1.本发明涉及图像识别技术,具体涉及一种基于类激活映射的路面裂缝分割方法。
背景技术:
2.裂缝会降低基础设施项目中建筑物、道路和桥梁的效率和功能,及时检测和修复裂缝能够避免基础设施进一步恶化,并有助于降低维护成本。维护人员可以使用基于视觉的方法来提取裂缝的基本数据,以有效评估工程建设的安全性和剩余价值。由于现代传感器技术和基础设施更容易收集道路图像。因此,许多研究人员研究了基于图像的自动路面裂缝检测方法。计算机辅助视觉检测方法的进步加速和改进了路面裂缝的检测,目标检测可用于估计图像上裂缝的位置,利用图像分类,可以在图像上提取裂缝语义信息。另一方面,语义分割可用于提取裂缝像素级别的详细语义信息。在裂缝图像中,由于路面裂缝没有固定的位置和形状,目标检测和分类任务无法在像素级上描述裂缝的形状和长度。因此,有必要研究基于语义分割的裂缝检测方法。
3.在现有技术中,往往采用阈值分隔、边缘检测和数学形态学等传统图像处理技术,利用多个gabor滤波器实现对任意方向路面裂缝的检测,利用lbp算子,将路面模式分为五个子类,以确定裂缝分段特有的判别局部特征。在分析灰度差异的基础上,基于阈值的裂缝分隔系统被开发。但是,由于拍摄时间或天气灯不同条件的影响,以及裂缝纹理的变化和路面上出现的不同类型的物体,上述方法都会受到这些噪声的影响,导致部分裂缝无法被正确检测。
技术实现要素:
4.针对现有技术中的上述不足,本发明提供的基于类激活映射的路面裂缝分割方法解决了现有裂缝分割方法在存在噪声时,部分裂缝不能被检测到的问题。
5.为了达到上述发明目的,本发明采用的技术方案为:
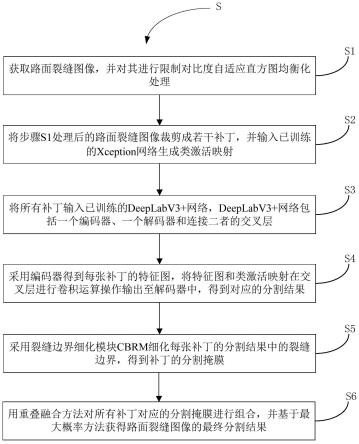
6.提供一种基于类激活映射的路面裂缝分割方法,其包括步骤:
7.s1、获取路面裂缝图像,并对其进行限制对比度自适应直方图均衡化处理;
8.s2、将步骤s1处理后的路面裂缝图像裁剪成若干补丁,并输入已训练的xception网络生成类激活映射;
9.s3、将所有补丁输入已训练的deeplabv3 网络,deeplabv3 网络包括一个编码器、一个解码器和连接二者的交叉层;
10.s4、采用编码器得到每张补丁的特征图,将特征图和类激活映射在交叉层进行卷积运算操作输出至解码器中,得到对应的分割结果;
11.s5、采用裂缝边界细化模块cbrm细化每张补丁的分割结果中的裂缝边界,得到补丁的分割掩膜;
12.s6、采用重叠融合方法对所有补丁对应的分割掩膜进行组合,并基于最大概率方法获得路面裂缝图像的最终分割结果。
13.进一步地,基于类激活映射的路面裂缝分割方法还包括采用类激活映射优化模块rcm对步骤s2中的类激活映射进行优化:
14.a1、采用类激活映射优化模块rcm计算类激活映射中当前像素k和像素q的特征相似性f
sim
(xk,xq):
[0015][0016]
其中,xk和xq分别为像素点k像素点q的像素值;和分别为像素点k像素点q的像素值通过一个单独的卷积层进行运算;为像素点k的运算结果进行转置操作;‖.‖为范数;
[0017]
a2、根据特征相似性和xception网络生成的类激活映射cam
original
,计算精细化的类激活映射cam
refined
:
[0018][0019]
其中,relu(.)为激活函数;
[0020]
步骤s4中采用的类激活映射为精细化后的类激活映射。
[0021]
进一步地,s5进一步包括:
[0022]
s51、采用卷积定向边界操作生成每张补丁分割结果的候选级别层次图,每张补丁在其候选级别层次图中选取m个不重叠的区域作为可靠区域;
[0023]
s52、每张补丁在可靠区域的空间和特征层建模形成构造图,可靠区域的空间和特征维度被表示为邻接图,构造图g=(g
i,j
)m×m:
[0024][0025]
其中,g
i,j
为图矩阵;ri和rj分别为补丁g中的第i个和第j个可靠区域;m(ri,rj)为ri和rj之间的相似度;exp(
·
)为以e为底的幂次方计算;为范数;
[0026]
s53、根据特征相似度,构建每个可靠区域r的分割得分模型:
[0027][0028]
其中,αj为第j个区域的矩阵;
[0029]
s54、构建优化目标函数,并对其进行规范化处理,规范化后模型为:
