1.本发明属于养殖监测技术领域,具体涉及一种白羽肉鸡健康监测方法。
背景技术:
2.近年来,全球经济发展水平的不断提高,刺激了以肯德基、麦当劳、汉堡王等为代表的快餐行业。快餐行业对畜牧肉类的需求量极大,其中,肉鸡作为最具代表性的家禽肉类,占据了肉类产业结构中很大一部分比重。作为世界第二大经济体的中国,仅2020年全年的肉鸡总产量就高达1485.0万吨,较2019年增长了8.00%。经济社会的消费需求的增加不可避免的带来养殖产业的扩大,也带了人们对肉鸡产业全过程的严格把控,确保进入消费市场的肉鸡的品质,肉鸡养殖,作为整个产业的源头环节,越来越受到部门监管人员及养殖人员的重视。
3.针对采用分区域圈养的方式进行肉鸡养殖方式,整个鸡群被划分为多个小的肉鸡群体,这样,当一只肉鸡感染疾病后,疾病的传播范围会得到最大程度的限制,所造成的损失也会得到有效控制。
4.目前对于肉鸡养殖过程中的肉鸡健康监测还基本停留在人工作业的阶段。一方面,养殖人员在喂食的过程中,通过眼睛查看当前喂养区域内鸡群体的活动状态,进而判断它们的健康状况。另一方面,养殖人员会定期在各养殖区域内随机抽取固定数量的肉鸡,通过抽血化验的方式得到一份报告。养殖人员阅读报告上各项生理指标数值,可以得出被抽取肉鸡的健康状况,进而粗略判断其所在区域的肉鸡群体的健康状况。这种随机抽取的方式具有很强的主观性和随机性,存在重检和漏检的可能,要求抽取的“样本”具备广泛代表性,这是比较苛刻的。另外,在这种情况下,养殖人员需要具备较高的专业水平来进行抽血化验操作和阅读报告,这无形中增加了肉鸡养殖的成本。因此急需一种完全自动化的肉鸡健康监测方法。
5.随着电子技术、人工智能技术等的发展,也出现了一些利用自动化设备对养鸡的状态等进行检测的手段,但是目前的监测大都基于图像实现的,由于图像只能对显性特征进行良好的捕捉和判断,对于鸡群而言,当鸡群的状态不明显时,例如在少数鸡患病初期,基于图像的判断方式并不能取得良好的判断结果。同时基于图像的监测对于养鸡场这种多实例的场景进行监测时不仅计算量非常大,而且也效果也不理想,尤其是养鸡场中的鸡总是在不断的运动,更加增加了监测难度、降低了监测的准确率。
技术实现要素:
6.本发明为了解决目前针对于养鸡场环境中的肉鸡健康监测方法存在计算量大、准确率低的问题。
7.基于声音信号特征和随机森林的白羽肉鸡健康监测方法,包括以下步骤:
8.步骤一:采集一段时长为t的待识别的肉鸡声音信号,并对声音信号进行基于“带通 基本谱减法”的初步信号滤波;
9.步骤二:对声音信号进行基于维纳滤波的深度信号滤波;
10.步骤三:对声音信号进行端点检测和分帧处理,并从每个帧信号中提取α维特征,建立初步的待预测的数据集;
11.步骤四:对初步的数据集进行min-max标准化处理,得到待预测的数据集;
12.步骤五:应用基于参数优化随机森林的多分类模型对待预测的数据集进行预测;
13.步骤六:根据多数表决结果计算咳嗽率,通过咳嗽率实现白羽肉鸡健康监测。
14.进一步地,步骤三中针对每个帧信号中提取α维特征是基于60维特征筛选后确定的,基于60维特征筛选α维特征的具体过程包括以下步骤:
15.采集肉鸡声音信号,并对声音信号进行基于“带通 基本谱减法”的初步信号滤波,再进行基于维纳滤波的深度信号滤波,作为训练数据;然后对训练数据进行端点检测和分帧处理,并从每个帧信号中提取60维特征,所述的60维特征包括:
