1.本发明涉及相似性智能判别的领域,且更为具体地,涉及一种军工科研生产数据管理方法及系统。
背景技术:
2.在长期的军工科研生产过程中积累了大量的数据文件,在开展数据处理与统计分析等相关工作时,面临着数据文件重复的问题,即,多个文件描述角度不同、分析层次不同、制作单位不同,但本质上描述的内容是相同的。
3.数据文件重复会给数据文件的管理带来挑战,在开展数据处理时,例如,在进行数据清理时,需要对本质上描述的内容相同的两份文本进行删除其中之一,以避免另外一份文本占据不必要的存储空间。
4.对两份文本的描述内容是否相同,可通过对两份文本进行相似性分析来进行。当前的相似性文本判重主要采用人工的方式进行,由有经验的资深专家来判断多份文件本质内容是否相同,这种方法耗时耗力且能处理的数据量有限,难以满足数字化智能化发展浪潮下大规模非结构化数据快速处理的需求。
5.因此,期待一种用于军工科研生产数据管理方案,其能够对军工科研生产数据的相似性进行判断以便于后续的数据管理,例如,数据压缩、重复数据删除等。
技术实现要素:
6.为了解决上述技术问题,提出了本技术。本技术的实施例提供了一种军工科研生产数据管理方法及其系统,其通过人工智能技术的深度神经网络模型来从第一军工科研生产文本数据和第二军工科研生产文本数据中分别提取出具有词序列和段序列的全局性隐含关联特征,进一步融合所述词序列和所述段序列的特征信息来进行所述第一军工科研生产文本数据和所述第二军工科研生产文本数据的相似性判断,以避免了传统的处理方式造成的数据量局限性和误差难以控制的问题。
7.根据本技术的一个方面,提供了一种军工科研生产数据管理方法,其包括:
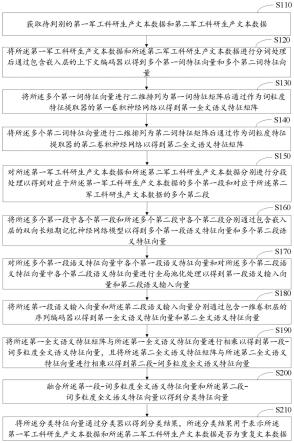
8.获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;
9.将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;
10.将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;
11.将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;
12.对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二
军工科研生产文本数据的多个第二段;
13.将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;
14.对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量;
15.将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;
16.将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;
17.融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及
18.将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
19.根据本技术的另一方面,提供了一种军工科研生产数据管理系统,其包括:
20.文本数据获取单元,用于获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;
21.上下文编码单元,用于将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;
22.第一特征提取单元,用于将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;
23.第二特征提取单元,用于将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;
24.分段处理单元,用于对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段;
25.双向长短期记忆编码单元,用于将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;
26.全局池化单元,用于对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量;
27.序列编码单元,用于将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;
28.关联相乘单元,用于将所述第一全文语义特征矩阵与所述第一全文语义特征向量
进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;
29.融合单元,用于融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及
30.分类单元,用于将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
31.根据本技术的再一方面,提供了一种计算机可读介质,其上存储有计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行如上所述的军工科研生产数据管理方法。
32.与现有技术相比,本技术提供的军工科研生产数据管理方法及其系统,其通过人工智能技术的深度神经网络模型来从第一军工科研生产文本数据和第二军工科研生产文本数据中分别提取出具有词序列和段序列的全局性隐含关联特征,进一步融合所述词序列和所述段序列的特征信息来进行所述第一军工科研生产文本数据和所述第二军工科研生产文本数据的相似性判断,以避免了传统的处理方式造成的数据量局限性和误差难以控制的问题。
