技术特征:
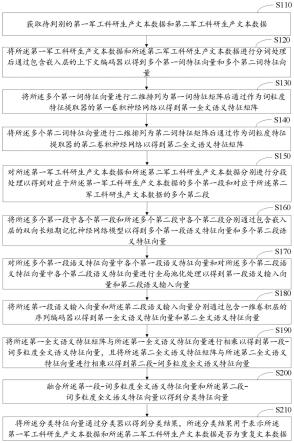
1.一种军工科研生产数据管理方法,其特征在于,包括:获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段;将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量;将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。2.根据权利要求1所述的军工科研生产数据管理方法,其特征在于,所述将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量,包括:对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理以将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别转化为由多个词组成的词序列以获得第一词序列和第二词序列;使用所述上下文编码器的嵌入层将所述第一词序列和所述第二词序列中各个词分别映射到词向量以获得第一词向量的序列和第二词向量的序列;以及使用所述上下文编码器的转化器对所述第一词向量的序列和所述第二词向量的序列分别进行基于全局的上下文语义编码以获得所述多个第一词特征向量和所述多个第二词特征向量。3.根据权利要求2所述的军工科研生产数据管理方法,其特征在于,所述将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积
神经网络以得到第一全文语义特征矩阵,包括:所述第一卷积神经网络的各层在层的正向传递中对输入数据分别进行:对输入数据进行卷积处理以得到卷积特征图;对所述卷积特征图进行基于局部通道维度的均值池化以得到池化特征图;以及对所述池化特征图进行非线性激活以得到激活特征图;其中,所述第一卷积神经网络的最后一层的输出为所述第一全文语义特征矩阵,所述第一卷积神经网络的第一层的输入为所述第一词特征矩阵。4.根据权利要求3所述的军工科研生产数据管理方法,其特征在于,所述将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵,包括:所述第二卷积神经网络的各层在层的正向传递中对输入数据分别进行:对输入数据进行卷积处理以得到卷积特征图;对所述卷积特征图进行基于局部通道维度的均值池化以得到池化特征图;以及对所述池化特征图进行非线性激活以得到激活特征图;其中,所述第二卷积神经网络的最后一层的输出为所述第二全文语义特征矩阵,所述第二卷积神经网络的第一层的输入为所述第二词特征矩阵。5.根据权利要求4所述的军工科研生产数据管理方法,其特征在于,所述对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量,包括:对所述多个第一段语义特征向量中各个第一段语义特征向量进行全局均值池化以得到对应于各个第一段语义特征向量的第一段语义特征向量;将所述对应于各个第一段语义特征向量的第一段语义特征向量排列为所述第一段语义输入向量;对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局均值池化以得到对应于各个第二段语义特征向量的第二段语义特征向量;和将所述对应于各个第二段语义特征向量的第二段语义特征向量排列为所述第二段语义输入向量。6.根据权利要求5所述的军工科研生产数据管理方法,其特征在于,所述将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量,包括:使用所述序列编码器的全连接层以如下公式分别对所述第一段语义输入向量和所述第二段语义输入向量进行全连接编码以提取出所述输入向量中各个位置的特征值的高维隐含特征,其中,所述公式为:其中x是所述输入向量,y是输出向量,w是权重矩阵,b是偏置向量,表示矩阵乘;使用所述序列编码器的一维卷积层以如下公式分别对所述第一段语义输入向量和所述第二段语义输入向量进行一维卷积编码以提取出所述输入向量中各个位置的特征值间的高维隐含关联特征,其中,所述公式为:
其中,a为卷积核在x方向上的宽度、f为卷积核参数向量、g为与卷积核函数运算的局部向量矩阵,w为卷积核的尺寸。7.根据权利要求6所述的军工科研生产数据管理方法,其特征在于,所述融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量,包括:计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置差分以得到差分特征向量;计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的按位置加和以得到初始融合特征向量;计算所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量之间的全场景单应矩阵,所述全场景单应矩阵为所述所述第一段-词多粒度全文语义特征向量的转置向量与所述第二段-词多粒度全文语义特征向量之间的乘积;计算所述差分特征向量的一范数作为场景深度流特征值;对所述初始融合特征向量进行对数运算以得到对数化初始融合特征向量,其中,所述对所述初始融合特征向量进行对数运算表示计算所述初始融合特征向量中各个位置的特征值的对数函数值;计算所述全场景单应矩阵的frobenius范数;以及以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量。