1.本发明属于数据挖掘和推荐系统技术领域,更具体地,涉及一种基于社交时空信息与用户偏好的连续兴趣点推荐方法及系统。
背景技术:
2.互联网经历了半个多世纪的发展,规模也变得空前巨大,这些海量的数据增加了用户获取感兴趣信息的时间开销,造成信息过载问题。为了提高信息的使用率,也为了商家更有效地提供个性化推荐服务,推荐系统技术应运而生,实现用户与商家之间的共赢。
3.兴趣点(point-of-interest,poi)在基于位置的社交网络(location based social networks,lbsn)中代表的是一个真实的地点信息,例如商场、学校。现有技术中通常采用连续兴趣点推荐,连续兴趣点具有较强的时间和空间性质,即根据用户过去签到的记录信息,来预测当前状态下用户可能的选择,同时由于签到需要用户亲自前往该地点,因此不同距离也影响着用户的选择,连续兴趣点推荐具备时空特性。
4.目前针对连续兴趣点的推荐,仍然存在以下的问题:由于用户和兴趣点的数量随着lbsn的规模扩大而增加,导致的签到数据稀疏性问题;只考虑其中一或两种元信息,忽视了其他的元信息,造成信息的考虑的遗漏,元信息利用广度不足的问题;对于一个加入lbsn不久的新用户,在没有社交网络数据的签到记录时,造成的冷用户推荐不准确的问题。
技术实现要素:
5.针对现有技术的以上缺陷或改进需求,本发明提供了一种基于社交时空信息与用户偏好的连续兴趣点推荐方法及系统,其目的在于解决签到数据稀疏性,元信息利用广度不足和冷用户推荐不准确的技术问题。
6.为实现上述目的,按照本发明的一个方面,提供了一种基于社交时空信息与用户偏好的连续兴趣点推荐方法,包括:
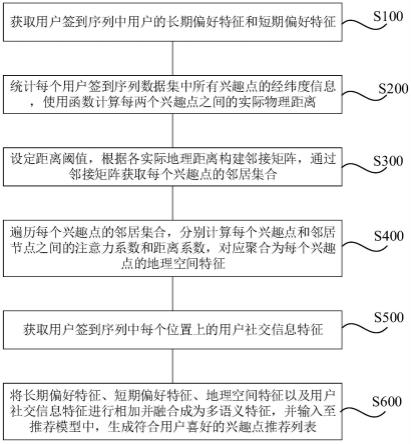
7.获取用户签到序列中用户的长期偏好特征和短期偏好特征;
8.统计每个用户签到序列数据集中所有兴趣点的经纬度信息,使用haversine函数计算每两个兴趣点之间的实际物理距离;
9.设定距离阈值,根据各所述实际地理距离构建邻接矩阵,通过邻接矩阵获取每个兴趣点的邻居集合;
10.遍历每个兴趣点的邻居集合,分别计算每个兴趣点和邻居节点之间的注意力系数和距离系数,对应聚合为每个兴趣点的地理空间特征;
11.获取所述用户签到序列中每个位置上的用户社交信息特征;
12.将所述长期偏好特征、所述短期偏好特征、所述地理空间特征以及所述用户社交信息特征进行相加融合成为多语义特征,并输入至推荐模型中,生成符合用户喜好的兴趣点推荐列表。
13.可选的,所述获取用户签到序列中用户的长期偏好特征和短期偏好特征,包括:
14.通过多头注意力机制对输入的所述用户签到序列进行特征提取,从多个子空间学习到用户的长期偏好特征;
15.通过循环神经网络rnn对输入的所述用户签到序列进行特征提取,对用户的近期签到行为进行建模,学习到用户的短期偏好特征。
16.可选的,所述遍历每个兴趣点的邻居集合,分别计算每个兴趣点和邻居节点之间的注意力系数和距离系数,对应聚合为每个兴趣点的地理空间特征,包括:
17.获取目标兴趣点的初始特征以及目标兴趣点的邻居集合;
18.从所述邻居集合中依次获取一个兴趣点,依次计算获取的兴趣点与目标兴趣点之间的注意力系数:其中,s
ij
为注意力打分机制,通过打分函数计算两点之间的相关性,得出一个分数,再使用softmax对分数进行归一化;a(
·
,
·
)表示的相似度计算函数,w表示可训练的参数矩阵,hj是节点j的特征;表示的是兴趣点i的邻居兴趣点集合;
19.依次计算获取的兴趣点与目标兴趣点之间的距离系数:依次计算获取的兴趣点与目标兴趣点之间的距离系数:其中,d(i,j)表示的是两个兴趣点之间的距离;
20.根据每次计算得到的所述注意力系数和所述距离系数更新目标兴趣点的特征:
21.遍历所述邻居集合后,根据目标兴趣点的位置信息,构造所述目标兴趣点的地理空间特征向量;并构造每个兴趣点的地理空间特征
22.可选的,所述获取所述用户签到序列中每个位置上的用户社交信息特征,包括:
23.根据不同用户的兴趣信息之间的偏好关联关系,构建社交网络图;
24.通过所述社交网络图获取用户的相似矩阵;
25.根据所述相似矩阵获取对应的邻居用户集,并采用随机邻居采样算法从所述邻居用户集中进行特征提取;
26.将提取的特征增加至目标用户,构成用户社交信息特征。
27.可选的,所述偏好关联关系采用类杰卡德相似度表示;
28.所述类杰卡德相似度公式为:若所述类杰卡德相似度大于用户相似度阈值δ,则判断对应的两个用户之间存在偏好关联。
29.可选的,所述将所述长期偏好特征、所述短期偏好特征、所述地理空间特征以及所述用户社交信息特征进行相加融合成为多语义特征,并输入至推荐模型中,生成符合用户喜好的兴趣点推荐列表,包括:
30.将所述长期偏好特征、所述短期偏好特征、所述地理空间特征以及所述用户社交信息特征的特征向量信息进行拼接,生成兴趣点元数据;
31.基于所述兴趣点元数据计算下一个兴趣点的候选集的概率分布;
32.选取候选集中概率最大的前k个作为用户喜好的兴趣点推荐列表。
33.可选的,所述兴趣点的候选集包括类别候选集和地点候选集。
34.可选的,在所述获取用户签到序列中用户的长期偏好特征和短期偏好特征之前,还包括:
35.将用户签到序列中多模态的标量信息转化为低维稠密的多模态的特征向量信息。
36.按照本发明的另一方面,提供了一种基于社交时空信息与用户偏好的连续兴趣点推荐系统,包括:
37.用户偏好追踪模块,利用循环神经网络rnn和多头注意力机制来对用户历史签到序列进行分析处理,获取用户签到序列中用户的长期偏好特征和短期偏好特征;
38.地理距离感知模块,利用图神经网络gnn获取所述用户签到序列中每个位置上的地理空间特征;
39.社交信息影响模块,使用随机邻居采样算法来从用户的社交网络图中进行特征提取,获取所述用户签到序列中每个位置上的用户社交信息特征;
40.候选集预测模块,用于根据所述用户偏好追踪模块、所述地理距离感知模块以及所述社交信息影响模块所获得的特征信息,进行相加融合成为多语义特征,并输入至推荐模型中,生成符合用户喜好的兴趣点推荐列表。
41.总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
42.1、对用户签到序列进行了层次化特征提取,全面地学习用户的行为特点;结合多种特性信息,形成多语义特征,丰富和增强特征表达上下文语义信息的能力,解决签到数据稀疏性的问题和元信息利用广度不足的问题,更有利于模型学习到用户的兴趣偏好、社交信息等分布特点。
43.2、通过构建用户的每个兴趣点的邻居集合,获取兴趣点的地理空间特征,即时空状态信息;在构建邻居集合时添加距离注意力系数,能够使得不同兴趣点之间的距离关系更加显著,也更符合兴趣点推荐的空间语义。
44.3、在构建用户社交信息特征时,通过随机邻居采样算法来构建特征,随机采样的方式可以模拟用户偏好在社交网络中的传播,同时也可以将相似用户的偏好特征进行吸收,从而增强用户的特征表达;建立的社交网络图和随机邻居采样算法可以解决冷用户启动推荐的问题。
45.4、将众多影响因素与特征融合到了一个多语义特征,使用推荐模型进行推荐时,可以利用各个部分特征的信息,使得连续兴趣点推荐具备时空特性,提高推荐效果。
附图说明
46.图1为本发明实施例一公开的一种基于社交时空信息与用户偏好的连续兴趣点推荐方法的流程示意图;
47.图2为本发明实施例一公开的用户签到序列结构的组成示例图;
48.图3为本发明实施例一公开的一种兴趣点距离关系示例图;
49.图4为本发明实施例一公开的随机采样策略的示例图;
50.图5为本发明实施例二公开的一种基于社交时空信息与用户偏好的连续兴趣点推荐系统的结构示意图。
具体实施方式
51.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
52.实施例一
53.如图1所示,一种基于社交时空信息与用户偏好的连续兴趣点推荐方法,包括:
54.s100、获取用户签到序列中用户的长期偏好特征和短期偏好特征;
