图像处理方法和设备
1.本技术为,申请号为201910229696.8、申请日为2019年03月25日、发明创造名称为图像显示方法和设备的发明专利申请的分案申请。
技术领域
2.本技术涉及图像处理领域,尤其涉及一种图像处理方法和设备。
背景技术:
3.目前智能终端技术不断发展,终端设备的使用越来越广泛。随着终端设备处理能力的不断增强以及摄像头技术的发展,人们对终端设备拍照质量的要求也逐步提升。目前,终端设备能够在覆盖0.3光照度及以上的场景,例如,在白天场景拍摄得到图像的画质较好。
4.但是,在低照度的场景下,例如,终端设备在覆盖0.3光照度及以下的场景,由于受制于摄像头传感器尺寸小、光圈小等因素,导致终端设备的摄像头的感光度较差,造成拍照得到的图像中会引入噪声从而图像模糊不清晰。因此,在极低照度的场景下如何提高图像去噪效果,成为亟待解决的问题。
技术实现要素:
5.本技术提供一种图像显示方法和设备,以提高在低照度的环境下的图像去噪的效果。
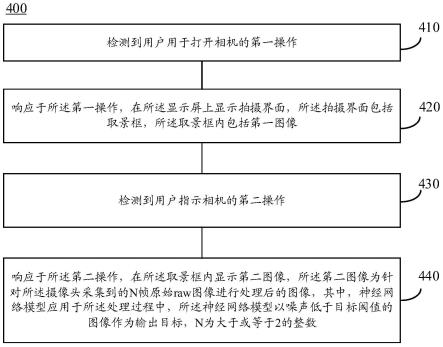
6.第一方面,本技术方案提供了一种图像显示方法,应用于具有显示屏(例如,触摸屏、柔性屏、曲面屏等)和摄像头的电子设备,包括:检测到用户用于打开相机的第一操作;响应于所述第一操作,在所述显示屏上显示拍摄界面,所述拍摄界面上包括取景框,所述取景框内包括第一图像;检测到所述用户指示相机的第二操作;响应于所述第二操作,在所述取景框内显示第二图像,所述第二图像为针对所述摄像头采集到的n帧原始raw图像进行处理后的图像,其中,神经网络模型(亦可简称为神经网络)应用于所述处理过程中,所述神经网络模型以噪声低于目标阈值的图像作为输出目标,n为大于或等于2的整数。
7.本技术中,检测到用户打开相机的第一操作,以及检测到用户指示相机的第二操作,响应所述第二操作,在显示屏的取景框内显示第二图像,第二图像是针对摄像头采集到的n帧原始raw图像进行处理后的图像。由于raw图像是未经过加速器算法以及isp的处理的图像,因此raw图像中噪声的形态未受到破坏。在本技术中,通过获取n帧raw图像进行去噪处理,能够提高低照度环境下图像的去噪效果。
8.可选地,在一种可能的实现方式中,所述第二图像为所述神经网络模型输出的yuv图像。
9.可选地,在另一种可能的实现方式中,所述第二图像为yuv图像,该yuv图像是对所述神经网络模型的输出的raw图像进行后处理,得到的yuv图像。
10.可选地,在另一种的可能的实现方式中,所述第二图像为所述神经网络模型输出
的raw图像。在本技术中,n帧原始raw图像为摄像头采集到的图像。例如,摄像头是包括传感器和镜头的模组,n帧原始raw图像可以是获取所述传感器生成的raw图像,raw图像未经过加速器,比如神经网络处理器(neural-network processing unit,npu)、图形处理器(graphics processing unit,gpu)、数字信号处理器(digital signal processor,dsp)等处理器进行算法加速,以及未经过图像信号处理器(image signal processor,isp)处理的原始图像。因此,raw图像中的噪声的原始形态并未由于算法的处理受到破坏。即raw图像中的噪声最接近用户的使用电子设备的真实的噪声引入的场景。
11.需要说明的是,原始raw图像不同于yuv图像,raw图像为传感器将捕捉到的光源信号转化为数字信号的原始数据,yuv图像为将raw图像进行后处理得到的图像,所述后处理可以将raw图像转换为yuv图像,例如,通过加速器和isp的处理。
12.应理解,神经网络可以是预先训练或者预先配置的神经网路该神经网络的训练数据可以包括raw图像和raw图像上加上噪声之后的噪声图像,其中,raw图像可以是包含噪声很少的图像,例如,可以是噪声低于目标阈值的raw图像。
13.例如,在一种可能的实现方式中,该神经网络模型以噪声低于目标阈值的raw图像作为输出目标。
14.需要说明的是,在本技术中电子设备具有显示屏,显示屏可以是触摸屏、柔性屏、曲面屏或者其它形式的屏幕,电子设备的显示屏具有显示图像的功能,至于显示屏的具体材质以及形状本技术对此不作任何限定。
15.还应理解,第一图像为极低照度场景下的预览图像,例如,第一图像可以是夜晚场景的预览图像,更具体地,可以是光照度在0.3lux以下场景的预览图像。第一图像和第二图像的显示内容相同或者实质上相同,其中,第二图像的画质优于第一图像,例如,第二图像中的颜色、亮度、细节、噪声优于第一图像。
16.在本技术中,电子设备获取的为原始raw图像,并对原始raw图像进行降噪处理,原始raw图像并未经过加速器算法以及isp的处理,使得噪声的形态未受到破坏,从而提高了低照度环境下图像去噪的效果。
17.结合第一方面,在第一方面的某些实现方式中,检测到所述用户指示第一处理模式的第二操作。
18.例如,第一处理模式可以是专业拍摄模式或夜景拍摄模式或其它模式,例如,可以是检测到用户选择专业拍摄模式或夜景拍摄模式的第二操作。响应于用户选择的专业拍摄模式或夜景拍摄模式的第二操作,电子设备将传感器的感光度iso值配置于目标范围内,例如,将电子设备的传感器的iso值设置大于12800以上。
19.结合第一方面,在第一方面的某些实现方式中,检测到所述用户用于指示拍摄的第二操作,所述第二操作为在低照度环境下用于指示拍摄的操作。
20.例如,可以是电子设备调用传感器检测到低照度场景下,如光照度在0.3lux以下场景中,用户指示拍摄的第二操作。其中,指示拍摄的第二操作可以是用户按下电子设备中的拍摄按钮,或者,也可以是用户设备通过语音指示电子设备进行拍摄行为,或者,还可以包括用户其它的指示电子设备进行拍摄行为。
21.进一步,当电子设备调用传感器检测到当前处于光照度在0.3lux以下场景时,电子设备可以将传感器的感光度iso值配置于目标范围内。
22.例如,目标范围可以是iso值大于6400,或者,也可以是iso值大于12800,本技术不限于此。
23.在一种可能的实现方式中,所述n帧原始raw图像包括参考帧图像和m帧待处理图像,所述处理过程包括:根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像;根据图像集合和所述神经网络模型得到去噪处理后的输出图像;其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述输出图像为所述第二图像。
24.也就是说,在一种可能的实现方式中,神经网络模型输出的输出图像是第二图像,即神经网络输出的图像可以是yuv图像,将所述yuv图像显示在显示屏的所述取景框内。
25.在一种可能的实现方式中,所述n帧原始raw图像包括参考帧图像和m帧待处理图像,所述处理过程包括:根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像;根据图像集合和所述神经网络模型得到去噪处理后的输出图像;其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述第二图像为对所述输出图像进行后处理得到的图像。
26.也就是说,在一种可能的实现方式中,神经网络模型输出的输出图像是raw图像,对raw图像进行后处理,例如,对输出的raw图像进行加速器和isp的处理得到yuv图像,将yuv图像显示在显示屏的所述取景框内。
27.在一种可能的实现方式中,获取n帧原始raw图像,其中,所述n帧原始raw图像中包括参考帧图像和m帧待处理图像,n为大于或等于2的整数,m为小于n的正整数;根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像;根据图像集合和神经网络模型,得到去噪处理后的输出图像,所述图像集合包括m帧配准图像和所述参考帧图像,所述神经网络以噪声模型以低于目标阈值的图像作为输出目标。
28.本技术中,可以获取n帧raw图像,将n帧raw图像中的m帧待处理图像根据参考帧图像进行配准处理,得到m帧配准图像;根据图像集合和神经网络模型,可以得到去噪处理后的输出图像,图像集合包括m帧配准图像和所述参考帧图像,所述神经网络以噪声模型以低于目标阈值的图像作为输出目标。在本技术中,由于raw图像是未经过加速器算法以及isp的处理的图像,因此raw图像中噪声的形态未受到破坏。在本技术中,通过获取n帧raw图像进行去噪处理,能够提高低照度环境下图像的去噪效果。
29.在一种可能的实现方式中,获取n帧原始raw图像,根据n帧原始raw图像的对比度确定n帧raw图像中的参考帧图像和m帧待处理图像。其中,参考帧图像可以是获取的n帧图像中画面质量较好的图像,例如,可以是n帧raw图像中清晰的图像。
30.在一种可能的实现方式中,所述根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像,包括:根据所述参考帧图像通过光流法对所述m帧待处理图像中的每帧图像进行配准处理,得到所述m帧配准图像。
31.结合第一方面,在第一方面的某些实现方式中,所述根据图像集合和所述神经网络模型得到去噪处理后的输出图像,包括:对图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;采用所述神经网络模型对所述图像集合对应的通道图像集合进行处理,得到关联数据,所述关联数据包括图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间
的关联信息中的一种或多种;根据所述关联数据得到每帧图像的目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;对所述目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
32.应理解,上述去噪处理后的输出图像可以是raw图像。
33.在一种可能的实现方式中,对所述图像集合进行前处理,得到每帧图像对应的通道图像,其中,所述前处理过程包括颜色通道分离,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;将所述图像集合中每帧图像对应的通道图像作为输入数据输入所述神经网络模型,得到所述神经网络模型的输出数据为目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像,对所述目标通道图像进行后处理,得到所述去噪处理后的输出图像,其中,所述后处理包括合并通道处理、drc处理、awb处理以及isp处理。
34.应理解,在一种可能的设计方式下,上述前处理和后处理流程中的任意一者或两者可以在所述神经网络模型中执行。或者,在另一种可能的实现方式中,上述前处理和后处理流程中的任意一者可以不在所述神经网络模型中执行,本技术对此不作任何限定。
35.可选地,当上述后处理流程在所述神经网络模型中执行时,神经网络输出的图像可以是yuv图像。
36.可选地,当上述后处理流程不在所述神经网络模型中执行时,神经网络输出的图像可以是raw图像。
37.应理解,噪声图像是通过神经网络模型预估的噪声图像。即可以是通过神经网络处理,得到预估的噪声图像,即噪声估计图像。
38.在一种可能的实现方式中,所述根据所述m帧配准图像、所述参考帧图像和神经网络,得到去噪处理后的输出图像,包括:对所述图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;将所述通道图像作为输入数据,采用所述神经网络模型得到每帧图像的目标通道图像,所述目标通道图像包括第一通道的噪声估计图像、第二通道的噪声估计图像以及第三通道的噪声估计图像;对所述目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
39.本技术中,可以对m帧配准图像、参考帧图像进行颜色通道分离,得到每帧图像对应的通道图像,神经网络可以根据更多的关联信息进行学习,例如可以根据不同图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息进行学习,从而能够提高低照度环境下图像去噪的效果。
40.应理解,不同通道可以是一帧图像中的对应的通道图像,也可以是不同帧图像之间的通道间的关联信息。此外,帧与帧之间的关联信息可以是对于不同帧图像中的同一特征点之间的关联信息,例如,可以是不同帧图像中的一个特征点a,在不同帧图像中的特征点a的像素值之间的关联信息,例如,可以是不同图像的亮度、纹理、噪声、细节等信息的关联性。通道间的关联信息,可以是指通道间的亮度、纹理、噪声的等信息的关联性。
41.结合第一方面,在第一方面的某些实现方式中,所述图像集合进一步包括鬼影图像,所述鬼影图像是通过所述m帧配准图像和所述参考帧图像作差得到的。在一种可能的实
现方式中,根据m帧配准帧图像和参考帧图像得到鬼影图像,包括:
42.获取第i个配准图像;根据第i个图像的图像特征和参考帧图像的图像特征进行作差处理。重复执行,得到第m个作差处理后的图像,进行图像特征融合,以得到鬼影图像。
43.应理解,当输入神经网络的图像集合中包括鬼影图像时,得到的输出图像可以是去噪且去鬼影的输出图像。
44.本技术中,在输入至神经网络的图像集合中包括鬼影图像时,不仅可以得到去噪处理的输出图像,进一步还可以去除输出图像中的鬼影图像。
