基于改进textrank的知识图谱补全方法和装置
技术领域
1.本技术涉及知识图谱技术领域,特别是涉及一种基于改进textrank的知识图谱补全方法和装置。
背景技术:
2.随着人工智能和大数据技术的发展,知识图谱已经因为其良好的搜索性能和较高的存储质量,成为了数据的主流存储方式,知识图谱往往用三元组(头实体、关系、尾实体)(即(h,r,t))来表示现实世界的事物,结构性好,直观性强。知识图谱作为结构化的显性知识,在语义表示、语义理解、语义推理、智能问答等语义计算任务中发挥着越来越重要的作用。虽然目前知识图谱中实体的数量可达到数十亿的水平,但大多知识图谱仍然相对稀疏,这影响了知识图谱的数据质量和整体结构性,降低知识图谱的应用效率。为了缓和这个问题,知识补全技术成为研究热点。
3.智能问答系统就是基于大量语料数据组成的知识图谱,通过数学模型,通过相关编程语言实现的一个能够和人类进行对话,解决问题的一个软件系统。智能问题系统要求有较高的搜索精度,实现真正的所答即所问。
4.现有知识补全模型欠缺关系和相似实体学习能力、难以处理冗余实体描述信息等问题,导致智能问答过程中搜索结果不够精准,可能会返回一堆相似的页面,还需要搜索者进行筛选,不能很好的实现所答即所问。
技术实现要素:
5.基于此,有必要针对上述问题,提供一种基于改进textrank的知识图谱补全方法和装置。
6.一种基于改进textrank的知识图谱补全方法,所述方法包括:
7.获取智能问答系统知识图谱中多个三元组的头实体和尾实体的文本描述信息,以及头实体与尾实体之间的关系文本。
8.将多个所述三元组作为正样本集,并根据所述正样本采用替换法构造负样本,得到负样本集;将所述正样本集和所述负样本集作为样本集。
9.将样本集中三元组的头实体和尾实体的文本描述信息分别输入到文本摘要层,采用改进textrank方式,利用实体名的覆盖率、句子位置以及句子相似度对句子权重进行调整,根据得到的最终句子权重确定头实体和尾实体的描述摘要,将头实体和尾实体的描述摘要与头实体与尾实体之间的关系文本进行拼接,得到输入序列。
10.将所述输入序列输入到序列编码层中,采用albert编码器对所述输入序列进行特征提取和特征编码,得到具有上下位语义特征的特征矩阵。
11.将所述特征矩阵输入到特征增强层,采用平均池化层和bigru层对所述特征矩阵进行特征增强,得到增强特征矩阵。
12.将所述增强特征矩阵输入到所述多任务微调层中,以链接预测任务为预测任务、
将关系预测任务和相关性排序任务作为训练任务,确定三元组中缺失的另一实体,完成智能问答系统的知识图谱补全任务。
13.一种基于改进textrank的知识图谱补全装置,所述装置包括:
14.数据获取模块,用于获取智能问答系统知识图谱中多个三元组的头实体和尾实体的文本描述信息,以及头实体与尾实体之间的关系文本;将多个所述三元组作为正样本集,并根据所述正样本采用替换法构造负样本,得到负样本集;将所述正样本集和所述负样本集作为样本集。
15.头实体和尾实体的描述摘要抽取模块,用于将样本集中三元组的头实体和尾实体的文本描述信息分别输入到文本摘要层,采用改进textrank方式,利用实体名的覆盖率、句子位置以及句子相似度对句子权重进行调整,根据得到的最终句子权重确定头实体和尾实体的描述摘要,将头实体和尾实体的描述摘要与头实体与尾实体之间的关系文本进行拼接,得到输入序列。
16.特征提取模块,用于将所述输入序列输入到序列编码层中,采用albert编码器对所述输入序列进行特征提取和特征编码,得到具有上下位语义特征的特征矩阵;将所述特征矩阵输入到特征增强层,采用平均池化层和bigru层对所述特征矩阵进行特征增强,得到增强特征矩阵。
17.知识图谱补全模块,将所述增强特征矩阵输入到所述多任务微调层中,以链接预测任务为预测任务、将关系预测任务和相关性排序任务作为训练任务,确定三元组中缺失的另一实体,完成智能问答系统的知识图谱补全任务。
18.上述基于改进textrank的知识图谱补全方法和装置,所述方法包括:获取知识问答系统知识图谱中三元组的头实体和尾实体的文本描述信息,以及头实体与尾实体之间的关系文本;将三元组作为正样本集,根据正样本集采用替换法构造负样本,将所述正样本集和所述负样本集作为样本集,采用改进textrank方式提取样本集中三元组的头实体和尾实体的描述摘要,将头实体和尾实体的描述摘要和实体关系文本拼接后,输入到albert编码器中进行特征提取,得到具有上下位语义特征的特征矩阵;将特征矩阵输入到特征增强层,采用平均池化层和bigru层进行特征增强,得到增强特征矩阵;根据增强特征矩阵采用多任务学习方式,确定三元组中缺失的另一实体,完成智能问答系统知识图谱补全任务。采用本方法对智能问答系统知识图谱进行补全,提高了智能问答过程中搜索结果的精准,实现所答即所问。
