1.本发明属于通信技术领域,具体涉及一种提高基于决策树的数据包分类速率的方法。
背景技术:
2.数据包分类算法是网络中常用的一种算法。其目的是按照报文携带的头部信息,一般是源ip、目的ip、源端口、目的端口和协议号这5个维度,把报文分成不同的种类,从而可以对其进行不同的处理。常见的应用有:访问控制列表、防火墙、基于流的计费统计。在核心网络设备和边缘网络设备中均有不同的应用。
3.进行数据包分类首先需要定义一套规则集,按照数据包的头部信息在规则集中进行查找。图1为规则示例,各个字段依次表示:源ip地址值/源ip掩码、目的ip地址值/目的ip掩码、源端口号范围、目的端口号范围和协议号值/协议号掩码值。每条规则都表示了一个范围,掩码小的规则表示的范围大。
4.在众多数据包分类算法中,hypersplit决策树是常用的一种。
5.然而,hypersplit决策树存在两个明显的问题:
6.1)原始用户策略集中的策略所表示的范围存在交集,由此在决策树创建过程中将父节点的策略划分至两个子节点时,会造成策略的复制,进而导致决决策树的层数过多。
7.2)使用原始的用户策略集创建决策树时,在将父节点的策略划分至两个子节点时,需要同时考虑划分的均匀性和策略复制程度小两个因素。如果仅考虑均匀性时,父节点的策略会平均分配给两个子节点,决策树的层数为log
2 n,其中n是策略集合中策略的总条数。而在额外考虑复制程度小时,父节点的策略不再能够平均分配给两个子节点,从而会导致决策树的最大层数过多,进而导致基于决策树的数据包分类的最坏查找速率过低。
8.3)决策树的创建是期望以逐层的局部最优来逼近全局最优的效果。逐层局部最优指的是每个节点的策略划分都依据当前节点信息规划最佳的划分方式,该最佳划分方式通过信息熵来保证。而全局最优指的是整棵决策树的平均层数和最大层数在所有建树方式中均最小。在建树完成后,叶子节点的多条策略可以基于优先级合并为一条策略,这种合并方案减少了整个决策树的存储需求,提升了查询性能。然而由于合并导致决策树的各个分支包含的规则数量发生变化,原有的平衡性被破坏,决策树存在进一步优化的可能性。
技术实现要素:
9.(一)要解决的技术问题
10.本发明要解决的技术问题是:如何设计一种提高基于决策树的数据包分类速率的方法。
11.(二)技术方案
12.为了解决上述技术问题,本发明提供了一种提高基于决策树的数据包分类速率的方法,包括以下步骤:
13.1)根据用户输入的原始策略集,创建第1棵决策树;
14.2)遍历第1棵决策树,将该决策树的每个叶子节点中的策略输出到策略文件;
15.3)释放第1棵决策树;
16.4)读取策略文件,从而获得新的策略集,新的策略集中的策略没有交集;
17.5)根据新的策略集,创建第2棵决策树,在该第2棵决策树中进行数据包的查找。
18.优选地,第1棵、第2棵决策树的结构相同,决策树中,成为叶子节点的依据为:节点仅拥有一条策略;或,节点拥有多条策略,但是策略在子节点间无法再被划分开,即子节点均拥有与父节点相同的策略。
19.优选地,决策树中,根节点拥有策略数组中的全部策略,同一条策略可被划分给多个子节点。
20.优选地,第1棵决策树、第2棵决策树的创建过程相同,创建过程如下:
21.11)创建根节点,将策略集合中的所有策略分配给根节点;
22.12)计算当前节点的最大信息熵;
23.13)如果最大信息熵为0,则将当前节点标记为叶子节点;否则执行步骤14);
24.14)创建左右子节点,将最大信息熵所对应的边沿值作为划分边沿值;利用所述划分边沿值将父节点的策略划分至左右两个子节点;
25.15)分别将左右子节点作为新的父节点;
26.16)重复步骤12)至15),直至hypersplit决策树的所有路径的末端是叶子节点。
27.优选地,步骤14中,通过最大信息熵选取划分父节点的策略至两个子节点的划分边沿值的过程如下:
28.步骤141:设父节点中包含若干条策略,策略条数记为cur,这些策略待划分至左右子节点;统计父节点的策略在不同维度的不同边沿值,假设不同边沿值个数为num_edge;定义num_edge对计数器,每个边沿值对应一对计数器{lc,rc},lc表示使用指定边沿值将父节点策略划分至左子节点的条数,rc表示使用指定边沿值将父节点策略划分至右子节点的条数;将num_edge对计数器初始化为0,执行步骤142;
29.步骤142:获取父节点中的一条策略filt,执行步骤143;
30.步骤143:选取步骤141中的一个边沿值cut_value,执行步骤144;
31.步骤144:设dim表示cut_value所属的维度;filt表示存储策略所有维度的低边沿值和高边沿值的变量,filt-》value[dim][0]表示策略filt在dim维度的低边沿值,filt-》value[dim][1]表示策略filt在dim维度的高边沿值;
[0032]
如果策略在dim维度的低边沿值小于或等于待选的划分边沿值cut_value,说明策略filt将被划分至左子节点,则执行步骤146;否则执行步骤145;
[0033]
步骤145:如果策略在dim维度的高边沿值大于待选的划分边沿值cut_value,说明策略filt将被划分至右子节点,则执行步骤147;否则分别执行步骤146和步骤147,说明策略filt将被同时划分至左子节点和右子节点;
[0034]
步骤146:左计数器lcn自增一,执行步骤148;
[0035]
步骤147:右计数器rcn自增一,执行步骤148;
[0036]
步骤148:重复步骤143至步骤147,直到指定filt的对num_edge个边沿值的计数统计完成,执行步骤149;
[0037]
步骤149:重复步骤142至步骤148,直到将父节点的所有策略在num_edge个边沿值的计数统计完,执行步骤1410;
[0038]
步骤1410:得到共计num_edge对计数器,执行步骤1411;
[0039]
步骤1411:根据num_edge对计数器计算出num_edge个信息熵,最大信息熵所对应的边沿值即为父节点策略的划分边沿值。
[0040]
优选地,信息熵的计算公式如下所示:
[0041][0042]
其中:
[0043]
表示父节点策略划分至左子节点的百分比;
[0044]
表示父节点策略划分至右子节点的百分比;
[0045]
0《a《=1,0《b《=1,a b》=1。
[0046]
优选地,信息熵的计算公式中的部分,表示父节点策略划分至两个子节点的均匀程度,该值越大,说明策略划分越均匀;公式中的log2(a b)部分,表示父节点的策略在划分至两个子节点时的复制程度,该值越大说明复制程度越高。
[0047]
优选地,当父节点的一条策略同时划分至两个子节点,则称该策略发生了一次复制。
[0048]
本发明还提供了一种用于实现所述方法的提高基于决策树的数据包分类速率的系统。
[0049]
本发明还提供了一种所述方法在通信技术领域中的应用。
[0050]
(三)有益效果
[0051]
1.通过信息熵能够计算出最佳的划分边沿值,能够将父节点的策略尽可能地平均划分至两个子节点。
[0052]
2.当某节点的信息熵为零时将该节点标记为叶子节点,信息熵为零能够确保叶子节点中的多条规则能够合并为一条。
[0053]
3.根据原始用户策略集创建决策树,将叶子节点中的策略输出到策略文件,生成新的策略集,新策略集中的策略没有交集。通过首次创建决策树,将有交集的原始策略集转换为了没有交集的新策略集。
[0054]
4.根据新策略集创建决策树时,由于新策略集中的策略没有交集,在父节点的策略划分至子节点时,不会发生策略复制,父节点中的策略几乎平分给两个子节点,降低了决策树的平均层数和最大层数,提高了数据包的平均查找速率和最坏查找速率。根据没有交集的策略集合创建的决策树的平均层数和最大层数,相比于根据原始策略集创建的决策树的平均层数和最大层数,分别减少20%和10%。因此本发明能够将基于决策树的数据包分类的平均速率和最坏速率分别提升20%和10%。
附图说明
[0055]
图1为五元组规则示例;
[0056]
图2为本发明方法整体处理流程图;
[0057]
