1.本发明属于人工智能和自然语言处理领域,涉及一种基于动态提示学习的小样本嵌套关系抽取方法。
背景技术:
2.随着互联网的高速发展,网络上每天都会产生大量非结构化的数字文本,例如新闻文章、电子邮件、社交媒体、政府文件等。如何帮助人类理解所有这些数据?一种流行的想法是通过注释语义信息将非结构化文本转换为结构化文本。然而,数据的绝对量和异构性使得人工注释变得不可能。相反,我们希望有一台计算机用我们感兴趣的结构注释所有数据。通常,我们对实体(人,组织,位置等)之间的关系(个人归属,组织结构等)感兴趣。当前最先进的命名实体识别(ner)模型,可以高精度地自动标记数据。然而,整个关系提取过程并不是一项简单的任务。为了做出正确的注释,计算机需要知道如何识别具有感兴趣语义属性的文本。因此,提取自然语言文本中实体之间的语义关系是实现自然语言理解应用的关键步骤。关系抽取就是指识别非结构化文本中实体之间关系的任务,在构建知识图谱,知识库问答、对话生成与事实抽取等领域有着广泛应用。
3.关系抽取技术根据任务复杂性主要分为三种,由简单到复杂依次分别为:扁平关系抽取(flat relation),重叠关系抽取(overlapping relation)和嵌套关系抽取(nested relation)。
4.1)扁平关系抽取:该研究面向实体之间扁平结构的关系抽取,并且只需要抽取出句子中两个指定实体之间的关系。
5.2)重叠关系抽取:该研究面向实体之间扁平结构的关系抽取,并且在此基础上,需要抽取出句子中多个实体之间所有的关系三元组,即,一个实体可能出现在多个不同的关系三元组中。
6.3)嵌套关系抽取:该研究不仅面向实体之间的关系抽取,还面向关系三元组与实体、关系三元组之间构成的嵌套结构的关系抽取,需要抽取出句子中所有的嵌套关系三元组,即,需要抽取实体与实体之间、实体与关系之间以及关系与关系之间的关系三元组。
7.这三种关系抽取任务中,相同点是都研究需要抽取出实体之间的关系;不同点是嵌套关系抽取还需要抽取关系三元组与实体、关系三元组之间的嵌套关系。
8.现有关系抽取算法研究工作大多集中在扁平关系抽取与重叠关系抽取,只关注实体之间的关系。但是,在实际应用场景中,以嵌套结构形式呈现的关系信息更加常见,而现有的面向扁平结构的关系抽取算法不能解决嵌套关系抽取的问题。因此,嵌套关系抽取的研究开始受到广泛关注。
9.目前,嵌套关系抽取的相关研究还较少,并且嵌套关系抽取算法的准确性依赖于大量的、高质量的、人工标注的训练数据,这与缺少有标注语料的研究现状互相矛盾,所以,亟需提出一种面向小样本场景的嵌套关系抽取方法。因此,研究面向小样本领域的嵌套关系抽取具有广阔的应用场景与较高的研究价值。
技术实现要素:
10.发明目的:本发明在现有研究的基础上,提出一种基于动态提示学习的小样本嵌套关系抽取方法,充分发挥预训练模型和提示学习在小样本场景下的有效性,提升模型在小样本场景下的嵌套关系抽取准确性。
11.技术方案:为实现上述发明目的,本发明提出一种基于动态提示学习的小样本嵌套关系抽取方法,包括以下步骤:
12.(1)提示模板设计,对嵌套关系任务原输入句子x按照prompt模版设计进行相应转换,经过prompt模版转换函数,得到prompt输入语句x
′
;
13.(2)答案搜索,将prompt输入语句x
′
输入到预训练语言模型对语句对应的单词序列进行编码,得到每个单词的词向量,然后在prompt输入语句x
′
中的掩码位置预测出标签词集合中概率最高的标签词;
14.(3)答案映射,通过预训练语言模型在prompt输入语句x
′
的掩码位置预测出最终的标签词之后,将预测出的标签词映射为对应的嵌套关系任务的关系类型标签;
15.(4)迭代抽取,逐层迭代地预测具有嵌套结构的关系三元组,并将当前层预测出的嵌套关系关系三元组用于下一层关系的预测,直到没有新的嵌套关系三元组产生。
16.进一步地,所述步骤(1)中,生成每层嵌套关系的候选左、右元素对;然后,使用prompt模版转换函数将原始输入句子与每层候选左、右元素对结合,转换为prompt输入语句。