45.结合第一方面,在第一方面的某些实现方式中,所述根据图像集合和所述神经网络模型得到去噪处理后的输出图像,包括:对所述图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;采用所述神经网络对所述图像集合对应的通道图像集合进行处理,得到关联数据,所述关联数据包括图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息中的一种或多种;根据所述关联数据得到每帧图像的第一目标通道图像,所述第一目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;对所述m帧配准图像的图像特征进行融合取平均值处理,得到平均图像;对所述平均图像进行颜色通道分离,得到通道平均图像,所述通道平均图像包括第一通道的平均图像、第二通道的平均图像以及第三通道的平均图像;将所述通道平均图像与对应的所述第一目标通道图像进行特征叠加,得到第二目标通道图像;对所述第二目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
46.应理解,在图像通道集合中包括m帧配准图像和参考帧图像以及鬼影图像时,关联数据可以图像帧与图像帧之间的关联信息,例如,可以是m个配准图像与参考图像的关联信息,或者,可以是m个配准图像与鬼影图像的关联信息,或者,可以是m个配准图像与鬼影图像、参考帧图像的关联信息;关联数据也可以是图像帧内的不同通道之间的关联信息;关联数据也可以是不同图像帧之间的通道间的关联信息。通道间的关联信息,可以是指通道间的亮度、纹理、噪声的等信息的关联性。
47.结合第一方面,在第一方面的某些实现方式中,所述第一通道图像、第二通道图像以及第三通道图像包括:r通道图像、y通道图像以及b通道图像,其中,所述y通道图像包括yb通道图像和yr通道图像。
48.其中,r通道图像可以表示图像中的红色通道图像、y通道图像可以表示全通道,类似于rgb的总和。
49.结合第一方面,在第一方面的某些实现方式中,所述第一通道图像、第二通道图像以及第三通道图像包括:r通道图像、g通道图像以及b通道图像,其中,所述g通道图像包括gb通道图像和gr通道图像。
50.其中,r通道图像可以表示图像的红色通道图像、g通道图像可以表示图像的绿色通道图像、b通道图像可以表示图像的蓝色通道图像。
51.结合第一方面,在第一方面的某些实现方式中,所述n帧raw图像为拜耳格式的图像。
52.结合第一方面,在第一方面的某些实现方式中,所述后处理包括:对所述输出图像进行动态压缩控制drc处理,得到高动态特征图像;对所述高动态特征图像进行白平衡awb
处理,得到色彩校正图像;对所述色彩校正图像进行图像信号处理,得到所述第二图像。
53.也就是说,在神经网络模型输出的输出图像是raw图像,进一步对raw图像进行后处理,例如,对输出的raw图像进行的后处理可以包括drc处理、awb处理以及图像信号处理,得到所述第二图像,其中,第二图像为yuv图像,即对输出的raw图像进行后处理后得到yuv图像。
54.第二方面,本技术方案提供了一种图像显示设备,包括:检测单元,用于检测检测到用户用于打开相机的第一操作;处理单元,用于响应于所述第一操作,在所述显示屏上显示拍摄界面,所述拍摄界面上包括取景框,所述取景框内包括第一图像;所述检测单元还用于检测到所述用户指示相机的第二操作;所述处理单元还用于响应于所述第二操作,在所述取景框内显示第二图像,所述第二图像为针对所述摄像头采集到的n帧原始raw图像进行处理后的图像,其中,神经网络模型应用于所述处理过程中,所述神经网络模型以噪声低于目标阈值的图像作为输出目标,n为大于或等于2的整数。
55.本技术中,检测到用户打开相机的第一操作,以及用户指示相机的第二操作,响应所述第二操作,在显示屏的取景框内显示第二图像,第二图像是针对摄像头采集到的n帧原始raw图像进行处理后的图像。由于raw图像是未经过加速器算法以及isp的处理的图像,因此raw图像中噪声的形态未受到破坏。在本技术中,通过获取n帧raw图像进行去噪处理,能够提高低照度环境下图像的去噪效果。
56.可选地,在一种可能的实现方式中,所述第二图像为所述神经网络模型输出的yuv图像。
57.可选地,在另一种可能的实现方式中,所述第二图像为yuv图像,该yuv图像是对所述神经网络模型的输出的raw图像进行后处理,得到的yuv图像。
58.可选地,在另一种的可能的实现方式中,所述第二图像为所述神经网络模型输出的raw图像。
59.其中,n帧原始raw图像为摄像头采集到的图像。摄像头是包括传感器和镜头的模组,例如,n帧原始raw图像可以是获取所述感器生成的raw图像,raw图像未经过加速器,比如神经网络处理器(neural-network processing unit,npu)、图形处理器(graphics processing unit,gpu)、数字信号处理器(digital signal processor,dsp)等处理器进行算法加速,以及未经过图像信号处理器(image signal processor,isp)处理的原始图像。因此,raw图像中的噪声的原始形态并未由于算法的处理受到破坏。即raw图像中的噪声最接近用户的使用电子设备的真实的噪声引入的场景。
60.需要说明的是,raw图像不同于yuv图像,raw图像为传感器将捕捉到的光源信号转化为数字信号的原始数据,yuv图像为将raw图像通过进行后处理得到的图像。所述后处理可以将raw图像转换为yuv图像,例如,通过加速器和isp的处理。
61.应理解,神经网络模型可以是预先训练或者预先配置的神经网路,该神经网络的训练数据可以包括raw图像和raw图像上加上噪声之后的噪声图像,其中,raw图像可以是包含噪声很少的图像,例如,可以是噪声低于目标阈值的raw图像。
62.可选地,在一种可能的实现方式中,所述神经网络模型以噪声低于目标阈值的raw图像作为输出目标。
63.还应理解,第一图像为极低照度场景下的预览图像,例如,第一图像可以是夜晚场
景的预览图像,更具体地,可以是光照度在0.3lux以下场景的预览图像。第一图像和第二图像的显示内容相同或者实质上相同,其中,第二图像的画质优于第一图像,例如,第二图像中的颜色、亮度、细节、噪声优于第一图像。
64.结合第二方面,在第二方面的某些实现方式中,所述检测单元具体用于,检测到所述用户指示第一处理模式的第二操作。
65.例如,第一处理模式可以是专业拍摄模式或夜景拍摄模式或其它模式,例如,可以是检测到用户选择专业拍摄模式或夜景拍摄模式的第二操作。响应于用户选择的专业拍摄模式或夜景拍摄模式的第二操作,电子设备将传感器的感光度iso值配置于目标范围内,例如,将电子设备的传感器的iso值设置大于12800以上。结合第二方面,在第二方面的某些实现方式中,所述检测单元具体用于,检测到所述用户用于指示拍摄的第二操作,所述第二操作为在低照度环境下用于指示拍摄的操作。
66.例如,可以是电子设备调用传感器检测到低照度场景下,如光照度在0.3lux以下场景中,用户指示拍摄的第二操作。其中,指示拍摄的第二操作可以是用户按下电子设备的相机中的拍摄按钮,或者,也可以是用户设备通过语音指示电子设备进行拍摄行为,或者,还可以包括用户其它的指示电子设备进行拍摄行为。
67.进一步,当电子设备调用传感器检测到当前处于光照度在0.3lux以下场景时,电子设备可以将传感器的感光度iso值配置于目标范围内,本技术不限于此。
68.结合第二方面,在第二方面的某些实现方式中,所述处理单元具体用于,根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像;根据图像集合和所述神经网络模型得到去噪处理后的输出图像;其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述输出图像为所述第二图像。
69.也就是说,在一种可能的实现方式中,神经网络模型输出的输出图像是第二图像,即神经网络输出的图像可以是yuv图像,将所述yuv图像显示在显示屏的所述取景框内。
70.在一种可能的实现方式中,所述处理单元具体用于:根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像;根据图像集合和所述神经网络模型得到去噪处理后的输出图像;其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述第二图像为对所述输出图像进行后处理得到的图像。
71.也就是说,在一种可能的实现方式中,神经网络模型输出的输出图像是raw图像,在电子设备的内部对raw图像进行后处理,例如对输出的raw图像进行加速器和isp的处理得到yuv图像,将yuv图像显示在显示屏的所述取景框内。
72.在一种可能的实现方式中,检测单元,用于获取n帧原始raw图像,其中,所述n帧原始raw图像中包括参考帧图像和m帧待处理图像,n为大于或等于2的整数,m为小于n的正整数;处理单元,用于根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像;所述处理单元还用于根据所述m帧配准图像、所述参考帧图像和神经网络,得到去噪处理后的输出图像,所述神经网络模型以噪声低于目标阈值的图像作为输出目标。
73.本技术中,可以获取n帧raw图像,对n帧raw图像中的m帧待处理图像根据参考帧图像进行配准处理,得到m帧配准图像;根据图像集合和神经网络模型,可以得到去噪处理后的输出图像。在本技术中,由于raw图像是未经过加速器算法以及isp的处理的图像,因此raw图像中噪声的形态未受到破坏。在本技术中,通过获取n帧raw图像进行去噪处理,能够
提高低照度环境下图像的去噪效果。
74.在一种可能的实现方式中,处理单元具体用于,根据n帧raw图像的对比度确定n帧raw图像中的参考帧图像和m帧待处理图像。其中,参考帧图像可以是获取的n帧图像中画面质量较好的图像,例如,可以是n帧raw图像中清晰的图像。
75.在一种可能的实现方式中,处理单元具体用于:根据所述参考帧图像通过光流法对所述m帧待处理图像中的每帧图像进行配准处理,得到所述m帧配准图像。
76.结合第二方面,在第二方面的某些实现方式中,所述处理单元具体用于:对所述图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;采用所述神经网络对所述图像集合对应的通道图像集合进行处理,得到关联数据,所述关联数据包括图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息中的一种或多种;根据所述关联数据得到每帧图像的目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;对所述目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
77.在一种可能的实现方式中,所述处理单元具体用于:对所述图像集合进行前处理,得到每帧图像对应的通道图像,其中,所述前处理为颜色通道分离,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;将所述图像集合中每帧图像对应的通道图像作为输入数据输入所述神经网络模型,得到所述神经网络模型的输出数据为目标通道图像,所述目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像,对所述目标通道图像进行后处理,得到所述去噪处理后的输出图像,其中,所述后处理包括合并通道处理、drc处理、awb处理以及isp处理。
78.应理解,在一种可能的,上述前处理和后处理流程中的任意一个可以在所述神经网络模型中执行。或者,在另一种可能的实现方式中,上述前处理和后处理流程中的任意一个可以不在所述神经网络模型中执行。
79.应理解,噪声图像是通过神经网络模型预估的噪声图像。即可以是通过神经网络处理,得到预估的噪声图像,即噪声估计图像。
80.本技术中,可以对m帧配准图像、参考帧图像进行颜色通道分离,得到每帧图像对应的通道图像,神经网络可以根据更多的关联信息进行学习,例如可以根据不同图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息进行学习,从而能够提高低照度环境下图像去噪的效果。
81.应理解,不同通道可以是一个图像中的对应的通道图像,也可以是不同图像之间的通道间的关联信息。此外,图像与图像之间的关联信息可以是对于不同图像中的同一特征点之间的关联信息,例如,可以是不同图像中的一个特征点a,在不同图像中的特征点a的像素值之间的关联信息,例如,可以是不同帧图像的亮度、纹理、噪声、细节等信息的关联性。通道间的关联信息,可以是指通道间的亮度、纹理、噪声的等信息的关联性。
82.结合第二方面,在第二方面的某些实现方式中,所述第一通道图像、第二通道图像以及第三通道图像包括:r通道图像、y通道图像以及b通道图像,其中,所述y通道图像包括
yb通道图像和yr通道图像。
83.结合第二方面,在第二方面的某些实现方式中,所述第一通道图像、第二通道图像以及第三通道图像包括:r通道图像、g通道图像以及b通道图像,其中,所述g通道图像包括gb通道图像和gr通道图像。
84.结合第二方面,在第二方面的某些实现方式中,所述处理单元具体用于:所述根据所述m帧配准图像、所述参考帧图像和神经网络,得到去噪处理后的输出图像,包括:根据所述m帧配准图像、所述参考帧图像、所述鬼影图像和所述神经网络,得到所述输出图像。
85.在一种可能的实现方式中,根据m帧配准帧图像和参考帧图像得到鬼影图像,包括:
86.获取第i个配准图像;根据第i个图像的图像特征和参考帧图像的图像特征进行作差处理。重复执行,得到第m个作差处理后的图像,进行图像特征融合,以得到鬼影图像。
87.应理解,当输入神经网络的图像集合中包括鬼影图像时,得到的输出图像可以是去噪且去鬼影的输出图像。
88.本技术中,在输入至神经网络的图像集合中包括鬼影图像时,不仅可以得到去噪处理的输出图像,进一步还可以去除输出图像中的鬼影图像。