附图说明
19.图1为一个实施例中基于改进textrank的知识图谱补全方法的流程图;
20.图2为另一个实施例中基于改进textrank的知识图谱补全方法的网络模型图;
21.图3为另一个实施例中采用改进textrank进行摘要提取步骤的流程图;
22.图4为一个实施例中基于改进textrank的知识图谱补全装置的结构图。
具体实施方式
23.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不
用于限定本技术。
24.基于改进textrank的知识图谱补全方法:multi-task-learning and improved textrank for knowledge graph completion,简称:mit-kgc模型。
25.在一个实施例中,如图1所示,提供了一种基于改进textrank的知识图谱补全方法,该方法包括以下步骤:
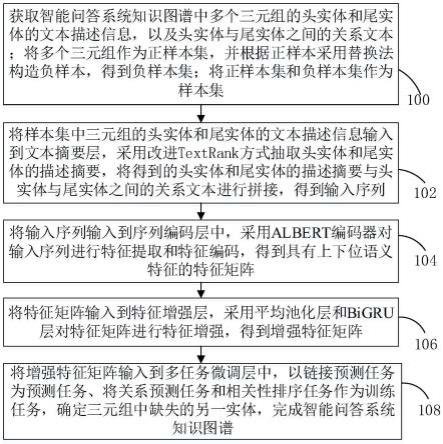
26.步骤100:获取智能问答系统知识图谱中多个三元组的头实体和尾实体的文本描述信息,以及头实体与尾实体之间的关系文本;将多个三元组作为正样本集,并根据正样本采用替换法构造负样本,得到负样本集;将正样本集和负样本集作为样本集。
27.具体的,智能问答系统知识图谱时根据智能问答系统中大量语料数据组成的知识图谱。智能问答系统可以是但不限于旅游景点问答系统、线上医疗问答系统、知识问答系统等。
28.步骤102:将样本集中三元组的头实体和尾实体的文本描述信息分别输入到文本摘要层,采用改进textrank方式,利用实体名的覆盖率、句子位置以及句子相似度对句子权重进行调整,根据得到的最终句子权重确定头实体和尾实体的描述摘要,将头实体和尾实体的描述摘要与头实体与尾实体之间的关系文本进行拼接,得到输入序列。
29.具体的,文本摘要层目的是解决实体描述冗余且大段落的问题,获取精简的关键描述信息。输入序列由特殊标记[cls]和[sep]隔开,作为序列编码层的albert器的输入。
[0030]
实体名的覆盖率计算公式为:
[0031][0032]
其中,we(i)为句子i的实体名的覆盖率,|entityname(seqi)|为句子i所包含的实体名称数量,|seqi|为句子i的单词数。
[0033]
句子位置计算公式为:
[0034][0035]
其中,w
p
(i)为句子位置,i为句子的位置,n为句子数量。
[0036]
将样本集中三元组的头实体和尾实体的文本描述信息分别输入到文本摘要层,采用改进textrank方式,并综合考虑句子位置、句子的相似度、实体的覆盖率等的因素,从而优化最终句子权重;对得到的候选摘要句群进行冗余处理,选取适量排序靠前的句子并根据其在原文中的顺序重新排列得到头实体和尾实体的描述摘要。
[0037]
基于改进textrank的知识图谱补全的网络模型如图2所示。
[0038]
步骤104:将输入序列输入到序列编码层中,采用albert编码器对输入序列进行特征提取和特征编码,得到具有上下位语义特征的特征矩阵。
[0039]
具体的,方案中采用albert编码器目的是从三元组文本提取特征值,编码成具有上下文语义特征的向量矩阵。
[0040]
albert编码器可用于自监督的语言表示学习。albert编码器是在bert模型基础上开发的一种轻量化语言模型,其核心架构与bert相似,但有三点改进:词向量参数分解、跨层参数共享和用sop任务替换nsp任务。本发明使用的albert-xlarge参数量为59m,远小于bert-base的108m,实现了模型的瘦身。在相同的实验上,albert编码器取得了与bert相似
的实验效果,不过减少了bert的参数量,提升了模型运行效率,缩短了运行时间。
[0041]
步骤106:将特征矩阵输入到特征增强层,采用平均池化层和bigru层对特征矩阵进行特征增强,得到增强特征矩阵。
[0042]
具体的,平均池化层的输入为albert编码器输出的具有上下位语义特征的特征矩阵,该层目的在于缓解特征重叠堆积的问题,融合[cls]标签值和其余单词的特征值,计算特征均值,提高编码器的表示能力。
[0043]
bigru由前后两层gru组成,目的是提高模型学习位置关系的能力。
[0044]
步骤108:将增强特征矩阵输入到多任务微调层中,以链接预测任务为预测任务、将关系预测任务和相关性排序任务作为训练任务,确定三元组中缺失的另一实体,完成智能问答系统知识图谱补全任务。