17.进一步地,所述步骤(2)中,使用预训练语言模型对prompt输入语句进行编码,根据掩码位置的编码词向量进行掩码预测,从标签词集合中选择预测概率最高的标签词,从而实现对每层嵌套关系候选左右元素对的关系类型分类。
18.进一步地,所述步骤(3)中,预训练语言模型根据转换后的prompt输入语句x
′
在掩码位置预测出标签词,但是预测出的标签词与下游任务输出不完全一一对应,所以在预训练语言模型预测出标签词后,需要再次进行答案映射,将预测出的标签词映射为对应的嵌套关系任务的关系类型标签。
19.进一步地,所述步骤(4)中,嵌套关系抽取任务需要对每个原始输入句子迭代地进行嵌套关系抽取,在迭代过程中,因为每一层嵌套关系会产生新的关系三元组,所以每一层的prompt输入语句也是各不相同的,需要迭代地根据每一层的嵌套关系三元组来生成新的prompt输入语句,从而迭代地生成prompt输入语句、答案搜索、答案映射。
20.有益效果:本发明能够有效解决嵌套关系抽取方法在小样本场景下嵌套关系抽取结果不准确的问题,充分发挥预训练模型和提示学习在小样本场景下的有效性,提升模型在小样本场景下的嵌套关系抽取准确性。第一,本发明通过将嵌套关系抽取任务转化为掩码语言模型任务形式,直接将下游任务转化为预训练任务的形式,能够有效地帮助预训练语言模型理解下游任务;第二,提出动态prompt机制,将原来通过固定转换模版函数生成prompt输入语句的方法进行改进,使用动态的模版转换函数生成prompt输入语句,起到数据增强的作用,从而缓解原来prompt模版带来的数据稀疏问题;第三,自底向上迭代地生成各层的嵌套关系候选三元组并完成表示与分类,直到没有新的嵌套关系三元组产生,因此能够全面准确地生成句子中的所有嵌套关系三元组。
附图说明
21.图1为本发明方法的整体框架图;
22.图2为本发明方法中基于prompt的嵌套关系迭代过程图;
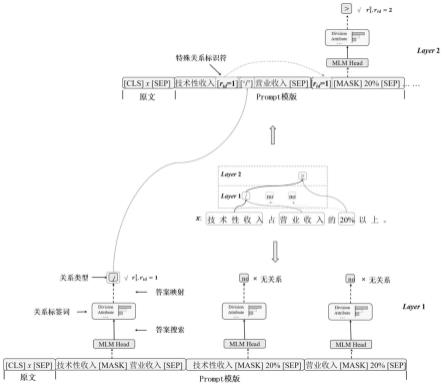
23.图3为本发明方法中特殊关系标识符使用示例图;
24.图4为本发明方法中动态prompt机制示例图;
25.图5(a)为本发明方法中模型prompt
auto
的实验结果图,(b)本发明方法中模型prompt
manual
的实验结果图。
具体实施方式
26.下面结合附图,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
27.本发明提出了一种基于动态提示学习的小样本嵌套关系抽取方法,解决了现有嵌套关系抽取方法在小样本场景下对嵌套关系识别准确性低的问题。如图1所示,本发明的完整流程包括提示模板设计阶段、答案搜索阶段、答案映射阶段、迭代抽取阶段4个部分。具体的实施方式说明如下:
28.提示模板设计阶段对应技术方案步骤(1)。具体实施方式为:给定嵌套关系任务的原输入句子x为:x={w1,w2,
…
,wn},表示x由n个单词组成,prompt模版转换函数将输入句子x转换为prompt输入语句x
′
,作为预训练语言模型的掩码语言模型任务输入形式。具体转换公式如下:
29.f
pre
(x)=[cls]x[sep]ri,ri∈s
[0030]
其中,f
pre
(x)表示嵌套关系prompt提示模版前缀函数;[cls]与[sep]都是预训练语言模型词表中的特殊单词,分别用来表示输入句子的起始标记与输入句子的分割标记;ri表示第i个嵌套关系三元组;s表示嵌套关系中已抽取出的关系三元组集合。
[0031]
x
′
=f
prompt1
(x)=f
pre
(x)[el
l
][mask][elr].[sep]
[0032]
=f
pre
(x)
⊕
《el
l
,elr》
[0033]
其中,f
prompt1
(x)表示第一种嵌套关系prompt输入模版转换函数;[el
l