55.s200、统计了每个用户签到序列数据集中所有兴趣点的经纬度信息,使用haversine函数计算每两个兴趣点之间的实际物理距离;
56.s300、设定距离阈值,根据每个兴趣点之间的实际地理距离关系构建邻接矩阵,通过邻接矩阵获取每个兴趣点的邻居集合;
57.s400、遍历每个兴趣点的邻居集合,分别计算每个兴趣点和邻居节点之间的注意力系数和距离系数,对应聚合为目标兴趣点的地理空间特征。
58.s500、获取用户签到序列中每个位置上的用户社交信息特征;
59.s600、将长期偏好特征、短期偏好特征、地理空间特征以及用户社交信息特征进行相加融合成为多语义特征,并输入至推荐模型中,生成符合用户喜好的兴趣点推荐列表。
60.可选的,s100之前,还包括:
61.将用户签到序列中多模态的标量信息转化为低维稠密的多模态的特征向量信息。
62.如图2所示,构建用户签到序列,单个签到记录可以表示为长度为n的用户签到记录数学形式可以表示为:
[0063][0064]
其中,表示用户ui的签到序列中第j个记录,ui、lj、t
τ
、ck分别表示用户、poi、时间区间、poi类别的编号id,时间戳t
τ
严格按照从小到大进行排序。
[0065]
户签到序列中包含多模态的标量信息,需要将这些标量信息处理为向量信息。多模态特征嵌入聚合模块将这些多模态的标量编号信息通过嵌入层映射到低维稠密向量中去,具体的实现是为每一个模态都创建一个二维嵌入矩阵,示例性的,用户、兴趣点、时间区间、类别等信息的嵌入矩阵分别为:mu、m
p
、m
t
、mc。然后根据对应的模态标量信息从嵌入矩阵对应的下标中获取低维稠密向量表示:
[0066]
[0067]
其中,ui、lj、t
τ
、ck分别表示用户、poi、时间区间、poi类别的编号id,embedding(
·
)表示嵌入层,内嵌对应的矩阵信息,通过标量获取对应的特征向量。分别表示用户、兴趣点、时间区间和兴趣点类别的特征向量,d表示的是特征向量的维度大小。多模态特征嵌入聚合模块具体包括:1)用户编号嵌入层,用于将用户编号标量处理成特征向量;2)兴趣点编号嵌入层,用于将兴趣点编号标量处理成特征向量;3)时间戳区间编号嵌入层,用于将时间戳区间编号标量处理成特征向量;4)兴趣点类别编号嵌入层,用于将兴趣点类别编号标量处理成特征向量。
[0068]
将用户签到序列中多模态的标量信息转化为低维稠密的多模态的特征向量信息之后,再对用户签到序列中的长期偏好特征、短期偏好特征、地理空间特征以及用户社交信息特征进行了层次化特征提取,便于更加全面地学习用户行为特点,同时通过统计分析对层次化提供了论证。
[0069]
然后将长期偏好特征、短期偏好特征、地理空间特征以及用户社交信息特征进行相加融合成为多语义特征,多特征按一定规则进行拼接,达到多模态特征嵌入聚合的目的,同时丰富用户个人信息,增加特征向量的表达能力。再将多语义特征输入至推荐模型中,即可生成符合用户喜好的兴趣点推荐列表。
[0070]
可选的,s100具体包括:
[0071]
s110、通过多头注意力机制对输入的用户签到序列进行特征提取,从多个子空间学习到用户的长期偏好特征;
[0072]
s120、通过循环神经网络rnn对输入的用户签到序列进行特征提取,重点对用户的近期签到行为进行建模,学习到用户的短期偏好特征。
[0073]
用户的签到记录数据具有层次化的特点,反映了用户长期和短期的偏好变化。例如,用户的签到行为往往具备周期性,在相似的时间段内用户很可能会做同一件事,时间较近的记录数据体现了用户近期的签到行为,可以从中分析出短期偏好;而时间较远的记录数据则反馈了用户潜在的签到意向,可以从中分析长期偏好。
[0074]
对于用户ui长度为l的长期历史签到序列通过多模态特征嵌入聚合模块进行处理,并得到长期历史序列的多模态嵌入表示然后使用多头自注意力机制进行建模,如下所示:
[0075][0076][0077][0078]
其中,表示长期历史签到序列通过多模态特征嵌入聚合模块对应的潜在表示,|l|表示长期签到序列的长度,表示长期历史特征在第j个子空间下通过自注意力机制学习到的特征,h表示多头注意力机制子空间的个数,表示拼接符号,表示h个子空间的长期历史特征的综合特征。
