1.本发明属于分布式计算的技术领域,具体涉及一种基于大数据平台分布式瓦片金字塔的三维路径规划方法。
背景技术:
2.月球车对月球的探索是人类探索太空的第一步,对月球车的路径规划问题一直是探月工程的研究热点。由于现代测绘技术和传感器硬件的快速发展,使得生成的dem精度越来越高,数据量也越来越大,因此传统策略对基于大型三维地形数据(dem)进行寻路计算的时间越来越长。
3.路径规划的核心思想是在一个未知的环境里,从当前的起始位置找到一条最优的路径到达目标位置。对大型数据进行路径规划的问题上,许多学者提出了不同的解决方案。这些方案可总结为:(1)通过改进原有路径规划算法提高路径规划算法的效率;(2)在将dem数据转换为离散点数据,并使用mapreduce或spark运行迪杰斯特拉或a星路径规划算法去解决最短路径问题。
4.然而通过改进原有路径规划算法提高路径规划算法的效率在大型数据上很难得到提升,受限于单台服务器的物理硬件影响,在大型dem数据的计算上,往往会产生内存溢出、磁盘存储空间不足、搜索时间随搜索数据量增大而指数性增长的问题;而通过利用mapreduce或spark等分布式计算框架运行迪杰斯特拉或a星路径规划算法虽然解决了单台服务器的物理硬件的影响,但在对dem栅格数据进行路径规划任务上,将大型dem数据简单的转换为离散点数据是非常耗时的操作,并且会导致分布式内存中保存着大量无用的离散点数据,从而增大计算的体量、增加计算所花费的时间。并且,将dem数据转换为离散数据仅仅是提高了算法的分布式计算能力,但并未考虑dem的数据结构特性,忽略了栅格数据的邻域特点。
技术实现要素:
5.针对目前dem栅格数据进行路径规划耗时耗力等技术问题,我们提出了一个基于大数据平台分布式瓦片金字塔的三维路径规划方法,对于大型dem数据的路径规划任务,本方法通过集群搭建的hdfs存储框架和spark计算框架分别解决了上述单机策略中磁盘存储空间不足的问题和内存溢出问题,并将瓦片金字塔应用到分布式的路径规划任务中用以解决单机策略中搜索时间随搜索数据量增大而指数性增长的问题和分布式策略中因大量无用离散数据导致计算时间增加的问题。
6.本发明提出的基于大数据平台分布式瓦片金字塔的三维路径规划方法将大型三维地形数据dem转换为分布式瓦片金字塔存储,通过分而治之及粗细粒度转换的思路,利用spark分布式计算价格和hadoop的分布式存储能力,来减少在大型的dem数据上进行路径规划任务所花费的时间,提高了计算速度。
7.本发明可通过以下技术方案实现:
8.一种基于大数据平台分布式瓦片金字塔的三维路径规划方法,将待探索区域的大型三维地形数据dem进行分布式瓦片金字塔处理,并将生成的分布式瓦片金字塔存储到hadoop分布式文件系统hdfs内;使用spark的分布式计算集群从hdfs里由上至下读取分布式瓦片金字塔的dem数据,并采用由粗粒度到细粒度迭代的路径规划方法进行待探索区域的三维路径规划。
9.进一步,依据起点和终点信息,在spark的分布式计算集群中规划出当前金字塔层瓦片数据里对应的当前层的三维路径节点数据,筛选所述当前层的三维路径节点数据与下一金字塔层瓦片数据中相交的瓦片,并计算对应的交点,由此将当前层三维路径划分为多个局部路径,其交点分别对应各个局部路径的起点和终点,记为局部起点和局部终点,然后再以迭代的方式规划出在下一金字塔层瓦片数据里对应各个局部起点和局部终点的局部路径,共同组成对应起点和终点的下一层三维路径节点数据,重复上述由粗粒度路径规划到细粒度分布式路径规划的迭代过程,直到完成在底层瓦片数据里对应起点和终点的三维路径规划。
10.进一步,由粗粒度到细粒度迭代的路径规划方法包括以下步骤:记分布式瓦片金字塔的分层由底层到顶层分别为第0层
…
第i层
…
第n层,
11.步骤一、从hdfs里读取分布式瓦片金字塔的第i=n层dem数据,并在内存中构造对应的瓦片rdd数据;
12.步骤二、依据起点和终点信息,采用spark分布式计算架构,规划出在第i层的瓦片rdd数据里对应的第i层瓦片路径;
13.步骤三、从hdfs里读取分布式瓦片金字塔的第i-1层金字塔的瓦片数据,并在内存中构造对应的瓦片rdd数据,筛选第i层瓦片路径与第i-1层瓦片数据中相交的瓦片,并计算对应的交点,分别为第i-1层瓦片路径中各个局部路径对应的起点和终点即为局部起点和局部终点集合;
