1.本发明属于计算机软件技术领域,涉及图数据压缩,具体涉及一种基于稠密子图的图压缩方法和系统。
背景技术:
2.随着互联网、移动互联网以及web3等技术的快速发展,众多的新兴产品与应用正在以一种前所未有的速度和方式创造大量的数据,图作为一种捕捉和描述关系的数据结构,通常被理解为结点与结点之间的关系的集合,图数据十分庞大,如何对其进行有效的描述、存储、分析和运用,成为了许多行业与领域面临的重大机遇与挑战。
3.众多研究表明,许多数据挖掘任务(例如,检测异常结点、识别兴趣组、估计中心性度量等)可以利用图信息转化为图挖掘问题,并且可以通过合适的图算法来解决,而这些算法通常假设图数据存储在内存之中,通过邻接矩阵或者邻接表的结构存储。当图数据中边的规模达到数十亿、上百亿甚至更高的时候,这样的假设变得难以实现,比如具有百万结点规模的图,其邻接矩阵大小约为116gb。根据中国互联网络信息中心发表的《第48次中国互联网络发展状况统计报告》,我国的网民规模已经达到10.11亿,对于网民间关系的存储,利用邻接矩阵模型进行存储,将达到tb规模。如何存储这样规模的图数据,国内外研究人员主要从以下三个方面做了大量研究:(1)内存技术(图压缩技术):将图压缩后存储在内存中,减少图中的冗余或者以更紧凑的结构描述同样的信息,对图的搜索通常需要解压缩。(2)分布式技术:对图进行分割,对于图的存储由更多的设备来分摊,但是会带来更多的通讯开销。(3)外存技术:将图规模存储在价格低廉的硬盘上,设计高效的存储调度算法降低io开销。
4.在上述的三种解决大规模图的存储方法中,本发明主要讨论图压缩方法,该方法可以改善另外两种方法的性能以及在设备限制的场景下使用。
5.对于大规模图的存储的压缩,很重要的工作在于结点排序使得邻接结点之间的间隙减少,而结点之间的联通关系与结点号并不对应,因此图压缩经常被转化为一个搜索图中频繁子集或者被转化为寻找图中稠密子结构问题。对于稠密子图的利用可以极大的降低图中的冗余信息,逼近熵存储的下限。现有方法中,缺少对于k边联通子图(k-edge connected component,下称k-ecc)的压缩讨论。k边联通子图是指在图g上的一个子图g
′
,是k边联通的,如果g
′
不被其他k边联通图包含,则g
′
是一个k边联通子图,简称k-ecc。
技术实现要素:
6.对于图中结点的随机性问题,本发明提供一种基于稠密子图的图压缩方法和系统,针对k-ecc设计一种排序重编码方式,通过降低相邻结点的间隙来压缩图。
7.本发明采用的技术方案如下:
8.一种基于稠密子图的图压缩方法,包括以下步骤:
9.获取k边联通子图;
10.对k边联通子图及其内部的结点进行重编码,使得结构上相邻的结点具有相邻的结点号;
11.对结点的邻接表进行压缩,并构建结点索引。
12.进一步地,所述对k边联通子图及其内部的结点进行重编码,包括:对k边联通子图即稠密集合进行排序;对k边联通子图内部的结点进行重编码。
13.进一步地,稠密集合内的所有结点以一个超级结点的形式呈现给所有的稠密集合外的结点,稠密集合内的结点都是由mas策略中的结点序列l生成。
14.进一步地,所述对k边联通子图进行排序,排序的比较标准如以下公式所示:
15.dv=∑deg
in
(v)-∑deg
out
(v)
16.其中,dv表示编码后的稠密集合,deg
in
(v)表示入度,deg
out
(v)表示出度,v表示结点集。
17.进一步地,采用标识位将集合号与结点号区分开,标识位设置为8位,第一个bit位为0。
18.进一步地,所述对结点的邻接表进行压缩,包括:
19.利用邻接表对边进行存储,邻接表包括同集合内结点的邻接表和非同集合内结点的邻接表;对所有的同集合内的边做一个间隔编码压缩,并用4位的gap位记录,对于4位的首位采用一个标识位记录是否有后续;对非同集合邻居,设置标识位来表达接下来的8位为一个集合号;
20.邻接表存储的内容只包含边的目标结点,用另外的空间存储边的类型;