16.短时能量、短时平均过零率、短时自相关函数、短时平均幅差、短时平均幅度、谱熵、频谱质心、均方根频率、频率标准差、第1维静态特征、第2维静态特征、第3维静态特征、第4维静态特征、第5维静态特征、第6维静态特征、第7维静态特征、第8维静态特征、第9维静态特征、第10维静态特征、第11维静态特征、第12维静态特征、第13维静态特征、第1维一阶动态特征、第2维一阶动态特征、第3维一阶动态特征、第4维一阶动态特征、第5维一阶动态特征、第6维一阶动态特征、第7维一阶动态特征、第8维一阶动态特征、第9维一阶动态特征、第10维一阶动态特征、第11维一阶动态特征、第12维一阶动态特征、第13维一阶动态特征、第1维二阶动态特征、第2维二阶动态特征、第3维二阶动态特征、第4维二阶动态特征、第5维二阶动态特征、第6维二阶动态特征、第7维二阶动态特征、第8维二阶动态特征、第9维二阶动态特征、第10维二阶动态特征、第11维二阶动态特征、第12维二阶动态特征、第13维二阶动态特征、30原子匹配伸缩因子、30原子匹配平移因子、30原子匹配频率因子、30原子匹配相位因子、50原子匹配伸缩因子、50原子匹配平移因子、50原子匹配频率因子、50原子匹配相位因子、100原子匹配伸缩因子、100原子匹配平移因子、100原子匹配频率因子、100原子匹配相位因子;
17.将60维特征进行min-max标准化处理,然后基于随机森林,根据特征重要性进行筛选得到α维的特征。
18.进一步地,根据特征重要性进行筛选时的特征重要性如下:
19.(1)利用袋外数据对随机森林中的每颗决策树计算它的袋外误差,记为err1;
20.(2)对袋外数据中样本的某一特征进行噪声干扰,再对其求取袋外误差,记为err2;
21.(3)假设随机森林中有n棵树,特征的重要性可表示为:
22.进一步地,根据特征重要性进行筛选得到α维的特征的过程包括以下步骤:
23.s1、设定最低的特征重要性,作为特征选择过程的终止判断条件;
24.s2、计算每一个特征的重要性,并按照降序方式排序;
25.s3、设定每次剔除的特征数为1,依据特征的重要性排序,得出本次排序中最后一个特征,比较它的重要性与s1中设定的最低的重要性的大小;如果它的重要性小于最低重要性,则将其剔除,进而得到一个新的特征集;如果它的重要性大于最低重要性,则特征选
择过程结束;
26.s4、用新的特征集建立新的随机森林,继续计算每个特征的重要性和按照降序方式排序;
27.s5、重复s2至s4,直到s3中的判断条件成立,即特征选择过程结束,得到最优特征集,即α维的特征对应的特征集。
28.进一步地,应用基于参数优化随机森林的多分类模型对待预测的数据集进行预测的过程包括以下步骤:
29.在特征提取阶段对肉鸡声音信号进行了端点检测与分帧处理,将对应的起始帧与终止帧看作一个组合,按照时间顺序排列的多个起始帧与终止帧的组合;然后获取每个组合内帧信号的个数,并通过提取特征来形成对应数量的待预测的数据;按照时间顺序将这些待预测的数据进行排列,最终可以形成待预测的数据集;
30.通过多分类模型预测和多数表决,获得按照时间顺序排列的多个组合的共同标签,也就是一段待识别肉鸡声音信号中按照时间顺序排列的多个声音类别的识别结果;进而得到一段待识别肉鸡声音信号中各声音类别的数量。
31.进一步地,步骤六所述根据多数表决结果计算咳嗽率的过程包括以下步骤:
