[0001][0002]
本发明属于知识图谱和数据流处理领域,具体而言,是将知识表示学习方法用于动态知识推理任务中,实现在高速知识更新场景下的语义数据流推理技术。
背景技术:
[0003]
随着移动互联网、大数据、物联网、社交网络等技术的发展,越来越多的需要对高速实时数据流进行分析和处理。传统的数据流处理手段主要根据数据流中的数据结构或者取值进行数据流的聚、分类研究
[1]
,无法在语义和知识层面上进行数据流的分析和推理。在知识图谱技术的支持下,可以利用资源描述框架(resource description framework,rdf)将语义和知识赋予数据流,获得具有更好的可互操作性和可推理能力的语义数据流。语义数据流可以与静态的背景知识相结合来进行查询和推理,具有广泛的应用价值。
[0004]
近年来知识推理领域取得了较多进展,但现有并行规则推理机制在应对大规模图谱时仍有不足
[2]
。rdfox
[3]
提出了一种高性能的知识图谱查询推理机制,并使用前后向结合的方式进行删除一致性检查。文献
[4]
提出了基于单链推导(single-way derivability)优化的并行前向推理算法,并且性能优于rdfox。然而,以上知识推理研究主要针对静态数据,不适用于语义数据流。国内对于语义数据流的研究主要集中在窗口与查询优化
[5]
、事件处理
[6]
和聚类分析
[7]
,对语义数据流的实时推理的研究较少。现有的语义数据流推理方案主要基于确定性规则推导,不确定性知识推理的目前尚无法应用到语义数据流上。较早的不确定性统计推理主要使用马尔可夫逻辑网
[8]
和概率软逻辑
[9]
等手段,对本体频繁模式、约束和路径进行分析,从而得出推理结果,但这些方法仍然需要依赖实例化,因此可计算性较差
[10]
。
[0005]
2013年,在mikolov等人提出了word2vec
[11]
词表示学习模型之后,表示学习的方式在知识图谱领域受到广泛关注。随后bordes等提出了transe知识表示学习模型
[12]
。该模型将三元组中的关系看作平移向量,表示头实体与尾实体之间的平移。因为transe模型的参数简单,计算复杂度低,出现了大量基于transe模型改进和补充的知识表示学习模型,如transh
[13]
、 transr
[14]
和transpare
[15]
等。虽然以上模型都对transe模型做了相应的改进,但是都是基于事实三元组的向量化而没有利用规则,因此kale
[16]
在transe模型的基础上建立了三元组与规则的统一表示框架。然而kale无法进行增量更新。此外,kale也无法进行对规则本身的学习和泛化,来满足弱规则约束下的推理需求。
[0006]
动态图嵌入(dynamic graph embedding)方法在知识表示学习的基础上研究对动态变化的图进行推理。动态嵌入方法通过在代价函数中引入时间正则化
[17]
或加入基于时间层的注意力机制
[18]
等方法来捕捉图的变化特征,往往运用在新闻事件、社交网络或无线网络分析领域。但这种方法仍需要进行全量训练,因此主要研究提高对于低速变化(更新时间以数日到数年计)图的预测准确性,而非及时性。通过对学习率的动态调整可以缩短训练时间
[19]
,这种方法依赖于数据特性,因此可迁移性较差。
sparse transfer matrix[c]//thirtieth aaai conference on artificial intelligence.aaai press,2016.
[0023]
[16]guo s,wang q,wang l,et al.jointly embedding knowledge graphs and logical rules[c]//proceedings of the 2016conference on empirical methods in natural language processing,2016:192
–
202.
[0024]
[17]j
éré
mie rappaz,dylan bourgeois,and karl aberer.2019.a dynamic embedding model of the media landscape.in the world wide web conference(www’19).association for computing machinery,new york,ny,usa,1544
–
1554.
[0025]
[18]yang l.,xiao z.,jiang w.,et al.(2020)dynamic heterogeneous graph embedding using hierarchical attentions.in:jose j.et al.(eds)advances in information retrieval.ecir 2020. lecture notes in computer science,vol 12036.springer,cham
[0026]
[19]minervini p,fanizzi n,d'amato c,et al.scalable learning of entity and predicate embeddings for knowledge graph completion[c]//2015ieee 14th international conference on machine learning and applications(icmla).ieee,2015.