21.使用bwt压缩来做字符级别的压缩。
22.进一步地,所述构建结点索引,是建立二级索引,包括一级集合索引和二级结点索引,其中一级集合索引由集合数组构成,二级结点索引由结点数组构成。
23.一种基于稠密子图的图压缩系统,其包括:
24.k-ecc获取模块,用于获取k边联通子图;
25.重编码模块,用于对k边联通子图及其内部的结点进行重编码,使得结构上相邻的结点具有相邻的结点号;
26.邻接表压缩与索引构建模块,用于对结点的邻接表进行压缩,并构建结点索引。
27.本发明的关键点包括:
28.1.本发明方案引入了新的稠密子图k-ecc以及多层编码策略进行压缩,对目标压缩子图的规模进行控制使得排序图规模降低。
29.2.本发明方案对引入的稠密子图进行编码以及子图内部结点进行编码,使得结构上相邻的结点拥有相邻的结点号。
30.3.本发明方案利用间隙编码以及文本压缩对结点的邻接表进行压缩,使得邻接表的存储花费更低。
31.本发明的有益效果如下:
32.在图数据中,稠密子图内的结点通常拥有更多的边(因为子图的平均度大于全局),边两端的结点重复出现,这也导致稠密子图内的结点在存储中占用的空间较多。本发明提出一个新的较为简单的排序方式,旨在利用稠密子图进行结点重排序并重编码,使得排序不用在大图上进行从而减少结点排序的时间,并降低稠密子图中各结点在内存中的冗
余消耗。对抽取出的k边联通子图内各结点进行重编码,构建新的边的存储表示,使得图中出现频次较高的结点占用的空间得以减少。对于图的稀疏空间上,采用压缩邻接表降低存储消耗并采用二级索引提高结点邻居的查找效率。该方法具有三个好处,首先,它有效减少了将图存储在内存中所需的空间。其次,该方法非常简单易于使用。最后,该方法降低了结点间的间隙距离。
附图说明
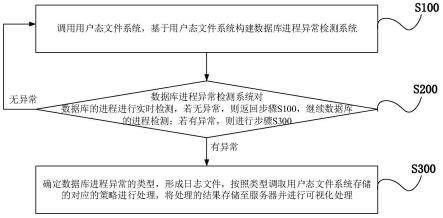
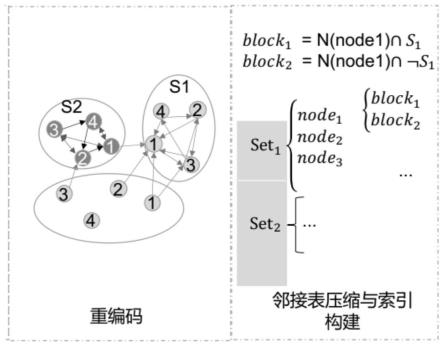
33.图1是基于稠密子图的图压缩框架示意图。其中,1~4表示二级结点索引,s1、s2表示一级集合索引,set1、set2表示结点集合,node1、node2、node3表示结点,block1、block2表示邻接表压缩块,n(node1)表示node 1的临近结点,
“┐s1”表示非同集合邻居。
34.图2是单结点存储示意图。
35.图3是边存储编码示意图(以1000020
→
323884332为例)。
36.图4是邻接表存储表示图。
37.图5是结点索引结构图。
38.图6是结点间隙对比图(圆圈表示mloggapa,加号表示本发明方案)。
具体实施方式
39.为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。
40.对子图抽取的图压缩的问题,可以转化为将初始图表示成图g,抽取出的多k-ecc子图,对子图以及子图内的点重新排序,并重新编码,确定每个结点的存储符,使得初始图上的每条边,无损的存储在内存中,并减少存储所需的空间。本发明方案假设k-ecc子图已经通过相关算法抽取出来。
41.本方案提出的基于稠密子图的图压缩方法的整体框架如图1所示。模型包含两个部分:重编码(recode)和邻接表压缩与索引构建(nebcompress)。排序重编码针对两个部分即稠密集合和稠密区内结点进行编码,以使得序号较小的结点拥有较多的边;邻接表压缩与索引构建是对非稠密区部分进行重新组织使得对具体结点的邻居查找和存储拥有良好的性能。如果一个派生集合在定义时省略了元素列表,那么意味着他的元素是全部父级元素的所有组合构成的,这样的集合被称为稠密集合。稠密区是指图中高相似性和高局部性的区域。具体实施方案将对这两个部分进行详细的介绍。
42.1.结点重编码
43.为了减少边图的类型,利用k-ecc子图结构的相似且稠密的特点可以设置结构上相近的结点拥有相近的结点号来降低边图的可能数,以此降低编码的范围,本步骤的工作是对于划分后的子图进行一个排序并设计编码方法。