32.针对一段待识别的肉鸡声音信号,根据多数表决结果得到声音信号中按照时间顺序排列的各个声音类别;计算声音类别为“咳嗽声”的数量占所有声音类别的数量的比例,即咳嗽率。
33.进一步地,通过咳嗽率实现白羽肉鸡健康监测的过程是将得到的咳嗽率与标准咳嗽率进行对比,根据对比结果判断这段肉鸡声音信号中咳嗽声的频率是否正常。
34.优选地,所述标准咳嗽率为10%至12%。
35.进一步地,步骤一采集待识别的肉鸡声音信号的时长为5min。
36.有益效果:
37.(1)本发明提出了一种评价肉鸡群体健康状况的指标,即咳嗽率,并考虑将其转化为机器学习中的多分类问题进行研究。通过识别固定长度的肉鸡声音信号中不同声音类别的数量,以及各声音类别的数量,计算其中声音类别为“咳嗽声”的数量占所有声音类别的数量的比例。不仅能够实现白羽肉鸡的自动健康监测,而且具有较高的准确率,同时相比图像等方式,可以极大地节省计算量。
38.(2)本发明在研究过程中实现了基于基本谱减法、改进谱减法和维纳滤波的深度信号滤波。并分别从信号角度与识别角度出发,综合评估三种滤波方法的深度信号滤波效果。通过比较得出其中最优的维纳滤波,并将其确定为统一的深度信号滤波方法。这种滤波方式有力地保障了监测的准确性。
39.(3)本发明还从时频域、梅尔频率倒谱系数(mfcc)和稀疏表示三个方面从肉鸡声音信号中提取了多个声音特征,并对特征进行标准化处理。结合随机森林分类器和特征重要性来筛选和保留对多分类模型的分类精度贡献大的特征,提高多分类模型的计算效率和分类精度。
40.本发明对推动肉鸡产业及其他畜牧业的稳定发展具有重要的实用价值。同时,该技术对信号检测与语音识别领域相关研究的开展也具有较高的参考价值。
附图说明
41.图1为具体实施方式一的基本流程图;图2为养殖大棚的实物图;图3(a)-图3(d)为单个声音类别分别对应鸣叫声、咳嗽声、呼噜声和拍翅膀声的频谱图;图4(a)-图4(d)为正常声、咳嗽声、呼噜声、拍翅膀声经过初步信号滤波的声音类别的频谱图;图5(a)-图5(c)为基本谱减法、改进谱减法、维纳滤波对第九段声音信号的滤波效果(局部);图6(a)-图6(c)分别为一个声音类别经过基本谱减法、改进谱减法、维纳滤波处理后的波形图;图7为mfcc特征参数提取原理框图;图8为养殖大棚内某肉鸡圈养区域的现场测试图;图9为可视化平台对待识别肉鸡声音信号的自动化监测过程图。
具体实施方式
42.具体实施方式一:结合图1说明本实施方式,
43.本实施方式为基于声音信号特征和随机森林的白羽肉鸡健康监测方法,包括信号采集与处理、数据集构建、多分类模型构建与预测部分。在信号采集与处理部分,我们在肉鸡大棚内不同圈养区域放置音频信号采集系统,采集了大量肉鸡声音图2信号,并对它们进行了基于带通滤波和基本谱减法的初步信号滤波。
44.1声音信号的采集与处理
45.肉鸡声音信号于2020年12月18日在黑龙江省牡丹江市林口县柳树镇汇兴养殖场(黑龙江省,林口县,44
°
91’n,130
°
02’e)3号养殖大棚内采集,养殖大棚的实物图如图2所示。
46.利用高精度拾音器进行声音采集,高精度拾音器选用广州峰火电子股份有限公司的hd-32k数字芯高保真降噪拾音器。进行肉鸡声音信号采集的具体参数信息为:8通道同步采集,12bit分辨率,100ks/s的采样频率。高精度拾音器模块的具体参数信息为:响应频率为150hz到12 000hz,灵敏度为10mv/pa。控制高精度拾音器模块每间隔30s采集一段时长为5min的肉鸡声音信号,采集的肉鸡声音信号为数字式的字符流信号。