附图说明
33.通过结合附图对本技术实施例进行更详细的描述,本技术的上述以及其他目的、特征和优势将变得更加明显。附图用来提供对本技术实施例的进一步理解,并且构成说明书的一部分,与本技术实施例一起用于解释本技术,并不构成对本技术的限制。在附图中,相同的参考标号通常代表相同部件或步骤。
34.图1为根据本技术实施例的军工科研生产数据管理方法的流程图;
35.图2为根据本技术实施例的军工科研生产数据管理方法的系统架构示意图;
36.图3为根据本技术实施例的军工科研生产数据管理方法中,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量的流程图;
37.图4为根据本技术实施例的军工科研生产数据管理系统的框图;
38.图5为根据本技术实施例的军工科研生产数据管理系统中融合单元的框图。
具体实施方式
39.下面,将参考附图详细地描述根据本技术的示例实施例。显然,所描述的实施例仅仅是本技术的一部分实施例,而不是本技术的全部实施例,应理解,本技术不受这里描述的示例实施例的限制。
40.场景概述
41.如前所述,在长期的军工科研生产过程中积累了大量的数据文件,在开展数据处理与统计分析等相关工作时,面临着数据文件重复的问题,即,多个文件描述角度不同、分析层次不同、制作单位不同,但本质上描述的内容是相同的。
42.数据文件重复会给数据文件的管理带来挑战,在开展数据处理时,例如,在进行数
short-term memory)是一种时间循环神经网络,其通过增加输入门、输出门和遗忘门,使得神经网络的权重能够自我更新,在网络模型参数固定的情况下,不同时刻的权重尺度可以动态改变,从而能够避免梯度消失或者梯度膨胀的问题。所述双向长短期记忆神经网络模型是由前向lstm与后向lstm组合而成,前向lstm可以学习到当前词的前文信息而后向lstm可以学习到当前词后续文本的信息,所以通过所述双向长短期记忆神经网络模型获得的语义特征向量学习到了全局上下文的信息。
51.然后,对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量。应可以理解,所述池化操作可用于特征降维,缓解过拟合风险,降低卷积层对输入信息的过度敏感性,而所述全局均值池化能够保留每个所述特征向量的重要信息,以用于突出所述多个第一段语义特征向量和所述多个第二段语义特征向量中响应最重要的部分。继而,为了更充分提取出所述文本数据中的高维隐含性特征信息,还需要将池化后的数据进行序列编码,以更能够体现出所述文本数据中的语义特征。也就是,具体地,将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量。
52.进而,再将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量。这样,就可以分别融合所述第一军工科研生产文本数据和所述第二军工科研生产文本数据中的每个段和每个词的全局性特征关联信息,以综合全局性特征信息来进行分类,就可以获得相似性的结果,也就是,所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据的分类结果。
53.但是,考虑到每个所述段-词多粒度全文语义特征向量都经过了上下文编码器 卷积神经网络与双向长短期记忆模型 序列编码器的并行架构,这使得所获得的所述段-词多粒度全文语义特征向量容易由于特征的深度前向传播导致特征分布的失配,从而影响融合效果。
54.基于此,对所述第一段-词多粒度全文语义特征向量v1和所述第二段-词多粒度全文语义特征向量v2进行分层深度单应对齐融合,即:
[0055][0056]
其中,v1表示所述第一段-词多粒度全文语义特征向量,v2表示所述第二段-词多粒度全文语义特征向量,vc表示所述分类特征向量,||
·
||1表示向量的一范数,且||
·
||f表示矩阵的frobenius范数,表示按位置差分,
⊙
表示按位置点乘,表示按位置加和,表示所述场景深度流特征值,||v
1tv2
||f表示所述全场景单应矩阵的frobenius范数。
[0057]
这里,分层深度单应对齐技术基于对象-场景的融合对齐原则,通过向量差分的一范数来表达场景深度流,并通过向量关联矩阵来表达全场景单应矩阵,以对向量的信息融合表征进行分层深度特性的单应性对齐,由此,即使所述第一段-词多粒度全文语义特征向量v1和所述第二段-词多粒度全文语义特征向量v2之间由于特征的深度前向传播存在特征
分布的失配,也可以通过单应性对齐来提高向量的深度融合效果,进而提高分类的准确性。
[0058]
基于此,本技术提出了一种军工科研生产数据管理方法,其包括:获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段;将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量;将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及,将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
[0059]
在介绍了本技术的基本原理之后,下面将参考附图来具体介绍本技术的各种非限制性实施例。
[0060]
示例性方法
[0061]