8.根据权利要求7所述的军工科研生产数据管理方法,其特征在于,所述以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量,包括:以所述场景深度流特征值作为加权权重和所述所述全场景单应矩阵的frobenius范数作为偏置项以如下公式对所述对数化初始融合特征向量进行线性变换处理以得到所述分类特征向量;其中,所述公式为:其中,v1表示所述第一段-词多粒度全文语义特征向量,v2表示所述第二段-词多粒度全文语义特征向量,v
c
表示所述分类特征向量,||
·
||1表示向量的一范数,且||
·
||
f
表示矩阵的frobenius范数,表示按位置差分,
⊙
表示按位置点乘,表示按位置加和,表示所述场景深度流特征值,||v
1tv2
||
f
表示所述全场景单应矩阵的frobenius范数。9.根据权利要求8所述的军工科研生产数据管理方法,其特征在于,所述将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据,包括:
使用所述分类器以如下公式对所述分类特征向量进行处理以获得所述分类结果,其中,所述公式为:softmax{(w
n
,b
n
):
…
:(w1,b1)|x},其中,w1到w
n
为权重矩阵,b1到b
n
为偏置向量,x为所述分类特征向量。10.一种军工科研生产数据管理系统,其特征在于,包括:文本数据获取单元,用于获取待判别的第一军工科研生产文本数据和第二军工科研生产文本数据;上下文编码单元,用于将所述第一军工科研生产文本数据和所述第二军工科研生产文本数据进行分词处理后通过包含嵌入层的上下文编码器以得到多个第一词特征向量和多个第二词特征向量;第一特征提取单元,用于将所述多个第一词特征向量进行二维排列为第一词特征矩阵后通过作为词粒度特征提取器的第一卷积神经网络以得到第一全文语义特征矩阵;第二特征提取单元,用于将所述多个第二词特征向量进行二维排列为第二词特征矩阵后通过作为词粒度特征提取器的第二卷积神经网络以得到第二全文语义特征矩阵;分段处理单元,用于对所述第一军工科研生产文本数据和所述第二军工科研生产文本数据分别进行分段处理以得到对应于所述第一军工科研生产文本数据的多个第一段和对应于所述第二军工科研生产文本数据的多个第二段;双向长短期记忆编码单元,用于将所述多个第一段中各个第一段和所述多个第二段中各个第二段分别通过包含嵌入层的双向长短期记忆神经网络模型以得到多个第一段语义特征向量和多个第二段语义特征向量;全局池化单元,用于对所述多个第一段语义特征向量中各个第一段语义特征向量和对所述多个第二段语义特征向量中各个第二段语义特征向量进行全局池化处理以得到第一段语义输入向量和第二段语义输入向量;序列编码单元,用于将所述第一段语义输入向量和所述第二段语义输入向量分别通过包含一维卷积层的序列编码器以得到第一全文语义特征向量和第二全文语义特征向量;关联相乘单元,用于将所述第一全文语义特征矩阵与所述第一全文语义特征向量进行相乘以得到第一段-词多粒度全文语义特征向量,且将所述第二全文语义特征矩阵与所述第二全文语义特征向量进行相乘以得到第二段-词多粒度全文语义特征向量;融合单元,用于融合所述第一段-词多粒度全文语义特征向量和所述第二段-词多粒度全文语义特征向量以得到分类特征向量;以及分类单元,用于将所述分类特征向量通过分类器以得到分类结果,所述分类结果用于表示所述第一军工科研生产文本数据和所述第二军工科研生产文本数据是否为重复文本数据。
技术总结
本申请涉及相似性智能判别的领域,其具体地公开了一种军工科研生产数据管理方法及系统,其通过人工智能技术的深度神经网络模型来从第一军工科研生产文本数据和第二军工科研生产文本数据中分别提取出具有词序列和段序列的全局性隐含关联特征,进一步融合所述词序列和所述段序列的特征信息来进行所述第一军工科研生产文本数据和所述第二军工科研生产文本数据的相似性判断,以避免了传统的处理方式造成的数据量局限性和误差难以控制的问题。式造成的数据量局限性和误差难以控制的问题。式造成的数据量局限性和误差难以控制的问题。
技术研发人员:田林涛 陆平 严真旭 张峰 张斌 廖大中 赵亿锌 张春宇
受保护的技术使用者:中国信息通信研究院
技术研发日:2022.08.17
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。