47.进行端点检测,也叫语音活动检测(voice activity detection,vad),它的目的是对声音信号中的语音和非语音的区域进行区分。通过设定检测阈值为前导无话帧能量总和的1.5倍,可以提取其中有效的语音区域。
48.通过对端点检测后保存的肉鸡声音信号进行识别,发现采集的肉鸡声音信号中能够被检测出来的声音包括:鸣叫声、咳嗽声、呼噜声和拍翅膀声四种。其中,鸣叫声为健康肉鸡生长过程中自然发出的短促的啼叫声,声音较为响亮尖锐。咳嗽声为患病肉鸡发出的拖长的异常鸣叫声,声音较为低沉。呼噜声为肉鸡的喉咙中卡有异物时发出的低沉的,作连续起伏状的声音。拍翅膀声为肉鸡活动时煽动翅膀与空气摩擦振动产生的,声音振幅较大且连续时间长。
49.借助音频剪辑软件,从保存的肉鸡声音信号中剪辑出多个鸣叫声、咳嗽声、呼噜声与拍翅膀声的声音片段。随机选取一个鸣叫声、咳嗽声、呼噜声与拍翅膀声的声音片段,并利用matlab分别对它们进行频谱分析,得到如图3(a)至图3(d)所示的频谱图。
50.从图3(a)至图3(d)中可以看出,未经信号滤波的原始声音信号中包含较大的噪声干扰,需要对其进行初步的信号滤波来保留尽可能多的有用的声音信号。进一步放大分析单个声音类别的频谱分布,可以发现,鸣叫声的频谱分布范围为800hz至2200hz,咳嗽声的
频谱分布范围为1100hz至2300hz,呼噜声的频谱分布范围为1000hz至1800hz,拍翅膀声的频谱分布范围为800hz至3200hz。所以综合进行考虑,四种声音类别的频谱分布范围均在800hz至3000hz之间。因此,在采集终端的软件程序中,我们一方面添加了带通滤波器的程序设计,将滤波器的频带范围设置为600h至3200hz。另一方面,我们结合基本谱减法,对经过带通滤波处理的声音信号再次进行信号滤波,初步得到信噪比较高的肉鸡声音信号。这种“带通滤波 基本谱减法”的组合滤波方式称为初步信号滤波,并在采集终端的软件程序中添加该滤波算法,实现对采集的原始声音信号的初步滤波。处理完的声音信号最终发送至远程pc端进行保存。
51.图4(a)至图4(d)展示了经过初步信号滤波的声音类别的频谱图。从图中可以看出,对比未经滤波的单个声音类别的频谱,声音信号在时域和频域上的表现得到了明显的改善,但是仍存在一定的噪声干扰,且不可忽视,所以我们会在远程pc端对经过初步信号滤波的肉鸡声音信号进行深度的信号滤波,以期得到表现最优的声音信号。
52.本实施方式中,在采用“带通滤波 基本谱减法”的组合滤波方式初步滤波后,还要进行深度滤波,深度滤波选择基本谱减法、改进谱减法与维纳滤波进行对比。从信号角度出发,选取信噪比(snr)和均方根误差(rmse)两个指标对三种滤波方法的处理效果进行评价。
53.设原始肉鸡信号为x(n)=d(n) u(n),其中x(n)为音频信号采集系统捕获的肉鸡声音信号,d(n)和u(n)分别表示声音信号中的语音和噪声。那么,信噪比是指一段声音信号中语音(也即有用信号)与噪声的比例。往往经过某种滤波方法处理后的声音信号的信噪比越大,表明使用当前滤波方法的处理效果越好。其表达式为:
[0054][0055]
均方根误差是指滤波前后的声音信号之间方差的均方根。往往经过某种滤波方法处理后的声音信号的均方根误差越小,说明滤波后的声音信号越接近于无噪信号,表明使用当前滤波方法的处理效果越好。其表达式为:
[0056][0057]
式中,f(n)为滤波处理后的声音信号。
[0058]
从识别角度出发,我们分别采用三种滤波方法对相同的肉鸡声音信号进行处理,并从处理后的声音信号中提取相同的特征形成各自的数据集。我们使用基于机器学习分类算法的分类器对三个数据集分别进行分类预测,得到三个分类精度。此时,分类器在哪个数据集上取得的分类精度最高,说明该数据集的质量最好,也就意味着构成该数据集的声音信号的质量最好。需要说明的是,我们这里统一提取语音识别领域常用的39维的mfcc特征,形成对应三种滤波方法的数据集。我们选择默认参数配置下的决策树和朴素贝叶斯作为分类器,分别对三个数据集进行分类预测,共得到六个分类精度。在对分类精度进行综合考虑的基础上确定最优的滤波方法。选择决策树和朴素贝叶斯作为分类器,是因为前者是基于“树”的理论,后者是基于经典的数学理论,两者在原理上是不相关的。笔者选择它们对数据集分别进行预测,并且综合评估它们的预测结果,可以得出具有说服力的结论。事实上,对
于一个高质量的数据集和低质量的数据集,不管是基于何种分类算法的分类器得出的结论应该是一致的。即在高质量的数据集上取得更高的分类精度。另外,这里没有选择基于随机森林的分类器,是为了确保最后训练的用于肉鸡健康监测的多分类模型的泛化能力。即,如果从肉鸡声音信号采集到训练得到多分类模型的过程中,涉及到分类预测的部分均采用随机森林算法,会使得整个过程都是为它“量身打造”的一样,容易导致过拟合。出于同样的考虑,我们提取了39维的mfcc而不是本研究提到的所有特征。也是因为不管数据集是由多少特征组成的,只要数据集的组成特征一样,就可以比较三种滤波算法的滤波性能,而且能够避免过拟合的现象。
[0059]
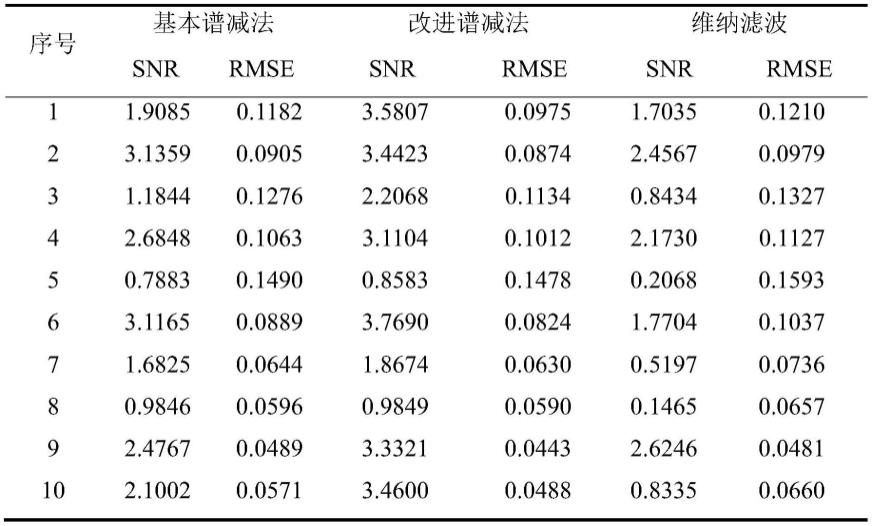
我们从信号角度进行评价。随机挑选10段在训练阶段采集的肉鸡声音信号,称为10段实验用肉鸡声音信号。在matlab上依次读取上述10端声音信号对应的信号文件。对于每个信号文件(即每段肉鸡声音信号),分别执行三种滤波方法的软件程序对它们进行信号滤波。在此基础上,我们计算不同滤波方法处理后肉鸡声音信号的信噪比和均方根误差,完成对它们的滤波效果的评估。表1示出了10段实验用肉鸡声音信号分别经过三种滤波方法处理后计算得到的snr和rmse。
[0060]
表1 10段实验用肉鸡声音信号计算得到的snr和rmse
[0061][0062][0063]
从表1可以看出,利用改进谱减法对声音信号进行处理后取得的信噪比大于利用基本谱减法对声音信号进行处理后取得的,利用改进谱减法对声音信号进行处理后取得的均方根误差略小于利用基本谱减法对声音信号进行处理后取得的。考虑到声音信号在滤波前后的信噪比越大或均方根误差越小说明滤波处理效果越好,因此从信号角度出发进行分析,改进谱减法的滤波处理效果要优于基本谱减法。同时,利用改进谱减法对声音信号进行处理后取得的信噪比大于利用维纳滤波对声音信号进行处理后取得的,利用改进谱减法对声音信号进行处理后取得的均方根误差小于利用维纳滤波对声音信号进行处理后取得的。基于同样的信噪比与均方根误差的判断规则,从信号角度出发进行综合分析,改进谱减法