图1图示了军工科研生产数据管理方法的流程图。如图1所示,根据本技术实施例的军工科研生产数据管理方法,包括:s110,获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;s120,将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;s130,将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;s140,将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;s150,对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段;s160,将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;s170,对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段
语义输入向量和第二段语义输入向量;s180,将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;s190,将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;s200,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及,s210,将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
[0062]
图2图示了根据本技术实施例的军工科研生产数据管理方法的架构示意图。如图2所示,在所述军工科研生产数据管理方法的网络架构中,首先,将获得的所述第一军工科研生产文本数据(例如,如图2中所示意的p1)和所述第二军工科研生产文本数据(例如,如图2中所示意的p2)进行分词处理后通过包含嵌入层的上下文编码器(例如,如图2中所示意的e1)以得到多个第一词特征向量(例如,如图2中所示意的vf1)和多个第二词特征向量(例如,如图2中所示意的vf2);接着,将所述多个第一词特征向量进行二维排列为第一词特征矩阵(例如,如图2中所示意的m1)后通过作为词粒度特征提取器的第一卷积神经网络(例如,如图2中所示意的cnn1)以得到第一全文语义特征矩阵(例如,如图2中所示意的mf1);然后,将所述多个第二词特征向量进行二维排列为第二词特征矩阵(例如,如图2中所示意的m2)后通过作为词粒度特征提取器的第二卷积神经网络(例如,如图2中所示意的cnn2)以得到第二全文语义特征矩阵(例如,如图2中所示意的mf2);接着,对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段(例如,如图2中所示意的q1)和对应于所述第二军工科研生产文本数据的多个第二段(例如,如图2中所示意的q2);然后,将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型(例如,如图2中所示意的cnn)以得到多个第一段语义特征向量(例如,如图2中所示意的vl1)和多个第二段语义特征向量(例如,如图2中所示意的vl2);接着,对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量(例如,如图2中所示意的vs1)和第二段语义输入向量(例如,如图2中所示意的vs2);然后,将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器(例如,如图2中所示意的e2)以得到第一全文语义特征向量(例如,如图2中所示意的vt1)和第二全文语义特征向量(例如,如图2中所示意的vt2);接着,将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量(例如,如图2中所示意的v1),且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量(例如,如图2中所示意的v2);然后,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量(例如,如图2中所示意的vf);以及,最后,将所述分类特征向量通过分类器(例如,如图2中所示意的圈s)以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
[0063]
在步骤s110和步骤s120中,获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据,并将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量。如前所述,相较于传统的人工判别方案,例如由有经验的资深专家来判断多份文件本质内容是否相同,基于深度学习的神经网络的判别方案能够从文本数据中提取到高维隐含特征以摆脱人为的数据处理量的局限性以及误差的不可控性。由于这本质上是一个分类的问题,也就是,基于所提供的两份文本的相似性分析进而来对于是否为重复文本数据进行分类判断,考虑到深度学习的卷积神经网络模型在数据的关联隐含特征提取方面具有重要的作用,因此,在本技术的技术方案中,使用卷积神经网络模型来提取出所述两份文本数据的相互隐含关联特征信息,使得分类的精准度更高。
[0064]
具体地,在本技术的技术方案中,首先,获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据。应可以理解,考虑到所述第一军工科研生产文本数据和所述第二军工科研生产文本数据都是文本数据,为了分别提取出这两者的所述文本数据中的全局性关联特征分布信息,使用包含嵌入层的上下文编码器对分词处理后的所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行编码,以在避免词序混乱的基础上提取出文本数据中隐含的全局性关联特征分布信息,从而得到多个第一词特征向量和多个第二词特征向量。
