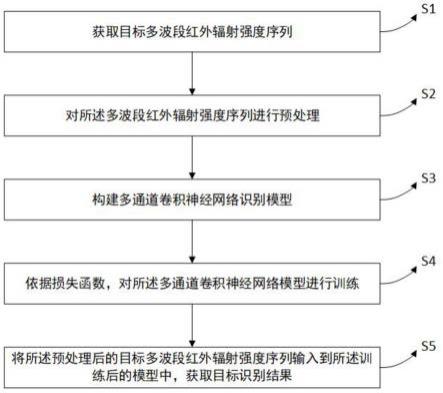
1.本发明属于红外信号处理技术领域,具体是基于多通道卷积神经网络的红外目标识别方法。
背景技术:
2.空间红外目标识别是红外监视系统的关键技术,其分类精度直接决定了任务的成败。多波段探测系统是空间目标识别信息来源的主要方式,具有频谱拓展和抗干扰能力强的特点。受探测器性能的限制,远距离的目标在探测器成像平面上以小点的形式出现,无法获取目标的外形和基本结构等重要信息,能够利用的信息十分有限。因此,大部分红外点目标识别的研究主要基于目标的辐射强度序列展开。
3.目前已有的红外目标识别方法可分为手工设计和深度学习两大方向。基于手工设计的方法侧重于特征提取过程,特征提取的精度直接决定分类结果。然而,基于手工设计的识别方法强烈依赖设计者的专业知识和数据的分布特征,很难充分挖掘红外目标数据的内在关联。基于深度学习的方法主要是考虑各类目标的辐射信息变化,将辐射信息输入到训练好的深度神经网络,进而实现各目标的分类识别,为空间物体分类提供了一个端到端的解决方案。然而,这些方法只聚焦于灰度图像或单波段信号,因此一些重要的特征信息丢失了。与单波段识别相比,多波段信号能够反映不同波段的辐射特性,在某些波段保持较高的信噪比,受目标速度、姿态等变化的影响较小。卷积神经网络(convolutional neural network,cnn)作为一种深度神经网络,已经成功地应用于目标检测、图像识别、和时间序列预测等领域。在典型的cnn中,提取的信息以同等重要性向后流动,同时只进行卷积可能会丢失cnn底层的一些重要信息,限制了其对多个特征提取的性能。
技术实现要素:
4.为了克服上述现有技术的不足,本发明提供了一种基于多通道卷积神经网络的红外目标识别方法,该网络能针对不同波段红外信号自适应的学习适合目标分类的特征,实现差分信息互补,可用于识别空间环境中的具有多波段红外辐射强度序列的目标。
5.为了实现上述目的,本发明的技术方案如下:一种基于多通道卷积神经网络的红外目标识别方法,包括如下步骤:
6.s1:获取目标多波段红外辐射强度序列;
7.s2:对目标多波段红外辐射强度序列进行预处理;
8.s3:构造多通道卷积神经网络识别模型;
9.s4:依据损失函数,对多通道卷积神经网络模型进行训练;
10.s5:将预处理后的目标多波段红外辐射强度序列输入到训练后的通道卷积神经网络识别模型中,获取目标识别结果
11.采用上述方案后实现了以下有益效果:
12.进一步,s1中,目标的多波段红外辐射强度序列是通过目标红外仿真系统进行仿
真得到。
13.进一步,s2中,包括如下步骤:s21:将目标多波段红外辐射强度序列进行归一化;s22:将归一化的目标多波段红外辐射强度序列分成n个单波段红外辐射强度序列,其中n为波段数量。
14.进一步,s3中,多通道卷积神经网络模型包括m个通道,每个通道都包含输入模块和三层卷积模块,m个通道通过融合模块连接,最后通过分类模块输出结果,m为通道数量。
15.进一步,输入模块将归一化处理后的单个波段辐射强度序列作为输入,每个波段对应一个通道。
16.进一步,卷积模块,包括卷积层和池化层,对输入模块的输入特征进行卷积操作和最大池化操作,其中,最后一层卷积模块中未设置池化层。
17.进一步,融合模块,包括如下融合步骤:
18.s01:通过一维卷积将每个通道内的所有特征向量融合成一个特征;
19.s02:将m个通道的特征向量拼接在一起;
20.计算过程如下:
21.fm=conv1([f1;f2;
…
;f
t
]),m∈[1,m]
[0022][0023]
其中,f表示每个通道卷积模块输出的特征向量,t为特征向量个数,conv1表示卷积核大小为1的卷积操作,f表示融合模块输出的特征。
[0024]
进一步,分类模块,包括flatten层、全连接层和softmax分类层。
[0025]
进一步,s4中,损失函数为交叉熵函数,定义为:
[0026][0027]