14.步骤四、采用spark分布式计算架构,规划出在第i-1层瓦片rdd数据里对应各个局部起点和局部终点的局部路径,共同组成对应起点和终点的第i-1层三维路径;
15.步骤五、记i=i-1,重复执行步骤三至四,直到完成在第i=0层瓦片rdd数据里对应起点和终点的三维路径规划。
16.进一步,从hdfs里读取dem的分布式瓦片金字塔的数据时,采用跳层读取方式。
17.进一步,将待探索区域的大型三维地形数据dem进行分布式瓦片金字塔处理,处理方式是将原始的大型三维地形数据dem进行一系列的上采样,得到的影像信息与原始的大型三维地形数据dem共同生成金字塔,再将金字塔的每层数据均切成多个大小相同矩形状的瓦片从而得到分布式瓦片金字塔,最后将生成的分布式瓦片金字塔存储到hadoop分布式文件系统hdfs内,存储方式是将每层的瓦片信息序列化为瓦片字节块和对应金字塔层的瓦片元数据,并将瓦片字节块和对应金字塔层的瓦片元数据存储到hadoop分布式文件系统hdfs的数据节点中。
18.本发明有益的技术效果在于:
19.(1)利用分布式服务器的存储特性和瓦片金字塔的模型特点,通过分布式瓦片金字塔的存储模型,将dem数据存储在hadoop分布式文件系统中,增加分布式集群中的存储效率。
20.(2)建立spark分布式处理瓦片金字塔的流程框架,通过迭代的方式,从粗粒度的瓦片路径规划任务转向细粒度的分布式瓦片路径规划任务,从而降低在大型dem数据上进行路径规划任务所花费的时间。
21.(3)在分布式路径规划任务的迭代过程中,对瓦片金字塔的分布式读取加入了跳层处理方式,减少集群运行任务的迭代次数,从而减少路径规划运行时间。
附图说明
22.图1为本发明的dem的分布式瓦片金字塔的结构示意图;
23.图2为本发明的dem数据生成分布式瓦片金字塔并存入hdfs的过程示意图;
24.图3为本发明的spark实现分布式瓦片金字塔dem的三维路径规划流程示意图;
25.图4为本发明的基于分布式瓦片金字塔的三维路径规划原理示意图;
26.图5为本发明的spark集群结构和任务分发方式示意图。
27.图6为本发明的分布式瓦片金字塔的三维路径规划方法的spark实现示意图;
28.图7本发明的当前节点在栅格地图上的方向示意图。
具体实施方式
29.下面结合附图及较佳实施例详细说明本发明的具体实施方式。
30.如图1所示,本发明提供了一种基于大数据平台分布式瓦片金字塔的三维路径规划方法,将待探索区域的大型三维地形数据dem进行分布式瓦片金字塔处理,并将生成的分布式瓦片金字塔存储到hadoop分布式文件系统hdfs内;依据spark分布式计算原理,从hdfs里由上至下读取分布式瓦片金字塔的dem数据,采用由粗粒度到细粒度迭代的路径规划方法进行待探索区域的三维路径规划。这样通过建立dem的分布式瓦片金字塔的存储模型以及spark分布式处理瓦片金字塔的流程框架,提升分布式瓦片金字塔的路径搜索效率,提高大型dem数据的远距离路径规划任务的运行速度。具体如下:
31.一、大型dem数据的分布式瓦片金字塔存储
32.针对大型dem数据的实际存储要求,本发明提出对大型dem数据进行分布式的瓦片金字塔操作,并将生成的瓦片金字塔存储在hadoop分布式文件系统hdfs内。
33.分布式瓦片金字塔的建立上是将原始的dem数据进行一系列的上采样,得到影像数据与原始的dem数据共同组成金字塔,并将金字塔的每层数据均切成多个大小相同矩形状的瓦片。如图1(a)所示,原始的dem数据为2048
×
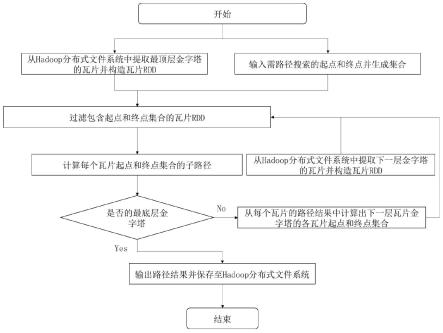
2048像元大小,把其作为第0层即为瓦片金字塔的底层,对其进行经过一系列上采样,生成瓦片金字塔,生成后的瓦片金字塔如图1(b)所示,每一层的金字塔都被切分成均匀大小的瓦片,每个瓦片都有与本层对应的瓦片行列号,瓦片行列号是用于快速定位瓦片在本层金字塔模型上的位置。
34.为加快瓦片金字塔的分布式处理,本发明采用hadoop分布式文件系统hdfs对dem数据的瓦片金字塔进行存储,hdfs是指被设计成适合运行在通用硬件上的分布式文件系统,hdfs能提供高吞吐量的数据访问和数据冗余机制,非常适合在大规模数据集上的应用。hdfs集群是典型的主从运行模式,其通过主节点和数据节点控制和管理集群的分布式存储,主节点负责存储分布式文件块的元数据,元数据的作用是定位真实数据在各个数据节点中的存储位置;数据节点负责存储和冗余备份真实数据。主节点通过网络与数据节点进