[0065]
具体地,在本技术实施例中,将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量的过程,包括:对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理以将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别转化为由多个词组成的词序列以获得第一词序列和第二词序列;使用所述上下文编码器的嵌入层将所述第一词序列和所述第二词序列中各个词分别映射到词向量以获得第一词向量的序列和第二词向量的序列;使用所述上下文编码器的转化器对所述第一词向量的序列和所述第二词向量的序列分别进行基于全局的上下文语义编码以获得所述多个第一词特征向量和所述多个第二词特征向量。
[0066]
在步骤s130和步骤s140中,将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵,并将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵。也就是,在本技术的技术方案中,进一步将所述多个第一词特征向量和所述多个第二词特征向量分别进行二维排列为第一和第二词特征矩阵,以整合所述第一军工科研生产文本数据和所述第二军工科研生产文本数据的全局性关联特征信息后通过作为词粒度特征提取器的卷积神经网络中进行处理,以挖掘出所述第一军工科研生产文本数据和所述第二军工科研生产文本数据中的深层次的文本数据间的对于全局的隐含特征信息,从而得到第一全文语义特征矩阵和第二全文语义特征矩阵。
[0067]
具体地,在本技术实施例中,将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵的过程,包括:所述第一卷积神经网络的各层在层的正向传递中对输入数据分别进行:对
输入数据进行卷积处理以得到卷积特征图;对所述卷积特征图进行基于局部通道维度的均值池化以得到池化特征图;以及,对所述池化特征图进行非线性激活以得到激活特征图;其中,所述第一卷积神经网络的最后一层的输出为所述第一全文语义特征矩阵,所述第一卷积神经网络的第一层的输入为所述第一词特征矩阵。
[0068]
具体地,在本技术实施例中,将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵的过程,包括:所述第二卷积神经网络的各层在层的正向传递中对输入数据分别进行:对输入数据进行卷积处理以得到卷积特征图;对所述卷积特征图进行基于局部通道维度的均值池化以得到池化特征图;以及,对所述池化特征图进行非线性激活以得到激活特征图;其中,所述第二卷积神经网络的最后一层的输出为所述第二全文语义特征矩阵,所述第二卷积神经网络的第一层的输入为所述第二词特征矩阵。
[0069]
在步骤s150和步骤s160中,对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段,并将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量。应可以理解,为了使得提取到的特征信息更能够充分利用所述第一军工科研生产文本数据和所述第二军工科研生产文本数据中的信息来进行分类,还需要对于所述文本数据进行分段的特征提取处理。也就是,在本技术的技术方案汇总,对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段。
[0070]
然后,使用包含嵌入层的双向长短期记忆神经网络模型对所述多个第一段中各个第一段和所述多个第二段中各个第二段进行深层的特征提取,以得到多个第一段语义特征向量和多个第二段语义特征向量。应可以理解,所述双向长短期记忆神经网络模型(lstm,long short-term memory)是一种时间循环神经网络,其通过增加输入门、输出门和遗忘门,使得神经网络的权重能够自我更新,在网络模型参数固定的情况下,不同时刻的权重尺度可以动态改变,从而能够避免梯度消失或者梯度膨胀的问题。所述双向长短期记忆神经网络模型是由前向lstm与后向lstm组合而成,前向lstm可以学习到当前词的前文信息而后向lstm可以学习到当前词后续文本的信息,所以通过所述双向长短期记忆神经网络模型获得的语义特征向量学习到了全局上下文的信息。
[0071]
在步骤s170和步骤s180中,对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量,并将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量。也就是,在本技术的技术方案中,进一步对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量。应可以理解,所述池化操作可用于特征降维,缓解过拟合风险,降低卷积层对输入信息的过度敏感性,而所述全局均值池化能够保留每个所述特征向量的重要信息,以用于突出所述多个
第一段语义特征向量和所述多个第二段语义特征向量中响应最重要的部分。继而,为了更充分提取出所述文本数据中的段间的高维隐含性特征信息,还需要将池化后的数据进行序列编码,以更能够体现出所述文本数据中的段间语义特征。也就是,具体地,将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量。