[0030][0031]
其中,f为f=(f(r1),...,f(rm))
t
,ω为区域的权值;δ1和δ2均为权重,d为邻接图中包含度值的对角矩阵,m为m(ri,rj)导出的f的范数,l为补丁的拉普拉斯矩阵,l=d-g;α为α=(α1,α1,...,αm)
t
;h为对角矩阵,其前r个元素设置为1,其余元素设置为0;
[0032]
s55、对规范化后模型进行求解,得到优化后的α
*
:
[0033][0034]
其中,α
*
为最终优化的方程;
[0035]
s56、根据优化后的α
*
和分割得分模型,得到优化后的分割得分作为补丁的分割掩膜。
[0036]
进一步地,步骤s6进一步包括:
[0037]
s61、读取记录的路面裂缝图像裁剪时每个补丁的位置,预测出分割掩膜的位置分布;
[0038]
s62、对于重叠位置的分割掩膜,将重叠区域的最大概率相加,计算出最终的输出概率;
[0039]
s62、根据补丁的位置分布和输出概率,对补丁进行拼接,之后对拼接后的图像经过argmax处理,得到路面裂缝图像的最终分割结果。
[0040]
进一步地,进行限制对比度自适应直方图均衡化处理的计算公式为:
[0041]
x=h(i)
[0042]
其中,x为后的路面裂缝图像,i为初始的路面裂缝图像;h(
·
)为限制对比度自适应直方图均衡化操作。
[0043]
进一步地,xception网络的训练方法:
[0044]
s21、获取预训练后的xception网络,移除xception网络的最后一层池化层,采用两个可分离扩张卷积取代xception最后的两个独立卷积;
[0045]
s22、采用裂缝图像分类数据集对步骤s21构建的xception网络进行训练;
[0046]
s23、训练过程中,随机初始化全连接层的权值,在完成全局平均池化gap后,将特征发送到初始化权重的全连接层后,采用softmax函数激活;
[0047]
s24、通过迭代最小化交叉熵损失,对xception网络进行优化,得到已训练的xception网络,交叉熵损失函数为:
[0048][0049]
其中,y为真实标签值;为预测值;loss为交叉熵损失。
[0050]
进一步地,所述裂缝图像分类数据集为数据集clc,包含40000张补丁,其中20000张裂缝表示正类,另外20000张非裂缝为负类;补丁大小为227*227,训练过程中调整为224*224。
[0051]
进一步地,deeplabv3 网络的训练方法包括:
[0052]
s31、采用编码器、解码器及连接二者的交叉层构成deeplabv3 网络,并对deeplabv3 网络的最后一个卷积层替换为一个单通道的卷积层;
[0053]
s32、获取裂缝训练集,并将裂缝中的每张裂缝图像分割成若干补丁,之后将所有补丁输入编码器,生成对应的特征图;
[0054]
s33、将步骤s32生成的所有补丁输入已训练的xception网络,得到类激活映射,并采用类激活映射优化模块rcm优化得到精细的类激活映射;
[0055]
s34、将步骤s32的特征图和步骤s33精细化后的类激活映射输入交叉层进行卷积运算操作输出至解码器中,得到对应的分割掩膜;
[0056]
s35、将分割出的裂缝掩膜与其对应的裂缝真实标签计算误差:
[0057]
l
loss
=l
bce
l
dice
l
ssim
[0058][0059][0060][0061]
其中,其中,l
losss
、l
bce
、l
dice
和l
ssim
分别为总损失、二元交叉熵损失函数、dice损失函数和ssim损失函数;y
(x,y)
为裂缝图像的真实标签;为预测的概率图;μ为均值;σ为方差,为和y
(x,y)
之间的协方差,(c1,c2)为计算稳定性的常数;h为图像的高;w为图像的宽度;
[0062]
s36、迭代优化过程中使用小批量的梯度下降方法,当迭代次数达到预设迭代次数时,停止训练得到已训练的deeplabv3 网络。
[0063]
进一步地,所述裂缝训练集为deepcrack、crack500和cfd;其中deepcrack为基准数据集,包含不同尺度和场景的裂缝,总共有300张训练图像和237张测试图像,分辨率为544
×