89.结合第二方面,在第二方面的某些实现方式中,所述处理单元具体用于:对所述图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;采用所述神经网络对所述图像集合对应的通道图像集合进行处理,得到关联数据,所述关联数据包括帧与帧之间的关联信息,帧内的不同通道之间的关联信息,以及不同帧之间的通道间的关联信息中的一种或多种;根据所述关联数据得到每帧图像的第一目标通道图像,所述第一目标通道图像包括第一通道的噪声估计图像、第二通道的噪声估计图像以及第三通道的噪声估计图像;对所述m帧配准图像的图像特征进行融合取平均值处理,得到平均图像;对所述平均图像进行颜色通道分离,得到通道平均图像,所述通道平均图像包括第一通道的平均图像、第二通道的平均图像以及第三通道的平均图像;将所述通道平均图像与对应的所述第一目标通道图像进行特征叠加,得到第二目标通道图像;对所述第二目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
90.应理解,在图像通道集合中包括m帧配准图像和参考帧图像以及鬼影图像时,关联数据可以帧与帧之间的关联信息,例如,可以是m个配准图像与参考图像的关联信息,或者,可以是m个配准图像与鬼影图像的关联信息,或者,可以是m个配准图像与鬼影图像、参考帧图像的关联信息;关联数据也可以是帧内的不同通道之间的关联信息;关联数据也可以是不同帧之间的通道间的关联信息。通道间的关联信息,可以是指通道间的亮度、纹理、噪声的等信息的关联性。
91.在一种可能的实现方式中,例如,对图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,图像集合中可以包括m帧配准图像和参考帧图像以及鬼影图像,其中,通道图像可以包括r通道图像、yr通道图像、yb通道图像以及b通道图像。
92.在一种可能的实现方式中,例如,对图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,图像集合中可以包括m帧配准图像和参考帧图像以及鬼影图像,通道图像可以包括r通道图像、gr通道图像、gb通道图像以及b通道图像。
93.应理解,在图像通道集合中包括m帧配准图像和参考帧图像以及鬼影图像时,关联数据可以帧与帧之间的关联信息,例如,可以是m个配准图像与参考图像的关联信息,或者,可以是m个配准图像与鬼影图像的关联信息,或者,可以是m个配准图像与鬼影图像、参考帧图像的关联信息;关联数据也可以是帧内的不同通道之间的关联信息;关联数据也可以是不同帧之间的通道间的关联信息。通道间的关联信息,可以是指通道间的亮度、纹理、噪声的等信息的关联性。
94.结合第二方面,在第二方面的某些实现方式中,所述n帧raw图像为拜耳格式的图像。
95.结合第二方面,在第二方面的某些实现方式中,所述处理单元具体用于:对所述输出图像进行动态压缩控制drc处理,得到高动态特征图像;对所述高动态特征图像进行白平衡awb处理,得到色彩校正图像;所述色彩校正图像进行图像信号处理,得到所述第二图像。
96.也就是说,在神经网络模型输出的输出图像是raw图像,在电子设备的内部对raw图像进行后处理,例如,对输出的raw图像进行的后处理可以包括drc处理、awb处理以及图像信号处理,得到所述第二图像,其中,第二图像为yuv图像,即对输出的raw图像进行后处理后得到yuv图像。
97.第三方面,本技术方案供了一种图像显示设备,包括:显示屏,其中,显示屏;摄像头;一个或多个处理器;存储器;多个应用程序;以及一个或多个计算机程序。其中,一个或多个计算机程序被存储在存储器中,一个或多个计算机程序包括指令。当指令被设备执行时,使得设备执行上述任一方面任一项可能的实现中的图像显示方法。
98.需要说明的是,在本技术中电子设备具有显示屏,显示屏可以是触摸屏、柔性屏、曲面屏或者其它形式的屏幕,电子设备的显示屏具有显示图像的功能,至于显示屏的具体材质以及形状本技术对此不作任何限定。
99.第四方面,提供一种图像显示的设备,所述装置包括存储介质和中央处理器,所述存储介质可以是非易失性存储介质,所述存储介质中存储有计算机可执行程序,所述中央处理器与所述非易失性存储介质连接,并执行所述计算机可执行程序以实现所述第一方面或者第一方面的任一可能的实现方式中的方法。
100.第五方面,提供一种芯片,所述芯片包括处理器与数据接口,所述处理器通过所述数据接口读取存储器上存储的指令,执行第一方面或第一方面的任一可能的实现方式中的方法。
101.可选地,作为一种实现方式,所述芯片还可以包括存储器,所述存储器中存储有指令,所述处理器用于执行所述存储器上存储的指令,当所述指令被执行时,所述处理器用于执行第一方面或第一方面的任一可能的实现方式中的方法。
102.第六方面,提供一种计算机可读存储介质,所述计算机可读介质存储用于设备执行的程序代码,所述程序代码包括用于执行第一方面或者第一方面的任一可能的实现方式中的方法的指令。
附图说明
103.图1是本技术实施例提供的系统架构的结构示意图;
104.图2是本技术实施例提供的根据cnn模型进行图像去噪的示意图;
105.图3是本技术实施例提供的一种芯片硬件结构示意图;
106.图4是本技术实施例的图像显示方法的示意性流程图;
107.图5是本技术实施例提供的一组显示界面示意图;
108.图6是本技术实施例提供的另一组显示界面示意图;
109.图7是本技术实施例提供的另一个显示界面示意图;
110.图8是本技术实施例提供的另一个显示界面示意图;
111.图9是本技术实施例的图像显示方法的示意性流程图;
112.图10是本技术实施例的图像配准处理的方法的示意性流程图;
113.图11是本技术实施例的图像格式的示意图;
114.图12是本技术实施例的图像显示方法的示意图;
115.图13是本技术实施例的神经网络模型的结构示意图;
116.图14是本技术实施例的动态压缩控制处理的方法的示意性流程图;
117.图15是本技术实施例的图像显示方法的示意性流程图;
118.图16是根据本技术实施例中的图像显示方法获取的图像的示意图;
119.图17是根据本技术实施例中的图像显示方法获取的图像的示意图;
120.图18是本技术实施例的图像显示的设备的结构示意图;
121.图19是本技术实施例的图像显示的设备的结构示意图。
具体实施方式
122.下面将结合附图,对本技术中的技术方案进行描述。
123.本技术实施例提供的图像显示方法能够应用在拍照、录像、平安城市、自动驾驶、人机交互以及需要处理图像、显示图像、对图像进行低层或高层视觉处理的场景,如图像识别、图像分类、语义分割、视频语义分析、视频行为识别等。
124.具体而言,本技术实施例的图像显示方法能够应用在拍照场景和基于图像和视频的视觉计算的场景中,下面分别对拍照场景和图像识别场景进行简单的介绍。
125.拍照场景:
126.在利用相机、终端设备或者其他智能电子设备进行拍照时,为了显示质量更好的图像,在拍照时或者拍照后可以采用本技术实施例的图像显示方法来去除拍照得到的图像中的噪声。通过采用本技术实施例的图像显示方法,能够提高图片质量,提升图片显示效果和提高基于图像的视觉算法的准确度。
127.图像识别景:
128.随着人工智能技术的应用的范围越来越广,在很多情况下,需要对图像中的内容进行识别,在对图像进行识别时,图像的噪声会在一定程度上影响图像的识别效果。通过采用本技术实施例的图像显示方法在图像识别过程中或者图像识别正式开始之前对图像进行去噪处理,能够提高图像的质量,从而提高后续的图像识别的效果。
129.由于本技术实施例涉及大量神经网络的应用,为了便于理解,下面先对本技术实施例可能涉及的相关术语及神经网络等相关概念进行介绍。
130.(1)神经网络
131.神经网络可以是由神经单元组成的,神经单元可以是指以xs和截距b为输入的运
算单元,该运算单元的输出可以为:
[0132][0133]
其中,s=1、2、
……
n,n为大于1的自然数,ws为xs的权重,b为神经单元的偏置。f为神经单元的激活函数(activation functions),用于将非线性特性引入神经网络中,来将神经单元中的输入信号转换为输出信号。该激活函数的输出信号可以作为下一层卷积层的输入。激活函数可以是sigmoid函数。神经网络是将许多个上述单一的神经单元联结在一起形成的网络,即一个神经单元的输出可以是另一个神经单元的输入。每个神经单元的输入可以与前一层的局部接受域相连,来提取局部接受域的特征,局部接受域可以是由若干个神经单元组成的区域。
[0134]
(2)深度神经网络
[0135]
深度神经网络(deep neural network,dnn),也称多层神经网络,可以理解为具有很多层隐含层的神经网络,这里的“很多”并没有特别的度量标准。从dnn按不同层的位置划分,dnn内部的神经网络可以分为三类:输入层,隐含层,输出层。一般来说第一层是输入层,最后一层是输出层,中间的层数都是隐含层。例如,全连接神经网络中层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i 1层的任意一个神经元相连。虽然dnn看起来很复杂,但是就每一层的工作来说,其实并不复杂,简单来说就是如下线性关系表达式:其中,是输入向量,是输出向量,是偏移向量,w是权重矩阵(也称系数),α()是激活函数。每一层仅仅是对输入向量经过如此简单的操作得到输出向量由于dnn层数多,则系数w和偏移向量的数量也就很多了。这些参数在dnn中的定义如下所述:以系数w为例:假设在一个三层的dnn中,第二层的第4个神经元到第三层的第2个神经元的线性系数定义为上标3代表系数w所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。总结就是:第l-1层的第k个神经元到第l层的第j个神经元的系数定义为需要注意的是,输入层是没有w参数的。在深度神经网络中,更多的隐含层让网络更能够刻画现实世界中的复杂情形。理论上而言,参数越多的模型复杂度越高,“容量”也就越大,也就意味着它能完成更复杂的学习任务。训练深度神经网络的也就是学习权重矩阵的过程,其最终目的是得到训练好的深度神经网络的所有层的权重矩阵(由很多层的向量w形成的权重矩阵)。
[0136]
(3)卷积神经网络
[0137]
卷积神经网络(convolutional neuron network,cnn)是一种带有卷积结构的深度神经网络。卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。该特征抽取器可以看作是滤波器,卷积过程可以看作是使用一个可训练的滤波器与一个输入的图像或者卷积特征平面(feature map)做卷积。卷积层是指卷积神经网络中对输入信号进行卷积处理的神经元层。在卷积神经网络的卷积层中,一个神经元可以只与部分邻层神经元连接。一个卷积层中,通常包含若干个特征平面,每个特征平面可以由一些矩形排列的神经单元组成。同一特征平面的神经单元共享权重,这里共享的权重就是卷积核。共享权重可以理解为提取图像信息的方式与位置无关。这其中隐含的原理是:图像的某一部分的统计信息
与其他部分是一样的。即意味着在某一部分学习的图像信息也能用在另一部分上。所以对于图像上的所有位置,都能使用同样的学习得到的图像信息。在同一卷积层中,可以使用多个卷积核来提取不同的图像信息,一般地,卷积核数量越多,卷积操作反映的图像信息越丰富。
[0138]
卷积核可以以随机大小的矩阵的形式初始化,在卷积神经网络的训练过程中卷积核可以通过学习得到合理的权重。另外,共享权重带来的直接好处是减少卷积神经网络各层之间的连接,同时又降低了过拟合的风险。
[0139]
(4)循环神经网络(recurrent neural networks,rnn)是用来处理序列数据的。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,而对于每一层层内之间的各个节点是无连接的。这种普通的神经网络虽然解决了很多难题,但是却仍然对很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。rnn之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐含层本层之间的节点不再无连接而是有连接的,并且隐含层的输入不仅包括输入层的输出还包括上一时刻隐含层的输出。理论上,rnn能够对任何长度的序列数据进行处理。对于rnn的训练和对传统的cnn或dnn的训练一样。同样使用误差反向传播算法,不过有一点区别:即,如果将rnn进行网络展开,那么其中的参数,如w,是共享的;而如上举例上述的传统神经网络却不是这样。并且在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖前面若干步网络的状态。该学习算法称为基于时间的反向传播算法(back propagation through time,bptt)。
[0140]
既然已经有了卷积神经网络,为什么还要循环神经网络?原因很简单,在卷积神经网络中,有一个前提假设是:元素之间是相互独立的,输入与输出也是独立的,比如猫和狗。但现实世界中,很多元素都是相互连接的,比如股票随时间的变化,再比如一个人说了:我喜欢旅游,其中最喜欢的地方是云南,以后有机会一定要去。这里填空,人类应该都知道是填“云南”。因为人类会根据上下文的内容进行推断,但如何让机器做到这一步?rnn就应运而生了。rnn旨在让机器像人一样拥有记忆的能力。因此,rnn的输出就需要依赖当前的输入信息和历史的记忆信息。
[0141]
(5)损失函数
[0142]