[0072]
具体地,在本技术实施例中,对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量的过程,包括:对所述多个第一段语义特征向量中各个第一段语义特征向量进行全局均值池化以得到对应于各个第一段语义特征向量的第一段语义特征向量;将所述对应于各个第一段语义特征向量的第一段语义特征向量排列为所述第一段语义输入向量;对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局均值池化以得到对应于各个第二段语义特征向量的第二段语义特征向量;将所述对应于各个第二段语义特征向量的第二段语义特征向量排列为所述第二段语义输入向量。
[0073]
具体地,在本技术实施例中,将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量的过程,包括:使用所述序列编码器的全连接层以如下公式分别对所述第一段语义输入向量和所述第二段语义输入向量进行全连接编码以提取出所述输入向量中各个位置的特征值的高维隐含特征,其中,所述公式为:其中x是所述输入向量,y是输出向量,w是权重矩阵,b是偏置向量,表示矩阵乘;使用所述序列编码器的一维卷积层以如下公式分别对所述第一段语义输入向量和所述第二段语义输入向量进行一维卷积编码以提取出所述输入向量中各个位置的特征值间的高维隐含关联特征,其中,所述公式为:
[0074][0075]
其中,a为卷积核在x方向上的宽度、f为卷积核参数向量、g为与卷积核函数运算的局部向量矩阵,w为卷积核的尺寸。
[0076]
在步骤s190中,将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量。也就是,在本技术的技术方案中,进一步再将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘,就可以分别融合所述第一军工科研生产文本数据和所述第二军工科研生产文本数据中的每个段和每个词的全局性特征关联信息,以综合全局性特征信息来进行分类,就可以获得相似性的结果,也就是,所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据的分类结果。
[0077]
在步骤s200中,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量。应可以理解,考虑到每个所述段-词多粒度全
文语义特征向量都经过了上下文编码器 卷积神经网络与双向长短期记忆模型 序列编码器的并行架构,这使得所获得的所述段-词多粒度全文语义特征向量容易由于特征的深度前向传播导致特征分布的失配,从而影响融合效果。因此,在本技术的技术方案中,进一步对所述第一段-词多粒度全文语义特征向量v1和所述第二段-词多粒度全文语义特征向量v2进行分层深度单应对齐融合。应可以理解,所述分层深度单应对齐技术基于对象-场景的融合对齐原则,通过向量差分的一范数来表达场景深度流,并通过向量关联矩阵来表达全场景单应矩阵,以对向量的信息融合表征进行分层深度特性的单应性对齐,由此,即使所述第一段-词多粒度全文语义特征向量v1和所述第二段-词多粒度全文语义特征向量v2之间由于特征的深度前向传播存在特征分布的失配,也可以通过所述单应性对齐来提高向量的深度融合效果,进而提高分类的准确性。
[0078]
具体地,在本技术实施例中,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量的过程,包括:首先,计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置差分以得到差分特征向量。接着,计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置加和以得到初始融合特征向量。然后,计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的全场景单应矩阵,所述全场景单应矩阵为所述所述第一段-词多粒度全文语义特征向量的转置向量与所述第二段-词多粒度全文语义特征向量之间的乘积。接着,计算所述差分特征向量的一范数作为场景深度流特征值。然后,对所述初始融合特征向量进行对数运算以得到对数化初始融合特征向量,其中,所述对所述初始融合特征向量进行对数运算表示计算所述初始融合特征向量中各个位置的特征值的对数函数值。接着,计算所述全场景单应矩阵的frobenius范数。最后,以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量。
[0079]
相应地,在一个具体示例中,以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项以如下公式对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量;
[0080]
其中,所述公式为:
[0081][0082]
其中,v1表示所述第一段-词多粒度全文语义特征向量,v2表示所述第二段-词多粒度全文语义特征向量,vc表示所述分类特征向量,||
·
||1表示向量的一范数,且||
·
||f表示矩阵的frobenius范数,表示按位置差分,
⊙
表示按位置点乘,表示按位置加和,表示所述场景深度流特征值,||v
1tv2
||f表示所述全场景单应矩阵的frobenius范数。
[0083]