]与[elr]分别表示候选嵌套关系元素对中的左元素与右元素,其具体内容取决于当前迭代抽取的层数;[mask]是预训练语言模型的特殊单词,表示掩码语言模型需要预测的单词位置;
⊕
表示拼接符;《el
l
,elr》表示候选嵌套关系元素对。
[0034]
x
′
=f
prompt2
(x)=f
pre
(x)[el
l
]对[elr]是[mask]关系.[sep]
[0035]
=f
pre
(x)
⊕
《el
l
,elr》
[0036]
其中,f
prompt2
(x)表示第二种嵌套关系prompt输入模版转换函数。
[0037]
考虑到prompt输入模板设计方法具有多样性,不同任务对应不同的prompt模版设计,相同任务也可以有多种prompt输入模版设计,因此,本发明方法设计了2种prompt输入模版f
prompt1
(
·
)与f
prompt2
(
·
),分别采用直接拼接与人工构造蕴含自然语义句子模版的方法:
[0038]
1)f
prompt1
(
·
)是第一种prompt转换模版函数,该函数直接将左元素内容[el
l
]、特殊单词[mask]和右元素内容[elr]依次拼接到嵌套关系任务原输入句子x后面,形成prompt
输入语句。
[0039]
2)f
prompt2
(
·
)是第二种prompt转换模版函数,该函数将左元素内容[el
l
]、“对”、右元素内容[elr]、“是”、特殊单词[mask]与“关系”依次拼接到嵌套关系任务原输入句子x后面,形成蕴含自然语义的prompt输入语句。
[0040]
答案搜索阶段对应技术方案步骤(2)。具体实施方式为:嵌套关系抽取任务的原输入句子x,经过prompt模版转换函数后,得到prompt输入语句x
′
,再输入到预训练语言模型,预训练语言模型在prompt输入语句x
′
中单词[mask]的位置预测出prompt答案词。因为这些答案词与嵌套关系抽取中的关系类型标签相对应,所以,prompt答案词也被称为标签词(label word)。
[0041]
在本方法中,设计实现了两种标签词设计方法:
[0042]
1)第一种标签词设计方法,记为prompt
manual
,人工地选择自然语言单词作为标签词,使得本发明嵌套关系抽取任务中各个关系类型与其对应的标签词在自然语义上紧密相关。
[0043]
2)第二种标签词设计方法,记为prompt
auto
,自动地选择预训练语言模型词表中的特殊单词[unused]作为标签词,使得本发明嵌套关系抽取任务中各个关系类型与这些标签词一一对应。
[0044]
设嵌套关系抽取任务的关系类型集合为r={rt1,rt2,
…
,rt
t
},其中rti表示第i种关系类型,t是嵌套关系抽取任务中关系类型的总数量。每种关系类型rt都使用对应的关系类型标签y
rt
表示,并且每种关系类型标签y
rt
对应着prompt模版的标签词集合可使用如下公式表示映射函数:
[0045][0046]
其中,表示关系类型标签y
rt
对应的标签词集合,是从预训练语言模型词表中选择的单词集合;f
map
表示关系类型标签的映射函数,将关系类型标签y
rt
映射到对应的标签词集合
→
表示函数映射符号。
[0047]
因为每种嵌套关系类型标签都对应着prompt标签词集合,所以嵌套关系抽取任务的所有prompt标签词集合为:
[0048][0049]
其中,v
p
表示嵌套关系抽取任务的所有prompt标签词集合,即为所有关系类型标签对应的标签词集合的并集。
[0050]
prompt标签词的预测概率公式如下:
[0051][0052]
其中,h
[mask]
表示预训练语言模型在单词[mask]位置输出的隐层向量;ww表示预训练语言模型可训练参数;p([mask]=w|x
′
)表示预训练语言模型从prompt输入语句x
′
中[mask]位置预测出标签词w的概率。
[0053]
该公式先计算每个标签词w的得分exp(ww·h[mask]
),再进行归一化,得到每个标签词的预测概率。