在训练深度神经网络的过程中,因为希望深度神经网络的输出尽可能的接近真正想要预测的值,所以可以通过比较当前网络的预测值和真正想要的目标值,再根据两者之间的差异情况来更新每一层神经网络的权重向量(当然,在第一次更新之前通常会有初始化的过程,即为深度神经网络中的各层预先配置参数),比如,如果网络的预测值高了,就调整权重向量让它预测低一些,不断的调整,直到深度神经网络能够预测出真正想要的目标值或与真正想要的目标值非常接近的值。因此,就需要预先定义“如何比较预测值和目标值之间的差异”,这便是损失函数(loss function)或目标函数(objective function),它们是用于衡量预测值和目标值的差异的重要方程。其中,以损失函数举例,损失函数的输出值(loss)越高表示差异越大,那么深度神经网络的训练就变成了尽可能缩小这个loss的过程。
[0143]
(6)像素值
[0144]
图像的像素值可以是一个红绿蓝(rgb)颜色值,像素值可以是表示颜色的长整数。例如,像素值为256*red 100*green 76blue,其中,blue代表蓝色分量,green代表绿色分量,red代表红色分量。各个颜色分量中,数值越小,亮度越低,数值越大,亮度越高。对于灰度图像来说,像素值可以是灰度值。
[0145]
(7)图像配准
[0146]
图像配准(image registration)是指同一目标的两幅或者两幅以上的图像在空间位置的对准。图像配准的过程,也可以称为图像匹配或者图像相关。
[0147]
例如,配准技术的流程可以是首先对两幅图像进行特征提取得到特征点;通过进行相似性度量找到匹配的特征点对;然后通过匹配的特征点对得到图像空间坐标变换参数;最后由坐标变换参数进行图像配准。而特征提取是配准技术中的关键,准确的特征提取为特征匹配的成功进行提供了保障。
[0148]
(8)感光度
[0149]
感光度,又称为iso值,是衡量底片对于光的灵敏程度,由敏感度测量学及测量数个数值来决定。
[0150]
(9)图像噪声
[0151]
图像噪声(image noise)是图像中一种亮度或颜色信息的随机变化(被拍摄物体本身并没有),通常是电子噪声的表现。它一般是由扫描仪或数码相机的传感器和电路产生的,也可能是受胶片颗粒或者理想光电探测器中不可避免的散粒噪声影响产生的。图像噪声是图像拍摄过程中不希望存在的副产品,给图像带来了错误和额外的信息。
[0152]
(10)鬼影
[0153]
对于动态场景,即包括移动的物体或相机、手的抖动,使获得的源曝光级序列中包含动态信息,但是不同曝光级别图像间的小小的位移都会最终导致融合的图像中产生鬼影,可以将鬼影看作是图像融合时产生的虚影。
[0154]
如图1所示,本技术实施例提供了一种系统架构100。在图1中,数据采集设备160用于采集训练数据,本技术实施例中训练数据包括原始raw图像(这里的原始图像可以是包含噪声很少的图像,例如,可以是噪声低于目标阈值的raw图像)和在原始图像上加上噪声之后的噪声图像。
[0155]
在采集到训练数据之后,数据采集设备160将这些训练数据存入数据库130,训练设备120基于数据库130中维护的训练数据训练得到目标模型/规则101。
[0156]
下面对训练设备120基于训练数据得到目标模型/规则101进行描述,训练设备120对输入的原始图像进行处理,将输出的图像与原始图像进行对比,直到训练设备120输出的图像与原始图像的差值小于一定的阈值,从而完成目标模型/规则101的训练。
[0157]
上述目标模型/规则101能够用于实现本技术实施例的图像显示方法,即,将待处理图像通过相关预处理后输入该目标模型/规则101,即可得到去噪处理后的图像。本技术实施例中的目标模型/规则101具体可以为神经网络。需要说明的是,在实际的应用中,所述数据库130中维护的训练数据不一定都来自于数据采集设备160的采集,也有可能是从其他设备接收得到的。另外需要说明的是,训练设备120也不一定完全基于数据库130维护的训练数据进行目标模型/规则101的训练,也有可能从云端或其他地方获取训练数据进行模型训练,上述描述不应该作为对本技术实施例的限定。
[0158]
根据训练设备120训练得到的目标模型/规则101可以应用于不同的系统或设备中,如应用于图1所示的执行设备110,所述执行设备110可以是终端,如手机终端,平板电脑,笔记本电脑,增强现实(augmented reality,ar)ar/虚拟现实(virtual reality,vr),车载终端等,还可以是服务器或者云端等。在图1中,执行设备110配置输入/输出(input/output,i/o)接口112,用于与外部设备进行数据交互,用户可以通过客户设备140向i/o接口112输入数据,所述输入数据在本技术实施例中可以包括:客户设备输入的待处理图像。
[0159]
预处理模块113和预处理模块114用于根据i/o接口112接收到的输入数据(如待处理图像)进行预处理,在本技术实施例中,也可以没有预处理模块113和预处理模块114(也可以只有其中的一个预处理模块),而直接采用计算模块111对输入数据进行处理。
[0160]
在执行设备110对输入数据进行预处理,或者在执行设备110的计算模块111执行计算等相关的处理过程中,执行设备110可以调用数据存储系统150中的数据、代码等以用于相应的处理,也可以将相应处理得到的数据、指令等存入数据存储系统150中。
[0161]
最后,i/o接口112将处理结果,例如,上述得到的去噪处理后的输出图像返回至客户设备140,从而提供给用户。
[0162]
需要说明的是,训练设备120可以针对不同的目标或称不同的任务,基于不同的训练数据生成相应的目标模型/规则101,该相应的目标模型/规则101即可以用于实现上述目标或完成上述任务,从而为用户提供所需的结果,例如,在本技术中可以是向用户提供去噪处理后的输出图像。
[0163]
如图1所示,根据训练设备120训练得到目标模型/规则101,该目标模型/规则101在本技术实施例中可以是本技术中的神经网络,具体的,本技术实施例提供的神经网络可以cnn,深度卷积神经网络(deep convolutional neural networks,dcnn),循环神经网络(recurrent neural network,rnns)等等。
[0164]
由于cnn是一种常见的神经网络,下面结合图2重点对cnn的结构进行详细的介绍。如上文的基础概念介绍所述,卷积神经网络是一种带有卷积结构的深度神经网络,是一种深度学习(deep learning)架构,深度学习架构是指通过机器学习的算法,在不同的抽象层级上进行多个层次的学习。作为一种深度学习架构,cnn是一种前馈(feed-forward)人工神经网络,该前馈人工神经网络中的各个神经元可以对输入其中的图像作出响应。
[0165]
如图2所示,卷积神经网络(cnn)200可以包括输入层210,卷积层/池化层220(其中池化层为可选的),以及神经网络层230。下面对这些层的相关内容做详细介绍。
[0166]
卷积层/池化层220:
[0167]
卷积层:
[0168]
如图2所示卷积层/池化层220可以包括如示例221-226层,举例来说:在一种实现中,221层为卷积层,222层为池化层,223层为卷积层,224层为池化层,225为卷积层,226为池化层;在另一种实现方式中,221、222为卷积层,223为池化层,224、225为卷积层,226为池化层。即卷积层的输出可以作为随后的池化层的输入,也可以作为另一个卷积层的输入以继续进行卷积操作。
[0169]
下面将以卷积层221为例,介绍一层卷积层的内部工作原理。
[0170]
卷积层221可以包括很多个卷积算子,卷积算子也称为核,其在图像处理中的作用相当于一个从输入图像矩阵中提取特定信息的过滤器,卷积算子本质上可以是一个权重矩
阵,这个权重矩阵通常被预先定义,在对图像进行卷积操作的过程中,权重矩阵通常在输入图像上沿着水平方向一个像素接着一个像素(或两个像素接着两个像素
……
取决于步长stride的取值)的进行处理,从而完成从图像中提取特定特征的工作。该权重矩阵的大小应该与图像的大小相关,
[0171]
需要注意的是,权重矩阵的纵深维度(depth dimension)和输入图像的纵深维度是相同的,在进行卷积运算的过程中,权重矩阵会延伸到输入图像的整个深度。因此,和一个单一的权重矩阵进行卷积会产生一个单一纵深维度的卷积化输出,但是大多数情况下不使用单一权重矩阵,而是应用多个尺寸(行
×
列)相同的权重矩阵,即多个同型矩阵。每个权重矩阵的输出被堆叠起来形成卷积图像的纵深维度,这里的维度可以理解为由上面所述的“多个”来决定。
[0172]
不同的权重矩阵可以用来提取图像中不同的特征,例如,一个权重矩阵可以用来提取图像边缘信息,另一个权重矩阵用来提取图像的特定颜色,又一个权重矩阵用来对图像中不需要的噪声进行模糊化等。该多个权重矩阵尺寸(行
×
列)相同,经过该多个尺寸相同的权重矩阵提取后的特征图的尺寸也相同,再将提取到的多个尺寸相同的特征图合并形成卷积运算的输出。
[0173]
这些权重矩阵中的权重值在实际应用中需要经过大量的训练得到,通过训练得到的权重值形成的各个权重矩阵可以用来从输入图像中提取信息,从而使得卷积神经网络200进行正确的预测。
[0174]
当卷积神经网络200有多个卷积层的时候,初始的卷积层(例如221)往往提取较多的一般特征,该一般特征也可以称之为低级别的特征;随着卷积神经网络200深度的加深,越往后的卷积层(例如226)提取到的特征越来越复杂,比如高级别的语义之类的特征,语义越高的特征越适用于待解决的问题。
[0175]
池化层:
[0176]
由于常常需要减少训练参数的数量,因此,卷积层之后常常需要周期性的引入池化层,在如图2中220所示例的221-226各层,可以是一层卷积层后面跟一层池化层,也可以是多层卷积层后面接一层或多层池化层。在图像处理过程中,池化层的唯一目的就是减少图像的空间大小。池化层可以包括平均池化算子和/或最大池化算子,以用于对输入图像进行采样得到较小尺寸的图像。平均池化算子可以在特定范围内对图像中的像素值进行计算产生平均值作为平均池化的结果。最大池化算子可以在特定范围内取该范围内值最大的像素作为最大池化的结果。另外,就像卷积层中用权重矩阵的大小应该与图像尺寸相关一样,池化层中的运算符也应该与图像的大小相关。通过池化层处理后输出的图像尺寸可以小于输入池化层的图像的尺寸,池化层输出的图像中每个像素点表示输入池化层的图像的对应子区域的平均值或最大值。
[0177]
神经网络层230:
[0178]
在经过卷积层/池化层220的处理后,卷积神经网络200还不足以输出所需要的输出信息。因为如前所述,卷积层/池化层220只会提取特征,并减少输入图像带来的参数。然而为了生成最终的输出信息(所需要的类信息或其他相关信息),卷积神经网络200需要利用神经网络层230来生成一个或者一组所需要的类的数量的输出。因此,在神经网络层230中可以包括多层隐含层(如图2所示的231、232至23n)以及输出层240,该多层隐含层中所包
含的参数可以根据具体的任务类型的相关训练数据进行预先训练得到,例如该任务类型可以包括图像识别,图像分类,图像超分辨率重建等等。
[0179]
在神经网络层230中的多层隐含层之后,也就是整个卷积神经网络200的最后层为输出层240,该输出层240具有类似分类交叉熵的损失函数,具体用于计算预测误差,一旦整个卷积神经网络200的前向传播(如图2由210至240方向的传播为前向传播)完成,反向传播(如图2由240至210方向的传播为反向传播)就会开始更新前面提到的各层的权重值以及偏差,以减少卷积神经网络200的损失,及卷积神经网络200通过输出层输出的结果和理想结果之间的误差。
[0180]
需要说明的是,如图2所示的卷积神经网络200仅作为一种卷积神经网络的示例,在具体的应用中,卷积神经网络还可以以其他网络模型的形式存在。
[0181]
图3为本技术实施例提供的一种芯片硬件结构,该芯片包括神经网络处理器(neural-network processing unit)30。该芯片可以被设置在如图1所示的执行设备110中,用以完成计算模块111的计算工作。该芯片也可以被设置在如图1所示的训练设备120中,用以完成训练设备120的训练工作并输出目标模型/规则101。如图2所示的卷积神经网络中各层的算法均可在如图3所示的芯片中得以实现。
[0182]
神经网络处理器npu 50作为协处理器挂载到主中央处理器(central processing unit,cpu)上,由主cpu分配任务。npu的核心部分为运算电路303,控制器304控制运算电路303提取权重存储器302或者输入存储器301中的数据并进行运算。
[0183]
在一些实现中,运算电路303内部包括多个处理单元(process engine,pe)。在一些实现中,运算电路303可以是二维脉动阵列。运算电路303还可以是一维脉动阵列或者能够执行例如乘法和加法这样的数学运算的其它电子线路。
[0184]
在一些实现中,运算电路303是通用的矩阵处理器。
[0185]
举例来说,假设有输入矩阵a,权重矩阵b,输出矩阵c。运算电路303从权重存储器302中取矩阵b相应的数据,并缓存在运算电路中每一个pe上。运算电路303从输入存储器301中取矩阵a数据与矩阵b进行矩阵运算,得到的矩阵的部分结果或最终结果,保存在累加器(accumulator)308中。
[0186]
向量计算单元307可以对运算电路303的输出做进一步处理,如向量乘,向量加,指数运算,对数运算,大小比较等等。例如,向量计算单元307可以用于神经网络中非卷积/非fc层的网络计算,如池化(pooling),批归一化(batch normalization),局部响应归一化(local response normalization)等。
[0187]
在一些实现种,向量计算单元能307将经处理的输出的向量存储到统一缓存器306。例如,向量计算单元307可以将非线性函数应用到运算电路303的输出,例如,累加值的向量,用以生成激活值。