44.对获取的稠密区进行一个排序以使得图中的结点之间的间隙更小更利于控制存储成本。首先,不考虑稠密集合内的结点的编码,假设稠密集合内的所有结点以一个超级结点的形式,呈现给所有的稠密集合外的结点。通过此假设,可以将原图中所有的拥有较高概率高度的结点集合揉合为一个结点,使得包含许多这样稠密集合的原始图的局部区域的局部性和相似性降低,图也变得相对更加的稀疏。对于这种比原图更加稀疏的图,本发明对其
做的编码方案是重排序后依次编号,排序的比较标准如以下公式所示。
45.dv=∑deg
in
(v)-∑deg
out
(v)
46.其中,dv表示编码后的稠密集合,deg
in
(v)表示入度,deg
out
(v)表示出度,v表示结点集。
47.将稠密集合理解为一个结点,对于一个结点,重要的是该结点的入度,这是因为排序后,所有的边在内存中的存储顺序都是以该结点为头结点进行存储,那么以该结点作为目标结点的边查找是很难找到的,同时,以该结点为源结点的边,可以通过邻接表进行压缩,剔除掉上述重复出现的头结点。因此排序的规则为入度减去出度的目的,是降低修改该结点为目标结点的难度。
48.其次,只考虑稠密集合内的结点,稠密集合内的点的编码方式和稠密集合的编码方式一致,但是这里并不做排序,因为对于获取到的稠密集合内的结点都是由mas策略中的结点序列l生成的,l自带排序,其排序规则基于l中的结点v与在v之前加入l的内部结点的连接度数的大小。这里需要注意的是,本发明方案的所有数据集,都以做了虚拟双向边为前提。其中,mas策略采用现有方法实现,其将父图分割成两个部分,一个是结点序列l,一个是剩余子图,对于l进行s-t cut判断最后的两个结点是否属于一个k-ecc,对于剩余子图,则是任意选择一个结点重新进行上述过程。
49.在重新排序后,所有结点的存储都将原数据存储的两个64位或32位结点,转化为了8个或4个8位的结点号,为了去除掉存储中的前导零并与后续的结点作以区分,这里采用了标识位作为隔离,标识位(flag)设置为8位,第一个bit位为0,如图2所示。这样就将集合号与结点号区分开来。除了边本身两端的结点需要存储以外,还需要存储的是边本身的类型。这里本方案以github的边类型作为假设边的类型,并不考虑实际的字符存储,统一的以单个数字字符进行存储,假设其花费位为4位,共可以表达16种边的类型。整个边存储编码流程如图3所示(1000020\to 323884332为例)。
50.2.邻接表压缩与索引构建
51.对每条边进行存储将会消耗一半的空间用于边的头结点上,这一点可以利用邻接表进行处理,但是邻接表的引入将会导致之前对于边的存储方案并不高效。本步骤将介绍邻接表的布置与结点索引的构建。分别是为了处理头结点的重复和压缩后的数据查找问题。
52.邻接表压缩基于间隙存储的思想,对于每一个结点的出边,本发明方案认为是对所有的同集合内的边做一个间隔编码压缩。这一点是因为,间隔编码可以很好的利用上文的工作中稠密子图内的结点在结构上是非常临近的且在结点号上也是临近的这一特点,因此本发明方案对于这些间隙采取一个间隙编码,并用4位的gap位记录。考虑到4位的gap位过于狭小,所以采用如同第1部分中的结点编码,对于4位的首位采用一个标识位记录是否有后续。假设对于某个稠密集合内的点v,拥有同集合邻居结点3,4,18以及非同集合邻居集合号为2的结点号为11以及集合号为3的结点号为19以及21的邻居,以此为例,同集合内结点的邻接表表示如图4所示。非同集合邻居则采用一个新的表示格式,即设置标识位(1000)(setflag)来表达接下来的8位为一个集合号,其余与之类似。同时,该表存储的内容只包含了边的目标结点,并用另外的空间存储边的类型。当同集合内的边过多的时候,利用与结点数等长字节数表示结点号,当两个结点间单向边超过一条,可以使用后继位码来存储边的
类型,进一步降低边的总储存。