[0054]
通过以上公式计算出每个标签词的预测概率后,选择其中预测概率最大单词的作为最终预测标签词,具体预测公式表示为:
[0055][0056]
其中,argmax表示选择概率最大单词的函数,表示模型最终作为标签词的单词。
[0057]
答案映射阶段对应技术方案步骤(3)。具体实施方式为:预训练语言模型在prompt输入语句x
′
中特殊单词[mask]的对应位置预测出最终的标签词之后,提示学习prompt模版需要将该标签词转化为对应的嵌套关系任务关系类型标签,对应的转化过程使用如下公式表示:
[0058][0059]
其中,表示关系标签词的映射函数,将预训练语言模型预测出的最终标签词映射为嵌套关系抽取任务中的关系类型标签y
rt
。
[0060]
迭代抽取阶段对应技术方案步骤(4)。具体实施方式为:一般的关系抽取任务或者文本分类任务只需要预测出输入句子所表达的实体之间关系或类别,属于单次预测任务。所以,为了将这类任务转化为预训练语言模型的掩码语言模型任务形式,只需要使用提示学习的prompt模版直接将原任务输入句子转化为prompt输入句子并且进行单次预测。
[0061]
但是,嵌套关系抽取任务为了抽取输入句子中的嵌套关系,需要逐层迭代地预测具有嵌套结构的关系三元组,并且需要将当前层预测出的嵌套关系关系三元组用于下一层关系的预测,构成迭代式嵌套关系抽取任务。
[0062]
为了将嵌套关系抽取任务转化为预训练语言模型的掩码语言模型任务形式,需要迭代地使用提示学习的prompt模版将原任务输入句子与每层嵌套关系转化为prompt输入句子并且进行迭代式预测。这也是基于动态提示学习的嵌套关系抽取任务与一般的关系抽取任务的主要区别。
[0063]
在基于prompt的嵌套关系抽取算法迭代过程中,嵌套关系抽取任务的prompt提示模版设计主要分为两种情况:嵌套关系层数l=0和l≥1,对于这2种情况分别讨论如下:
[0064]
(1)嵌套关系层数l=0
[0065]
当嵌套关系层数l=0时,嵌套关系中元素只包含句子中的全部实体,对应的嵌套关系prompt提示模版设计中转换模版公式如下:
[0066][0067]
表示第0层的嵌套关系prompt提示模版前缀函数,当嵌套关系层数l=0时,该函数将[cls]拼接上嵌套关系原始输入句子x再拼接上[sep],得到第0层的prompt提示模版前缀。
[0068][0069]
其中,x
′0表示prompt提示模版将第0层嵌套关系与对应的候选嵌套关系元素对转换后的prompt输入语句;表示第0层的嵌套关系prompt输入模版转换函数;表示原任务输入句子x中第0层的嵌套关系元素集合,即句子x中的所有实体构成的集合;表示中的第i个元素。
[0070]
(2)嵌套关系层数l≥1
[0071]
当嵌套关系层数l≥1时,嵌套关系中元素不仅有实体,还有关系三元组,对应的嵌套关系prompt输入模版转换公式如下:
[0072][0073]
其中,表示第l层的嵌套关系prompt提示模版前缀函数,当嵌套关系层数l≥1时,该函数将第l层的嵌套关系三元组都拼接到第l-1层prompt提示模版前缀后面,得到第l层的prompt提示模板前缀,用于抽取下一层的嵌套关系三元组;表示输入句子中第l层的第i个嵌套关系三元组;p
l
表示输入句子中第l层的嵌套关系三元组数量。
[0074][0075]
其中,x
′
l
表示prompt提示模版将第l层嵌套关系与对应的候选嵌套关系元素对转换后的prompt输入语句;表示第l层的嵌套关系prompt输入模版转换函数;表示包含输入句子中前l层的所有嵌套关系元素集合;表示中的第i个嵌套关系元素。
[0076]
根据上述公式,当嵌套关系层数l≥1时,首先,将输入句子中第l层的所有嵌套关系三元组都依次拼接到第l-1层的prompt前缀模版函数后面,得到第l层的prompt前缀模版函数然后,把第l层生成的候选嵌套关系元素对拼接到第l层的prompt前缀模版函数后面,形成第l层的嵌套关系prompt输入句子x