[0188]
在一些实现中,向量计算单元307生成归一化的值、合并值,或二者均有。
[0189]
在一些实现中,处理过的输出的向量能够用作到运算电路303的激活输入,例如,用于在神经网络中的后续层中的使用。
[0190]
统一存储器306用于存放输入数据以及输出数据。
[0191]
权重数据直接通过存储单元访问控制器(direct memory access controller,dmac)305将外部存储器中的输入数据搬运到输入存储器301和/或统一存储器306、将外部
存储器中的权重数据存入权重存储器302,以及将统一存储器306中的数据存入外部存储器。
[0192]
总线接口单元(bus interface unit,biu)310,用于通过总线实现主cpu、dmac和取指存储器309之间进行交互。
[0193]
与控制器304连接的取指存储器(instruction fetch buffer)309,用于存储控制器504使用的指令;控制器304,用于调用指存储器309中缓存的指令,实现控制该运算加速器的工作过程。
[0194]
一般地,统一存储器306,输入存储器301,权重存储器302以及取指存储器309均为片上(on-chip)存储器,外部存储器为该npu外部的存储器,该外部存储器可以为双倍数据率同步动态随机存储器(double data rate synchronous dynamic random access memory,ddr sdram)、高带宽存储器(high bandwidth memory,hbm)或其他可读可写的存储器。
[0195]
其中,图2所示的卷积神经网络中各层的运算可以由运算电路303或向量计算单元307执行。
[0196]
上文中介绍的图1中的执行设备110能够执行本技术实施例的图像显示方法的各个步骤,具体地,图2所示的cnn模型和图3所示的芯片也可以用于执行本技术实施例的图像显示方法的各个步骤。
[0197]
应理解,在本技术的各实施例中,“第一”、“第二”、“第三”等仅是为了指代不同的对象,并不表示对指代的对象有其它限定。
[0198]
下面结合附图4对本技术实施例的图像显示方法进行详细的介绍。图像显示设备可以是具有图像显示功能的电子设备,该电子设备可以包括显示屏和摄像头。该电子设备具体可以是移动终端(例如,智能手机),电脑,个人数字助理,可穿戴设备,车载设备,物联网设备或者其他能够进行图像显示的设备。
[0199]
图4所示的方法包括步骤410至440,下面分别对这些步骤进行详细的描述。
[0200]
410、检测到用户用于打开相机的第一操作。
[0201]
420、响应于所述第一操作,在所述显示屏上显示拍摄界面,在所述显示屏上显示拍摄界面,所述拍摄界面上包括取景框,所述取景框内包括第一图像。
[0202]
在一个示例中,用户的拍摄行为可以包括用户打开相机的第一操作;响应于所述第一操作,在显示屏上显示拍摄界面。
[0203]
图5中的(a)示出了手机的一种图形用户界面(graphical user interface,gui),该gui为手机的桌面510。当电子设备检测到用户点击桌面510上的相机应用(application,app)的图标520的操作后,可以启动相机应用,显示如图5中的(b)所示的另一gui,该gui可以称为拍摄界面530。该拍摄界面530上可以包括取景框540。在预览状态下,该取景框540内可以实时显示预览图像。
[0204]
示例性的,参见图5中的(b),电子设备在启动相机后,取景框540内可以显示有第一图像,该第一图像为彩色图像。拍摄界面上还可以包括用于指示拍照模式的控件550,以及其它拍摄控件。需要注意的是,在本技术实施例中,为了区别于灰度图像部分,彩色图像部分通过斜线填充来表示。
[0205]
在一个示例中,用户的拍摄行为可以包括用户打开相机的第一操作;响应于所述
第一操作,在显示屏上显示拍摄界面。例如,电子设备可以检测到用户点击桌面上的相机应用(application,app)的图标的第一操作后,可以启动相机应用,显示拍摄界面。在拍摄界面上可以包括取景框,可以理解的是,在拍照模式和录像模式下,取景框的大小可以不同。例如,取景框可以为拍照模式下的取景框。在录像模式下,取景框可以为整个显示屏。在预览状态下即可以是用户打开相机且未按下拍照/录像按钮之前,该取景框内可以实时显示预览图像。
[0206]
在一个示例中,预览图像可以为彩色图像,根据预览图像可以确定当前电子设备所处环境的光照度。例如,若当前预览图像的亮度较低,则可以说明当前电子设备处于低光照度的环境下,低光照度可以是光照度在0.3lux及其以下的场景中。
[0207]
430、检测到所述用户指示相机的第二操作。
[0208]
例如,可以是检测到用户指示第一处理模式的第二操作。其中,第一处理模式可以是专业拍摄模式,或者,第一处理模式还可以是夜景拍摄模式。参见图6中的(a),拍摄界面上包括拍摄选项560,在电子设备检测到用户点击拍摄选项560后,参见图6中的(b),电子设备显示拍摄模式界面。在电子设备检测到用户点击拍摄模式界面上用于指示专业拍摄模式561后,手机进入专业拍摄模式。
[0209]
例如,可以是检测到用户用于指示拍摄的第二操作,该第二操作为在低照度下用于指示拍摄的操作。参见图7中,电子设备在低照度环境下,检测到用户用于指示拍摄的第二操作570。
[0210]
应理解,用户用于指示拍摄行为的第二操作可以包括按下电子设备的相机中的拍摄按钮,也可以包括用户设备通过语音指示电子设备进行拍摄行为,或者,还可以包括用户其它的指示电子设备进行拍摄行为。上述为举例说明,并不对本技术作任何限定。
[0211]
440、响应于所述第二操作,在所述取景框内显示第二图像,所述第二图像为针对所述摄像头采集到的n帧原始raw图像进行处理后的图像,其中,神经网络模型应用于所述处理过程中,所述神经网络模型以噪声低于目标阈值的图像作为输出目标,n为大于或等于2的整数。
[0212]
例如,所述神经网络模型可以是以噪声低于目标阈值的raw图像作为输出目标。
[0213]
本技术中,检测到用户打开相机的第一操作,以及用户指示相机的第二操作,响应所述第二操作,在显示屏的取景框内显示第二图像,第二图像是针对摄像头采集到的n帧原始raw图像进行处理后的图像。由于raw图像是未经过加速器算法以及isp的处理的图像,因此raw图像中噪声的形态未受到破坏。在本技术中,通过获取n帧raw图像进行去噪处理,能够提高低照度环境下图像的去噪效果。
[0214]
可选地,在一种可能的实现方式中,第二图像为神经网络模型输出的yvu图像。
[0215]
可选地,在一种可能的实现方式中,第二图像为yuv图像,该yuv图像是将神经网络模型输出的raw图像进行后处理,得到的yuv图像。后处理可以将raw图像转换为yuv图像,例如,可以包括drc处理、awb处理以及isp处理。
[0216]
可选地,在一种可能的实现方式中,第二图像为神经网络模型输出的raw图像。
[0217]
参见图8,图8中取景框内显示的是第二图像,第二图像和第一图像的内容相同或者实质上相同。但是第二图像的画质优于第一图像。
[0218]
示例性地,在一种可能的实现方式中,所述第二图像为所述神经网络模型的输出
图像,所述第二图像为yuv图像。
[0219]
示例性地,在另一种可能的实现方式中,所述第二图像为对所述神经网络模型的输出图像(例如,raw图像)进行后处理,得到的yuv图像。
[0220]
例如,所述后处理可以包括:对所述输出图像进行动态压缩控制drc处理,得到高动态特征图像;对所述高动态特征图像进行白平衡awb处理,得到色彩校正图像;对所述色彩校正图像进行图像信号处理,得到所述第二图像。
[0221]
也就是说,在神经网络模型输出的输出图像是raw图像,在电子设备的内部对raw图像进行后处理,例如,对输出的raw图像进行的后处理可以包括drc处理、awb处理以及图像信号处理,得到所述第二图像,其中,第二图像为yuv图像,即对输出的raw图像进行后处理后得到yuv图像。
[0222]
应理解,第一图像为极低照度场景下的预览图像,例如,第一图像可以是夜晚场景的预览图像,更具体地,可以是光照度在0.3lux以下场景的预览图像。第二图像的画质优于第一图像,例如,第二图像中的颜色、亮度、细节、噪声优于第一图像。
[0223]
在本技术中,电子设备处理的为通过摄像头采集到的n帧原始raw图像,原始raw图像不同于yuv图像,raw图像为传感器将捕捉到的光源信号转化为数字信号的原始数据,yuv图像为将raw图像通过通过后处理得到的图像,后处理包括加速器和isp处理。也就是说,原始raw图像中的噪声最接近用户的使用电子设备的真实的噪声引入的场景。
[0224]
在本技术中,步骤440中的第二图像为经过电子设备中的神经网络模型处理后得到输出图像,其中,第二图像为yuv图像。下面结合图9,包括步骤121至步骤123,对神经网络模型得到输出图像的过程进行详细的说明。
[0225]
步骤121、获取n帧原始raw图像,其中,所述n帧原始raw图像中包括参考帧图像和m帧待处理图像,n为大于或等于2的整数,m为小于n的正整数。
[0226]
应理解,上述获取n帧原始raw图像可以是步骤440中的电子设备的摄像头采集到的n帧原始raw图像。
[0227]
例如,摄像头为包括传感器和镜头的模组。获取n帧原始raw图像可以是获取传感器生成的raw图像。raw图像未经过加速器,比如神经网络处理器(neural-network processing unit,npu)、图形处理器(graphics processing unit,gpu)、数字信号处理器(digital signal processor,dsp)等处理器进行算法加速,以及未经过图像信号处理器(image signal processor,isp)处理的原始图像。因此,raw图像中的噪声的原始形态并未由于算法的处理受到破坏。即raw图像中的噪声最接近用户的使用电子设备的真实的噪声引入的场景。
[0228]
在本技术的实施例中,电子设备满足预设条件可以是电子设备拍摄时所处环境为低照度,即可以是显示屏上显示的拍摄界面的亮度值低于目标亮度值,例如,目标亮度值可以是80;或者,可以是电子设备的iso值处于目标范围内,例如,目标范围可以是iso值大于12800,其中,电子设备的iso值可以是用户设置的。当电子设备满足上述任意至少一个条件或者是多个条件同时满足时,电子设备可以从传感器获取n帧raw图像。
[0229]
在一个示例中,电子设备检测到用户打开相机的第一操作,可以启动相机应用,显示拍摄界面。在拍摄界面上可以包括取景框,取景框中显示的第一图像即可以是预览图像。例如,当第一图像的亮度值低于目标亮度值,并且,检测到用户指示拍摄的第二操作,此时,
电子设备可以获取传感器中的n帧raw图像。
[0230]
在一个示例中,电子设备检测到用户打开相机的第一操作,可以启动相机应用。进一步,检测到用户指示相机的第二操作。例如,检测到所述用户指示第一处理模式的第二操作。其中,第一处理模式可以是专业拍摄模式或夜景拍摄模式或其它模式,例如,可以是检测到用户选择专业拍摄模式或夜景拍摄模式的第二操作。响应于用户选择的专业拍摄模式或夜景拍摄模式的第二操作,电子设备将传感器的感光度iso值配置于目标范围内,例如,将电子设备的传感器的iso值设置大于12800以上。
[0231]
上述获取的n帧原始raw图像中可以包括参考帧图像和m帧待处理图像,其中,参考帧图像可以是获取的n帧图像中画面质量较好的图像,例如,可以通过对比度从获取的n帧raw图像中选择出作为参考帧的图像。
[0232]
步骤122、根据所述参考帧图像对所述m帧待处理图像进行配准处理,得到m帧配准图像。
[0233]
其中,配准处理可以看作是将m帧待处理图像中的每帧待处理图像与参考帧图像中对应的图像特征点进行坐标对齐。
[0234]
示例性地,可以根据参考帧图像通过光流法对m帧待处理图像中的每帧图像进行配准处理。
[0235]
在一种实现方式中,可以采用图10所示的图像配准方法。
[0236]
如图10所示,一帧待处理图像与参考帧图像之间的配准处理可以包括图像预处理、klt、图像扭转(image warping)的处理过程。具体地,图10所示的方法包括步骤501至步骤509,下面分别对步骤501至步骤509进行详细描述。
[0237]
其中,图像预处理过程包括步骤501至步骤503,可以将输入的bayer域的raw图像进行预处理,得到灰度图像。具体地,包括:
[0238]
步骤501:分别对一帧待处理图像和参考帧图像进行合并g通道处理。
[0239]
步骤502:直方图均衡化处理。即使得经过g通道合并处理后的待处理图像和参考帧图像的图像亮度一致。
[0240]
步骤503:直方图均衡化处理后得到的图像进行高斯滤波,分别得到待处理图像对应的灰度图像和参考帧对应的灰度图像。
[0241]
其中,高斯滤波处理是指是一种线性平滑滤波,适用于消除高斯噪声,应用于图像处理的减噪过程。通俗的讲,高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替换中心像素点的值。
[0242]
klt(kanade-lucas-tomasi)算法包括步骤504至步骤507,klt算法是对预处理的两张灰度图计算待处理帧(match frame)和参考帧(reference frame)之间的单应矩阵。具体算法流程:
[0243]
步骤504:特征检测。即可以是参考帧图像分成大小相同的16*16个块,在每个块里检测最多3个特征点,保证每个特征点之间横向和纵向距离最小为11。
[0244]
步骤505:特征点跟踪。即可以是以每个特征点为中心,大小为11*11作为一个patch,在待处理图像上搜索与参考帧图像patch最为相似的patch。搜索到的最为相似的
