1.本发明涉及深度学习、深伪检测及可解释性应用技术领域,特别涉及基于推理模式评估深伪图像检测模型泛化性方法及装置。
背景技术:
2.随着深度学习技术和图像生成技术的大幅发展与应用,无需复杂的操作便可以生成逼真的图像和视频。例如,目前在领域内知名的deepfake、faceswap技术等图像深度伪造技术。从视觉角度,深度伪造技术一般可划分四类:重现、替换、编辑、合成。重现是指使用源身份驱动目标身份,使得源身份的行为和目标身份一样,包括表情、嘴部、眼部、头部及躯干。替换是指使用源身份的内容替换目标身份,使得目标身份变成了源身份。编辑是指添加、更改或删除目标身份的属性,比如,更换目标对象的发型、衣服、胡须、年龄、体重、颜值、眼镜和种族等属性。合成是指在没有目标身份作为基础的情况下创建深度伪造角色,类似直接用对抗生成网络或者其它生成模型生成人脸,没有明确的目标,人脸和身体合成技术可以创建影视素材,生成电影和游戏角色。
3.从深度伪造图像的发展来看,早期,有研究提出一种基于lstm模型的学习口腔形状和声音之间关联性的方法,仅通过音频即可合成对应的口部特征;有研究提出一种基于对抗生成模型的自动化实时换脸技术;以及出现伪造的色情视频,名人的面孔被换成色情演员的面孔,由reddit用户使用自动编码器-解码器配对结构开发。后来,有研究提出了一种将源视频中的运动转移到另一个视频中目标人的方法,而不仅是换脸;有研究提出一种控制图片生成器并能编辑造假图片各方面特性的方法,比如肤色、头发颜色和背景内容,不同于图片生成方法,这是一种重大突破;有研究提出一种能使得真实人物图像说话的方法,基于生成对抗模型的元学习,该模型基于少量图像(few-shot)训练后,向其输入一张人物头像,可以生成人物头像开口说话的动图;甚至,网络上出现“一键式”智能脱衣软件 deepnude,迫于舆论压力,开发者快速下架;近期,更多的研究着重于在提高原生分辨率、提升深度伪造图像的制作效果等方面。这些技术提供了一种接口给使用者,使其能够通过内容交换来操纵图像\视频并合成新的图像/视频。生成的图片\视频真实度极高,即使是人眼也难以区分。
4.然而,该技术往往被带有不良目的的使用者用于制造虚假信息、制造色情视频等,伪造的图像和视频在社交媒体上进一步分享,用于传播名人假新闻、影响选举或操纵股价等恶意目的,为国家间的政治抹黑、军事欺骗、经济犯罪甚至恐怖主义行动等提供了新工具,给政治安全、经济安全、社会安全、国民安全等国家安全领域带来了诸多风险,给社会造成严重的负面影响。
5.为了减轻深度伪造技术带来的不利影响,如何检测深度伪造的图像这个难题已经引起越来越多的关注,现有的研究通过训练通用的分类器,让神经网络决定分析的特征,大量的研究者开发了深伪检测模型,基于标准的cnn架构提出改进策略,使得更加有效的检测伪造视频。例如,使用真假数据集训练基于cnn的孪生网络、使用hmn网络架构同时学习见过
与未见过的脸部数据、使用集成方式将多种深度伪造cnn的预测结果输入至元分类器、利用视频流的时空特征来检测深度伪造,在视频上逐帧学习由面部操作产生的低级伪影表现出来的跨帧不一致的时间伪影,等等。但是这些方法存在一个共同的问题,即深伪检测模型泛化性差。具体来说,深伪检测模型在训练、测试数据集上取得了优异的检测精度,但是在实际应用中,面对检测时出现的模型未知的样本(即未经过模型训练的样本)时,模型的检测表现大幅下降,出现大量漏检、错检的案例。因此,我们需要在实际应用前对模型的泛化性进行精准的评估。
6.目前业内评估深伪检测模型泛化性的往往利用检测精度下降程度、方差-偏差曲线、交叉验证等统计数学方法。但是,依据统计的检测方法的检测准确性极大的依靠统计样本的数量。建立大量已标注的评测样本需要耗费大量人力物力,同时该检测方法并没有考虑到深伪检测模型内部的一些特性。
技术实现要素:
7.本发明的目的在于提供基于推理模式评估深伪图像检测模型泛化性方法及装置,以克服现有技术中的不足。
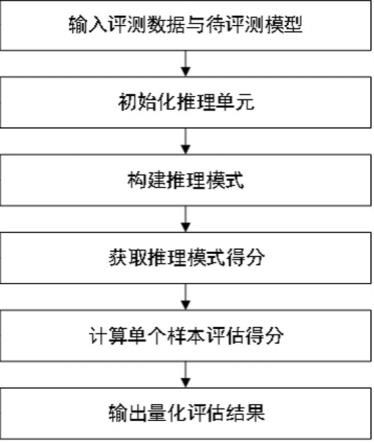
8.为实现上述目的,本发明提供如下技术方案:本发明公开了一种基于推理模式评估深伪图像检测模型泛化性方法,具体包括如下步骤:s1、给定评测数据集与待评测的深伪检测模型;所述评测数据集中包含若干个样本图像;s2、选择一个样本图像,在样本图像上划分若干个固定大小的区域,每个区域作为一个推理单元;s3、在步骤s2的所有推理单元中,随机选择两个推理单元作为前景推理单元;s4、在经过步骤s3选择后剩余的推理单元中,随机选择若干个推理单元构成背景推理单元;s5、将未被步骤s3和步骤s4选择的推理单元作为基础推理单元;将基础推理单元的值修改为基准值;s6、通过前景推理单元、背景推理单元和基础推理单元组成推理模式;其中背景推理单元和基础推理单元共同组成推理模式的推理背景;s7、将推理模式输入到推理模式得分计算函数中,输出该推理模式对应的得分;s8、迭代步骤s3至步骤s7;计算该样本图像的平均得分;s9、遍历所有样本,计算评测数据集的平均得分,输出泛化性量化评测结果。
9.作为优选,步骤s1中样本图像的分辨率为224
×
224,样本图像的长和宽均为224。
10.作为优选,步骤s2具体包括如下子步骤:s21、设定推理单元的大小;s22、从左往右,从下而下,依次在样本上划分若干个大小与推理单元相同的区域,每个区域作为一个推理单元。
11.作为优选,步骤s21中推理单元的长和宽为14
×
14。
12.作为优选,步骤s3中,作为前景推理单元的两个推理单元之间的距离不大于3个推
理单元。
13.作为优选,步骤s5中基准值为所有推理单元的平均值。
14.作为优选,步骤s8中迭代的次数大于等于100次。
15.本发明还公开了一种基于推理模式评估深伪图像检测模型泛化性装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述的一种基于推理模式评估深伪图像检测模型泛化性方法。
16.本发明还公开了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述的一种基于推理模式评估深伪图像检测模型泛化性方法。
17.本发明的有益效果:发明提出了基于推理模式评估深伪图像检测模型泛化性方法及装置,能够从语义层面评估深伪检测模型的泛化性,能够作为传统评估方式的一种补充,从而提升深伪检测模型泛化性评估的准确性;相比于传统依靠准确率下降程度判断泛化性的方式,本方法具有以下优势:1.无需额外的数据与标注。传统评估方式需要提供不同领域的的评测数据,且需要人工标注数据类别。而本发明提出的方法直接计算模型内在特征,大大减少成本开销。
18.2.具备理论基础,评估结果可靠;本发明提出的方法建立在博弈论的基础上,对推理模式进行建模,计算推理模式的复杂度,并经过大量实验证明,结果可靠。
19.本发明的特征及优点将通过实施例结合附图进行详细说明。
附图说明
20.图1是本发明基于推理模式评估深伪图像检测模型泛化性方法的整体流程图;图2是本发明基于推理模式的深伪检测模型泛化性迭代计算方法示意图;图3是本发明实施例使用deepfake算法伪造的样本的评估结果;图4是本发明实施例使用face2face算法伪造的样本的评估结果;图5是本发明实施例使用faceswap算法伪造的样本的评估结果;图6是本发明实施例使用faceshift算法伪造的样本的评估结果;图7是本发明实施例使用neuraltextures算法伪造的样本的评估结果;图8是本发明三种模型在五种不同伪造数据上的泛化性量化评估结果;图9是本发明基于推理模式评估深伪图像检测模型泛化性装置的结构示意图。
具体实施方式