[0045]
具体的,多任务微调层以多任务学习框架(multi-task learning in deep neural networks,简称mtl-dnn)为基础构架的。
[0046]
将bigru输出的增强特征矩阵作为多任务微调层的共享隐层值,同时训练链接预测任务、关系预测任务和相关度排序任务,融合关系与相似实体特征,训练时,先从每个epoch选择minibatch,分别为每种任务计算损失函数,再根据minibatch的随机梯度下降算法优化各个损失函数,达到优化模型的目的,预测缺失的三元组,完成智能问答系统的知识图谱补全任务。
[0047]
上述基于改进textrank的知识图谱补全方法中,所述方法包括:获取知识问答系统知识图谱中三元组的头实体和尾实体的文本描述信息,以及头实体与尾实体之间的关系文本;将三元组作为正样本集,根据正样本集采用替换法构造负样本,将所述正样本集和所述负样本集作为样本集,采用改进textrank方式提取样本集中三元组的头实体和尾实体的描述摘要,将头实体和尾实体的描述摘要和实体关系文本拼接后,输入到albert编码器中进行特征提取,得到具有上下位语义特征的特征矩阵;将特征矩阵输入到特征增强层,采用平均池化层和bigru层进行特征增强,得到增强特征矩阵;根据增强特征矩阵采用多任务学习方式,确定三元组中缺失的另一实体,完成智能问答系统知识图谱补全任务。采用本方法对智能问答系统知识图谱进行补全,提高了智能问答过程中搜索结果的精准,实现所答即所问。。
[0048]
本方法可以克服现有知识补全模型欠缺关系和相似实体学习能力、难以处理冗余实体描述信息等问题。
[0049]
在其中一个实施例中,如图3所示,步骤102包括如下步骤:
[0050]
步骤300:对头实体的文本描述进行分词预处理,得到头实体的多个句子。
[0051]
具体的,首先对文本进行预处理分词,识别n个文本单元(句子)并构成集合,再将文本单元作为图顶点,并且计算句子与句子的相似度作为图的边,构造textrank图模型。
[0052]
步骤302:将头实体的多个句子作为图顶点,并计算不同图顶点之间的相似度,得到相似度矩阵。
[0053]
具体的,文本单元(句子)作为图顶点,并且计算句子与句子的相似度作为图的边,构造textrank图模型。
[0054]
对每个文本单元(句子)进行等同的初始化,之后进行相似度计算。
[0055]
步骤304:根据图顶点和相似度矩阵,构造textrank图模型。
[0056]
步骤306:根据相似度矩阵和textrank图模型,得到句子权重矩阵。
[0057]
步骤308:根据每个句子包含的实体名数量、句子的单词数,得到句子的实体覆盖率矩阵;根据原本实体描述文本段所包含的句子数量和当前句子在段落中的索引,得到句子位置矩阵;根据预设权重值、归一化处理后的实体覆盖率矩阵和句子位置矩阵对所述句子权重矩阵进行修正,得到最终句子权重矩阵。
[0058]
具体的,传统textrank算法只是简单地计算句子间相同单词覆盖率作为边,有如下缺点:1)忽略了实体名的重要性,而我们想要的实体描述往往包含实体名(例如“洛杉矶是美国西部最大城市,坐落于加利福尼亚南部”);2)忽略句子位置的重要性,在一段冗余的实体描述中,往往越靠前的句子越有可能是总结性的描述文本。因此,本发明改进了传统textrank算法,以满足抽取精炼实体描述的需求,利用实体名的覆盖率(计算公式如式(1))和句子位置(计算公式如式(2))对最终的句子权重进行调整。
[0059]
通过实体覆盖率、句子位置计算,得到对应的两个特征矩阵和我们分别归一化得到we和w
p
,并用we和w
p
来调整句子权重矩阵bf,最终句子权重矩阵计算公式如式(3)所示。
[0060]
b=bf·
(αwe βw
p
)
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0061]
其中,b为最终句子权重矩阵,bf为句子权重矩阵
·
表示矩阵点乘,α,β分别为两种特征矩阵的权重,且α β=1,b维度为1
×
n。
[0062]
步骤310:根据最终句子权重矩阵对句子进行排序,权重较高的预设数量个句子作为头实体的摘要描述。
[0063]
具体的,根据句子权重排序,权重较高的x个句子形成摘要,作为优选x=1。
[0064]
步骤312:对尾实体的文本描述信息输入到文本摘要层中,得到尾实体的摘要描述。
[0065]
步骤314:将头实体的摘要描述、尾实体的摘要描述以及头实体与尾实体之间的关系文本进行拼接,得到输入序列。