技术实现要素:
[0027]
针对现有的语义数据流推理方法的不足之处,本发明提出基于规则嵌入表示的多空间语义数据流推理方法。本发明的目的是在现有的语义数据流查询和推理的基础上提供准确性高、及时性好的不确定性知识推理方法,从而实现在高速更新的三元组数据流场景下的动态实时知识推理。
[0028]
为了解决上述现有技术中存在的不足,本发明提出一种基于规则嵌入和上下文感知的动态知识推理方法,首先实现规则与事实的联合嵌入表示,然后针对不同的语义数据流推理需求和场景实现设置不同的动态推理过程,包括基于平行语义空间推理的规则嵌入动态推理,基于上下文感知的规则嵌入动态推理和基于规则泛化学习的动态推理;
[0029]
所述基于平行语义空间推理的规则嵌入动态推理,是针对头尾实体比例为1:1的推理场景,结合语义数据流处理平台和知识表示学习进行处理,实现过程包括首先,对联合嵌入模型kale扩展,实现复杂规则和事实元组的统一表示推理框架;然后实现嵌入空间的构建和选择;最后实现基于联合嵌入模型的动态推理训练,并根据训练输出模型实现实时知识推理;
[0030]
所述基于上下文感知的规则嵌入动态推理,是针对头尾实体比例1对多或多对多的推理场景,进行基于上下文感知的多语义空间融合表示知识推理,实现过程包括首先,在多空间联合嵌入模型基础上扩展,实现上下文感知的动态推理框架;其次,对实体关系及其类型与规则关联上下文进行建模和表示;第三,进行上下文向量空间和规则嵌入空间的集成;最后,实现对增量更新和累计偏移感知的支持;
[0031]
所述基于规则泛化学习的动态推理,是针对弱规则约束或规则不全的推理场景,依据规则样例来进行规则学习,从而泛化规则并扩展推理结果,实现过程包括在知识表示学习的实时推理基础上进行规则泛化研究,并结合语义数据流处理平台,实现弱规则约束
下的不确定性实时知识推理。
[0032]
而且,所述基于平行语义空间推理的规则嵌入动态推理包括以下步骤:
[0033]
步骤1,构建动态联合嵌入模型整体训练框架;
[0034]
步骤2,基于语义与结构关联相结合的子嵌入空间生成方法,覆盖2跳范围内的语义和结构关联空间;
[0035]
步骤3,基于三元组索引的子嵌入空间选择,基于新增三元组及其关联规则选择更新的自嵌入空间;
[0036]
步骤4,制定基于间距模型的目标函数与方案;
[0037]
步骤5,实现基于c-sparql引擎的动态联合嵌入模型扩展和实时推理。
[0038]
而且,所述基于上下文感知的规则嵌入动态推理包括以下步骤:
[0039]
步骤1,涵盖2跳距离的实体及其类型上下文子图构造;
[0040]
步骤2,涵盖2跳距离的同向路径、父关系类型和规则关联的关系上下文子图构造;
[0041]
步骤3,多向量集成和规则联合嵌入;
[0042]
步骤4,基于上下文子图的增量更新,并动态维护累计向量偏移量,当累计偏移量超过限定值时进行全局嵌入空间更新。
[0043]
而且,所述规则泛化学习的动态推理包括以下步骤,
[0044]
步骤1,面向owl规则的泛化学习模型;
[0045]
步骤2,基于多空间增量训练的nre推理。
[0046]
与现有技术相比,本发明具有以下的优点:1)使用基于深度学习的方法实现适用于语义数据流的不确定性知识推理,通过牺牲一定准确性获得通过向量计算来进行推理的高效率,从而实现高吞吐量动态知识推理;2)使用基于规则泛化学习的方法实现适用于语义数据流的不确定性知识推理,通过对规则本身的学习来回避人工规则制定的复杂性,从而获得更全面的实时推理结果。
[0047]
本发明方案实施简单方便,实用性强,解决了相关技术存在的实用性低及实际应用不便的问题,能够提高用户体验,具有重要的市场价值。
附图说明
[0048]
图1为本发明实施例的扩展联合嵌入模型的实时推理架构示意图;
[0049]
图2为本发明实施例的nre原子操作及树结构具体实施示意图。
[0050]
图3为本发明实施例的语义相关的嵌入空间三元组生成策略示意图;
[0051]
图4为本发明实施例的结构相关的嵌入空间三元组生成策略示意图;
[0052]
图5为本发明实施例的语义结构融合的嵌入空间三元组生成策略示意图;
[0053]
图6为本发明实施例的实体和关系到嵌入空间的映射图;
[0054]
图7为本发明实施例的基于索引映射的嵌入空间选择流程图;