21.为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
22.本发明基于推理模式评估深伪图像检测模型泛化性方法,具体包括如下步骤:s1、给定评测数据集与待评测的深伪检测模型;所述评测数据集中包含若干个样本图像;s2、选择一个样本图像,在样本图像上划分若干个固定大小的区域,每个区域作为
一个推理单元;s3、在步骤s2的所有推理单元中,随机选择两个推理单元作为前景推理单元;s4、在经过步骤s3选择后剩余的推理单元中,随机选择若干个推理单元构成背景推理单元;s5、将未被步骤s3和步骤s4选择的推理单元作为基础推理单元;将基础推理单元的值修改为基准值;s6、通过前景推理单元、背景推理单元和基础推理单元组成推理模式;其中背景推理单元和基础推理单元共同组成推理模式的推理背景;s7、将推理模式输入到推理模式得分计算函数中,输出该推理模式对应的得分;s8、迭代步骤s3至步骤s7;计算该样本图像的平均得分;s9、遍历所有样本,计算评测数据集的平均得分,输出泛化性量化评测结果。
23.在一种可行的实施例中,步骤s1中样本图像的分辨率为224
×
224,样本图像的长和宽均为224。
24.在一种可行的实施例中,步骤s2具体包括如下子步骤:s21、设定推理单元的大小;s22、从左往右,从下而下,依次在样本上划分若干个大小与推理单元相同的区域,每个区域作为一个推理单元。
25.在一种可行的实施例中,步骤s21中推理单元的长和宽为14
×
14。
26.在一种可行的实施例中,步骤s3中,作为前景推理单元的两个推理单元之间的距离不大于3个推理单元。
27.在一种可行的实施例中,步骤s5中基准值为所有推理单元的平均值。
28.在一种可行的实施例中,步骤s8中迭代的次数为100次。
29.实施例1:将本发明提出的一种基于推理模式评估深伪图像检测模型泛化性方法应用到模型上,给定三个待评测模型,基于resnet18架构,在ff 数据集上训练,训练策略不同,在与训练集上相同的测试集上均能够取得99%的识别精度,但是识别未知数据的性能不同;本实施例利用deepfake方法生成伪造数据集作为评测数据集,从语义层面定量评估三个深伪检测模型的泛化性,参阅图1:步骤1、给定一个评测数据集与一个待评测的深伪检测模型, 其中数据集包含140张样本图像,每张样本图像的分辨率为224
×
224;图像的长和宽均为224;步骤2、初始化推理单元。在步骤1提供的样本上,人工设定推理单元的长和宽,分别为14
×
14, 从左往右,从上而下,依次在样本上划分大小为14
×
14的区域,设置为推理单元,每个区域作为一个推理单元。因此,样本 能够被划分为256个单独的推理单元,其中,所有推理单元能够组合为整个样本。
30.步骤3:构建推理模式,参阅图2,步骤3.1:构建前景推理单元;在步骤2划分完成的256个推理单元的中,随机选择两个推理单元作为前景推理单元,两个推理单元之间的距离由人工设定,根
据先验知识,这里设定之间的距离为小于3个推理单元,即被选择的两个推理单元之间距离可以是1个推理单元、2个推理单元和3个推理单元。
31.步骤3.2:构建背景推理单元;在步骤3.1的基础上,从剩余的推理单元中,随机选择26个的推理单元,构成背景。这里,背景中推理单元的个数26;根据先验知识设定,大小为26表示背景复杂度简单,实验中发现,使用简单复杂度的背景推理单元计算泛化性更加精确。
32.步骤3.3:构建基础推理单元;基于步骤3.2,未被选择的推理单元为基础推理单元(即除去前景、背景推理单元后,剩余的推理单元)。将属于基础推理单元的值修改为基准值,基准值设定为所有推理单元的平均值,其他推理单元的值保持不变。
33.步骤3.4:构建推理模式;基于步骤3.1-3.3,前景推理单元、背景推理单元、基础推理单元,共三部分共同组成推理模式。背景推理单元与基础推理单元共同组成推理背景。