384,裁剪补丁时将训练集的每一张裂缝图像裁剪成15个补丁,训练时补丁数量为4500张,测试时补丁数量为3555张,每个补丁的大小为224*224;
[0064]
crack500数据集包含1896幅训练图像和1124幅测试图像,分辨率为360
×
640,裁剪补丁时将训练集的每一张裂缝图像裁剪成12个补丁,训练时补丁数量为22752张,测试时补丁数量为13488张,每个补丁的大小为224*224;
[0065]
cfd数据集包含118张裂缝图像,人工标注的裂缝尺寸大小为480
×
320,先使用旋转增强和在水平轴与垂直轴分别翻转进行增强,增强到590张图像,按照7:3的比例划分训练集和测试集,训练集有413张图片,测试时有177张图片;裁剪补丁时将训练集的每一张裂缝图像裁剪成8个补丁,最终训练时补丁数量为3304张,测试时补丁数量为1416张,每个补丁的大小为224*224。
[0066]
与现有技术相比,本发明的有益效果为:
[0067]
一、本方案将xception网络作为分类网络,deeplabv3 网络作为分割网络,通过分类网络和分割网络结合起来对路面裂缝图像进行检测,使用分类网络生成类激活映射(高质量的裂缝定位图),这些裂缝定位图与编码器的特征图相结合并输入到解码器中,使裂缝的分割结果更加精确。
[0068]
二、本方案的类激活映射优化模块rcm对类激活映射进行优化,通过自注意力机制,捕获上下文信息,增强了像素级预测结果,采用融合每个像素的低级特征,进而改进类激活映射,在去除残余连接时保持了与原始类激活映射相同的激活程度,将relu激活与l1归一化相结合,消除了不相关的像素,提高了类激活映射的质量。
[0069]
三、本方案在分割网络的编码器和解码器中间添加了交叉层cl,将优化后的类激活映射与编码器的图像特征结合起来,再将新的特征图传送给解码器,这保证了裂缝能够
被精确分割。
[0070]
四、本方案采用混合损失函数来优化分割网络,将三种损失函数进行结合,由于dice损失函数主要关注训练过程中的准确率,将ssim损失函数引入,通过预测裂缝结构的空间位置来准确测量不同宽度的裂缝,此外,由于路面裂缝分割是一个标准的二值分割问题,因此,引入二元交叉熵损失函数,将三种损失函数结合起来提高了路面裂缝的分割性能。
[0071]
五、本方案设置了裂缝边界细化模块cbrm,由于分割网络生成的分割图裂缝边界比较模糊,裂缝边界细化模块cbrm基于图的优化方法,利用卷积定向边界生成分层分割级别的可靠区域,利用裂缝边界细化模块cbrm能够生成更精细的、具有清晰边界的路面裂缝分割。
附图说明
[0072]
图1为基于类激活映射的路面裂缝分割方法的流程图。
[0073]
图2为是本方案的路面裂缝分割方法整体工作流程的原理框图。
[0074]
图3为本方案的xception网络(分类网络)的架构图。
[0075]
图4为类激活映射优化模块rcm的架构图。
[0076]
图5为deeplabv3 网络的工作流程图。
[0077]
图6是裂缝边界细化模块cbrm流程图。
具体实施方式
[0078]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0079]
参考图1,图1示出了基于类激活映射的路面裂缝分割方法的流程图,如图1所示,该方法s包括步骤s1至步骤s6。
[0080]
在步骤s1中,获取路面裂缝图像,并对其进行限制对比度自适应直方图均衡化处理:
[0081]
x=h(i)
[0082]
其中,x为后的路面裂缝图像,i为初始的路面裂缝图像;h(
·
)为限制对比度自适应直方图均衡化操作。
[0083]
路面裂缝图像采用步骤s1的方式进行处理后,能减少光照的负面影响,以降低光照对路面裂缝图像质量的影响。
[0084]
在步骤s2中,将步骤s1处理后的路面裂缝图像裁剪成若干补丁,并输入已训练的xception网络生成类激活映射;
[0085]
本方案构建好的xception网络的架构图可以参考图3,xception网络(分类网络)由三部分组成:entryflow、middleflow和exitflow;conv bn relu表示卷积 批标准化 relu激活,separable conv bn relu表示可分离卷积 批标准化 relu激活,dilated separable conv bn relu表示扩张可分离式卷积。