其中,其中n表示输入样本的大小,j表示类别数量,y表示预测类别,对应实际类别,采用adam算法反向更新参数。
[0028]
进一步,s5中,输入为预处理后的目标多波段红外辐射强度序列,输出为其类别及概率,即所述目标的识别结果。
[0029]
与现有技术相比,本发明的有益效果是
[0030]
1.在多通道卷积神经网络分类模型中,在每个通道中学习单个波段的特征,然后在融合过程中将所有通道的信息作为特征表示。这种设计迎合了对多波段红外数据处理的需要,同时提高了识别方法对数据缺失、波段不匹配的容忍度。
[0031]
2.在多通道融合过程中,通过卷积核为1*1的卷积最大程度的保持了原有波段的底层特征,使分类模型能有效区分不同波段特征的不同模式,提高了对多波段辐射数据的分类性能和处理效率。
[0032]
3.本发明以红外目标的多波段辐射强度序列作为输入,不需要复杂的特征提取过程,且无需人工干预和相关领域知识,泛化能力强.
附图说明
[0033]
图1为本发明提供的一种红外目标识别方法的流程示意图;
[0034]
图2为本方明构造的多通道卷积神经网络分类模型示意图;
[0035]
图3为本方明的一个实施例中六种目标结构示意图;
[0036]
图4为本方明的一个实施例中六类目标在单波段下的辐射强度序列示例;
[0037]
图5为本方明的一个实施例中六类目标识别结果的混淆矩阵。
具体实施方式
[0038]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行详细的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0039]
本技术提供一种基于多通道卷积神经网络的红外目标识别方法,基本如附图1所示,包括如下步骤,
[0040]
s1,获取目标多波段红外辐射强度序列;
[0041]
其中,目标的多波段红外辐射强度序列是通过目标红外仿真系统进行仿真得到。
[0042]
本实施例中,从空间红外目标的物理特性出发,考虑了六种典型空间目标的微动特性和红外辐射特性,利用目标红外仿真系统,进行红外辐射强度序列模拟。其中六种目标分别是:o1:平底锥、o2:柱底锥、o3:球底锥、o4:球体、o5:圆柱和o6:等曲率弧形碎片。图3所示为各目标的形状示意图。表1为不同目标具体仿真参数。一系列的红外辐射强度序列是通过表1所列的物理属性和动态状态的分布中随机抽样产生的。
[0043]
表1 不同目标的仿真参数设置
[0044][0045]
本实施例中,通过目标红外仿真系统获取了6000组观测时长为20s的红外辐射强度序列,包括o1到o6各1000组。随机选取4200组序列作为训练集,800组目标作为验证集,剩下1000组作为测试集。探测器波段设置为三个,分别是3~5μm,5~8μm,8~12μm;采样频率为25hz。需要注意的是,在真实的探测过程中,红外传感器的灵敏度、响应速率等都会有轻微的变化,物体表面的温度变化也并不是完全不一致的。因此,在红外辐射强度序列模拟
中,为了提高真实性,我们假定这些因素都用高斯加性白噪声模型来描述。信噪比定义为信号功率与噪声功率的比值,计算公式为:
[0046]
snr=10log
10
(ps/pn)。
[0047]
s2,对所述目标多波段红外辐射强度序列进行预处理;
[0048]
其中,所述s2包括;
[0049]
s21:将所述目标多波段红外辐射强度序列进行归一化;
[0050]
s22:将所述归一化的目标多波段红外辐射强度序列分成n个单波段红外辐射强度序列,其中n为波段数量。在实施例中,采用最大最小归一化,将原始数据线性化的方法转换到[0,1]的范围。因为目标辐射强度的大小不是固定的,对于识别而言,只有信号序列的波形才有相对意义。因此我们需要将数据进行归一化,这样识别方法就有了尺度不变性。此外,在本实施例中,波段数量n=3。图4展示了六类目标在单波段5~8μm下的辐射强度序列,分别是原始数据、加噪数据和归一化数据。
[0051]
s3,构造多通道卷积神经网络识别模型;