34.步骤4:获取推理模式得分。将推理模式输入到推理模式得分计算函数中,输出该模式对应的得分;步骤5、迭代步骤3-步骤4,共计100次,对于单个评测样本,随机选择不同的前景推理单元,计算该样本的平均得分。
35.其中;表示样本被划分的所有推理单元数目。表示被采样的概率。表示所有产生结果的期望;步骤7、计算评测数据集平均得分,输出泛化性量化评测结果。
[0036]36.表示评测数据集中的样本编号,表示评测数据集中的样本总数;步骤8、给定模型a、模型b与模型c,其中模型a采用在ff 数据集上直接训练的策略,模型b在模型a的训练策略上添加了数据增强的训练策略,模型c在模型b的训练策略基础上增加了辅助结构,用于提升泛化性。使用deepfake伪造算法生成500张伪造样本,构建基于deepfake的泛化性评测数据集。执行步骤1-步骤7,计算每个模型在五种评测数据集上的泛化性量化评估结果,结果如图3、图8所示。由图可知,模型a的泛化性显著低于模型b和模型c,模型c的泛化性略优于模型b。
[0037]
实施例2:将本发明提出的一种基于推理模式评估深伪图像检测模型泛化性方法应用到模型上,给定三个待评测模型,基于resnet18架构,在ff 数据集上训练,训练策略不同,在与
训练集上相同的测试集上均能够取得99%的识别精度,但是识别未知数据的性能不同;本实施例利用face2face方法生成伪造数据集作为评测数据集,从语义层面定量评估三个深伪检测模型的泛化性,参阅图1:步骤1、给定一个评测数据集与一个待评测的深伪检测模型, 其中数据集包含140张样本图像,每张样本图像的分辨率为224
×
224;图像的长和宽均为224;步骤2、初始化推理单元。在步骤1提供的样本上,人工设定推理单元的长和宽,分别为14
×
14, 从左往右,从上而下,依次在样本上划分大小为14
×
14的区域,设置为推理单元,每个区域作为一个推理单元。因此,样本 能够被划分为256个单独的推理单元,其中,所有推理单元能够组合为整个样本。
[0038]
步骤3:构建推理模式,参阅图2,步骤3.1:构建前景推理单元;在步骤2划分完成的256个推理单元的中,随机选择两个推理单元作为前景推理单元,两个推理单元之间的距离由人工设定,根据先验知识,这里设定之间的距离为小于3个推理单元,即被选择的两个推理单元之间距离可以是1个推理单元、2个推理单元和3个推理单元。
[0039]
步骤3.2:构建背景推理单元;在步骤3.1的基础上,从剩余的推理单元中,随机选择26个的推理单元,构成背景。这里,背景中推理单元的个数26;根据先验知识设定,大小为26表示背景复杂度简单,实验中发现,使用简单复杂度的背景推理单元计算泛化性更加精确。
[0040]
步骤3.3:构建基础推理单元;基于步骤3.2,未被选择的推理单元为基础推理单元(即除去前景、背景推理单元后,剩余的推理单元)。将属于基础推理单元的值修改为基准值,基准值设定为所有推理单元的平均值,其他推理单元的值保持不变。
[0041]
步骤3.4:构建推理模式;基于步骤3.1-3.3,前景推理单元、背景推理单元、基础推理单元,共三部分共同组成推理模式。背景推理单元与基础推理单元共同组成推理背景。
[0042]
步骤4:获取推理模式得分。将推理模式输入到推理模式得分计算函数中,输出该模式对应的得分;步骤5、迭代步骤3-步骤4,共计100次,对于单个评测样本,随机选择不同的前景推理单元,计算该样本的平均得分。
[0043]
其中;表示样本被划分的所有推理单元数目。表示被采样的概率。表示所有产生结果的期望;
步骤7、计算评测数据集平均得分,输出泛化性量化评测结果。
[0044][0044]
