一种基于数据增强和残差cnn的水声目标识别方法
技术领域
1.本发明属于数字信号处理、机器学习和水声测量等领域,涉及一种基于数据增强和残差cnn的水声目标识别方法,利用数据增强技术和残差cnn模型,实现在水声目标样本数据相对稀缺的场景下的声信号识别。
背景技术:
2.在机器学习技术迅速发展的背景下,由于神经网络等数据驱动模型可挖掘不同目标声信号的深层特征,且在很大程度上可减少噪声的影响,有效实现分类决策的自主化与智能化,因此,在声音信号处理领域,机器学习方法得到了广泛的研究和应用,但水声目标样本数据相对稀缺,使得机器学习在实际水声识别中的应用受到限制。在2013年,kamal等将深度置信网络(deep brief network,dbn)模型应用于水声信号被动目标识别任务中,实现了无标签的水下目标声信号识别(s.kamal,s.k.mohammed,p.r.s.pillai,m.h.supriya,“deep learning architectures for underwater target recognition,”.sympol 2013,pp.48-54.)。在2014年,shamir等人在提取鲸鱼声学特征的基础上,利用机器学习方法实现了不同种类鲸鱼的自动识别(l.shamir,c.yerby,r.simpson,a.m.von benda-beckmann,p.tyack,f.samarra,et al,“classification of large acoustic datasets using machine learning and crowdsourcing:application to whale calls,”journal of the acoustical society of america,2014,vol.135no.2,pp.953-962.)。2017年,yue等人利用svm、dbn和cnn模型,实现了船舶目标声信号的有效识别(hao y,zhang l,wang d,et al.the classification of underwater acoustic targets based on deep learning methods.2017 2nd international conference on control,automation and artificial intelligence.2017.)。在2020年,yu等人搭建了多种机器学习模型,用于检测北大西洋露脊鲸的发声,结果表明cnn模型可很大程度地提高准确度(y.shiu,k.j.palmer,m.a.roch,e.fleishman,x.liu,e.m.nosal,t.helble,d.cholewiak,d.gillespie,and h.klinck,“deep neural networks for automated detection of marine mammal species,”sci.rep.10(1),1-12(2020).)。
3.随着机器学习模型层数及复杂度的增加,使得对数据量的要求越来越大,只有通过海量的有标签数据训练模型才能达到好的识别效果,而现实中,水声目标样本数据相对稀缺,使得机器学习在实际水声识别中的应用受到限制。为了增加机器学习训练所需的样本量,数据增强方法已成为最流行的技术之一(fong,r.,&vedaldi,a.(2019).occlusions for effective data augmentation in image classification.)。传统数据增强技术通过添加几何变换、颜色空间变换等方法实现训练样本的扩充。但由于传统数据增强技术无法得到实质上的生成样本,且修改量较小,数据扩充后的训练性能受到限制。为避免传统数据增强技术的局限性,goodfellow等人提出了生成对抗性网络(generative adversarial network,gan),通过生成器和鉴别器的对抗式训练,得到与真实数据分布一致的生成数据(goodfellow i,pouget-abadie j,mirza m,et al.generative adversarial nets[c]//
