1.本发明涉及图神经网络应用领域的技术,具体是一种基于异质图卷积网络的虚假新闻识别方法。
背景技术:
2.虚假新闻是指在社交媒体上故意发布并可以被证实为假的消息。社交媒体的广泛应用使得虚假新闻的传播更为迅速、传播范围更广,使得虚假新闻的传播不但会对网络安全、社会经济造成影响,还会损害政府、媒体的公信力。因此尽早识别虚假新闻成为一项至关重要的工作。当前虚假新闻检测方法可以分为两类:基于文本内容的方法和基于社交网络交互信息的方法。
3.基于文本内容的方法侧重于通过新闻文本提取词汇特征、语法特征、写作风格特征,并通过特征分类方法进行虚假新闻的判断。但这种方法通常独立的分析新闻文本,忽略了新闻传播时的新闻与新闻、新闻与用户之间深层次的结构关系。
4.为弥补以上问题,基于社交网络交互信息的方法在文本的基础上,融合了社交网络中用户与新闻、新闻与新闻、用户与评论之间的关系,通过这些更深层次的关系来提升虚假新闻识别的性能。bian和ma等人利用源新闻与评论之间的关系形式化为一个树形的传播图,然后通过图表示方法进行进一步分类。yuan和yang等人将用户、源新闻、评论一起建模为一个新闻传播异质图,然后通过图表示学习模型进行节特征学习并进行分类。虽然这类方法在虚假新闻检测方面取得了优异的效果,然而在图学习过程中忽略了新闻传播图中边的真实性以及图中本身存在的拓扑不平衡性,使得这类方法的新闻特征学习效果受到了限制。
技术实现要素:
5.要解决的技术问题
6.为了避免现有技术的不足之处,本发明提供一种基于异质图卷积网络的虚假新闻识别方法。
7.技术方案
8.一种基于异质图卷积网络的虚假新闻识别方法,其特征在于步骤如下:
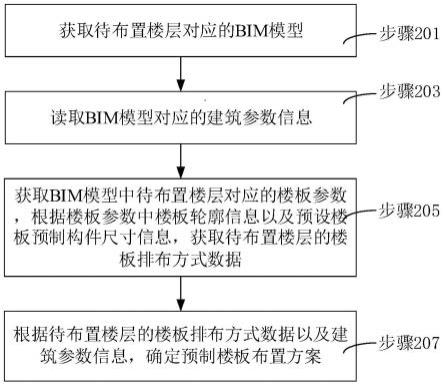
9.步骤1:从社交平台中获取新闻数据,所述新闻数据包括源新闻m、相关评论c以及相应的用户u,并根据三者之间的联系构建一个异质新闻传播图hng;
10.步骤2:使用自然语言处理模型对源新闻内容、评论内容进行文本特征信息获取;
11.步骤2.1:使用自然语言处理模型对文本进行初始特征获取;
12.步骤2.2:为进一步获取源新闻与评论之间的上下文语义特征,通过多头自注意力模型获取评论与源新闻的相关性,从而为新闻、评论得到新的具有上下文语义的特征;并将此特征作为异质图学习中源新闻节点、评论节点的初始特征向量;
13.步骤3:设计层次图卷积模型进行学习hng结构,并得到节点的结构特征;
14.步骤3.1:设计拓扑平滑策略为新闻传播网络中的每个节点获取其拓扑位置权重;
15.步骤3.2:设计层次图注意力机制对构建好的hng进行训练,并对网络中每个节点进行特征学习;
16.步骤4:将步骤3中得到的网络结构特征与步骤2中得到的文本信息特征相融合,进而产生新的向量进行进一步分类操作,达到虚假新闻检测的目的。
17.本发明进一步的技术方案:步骤1中社交平台为微博和twitter,并从中获得了三个数据集,分别为weibo、twitter15和twitter16。
18.本发明进一步的技术方案:步骤1中异质新闻传播图hng的构造方式具体为:
19.①
若用户与用户存在关注关系、或都评论或转发了同一则新闻,则将两个用户连接;
20.②
若用户评论或发布了一则新闻,则将用户与评论节点连接、将用户与新闻节点连接;
21.③
若新闻与新闻是同时段发布的,或者具有共同的用户,则将新闻与新闻连接;
22.④
若一则评论是另一则评论的回复,则连接这两则评论。
23.本发明进一步的技术方案:步骤2.1中所使用的自然语言处理模型为cnn模型,目的为每一则新闻、每一则评论信息学习一个代表此句话的特征向量。
24.本发明进一步的技术方案:步骤2.2中所使用的多头自注意力模型输入为由步骤2.1获得的每一则新闻、每一则评论的特征向量,通过多头自注意力机制进行交叉学习新闻与评论之间的句子的语义关系,最终为每一则新闻、每一则评论获得一个代表上下文语意特征向量。
25.本发明进一步的技术方案:步骤3.1中拓扑平滑策略中每一个节点的拓扑权重计算,具体为:
26.首先,通过个性化pagerank算法来衡量每个标记节点的节点影响分布,最终得到概率矩阵p,计算公式如(1)所示,其中a∈(0,1]是随机游走概率;
27.p=a(i-(1-a)a
′
)-1
ꢀꢀꢀ⑴
28.其次,假设一个有标签的新闻节点mi受到来自其他标签的邻居节点的强烈影响时,节点mi在消息传递中遇到较大的影响,并且接近拓扑类边界;基于此假设,本发明设计基于节点信息冲突检测的拓扑不均衡量化指标tm,来捕捉图的拓扑不平衡程度,在减少靠近类边界节点的训练权重,增加靠近类中心节点的训练权重的同时,来重新对目标节点加权;权重计算公式如下所示:
[0029][0030]
式中,w
min
,w
min
为超参数,tm表示拓扑值,rank(tm)表示将拓扑值tm升序排序,y表示有标签的新闻节点;最终,为网络中的每个节点都得到相应的拓扑权重值,只取新闻节点的权重值wm用于后续计算。
[0031]
本发明进一步的技术方案:步骤3.2中层次图注意力机制中每种类型节点的特征向量学习,具体为:
[0032]
首先通过节点级注意力捕捉目标节点的其他类型邻居节点的重要性;然后通过类型级注意力获取与目标节点的相同类型的邻居节点的权重,公式如(3)(4)所示;
[0033][0034][0035]
式中,σ(
·
)表示leakyrelu函数;τ表示节点类型,分别为新闻、评论、用户三类。
[0036]
本发明进一步的技术方案:步骤4中特征融合与分类模块,具体为:
[0037]
首先,对于任意一个新闻节点mi,通过步骤2.2获得其文本特征通过步骤3.2获得其结构特征为更有效处理特征,本发明将相融合得到最终的特征,然后通过交叉熵来进行训练最后一层的节点权重进行虚假新闻分类,计算公式如下:
[0038][0039][0040]
式中,w为参数矩阵,b为误差参数,l表示类别个数。
[0041]
有益效果
[0042]
本发明提供的一种基于异质图卷积网络的虚假新闻识别方法。首先,设计一种新的拓扑平滑策略来度量每个节点的拓扑权值,通过增大靠近类中心的节点的权重、减少远离类中心的节点的权值来获取每一个节点的拓扑权重。其次,采用分层注意机制来自适应学习新闻传播网络中每条边的权重,以此来衡量每条边的重要程度,来缓解不真实的边带来的负面影响。
[0043]
与现有技术相比,本发明具有以下有益的效果:
[0044]
1、本发明设计了一个拓扑平滑策略来度量标记节点的拓扑权值,以缓解拓扑不平衡的问题。
[0045]
2、在此基础上,本发明提出一种分层注意机制来学习hng的特征,通过对每个关系的权重进行适当的衡量,来识别关系的真实性,从而有效地减少非真实性关系对hng的影响。
[0046]
3、在标准数据集上的实验结果证明,本发明涉及的技术模型取得了比现有方法更加优秀的表现。
附图说明
[0047]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
[0048]
图1为本发明实例中所述方法的总体模型框架图。
[0049]
图2为本发明实例涉及到的异质新闻传播图(hng)示意图。
[0050]
图3为本发明实例中所述方法中多头自注意力机制算法框架图。
[0051]
图4为本发明实例中所述方法与现有方法的早期新闻检测效果对比图。
具体实施方式
[0052]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不
用于限定本发明。此外,下面描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0053]
本发明提出一种基于异质图卷积网络的虚假新闻识别方法,由四个子模块组成:文本数据获取及异质新闻传播图构建模块、文本特征获取模块、层次图卷积模块以及节点分类任务训练模块。整体模型框架如图1所示,具体如下所述:
[0054]
1.文本数据获取及异质新闻传播图构建
[0055]
1.1文本数据获取
[0056]
本发明所使用的数据从微博、twitter社交平台中获取,最终得到的weibo数据集、twitter15数据集、twitter16数据集为已被证实使用的公开数据。数据中包含新闻m=[m1,m2,...,mn],以及每则新闻对应的评论r=[r1,r2,...,rj],用户u=[u1,u2,...,ur]
[0057]
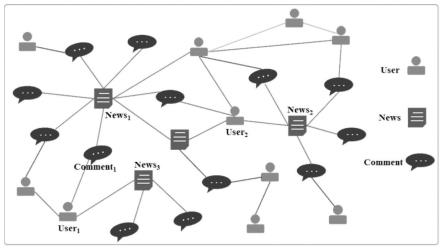
1.2异质新闻传播图(hng)构建
[0058]
本发明根据新闻文本、评论、新闻用户三种节点,建模《用户-发布-新闻》、《源新闻-相近时间/相似-源新闻》、《评论-点评-源新闻》、《评论意见-赞同/质疑-新闻》、《用户-关注-用户》五种关系,构建异质虚假新闻网络hng以丰富虚假新闻的信息,最终构建的hng如图2所示。为更方便描述方法,本发明将hng记作g=(v,e),a表示邻接矩阵,a
′
=a i表示加入自环的邻接矩阵,d表示度矩阵。
[0059]
2.文本特征获取
[0060]
2.1初始文本特征获取
[0061]
对于一则源新闻mi及其评论r=[r1,r2,...,rj]。首先,利用cnn获取新闻mi的初始序列特征cnn特征获取公式为:
[0062][0063]
式中,w表示卷积核参数矩阵,σ(
·
)表示非线性激活函数。同理提取每个回复rj的特征
[0064]
2.2文本上下文语意特征获取
[0065]
为进一步提炼评论和源新闻之间的语义表示,使用多头自注意力机制来以捕获新闻内容和评论之间的相关性。具体而言,使用注意机制对所有句子进行模型交叉检查,以捕捉它们之间的连贯性。经过上述语义一致性编码过程,得到每个新闻的文本特征评论的特征多头自注意力模型如图3所示。
[0066]
3.层次图卷积模型
[0067]
3.1拓扑平滑策略
[0068]
在图结构hng中,不同类别的训练样本不仅有在数量上的差异,也有在位置结构上的差异,具体到节点分类任务中,标注(训练)节点在图上的分布也是不均匀的,由此产生拓扑不平衡问题。为缓解由于拓扑不平衡带来的模型训练能力不佳的问题,首先,通过个性化pagerank算法来衡量每个标记节点的节点影响分布,最终得到概率矩阵p,计算公式如(8)所示,其中a∈(0,1]是随机游走概率。
[0069]
p=a(i-(1-a)a
′
)-1
ꢀꢀꢀ⑻
[0070]
其次,假设一个有标签的新闻节点mi受到来自其他标签的邻居节点的强烈影响
时,节点mi在消息传递中遇到较大的影响,并且接近拓扑类边界。基于此假设,本发明设计基于节点信息冲突检测的拓扑不均衡量化指标tm,来捕捉图的拓扑不平衡程度,在减少靠近类边界节点的训练权重,增加靠近类中心节点的训练权重的同时,来重新对目标节点加权。权重计算公式如下所示:
[0071][0072]
式中,w
max
,w
min
为超参数,tm表示拓扑值,rank(tm)表示将拓扑值tm升序排序,y表示有标签的新闻节点。最终,为网络中的每个节点都得到相应的拓扑权重值,只取新闻节点的权重值wm用于后续计算。
[0073]
3.2层次图注意力机制
[0074]
在异质新闻传播结构hng中,给定一个特定的节点,不同类型下相邻节点可能会对其产生不同的影响,同类型下各相邻节点也可能具有不同的重要性。因此,为了同时捕捉节点级和类型级的不同重要性,采用双层注意力机制辨别虚假新闻,具体为通过节点级注意力(node-level attention)捕捉目标节点的其他类型邻居节点的重要性;然后通过类型级注意力(type-level attention)获取与目标节点的相同类型的邻居节点的权重,公式如(10)(11)所示。式中,σ(
·
)表示leakyrelu函数;τ表示节点类型,分别为新闻、评论、用户三类。
[0075][0076][0077]
4.虚假新闻分类
[0078]
本发明将虚假新闻检测看做是分类问题。对于任意一个新闻节点mi,将其在hng中的结构特征与文本特征相结合。最终,通过交叉熵来进行训练最后一层的节点权重进行虚假新闻分类,计算公式如下:
[0079][0080][0081]
式中,w为参数矩阵,b为误差参数,l表示类别个数,比如weibo数据集只有两类(真新闻、假新闻),而twitter15和twitter16数据集有四类。
[0082]
5.实验与结果
[0083]
5.1分类效果
[0084]
表1展示了本发明在twitter15,twitter16数据集上的分类效果。结果显示,本发明在所有数据集上的性能都优于最先进的基于图的glan。具体而言,在twitter15和twitter16数据集的所有指标上,trhan比最佳模型的准确性分别提高了2.5%和1.7%。这主要归因于两个原因,首先,trhan考虑了新闻传播图中固有的不可靠关系和丰富的结构特征。其次,与cgat和glan不同,trhan更关注新闻图上的节点拓扑不平衡问题,这有助于提升模型效果。
[0085]
表1 twitter15,twitter16数据集上trhan方法的检测性能
[0086][0087][0088]
5.2早期检测性能
[0089]
早期阶段对假新闻进行检测对于限制假新闻的传播范围尤为重要。检测期限越早,可以得到的评论和用户等传播信息就越少。为了评估早期假新闻检测的性能,本发明设置了一系列的检测期限[0h,2h,4h,6h,8h,12h,24h)。图4展示了早期假新闻检测的性能。从图中得知,trhan方法在很早就达到了较高的准确率。具体而言,trhan在2小时内微博数据集的准确率高达94%,twitter15数据集上和twitter16数据集上的准确率分别达到准确率87.2%和84.9%,比其他方法的结果高很多。
[0090]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。