patch中心与参考帧图像的特征点构成相似特征点对。
[0245]
步骤506:单应性估计。即采用ransac的方式迭代剔除异常的特征点对,然后用筛选得到的内点集计算单应矩阵。
[0246]
步骤507:图像扭转处理,即可以是通过单应矩阵将待处理图像变换到和参考帧图像相似的warp图像,可以采用分通道(bggr四个通道)进行最邻近的插值warp算法。
[0247]
步骤508:鬼影检测,通过将图像扭转处理后得到的图像与参考帧图像进行作差处理,得到鬼影图像,从而确定哪些特征点处存在鬼影。例如,作差处理后得到的某一个特征点的差值较大,则说明该特征点存在鬼影;若作差处理后得到的某一特征点的差值较小,则说明该特征点不存在鬼影。
[0248]
步骤509:得到配准图像。
[0249]
可以理解的是,上述对配准处理过程进行了举例描述,仅仅是为了帮助本领域技术人员理解本技术实施例,而非要将本技术实施例限于所例示的具体场景。本领域技术人员根据所给出的图10的例子,显然可以进行各种等价的修改或变化,这样的修改或变化也落入本技术实施例的范围内。
[0250]
步骤123、根据图像集合和神经网络模型,得到去噪处理后的输出图像,所述神经网络模型以噪声低于目标阈值的图像作为输出目标,所述图像集合包括所述m帧配准图像和所述参考帧图像。
[0251]
在本技术的实施例中,神经网络模型可以是通过图1所示预先配置的神经网络,该预配置的神经网络可以通过训练数据进行预先训练的神经网络,其中,训练数据可以包括原始raw图像(这里的原始raw图像可以是包含噪声很少的图像,例如,可以是噪声低于目标阈值的raw图像)和在原始图像上加上噪声之后的噪声图像。
[0252]
示例性地,根据所述图像集合和所述神经网络模型,得到去噪处理后的输出图像,可以包括:对图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,所述图像集合包括m帧配准图像和参考帧图像,通道图像包括第一通道图像、第二通道图像以及第三通道图像;采用神经网络模型对图像集合对应的通道图像集合进行处理,得到关联数据,关联数据包括图像与图像之间的关联信息(即帧与帧之间的关联信息),图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息中的一种或多种;根据关联数据得到每帧图像的目标通道图像,目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;对目标通道图像进行合通道处理,得到去噪处理后的输出图像。
[0253]
应理解,噪声图像是通过神经网络模型预估的噪声图像。即可以是通过神经网络处理,得到预估的噪声图像,即噪声估计图像。
[0254]
在一种可能的实现方式中,根据所述图像集合和所述神经网络模型,得到去噪处理后的输出图像,包括:
[0255]
对所述图像集合进行前处理,得到每帧图像对应的通道图像,其中,所述前处理为颜色通道分离,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;将所述图像集合中每帧图像对应的通道图像作为输入数据输入所述神经网络模型,得到所述神经网络模型的输出数据为目标通道图像,所述目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图
像以及第三通道的噪声图像,对所述目标通道图像进行后处理,得到所述去噪处理后的输出图像,其中,所述后处理包括合并通道处理、drc处理、awb处理以及isp处理。
[0256]
应理解,在一种可能的,上述前处理和后处理流程中的任意一个可以在所述神经网络模型中执行。或者,在另一种可能的实现方式中,上述前处理和后处理流程中的任意一个可以不在所述神经网络模型中执行,本技术对此不作任何限定。
[0257]
示例性地,在本技术中,可以对图像集合中的图像进行颜色通道分离处理后输入至神经网络模型,使得神经网络模型可以根据更多的参照信息进行学习。
[0258]
例如,神经网络模型可以根据输入的图像集合进行学习得到关联数据,根据关联数据得到每帧图像的目标通道图像,即神经网络模型输出的是目标通道图像。应理解,关联数据为神经网络模型内部根据输入的图像进行学习得到的关联数据,例如,关联数据可以包括图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息。
[0259]
示例性地,图像与图像之间的关联信息可以是图像与图像之间的亮度、纹理、噪声、细节等信息,或者,可以是不同图像中同一特征点的像素值。通道间的关联信息,可以是指不同通道或者不同图像的同一通道之间的亮度、纹理、噪声的等信息的关联性。其中,纹理特征可以用于描述图像或图像中部分区域的空间颜色分布和光强分布。
[0260]
可选地,在一个实施例中,第一通道图像、第二通道图像、第三通道图像可以对应r通道图像、y通道图像以及b通道图像,y通道图像可以包括yb通道图像和yr通道图像,其中,y通道可以代表全通道,类似于rgb的总和,yb通道图像是指在含有b的像素的左右相邻两侧的y通道图像,yr通道图像是指在含有r的像素的左右相邻两侧的y通道图像。
[0261]
可选地,在一个实施例中,第一通道图像、第二通道图像、第三通道图像可以对应r通道图像、g通道图像以及b通道图像,g通道图像可以包括gb通道图像和gr通道图像,gb通道图像可以表示g通道与b通道具有相关联性的通道图像,gr通道图像可以表示g通道与r通道具有相关联性的通道图像。
[0262]
例如,以m=2进行举例说明。可以将第一帧配准图像进行通道分离处理,得到第一通道#1、第二通道图像#1、第三通道图像#1;对第二帧配准图像进行通道分离处理,得到第二帧配准图像对应的第一通道#2、第二通道图像#2、第三通道图像#2。以第一通道图像为r通道图像、第二通道图像为yr通道图像和yb通道图像、第三通道图像为b通道图像进行举例说明。将第一帧配准图像经过分离通道处理后可以包括的r通道图像#1、yr通道图像#1、yb通道图像#1以及b通道图像#1,第二帧配准图像经过分离通道处理后可以包括的r通道图像#2、yr通道图像#2、yb通道图像#2以及b通道图像#2,以及参考帧图像进行通道分离处理后包括的r通道图像#3、yr通道图像#3、yb通道图像#3以及b通道图像#3,将图像集合输入至神经网络模型,图像集合中包括r通道图像#1~#3、yr通道图像#1~#3、yb通道图像#1~#3以及b通道图像#1~#3,神经网络模型可以根据第一帧配准图像、第二帧配准图像以及参考帧图像中,同一个特征点的像素值之间的关联信息进行学习,还可以根据r通道图像#1~#3、yr通道图像#1~#3、yb通道图像#1~#3、b通道图像#1~#3中任意通道之间的亮度、纹理、噪声的等信息进行学习,可以是同一帧图像对应的不同通道之间进行学习,也可以是不同帧图像对应的相同通道之间进行学习,从而得到关联数据。应理解,上述第一通道图像也可以为r通道图像、第二通道图像为gr通道图像和gb通道图像、第三通道图像为b通道图像,本
申请对此不作任何限定。
[0263]
可选地,n帧raw图像可以是拜耳格式的图像。
[0264]
利用拜耳(bayer)格式的图像时,即可以在一块滤镜上设置的不同的颜色,通过分析人眼对颜色的感知发现,人眼对绿色比较敏感,所以在bayer格式的图片中绿色格式的像素可以是r像素和g像素的和,即可以看作是图像中的g通道图像可以是gb通道图像和gr通道图像,通过gb通道图像和gr通道图像从而确定图像的g通道。
[0265]
例如,图11(a)所示的为bayer色彩滤波阵列,由一般的g,1/4的r以及1/4的b组成。每一个像素可能只包括光谱的一部分,需要通过插值来实现每个像素的rgb值。为了从bayer格式得到每个像素的rbg格式,可以通过插值填补缺失的2个色彩。如可以使用领域、线性、3*3等插值的方法,以线性插值补偿算法举例进行说明。如图11(b)至图11(g)所示,在图11(b)和图11(c)中,r和b可以分别确邻域的平均值;在图11(d)中,可以取邻域的4个b的均值作为中间像素的b值;在图11(e)中,可以取邻域的4个r的均值作为中间像素的b值。
[0266]
进一步,扩展开来,在图11(f)中,中间像素g值的算法可以如下:
[0267][0268]
进一步,扩展开来,在图11(g)中,中间像素g值的算法可以如下:
[0269][0270]
上述确定像素g(r)的算法可以看作是确定gb通道图像的过程,上述确定像素g(b)的算法可以看作是确定gb通道图像的过程。
[0271]
应理解,在图11(a)中第一行g通道的左右相邻两侧为r通道,即第一行中的g通道可以表示gr通道;第二行g通道的左右相邻两侧为b通道,即第二行中的g通道可以表示gb通道。
[0272]
在本技术中,神经网络模型可以根据关联数据,例如可以包括帧与帧之间的关联信息,帧内的不同通道之间的关联信息,以及不同帧之间的通道间的关联信息,从而可以使神经网络模型根据更多的相关信息进行学习训练,最终使得图像进行去噪处理时的去噪效果更好。
[0273]
在一个示例中,图像集合中可以进一步包括鬼影图像,鬼影图像是通过m帧配准图像和参考帧图像作差得到的;根据m帧配准图像、参考帧图像、鬼影图像和神经网络模型,得到输出图像。
[0274]
其中,可选地,上述根据m帧配准帧图像和参考帧图像得到鬼影图像,包括:
[0275]
步骤1:获取第i个配准图像;
[0276]
步骤2:根据第i个图像的图像特征和参考帧图像的图像特征进行作差处理。
[0277]
重复上述步骤1和步骤2,得到第m个作差处理后的图像,进行图像特征融合,以得到鬼影图像。
[0278]
应理解,当输入神经网络模型的图像集合中包括鬼影图像时,得到的输出图像可以是去噪且去鬼影的输出图像。
[0279]
例如,对图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,图像集合中可以包括m帧配准图像和参考帧图像以及鬼影图像,通道图像可以包括第一通道图像、第二通道图像以及第三通道图像,例如通道图像可以包括r通道图像、b通道图像、yb通道图像以及yr通道图像,或者,通道图像可以包括r通道图像、b通道图像、gb通道图像以及gr通道图像;采用神经网络模型对图像集合对应的通道图像集合进行处理,得到关联数据,关联数据可以包括帧与帧之间的关联信息,帧内的不同通道之间的关联信息,以及不同帧之间的通道间的关联信息中的一种或多种;根据关联数据得到每帧图像的第一目标通道图像,第一目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;对m帧配准图像的图像特征进行融合取平均值处理,得到平均图像;对平均图像进行颜色通道分离,得到通道平均图像,通道平均图像包括第一通道的平均图像、第二通道的平均图像以及第三通道的平均图像;将通道平均图像与对应的第一目标通道图像进行特征叠加,得到第二目标通道图像;对第二目标通道图像进行合通道处理,得到去噪处理后的输出图像。
[0280]
进一步地,本技术中,在输入至神经网络模型的图像集合中包括鬼影图像时,不仅可以得到去噪处理的输出图像,还可以去除输出图像中的鬼影图像。
[0281]
下面结合图12对具体流程进行举例性描述。
[0282]
如图12所示,首先对输入图像以及输出图像的参数配置进行简要说明。
[0283]
数据来源可以包括经过配准处理的m帧配准图像,其中,配准图像的尺寸大小和曝光参数可以相同,配准图像可以是彩色raw图像支持bayer格式,例如,图像格式可以是bggr、rggb、ryyb(对于bggr以外的格式,需要做padding转为bggr,并在输出裁剪掉padding的部分),输出raw图像支持与输入对应,图像数据存储方式支持stride≠width。输入raw图像的分辨率为m x n,m可以是{3264,3648,3968,4608,5120}中的任意一个,n可以是{2056,2240,2448,2736,2976,3456,3840}中的任意一个。
[0284]
例如,图12中输入图像为7帧raw图像,7帧raw图像包括1帧鬼影图像和6帧raw配准图像(其中,一帧图像的分辨率为w
×
h),将7帧图像中的每帧图像分别进行通道拆分,每帧raw图分别得到4张宽和高缩小为原来一半的raw图(分辨率为w/2
×
h/2),共获取28个raw图像,将28个raw图像输入至基于深度学习的多帧降噪网络(deep learning based multiple frame noise reduction,dl-mfnr),得到输出的4个噪声估计图像(例如,噪声图像),4个噪声估计图可以对应于不同的通道,例如,若输入图像进行通道拆分时得到r通道图像、gr通道图像、gb通道图像以及b通道图像,则4个噪声估计图为r通道噪声估计图、gr通道噪声估计图、gb通道噪声估计图以及b通道噪声估计图;此外,通道拆分还可以按照bggr或者ryyb进行通道拆分。将6帧raw配准图像进行图像特征融合取平均值处理,得到1帧分辨率为w
×
h平均图像,对平均图像进行通道拆分,得到4个分通道图像,将得到的4个分通道图像分别与
对应的4个噪声估计图进行叠加得到4个通道对应的目标通道图像,对4个通道对应的目标通道图像进行合并通道处理,得到输出图像。
[0285]
在dl-mfnr网络中,对应的通道图像集合进行处理,可以得到关联数据,在图像通道集合中包括m帧配准图像和参考帧图像以及鬼影图像时,关联数据可以帧与帧之间的关联信息,例如,可以是m个配准图像与参考图像的关联信息,或者,可以是m个配准图像与鬼影图像的关联信息,或者,可以是m个配准图像与鬼影图像、参考帧图像的关联信息;关联数据也可以是帧内的不同通道之间的关联信息;关联数据也可以是不同帧之间的通道间的关联信息。
[0286]