53.除了在邻接表做了一个新的表示,还使用了bwt压缩来做字符级别的压缩。字符的压缩有很多方式,采用bwt的压缩是因为考虑到每一个字节都包含了很短的信息,如集合号或者结点号的一部分,这种情况下,使用游程编码很难找到长段的重复的字符串。不仅如此,同集合内每个结点号都只出现一次,哪怕是多个集合内的结点号,也由于分布的分散,很少出现很多次。在多重障碍下,选择了bwt做字符压缩。
54.当边的规模达到十亿甚至百亿级别,对于每一次图上结点的查找都变得非常的困难。因此,设计一个好的索引的表示对图的压缩也是非常的重要。
55.当处理完以上所有的步骤以后,现在的数据已经自带了一些特征,例如每一个结点自带了一个集合号(非k-ecc子图的结点同样构建成一个集合参与排序),并且,每一个结点都自带了一个邻接表,因此,本发明设计了一个二级索引,包括一级集合索引和二级结点索引,一级集合索引是由集合数组构成,二级结点索引由一个结点数组构成。采用数组是为了在查询的时候便于直接索引到该结点。索引的部署结构如图5所示。
56.本发明设计实验来从三个方面证明本方案的技术先进性。(1)与现有基于稠密子图的压缩技术相比,本发明提出的压缩算法对于原始图的压缩率如何?(2)本发明的压缩算法在各类数据集上压缩的速率如何?(3)本方案在排序后,是否降低了图的结点的间隙距离?
57.本发明分为了两个部分做对比实验,分别别压缩率与压缩时长的对比实验以及重编码后结点间隙对比实验。
58.发明实验的硬件配置如下:intel i7-11800h cpu(主频:4.60ghz 8核16线程),128gb ddr3内存,linux ubuntu 18.04(64位)操作系统。代码以c 实现,用gcc 8.2.1编译并采用o3优化。
59.本发明的实验使用了几个公开可用的构造图、网络图、社交网络,见表1。并以这些数据集表明本发明的拓展性。在运行测试之前,所有图都进行了k-ecc抽取。因为缺少带类型的数据集,在实验中给每一条边随机的增加了类型。以下是实验中的采用的数据集:
60.(1)r-mat是一种构造集,使用了一个简单的递归模型仅用几个参数,可以快速生成逼真的图。利用这个模型可以轻松生成加权图、有向图和二分图;利用r-mat可以生成符合著名的概率的图且可以满足幂律分布。我们利用r-mat生成权重为整数的加权图,以权重模拟边的类型。
61.(2)web-google是一种网络图,每一条边表示网页之间有超链接。该数据由google于2002年发布;数据可在https://snap.stanford.edu/data/web-google.html找到。
62.(3)twitter是一个公开的推特社交数据集,拥有4100万个结点,和24000万的边。
63.(4)livejournal是一个拥有近1000万会员的免费在线社区;这些成员中有很大一部分非常活跃。(例如,在任何给定的24小时内,大约有300,000人更新他们的内容。),
64.(5)ca-mathscinet是一个数学科学文献的评论、摘要和书目饮用相关关系的数据集。该数据集可以在https://networkrepository.com/ca-mathscinet.php找到。
65.表1压缩实验中使用的数据集主要属性
[0066][0067]
图涉及结点最多且处理时长低于1000s的k值,数据集都采用k=8作为切分图参数。边类型强制占用四个bit,对应16种边类型。
[0068]
对于不同的场景,本发明希望能尽可能多的考虑不同类型的图上的一般性,在实验中采用了空间和压缩时长来描述。对于压缩空间上,采用压缩后的每条边的平均占用字节bits数(bits per edge,以下简称bpe)以及压缩率来描述,其中gc标识压缩后的存储总字节数,g标识压缩前总字节数。时间上采用总时间消耗(秒s)描述。在结点间隙上,本发明将图中边两端的结点号相减,对于被本发明处理过的压缩图的不同集合间的结点,采用如下公式来描述。
[0069][0070]