[0079]
采用多头注意力机制对输入的长期签到序列进行特征提取,从多个子空间学习到用户的长期偏好特征,使得提取的长期特征不随着时间的推移而发生显著改变,保留了用户长久以来的潜在签到行为特点。并且,注意力机制能够发掘签到序列中不相邻的记录之间的关系,同时多头机制可以从不同角度对用户的长期特征进行建模,从而达到更好提取效果。
[0080]
对于用户ui长度为s的短期当前签到序列通过多模态特征嵌入聚合模块进行处理,可以得到短期当期序列的多模态嵌入表示本实施例中采用循环神经网络rnn中的gru模型进行建模,如下所示:
[0081][0082][0083]
其中,表示短期当前签到序列通过多模态特征嵌入聚合模块对应的潜在表示,|s|表示短期签到序列的长度,gru(
·
)表示gru模型,而ps表示的是最终的短期当前偏好特征向量。和分别表示初始和最终的隐藏状态。
[0084]
使用门控循环单元gru对输入的近期签到序列进行建模和特征提取,gru能够发掘签到记录中用户的周期行为,从而对用户最近一段时间内的签到偏好进行建模,学习到用户的短期偏好特征,具有显著的周期性和时效性,反映用户最近一段时间的签到行为特点。
[0085]
为了方便起见,对于长期和短期序列均取相同的长度,即|l|=|s|=n,接着下一步对输入序列进行长期历史特征和短期偏好特征的捕捉,分别得到其长期特征和短期特征并且将其融合成最终的偏好特征表示并且将其融合成最终的偏好特征表示
[0086]
在本实施例中,通过分别对用户长期签到序列和用户短期签到序列进行层次化建模和特征提取,能够更有效地学习到用户隐藏在签到记录中的偏好特征,更加全面地学习用户行为特点,有利于模型更好地捕捉特征信息。
[0087]
获取用户签到序列中每个位置上的地理空间特征,具体包括:s200、s300、s400三个步骤。
[0088]
用户对下一个签到地点的选择受到其距离远近的影响,比起距离更远的地点,用户倾向于选择近的地点作为下一个选择。距离信息需要从每个不同兴趣点之间的距离进行体现,如图3所示,a节点代表当前位置,而b节点代表用户最可能前往的地点,c节点为用户前往可能性较小的地方,用户可能前往的地点与距离相关,如图3所示,以a节点为圆心,在一定半径形成的圆形范围a内,存在的兴趣点均为下一次选择的兴趣点。在研究用户的兴趣点的地理空间特征时,需要构建用户的兴趣点邻接图。
[0089]
兴趣点(point-of-interest,poi)邻接图即为“poi—poi”邻接图,其描述了两个不同poi之间的距离关联关系:
[0090]gg
=《vg,eg,ag》
[0091]
其中,vg表示邻接图中的poi节点信息,eg表示的是不同poi节点之间的边信息。poi节点的边关系来源于相互之间的距离关系,首先统计了每个数据集中所有poi的经纬度信
息,然后根据每对poi之间的经纬度信息计算它们之间的实际物理距离,使用haversine函数进行计算两点之间的距离;设置一个距离阈值d
δ
,当两个poi之间的实际地理距离小于等于d
δ
时,表明两个poi之间具有关联,则在两个poi节点上新增一条边。例如poi节点li和poi节点lj之间的距离小于d
δ
,则在图gg的边集合eg中新增一条双向边ε
ij
∈eg。ag则表示的是每个节点的特征集合,即与vg中的poi节点一一对应,其中aj=《lj,ck》,lj和ck表示地点及其类别。
[0092]
根据与目标兴趣点i距离小于d
δ
的兴趣点构建邻接矩阵wg,再根据邻接矩阵wg构建每个poi节点i的邻居集合引入了距离度量相似度β,用来计算两个兴趣点的距离上的相似度。随着距离的增大,距离相似度也随着减小。遍历目标兴趣点的邻居集合,计算目标兴趣点i和邻居节点之间的注意力系数和距离系数,聚合为目标兴趣点i的地理空间特征。遍历所有兴趣点后,构建每个兴趣点的地理空间特征。
[0093]
可选的,s400具体包括:
[0094]
s410、获取目标兴趣点的初始特征以及目标兴趣点的邻居集合;
[0095]
s420、从邻居集合中依次获取一个兴趣点,依次计算获取的兴趣点与目标兴趣点之间的注意力系数:其中,s
ij
为注意力打分机制,通过打分函数计算两点之间的相关性,得出一个分数,再使用softmax对分数进行归一化;a(
·
,
·
)表示的相似度计算函数,w表示可训练的参数矩阵,hj是节点j的特征;表示的是兴趣点i的邻居兴趣点集合;
[0096]
s430、依次计算获取的兴趣点与目标兴趣点之间的距离系数:其中,d(i,j)表示的是两个兴趣点之间的距离;
[0097]
s440、根据每次计算得到的所述注意力系数和所述距离系数更新目标兴趣点的特征:
[0098]
s450、遍历邻居集合后,根据目标兴趣点的位置信息,构造目标兴趣点的地理空间特征向量;并构造每个兴趣点的地理空间特征
[0099]
其中,α
ij
表示两个poi节点之间的归一化注意力系数,而β
ij
表示的是两个poi节点之间的归一化距离系数,当距离变大时,β
ij
将会减小。a(
·
,
·
)表示的相似度计算函数,d(i,j)表示的是两个poi节点之间的距离。表示的是poi节点i的邻居poi节点集合。最后通过将注意力系数和距离系数统一起来,聚合成当前poi的地理空间特征向量
[0100]
其中,在遍历一个邻居节点信息后,更新一次地理空间特征向量,遍历完目标兴趣点的所有邻居节点信息之后,得到最终的地理空间特征向量h
′i。
[0101]
根据不同的兴趣点之间的物理距离关系进行邻接图的构建,并使用图注意力网络来对每个兴趣点及其邻居之间的关系获取其节点注意力系数来进行建模,此外,根据不同兴趣点之间的距离远近,获取其距离注意力系数,通过节点注意力系数和距离注意力系数
来共同对签到序列中每一个兴趣点进行空间特征建模。在传统的图注意力网络中,邻域集合不包含具体的距离关系,而只是一种抽象的邻居,在添加距离注意力系数之后,能够使得不同兴趣点之间的距离关系更加显著,也更符合兴趣点推荐的空间语义。
[0102]
可选的,s500具体包括:
[0103]
s510、根据不同用户的兴趣信息之间的偏好关联关系,构建社交网络图;
[0104]
s520、通过社交网络图获取用户的相似矩阵;
[0105]
s530、根据相似矩阵获取对应的邻居用户集,并采用随机邻居采样算法从邻居用户集中进行特征提取;
[0106]
s540、将提取的特征增加至目标用户,构成用户社交信息特征。
[0107]
用户的兴趣偏好可能在朋友社交圈内传播,而用户也将受到社交网络中邻居偏好的影响。用户的社交网络图描述了不同用户之间的偏好关联关系,用户的兴趣可以受到社交网络中邻居偏好的影响,需要构建出不同用户的社交网络图关系:
[0108]gu
=《vu,eu,au》
[0109]
其中,vu表示邻接图中的用户节点信息,eu表示的是不同用户节点之间的边信息,表示用户节点的特征集合,表示用户的总数,其中ui为用户的编号。
[0110]
在用户社交网络图中,若两个用户之间存在偏好关联关系,则可以构建社交网络图,偏好关联关系采用类杰卡德相似度表示,如果类杰卡德相似度大于等于设定的相似度阈值s
δ
,则表明这些用户属于兴趣接近的群体。示例性的,用户ui和用户uj的签到集合分别为和如果两个签到集合之间类杰卡德相似度大于等于阈值s
δ
,则表示两个用户存在一条双向边关系ε
ij
∈eu。其中,类杰卡德相似度公式为:
[0111]
通过用户社交网络图gu可以构建一个用户相似矩阵用于表示用户ui和用户uj之间是否存在联系,存在则为1,否则为0。
[0112]
获取目标用户的相似矩阵后,还需要从中获取目标用户的用户社交信息特征。由于目标用户的相似矩阵中至少具有一个邻居,为了增强目标用户的社交特征信息,还需要提取邻居的特征,对目标用户的特征进行丰富,为了提高用户社交信息特征的获取速度,在本实施例中采用随机邻居采样算法从邻居用户集中进行特征提取,由社交信息影响模块实现,如图4所示。
[0113]