表示评测数据集中的样本编号,表示评测数据集中的样本总数;步骤8、给定模型a、模型b与模型c,其中模型a采用在ff 数据集上直接训练的策略,模型b在模型a的训练策略上添加了数据增强的训练策略,模型c在模型b的训练策略基础上增加了辅助结构,用于提升泛化性。使用face2face伪造算法生成500张伪造样本,构建基于face2face的泛化性评测数据集。执行步骤1-步骤7,计算每个模型在五种评测数据集上的泛化性量化评估结果,结果如图4、图8所示。由图可知,模型a的泛化性显著低于模型b和模型c,模型c的泛化性略优于模型b。
[0045]
实施例3:将本发明提出的一种基于推理模式评估深伪图像检测模型泛化性方法应用到模型上,给定三个待评测模型,基于resnet18架构,在ff 数据集上训练,训练策略不同,在与训练集上相同的测试集上均能够取得99%的识别精度,但是识别未知数据的性能不同;本实施例利用faceswap方法生成伪造数据集作为评测数据集,从语义层面定量评估三个深伪检测模型的泛化性,参阅图1:步骤1、给定一个评测数据集与一个待评测的深伪检测模型, 其中数据集包含140张样本图像,每张样本图像的分辨率为224
×
224;图像的长和宽均为224;步骤2、初始化推理单元。在步骤1提供的样本上,人工设定推理单元的长和宽,分别为14
×
14, 从左往右,从上而下,依次在样本上划分大小为14
×
14的区域,设置为推理单元,每个区域作为一个推理单元。因此,样本 能够被划分为256个单独的推理单元,其中,所有推理单元能够组合为整个样本。
[0046]
步骤3:构建推理模式,参阅图2,步骤3.1:构建前景推理单元;在步骤2划分完成的256个推理单元的中,随机选择两个推理单元作为前景推理单元,两个推理单元之间的距离由人工设定,根据先验知识,这里设定之间的距离为小于3个推理单元,即被选择的两个推理单元之间距离可以是1个推理单元、2个推理单元和3个推理单元。
[0047]
步骤3.2:构建背景推理单元;在步骤3.1的基础上,从剩余的推理单元中,随机选择26个的推理单元,构成背景。这里,背景中推理单元的个数26;根据先验知识设定,大小为26表示背景复杂度简单,实验中发现,使用简单复杂度的背景推理单元计算泛化性更加精确。
[0048]
步骤3.3:构建基础推理单元;基于步骤3.2,未被选择的推理单元为基础推理单元(即除去前景、背景推理单元后,剩余的推理单元)。将属于基础推理单元的值修改为基准值,基准值设定为所有推理单元的平均值,其他推理单元的值保持不变。
[0049]
步骤3.4:构建推理模式;基于步骤3.1-3.3,前景推理单元、背景推理单元
、基础推理单元,共三部分共同组成推理模式。背景推理单元与基础推理单元共同组成推理背景。
[0050]
步骤4:获取推理模式得分。将推理模式输入到推理模式得分计算函数中,输出该模式对应的得分;步骤5、迭代步骤3-步骤4,共计100次,对于单个评测样本,随机选择不同的前景推理单元,计算该样本的平均得分。
[0051]
其中;表示样本被划分的所有推理单元数目。表示被采样的概率。表示所有产生结果的期望;步骤7、计算评测数据集平均得分,输出泛化性量化评测结果。
[0052][0052]
表示评测数据集中的样本编号,表示评测数据集中的样本总数;步骤8、给定模型a、模型b与模型c,其中模型a采用在ff 数据集上直接训练的策略,模型b在模型a的训练策略上添加了数据增强的训练策略,模型c在模型b的训练策略基础上增加了辅助结构,用于提升泛化性。使用faceswap伪造算法生成500张伪造样本,构建基于faceswap的泛化性评测数据集。执行步骤1-步骤7,计算每个模型在五种评测数据集上的泛化性量化评估结果,结果如图5、图8所示。由图可知,模型a的泛化性显著低于模型b和模型c,模型c的泛化性略优于模型b。
[0053]