′
l
。
[0077]
此外,在生成嵌套关系候选元素对时,保证该元素对中左元素与右元素互不相同,并且其中至少一个元素属于第l层的嵌套关系三元组集合,即候选关系元素对满足以下条件公式:
[0078][0079]
其中,表示输入句子中前l层的所有嵌套关系元素集合减去前l-1层的所有嵌套关系元素集合,即为第l层的所有嵌套关系三元组集合。
[0080]
以图2中的嵌套关系抽取迭代过程为例,嵌套关系原始输入句子为x=“技术性收入占营业收入的20%以上。”,该句子具有三个实体分别是“技术性收入”、“营业收入”和“20%”。
[0081]
首先,算法从生成待分类的嵌套关系左右元素对《技术性收入,20%》、《技术性收入,营业收入》与《营业收入,20%》;然后,使用prompt模版转换函数得到第0层的prompt输入为:
[0082][0083]
随后,预训练语言模型对该层prompt输入的[mask]位置依次预测出对应嵌套关系
元素对的类型标签词“division”、“none”与“none”;最后,将标签词映射为关系类型标签“/”、“no”与“no”。
[0084]
经过以上过程,嵌套关系抽取模型在l=0时,抽取出了新的嵌套关系三元组为《技术性收入,/,营业收入》。
[0085]
当嵌套关系层数l=1时,第1层的嵌套关系三元组集合为其中其中则该层已有的嵌套关系元素集合是则该层已有的嵌套关系元素集合是
[0086]
首先,算法将第一层的嵌套关系三元组拼接到前一层的prompt前缀模版函数输出后面;然后,从生成嵌套关系左右元素对《
‘
20%’》与《
‘
20%’,》,并使用prompt模版转换函数得到该层的prompt输入为:
[0087][0088]
随后,预训练语言模型对该层prompt输入的[mask]位置依次预测出对应嵌套关系元素对的关系类型标签词,并映射为嵌套关系类型标签;最后,算法抽取出嵌套关系层数l=1时新的嵌套关系三元组为20%》。
[0089]
当嵌套关系层数l=2时,模型继续生成嵌套关系左右元素对,再转换为prompt输入,使用预训练语言模型预测出对应的标签词,没有产生新的嵌套关系三元组,最终结束嵌套关系抽取的迭代过程。
[0090]
动态prompt机制是对技术方案步骤(4)的扩展。具体实施方式为:当嵌套关系层数l≥1时,候选嵌套关系元素对会使用到前l层的嵌套关系三元组。所以,在使用prompt输入模版转换函数生成第l层的prompt输入语句时,需要先使用prompt提示模板前缀函数将前l层的嵌套关系三元组进行表示,然后再将每个候选嵌套关系元素对拼接到后面。但是,高层嵌套关系三元组的左、右元素可能是低层嵌套关系三元组,难以直接使用自然语言单词来表示复杂多层的嵌套关系三元组。
[0091]
为了解决该问题,本发明方法提出使用特殊关系标识符来表示底层嵌套关系三元组。考虑到使用特殊关系标识符的方法会将特殊关系标识符与部分嵌套关系三元组绑定,从而引发数据稀疏问题。对此,本发明提出了动态prompt机制,对特殊关系标识符进行动态分配,起到数据增强作用,从而缓解数据稀疏问题。
[0092]
动态prompt机制主要分为两个部分:特殊关系标识符设计和动态分配。
[0093]
(1)特殊关系标识符设计
[0094]
本方法提出的特殊关系标识符集合为{[r
id
=1],[r
id
=2],
…
,[r
id
=k]},其中,每个特殊关系标识符[r
id
=k]都是从预训练语言模型词表中选择的特殊单词,用来表示嵌套关系中的关系三元组。
[0095]
当嵌套关系层数l=0时,因为嵌套关系中所有元素都是实体,不会使用到特殊关系标识符。
[0096]
当嵌套关系层数l≥1时,前缀计算公式如下:
[0097]
[0098]
根据上述公式,使用prompt提示模版前缀函数将输入句子中第l层的所有嵌套关系三元组都依次拼接到第l-1层的prompt前缀模版函数后面,从而形成第l层的prompt前缀模版函数
[0099]
