1.本发明属于深度学习和计算机视觉技术领域,尤其涉及一种基于增量技术和注意力机制的公平人脸表情识别方法。
背景技术:
2.随着人工智能逐渐地融入人们的日常生活中,研究人员对智能情感分析的研究取得了不错的进展。而人脸表情是表达人类意图和情绪的重要信号。因此,人脸表情识别技术得到了深入研究,并已广泛应用于社会分析、医疗保健、安全驾驶等领域。现有的表情识别方法是基于深度神经网络进行分类,同时,深度神经网络在数据和算法上存在偏差。虽然针对人口统计属性偏差的公平表情识别已获得不错的进展,但对于表情类别偏差的研究较少。事实上,在很多应用场景中,表情类别偏差对系统的应用效果有不利影响。例如,在对自闭症儿童的案例研究中,惊讶的识别率远高于恐惧的识别率。同样,在自动驾驶汽车的驾驶员监控案例中,经过训练的神经网络在检测快乐、中立和惊喜方面表现出色,但在识别恐惧和悲伤方面却很弱。所以,需要开展针对表情类别偏差的研究,以满足人们更高的公平要求。
3.有研究证明平衡采样和公平加权技术可以缓解类别偏差。采样方法指的是在预处理阶段干预数据分布后再进行神经网络训练,而加权方法是在神经网络结构中添加代价敏感层,改变神经网络的偏向性。但是,平衡采样方法容易导致模型过拟合,而公平加权方法可能会为某类别分配不合理的预测值。而注意力机制和增量技术开始成为了近几年的研究热点。注意力机制表明不同图像区域对于预测结果的重要性是不同的。对人脸表情而言,人脸的特殊区域,如眼睛、嘴角、眉毛,对于识别结果更加重要。该机制可以加强地关注代表性低的表情,以减轻深度神经网络的偏差。而增量技术可以敏锐地感知数据分布的变化,确保某个类别不会主导整个神经网络。就表情识别而言,增量技术可以让代表性强的表情类别不再主导神经网络。然而,注意力机制和增量技术对表情类别偏差的缓解方法尚未成熟,对公平人脸表情识别的实现还需进一步完善。
技术实现要素:
4.为解决上述技术问题,本发明提出了一种基于增量技术和注意力机制的公平人脸表情识别方法,有效地提升代表性低的表情类别的识别性能,减缓人脸表情识别中的类别偏差。
5.为实现上述目的,本发明提供了一种基于增量技术和注意力机制的公平人脸表情识别方法,包括:构建并训练表情平衡模型,所述表情平衡模型包括:骨干模块、注意力特征融合模块和表情平衡微调模块;将人脸表情图像输入所述骨干模块,提取所述人脸表情图像的表情特征;将所述表情特征输入所述注意力特征融合模块,获取不同表情类别;
将所述不同表情类别输入所述表情平衡微调模块,对不同所述表情类别进行调节,输出公平人脸表情识别结果。
6.可选地,训练所述表情平衡模型包括:获取所述人脸表情图像的数据集;构建交叉注意蒸馏损失函数;基于所述数据集和所述交叉注意蒸馏损失函数对所述表情平衡模型进行训练。
7.可选地,所述表情平衡模型还包括:增量记忆内存模块;所述增量记忆内存模块与所述骨干模块连接;在所述表情平衡模型的训练过程中,基于所述增量记忆内存模块保留上一训练阶段的预设数量的旧类别数据,减少所述表情平衡模型对代表性不足的表情类别的偏见。
8.可选地,所述骨干模块包括:一个卷积层、一个池化层和若干相连的残差连接单元;所述卷积层、池化层和若干所述残差连接单元依次连接;所述残差连接单元包括:主分支子单元和副分支子单元;所述主分支子单元,用于提取输入图像的不同特征;所述副分支子单元,用于连接所述残差连接单元的输入和输出。
9.可选地,所述注意力特征融合模块包括:空间子模块、通道子模块和全连接层子模块;所述注意力特征融合模块将所述表情特征,从两个维度进行压缩和融合为注意力图,并将所述注意力图输入所述全连接层,获得所述不同表情类别;其中,所述两个维度包括:所述空间子模块提供的空间维度和所述通道子模块提供的通道维度。
10.可选地,所述空间子模块包括:最大和平均池化层,以及与所述最大和平均池化层连接的三个并联的卷积层;所述通道子模块包括:若干编码器,以及与所述若干编码器连接的两个并联的池化层。
11.可选地,所述交叉注意蒸馏损失函数包括:交叉熵损失、注意力分区损失和蒸馏损失;所述交叉注意蒸馏损失函数为:其中,为注意力分区损失,为交叉熵损失,为蒸馏损失。
12.可选地,对所述表情平衡模型进行训练包括:将所述数据集以类别增量的形式输入所述表情平衡模型中,每批次有一组新类别数据。