[0052]
其中,所述网络模型包括m个通道,每个通道都包含输入模块和三层卷积模块,m个通道通过融合模块连接,最后通过分类模块输出结果。本实施例中,每个波段对应一个通道。
[0053]
在实施例中,所述的输入模块将所述目标归一化处理后的3个单波段辐射强度序列作为3个通道的输入。依次连接卷积模块、融合模块和分类模块,分类模块,包括flatten层、全连接层和softmax分类层,卷积模块,包括卷积层和池化层,对输入模块的输入特征进行卷积操作和最大池化操作,其中,最后一层卷积模块中未设置池化层。整个多通道卷积神经网络结构如图2所示。在融合模块中,通过一维卷积将每个通道内的所有特征向量融合成一个,然后将3个通道的特征向量拼接在一起,计算过程如下:
[0054]fm
=conv1([f1;f2;
…
;f
t
]),m∈[1,m]
[0055][0056]
其中,f表示每个通道卷积模块输出的特征向量,t为特征向量个数,conv1表示卷积核大小为1的卷积操作,f表示融合模块输出的特征。
[0057]
本实施例中,整个多通道卷积神经网络的参数设置如表2所示。
[0058]
表2 网络参数设置
[0059]
[0060][0061]
s4,依据损失函数,对所述多通道卷积神经网络模型进行训练;
[0062]
在实施例中,训练样本来自于步骤1到步骤2中获取的4200组训练集和800组验证集,采用学习速率为0.001的adam优化器,并使用交叉验证来获得模型的最优参数,本实施例中,损失函数为交叉熵函数,定义为:
[0063][0064]
其中,其中n表示输入样本的大小,j表示类别数量,y表示预测类别,对应实际类别,采用adam算法反向更新参数。整个分类模型的总参数量约为25万个,相对于其它复杂的深度神经网络,该网络仍然是轻量级的。
[0065]
s5,将所述预处理后的目标多波段红外辐射强度序列输入到所述训练后的模型中,获取所述目标识别结果。
[0066]
在实施例中,测试样本来自于步骤1到步骤2中获取的800组不同类别的测试集,设置了5db、10db、15db、20db、30db和原始数据五种噪声水平。目标识别结果如表3所示。图5为根据20db测试集的识别结果绘制的混淆矩阵,各类目标的召回率分别是0.521、0.177、1.0、0.364、0.753和1.0,平均召回率是0.6358。可以看出,该方法在信噪比为20db的情况下,识别的精确率可以达到85%。
[0067]
表3 识别结果
[0068]
[0069][0070]
在实施例中,为了验证本方法对数据缺失、波段不匹配时的鲁棒性,以30db测试集为基础,重新进行了处理。数据缺失是指在实际应用场景中由于器件的不稳定性而导致序列中某些序列点的极端异常值。本实施例主要考虑了成像焦平面上光敏阵列中可能出现的不良元素引起的辐射强度序列值的异常大小。波段不匹配指的是多个红外传感器返回的数据存在一定的延迟。虽然有许多预处理算法可用于对齐不同的波段数据,但它们总是会增加时间成本或人为地引入噪声。在实施例中,将辐射强度序列长度的一定比例(定义为数据缺失率)的时间序列点随机设置为0或1,以模拟缺失序列值;将样本一个波段的时间序列点向后延迟一定比例(定义为波段匹配率)。并以其它方法作为对比。数据缺失时分类精确率如表4所示。波段不匹配时分类精确率如表5所示。最高精确率用粗体表示。可以看出,本发明提出的方法在出现数据缺失、波段不匹配等情况时,仍然能够稳定识别目标。
[0071]
表4 数据缺失时分类精确率
[0072][0073]
表5 波段不匹配时分类精确率
[0074][0075]
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本技术给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本技术的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。