[0055]
图8为本发明实施例的kale-ctx模型基本结构图;
[0056]
图9为本发明实施例的上下文子图选择示意图;
[0057]
图10为本发明实施例的关系上下文选择示意图;
[0058]
图11为本发明实施例的基于上下文的实体和关系联合嵌入结构图;
[0059]
图12为本发明实施例的增量更新示意图。
具体实施方式
[0060]
以下结合附图和实施例具体说明本发明的技术方案。
[0061]
本发明实施例公开了一种基于规则嵌入表示的多空间语义数据流推理方法,其目标是对海量高速的语义数据流推理进行研究并降低其推理延迟。本发明对融合了规则学习的联合嵌入模型做出改进以适应高速变化的语义数据流推理查询。具体而言,为实现数据流中知识的增量更新并减少推理时延,本发明引入了平行的多嵌入空间,针对嵌入空间的生成方式,提出了三种嵌入空间生成算法;针对嵌入空间的选择,本发明提出了基于索引映射的嵌入空间选择算法以加快其选择速度。此外,为进一步提高嵌入空间中的复杂多样数据与查询的相关性,本发明引入了基于上下文信息的知识表示和嵌入方法,并提出了基于实体和关系上下文的嵌入空间生成方式;最后,本发明提出了基于规则泛化学习的语义数据流推理方法,从而在弱规则约束条件下获取更为全面的推理结果。本发明将经过以上改进的规则嵌入表示学习方法整合到数据流推理引擎csparql-engine中使之具备基于多模式知识表示学习的实时推理能力,该方案相比传统的流推理引擎可以在保证较高推理准确性的前提下提升复杂推理速度,其知识嵌入表示方法适用于1-1至n-n实体关系嵌入场景,同时其规则学习方法适用于弱规则约束下的动态推理场景。
[0062]
本发明实施例在经典的transe翻译模型基础上进行改进,首先实现规则与事实的联合嵌入表示,然后针对不同的语义数据流推理需求和场景设计不同的动态推理方案,主要包含基于平行语义空间推理的规则嵌入动态推理,基于上下文感知的规则嵌入动态推理和基于规则泛化学习的动态推理3个部分。
[0063]
(1)针对头尾实体比例为1:1情况较多的推理场景,本发明设计一种结合语义数据流处理平台和知识表示学习的解决方案。首先,研究对联合嵌入模型(kale)的扩展,实现复杂规则和事实元组的统一表示推理框架;然后设计嵌入空间的构建和选择方法;最后实现基于联合嵌入模型的动态推理训练方案,并根据训练输出模型实现实时知识推理。
[0064]
(2)针对头尾实体比例1对多或多对多的推理场景,本发明设计一种基于上下文感知的多语义空间融合表示知识推理解决方案。首先,在多空间联合嵌入模型基础上扩展,实现上下文感知的动态推理框架;其次,对实体关系及其类型与规则关联上下文进行建模和表示;第三,进行上下文向量空间和规则嵌入空间的集成;最后,实现对增量更新和累计偏移感知的支持。
[0065]
(3)针对弱规则约束或规则不全的推理场景,需要依据规则样例来进行规则学习,从而泛化规则并扩展推理结果。本发明在知识表示学习的实时推理基础上进行规则泛化研究,并结合语义数据流处理平台,实现弱规则约束下的不确定性实时知识推理。
[0066]
一、本发明实施例提供的基于规则与事实联合嵌入表示的语义数据流推理方案,实现如下:
[0067]
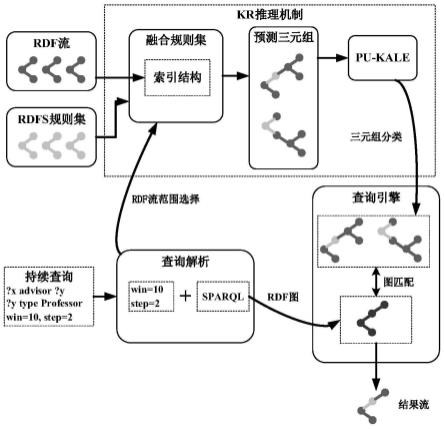
本发明在联合嵌入模型的基础上进行扩展,首先拓展规则嵌入支持范围至owl规则类型并设计相应真值计算方式,然后使之可以适用于动态更新的语义数据流,并构建基于三元组索引的预测模板生成算法,使之适用于知识推理任务。其总体推理架构如图1所示。该架构主要包含kr推理机制,查询引擎和查询解析3个部分,其中kr推理机制首先利用rdf 数据流和规则集,以及查询中对流的范围选择信息,构建rdf索引结构,并依据该索引结构生成待预测三元组,然后将待预测三元组送入pu-kale模型进行基于知识表示模型的
三元组分类;分类结果即推理出的额外三元组和原rdf流一起送入查询引擎进行图匹配,并生成结果流;查询解析模型主要对持续rdf流查询进行解析,例如图1左下角方框内查询意图为:查找数据流中的学生及其导师(?x advisor?y)信息,且导师职称为教授(?y type professor),查询范围为过去十分钟,以2分钟为窗口滑动(win=10,step=2)。其中查询的流选择部分 (win=10,step=2)用于结合索引生成预测三元组,sparql查询模式部分将提交给查询引擎进行图匹配查询。该架构的实现需要进行以下步骤。