13.可选地,将所述数据集以类别增量的形式输入所述表情平衡模型中包括:s1.设定第一训练阶段的数据集,其中为第张图像, 为第一训练阶段数据集的图像总数;设定第二或后续阶段的数据集,其中和分别为第训练阶段中第张新类
别和旧类别的图像,和分别为第训练阶段中新类别和旧类别的图像总数;s2.在所述第训练阶段,采用数据集对所述表情平衡模型进行训练:s3.选取当前训练阶段的数据集中的预设数量的新类别数据,其中,为每个表情类别运行存放的样本数量;将所述新类别数据放入所述增量记忆内存模块中,完成所述增量记忆内存模块的内存更新;此外,在最后一个训练阶段,不再更新所述增量记忆内存模块的内存。
14.可选地,所述表情平衡微调模块对所述不同表情类别进行调节包括:构建一个平衡子集,其中表示第张图像, 为平衡子集中图像的总数;基于所述平衡子集以预设阈值的学习率对所述表情平衡模型进行调整,保持所述表情平衡模型的识别性能平衡。
15.与现有技术相比,本发明具有如下优点和技术效果:本发明采用增量技术来研究人脸表情识别的类别偏差问题,利用增量技术对数据分布敏感的特点,从而克服了不同表情类别在数据量和特征上的分布不平衡的问题,缓解了识别中的表情类别偏差。
16.本发明搭建了一个表情平衡网络对人脸表情图像中代表性不足的表情类别强化了特征提取,确保表情平衡网络不会被某个表情类别给主导,并将代表性强的特征迁移到不足的类别特征上。同时混合损失函数(交叉注意蒸馏损失),解决了表情平衡网络训练中存在的不稳定问题。最后表情平衡微调模块,有效地减缓模型对代表性强的表情类别的偏向性。
附图说明
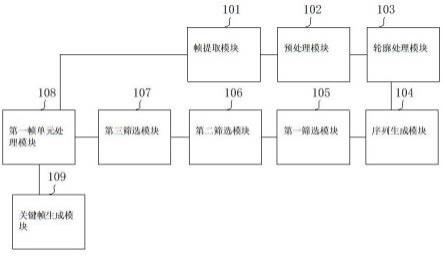
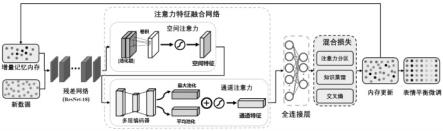
17.构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:图1为本发明实施例的表情平衡网络示意图;图2为本发明实施例的注意力特征融合网络示意图;图3为本发明实施例的表情平衡微调模块示意图。
具体实施方式
18.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
19.需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
实施例
20.本发明提供了一种基于增量技术和注意力机制的公平人脸表情识别方法,包括:
构建并训练表情平衡模型,表情平衡模型包括:骨干模块、注意力特征融合模块和表情平衡微调模块;将人脸表情图像输入骨干模块,提取人脸表情图像的表情特征;将表情特征输入注意力特征融合模块,获取不同表情类别;将不同表情类别输入表情平衡微调模块,对不同表情类别进行调节,输出公平人脸表情识别结果。
21.进一步地,训练表情平衡模型包括:获取人脸表情图像的数据集;构建交叉注意蒸馏损失函数;基于数据集和交叉注意蒸馏损失函数对表情平衡模型进行训练。
22.进一步地,表情平衡模型还包括:增量记忆内存模块;在表情平衡模型的训练过程中,基于增量记忆内存模块保留上一训练阶段的预设数量的旧类别数据,减少表情平衡模型对代表性不足的表情类别的偏见。
23.进一步地,骨干模块包括:一个卷积层、一个池化层和若干相连的残差连接单元;卷积层、池化层和若干所述残差连接单元依次连接;残差连接单元包括:主分支子单元和副分支子单元;主分支子单元,用于提取输入图像的不同特征;副分支子单元,用于连接残差连接单元的输入和输出。
24.进一步地,注意力特征融合模块包括:空间子模块、通道子模块和全连接层子模块;注意力特征融合模块将表情特征,从两个维度进行压缩和融合为注意力图,并将注意力图输入全连接层,获得不同表情类别;其中,两个维度包括:空间子模块提供的空间维度和通道子模块提供的通道维度。
25.进一步地,空间子模块包括:最大和平均池化层、三个并联的卷积层和一个激活函数;通道子模块包括:若干编码器、两个并联的池化层和一个激活函数。
26.进一步地,交叉注意蒸馏损失函数包括:交叉熵损失、注意力分区损失和蒸馏损失;交叉注意蒸馏损失函数为:其中,为注意力分区损失,为交叉熵损失,为蒸馏损失。
27.进一步地,对表情平衡模型进行训练包括:将数据集以类别增量的形式输入表情平衡模型中,每批次有一组新类别数据。