neural information processing systems.mit press,2014.)。
[0004]
综上所述,在水声目标样本数据匮乏的场景中,一种将声信号特征提取技术、数据增强技术和机器学习方法相结合的水声目标识别方法是必不可少的。
技术实现要素:
[0005]
要解决的技术问题
[0006]
为了避免现有技术的不足之处,本发明提出一种基于数据增强和残差cnn的水声目标识别方法
[0007]
技术方案
[0008]
一种基于数据增强和残差cnn的水声目标识别方法,其特征在于步骤如下:
[0009]
步骤1:提取各个类别水声目标信号的mfcc特征;
[0010]
步骤2:将每5个连续帧mfcc特征并联拼接生成一个二维矩阵,此二维矩阵可绘制为彩图,以此作为单个样本的输入特征图像,即初始特征图像,各个类别均选取其中3/4的图片样本用于模型的训练和验证,剩余的1/4用于模型的测试;
[0011]
步骤3:采用传统数据增强技术,设置多个图像对比度范围,得到不同对比度范围的生成图,并设置图像水平和垂直方向的缩放范围和平移范围。
[0012]
步骤4:将特征图像输入深度卷积生成对抗网络dcgan模型训练,dcgan模型包括鉴别器和生成器,两个网络通过对抗共同进步,以达到样本生成的最佳效果,从而输出得到相应的生成特征图像;
[0013]
步骤5:在resnet18模型的基础上搭建残差cnn分类模型,去掉其中的池化层,并调节其输入层、全连接层和输出层换为适合识别任务的尺寸,将该残差cnn模型作为识别任务的分类模型,并将特征图像转化为与resnet18模型中的卷积层尺寸相匹配的尺寸;
[0014]
步骤6:将初始特征图像、步骤3经过调节对比度处理和步骤4深度卷积生成对抗网络dcgan模型的多个生成特征图像均作为残差cnn模型的输入特征,对残差cnn模型进行训练,并对测试数据以及数据识别。
[0015]
所述提取水声目标mfcc特征:对每帧信号做fft得到频谱,将频谱通过一组三角带通滤波器滤波得到mel滤波,计算每个滤波器输出的对数能量,并计算其离散余弦变换,求出l阶的mfcc,计算l个mfcc倒谱差分参数,将mfcc、一阶和二阶的倒谱差分参数三部分参数组合作为信号的特征向量。
[0016]
所述对初始特征图像采用传统数据增强技术:调节图像对比度范围:0.1~0.9,0.2~0.8和0.3~0.7,原始信号图可通过调节对比度得到3个生成图;设置图像水平和垂直方向的缩放范围均为0.9~1.1,平移范围为-30~30个像素点。
[0017]
所述深度卷积对抗网络dcgan模型包括鉴别器和生成器,且鉴别器和生成器相连,生成器用于生成仿真样本,判别器对样本的真实性进行判断;鉴别器输入图像样本,其结构包括4个卷积核尺寸为5*5的卷积层,滤波器数量分别为64、128、256和512,每个卷积层后包括一个范归一化层和relu激活层,最后为一个卷积核尺寸为4*4的卷积层,滤波器数量为1;生成器输入随机噪声,且需要经过投影和重塑,其结构包括3个卷积核尺寸为5*5的转置卷积层,滤波器数量分别为256、128和64,每个转置卷积层后包括一个范归一化层和relu激活层,最后为一个卷积核尺寸为5*5的转置卷积层,滤波器数量为3。
[0018]
所述残差卷积神经网络resnet18模型,在resnet18模型的基础上,去掉其中的池化层,并将输入层、全连接层和输出层换为与识别任务相吻合的尺寸,搭建残差cnn模型,输入层尺寸为224*224*1,全连接层尺寸与识别任务中的目标类型数量一致。
[0019]
所述图像尺寸和resnet18模型中输入层、全连接层和输出层的相吻合的尺寸为224*224。
[0020]
有益效果
[0021]
本发明提出的一种基于数据增强和残差cnn的水声目标识别方法,主要包括提取水声目标mfcc特征、数据增强处理和resnet18模型识别,充分发挥了数据增强技术的数据扩充优势和残差cnn模型的深层特征挖掘能力,有效识别水声目标。