其中seti.n集合i内的结点数量,nodes为头结点的集合内结点号,nodes为尾结点的结点号。为了便于统计排序效果以及解决排序后结点与原结点并不一致的问题,使用结点 邻接表的形式进行存储一个结点,并以(一个结点存储总字节数/一个结点的邻居数)表达bpe。
[0071]
实验采用的baseline是以下三个算法:
[0072]
(1)graphzip算法:寻找图中的团结构并记录团的首结点号以及非团结点号压缩成一个超结点,使得查询图更小。
[0073]
(2)mloggapa算法:利用二分图对图的结点进行重排序以缩小图结点间的间隙。
[0074]
(3)cc算法:对图中的团结构进行发掘并压缩存储,对团的查询存储提供了新的搜索方式。
[0075]
1.压缩率和压缩时间比较
[0076]
在实验过程中,将本发明提出的方法在以上几个数据集上与基准算法graphzip和cc算法进行比较,以验证在时间和空间上基于结点重编码的稠密子图方法有效性。实验结果如表2所示,其中,本发明使用粗体标识出各项指标中最佳的实验结果。
[0077]
表2的实验结果表明,与现有的基于稠密子图的压缩方案相比,本发明提出的结点重编码压缩方法对于结点规模越大的图压缩效果更好,时间效率更高。从实验的结果可以看出,相较于graphzip算法,本方法在构造集web-google、twitter和livejournal上,压缩后的bpe要低2-5个比特,同时,在规模更大的图如twitter上,graphzip方法无法有效的在短时间内(10000s)完成图的压缩工作。但是graphzip的与本方法在平均度不同的场景下,有着不同的效率,在web-google数据集上和ca-mathscinet数据集对比上,本方法从图的平
均度增长中获得的收益稍弱于graphzip,web-google数据集的密度和ca-mathscinet相当但是平均度相差2.3倍,在这种稠密度更大的图上本方法增长率稍弱于graphzip,其中一种可能是平均度的增加导致了团量的增加。对比cc算法,本方法在多数数据集上效果更好,并且在压缩速率上本方法均高于cc算法,由于cc算法允许以压缩的形式查询,本方法事实上在解压缩的时候需要对图进行更多的操作。另外也可以从web-google和ca-mathscinet的对比中看出,web图的压缩相较于社交图更容易。
[0078]
表2时间和空间上对比的结果
[0079][0080]
2.结点间隙变化
[0081]
在结点排序上,本实验将与mloggapa算法进行比较。图6表示livejournal数据集上,图的间隙长度对应的结点的数量,x轴为间隙长度,y轴为结点数量。可以直观的看出,本发明的结点排序比自然排序更好,与mloggapa比较,本发明在间隙长度10-1000区段上汇聚结点更多并在更大间隙上结点稍少且低间隙数量更多。同时,在实验中发现,本发明每轮排序时使用的图规模是子图规模,这也为并行化算法提供可能。可以看出本发明有助于降低结点间隙,这也是本发明方法在时间与空间压缩上优于别的方法的原因。
[0082]
基于同一发明构思,本发明的另一实施例提供一种基于稠密子图的图压缩系统,其包括:
[0083]
k-ecc获取模块,用于获取k边联通子图;
[0084]
重编码模块,用于对k边联通子图及其内部的结点进行重编码,使得结构上相邻的结点具有相邻的结点号;
[0085]
邻接表压缩与索引构建模块,用于对结点的邻接表进行压缩,并构建结点索引。
[0086]
其中各模块的具体实施过程参见前文对本发明方法的描述。
[0087]
基于同一发明构思,本发明的另一实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0088]
基于同一发明构思,本发明的另一实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
[0089]
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。