28.如图1所示,为本实施例所构建的基于增量技术和注意力机制的公平人脸表情识别方法的结构流程,本实施例的具体流程如下:步骤一,从公开表情数据集中收集数据,对数据集中的表情图片进行预处理。
29.本步骤通过选定某几类特定的表情,从公开的表情数据集中进行采集,并将表情图片经过对齐和裁剪处理后,并检查数据集中的表情标签。人脸图像的尺寸统一为224
×
224,数据集为,其中表示第张图像, 为图像数据集中人脸图像的总数。
30.步骤二,搭建一个包括resnet18、增量记忆内存、注意力特征融合网络和表情平衡微调模块的表情平衡网络。其具体实施流程如下:s2.1:构建一个具有18层的残差网络(resnet18)作为骨干网络用于人脸表情特征的提取;骨干网络依次设置有一个卷积层、一个池化层和若干个相连的残差连接单元;残差连接单元包括主分支和副分支,主分支包括有卷积核大小为3
×
3的三层卷积层,第一个卷积层可能只提取一些如边缘、线条和角的低级特征,越后面的单元能从低级特征中迭代提取更复杂的特征。副分支子单元的构成为1
×
1的卷积核,副分支用于连接每个残差连接单元的输入和输出。当输入通道数不同时,可以利用副分支1
×
1的卷积核进行修改匹配;s2.2:构建一个增量记忆内存用于保留上一个训练阶段的少量旧类别数据,减少模型对代表性不足的表情类别的偏见;s2.3:构建一个注意力特征融合网络用于生成通道和空间的融合注意力图;如图2所示,注意力特征融合网络包括空间模块和通道模块;空间模块包括最大和平均池化层,三个并联的卷积层和一个激活函数,其中三个并联层的卷积核大小分别为3
×
1、3
×
3、1
×
3的三层卷积,激活函数采用relu;通道模块包括多层编码器,两个并联的池化层和一个激活函数,其中两个并联池化层分别为最大池化和平均池化,激活函数采用relu;s2.4:如图3所示,设置一个表情平衡微调模块用于调节不同表情类别。
31.步骤三,建立混合损失函数(交叉注意蒸馏损失)用于对注意力融合网络进行分区,并提取旧表情类别的网络参数:s3.1:建立如式(1)所示的交叉熵损失:其中,表示为样本数量,表示为分类数,和分别表示为第样本为类表情的真实概率和预测概率;s3.2:建立如式(2)所示的注意力分区损失:其中,表示为注意力图的通道长度,表示为第样本中第通道上的方差;s3.3:建立如式(3)所示的蒸馏损失:
其中,表示为旧表情的类别数目,表示为蒸馏温度系数,和分别表示为第样本为类表情的真实概率和旧模型的预测概率;s3.4:构建如式(6)混合损失(交叉注意蒸馏损失):步骤四,将表情数据以类别增量的形式输入模型中,每批次有一组新类别数据:s4.1:给定第一训练阶段的数据集,其中表示第张图像, 为第一训练阶段数据集的图像总数;第二或后续阶段的数据集,其中和分别表示第训练阶段中第张新类别和旧类别的图像,和分别为第训练阶段中新类别和旧类别的图像总数;s4.2:对于第训练阶段,采用数据集对步骤二所构造的表情平衡网络进行训练,训练包括:s2.1中的骨干网络采用resnet18的结构,并提取输入数据的表情特征;然后将这些数据特征输入到注意力模块中。
32.s2.3中的注意力特征融合网络采用空间和通道注意力机制,并将输入数据的特征从空间和通道两个维度进行压缩和融合为注意力图;然后将这些注意力图输入到全连接层,并获得表情标签。
33.依据这些表情标签和步骤三中的混合损失函数(交叉注意蒸馏损失),计算损失值;然后利用随机梯度下降算法更新骨干网络、注意力特征融合网络的参数值;s4.3:更新增量记忆内存中的数据:选取当前训练阶段的数据集中的部分新类别数据,为每个表情类别运行存放的样本数量;然后将这些新类别数据放入s2.2中的增量记忆内存中,完成内存更新;此外,在最后一个训练阶段,不再更新内存。
34.步骤五,如图1和图3所示,采用s2.4中的表情平衡微调模块对模型进行微调:s5.1:从本地内存中选择数据来构建一个平衡的子集,其中
表示第张图像, 为平衡子集中图像的总数。基于平衡子集以较低的学习率对模型进行微调,以获得更平衡的性能,最后结束训练。
35.以上,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。