图3为本发明设计的决策树的整体结构示意图;
[0058]
图4为本发明设计的决策树创建的整体流程图;
[0059]
图5为本发明设计的通过最大信息熵选取最佳划分边沿值的流程图;
[0060]
图6为策略划分至子节点后的变化示意图。
具体实施方式
[0061]
为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
[0062]
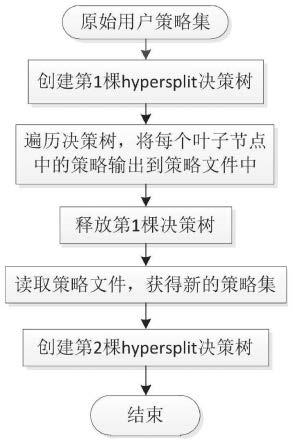
本发明提供的一种提高基于决策树的数据包分类速率的方法,将原始策略集转换为新的策略集合,新策略集合中的策略不存在交集。在使用新的策略集合创建决策树的过程中,由于策略间没有交集,因此能将策略从父节点均匀地划分至两个子节点,降低了决策树的平均层数和最大层数。本发明通过两次创建决策树,达到降低决策树平均层数和最大层数的目的。整体处理流程如图2所示,包括以下步骤:
[0063]
1)根据用户输入的原始策略集,创建第1棵决策树;
[0064]
2)遍历第1棵决策树,将该决策树的每个叶子节点中的策略输出到策略文件;
[0065]
3)此时创建第1棵决策树的目的达成,因此,释放第1棵决策树;
[0066]
4)读取策略文件,从而获得新的策略集。通过创建第1棵决策树,将原始策略集转换为新的策略集。新的策略集中的策略没有交集,这是由决策树的创建原理决定的。决策树的创建过程在下文中简要说明。
[0067]
5)根据新的策略集,创建第2棵(hypersplit)决策树;数据包的查找在该第2棵决策树中进行。
[0068]
下面通过一个示例图说明决策树的整体结构,第1棵、第2棵决策树的结构相同。
[0069]
在图3中,假设策略集中共有10条策略,基于这10条策略创建了上面的决策树。对图3中决策树的基本信息描述如下:
[0070]
1)圆形表示决策树中的节点;圆形上方的数字表示策略数组的索引,即表示节点拥有这些策略;
[0071]
2)“leaf”节点表示叶子节点,“cld”节点表示孩子节点;
[0072]
3)成为叶子节点的依据:
[0073]
3.1)节点仅拥有一条策略;比如第3层的第1个节点,仅拥有策略1这一条策略,因此被标记为叶子节点;
[0074]
3.2)节点拥有多条策略,但是策略在子节点间无法再被划分开,即子节点均拥有与父节点相同的策略;比如第3层中的第3个节点,拥有策略1和策略3;
[0075]
4)根节点拥有策略数组中的全部策略;
[0076]
5)策略可复制:同一条策略可被划分给多个子节点;比如第1层中的第1个节点中的策略1被划分给了它的两个子节点。
[0077]
6)为降低树高,进而提高数据包的查找速率,期望父节点的策略能够均匀地划分
给子节点。
[0078]
如图4所示,对hypersplit决策树的创建过程说明如下(第1棵决策树、第2棵决策树的创建过程相同):
[0079]
11)创建根节点,将策略集合中的所有策略分配给根节点;
[0080]
12)计算当前节点的最大信息熵;
[0081]
13)如果最大信息熵为0,则将当前节点标记为叶子节点;否则执行步骤14);
[0082]
14)创建左右子节点,将最大信息熵所对应的边沿值作为划分边沿值;利用所述划分边沿值将父节点的策略划分至左右两个子节点;
[0083]
15)以深度优先递归方法处理左右子节点,分别将左右子节点作为新的父节点;
[0084]
16)重复步骤12)至15),直至hypersplit决策树的所有路径的末端是叶子节点。
[0085]
如图5所示,步骤14中,通过最大信息熵选取划分父节点的策略至两个子节点的划分边沿值的过程如下:
[0086]
步骤141:设父节点中包含若干条策略,策略条数记为cur,这些策略待划分至左右子节点;统计父节点的策略在不同维度的不同边沿值,假设不同边沿值个数为num_edge;定义num_edge对计数器,每个边沿值对应一对计数器{lc,rc},lc表示使用指定边沿值将父节点策略划分至左子节点的条数,rc表示使用指定边沿值将父节点策略划分至右子节点的条数;将num_edge对计数器初始化为0,执行步骤142;