[0068]
步骤1:构建整体训练框架:构建动态联合嵌入模型整体训练框架;本发明提出一种 pu-kale(parallel universe kale,平行空间规则联合嵌入模型)的解决方案,用于构建动态更新背景下的知识推理框架。pu-kale借用平行语义空间的思想,在kale模型的基础上,显式地生成多个嵌入空间用来学习新增的事实三元组。pu-kale在初始知识图谱模型的变动过程中,进行不同子空间的划分,并可以与查询窗口的滑动相匹配,即将每次窗口更新内容作为一个新的向量空间来训练。在每次训练过程中,滑动窗口内的数据都会和新增加的语义空间建立联系,方便区分多个语义空间里不同的事实三元组。
[0069]
在训练准备阶段,本发明根据预先设定好的参数如训练集三元组的总数和子嵌入大小等,生成多个嵌入空间,联合嵌入模型将在多个嵌入空间分别进行训练。当三元组进行增量更新时,如果新的实体、关系在已有的嵌入空间中,则更新对应子嵌入空间并重训练;反之,若当前多个子空间仍有剩余嵌入位置(即子空间容量未达限定值),则将新的三元组加入未满的子空间并重新训练;若所有子空间已满,则新建一个子嵌入空间。具体包含以下子步骤:
[0070]
步骤1.1:准备划分嵌入空间,包括获取三元组集合t={(h,r,t)}、实体集合e、关系集合r、向量维度d、训练次数δ;其中,h,r,t分别表示头实体、关系、尾实体。
[0071]
步骤1.2:读取规则集ζ到模型中;
[0072]
步骤1.3:对于每个子嵌入空间分别执行步骤1.4-1.11;其中,i表示第i个子空间;
[0073]
步骤1.4:为子嵌入空间生成随机超参数;
[0074]
步骤1.5:初始化当前嵌入空间的实体ei和关系矩阵ri以及三元组集合ti;
[0075]
步骤1.6:根据规则推理新的三元组,并加入ti作为正例;
[0076]
步骤1.7:当训练迭代次数小于预设值δ(建议取值20,可按照实际效果调整),执行步骤1.8-1.10,当训练迭代次数大于等于δ,则进入1.12;
[0077]
步骤1.8:挑选随机三元组生成否定三元组并加入ti作为负例;
[0078]
步骤1.9:挑选规则生成否定规则并加入ti作为规则负例;
[0079]
步骤1.10:更新矩阵参数;
[0080]
步骤1.11:迭代次数 1,然后返回步骤1.7;
[0081]
步骤1.12:保存嵌入空间的实体和关系矩阵。
[0082]
步骤2:子嵌入空间生成:基于语义与结构关联相结合的子嵌入空间生成方法,覆盖2跳范围内的语义和结构关联空间;对于pukale模型中嵌入空间的生成,本发明实现了多种嵌入空间的生成策略。第一种策略是语义相关的生成方法,第二种策略是结构上相关的方法,第三种策略是二者的有机结合。
[0083]
第一种语义相关策略在往一个嵌入空间划分三元组的时候,具有相同关系的三元
组更倾向于划分到同一个嵌入空间。而具有不同关系的三元组更倾向于划分到其他嵌入空间。
[0084]
第二种结构相关策略。其思路是在创建一个嵌入空间时,先随机选择一个三元组,加入当前嵌入空间,然后,以当前三元组的头实体和尾实体为起点,选择出度和入度方向的三元组加入当前嵌入空间,之后,继续以新加入的三元组的头实体和尾实体为起点,继续添加出度和入度方向的三元组,以此类推,直到添加的三元组的个数达到了嵌入空间的限定值。
[0085]
第三种嵌入空间的生成策略是第一种方法和第二种方法的结合,其生成嵌入空间的主要思路是,先随机选择一个三元组,将其加入当前嵌入空间,并记录下当前三元组的谓语关系,之后,以当前三元组的头尾实体为起点选择出度和入度方向两跳范围内的三元组,加入嵌入空间。
[0086]
本发明的子空间生成方法主要采用第三种策略,其中包含以下子步骤。
[0087]
步骤2.1:准备训练集三元组t={(h,r,t)},嵌入空间三元组个数限制const,保存待嵌入空间三元组
[0088]
步骤2.2:当中的三元组个数大于0,执行步骤2.3-2.9;当中的三元组个数小于等于 0,终止训练;
[0089]
步骤2.3:构建第i个嵌入空间
[0090]