图3图示了根据本技术实施例的军工科研生产数据管理方法中,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量的流程图。如图3所示,融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量,包括:s201,计算所述第一段-词多粒度全文
语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置差分以得到差分特征向量;s202,计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置加和以得到初始融合特征向量;s203,计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的全场景单应矩阵,所述全场景单应矩阵为所述所述第一段-词多粒度全文语义特征向量的转置向量与所述第二段-词多粒度全文语义特征向量之间的乘积;s204,计算所述差分特征向量的一范数作为场景深度流特征值;s205,对所述初始融合特征向量进行对数运算以得到对数化初始融合特征向量,其中,所述对所述初始融合特征向量进行对数运算表示计算所述初始融合特征向量中各个位置的特征值的对数函数值;s206,计算所述全场景单应矩阵的frobenius范数;以及,s207,以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量。
[0084]
在步骤s210中,将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。也就是,在一个具体示例中,使用所述分类器以如下公式对所述分类特征向量进行处理以获得所述分类结果,其中,所述公式为:softmax{(wn,bn):
…
:(w1,b1)|x},其中,w1到wn为权重矩阵,b1到bn为偏置向量,x为所述分类特征向量。
[0085]
综上,本技术实施例的军工科研生产数据管理方法被阐明,其通过人工智能技术的深度神经网络模型来从第一军工科研生产文本数据和第二军工科研生产文本数据中分别提取出具有词序列和段序列的全局性隐含关联特征,进一步融合所述词序列和所述段序列的特征信息来进行所述第一军工科研生产文本数据和所述第二军工科研生产文本数据的相似性判断,以避免了传统的处理方式造成的数据量局限性和误差难以控制的问题。
[0086]
示例性系统
[0087]
图4图示了根据本技术实施例的军工科研生产数据管理系统的框图。如图4所示,根据本技术实施例的军工科研生产数据管理系统400,包括:文本数据获取单元410,用于获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;上下文编码单元420,用于将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;第一特征提取单元430,用于将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;第二特征提取单元440,用于将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;分段处理单元450,用于对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段;双向长短期记忆编码单元460,用于将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;全局池化单元470,用于对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入
向量和第二段语义输入向量;序列编码单元480,用于将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;关联相乘单元490,用于将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;融合单元500,用于融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及,分类单元510,用于将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
[0088]
在一个示例中,在上述军工科研生产数据管理系统400中,所述上下文编码单元420,进一步用于:对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理以将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别转化为由多个词组成的词序列以获得第一词序列和第二词序列;使用所述上下文编码器的嵌入层将所述第一词序列和所述第二词序列中各个词分别映射到词向量以获得第一词向量的序列和第二词向量的序列;以及,使用所述上下文编码器的转化器对所述第一词向量的序列和所述第二词向量的序列分别进行基于全局的上下文语义编码以获得所述多个第一词特征向量和所述多个第二词特征向量。
[0089]
在一个示例中,在上述军工科研生产数据管理系统400中,所述第一特征提取单元430,包括:所述第一卷积神经网络的各层在层的正向传递中对输入数据分别进行:对输入数据进行卷积处理以得到卷积特征图;对所述卷积特征图进行基于局部通道维度的均值池化以得到池化特征图;以及,对所述池化特征图进行非线性激活以得到激活特征图;其中,所述第一卷积神经网络的最后一层的输出为所述第一全文语义特征矩阵,所述第一卷积神经网络的第一层的输入为所述第一词特征矩阵。
[0090]