需要说明的是,图12是以将raw图像进行4个通道拆分的举例说明,并不对通道拆分的具体通道数量进行任何限定。
[0287]
应理解,在图12中是以颜色通道分离处理和合通道处理在神经网络模型外执行进行举例说明,但是上述颜色通道分离和合通道处理也可以在神经网络模型内执行,即神经网络模型也可以具有上述颜色通道分离和合通道的功能,本技术对此不作任何限定。
[0288]
图13示出了dl-mfnr网络的结构示意图。
[0289]
如图13所示,图13中包括输入层、卷积层、隐含层和输出层。其中,201可以表示输入层、202可以表示输出层,其余均可以包括卷积层和隐含层。图13所示w/2
×
h/2
×
28可以表示28个分辨率为w/2
×
h/2的特征图像,relu表示线性整流函数(rectified linear unit,relu)。
[0290]
在图13中,卷积算子为3
×
3。卷积层可以包括很多个卷积算子,卷积算子也称为核,其在图像处理中的作用相当于一个从输入图像矩阵中提取特定信息的过滤器,卷积算子本质上可以是一个权重矩阵,这个权重矩阵通常被预先定义,在对图像进行卷积操作的过程中,权重矩阵通常在输入图像上沿着水平方向一个像素接着一个像素(或两个像素接着两个像素
……
取决于步长stride的取值)的进行处理,从而完成从图像中提取特定特征的工作。该权重矩阵的大小应该与图像的大小相关。输出层201具有类似分类交叉熵的损失函数,具体用于计算预测误差,一旦整个卷积神经网络的前向传播完成,反向传播(就会开始更新前面提到的各层的权重值以及偏差,以减少卷积神经网络的损失,及卷积神经网络通过输出层输出的结果和理想结果之间的误差。在图13所示的网络中,以噪声低于目标阈值的图像作为输出目标,不断对输入网络的原始raw图像进行迭代处理,最终将得到的无限接近于输出目标的raw图像输出网络。
[0291]
应理解,图13所示的神经网络的层数、卷积核大小以及每个卷积层的特征数量均为举例说明,本技术对此不作任何限定。
[0292]
应理解,在本技术中,神经网络模型可以是图13所示的dl-mfnr网络。
[0293]
可选地,进一步,可以对得到输出图像进行动态压缩控制drc处理,得到高动态特征图像;对高动态特征图像进行白平衡awb处理,得到色彩校正图像;对色彩校正图像进行图像信号处理,得到所述第二图像。
[0294]
例如,在神经网络模型输出的输出图像是raw图像,在电子设备的内部对raw图像进行后处理,例如,对输出的raw图像进行的后处理可以包括drc处理、awb处理以及图像信号处理,得到所述第二图像,其中,第二图像为yuv图像,即对输出的raw图像进行后处理后得到yuv图像。
[0295]
在一种实现方式中,可以采用图14所示的动态压缩控制drc处理方法。
[0296]
如图14所示,drc处理的方法包括步骤601至步骤621,下面分别对步骤601至步骤621进行详细描述。
[0297]
步骤601:获取原始图像,即获取神经网络的输出的输出图像,输出图像可以为raw图像。
[0298]
步骤602:导向滤波。
[0299]
通过导向滤波用(guided filter)对原始图像的各通道分别作滤波,分离出细节(detail)层和基础(base)层。其中,base层用于模拟曝光融合,生成高动态图像,detail层用于最后的细节增强。
[0300]
步骤603:暗角修正。对base层做暗角修正(lens shading)补偿。
[0301]
步骤604:rggb至灰度图1。将步骤603处理得到的补偿后的图像进行rggb2gray,结果记为gray1,该灰度图1是后续hdr计算的基础图。
[0302]
步骤605:下采样。为了减小计算开销,可以对gray1进行下采样处理,得到原灰度图1的1/4,记为gray_ds。
[0303]
步骤606:彩色阴影校正。
[0304]
对base层做彩色阴影(color shading)校正,可以消除拜耳格式(bayer pattern)上四通道shading值的差异。
[0305]
步骤607:rggb至灰度图2。将步骤605处理得到的校正的图像进行rggb2gray,结果记为gray2,该灰度图2是未做暗角修正,因此能够保留更多暗区光源细节,用于恢复高光区域。
[0306]
步骤608:下采样。为了减小计算开销,可以对gray2进行下采样处理,得到原灰度图2的1/4,记为gray_low_ds。
[0307]
步骤609:全局色调映射。
[0308]
对步骤605得到的gray_ds做全局色调映射(global tone mapping),保护暗区,防止进行提亮处理后图像无暗区。
[0309]
步骤610:曝光估计。
[0310]
对步骤609进行全局色调映射处理后的gray_ds进行估计模拟曝光的亮帧、暗帧、人脸提亮帧的曝光参数。
[0311]
步骤611:亮度映射。
[0312]
可以采用retinex算法,由gray_ds进行亮度映射确定亮帧和人脸提亮帧,由gray_low_ds确定暗帧。
[0313]
步骤612:高亮度帧曝光。
[0314]
步骤613:曝光融合。
[0315]
基于guided filter的曝光融合算法是采用的gaussian filter替换为guided filter。利用guided filter建立图像可以更好地保持图像对比度,将融合图像记为gray_f。
[0316]
步骤614:细节增强。
[0317]
采用guided filter对gray_f进行保边滤波,将滤出的detail层在乘以增益值后回叠,进行细节增强。
[0318]
步骤615:全局色调映射。
[0319]
对gray_f做全局色调映射2,改善全局对比度。
[0320]
步骤616:计算伽马校正后的drc增益。
[0321]
步骤617:计算伽马校正前的drc增益。
[0322]
其中,计算伽马校正(degamma)前后的drc增益;伽马校正前的drc增益用于细节回叠强度的计算;伽马校正后的drc增益用于计算最后的drc结果。
[0323]
步骤618:上采样。
[0324]
可以对伽马校正后的drc增益做4倍上采样。
[0325]
步骤619:细节增强。利用guided filter增强drc_gain的高频细节。
[0326]
步骤620:细节增益。
[0327]
估计rggb域上detail层回叠强度detail_strength。
[0328]
步骤621:输出drc结果。
[0329]
将detail层回叠到原始图像上,得到结果图像。
[0330]
应理解,上述图14所示的drc处理方法为举例说明,本技术中进行drc处理的具体流程也可以采用其他现有技术中的drc处理方法,本技术对此不作任何限定。
[0331]
图15是本技术实施例提供的图像显示方法的示意性流程图。图15所示的方法包括步骤701至步骤705,下面分别对步骤701至步骤705进行详细描述。
[0332]
步骤701:场景检测或者专业模式选择。
[0333]
例如,检测到用户用于打开相机的第一操作;响应于所述第一操作,在所述显示屏上显示拍摄界面,所述拍摄界面上包括取景框,所述取景框内包括第一图像。第一图像为极低照度场景下的预览图像,例如,第一图像可以是夜晚场景的预览图像,更具体地,可以是光照度在0.3lux以下场景的预览图像。进一步,可以是电子设备调用传感器检测到低照度场景下,如光照度在0.3lux以下场景中,用户指示拍摄的第二操作。其中,指示拍摄的第二操作可以是用户按下电子设备的相机中的拍摄按钮,或者,也可以是用户设备通过语音指示电子设备进行拍摄行为,或者,还可以包括用户其它的指示电子设备进行拍摄行为。
[0334]
示例性地,检测到所述用户指示第一处理模式的第二操作。
[0335]
例如,第一处理模式可以是专业拍摄模式或夜景拍摄模式或其它模式,例如,可以是检测到用户选择专业拍摄模式或夜景拍摄模式的第二操作。响应于用户选择的专业拍摄模式或夜景拍摄模式的第二操作,电子设备将传感器的感光度iso值配置于目标范围内,例如,将电子设备的传感器的iso值设置大于12800以上。
[0336]
步骤702:电子设备对传感器进行曝光时间和iso以及帧数的配置。
[0337]
例如,图12所示的实施例中,配置为输出6帧原始raw图。
[0338]
步骤703:获取传感器中的n帧raw图像。
[0339]
步骤704:将n帧raw图像进行图像处理。其中,包括:
[0340]
步骤1,进行配准处理。
[0341]
具体执行流程可以参见上述图9所示的步骤122中的可能实现方式,以及图10所示的配准处理流程图,此处不再赘述。
[0342]
步骤2,将配准处理后的raw图像输入至dl-mfnr网络进行降噪处理。
[0343]
进一步地,若dl-mfnr的网络的输入图像中包括鬼影图像,则可以获取去噪声且去
鬼影的输出图像。
[0344]
具体执行流程可以参见上述图9所示的步骤123中的可能实现方式,以及图12所示的图像处理方法,此处不再赘述。
[0345]
步骤3,获取dl-mfnr网络输出的输出图像,即获取输出raw图像,对输出图像进行drc处理。
[0346]
具体执行流程参见上述图14所示的drc处理方法,此处不再赘述。
[0347]
步骤4,将进行drc处理后得到的高动态特征图像,进行白平衡awb处理,得到色彩校正图像。
[0348]
步骤705:将得到的色彩校正图像通过isp进行处理,得到yuv图像,即在得到第二图像,在电子设备的显示屏的取景框内显示第二图像。
[0349]
上述图15将电子设备在低照度场景下图像处理的流程进行了描述,其中,具体每个步骤的可能实现方式可以参见前述图4、图9以及图12中的描述,此处不再赘述。
[0350]
需要说明的是,图15中是以神经网络模型(即dl-mfnr网络)输出的输出图像为raw图像为例进行说明,进一步需要对输出的raw图像进行后处理,其中,后处理可以包括drc、awb以及isp处理。应理解,上述后处理的执行可以是在神经网络模型外执行,即上述后处理过程可以不在神经网络中执行。在一种可能的实现方式中,神经网络模型也可以具有上述后处理的功能,即上述后处理的流程也可以是在神经网络模型中执行的步骤,本技术对此不作任何限定。
[0351]
图16和图17所示的示意图为根据本技术实施例中的图像显示方法和现有技术中图像显示方法对同一场景拍摄获得的图像的示意图。如图16所示,在同一拍摄场景下,例如,可以是在光照度低于0.3lux以下的拍摄场景中,图16中(d)为根据本技术实施例中图像显示方法得到的图像。需要说明的是,图16(a)至图16(d)均为彩色图像,根据图16可以看出,图16(d)画质优于其它图像,例如,图16(d)中图像的颜色、亮度、细节、噪声等均优于其它图像。同理,如图17所示,在同一拍摄场景下,例如,可以是在光照度低于0.3lux以下的拍摄场景中,图17中(d)为根据本技术实施例中图像显示方法得到的图像。根据图17可以看出,图17(d)画质优于其它图像,例如,图17(d)中图像的颜色、亮度、细节、噪声等均优于其它图像。需要说明的是,图17(a)至图17(d)均为彩色图像。
[0352]
本技术中,检测到用户打开相机的第一操作,以及用户指示相机的第二操作,响应所述第二操作,在显示屏的取景框内显示第二图像,第二图像是针对摄像头采集到的n帧原始raw图像进行处理后的图像。由于raw图像是未经过加速器算法以及isp的处理的图像,因此raw图像中噪声的形态未受到破坏。在本技术中,通过获取n帧raw图像进行去噪处理,能够提高低照度环境下图像的去噪效果。
[0353]
应理解,上述举例说明是为了帮助本领域技术人员理解本技术实施例,而非要将本技术实施例限于所例示的具体数值或具体场景。本领域技术人员根据所给出的上述举例说明,显然可以进行各种等价的修改或变化,这样的修改或变化也落入本技术实施例的范围内。
[0354]
上文结合图1至图17,详细描述了本技术实施例提供的神经网络预先训练的方法以及图像显示方法,下面将结合图18至图19,详细描述本技术的装置实施例。应理解,本技术实施例中的图像显示设备可以执行前述本技术实施例的各种方法,即以下各种产品的具
体工作过程,可以参考前述方法实施例中的对应过程。
[0355]
图18是本技术实施例的图像显示的设备800的示意性框图。应理解,设备800能够执行图4至图17的方法中的各个步骤,为了避免重复,此处不再详述。设备800包括:检测单元801和处理单元803。
[0356]
检测单元801,用于检测检测到用户用于打开相机的第一操作;处理单元803,用于响应于所述第一操作,在所述显示屏上显示拍摄界面,所述拍摄界面上包括取景框,所述取景框内包括第一图像;所述检测单元801还用于检测到所述用户指示相机的第二操作;所述处理单元803还用于响应于所述第二操作,在所述取景框内显示第二图像,所述第二图像为针对所述摄像头采集到的n帧原始raw图像进行处理后的图像,其中,神经网络模型应用于所述处理过程中,所述神经网络模型以噪声低于目标阈值的图像作为输出目标,n为大于或等于2的整数。
[0357]
可选地,在一种可能的实现方式中,所述第二图像为所述神经网络模型输出的yuv图像。
[0358]
可选地,在另一种可能的实现方式中,所述第二图像为yuv图像,该yuv图像是对所述神经网络模型的输出的raw图像进行后处理,得到的yuv图像。
[0359]
可选地,在另一种的可能的实现方式中,所述第二图像为所述神经网络模型输出的raw图像。
[0360]
可选地,在一种可能的实现方式中,所述神经网络模型以噪声低于目标阈值的raw图像作为输出目标。
[0361]
需要说明的是,原始的raw图像不同于yuv图像,原始的raw图像为传感器将捕捉到的光源信号转化为数字信号的原始数据,yuv图像为将raw图像进行后处理得到的图像,所述后处理可以将raw图像转换为yuv图像,例如,通过加速器和isp的处理。
[0362]