[0086]
sconv表示separable conv,dsconv表示dilated separable conv。gap表示全局平均池化,fc表示全连接层。输入的补丁图像(inputimages)经过图2中的一系列操作之后,能够定位出裂缝的具体位置,从分类网络的最后一个卷积层中提取出裂缝的具体位置。
[0087]
在本发明的一个实施例中,xception网络的训练方法:
[0088]
s21、获取预训练后的xception网络,移除xception网络的最后一层池化层,采用两个可分离扩张卷积取代xception最后的两个独立卷积;
[0089]
s22、采用裂缝图像分类数据集对步骤s21构建的xception网络进行训练;其中,裂缝图像分类数据集为数据集clc,包含40000张补丁,其中20000张裂缝表示正类,另外20000张非裂缝为负类;补丁大小为227*227,训练过程中调整为224*224。
[0090]
s23、训练过程中,随机初始化全连接层的权值,在完成全局平均池化gap后,将特征发送到初始化权重的全连接层后,采用softmax函数激活;
[0091]
s24、通过迭代最小化交叉熵损失,对xception网络进行优化,得到已训练的xception网络,交叉熵损失函数为:
[0092][0093]
其中,y为真实标签值;为预测值;loss为交叉熵损失。
[0094]
由于cnn是为了提高分类精度,往往会捕捉一个物体最具鉴别性的特征,以最大限度的减少分类歧义,所以cnn无法激活图像的完整空间响应;为了克服cnn无法激活图像的完整空间响应的问题,本方案还引入了类激活映射优化模块rcm对已训练的xception网络生成类激活映射进行优化,优化的具体步骤为:
[0095]
a1、采用类激活映射优化模块rcm计算类激活映射中当前像素k和像素q的特征相似性f
sim
(xk,xq):
[0096][0097]
其中,xk和xq分别为像素点k像素点q的像素值;和分别为像素点k像素点q的像素值通过一个单独的卷积层进行运算;为像素点k的运算结果进行转置操作;‖.‖为范数;
[0098]
a2、根据特征相似性和xception网络生成的类激活映射cam
original
,计算精细化的类激活映射cam
refined
:
[0099][0100]
其中,relu(.)为激活函数;
[0101]
下面步骤s4中采用的类激活映射为精细化后的类激活映射。
[0102]
本方案的类激活映射优化模块rcm可以参考图4,在生成精细的类激活映射(refinedcam)的过程中,特征图(featuremaps)是通过分类网络产生的1
×
1conv表示卷积核大小为1
×
1的卷积层,h、w分别表示特征图(featuremaps)的高度和宽度,c、c1、c2表示通道数。
[0103]
在步骤s3中,将所有补丁输入已训练的deeplabv3 网络,deeplabv3 网络包括一
个编码器、一个解码器和连接二者的交叉层;deeplabv3 网络的工作流程图可以参考图5。
[0104]
在本发明的一个实施例中,deeplabv3 网络的训练方法包括:
[0105]
s31、采用编码器、解码器及连接二者的交叉层构成deeplabv3 网络,并对deeplabv3 网络的最后一个卷积层替换为一个单通道的卷积层;
[0106]
s32、获取裂缝训练集,并将裂缝中的每张裂缝图像分割成若干补丁,之后将所有补丁输入编码器,生成对应的特征图;
[0107]
其中,裂缝训练集为deepcrack、crack500和cfd;其中deepcrack为基准数据集,包含不同尺度和场景的裂缝,总共有300张训练图像和237张测试图像,分辨率为544
×
384,裁剪补丁时将训练集的每一张裂缝图像裁剪成15个补丁,训练时补丁数量为4500张,测试时补丁数量为3555张,每个补丁的大小为224*224;
[0108]
crack500数据集包含1896幅训练图像和1124幅测试图像,分辨率为360
×
640,裁剪补丁时将训练集的每一张裂缝图像裁剪成12个补丁,训练时补丁数量为22752张,测试时补丁数量为13488张,每个补丁的大小为224*224;