实施例4:将本发明提出的一种基于推理模式评估深伪图像检测模型泛化性方法应用到模型上,给定三个待评测模型,基于resnet18架构,在ff 数据集上训练,训练策略不同,在与训练集上相同的测试集上均能够取得99%的识别精度,但是识别未知数据的性能不同;本实施例利用faceshift方法生成伪造数据集作为评测数据集,从语义层面定量评估三个深伪检测模型的泛化性,参阅图1:步骤1、给定一个评测数据集与一个待评测的深伪检测模型, 其中数据集包含140张样本图像,每张样本图像的分辨率为224
×
224;图像的长和宽均为224;步骤2、初始化推理单元。在步骤1提供的样本上,人工设定推理单元的长和宽,分别为14
×
14, 从左往右,从上而下,依次在样本上划分大小为14
×
14的区域,设置为推理单元,每个区域作为一个推理单元。因此,样本 能够被划分为256个单独的推理单元,其中,所有推理单元能够组合为整个样本。
[0054]
步骤3:构建推理模式,参阅图2,步骤3.1:构建前景推理单元;在步骤2划分完成的256个推理单元的中,随机选择
两个推理单元作为前景推理单元,两个推理单元之间的距离由人工设定,根据先验知识,这里设定之间的距离为小于3个推理单元,即被选择的两个推理单元之间距离可以是1个推理单元、2个推理单元和3个推理单元。
[0055]
步骤3.2:构建背景推理单元;在步骤3.1的基础上,从剩余的推理单元中,随机选择26个的推理单元,构成背景。这里,背景中推理单元的个数26;根据先验知识设定,大小为26表示背景复杂度简单,实验中发现,使用简单复杂度的背景推理单元计算泛化性更加精确。
[0056]
步骤3.3:构建基础推理单元;基于步骤3.2,未被选择的推理单元为基础推理单元(即除去前景、背景推理单元后,剩余的推理单元)。将属于基础推理单元的值修改为基准值,基准值设定为所有推理单元的平均值,其他推理单元的值保持不变。
[0057]
步骤3.4:构建推理模式;基于步骤3.1-3.3,前景推理单元、背景推理单元、基础推理单元,共三部分共同组成推理模式。背景推理单元与基础推理单元共同组成推理背景。
[0058]
步骤4:获取推理模式得分。将推理模式输入到推理模式得分计算函数中,输出该模式对应的得分;步骤5、迭代步骤3-步骤4,共计100次,对于单个评测样本,随机选择不同的前景推理单元,计算该样本的平均得分。
[0059]
其中;表示样本被划分的所有推理单元数目。表示被采样的概率。表示所有产生结果的期望;步骤7、计算评测数据集平均得分,输出泛化性量化评测结果。
[0060][0060]
表示评测数据集中的样本编号,表示评测数据集中的样本总数;步骤8、给定模型a、模型b与模型c,其中模型a采用在ff 数据集上直接训练的策略,模型b在模型a的训练策略上添加了数据增强的训练策略,模型c在模型b的训练策略基础上增加了辅助结构,用于提升泛化性。使用faceshift伪造算法生成500张伪造样本,构建基于faceshift的泛化性评测数据集。执行步骤1-步骤7,计算每个模型在五种评测数据集上的泛化性量化评估结果,结果如图6、图8所示。由图可知,模型a的泛化性显著低于模型b和模型c,模型c的泛化性略优于模型b。
[0061]
实施例5:将本发明提出的一种基于推理模式评估深伪图像检测模型泛化性方法应用到模
型上,给定三个待评测模型,基于resnet18架构,在ff 数据集上训练,训练策略不同,在与训练集上相同的测试集上均能够取得99%的识别精度,但是识别未知数据的性能不同;本实施例利用neuraltexture方法生成伪造数据集作为评测数据集,从语义层面定量评估三个深伪检测模型的泛化性,参阅图1:步骤1、给定一个评测数据集与一个待评测的深伪检测模型, 其中数据集包含140张样本图像,每张样本图像的分辨率为224
×
224;图像的长和宽均为224;步骤2、初始化推理单元。在步骤1提供的样本上,人工设定推理单元的长和宽,分别为14
×
14, 从左往右,从上而下,依次在样本上划分大小为14
×