在一个示例中,在上述军工科研生产数据管理系统400中,所述第二特征提取单元440,进一步用于:所述第二卷积神经网络的各层在层的正向传递中对输入数据分别进行:对输入数据进行卷积处理以得到卷积特征图;对所述卷积特征图进行基于局部通道维度的均值池化以得到池化特征图;以及,对所述池化特征图进行非线性激活以得到激活特征图;其中,所述第二卷积神经网络的最后一层的输出为所述第二全文语义特征矩阵,所述第二卷积神经网络的第一层的输入为所述第二词特征矩阵。
[0091]
在一个示例中,在上述军工科研生产数据管理系统400中,所述全局池化单元470,进一步用于:对所述多个第一段语义特征向量中各个第一段语义特征向量进行全局均值池化以得到对应于各个第一段语义特征向量的第一段语义特征向量;将所述对应于各个第一段语义特征向量的第一段语义特征向量排列为所述第一段语义输入向量;对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局均值池化以得到对应于各个第二段语义特征向量的第二段语义特征向量;将所述对应于各个第二段语义特征向量的第二段语义特征向量排列为所述第二段语义输入向量。
[0092]
在一个示例中,在上述军工科研生产数据管理系统400中,所述序列编码单元480,进一步用于:使用所述序列编码器的全连接层以如下公式分别对所述第一段语义输入向量和所述第二段语义输入向量进行全连接编码以提取出所述输入向量中各个位置的特征值
的高维隐含特征,其中,所述公式为:其中x是所述输入向量,y是输出向量,w是权重矩阵,b是偏置向量,表示矩阵乘;使用所述序列编码器的一维卷积层以如下公式分别对所述第一段语义输入向量和所述第二段语义输入向量进行一维卷积编码以提取出所述输入向量中各个位置的特征值间的高维隐含关联特征,其中,所述公式为:
[0093][0094]
其中,a为卷积核在x方向上的宽度、f为卷积核参数向量、g为与卷积核函数运算的局部向量矩阵,w为卷积核的尺寸。
[0095]
在一个示例中,在上述军工科研生产数据管理系统400中,如图5所示,所述融合单元500,包括:差分子单元501,用于计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置差分以得到差分特征向量;加和子单元502,用于计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置加和以得到初始融合特征向量;全场景单应矩阵生成子单元503,用于计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的全场景单应矩阵,所述全场景单应矩阵为所述所述第一段-词多粒度全文语义特征向量的转置向量与所述第二段-词多粒度全文语义特征向量之间的乘积;一范数子单元504,用于计算所述差分特征向量的一范数作为场景深度流特征值;对数化子单元505,用于对所述初始融合特征向量进行对数运算以得到对数化初始融合特征向量,其中,所述对所述初始融合特征向量进行对数运算表示计算所述初始融合特征向量中各个位置的特征值的对数函数值;范数计算子单元506,用于计算所述全场景单应矩阵的frobenius范数;以及,线性变换子单元507,用于以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量。
[0096]
在一个示例中,在上述军工科研生产数据管理系统400中,所述线性变换子单元507,进一步用于:以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项以如下公式对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量;
[0097]
其中,所述公式为:
[0098][0099]
其中,v1表示所述第一段-词多粒度全文语义特征向量,v2表示所述第二段-词多粒度全文语义特征向量,vc表示所述分类特征向量,||
·
||1表示向量的一范数,且||
·
||f表示矩阵的frobenius范数,表示按位置差分,
⊙
表示按位置点乘,表示按位置加和,表示所述场景深度流特征值,||v
1tv2
||f表示所述全场景单应矩阵的frobenius范数。
[0100]
在一个示例中,在上述军工科研生产数据管理系统400中,所述分类单元510,进一步用于:使用所述分类器以如下公式对所述分类特征向量进行处理以获得所述分类结果,
其中,所述公式为:softmax{(wn,bn):
…
:(w1,b1)|x},其中,w1到wn为权重矩阵,b1到bn为偏置向量,x为所述分类特征向量。
[0101]
这里,本领域技术人员可以理解,上述军工科研生产数据管理系统400中的各个单元和模块的具体功能和操作已经在上面参考图1到图3的军工科研生产数据管理方法的描述中得到了详细介绍,并因此,将省略其重复描述。
[0102]
如上所述,根据本技术实施例的军工科研生产数据管理系统400可以实现在各种终端设备中,例如基于知识图谱的军工科研生产数据相似性判别算法的服务器等。在一个示例中,根据本技术实施例的军工科研生产数据管理系统400可以作为一个软件模块和/或硬件模块而集成到终端设备中。例如,该军工科研生产数据管理系统400可以是该终端设备的操作系统中的一个软件模块,或者可以是针对于该终端设备所开发的一个应用程序;当然,该军工科研生产数据管理系统400同样可以是该终端设备的众多硬件模块之一。
[0103]
替换地,在另一示例中,该军工科研生产数据管理系统400与该终端设备也可以是分立的设备,并且该军工科研生产数据管理系统400可以通过有线和/或无线网络连接到该终端设备,并且按照约定的数据格式来传输交互信息。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。