[0022]
mel频率倒谱系数(mel-frequency cepstral coefficient,mfcc)是一种在语音识别中广泛使用的特征,是基于人耳特性提出的。由于人耳结构的特殊性,听者能够自动分离语音的低频部分和高频部分,其中低频部分是辨识语音特性的主要部分。
[0023]
本研究的生成对抗网络由生成器和判别器组成。训练过程中,生成器用于生成仿真样本,判别器对样本的真实性进行判断,生成对抗网络基本框架如图1所示。两个网络通过对抗共同进步,以达到样本生成的最佳效果。训练完成后,只保留生成网络用于样本生成。深度卷积生成对抗网络(deep convolutional generative adversarial networks,dcgan)由gan模型衍生而来,dcgan将cnn和基础gan相结合,生成器和鉴别器均运用到了深度cnn。dcgan提高了基础gan的稳定性和生成结果质量。
[0024]
本发明有益效果:
[0025]
1、本研究采用dcgan模型,dcgan具有优异的生成图像架构,相比传统gan模型,dcgan的训练相对稳定,且dcgan判别器通过引入cnn模型可提取到更深层的图片特征,在图像生成和分类上具有较大的优势。
[0026]
2、本研究采用调节图像对比度的方法,设置了三个对比度范围:0.1~0.9,0.2~0.8和0.3~0.7,从而原始特征图可通过调节对比度得到3个生成图,实现特征图像的扩充。
[0027]
3、分类模型采用具有残差连接的resnet18模型,本研究在resnet18模型的基础上,去掉其中的池化层,保留更多水声特征信息,调节网络模型的尺寸,从而与本研究输入的特征图像相适应。
[0028]
4、本研究使用了传统数据增强技术和dcgan模型,扩充了由水声数据提取出的mfcc特征拼接得到的特征图像,从而在水声目标样本数据相对稀缺的场景中,利用数据增强技术和残差cnn模型,实现了水声目标的有效识别。
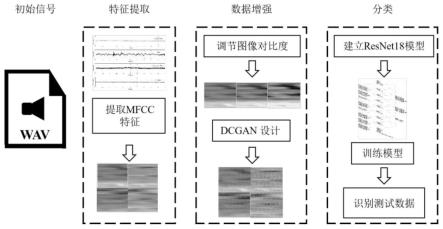
附图说明
[0029]
图1:生成对抗网络基本框架
[0030]
图2:总体流程框图
[0031]
图3:鉴别器框图
[0032]
图4:生成器框图
[0033]
图5:deepship数据集船舶原始信号波形图
[0034]
图6:不同种类船舶mfcc特征
[0035]
(a)拖船;(b)货轮;(c)油轮;(d)客船
[0036]
图7:不同种类船舶图像样本
[0037]
(a)拖船;(b)货轮;(c)油轮;(d)客船
[0038]
图8:不同对比度范围下拖船图像样本
[0039]
(a)0.1-0.9;(b)0.2-0.8;(c)0.3-0.7
[0040]
图9:不同种类船舶图像dcgan模型生成样本
[0041]
(a)拖船;(b)货轮;(c)油轮;(d)客船
具体实施方式
[0042]
现结合实施例、附图对本发明作进一步描述:
[0043]
mel频率倒谱系数(mel-frequency cepstral coefficient,mfcc)是一种在语音识别中广泛使用的特征,是基于人耳特性提出的。由于人耳结构的特殊性,听者能够自动分离语音的低频部分和高频部分,其中低频部分是辨识语音特性的主要部分。
[0044]
本研究采用的传统数据增强方法:设置调节图像对比度范围:0.1~0.9,0.2~0.8和0.3~0.7,原始信号图可通过调节对比度得到3个生成图;本研究设置图像水平和垂直方向的缩放范围均为0.9~1.1,平移范围为-30~30个像素点。
[0045]
生成对抗网络由生成器和判别器组成。训练过程中,生成器用于生成仿真样本,判别器对样本的真实性进行判断,生成对抗网络基本框架如图1所示。两个网络通过对抗共同进步,以达到样本生成的最佳效果。训练完成后,只保留生成网络用于样本生成。深度卷积生成对抗网络(deep convolutional generative adversarial networks,dcgan)由gan模型衍生而来,dcgan将cnn和基础gan相结合,生成器和鉴别器均运用到了深度cnn。dcgan提高了基础gan的稳定性和生成结果质量。