步骤2.4:构建当前嵌入空间的三元组集合tripleset,实体集合entityset,关系集合 relationset;
[0091]
步骤2.5:当tripleset中的个数小于预设阈值const,执行步骤2.6-2.9,否则停止子空间构造;
[0092]
步骤2.6:随机选择一个三元组(h,r,t),加入tripleset;
[0093]
步骤2.7:头尾实体h,t加入集合tmplist;
[0094]
步骤2.8:对于tmplist每一个元素e,执行步骤2.9,所有e的步骤2.9完成后,进入2.10;
[0095]
步骤2.9:获取e出入度方向2跳范围内所有三元组v,并将v添加入tripleset;
[0096]
步骤2.10:获得并输出所有子嵌入空间
[0097]
步骤3:子嵌入空间选择:基于三元组索引的子嵌入空间选择,基于新增三元组及其关联规则选择更新的自嵌入空间;在进行子嵌入空间的增量更新和重训练时,对于所更新或重训练的子嵌入空间的选择十分重要。较为简单的做法是线性遍历每个嵌入空间,并计算当前三元组在当前嵌入空间的能量分数(通过已有的语义匹配能量模型sme计算),最后,选择符合条件的嵌入空间中能量分数的最大的。此方式需要执行遍历计算,时间消耗较多,本发明设计基于索引的优化选择方式。首先建立实体和关系到各个嵌入空间的索引映射,见图6所示,例如e1实体和r2关系通过索引映射到e1,e3,e6这3个子空间,e3映射熬e2,e3,e6 这3个子空间;然后,当新三元组到达,将根据其实体和关系,以及所可能触发逻辑规则生成的三元组实体关系,查找对应的索引列表,并寻访到符合要求的嵌入空间,如图7中,先通过头尾实体(head/tail)找到相应子空间e2,e3,e6,然后按照关系索引(relation)找到e1,e3, e6,然后取交集得到e3,e6这2个子空间。本发明的嵌入空间算法步骤包含以下子步骤。
[0098]
步骤3.1:初始化训练好的嵌入空间,准备测试元组t={(e,r)},获取索引ie,ir;其中,e,r, 为待测实体和关系,ie,ir分别表示其索引值;
[0099]
步骤3.2:对于t中的每一个三元组t=(e,r),通过在ie、ir中查找实体和关系,找到符合条件的嵌入空间集合
[0100]
步骤3.3:对于每个三元组t=(e,r),检索所有规则集,找到其可能触发规则所生成的三元组,并使用步骤3.2中相同方法,通过查找三元组索引找到符合条件的嵌入空间集合,并补充进入嵌入空间集合
[0101]
步骤3.4:对于每一个中的空间计算t的能量分数s
t
,将s
t
存入分数集合s
t
;
[0102]
步骤3.5:取max(s
t
)所对应的嵌入空间作为被选中嵌入空间。其中,max(s
t
)表示待补
[0103]
步骤4:制定模型训练目标函数与方案;可制定基于间距模型的目标函数与方案,本发明实施例基于间距模型和联合嵌入模型中损失函数,并制定训练方案,具体包含以下子步骤。
[0104]
步骤4.1:设计损失函数如下:
[0105][0106]
式(1)中:l表示正负三元组的间隔距离,s 、s-为正负三元组集合,i为表示模型计算出的真值,γ是距离超参数;f
是正例,f-是负例,i(f
)是正例真值,i(f-)是负例真值, max()是取最大值函数。
[0107]
步骤4.2:模型开始训练后,首先随机初始化三元组的实体与关系的向量表示(h,r,t);
[0108]
步骤4.3:对训练样本生成否定三元组,生成方式是随机替换样本的头实体或者尾实体,构造出负例(h
′
,r,t)或者(h,r,t
′
);其中,h
′
是头实体变化后的负例,t
′
是尾实体变化后的负例;
[0109]
步骤4.4:根据式(1)对每个三元组计算得分,对于正确的三元组,其期望的得分更低;而对于一个否定三元组,其期望的得分更高,这样通过训练样本的分数区分正负样本。
[0110]
步骤5:实现基于c-sparql的动态联合嵌入模型扩展和实时推理;本发明将基于多嵌入空间的pukale模型嵌入到语义数据流平台csparql-engine中,使得复杂的规则推理可以映射至低维向量空间进行简单的向量计算,降低图谱规模不断增大后的推理延迟,使其适应大规模流式数据场景下的实时推理需求。具体包含以下步骤:
[0111]
步骤5.1:通过实时语义标注模块,调用jena库方法,将输入数据格式化为rdf图;