行通信。图2是依据dem数据生成分布式瓦片金字塔并存入hdfs的示意图,以像元大小为2048
×
2048的dem为例,此图展示了dem数据如何转换成瓦片的像元大小为512
×
512的分布瓦片金字塔并存入hdfs的过程,其步骤如下:
35.1.将2048
×
2048像元大小的原始dem数据经过一系列上采样得到影像数据,并与原始dem数据共同生成3层金字塔结构。
36.2.将每一层金字塔分别均切成512
×
512像元大小的瓦片。
37.3.将每层的瓦片信息序列化为瓦片字节块和对应金字塔层的瓦片元数据。
38.4.将瓦片字节块和对应金字塔层的瓦片元数据存储到hdfs的数据节点中。
39.其中,瓦片字节块为瓦片块的序列化文件,本发明通常使用z阶填充曲线或希尔伯特填充曲线序列化;瓦片元数据中包含了金字塔层级信息、瓦片行列号及对应的瓦片存储节点和存储位置信息也就是对应在当前字节块的存储信息。
40.二、基于分布式瓦片金字塔的三维路径规划
41.apache spark是专为大规模数据处理而设计的快速通用的计算引擎,其通过在内存构建弹性分布式数据集rdd和有向无环图dag来保证任务在分布式计算环境的高容错性和减少任务写入磁盘所花费的时间,rdd是spark中最基本的数据处理模型,它代表一个弹性的、不可变、可分区、可并行计算的内存集合,dag是一组顶点和边的组合,顶点用来表示rdd,边用来表示rdd之间的操作关系,spark中的dag是保证分布式计算能按顺序执行任务的关键。研究表明,spark比mapreduce的计算效率高,其主要原因是mapreduce的各阶段操作之间相互独立,所以每次mapreduce操作都会写入磁盘,而spark的dag可以根据rdd之间的操作类型来判断当前操作是否需要写入磁盘,从而通过减少写入磁盘的次数提升计算效率。
42.本发明提出的分布式瓦片金字塔的三维路径规划采用由粗粒度到细粒度迭代的路径规划方法,将大规模的路径规划任务拆解为在瓦片上进行分布式的部分路径规划子任务,并通过在dem数据上利用金字塔特性以确定每一层瓦片进行路径规划任务的起点和终点,即依据起点和终点信息,采用spark分布式计算架构,规划出在当前金字塔层瓦片数据里对应的当前层三维路径,筛选所述当前层三维路径与下一金字塔层瓦片数据中相交的瓦片,并计算对应的交点,由此将当前层三维路径划分为多个局部路径,其交点分别对应各个局部路径的起点和终点,记为局部起点和局部终点,再采用spark分布式计算原理,规划出在下一金字塔层瓦片数据里对应各个局部起点和局部终点的局部路径,共同组成对应起点和终点的下一层三维路径,重复上述过程,直到完成在底层瓦片数据里对应起点和终点的三维路径规划。其中,spark用于构造和转换每层金字塔的瓦片rdd数据,如图5所示,通过主从模式,spark将路径规划任务划分为多个子任务分配给工作节点执行,工作节点从hdfs中获取瓦片rdd数据并执行驱动节点分配的子任务,最终向hdfs写入结果。如图3所示,具体如下:
43.记分布式瓦片金字塔的分层由底层到顶层分别为第0层
…
第i层
…
第n层,
44.步骤一、从hdfs里读取分布式瓦片金字塔的第i=n层dem数据,并在内存中构造对应的瓦片rdd数据;
45.步骤二、依据起点和终点信息,采用spark分布式计算架构,规划出在第i层的瓦片rdd数据里对应的第i层瓦片路径;
46.步骤三、从hdfs里读取分布式瓦片金字塔的第i-1层金字塔的瓦片数据,并在内存中构造对应的瓦片rdd数据,筛选第i层瓦片路径与第i-1层瓦片数据中相交的瓦片,并计算对应的交点,分别为第i-1层瓦片路径中各个局部路径对应的起点和终点即为局部起点和局部终点集合;
47.步骤四、采用spark分布式计算架构,规划出在第i-1层瓦片rdd数据里对应各个局部起点和局部终点的局部路径,共同组成对应起点和终点的第i-1层三维路径;
48.步骤五、记i=i-1,重复执行步骤三至四,直到完成在第i=0层瓦片rdd数据里对应起点和终点的三维路径规划。