[0066]
在其中一个实施例中,步骤306包括:设置每个句子的权重初始值为相同的数,其中所有句子的权重之和为1;根据每个句子的权重初始值、相似度矩阵以及textrank图模型,得到句子权重矩阵;句子权重矩阵的元素计算公式为:
[0067][0068]
其中,tr(xi)为第i句的权重值,w
ji
∈sd为第j个顶点到第i个顶点之间的相似度,sd为相似度矩阵,in(x)表示指向句子x的句子集合,out(x)为句子x指向的句子集合,d为阻尼系数。阻尼系数表示某一节点跳转到别的节点的概率,作为优选,阻尼系数为0.85。
[0069]
具体的,相似度矩阵(对称矩阵,由n
×
n个w
ab
组成)。然后,初始化句子权重值为b0=[1/n,1/n,...,1/n],再根据公式(4)进行权重值的迭代,得到句子权重矩阵bf=[tr(x1),tr(x2),...,tr(xn)]。
[0070]
在其中一个实施例中,步骤302中不同图顶点之间的相似度的表达式为:
[0071][0072]
其中,w
ab
为句子a对应的顶点与句子b对应的顶点之间的相似度,seqa和seqb分别代表句子a和句子b,|seqa|、|seqb|分别为句子a和句子b包含的单词数,tk为句子a和句子b中重叠的词汇。
[0073]
在其中一个实施例中,步骤306中最终句子权重矩阵的表达式为:
[0074]
b=bf·
(αwe βw
p
)
t
ꢀꢀꢀꢀꢀꢀꢀ
(6)
[0075]
其中,b为最终句子权重矩阵,b的维度为1
×
n,bf为句子权重矩阵,
·
表示矩阵点乘,α,β分别为两种特征矩阵的权重,且α β=1,we为归一化的实体覆盖率矩阵,w
p
为归一化的句子位置矩阵。
[0076]
在其中一个实施例中,特征增强层包括:平均池化层和bigru层;bigru是在隐层同时有一个正向gru和反向gru,正向gru用于捕获上文的特征信息,反向gru用于捕获下文的特征信息;步骤106包括:将特征矩阵输入到特征增强层的平均池化层中,得到池化特征矩阵;将池化特征矩阵输入到bigru层中,利用正向gru捕获上文的特征信息,利用反向gru捕获下文的特征信息,得到增强特征矩阵。
[0077]
具体的,传统bert以[cls]标签表征序列的思路为:设特征矩阵z在每个维度i(i=1,2,3,...,h)的第一个位置的隐层值h
(i,0)
为[cls]标签值,并以各个维度的[cls]标签值拼接为序列表征向量e'=(h
(1,0)
,h
(2,0)
,...,h
(h,0)
)。本文采用的平均池化策略主要思路为:设特征矩阵z在维度i(i=1,2,3,...,h i=1,2,3,..,h
)的隐层值为h
i,j
(j=1,2,3,...,l),计算h
i,j
的均值拼接每个维度的组成新特征矩阵值计算如式(7)所示,新特征矩阵如式(8)所示。
[0078][0079][0080]
bigru由前后两层gru组成,目的是提高模型学习位置关系的能力。gru利用更新门控制当前时刻t对前一时刻t-1的信息接收程度,并通过重置门控制对前一时刻t-1的信息忽略程度。bigru的输入是平均池化层的输出特征向量在每个t位置的分量e
t
,在t时刻的主要工作流程如下:1)首先拼接e
t
和上一个gru网络的隐层值h
t-1
,计算重置门系数r
t
∈[0,1],选择性地遗忘上一个gru网络的隐层值h
t-1
,更新到候选隐层值中,如式(9)和(10)所示;2)再计算更新门系数z
t
∈[0,1],选择e
t
和h
t-1
的重要信息,利用z
t
有选择地更新隐层值h
t
,如式(11)和(12)所示;3)经过对隐层值的更新,最终得到特征增强层的输出,即维度为l
×
h的增强特征矩阵如式(13)所示。
[0081]rt
=σ(h
t-1
wr e
t
wr br)
ꢀꢀꢀꢀꢀꢀꢀ
(9)
[0082][0083]zt
=σ(h
t-1
wz e
t
wz bz)
ꢀꢀꢀꢀꢀ
(11)
[0084][0085]
e=(h1,h2,...,h
t
,...,hh)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0086]
其中wr、wz为权重矩阵,br、bz为偏置向量,
⊙
表示矩阵元素相乘。
[0087]