[0112]
步骤5.2:在jena生成的三元组集合中为每个三元组加上时间戳,形成c-sparql可以接受的四元组输入;
[0113]
步骤5.3:读取并解析csparql查询,获得查询的时间步长和rdf流窗口大小;
[0114]
步骤5.4:从esper引擎中取出底层物理窗口数据,同时提供给csparql引擎和pukale 模型;
[0115]
步骤5.5:执行pukale推理模块,利用预测结果生成推理结果三元组集合,输入至查询引擎;
[0116]
步骤5.6:csparql引擎将原始三元组和推理三元组合并至输入流,执行查询语句并给出结果。
[0117]
其中,jena是apache旗下开源知识处理框架,rdf是资源描述框架,esper是开源数据流处理引擎。
[0118]
二、本发明实施例提供的基于上下文感知的多语义空间融合表示知识推理方案,实现如下:
[0119]
pukale实现了在语义数据流平台csparql-engine上的增量更新,但还是存在以下问题:1)pukale中还是沿用了transe中的评分函数用于计算每个三元组的得分,而这并不能很好建模知识图谱中1-n、n-1、n-n的关系;2)pukale缺乏对类型信息的表示;3)pukale 使用多语义空间,虽然避免了增量更新模型在整个数据集上重新训练,而是选择对应的嵌入空间重训练,减少了需要重训练的三元组的个数,但对需要重训练的三元组还是缺乏更细粒度的控制。
[0120]
针对以上问题,本发明以kale模型为基础,使用上下文感知的动态图谱嵌入方法,改进了图谱中实体以及关系上下文子图的生成方式,提出(上下文联合嵌入模型推理机) kale-ctx模型,之后,将模型嵌入到数据流引擎csparql-engine中,模型的基本结构图如图8所示。在kale-ctx中,每个实体和关系使用2个向量进行表示:通过知识嵌入方法形成的自身实体向量表示和实体的上下文子图向量,将所有实体的2部分向量融合后形成初始向量空间,在进行了增量更新以后,定位到受影响(增删改)的三元组,并更新其上下文嵌入,并实施增量重训练。该模型的实施包含以下步骤。
[0121]
步骤1:实体及其类型上下文选择:涵盖2跳距离的实体及其类型上下文子图构造;对于图谱网络中实体的上下文子图,本发明从两个方面进行选择,首先选择该实体相邻的所有出入度方向2跳范围的实体;然后,选择实体类型所有2跳范围内的模式层三元组。上述实体及其类型相关三元组组成了实体上下文子图。之所以没有引入距离更远的其他实体,一方面是为了限制子图中节点的规模,降低复杂度;另一方面,在实验中,包含距离多跳的实体后,模型的准确率并没有明显提高,反而,训练时间增加了。例如,在图9的(a)部分中,如果往图谱中加入了(舰队,拥有,船舰2),则实体舰队的上下文子图由实体船舰1、船舰2、船舰 3以及舰队实体本身构成,如图9的(b)部分所示。实体上下文子图的选择方法具体包含以下子步骤:
[0122]
步骤1.1:获取目标实体出入度方向一跳的所有三元组;
[0123]
步骤1.2:保存选择的三元组并将这些一跳三元组的尾实体保存;
[0124]
步骤1.3:循环遍历,寻找目标为二跳的三元组;
[0125]
步骤1.4:选择从二跳三元组的尾实体出发指向目标实体的三元组;
[0126]
步骤1.5:选择实体类型2跳范围内的模式层三元组并保存;
[0127]
步骤1.6:将所有保存的三元组设为上下文空间执行嵌入。
[0128]
步骤2:关系及其类型上下文选择:涵盖2跳距离的同向路径、父关系类型和规则关联的关系上下文子图构造;对于图谱网络中某个关系的上下文,很难选择合适的相邻实体或者关系形成上下文子图,因为图谱中关系可能会出现很多次。针对关系上下文,本发明从3个方面进行选择:
[0129]
1)基于关系路径的上下文信息:选择和关系同方向并且连接到同一实体对路径上的关系作为关系上下文的组成部分,为了获取这些关系之间结构上的信息,本发明将关系以及对应的关系路径都映射成图的顶点,在它们之间添加无向边,如果从同一个实体出发
的两条关系路径指向同一个终点,则在两条路径对应的顶点之间也添加一条无向边,这样就可以构造一个关系的上下文子图,考虑到从一个实体顶点出发可以经过多跳路径到达终点,为了控制关系路径的个数,降低复杂度,本发明选择的关系路径不超过两跳;