49.本发明是通过迭代的方式,从粗粒度的瓦片路径规划任务转向细粒度的分布式瓦片路径规划任务,从而降低在大规模dem上进行路径规划任务所花费的时间。为减少在分布式集群中对分布式瓦片金字塔进行路径规划的迭代时间,本发明在从瓦片金字塔的上层数据到瓦片金字塔的下层数据的读取操作中采用跳层处理,即隔层读取,如从最上层(n=4)的瓦片金字塔开始进行粗粒度的路径规划,并从粗粒度的路径规划的结果中计算出n-2层瓦片金字塔中每个瓦片的起点和终点,再对n-2层的瓦片金字塔进行分布式路径规划,直到计算出底层瓦片金字塔的路径规划的结果。
50.在spark实现的分布式瓦片金字塔的路径规划中,驱动节点负责广播每个瓦片的起点和终点集合并控制迭代次数,工作节点集群负责每个瓦片的子路径规划任务。如图6所示,首先驱动节点和工作节点集群从hdfs构建最顶层金字塔(i=n)的瓦片rdd和瓦片元数据,驱动节点将路径规划的起点和终点广播给工作节点集群。然后工作节点集群过滤掉不参与路径规划的瓦片rdd,根据设定的起点和终点对剩余瓦片进行子路径规划。最后根据瓦片元数据判断该层是否为最底层(i=0)。如果是,则将获取的路径节点rdd保存到hdfs,如果不是,则进行迭代操作。迭代操作是驱动节点收集从工作节点集群获取的路径节点rdd,并计算出第i-2层每个瓦片的起点和终点集合,最后通知hdfs构造第i-2层金字塔的瓦片rdd和瓦片元数据到spark并执行第i-2层的分布式路径规划。
51.为了验证本发明的三维路径规划方法的可行性,我们使用来自中国月球与深空探测工程地面应用系统的嫦娥二号ccd立体相机dem-20m数据集(中国国家航天局,2020。http://moon.bao.ac.cn)的部分dem数据进行分布式瓦片金字塔的路径规划,其中选取的dem像元总大小为32768
×
32768、分辨率为20m。参考履带式月球车,将路径规划中小车是否通过的可行坡度阈值设置为20
°
,应用于dem栅格路径规划任务中。在测试中,假设车辆的投影面积是一个网格单元,根据网格单元(i,j)(对应的高程为z
i,j
)和周围8个网格单元,形成一个3
×
3的窗口,如图7所示,利用这些信息,垂直/水平方向的坡度和斜方向的坡度使用等式(1)计算。其中cellsize为每个网格的大小:
[0052][0053]
本发明在各个瓦片上进行局部路径规划的算法采用a星算法,其启发式函数如等式2所示:
[0054]
f(p)=g(p) h(p)
ꢀꢀꢀ
(2)
[0055]
其中,g(p)是节点p到起点的距离成本,h(p)是节点s到终点的距离成本。在本研究中,使用欧几里得距离用于计算g(p),如等式3所示;曼哈顿距离用于计算h(p),如等式4所示,其中g(p
′
)表示从起点到p
′
的实际距离,g(p)为从起点经过p
′
到点p的实际距离,p
end
表示终点的位置,x,y,z分别表示节点的水平、垂直位置以及对应的高程值。
[0056][0057][0058]
下表显示了下列测试所需的四组点,测试均选取了四组点分别模拟长、中长、中等、短路径的选取。
[0059][0060]
在a星算法中,记录四组不同距离的起点和终点上,测试在单机串行模式下和分布式瓦片金字塔并行模式下进行路径规划的时间开销,如下表:
[0061][0062]
对比单机串行计算策略和分布式瓦片金字塔并行计算策略,在短距离的路径搜索的情况下,由于集群启动和rdd算子转换的时间超过路径规划的时间,导致分布式瓦片金字塔并行计算策略的时间开销大于单机串行计算策略,但在寻路路径较长的情况下,分布式瓦片金字塔并行计算策略的时间开销均小于单机串行计算策略。
[0063]
在a星算法中,记录四组不同距离的起点和终点上,测试在分布式并行计算模式下和分布式瓦片金字塔并行模式下进行路径规划的时间开销,如下表:
[0064][0065]
[0066]
结果表明,在分布式计算环境中,由于在分布式瓦片金字塔并行计算策略中保留了各像元的邻域信息,因此使用分布式瓦片金字塔并行计算策略进行路径规划的时间开销要远低于仅使用集群对dem数据进行分布式路径规划,其中在长距离的路径搜索情况下,使用分布式瓦片金字塔并行计算策略的速度是仅使用集群对dem数据进行分布式路径规划的113倍。
[0067]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。