[0087]
步骤142:获取父节点中的一条策略filt,执行步骤143;
[0088]
步骤143:选取步骤141中的一个边沿值cut_value,执行步骤144;
[0089]
步骤144:设dim表示cut_value所属的维度;filt表示存储策略所有维度的低边沿值和高边沿值的变量,filt-》value[dim][0]表示策略filt在dim维度的低边沿值,filt-》value[dim][1]表示策略filt在dim维度的高边沿值;
[0090]
如果策略在dim维度的低边沿值小于或等于待选的划分边沿值cut_value,说明策略filt将被划分至左子节点,则执行步骤146;否则执行步骤145;
[0091]
步骤145:如果策略在dim维度的高边沿值大于待选的划分边沿值cut_value,说明策略filt将被划分至右子节点,则执行步骤147;否则分别执行步骤146和步骤147,说明策略filt将被同时划分至左子节点和右子节点;
[0092]
步骤146:左计数器(记为:lcn)自增一,执行步骤148;
[0093]
步骤147:右计数器(记为:rcn)自增一,执行步骤148;
[0094]
步骤148:重复步骤143至步骤147,直到指定filt的对num_edge个边沿值的计数统计完成,执行步骤149;
[0095]
步骤149:重复步骤142至步骤148,直到将父节点的所有策略在num_edge个边沿值的计数统计完,执行步骤1410;
[0096]
步骤1410:得到共计num_edge对计数器,执行步骤1411;
[0097]
步骤1411:根据num_edge对计数器计算出num_edge个信息熵,最大信息熵所对应的边沿值即为父节点策略的划分边沿值。
[0098]
信息熵的计算公式如下所示:
[0099]
[0100]
其中:
[0101]
1)cur表示父节点的策略条数,lc表示左子节点的策略条数,a表示父节点策略划分至左子节点的百分比;
[0102]
2)cur表示父节点的策略条数,rc表示右子节点的策略条数,b表示父节点策略划分至右子节点的百分比;
[0103]
3)0《a《=1,0《b《=1,a b》=1;
[0104]
4)公式中的部分,表示父节点策略划分至两个子节点的均匀程度,该值越大,说明策略划分越均匀;公式中的log2(a b)部分,表示父节点的策略在划分至两个子节点时的复制程度(当父节点的一条策略同时划分至两个子节点,则称该策略发生了一次复制),该值越大说明复制程度越高。完整的信息熵公式期望选取的划分比特能够将父节点的策略均匀且复制程度低地划分至左右两个子节点。
[0105]
下面描述策略从父节点被划分至子节点后的变化。如图6所示,为简化说明过程,下面所示例的策略仅包含一个维度。多个维度的策略的划分也是类似的。
[0106]
在图6中,父节点中包含两条策略,策略1的范围是0至100,策略2的范围是1至150。通过上面介绍的通过计算最大信息熵选取划分边沿值的方法,可得知使用策略1的右边沿值100划分两条策略是最佳的。划分过程如下:
[0107]
1)策略1的右边沿值100小于或等于划分边沿值100,策略1被划分至左子节点;
[0108]
2)策略2所表示的范围包含划分边沿值100,因此策略2将被划分为两部分:0至100被划分至左子节点、101至150被划分至右子节点;
[0109]
左子节点中的两条策略表示的范围相同,仅保留优先级最高的一条策略,之后左子节点被标记为叶子节点。
[0110]
右节点仅包含一条策略,直接被标记为叶子节点。
[0111]
将两个叶子节点中的策略输出到策略文件中,生成新的策略集合。原始策略集中包含0至100、0-150两条策略,这两条策略存在交集。新策略集中包的策略是0-100、101至150,这两条策略不存在交集。
[0112]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。