[0130]
2)基于关系类型的上下文信息:通过subproperty关联找到关系的父类型,并运用与1) 中相同办法构造基于关系类型的上下文子图;
[0131]
3)基于规则的上下文信息:逻辑规则在关系的选择中也提供了重要的信息,因此,本发明也会结合规则进行关系上下文选择。例如,在图10的(a)部分中,在实体船舰3和实体船舰 1之间添加了关系同一战斗组,和关系同一战斗组有关的关系路径为p1=(隶属于,有驱逐舰),这个两跳路径连接实体船舰3和实体船舰1。此外,还有一条针对同一战斗组的逻辑规则,即(x,同一战斗组,y)-》(x,同一舰队,y),因此,关系同一舰队也可以引入到关系同一战斗组的上下文子图中,即顶点p2=(同一舰队)。可以得到关系同一战斗组的上下文子图如图 10的(b)部分所示。关系上下文选择具体包含以下子步骤:
[0132]
步骤2.1:获取目标三元组头尾实体;
[0133]
步骤2.2:选择连接到同一实体对的路径为2跳范围的三元组;
[0134]
步骤2.3:选择2跳路径上所有关系的父类型关系的2跳范围三元组;
[0135]
步骤2.4:检索逻辑规则集,添加2.2-2.3中所有关系的所有规则上下文关联三元组;
[0136]
步骤2.5:保存2.2-2.4形成的关系上下文子图。
[0137]
步骤3:多向量集成和规则的联合嵌入;在获取到实体或关系的上下文子图后,通过dkge 中的神经网络可以对子图编码,得到一个上下文向量,而实体或关系本身还拥有一个规则联合嵌入向量。图11给出了一个多向量联合嵌入结构图,其中subgraph(h),subgraph(t)为头尾实体子图,subgraph(r)指关系子图,头尾实体子图经过实体图神经网络(entity gcn)得到实体自身向量h,t以及其上下文向量c(h),c(t);关系子图经过关系图神经网络(relation gcn) 得到其自身向量r和关系上下文向量c(r);将各自自身及上下文向量融合后形成融合向量h*,r* 和t*,并集成形成完整模型。此步骤的具体实施包含以下子步骤:
[0138]
步骤3.1:对于实体或关系上下文向量和知识向量的联合嵌入,采取平均操作得到结果向量,如式(2):
[0139][0140]
其中,o代表图谱中的实体或关系,ok代表实体或关系对应的知识嵌入,context(o)代表实体或关系对应的上下文嵌入,o
*
表示二者的联合嵌入向量。
[0141]
步骤3.2:对于规则嵌入,使用的是kale中规则嵌入的方式,通过特定的基于t-norm的逻辑连接词,将规则转换为真值的计算。对于三元组真值的计算,kale-ctx使用了如式(3) 所示的真值计算函数。
[0142][0143]
其中,h
*
、r
*
、t
*
是通过公式(2)计算,||.||
l1
是l1范式,d是向量维度,对于训练过程中实体和关系向量的初始化是是遵从均匀分布三元组真值i的取值范围为[0,
1],正确的三元组对应的真值越大。
[0144]
步骤3.3:定义基于距离的损失函数如下:
[0145]
l=∑
(h,r,t)∈5
∑
(m,r,t,)∈s
,max(0,i(h,r,t) γ-i(h
′
,r,t
′
))
ꢀꢀ
(4)
[0146]
其中,s是图谱中正确三元组的集合,s
′
是错误三元组的集合,生成错误三元组的方式是替换掉正确三元组中头实体和尾实体后形成的新的三元组(h
′
,r,t
′
),i是三元组对应的真值, max()函数用于表示取非负的真值差距(如小于0则取0)。
[0147]
步骤4:增量更新和累计偏移感知:基于上下文子图的增量更新,并动态维护累计向量偏移量,当累计偏移量超过限定值时进行全局嵌入空间更新;本发明对知识图谱的嵌入空间实际上包含两类,第一类为全局嵌入空间,使用事实规则联合嵌入(kale)方式生成,另一类为上下文嵌入空间,通过步骤1-2中的实体和关系上下文生成步骤产生。在图谱发生小规模动态更新时,没有直接受到影响的实体或关系的知识表示是不变的,上下文向量表示也是不变的,它们仍然可以保证三元组满足h* r*≈t*。而对于受到直接影响的实体或者关系,只需要对这一部分元素以及新增的元素的知识嵌入以及上下文嵌入进行重新训练,这极大减少了需要重新训练的三元组的数量。
[0148]