在其中一个实施例中,链接预测任务包括全连接层和softmax激活函数、关系预测任务包括全连接层和softmax激活函数;相关性排序任务包括全连接层和sigmoid激活函数;步骤108包括:将性增强特征矩阵输入到链接预测任务的全连接层中,将得到的输出结果采用softmax函数激活后,得到链接预测得分,根据链接预测得分采用二进制交叉熵损失函数计算链接预测任务的损失函数,通过梯度下降算法优化链接预测任务的参数,得到最优链接预测结果;将性增强特征矩阵输入到关系预测任务的全连接层中,将得到的输出结果采用softmax函数激活后,得到关系预测得分,根据关系预测得分采用交叉熵损失函数,确定关系预测任务的损失函数,通过梯度下降算法优化关系预测任务的参数,得到最优关系预测结果;将性增强特征矩阵输入到相关性排序任务的全连接层中,将得到的输出结果采用sigmoid函数激活后,得到相关性排序任务得分,根据关系预测得分采用边际损失函数,确定相关性排序任务的损失函数,通过梯度下降算法优化相关性排序任务的参数,得到最优相关性排序结果;根据最优链接预测结果、最优关系预测结果以及最优相关性排序结果,确定三元组中缺失的另一实体,完成智能问答系统知识图谱补全任务。
[0088]
具体的,本发明将链接预测任务看作二分类任务,合理正确的三元组得分应较高。链接预测任务目的是给定一个实体和关系(h,r,?)或(?,r,t),预测缺失的另一实体。模型得分函数设置为s
lp
,如式(14)所示,然后通过梯度下降算法优化模型的链接预测参数。由于数据集中的三元组都是事实,这些事实组成真样本集因此需要采用替换法构造负样本如公式(15)所示。从而给定正负样本集和计算链接预测任务的二进制交叉熵损失函数如式(16)所示。
[0089]slp
=softmax(ew
lp
)
ꢀꢀꢀꢀꢀꢀ
(14)
[0090][0091][0092]
其中,是链接预测分类层参数矩阵,s
lp
是一个二维向量,由两部分s
lp1
,s
lp2
∈[0,1]组成,代表三元组t属于两种标签的概率得分,且s
lp1
s
lp2
=1,y
t
∈{0,1}为三元组t的标签(负样本或正样本)。
[0093]
关系预测任务目的是给定两个实体(h,?,t),预测缺失的关系,从而融入关系信息。关系预测遮盖关系,训练模型依据实体预测遮盖的关系的能力,以此来学习关系特征。关系预测实质为分类任务,正确的关系得分较高,并优化交叉熵损失函数。关系预测得分函数s
rp
如式(17)所示,损失函数如式(18)所示。
[0094]srp
=softmax(ew
rp
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0095][0096]
其中是关系预测分类层参数矩阵,r是数据集中关系的个数,yr为关系标
签。
[0097]
负样本由手工替代正样本实体得到,因此得分应比正样本低,相关性排名目的是给予正确实体更高的得分,训练模型区分合理实体和非合理实体,从而克服相似实体带来的影响。相关性排序任务得分函数s
rr
使用sigmoid函数,如式(19)所示,使用的损失函数不同于以上两个任务,为了优化不同实体的距离采用边际损失函数(margin ranking loss),如式(20)所示。
[0098]srr
=sigmoid(ew
rr
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)
[0099][0100]
其中,是相关性排序任务参数矩阵,s
rr
′
代表负样本得分函数,λ是损失函数中的边际。
[0101]
应该理解的是,虽然图1的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
[0102]
在一个验证性实施例中,本实施例中所用数据集是fb15k-237和wn18rr,这两个数据集是现在最流行的两个知识补全数据集。wn18rr是来自于wordnet的子集,包含英文的三元组数据和实体描述信息。fb15k-237是freebase的子集,它包含的英文实体关系以及描述文本比wn18rr更加复杂。表1为数据集的统计信息。
[0103]
表2数据集统计信息
[0104][0105]
(1)基线模型
[0106]
本实施例中基线模型包括:基于预训练语言模型的知识补全模型和传统知识补全模型两大类,基于预训练语言模型的知识补全模型包括:基于多任务学习双向语言编码器的知识补全模型(mtlbert)、基于自回归语言理解方法的知识补全模型(kg-xlnet)、基于双向语言编码器的知识表示模型(kg-bert),传统知识补全模型包括:基于距离嵌入的知识表示模型(dense)、关系图卷积神经网络(r-gcn)、基于关系旋转的知识嵌入模型(rotate)、基于卷积神经网络的知识嵌入模型(conve)、基于复空间的知识嵌入模型(complex)、基于双线性方法的知识嵌入模型(distmult)、基于翻译的知识嵌入模型(transe)。
