷取到较差的子图像从而降低手指节估测精度下降的问题。在一张影像出现k只手的情况下,传统的多手姿态追踪系统需要执行k 1次的模型运算,反观本发明的实施例,其可在经1次的运算后便能同时获得k只手及其手指节的位置。故,本发明的实施例可降低在消费者终端上的延迟性,并提高用户体验质量。
[0058]
以上所述仅为本发明之较佳实施例而已,当不能以此限定本发明实施之范围,所有依本发明专利的权利要求书和说明书内容所作之简单的等效变化与修饰,皆仍属本发明专利涵盖之范围内。另外本发明的任一实施例或权利要求的技术方案不须达成本发明所本发明之全部目的或优点或特点。此外,摘要部分和标题仅是用来辅助专利文件搜寻之用,并非用来限制本发明之权利范围。此外,本说明书或权利要求书中提及的“第一”、“第二”等用语仅用以命名元件(element)的名称或区别不同实施例或范围,而并非用来限制元件数量上的上限或下限。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