[0046]
本发明解决其技术问题所采用的技术方案包括以下步骤:
[0047]
1)本研究需要提取声信号的mfcc特征,首先,对采集到的声信号进行预处理,预处理的过程包括预加重,分帧和加窗。预加重是通过提升信号高频部分的频谱,使信号的频谱变得更加平缓。分帧可以将信号划分为若干个短时段的信号,在短时段内信号可看作平稳过程。在分帧过程中,一般采用重叠分段的办法,使得帧与帧之间过度平滑。加窗则是为了减小信号的截断效应
[0048]
2)预处理完成后,对每帧信号做fft得到频谱。
[0049]
3)再将频谱通过一组三角带通滤波器滤波得到mel滤波。
[0050]
4)计算每个滤波器输出的对数能量,并计算其离散余弦变换,求出l阶的mfcc。
[0051]
5)根据l个mfcc倒谱系数值计算倒谱差分参数(delta cepstrum),将mfcc、一阶和二阶的倒谱差分参数三部分参数组合作为信号的特征向量。
[0052]
6)将每5段mfcc特征生成一个图片,以此作为单个样本的特征输入,各个类别均选取其中3/4的图片样本用于模型的训练和验证,剩余的1/4用于模型的测试。
[0053]
7)首先采用传统数据增强技术,调节图像对比度范围,并设置图像水平和垂直方向的缩放范围和平移范围。
[0054]
8)搭建dcgan模型,将特征图像输入dcgan模型训练,并得到相应的生成图像。
[0055]
9)在resnet18模型的基础上,去掉其中的池化层,并将输入层、全连接层和输出层换为适合识别任务的尺寸,搭建残差cnn模型,并将图像尺寸转化为224*224,从而与
resnet18模型中的卷积层尺寸相匹配。
[0056]
10)将初始特征和生成特征均可作为神经网络的输入特征,从而实现训练样本的扩充,训练resnet18模型,并对测试数据识别。
[0057]
具体实施流程
[0058]
经提取mfcc特征和数据增强处理,resnet18模型实现对声音信号的识别,参照图2,总体流程其搭建和训练具体分为以下步骤:
[0059]
1)数据预处理包括预加重,分帧和加窗。预加重:提升信号高频部分的频谱,使信号的频谱变得更加平缓;分帧:将信号划分为若干个短时段的信号,在短时段内信号可看作平稳过程;加窗:设信号为s(n),窗函数为w(n)。加窗后得到的信号s'(n)为:
[0060]
s'(n)=s(n)w(n)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0061]
其中,0≤n≤n-1,n为样点数,w(n)通常取海明窗。
[0062]
2)预处理完成后,对每帧信号做fft得到频谱,信号的离散频谱s'a(k)为:
[0063][0064]
3)将频谱通过一组三角带通滤波器滤波得到mel滤波,设有m个滤波器,中心频率为f(m),其中,m=1,2,
…
,m。三角滤波器的公式为:
[0065][0066]
4)计算每个滤波器输出的对数能量:
[0067][0068]
5)将计算得到的m个对数能量进行离散余弦变换,求出l阶的mfcc,通常l取12~16,其中,离散余弦变换公式为:
[0069][0070]
6)根据l个mfcc倒谱系数值计算倒谱差分参数,公式如下:
[0071][0072]
式中,d表示第n个一阶差分结果,cn表示经过(5)式计算得到的第n个倒谱系数,l表示求取mfcc时的阶数,k表示一阶导数的时间差,可取1或2。将计算结果再带入(6)式时可得到二阶差分结果。
[0073]
7)将mfcc、一阶倒谱差分参数和二阶倒谱差分参数三部分参数组合作为输入grnn模型的信号特征向量。
[0074]
8)将每5段mfcc特征生成一个图片,以此作为单个样本的特征输入,各个类别均选取其中3/4的图片样本用于模型的训练和验证,剩余的1/4用于模型的测试。
[0075]
9)首先采用传统数据增强技术,设置调节图像对比度范围:0.1~0.9,0.2~0.8和0.3~0.7,原始信号图可通过调节对比度得到3个生成图;设置图像水平和垂直方向的缩放范围均为0.9~1.1,平移范围为-30~30个像素点。