[0107]
(2)实验设置
[0108]
本实施例选用albert-xlarge作为编码器,fb15k-237最大句子长度为128,wn18rr最大句子长度为76,minibatch大小设置为32,优化器选用adam,训练epoch为5,学习率为5e-5,相关性排序任务损失函数的margin设置为0.1。
[0109]
(3)实验任务与评估指标
[0110]
本实验任务为链接预测,链接预测的主要评估指标为平均排名(mean rank,mr)和前k命中率(hit@k)。mr指目标三元组的平均排名,此指标越小代表模型性能越好;hit@k指目标三元组排名在前k名的比率,此指标越大代表模型性能越好。实验排除了替换后的其余正确三元组对目标三元组排名的影响,使用filtered mean rank和filtered hits@k指标,分别表示删去了其他正确三元组后目标三元组的平均排名和删去了其他正确三元组后目标三元组在前k个三元组中出现的概率。
[0111]
(4)链接预测实验
[0112]
模型在数据集fb15k-237以及wn18rr上的链接预测实验如表2所示。
[0113]
表2链接预测实验结果
[0114][0115]
实验结果表明,mit-kgc模型在大多数指标上有所改善。在fb15k-237数据集上,mr、hit@10、hit@3分别提升31、1.2%、0.7%,其中mr提升明显,原因可能在于fb15k-237关系多且复杂,多任务学习可以有效学习这些关系,而且fb15k-237实体描述文本较长,摘要技术会避免冗余的描述文本,提升了模型预测正确实体的能力;在wn18rr数据集上,mr、hit@10、hit@3分别提升37、14.2%、3.7%,其中hit@10提升明显,可能是因为wn18rr实体较多,伴随着相似实体也较多,多任务学习可以加强模型分辨相似实体的能力,提高正确实体得分。虽然hit@1指标没有达到最优,原因可能是预训练语言模型主要从语义层面建模,缺乏三元组的结构性特征,相比传统知识补全模型,难以将正确目标预测为第一名,但总体而言,mit-kgc取得了进步。
[0116]
(5)消融实验
[0117]
1)训练任务组合策略实验
[0118]
为了分析多任务学习框架中每个训练任务的影响,我们设置了不同训练任务组合的消融实验。实验结果如表4所示。
[0119]
表4不同训练任务实验结果
[0120][0121]
链接预测任务:lp;关系预测任务:rp;相关性排序任务:rr。
[0122]
从实验结果可知,本文采用的“lp rp rr”任务策略取得的效果最好。在数据集wn18rr上,“lp rp rr”任务策略相比单独的lp训练,mr、hit@10、hit@3、hit@1上分别提升34.9、10.9%、10%、9.4%,说明加多任务学习策略对实验结果有益,提升了总体模型性能。而从“lp rp”和“lp rr”任务策略的实验结果分析,前者相比于lp任务提升8.2、2.5%、5.7%、4.1%,后者提升31.1、9.5%、9.2%、7.2%,说明加入的rr和rp是有效的,并且我们可以发现rr任务带来的提升更加明显,说明原本的训练模式存在无法分辨相似实体的情况,造成正确实体得分较低,而rr任务可以有效缓解这种问题,提升了预测的准确性。
[0123]
2)编码器分析实验
[0124]
为了对比不同编码器的实验效果和运行效率,设计了以bert为编码器的另一种模型,具体来说是bert-xlarge和bert-large,并且将这两种编码器与albert-xlarge和albert-large对比,几种编码器的主要参数如表5所示。在数据集wn18rr上,链接预测实验结果与运行速度如表6所示,其中运行速度通过训练时间的倒数计算,以bert-xlarge为基准。
[0125]
表5不同编码器参数
[0126][0127]
表6不同编码器实验结果
[0128][0129]
从实验结果可知,albert-xlarge在mr、hit@10、hit@3、hit@1上分别提升12.8、
6.4%、2.9%、2.1%,并且速度达到bert-xlarge的2.1倍。得益于词向量参数分解以及层级参数共享,albert-xlarge减少了模型参数,增加了数据吞吐量,因此获得了速度的提升;同时,在相同隐层大小情况下,albert-xlarge通过词向量参数分解保持嵌入大小不变,从而提升模型预测性能。从模型速度看,albert-large的运行速度最快,但测试结果不是最佳,甚至比bert-large差,而albert-xlarge虽然速度不是最快,但是性能提升明显,综合考虑时间成本和预测准确率,本文采用的albert-xlarge兼顾了实验结果与运行速度,是合理有效的。