还应理解,第一图像为极低照度场景下的预览图像,例如,第一图像可以是夜晚场景的预览图像,更具体地,可以是光照度在0.3lux以下场景的预览图像。第一图像和第二图像的显示内容相同或者实质上相同,其中,第二图像的画质优于第一图像,例如,第二图像中的颜色、亮度、细节、噪声优于第一图像。
[0363]
可选地,作为一个实施例,所述检测单元801具体用于,检测到所述用户指示第一处理模式的第二操作;或者,检测到所述用户用于指示拍摄的第二操作,所述第二操作为在低照度下用于指示拍摄的操作。
[0364]
例如,第一处理模式可以是专业拍摄模式或夜景拍摄模式或其它模式,例如,可以是检测到用户选择专业拍摄模式或夜景拍摄模式的第二操作。响应于用户选择的专业拍摄模式或夜景拍摄模式的第二操作,电子设备将传感器的感光度iso值配置于目标范围内,例如,将电子设备的传感器的iso值设置大于12800以上。
[0365]
例如,可以是电子设备调用传感器检测到低照度场景下,如光照度在0.3lux以下场景中,用户指示拍摄的第二操作。其中,指示拍摄的第二操作可以是用户按下电子设备中的拍摄按钮,或者,也可以是用户设备通过语音指示电子设备进行拍摄行为,或者,还可以包括用户其它的指示电子设备进行拍摄行为。
[0366]
进一步,当电子设备调用传感器检测到当前处于光照度在0.3lux以下场景时,电子设备可以将传感器的感光度iso值配置于目标范围内。
[0367]
例如,目标范围可以是iso值大于6400,或者,也可以是iso值大于12800,本技术不限于此。
[0368]
可选地,作为一个实施例,所述处理单元803具体用于:
[0369]
对所述图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,其中,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;
[0370]
采用所述神经网络对所述图像集合对应的通道图像集合进行处理,得到关联数据,所述关联数据包括图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息中的一种或多种;
[0371]
根据所述关联数据得到每帧图像的目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;
[0372]
对所述目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
[0373]
例如,处理单元803具体用于:对所述图像集合进行前处理,得到每帧图像对应的通道图像,其中,所述前处理为颜色通道分离,所述图像集合包括所述m帧配准图像和所述参考帧图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;将所述图像集合中每帧图像对应的通道图像作为输入数据输入所述神经网络模型,得到所述神经网络模型的输出数据为目标通道图像,所述目标通道图像,所述目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像,对所述目标通道图像进行后处理,得到所述去噪处理后的输出图像,其中,所述后处理包括合并通道处理、drc处理、awb处理以及isp处理。
[0374]
应理解,在一种可能的,上述前处理和后处理流程中的任意一个可以在所述神经网络模型中执行。或者,在另一种可能的实现方式中,上述前处理和后处理流程中的任意一个可以不在所述神经网络模型中执行。
[0375]
可选地,作为一个实施例,所述第一通道图像、第二通道图像以及第三通道图像包括:r通道图像、y通道图像以及b通道图像,其中,所述y通道图像包括yb通道图像和yr通道图像。
[0376]
可选地,作为一个实施例,所述第一通道图像、第二通道图像以及第三通道图像包括:r通道图像、g通道图像以及b通道图像,其中,所述g通道图像包括gb通道图像和gr通道图像。
[0377]
可选地,作为一个实施例,所述处理单元803具体用于:
[0378]
对所述图像集合中每帧图像进行颜色通道分离,得到每帧图像对应的通道图像,所述通道图像包括第一通道图像、第二通道图像以及第三通道图像;
[0379]
采用所述神经网络对所述图像集合对应的通道图像集合进行处理,得到关联数据,所述关联数据包括图像与图像之间的关联信息,图像内的不同通道之间的关联信息,以及不同图像之间的通道间的关联信息中的一种或多种;
[0380]
根据所述关联数据得到每帧图像的第一目标通道图像,所述第一目标通道图像包括第一通道的噪声图像、第二通道的噪声图像以及第三通道的噪声图像;
[0381]
对所述m帧配准图像的图像特征进行融合取平均值处理,得到平均图像;
[0382]
对所述平均图像进行颜色通道分离,得到通道平均图像,所述通道平均图像包括
第一通道的平均图像、第二通道的平均图像以及第三通道的平均图像;
[0383]
将所述通道平均图像与对应的所述第一目标通道图像进行特征叠加,得到第二目标通道图像;
[0384]
对所述第二目标通道图像进行合通道处理,得到所述去噪处理后的输出图像。
[0385]
可选地,作为一个实施例,所述n帧原始raw图像为拜耳格式的图像。
[0386]
可选地,作为一个实施例,所述处理单元803具体用于:
[0387]
对所述输出图像进行动态压缩控制drc处理,得到高动态特征图像;对所述高动态特征图像进行白平衡awb处理,得到色彩校正图像;所述色彩校正图像进行图像信号处理,得到所述第二图像。
[0388]
例如,在神经网络模型输出的输出图像是raw图像,在电子设备的内部对raw图像进行后处理,例如,对输出的raw图像进行的后处理可以包括drc处理、awb处理以及图像信号处理,得到所述第二图像,其中,第二图像为yuv图像,即对输出的raw图像进行后处理后得到yuv图像。
[0389]
可选地,作为一个实施例,所述处理单元803具体用于:
[0390]
根据所述参考帧图像通过光流法对所述m帧待处理图像中的每帧图像进行配准处理,得到所述m帧配准图像。
[0391]
应理解,这里的图像显示的设备800以功能单元的形式体现。这里的术语“单元”可以通过软件和/或硬件形式实现,对此不作具体限定。例如,“单元”可以是实现上述功能的软件程序、硬件电路或二者结合。所述硬件电路可能包括应用特有集成电路(application specific integrated circuit,asic)、电子电路、用于执行一个或多个软件或固件程序的处理器(例如共享处理器、专有处理器或组处理器等)和存储器、合并逻辑电路和/或其它支持所描述的功能的合适组件。
[0392]
因此,在本技术的实施例中描述的各示例的单元,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0393]
本技术实施例还提供一种电子设备,该电子设备可以是终端设备也可以是内置于所述终端设备的电路设备。该设备可以用于执行上述方法实施例中的功能/步骤。
[0394]
如图19所示,电子设备900包括处理器910和收发器920。可选地,该电子设备900还可以包括存储器930。其中,处理器910、收发器920和存储器930之间可以通过内部连接通路互相通信,传递控制和/或数据信号,该存储器930用于存储计算机程序,该处理器910用于从该存储器930中调用并运行该计算机程序。
[0395]
可选地,电子设备900还可以包括天线940,用于将收发器920输出的无线信号发送出去。
[0396]
上述处理器910可以和存储器930可以合成一个处理装置,更常见的是彼此独立的部件,处理器910用于执行存储器930中存储的程序代码来实现上述功能。具体实现时,该存储器930也可以集成在处理器910中,或者,独立于处理器910。该处理器910可以与图18中设备800中的处理单元803对应。
[0397]
除此之外,为了使得电子设备900的功能更加完善,该电子设备900还可以包括输
入单元960、显示单元970、音频电路980、摄像头990和传感器901等中的一个或多个,所述音频电路还可以包括扬声器982、麦克风984等。其中,显示单元970可以包括显示屏,显示单元970可以与图18中设备800中的检测单元801对应。
[0398]
可选地,上述电子设备900还可以包括电源950,用于给终端设备中的各种器件或电路提供电源。
[0399]
应理解,图19所示的电子设备900能够实现图4至图17所示方法实施例的各个过程。电子设备900中的各个模块的操作和/或功能,分别为了实现上述方法实施例中的相应流程。具体可参见上述方法实施例中的描述,为避免重复,此处适当省略详细描述。
[0400]
应理解,图19所示的电子设备900中的处理器910可以是片上系统(system on a chip,soc),该处理器910中可以包括中央处理器(central processing unit,cpu)以及图3所示的(neural-network processing unit,npu)30,还可以进一步包括其他类型的处理器,所述cpu可以叫主cpu,神经网络处理器npu 30作为协处理器挂载到主cpu(host cpu)上,由host cpu分配任务。各部分处理器配合工作实现之前的方法流程,并且每部分处理器可以选择性执行一部分软件驱动程序。
[0401]
例如,图4中410至430可以由cpu执行,也可以由dsp执行,440可以由npu或者gpu 30执行。
[0402]
总之,处理器910内部的各部分处理器或处理单元可以共同配合实现之前的方法流程,且各部分处理器或处理单元相应的软件程序可存储在存储器930中。以上npu30仅用于举例,实际的神经网络功能可以由除了npu30之外的处理设备代替,如图像处理器(graphics processing unit,gpu)也可用于神经网络的处理,本实施例对此不限定。
[0403]
本技术还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有指令,当该指令在计算机上运行时,使得计算机执行如上述图4或图9所示的图像显示方法中的各个步骤。
[0404]
本技术还提供了一种包含指令的计算机程序产品,当该计算机程序产品在计算机或任一至少一种处理器上运行时,使得计算机执行如图4或图9所示的图像显示方法中的各个步骤。
[0405]
本技术还提供一种芯片,包括处理器。该处理器用于读取并运行存储器中存储的计算机程序,以执行本技术提供的图像显示方法执行的相应操作和/或流程。
[0406]
可选地,该芯片还包括存储器,该存储器与该处理器通过电路或电线与存储器连接,处理器用于读取并执行该存储器中的计算机程序。进一步可选地,该芯片还包括通信接口,处理器与该通信接口连接。通信接口用于接收需要处理的数据和/或信息,处理器从该通信接口获取该数据和/或信息,并对该数据和/或信息进行处理。该通信接口可以是输入输出接口。
[0407]
以上各实施例中,涉及的处理器910可以例如包括中央处理器(central processing unit,cpu)、微处理器、微控制器或数字信号处理器,还可包括gpu、npu和isp,该处理器还可包括必要的硬件加速器或逻辑处理硬件电路,如特定应用集成电路(application-specific integrated circuit,asic),或一个或多个用于控制本技术技术方案程序执行的集成电路等。此外,处理器可以具有操作一个或多个软件程序的功能,软件程序可以存储在存储器中。
[0408]
存储器可以是只读存储器(read-only memory,rom)、可存储静态信息和指令的其它类型的静态存储设备、随机存取存储器(random access memory,ram)或可存储信息和指令的其它类型的动态存储设备,也可以是电可擦可编程只读存储器(electrically erasable programmable read-only memory,eeprom)、只读光盘(compact disc read-only memory,cd-rom)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其它磁存储设备,或者还可以是能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其它介质等。
[0409]
本技术实施例中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示单独存在a、同时存在a和b、单独存在b的情况。其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项”及其类似表达,是指的这些项中的任意组合,包括单项或复数项的任意组合。例如,a,b和c中的至少一项可以表示:a,b,c,a-b,a-c,b-c,或a-b-c,其中a,b,c可以是单个,也可以是多个。
[0410]
本领域普通技术人员可以意识到,本文中公开的实施例中描述的各单元及算法步骤,能够以电子硬件、计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0411]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0412]
在本技术所提供的几个实施例中,任一功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0413]
以上所述,仅为本技术的具体实施方式,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。本技术的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