在表示嵌套关系三元组时,对于前l层嵌套关系三元组集合中每个嵌套关系三元组ri=《el
l
,rt,elr》,本方法为嵌套关系三元组ri分配一个特殊关系标识符[r
id
=i]。在前缀模版函数中,使用“[el
l
][r
id
=i][w
rt
][elr]”表示嵌套关系三元组ri,具体含义依次为:嵌套关系三元组ri的左元素内容[el
l
]、特殊关系标识符[r
id
=i]、嵌套关系三元组的类型标签词[w
rt
]与嵌套关系三元组的右元素内容[elr]。在高层中使用该嵌套关系三元组ri作为高层嵌套关系三元组的左元素或者右元素时,直接使用[r
id
=i]表示该嵌套关系三元组。
[0100]
以图3中嵌套关系抽取过程为例,对特殊关系标识符的使用过程进行介绍。
[0101]
当嵌套关系层数l=1时,第l=1层的嵌套关系三元组集合为其中其中
[0102]
基于动态提示学习的嵌套关系抽取算法为嵌套关系三元组分配特殊关系标识符[r
id
=1]后,使用prompt模版转换函数得到该层的prompt输入句子为:
[0103][0104]
[
′
/
′
]营业收入[sep]
[0105]
[r
id
=1][mask1]20%[sep]
[0106]
20%[mask2][r
id
=1][sep]
[0107]
然后,预训练语言模型从prompt输入x
′1中[mask1]与[mask2]的位置分别预测出关系类型“》”与“no”,表示对应的嵌套关系元素对分别是“》”关系与没有关系。最终,抽取出新的嵌套关系三元组20%》。
[0108]
(2)特殊关系标识符动态分配
[0109]
基于动态提示学习的嵌套关系抽取方法在为各个嵌套关系三元组分配特殊关系标识符时,如果只按照预定义好的标识符顺序进行分配,那么排序越靠后的特殊关系标识符出现的频率越低。
[0110]
这是因为,只有当一个样本包含的嵌套关系三元组个数越多时,排序靠后的特殊关系标识符才会在该样本中被使用到,即,[r
id
=k]只会在嵌套关系三元组个数大于等于k的样本中被使用到。但是,随着k不断增大,嵌套关系三元组个数大于等于k的样本数量不断减小,导致特殊关系标识符[r
id
=k]的出现次数不断减小。因此,静态的关系标识符分配方法会产生数据稀疏的问题,导致排序靠后的特殊关系标识符不能充分训练。
[0111]
为了解决该问题,本发明提出了基于特殊关系标识符的动态分配机制:
[0112]
对于样本中的任意嵌套关系三元组ri,在为嵌套关系三元组ri分配特殊关系标识符时,采用随机采样,即从0~k范围中随机采样出一个特殊关系标识符[r
id
=rand(k)]来表示嵌套关系三元组ri,其中,rand(k)表示随机函数,将会随机产生0~k范围中的数。同时,
为了保证特殊关系标识符数量能够完全覆盖所有样本的嵌套关系三元组,特殊关系标识符数量k需要满足以下条件:
[0113]
k≥max(relnum(x1),relnum(x2),
…
,relnum(xn))
[0114]
其中,relnum(xi)表示数据集样本句子xi中嵌套关系三元组的个数;n表示数据集中的样本句子数量。
[0115]
以图4为例,采用特殊关系标识符的动态分配机制后,当嵌套关系层数l=1时,第l=1层的嵌套关系三元组集合为其中其中特殊关系标识符的动态分配机制,为随机分配特殊关系标识符[r
id
=rand(k)],使用prompt模版转换函数得到第l=1层的prompt输入句子为:
[0116][0117]
[r
id
=rand(k)][
′
/
′
]营业收入[sep]
[0118]
[r
id
=rand(k)][mask1]20%[sep]
[0119]
20%[mask2][r
id
=rand(k)][mask1][sep]
[0120]
然后,预训练语言模型从prompt输入x
′1中[mask1]和[mask2]的位置分别预测出关系类型“》”与“no”,表示对应的嵌套关系元素对分别是“》”关系与没有关系。最终,抽取出新的嵌套关系三元组20%》。