随机邻居采样算法具体操作为:对于用户ui,根据用户相似矩阵wu获取其邻居用户集并从中随机采样一名邻居用户uj,同时随机获取uj感兴趣的一个poi信息lj,最后使用多模态特征嵌入聚合层来对用户ui、邻居uj以及poi节点lj进行向量化,分别获取和并更新用户ui自身的信息特征:
[0114]
利用不同用户之间历史签到记录之间的相似程度来进行社交网络的构建,并使用随机邻居采样算法来处理社交网络的信息,对于一个用户,算法会选择该用户的一位邻居用户以及邻居用户所感兴趣的一个兴趣点,并将当前用户、邻居用户以及邻居用户兴趣点
的信息融合到当前用户状态上,达到兴趣传播的目的。相似用户在社交网络中的偏好变化是接近的,通过随机采样的方式可以模拟用户偏好在社交网络中的传播,同时也可以将相似用户的偏好特征进行吸收,从而增强用户的特征表达。
[0115]
可选的,s600具体包括:
[0116]
s610、将长期偏好特征、短期偏好特征、地理空间特征以及用户社交信息特征的特征向量信息进行拼接,生成兴趣点元数据;
[0117]
s620、基于兴趣点元数据计算下一个兴趣点的候选集的概率分布;
[0118]
s630、选取候选集中概率最大的前k个作为用户喜好的兴趣点推荐列表。
[0119]
在获取了各个模态的特征之后,接着将这些模态信息进行拼接,用来获取兴趣点元数据的特征表示ej::concat(
·
)表示拼接函数,最后整个序列的嵌入特征表示e:e=[e1,e2,
…
,en]。
[0120]
候选集预测模块结合上述所有不同模块之间获取的上下文语义信息,进行分析计算并为用户做出下一个poi推荐的候选集。对于给定长度为n的签到序列可以得到长度均为n-1的输入序列:和输出序列:将偏好特征表示结合当前地理空间特征以及用户社交信息特征构成兴趣点元数据。
[0121]
将兴趣点元数据输入至推荐模型中,计算下一个兴趣点的候选集的概率分布。得到下一个兴趣点候选集的概率分布:到下一个兴趣点候选集的概率分布:其中,兴趣点的候选集包括类别候选集c=[c1,c2,
…
,cn]和地点候选集l=[l1,l2,
…
,ln]。选取候选集中概率最大的前k个作为用户喜好的兴趣点推荐列表,k为正整数,可由用户个性化设置。
[0122]
本发明实施例的技术方案,通过融合用户的长期偏好特征、短期偏好特征、地理空间特征和用户社交信息特征,获取用户在历史签到信息、时空状态信息和社交网络中的兴趣信息,对用户的兴趣数据进行全面分析,生成符合用户喜好的兴趣点推荐列表,对用户的下一个兴趣点进行合理的推荐。解决了签到数据稀疏性,元信息利用广度不足和冷用户推荐不准确的技术问题,实现对用户签到序列进行了层次化特征提取,增加了地理空间特征,增强了用户社交信息特征,实现了充分使用签到数据,全面学习用户的行为特点,准确推荐的下一个兴趣点,优化用户的使用感受。
[0123]
实施例二
[0124]
如图5所示,一种基于社交时空信息与用户偏好的连续兴趣点推荐系统,包括:
[0125]
用户偏好追踪模块,利用循环神经网络rnn和多头注意力机制来对用户历史签到序列进行分析处理,获取用户签到序列中用户的长期偏好特征和短期偏好特征;
[0126]
地理距离感知模块,利用图神经网络gnn获取用户签到序列中每个位置上的地理空间特征;
[0127]
社交信息影响模块,使用随机邻居采样算法来从用户的社交网络图中进行特征提取,获取用户签到序列中每个位置上的用户社交信息特征;
[0128]
候选集预测模块,用于根据用户偏好追踪模块、地理距离感知模块以及社交信息
影响模块所获得的特征信息,进行相加融合成为多语义特征,并输入至推荐模型中,生成符合用户喜好的兴趣点推荐列表。
[0129]
本发明实施例所提供的一种基于社交时空信息与用户偏好的连续兴趣点推荐系统可执行本发明任意实施例所提供的一种基于社交时空信息与用户偏好的连续兴趣点推荐方法,具备执行方法相应的功能模块和有益效果。
[0130]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