[0130]
3)文本摘要分析实验
[0131]
从实验结果、摘要示例和文本长度变化三个方面完成了对改进textrank的分析实验。
[0132]
首先,如表7所示,mit-kgc在没有改进textrank的时候,在mr、hit@10、hit@3、hit@1指标上分别下降了12.7、3.7%、0.2%、5.9%,表明了改进textrank对实验效果是正相关的,文本摘要技术的丢失会对模式预测能力造成负面影响。
[0133]
表8展示了使用改进textrank之后实体描述的长度变化。我们分别分析了两个数据集的文本描述长度变化,fb15k-237数据集在经历改进textrank算法处理后,实体描述的平均长度(字符数)下降692.3(80.1%),而wn18rr下降25.1(28.0%),说明了文本摘要算法大幅度降低了描述文本的冗余性,提高了实体描述质量,而fb15k-237由于其更复杂更冗余的文本描述,因此长度下降更加明显。
[0134]
表7改进textrank消融实验
[0135][0136]
表8改进textrank对描述文本长度的影响
[0137][0138]
4)特征增强组件分析实验
[0139]
除了上述实验,本实施例还对mit-kgc的特征增强组件(bigru、(平均池化)mean-pooling)进行了消融实验,来探索特征增强对模型的作用,如表9所示。
[0140]
表9特征增强组件实验结果
[0141][0142]
观察每个组件去除后的实验结果变化,判断每个组件对整个模型的影响。消除bigru后,模型在mr、hit@10、hit@3、hit@1指标上下降了31.1、5.2%、7.3%、4.4%;消除
mean-pooling后,指标下降39.3、9.7%、12.2%、12.3%。我们发现,bigru和mean-pooling的消除,对模型都产生了负面影响,也就是说,特征增强层是有一定效果的。其中,消除bigru后影响较小,而消除mean-pooling后影响较大,说明mean-pooling增强了编码特征,改善了albert的编码能力,对模型的帮助更加明显。
[0143]
在一个实施例中,如图4所示,提供了一种基于改进textrank的知识图谱补全装置,包括:数据获取模块、头实体和尾实体的描述摘要抽取模块、特征提取模块和知识图谱补全模块,其中:
[0144]
数据获取模块,用于获取智能问答系统知识图谱中多个三元组的头实体和尾实体的文本描述信息,以及头实体与尾实体之间的关系文本;将多个三元组作为正样本集,并根据正样本采用替换法构造负样本,得到负样本集;将正样本集和负样本集作为样本集。
[0145]
头实体和尾实体的描述摘要抽取模块,用于将样本集中三元组的头实体和尾实体的文本描述信息分别输入到文本摘要层,采用改进textrank方式,利用实体名的覆盖率和句子位置对最终句子权重进行调整,根据最终句子权重确定头实体和尾实体的描述摘要,将头实体和尾实体的描述摘要与头实体与尾实体之间的关系文本进行拼接,得到输入序列。
[0146]
特征提取模块,用于将输入序列输入到序列编码层中,采用albert编码器对输入序列进行特征提取和特征编码,得到具有上下位语义特征的特征矩阵;将特征矩阵输入到特征增强层,采用平均池化层和bigru层对特征矩阵进行特征增强,得到增强特征矩阵。
[0147]
具体的,albert编码器主要组成部分是transformer中的encoder,采用多个相同的网络层结构堆叠而成,每个网络层由多头自注意力机制层和前馈网络层两个子网络层组成,两者采用残差网络模块进行连接。其中,多头自注意力机制层计算字词的相互关系,前馈网络层融合字词的位置信息,add&norm层将该网络层的输入和输出相加并进行归一化处理。多头自注意力机制是其中最重要的组成模块,输入的文本序列中每个词的query、key和value组成输入向量q、k、v,利用多头注意力机制将多个网络层的输出矩阵拼接成一大的词向量矩阵。
[0148][0149]
head
t
=a(qw
tq
,kw
tk
,vw
tv
),t∈(1,2,3,...,h)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0150]
multihead(q,k,v)=concat(head1,head2,...,headh)wmꢀꢀꢀ
(23)
[0151]
其中,w
tq