[0121]
本发明提出了一种基于动态提示学习的小样本嵌套关系抽取方法,为了测试该方法的有效性,在本发明构建的policy数据集上从“from scratch”与“guided”两种模式,使用查准率precision、查全率recall与f1指标评估了方法,并和其他嵌套关系抽取方法进行了对比。此外,为了验证本方法在小样本场景下的有效性,还从全量的嵌套关系抽取数据集policy中抽取出部分数据集作为小样本数据集进行实验。
[0122]“from scratch”模式指模型按层次迭代地预测嵌套关系,当前层次预测出的错误关系三元组可能被用于下一层嵌套关系三元组,导致误差传播,模型性能随着层次增加而衰减。
[0123]“guided”模式指在预测下一层的嵌套关系时,使用当前层的正确嵌套关系三元组来代替模型预测结果,避免误差传播。两种模式对比可以测试嵌套关系层次之间预测结果误差传播的影响。
[0124]
表1动态提示学习模型超参数设置信息
[0125]
[0126][0127]
本发明方法模型超参数如表1所示。其中,提示学习使用的预训练语言模型为bert的base版本,具有12层transformer编码器层;在模型训练时,使用early stop训练策略,模型每训练一个epoch,都在验证集上进行测试计算指标,如果连续10个epoch都没有指标上升,则提前结束模型训练;模型使用adam作为参数优化器;模型参数的学习率设置为1e-5;模型隐层向量维度大小为768;模型输入句子的最大长度设置为512;每个batch的样本数量设置为[4,8];特殊关系标识符的数量为60。
[0128]
表2动态提示学习模型对比实验结果
[0129][0130]
不同嵌套关系抽取算法在policy数据集上对比实验结果如表2所示,模型从第一层开始迭代地预测出所有层的嵌套关系三元组后,计算整体评价指标。其中,prompt
manual
指本发明中使用的prompt标签词通过人工设计,选择自然语言单词作为标签词,使得嵌套关系抽取任务中各个关系类型与其对应的标签词在自然语义上紧密相关;prompt
auto
指本发明中使用的prompt标签词通过自动设计,选择预训练语言模型词表中的特殊单词[unused]作为标签词。
[0131]
从表2中的实验结果可以看出,本发明提出的基于动态提示学习的嵌套关系抽取算法,相比于其他嵌套关系抽取算法,在policy数据集上“from scratch”与“guided”两种模式下都取得了最好的整体指标,所以,该对比实验结果证明了本发明算法在嵌套关系抽取任务上的有效性。
[0132]
为了评估发明方法提出的基于动态提示学习的小样本嵌套关系抽取方法在小样本场景下的准确性,本发明从全量的嵌套关系抽取数据集policy中按照10%、20%、30%与50%的百分比采样出多个小样本数据集。
[0133]
表3动态提示学习模型百分比小样本实验结果
[0134][0135]
本发明方法在百分比小样本数据集上的实验结果如表3所示,从上述表中的实验结果可以看出,本发明提出的基于动态提示学习的面向小样本场景下的嵌套关系抽取方法,相比其他嵌套关系抽取算法,在所有百分比小样本数据上,准确性都超过了其他模型,说明了本方法能够有效提升模型在小样本场景下嵌套关系抽取任务上的准确性。
[0136]
图5显示了prompt特殊关系标识符数量对实验结果的影响,其中(a)与(b)分别是特殊关系标识符数量对模型prompt
auto
与prompt
manual
效果影响图。通过评估本发明方法中特殊关系标识符数量对嵌套关系抽取任务准确性的影响,可以看出prompt特殊关系标识符可以提升本发明方法模型在嵌套关系抽取任务上的准确性,避免数据稀疏问题,但是特殊关系标识符数量过大会导致嵌套关系抽取任务的准确性下降。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