[0109]
cfd数据集包含118张裂缝图像,人工标注的裂缝尺寸大小为480
×
320,先使用旋转增强和在水平轴与垂直轴分别翻转进行增强,增强到590张图像,按照7:3的比例划分训练集和测试集,训练集有413张图片,测试时有177张图片;裁剪补丁时将训练集的每一张裂缝图像裁剪成8个补丁,最终训练时补丁数量为3304张,测试时补丁数量为1416张,每个补丁的大小为224*224。
[0110]
s33、将步骤s32生成的所有补丁输入已训练的xception网络,得到类激活映射,并采用类激活映射优化模块rcm优化得到精细的类激活映射;
[0111]
s34、将步骤s32的特征图和步骤s33精细化后的类激活映射输入交叉层进行卷积运算操作输出至解码器中,得到对应的分割掩膜;
[0112]
s35、将分割出的裂缝掩膜与其对应的裂缝真实标签计算误差:
[0113]
l
loss
=l
bce
l
dice
l
ssim
[0114][0115][0116][0117]
其中,l
losss
、l
bce
、l
dice
和l
ssim
分别为总损失、二元交叉熵损失函数、dice损失函数和ssim损失函数;y
(x,y)
为裂缝图像的真实标签;为预测的概率图;μ为均值;σ为方差,为和y
(x,y)
之间的协方差,(c1,c2)为计算稳定性的常数;h为图像的高;w为图像的宽度;
[0118]
s36、迭代优化过程中使用小批量的梯度下降方法,当迭代次数达到预设迭代次数
时,停止训练得到已训练的deeplabv3 网络。
[0119]
在步骤s4中,采用编码器得到每张补丁的特征图,将特征图和类激活映射在交叉层进行卷积运算操作输出至解码器中,得到对应的分割结果;
[0120]
在步骤s5中,采用裂缝边界细化模块cbrm细化每张补丁的分割结果中的裂缝边界,得到补丁的分割掩膜;裂缝边界细化模块cbrm的工作流程可以参考图6。
[0121]
实施时,本方案优选步骤s5的具体实现过程包括:
[0122]
s51、采用卷积定向边界操作生成每张补丁分割结果的候选级别层次图,每张补丁在其候选级别层次图中选取m个不重叠的区域作为可靠区域;
[0123]
s52、每张补丁在可靠区域的空间和特征层建模形成构造图,可靠区域的空间和特征维度被表示为邻接图,构造图g=(g
i,j
)m×m:
[0124][0125]
其中,g
i,j
为图矩阵;ri和rj分别为补丁g中的第i个和第j个可靠区域;m(ri,rj)为ri和rj之间的相似度;exp(
·
)为以e为底的幂次方计算;为范数;
[0126]
s53、根据特征相似度,构建每个可靠区域r的分割得分模型:
[0127][0128]
其中,αj为第j个区域的矩阵;
[0129]
s54、构建优化目标函数,并对其进行规范化处理,规范化后模型为:
[0130][0131]
其中,f为f=(f(r1),...,f(rm))
t
,ω为区域的权值;δ1和δ2均为权重,d为邻接图中包含度值的对角矩阵,m为m(ri,rj)导出的f的范数,l为补丁的拉普拉斯矩阵,l=d-g;α为α=(α1,α1,...,αm)
t
;h为对角矩阵,其前r个元素设置为1,其余元素设置为0;
[0132]
s55、对规范化后模型进行求解,得到优化后的α
*
:
[0133][0134]
其中,α
*
为最终优化的方程;
[0135]
s56、根据优化后的α
*
和分割得分模型,得到优化后的分割得分作为补丁的分割掩膜。
[0136]
在步骤s6中,采用重叠融合方法对所有补丁对应的分割掩膜进行组合,并基于最大概率方法获得路面裂缝图像的最终分割结果。
[0137]
在本发明的一个实施例中,步骤s6进一步包括:
[0138]
s61、读取记录的路面裂缝图像裁剪时每个补丁的位置,预测出分割掩膜的位置分布;
[0139]
s62、对于重叠位置的分割掩膜,将重叠区域的最大概率相加,计算出最终的输出概率;
[0140]
s62、根据补丁的位置分布和输出概率,对补丁进行拼接,之后对拼接后的图像经过argmax处理,得到路面裂缝图像的最终分割结果
[0141]