以图12为例,如图谱新增三元组(e5,r5,e1),其中,e5,r5是新增的实体和关系,e1为既有实体。对于三元组(e2,r2,e3)和(e4,r4,e3)来说,其对应的实体和关系的全局嵌入和上下文嵌入都没有变化,因此,当前更新对它们没有影响,三元组限制条件h
*
r
*
≈t
*
仍然成立,不需要调整。而原图谱中受到影响的三元组有(e1,r1,e2)和(e4,r3,e1),因为实体e1的上下文发生了变化,因此,只需要对原图谱中受到影响的e1的知识嵌入和上下文嵌入、以及新增加的实体e5和关系r5的知识嵌入和上下文嵌入进行重新学习,也就是说,模型只需要对(e1,r1, e2)、(e4,r3,e1)、(e5,r5,e1)三个三元组进行重训练,而不是在整个图谱上重新训练,这可以很好满足语义数据流场景下知识图谱的快速更新。
[0149]
显然,当三元组更新累计较多时,仅更新上下文子图嵌入不足以提供准确推理结果,此时初始全局嵌入空间和实际全局嵌入空间产生较大偏移,有必要进行重新训练。为实现推理结果在长时间内或大量更新场景下的性能稳定性,有必要提供偏移感知功能。本发明针对此问题,在每次进行上下文子图更新时统计相关实体关系向量偏移量δ,并动态维护总偏移量δ=∑δ,当总偏移量δ大于等于阈值δ
lim
时,则触发全局离线重训练,从而保证推理准确性,阈值的选择可以简单使用经验方法确定,也可通过进行步进式搜索来绘制准确性-向量偏移量曲线来寻找最优值。
[0150]
三、本发明实施例提供一种基于神经规则引擎的语义数据流推理方案,实现如下:
[0151]
神经规则引擎(nre)是最近提出的一种将规则和神经网络深度融合并运用于自然语言处理任务的新模式。nre的特点是将正则表达式形式的规则改写为节点为6种文本匹配基本操作之一的规则树后,对树的结构或布局进行端到端的序列标注和训练,从而得到规则的泛化。进而,对于需要神经网络的叶子操作节点进行基于卷积神经网络的学习和训练,并在文本分类任务阶段基于泛化规则布局调用训练好的模型进行文本的标注和分类。nre目前不能用于知识推理,显然也不能用于实时数据流处理。本发明在其基础上进行扩展,以达到在弱规则约束场景下进行实时知识推理的要求。主要技术方案包括对规则布局训练模型的改进和与 pu-kale的结合2个步骤。
[0152]
步骤1:面向owl规则的规则泛化学习;在原本的nre中,对正则表达式形成的规则
树进行逆波兰式表达,将其解析成唯一的序列形式。本发明可以对知识推理中的查询树进行类似处理。但sparql查询和正则匹配的操作不同,因此需要重定义原子操作及其参数。nre 的原子操作和使用范围如图2所示。其中find_pos(寻找正规则匹配)和find_neg(寻找负规则匹配)可以映射为sparql中的mapping(即知识查询模式匹配)和unbound()(即过滤未匹配变量)操作;由于rdf是无序的,因此and_order(有序合取)和and_unorder(无序合取)可以合并为join(变量连接)操作,or(析取)可以映射为union(模式合并)或optinonal (可选模式)运算。此外,操作的参数也需要重定义。原本的nre操作参数主要是文本的位置信息,本发明拟使用图谱结构关系替换这些参数。原子操作和参数被定义后,布局的解析和泛化学习可以用类似原本nre的序列标注模型来进行。
[0153]
步骤2:基于多空间增量训练的nre推理;为了解决改进nre对动态更新的语义数据流的适用性问题,本发明使用类似pu-kale的方案,即采用多空间方式来进行增量训练。其模型此处不再赘述。考虑到nre的需要同时对查询树布局和原子操作进行训练,可能存在训练时间过久的问题,本发明拟使用三种方案尝试在nre上实现实时知识推理:除了类似 pu-kale的pu-nre方式进行推理以外,还采用离线规则泛化 在线操作训练或离线学习 在线查询方式进行推理。
[0154]
具体实施时,本发明技术方案提出的方法可由本领域技术人员采用计算机软件技术实现自动运行流程,实现方法的系统装置例如存储本发明技术方案相应计算机程序的计算机可读存储介质以及包括运行相应计算机程序的计算机设备,也应当在本发明的保护范围内。
[0155]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。