[0076]
10)搭建dcgan模型,其鉴别器和生成器框架分别如图3和图4所示,将特征图像输入dcgan模型训练,并得到相应的生成图像。
[0077]
11)在resnet18模型的基础上,去掉其中的池化层,并将输入层、全连接层和输出层换为适合识别任务的尺寸,搭建残差cnn模型,并将图像尺寸转化为224*224,从而与resnet18模型中的卷积层尺寸相匹配。
[0078]
12)将初始特征和生成特征均可作为神经网络的输入特征,从而实现训练样本的扩充,训练resnet18模型,并对测试数据识别。
[0079]
具体实施例子
[0080]
本研究选取的船舶音频数据来自于deepship数据集,该数据集包括四种船舶:拖船、货轮、油轮和客船,各个类型船舶初始信号如图5所示。本研究输入为音频数据的mfcc特征,首先将音频数据进行分段,每段256个样本,每段偏移128个样本,并求取每段数据的mfcc,提取的过程中,设置20组滤波器,并求取其一阶差分系数和二阶差分系数,从而使每段数据得到一个1*36的特征向量,本研究各个类型船舶均提取到6250段mfcc特征。拖船、货轮、油轮和客船均选取2.5s声音数据的mfcc特征为例,如图6所示。
[0081]
将每5段mfcc特征生成一个图片,以此作为单个样本的特征输入,如图7所示,各个类型船舶均得到1250个样本,各个类别均选取其中3/4的图片样本用于模型的训练和验证,剩余的1/4用于模型的测试,从而各个类型船舶均得到1000个训练样本和250个测试样本。
[0082]
设置图像对比度范围分别为0.1~0.9,0.2~0.8和0.3~0.7,经过调节对比度后,原始信号图可通过调节对比度得到3个生成图,以拖船为例,如图8所示。dcgan模型生成结果如图9所示,结果表明,经过大量训练后,生成结果已与实际特征图较接近。对一个初始信号特征图,本研究利用数据增强方法共得到4个生成特征图,初始特征和生成特征均可作为神经网络的输入特征,从而实现训练样本的扩充,即本研究的训练样本数量由1000扩充至5000。
[0083]
本研究将支持向量机和普通cnn模型作为对比模型。对支持向量机,通过将图片转化为特征矩阵后,输入模型进行训练,并预测得到分类结果。对普通cnn模型,层数较浅,包括3个卷积层,表示为3_cnn。本研究将识别准确度作为估计结果的衡量指标,公式如下:
[0084][0085]
其中,n为样本数量,为n个样本中正确识别的样本数量。
[0086]
表1表示各种方法对船舶目标信号识别的识别准确度,各种方法均对比使用数据增强技术与未使用数据增强技术两种情况,aug表示使用数据增强技术。结果表明,对于相同方法下,使用数据增强技术可明显提高识别性能,且resnet18模型优于svm和3_cnn模型。
由于深度较深的cnn模型可挖掘到更丰富的数据特征,所以,resnet18模型的识别性能优于3_cnn模型。相比传统机器学习模型,由于cnn的策略有着局部感知和权值共享的优势,所以,cnn模型的识别性能优于svm模型。基于数据增强技术和残差cnn的resnet18_aug模型有着最好的识别结果,这是由于resnet18_aug模型结合了数据增强技术的数据扩充优势和残差cnn模型的深层特征挖掘能力。
[0087]
表1不同方法船舶目标信号识别准确度
[0088]
方法拖船货轮油轮客船总共svm78.55%78.38%79.92%77.85%78.68%svm_aug80.29%81.31%80.96%79.32%80.47%3_cnn83.18%81.91%82.35%81.03%82.12%3_cnn_aug88.95%86.21%87.72%85.52%87.10%resnet1893.11%92.24%92.98%91.62%92.48%resnet18_aug96.85%96.23%97.01%95.38%96.37%
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。