图2给出了本方案的路面裂缝分割的完整原理框图;在图1的第1部分为图像预处理,输入原始图片(original inage)经过限制对比度自适应直方图均衡化处理(clahe)以后,使用裁剪(crop)操作将图像裁剪成补丁(patches)。
[0142]
第2部分为训练分割网络,首先将裁剪后的补丁(patches)通过分类网络(cnn)的训练,应用类激活映射模块(cam)生成初始类激活映射(originalcam),在应用类激活映射优化模块(rcm)生成精细的类激活映射(refinedcam);同时,将裁剪后的补丁(patches)传入分割网络的编码器(encoder)中,得到相对应的特征图(features);利用交叉层(crosslayer)将精细的类激活映射(refinedcam)与特征图(features)结合,传到解码器中生成相应补丁的分割结果(segmentationoutput);最后,使用裂缝边界细化模块(cbrm)对分割结果(segmentationoutput)进行优化生成精细化的分割结果(refinedresult)。
[0143]
第3部分是后处理,每一个补丁的精细化结果(refinedresultt of patches)通过第2部分生成,为了最终得到一张完整的裂缝分割图像,使用重叠融合方法(overlapping fusion strategy)将补丁进行整合,得到最终的输出结果。
[0144]
下面结合具体的实例对本方案路面裂缝分割方法的效果进行说明:
[0145]
实施例1
[0146]
利用现有方法多种裂缝分割方法与本方案的路面裂缝分割方法在三个数据集上进行比对,在deepcrack数据集上选择召回率、精度和f-分数指标作为3种常见的评价方法,与现有技术多种分割方法hed、u-net、deeplabv3 、autocrack、deepcrack、deepcrack-aug、roadcnns、segnet、psp-net、u2net、dma-net进行对比,最终对比结果如下表1所示。
[0147]
表1
[0148]
methodrecallprecisionf1meausrehed0.6910.5940.649u-net0.8350.8620.848deeplabv3 0.8530.8400.846autocrack0.4240.7720.548deepcrack0.7990.7940.796deepcrack-aug0.8690.8610.865roadcnns0.8600.2290.361segnet0.7290.7970.762psp-net0.8350.8510.843u2net0.8680.8230.864dma-net0.8710.8690.870本方案方法0.8820.8870.886
[0149]
在crack500数据集上选择召回率、精度、f-分数、dice系数和均交并比指标作为5种常见的评价方法,与cnn、u-net、san、fphbn、deeplabv3 、psp-net、u2net、dma-net进行对比,最终对比结果如下表2所示;
[0150]
表2
[0151][0152][0153]
在cfd数据集上选择召回率、精度和f-分数指标作为3种常见的评价方法,与cnn、u-net、san、deeplabv3 、u2net进行对比,最终对比结果如下表3所示。
[0154]
表3
[0155]
methodrecallprecisionf1meausrecnn0.9480.9120.924u-net0.9130.8570.875u-net0.9160.8520.873san0.9380.9700.952deeplabv3 0.9270.9580.942u2net0.9380.9650.951u-net0.9430.9700.956本方案方法0.9410.9790.960
[0156]
通过3个表可以看出,本方案方法无论是在数据图像较多的deepcrack数据集上,还是在数据图像较少的cfd数据集上,整体分割性能都明显优于其他方法。
[0157]
由于路面裂缝分割的基本问题是裂缝的形状和大小众多、裂缝强度不均匀、路面环境的复杂以及缺乏标记的训练集。本方法利用了路面裂缝分割中分割和分类任务之间的内在关系,通过将分类网络中的知识转移到裂缝边界细化的分割过程中,以便于路面裂缝分割。