、w
tk
、w
tv
为权重矩阵,d
t
为qkv维度,wm为附加权重矩阵。
[0152]
通过注意力机制,albert编码器计算每个字词与所有字词的相互关系,并调整每个字词在句子中的权重,根据权重获得新的向量表达,从而得到融合上下文语义特征的特征矩阵,再将计算得到的特征矩阵传递到下一层中。
[0153]
知识图谱补全模块,将增强特征矩阵输入到多任务微调层中,以链接预测任务为预测任务、将关系预测任务和相关性排序任务作为训练任务,确定三元组中缺失的另一实体,完成智能问答系统知识图谱补全任务。
[0154]
在其中一个实施例中,头实体和尾实体的描述摘要抽取模块,还用于对头实体的文本描述进行分词预处理,得到头实体的多个句子;将头实体的多个句子作为图顶点,并计算不同图顶点之间的相似度,得到相似度矩阵;根据图顶点和相似度矩阵,构造textrank图
模型;根据相似度矩阵和textrank图模型,得到句子权重矩阵;根据每个句子包含的实体名数量、句子的单词数,得到句子的实体覆盖率矩阵;根据原本实体描述文本段所包含的句子数量和当前句子在段落中的索引,得到句子位置矩阵;根据预设权重值、归一化处理后的实体覆盖率矩阵和句子位置矩阵对所述句子权重矩阵进行修正,得到最终句子权重矩阵;根据最终句子权重矩阵对句子进行排序,权重较高的预设数量个句子作为头实体的摘要描述;对尾实体的文本描述信息输入到文本摘要层中,得到尾实体的摘要描述;将头实体的摘要描述、尾实体的摘要描述以及头实体与尾实体之间的关系文本进行拼接,得到输入序列。
[0155]
在其中一个实施例中,头实体和尾实体的描述摘要抽取模块,还用于设置每个句子的权重初始值为相同的数,其中所有句子的权重之和为1;根据每个句子的权重初始值、相似度矩阵以及textrank图模型,得到句子权重矩阵;句子权重矩阵的元素计算公式如式(4)所示
[0156]
在其中一个实施例中,头实体和尾实体的描述摘要抽取模块中不同图顶点之间的相似度的表达式如式(5)所示。
[0157]
在其中一个实施例中,头实体和尾实体的描述摘要抽取模块中最终句子权重矩阵的表达式如式(6)所示。
[0158]
在其中一个实施例中,特征增强层包括:平均池化层和bigru层;bigru是在隐层同时有一个正向gru和反向gru,正向gru用于捕获上文的特征信息,反向gru用于捕获下文的特征信息;特征提取模块,还用于将特征矩阵输入到特征增强层的平均池化层中,得到池化特征矩阵;将池化特征矩阵输入到bigru层中,利用正向gru捕获上文的特征信息,利用反向gru捕获下文的特征信息,得到增强特征矩阵。
[0159]
在其中一个实施例中,链接预测任务包括全连接层和softmax激活函数、关系预测任务包括全连接层和softmax激活函数;相关性排序任务包括全连接层和sigmoid激活函数;知识图谱补全模块,还用于将性增强特征矩阵输入到链接预测任务的全连接层中,将得到的输出结果采用softmax函数激活后,得到链接预测得分,根据链接预测得分采用二进制交叉熵损失函数计算链接预测任务的损失函数,通过梯度下降算法优化链接预测任务的参数,得到最优链接预测结果;将性增强特征矩阵输入到关系预测任务的全连接层中,将得到的输出结果采用softmax函数激活后,得到关系预测得分,根据关系预测得分采用交叉熵损失函数,确定关系预测任务的损失函数,通过梯度下降算法优化关系预测任务的参数,得到最优关系预测结果;将性增强特征矩阵输入到相关性排序任务的全连接层中,将得到的输出结果采用sigmoid函数激活后,得到相关性排序任务得分,根据关系预测得分采用边际损失函数,确定相关性排序任务的损失函数,通过梯度下降算法优化相关性排序任务的参数,得到最优相关性排序结果;根据最优链接预测结果、最优关系预测结果以及最优相关性排序结果,确定三元组中缺失的另一实体,完成智能问答系统知识图谱补全任务。
[0160]
关于基于改进textrank的知识图谱补全装置的具体限定可以参见上文中对于基于改进textrank的知识图谱补全方法的限定,在此不再赘述。上述基于改进textrank的知识图谱补全装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0161]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例
中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0162]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。