14的区域,设置为推理单元,每个区域作为一个推理单元。因此,样本 能够被划分为256个单独的推理单元,其中,所有推理单元能够组合为整个样本。
[0062]
步骤3:构建推理模式,参阅图2,步骤3.1:构建前景推理单元;在步骤2划分完成的256个推理单元的中,随机选择两个推理单元作为前景推理单元,两个推理单元之间的距离由人工设定,根据先验知识,这里设定之间的距离为小于3个推理单元,即被选择的两个推理单元之间距离可以是1个推理单元、2个推理单元和3个推理单元。
[0063]
步骤3.2:构建背景推理单元;在步骤3.1的基础上,从剩余的推理单元中,随机选择26个的推理单元,构成背景。这里,背景中推理单元的个数26;根据先验知识设定,大小为26表示背景复杂度简单,实验中发现,使用简单复杂度的背景推理单元计算泛化性更加精确。
[0064]
步骤3.3:构建基础推理单元;基于步骤3.2,未被选择的推理单元为基础推理单元(即除去前景、背景推理单元后,剩余的推理单元)。将属于基础推理单元的值修改为基准值,基准值设定为所有推理单元的平均值,其他推理单元的值保持不变。
[0065]
步骤3.4:构建推理模式;基于步骤3.1-3.3,前景推理单元、背景推理单元、基础推理单元,共三部分共同组成推理模式。背景推理单元与基础推理单元共同组成推理背景。
[0066]
步骤4:获取推理模式得分。将推理模式输入到推理模式得分计算函数中,输出该模式对应的得分;步骤5、迭代步骤3-步骤4,共计100次,对于单个评测样本,随机选择不同的前景推理单元,计算该样本的平均得分。
[0067]
其中;表示样本被划分的所有推理单元数目。表示被采样的概率。表示所有
产生结果的期望;步骤7、计算评测数据集平均得分,输出泛化性量化评测结果。
[0068]068]
表示评测数据集中的样本编号,表示评测数据集中的样本总数;步骤8、给定模型a、模型b与模型c,其中模型a采用在ff 数据集上直接训练的策略,模型b在模型a的训练策略上添加了数据增强的训练策略,模型c在模型b的训练策略基础上增加了辅助结构,用于提升泛化性。使用neuraltexture伪造算法生成500张伪造样本,构建基于neuraltexture的泛化性评测数据集。执行步骤1-步骤7,计算每个模型在五种评测数据集上的泛化性量化评估结果,结果如图7、图8所示。由图可知,模型a的泛化性显著低于模型b和模型c,模型c的泛化性略优于模型b。
[0069]
本发明基于推理模式评估深伪图像检测模型泛化性装置的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图9所示,为本发明基于推理模式评估深伪图像检测模型泛化性装置所在任意具备数据处理能力的设备的一种硬件结构图,除了图9所示的处理器、内存、网络接口、以及非易失性存储器之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
[0070]
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0071]
本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的基于推理模式评估深伪图像检测模型泛化性装置。
[0072]
所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备的外部存储设备,例如所述设备上配备的插接式硬盘、智能存储卡(smart media card,smc)、sd卡、闪存卡(flash card)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。
[0073]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。