[0158]
根据本方案的研究结果,提出的路面裂缝分割框架在三个基准数据集(包括deepcrack、crack500和cfd)上取得了最新的结果,能够生成更精细的裂缝分割图,同时能够检测和分割短而小的裂缝,证明了本方法的有效性。
[0159]
实施例2
[0160]
在本实施例中,验证了类激活映射优化模块在裂缝分割任务中的有效性。在分类网络中,使用了类激活映射框架,生成特定类的定位映射,但是cnn不能激活物体的完整空
间响应,本方法使用类激活映射优化模块对类激活映射进行优化。由于deepcrack数据集更具有代表性,能够更加充分反映算法的泛化性能,本方法选择在deepcrack数据集上进行了验证,分别使用和不使用类激活映射优化模块的对比,对比结果如表4;使用类激活映射优化模块生成更精确的裂缝定位图,这些图与编码器的图像特征融合,并反馈给解码器。
[0161]
表4
[0162]
methodrecallprecisionf1meausremioucam0.5960.4970.5420.488cam rcm0.6450.5860.6140.577
[0163]
通过表4可知,本方案使用类激活映射优化模块生成的像素级注释的miou从0.488显著提高到0.577,这表明了本方法提出的类激活映射优化模块是有效的,有利于提高模型的分割性能。
[0164]
实施例3
[0165]
本实施例验证了在分割网络的编码器和解码器中间使用交叉层,融合裂缝定位图(精细化类激活映射)与编码器的特征图,再传送给解码器的有效性。由于分类网络能够定位裂缝的位置,本方法将分类网络的定位映射引入到分割网络中,有利于提高分割网络的分割性能。本方法在deepcrack数据集上验证了交叉层的有效性,对比结果如表5所示。
[0166]
表5
[0167]
methodrecallprecisionf1meausremiousegmentation0.8230.8080.8150.807cam segmentation0.8690.8460.8570.867
[0168]
根据表5的结果可知,本方法将裂缝定位图从分类网络中转移到分割网络中,对裂缝的分割更加有效,在召回率、精度、f-分数和均交并比四个指标上明显高于没有使用交叉层的结果,进一步证明了本方法提出的交叉层的有效性。
[0169]
实施例4
[0170]
本实施例验证了结合二元交叉熵损失函数、ssim损失函数以及dice损失函数三者在裂缝分割任务中的有效性,由于路面裂缝分割是一个标准的二值分割问题,因此使用了二元交叉熵损失函数,在此基础上,引入了dice损失函数和ssim损失函数。针对不同的组合,本方法进行了不同组合的验证实验,如表6所示。
[0171]
表6
[0172]
methodrecallprecisionf1meausremioubce0.8240.8690.8460.837bce ssim0.8340.8720.8530.841bce dice0.8560.8780.8670.848bce ssim dice0.8780.8870.8830.878
[0173]
通过表6可知,将三种损失函数结合起来的结果比仅使用二元交叉熵损失函数和其他两种组合的分割指标更优,验证了本方法提出结合三种损失函数的有效性。
[0174]
实施例5
[0175]
本实施例验证了裂缝边界细化模块(cbrm)在裂缝分割中的有效性,由于分割网络
生成的分割图对象边界模糊,为了细化边界,基于图的优化方法,利用卷积定向边界生成分层分割级别为的可靠区域。本方法在deepcrack数据集上验证了裂缝边界细化模块的有效性,对比了使用和不使用cbrm模块的指标,如表7所示。
[0176]
表7
[0177]
methodrecallprecisionf1meausremiousegmentation0.8690.8460.8300.867cbrm segmentation0.8820.8870.8860.898
[0178]
通过表7可知,使用了裂缝边界细化模块对裂缝的分割是有效的,各指标有明显提高,表明使用cbrm模块能够生成更精细的分割结果。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。