的滤波处理效果要优于维纳滤波。从表中还可以看出,滤波处理前后效果最明显的是第9个声音信号,它在三种滤波方法中都得到了较好的结果。考虑到在matlab上直接绘制和显示5min肉鸡声音信号的波形图会带来观察不便的问题,我们先绘制和显示前4.4s声音信号的波形图,以此来展示不同滤波方法对声音信号的滤波效果,如图5(a)至图5(c)所示。
[0064]
更进一步的,我们截取和显示该段声音信号中一个声音类别经过不同滤波方法处理后的波形图,如图6(a)至图6(c)所示。从图6(c)中我们可以看出,利用维纳滤波进行处理后的声音信号在开始一段无话帧之前还存在一段噪声,如图中方框标注所示。因此,我们在计算经过三种滤波方法处理后10段实验用肉鸡声音信号的信噪比和均方根误差时,维纳滤波的计算结果不佳,这也是维纳滤波从信号角度出发进行分析时,滤波处理效果没有改进谱减法好的原因。
[0065]
其次,我们从识别角度进行评价。在同样利用matlab读取“.m4a”格式信号文件并分别进行三种滤波方法处理后,我们不计算它们的snr和rmse,而是分别从三种滤波方法处理后的10段实验用肉鸡声音信号中提取39维mfcc特征,形成对应三种滤波方法的数据集。具体来说,从机器学习的角度出发,“.m4a”格式的音频信号不能直接应用于多分类模型的训练,需要将其转化成多条单维的数据格式。因此,首先需要利用matlab对每段实验用肉鸡声音信号进行分帧处理和端点检测。我们利用matlab的enframe函数将设置每40个采样点为一个帧信号,相邻两个帧信号的起始点之间间隔5个采样点。由于设置的采样频率为100ks/s,所以在本研究中每个帧信号时长0.4ms,相邻两个帧信号之间间隔0.05ms。这样,每个帧信号的都能计算得到39维mfcc特征的具体数值,进而形成一条单维的数据。具体来说,对于一段肉鸡声音信号,我们通过分帧处理和端点检测可以获取这段声音信号中单个声音类别的起始帧和终止帧,则在它们之间的所有帧信号都被认定为属于同一个声音类别。如我们对一段声音信号进行分帧处理和端点检测后,获取到第10帧为鸣叫声的起始帧,第55帧为鸣叫声的终止帧,则第10至55帧信号我们认定属于鸣叫声,由此可以提取出46个标签为鸣叫声的数据。通过这种方式,我们对分别经过三种滤波方法处理后的10段实验用肉鸡声音信号进行分帧处理和端点检测,并通过人工作业方式对每个起始帧与终止帧对应的单个声音类别进行识别,由此完成对对应的多条数据的标签标注工作,最终形成如表2所示的对应不同滤波方法的数据集。需要说明的是,因为不同滤波方法的处理效果不同,带来处理后的声音信号中包含的语音与噪声的成分不同,所以即使是10段相同的声音信号,最终提取的数据个数也是不一样的。
[0066]
表2三种滤波方法对应数据集
[0067][0068]
我们选择默认参数配置下的决策树和朴素贝叶斯作为分类器,分别对上述三个数据集进行预测。为了得到相对准确的预测结果,所有实验测试都在同一台电脑上运行。每个
数据集进行10次分类预测,取10次分类预测的平均值作为最终的分类精度,以此来减少随机误差。表3、表4示分别出了基于决策树和朴素贝叶斯的分类器的分类预测结果。
[0069]
表3基于决策树的分类器在不同数据集上取得的预测结果
[0070][0071]
表4基于朴素贝叶斯的分类器在不同数据集上取得的预测结果
[0072][0073][0074]
从上表可以看出,当我们分别采用基于决策树和朴素贝叶斯的分类器对三个数据集进行预测时,基于决策树和朴素贝叶斯的分类器在经过改进谱减法处理后形成的数据集上取得的平均分类精度比在经过基本谱减法处理后形成的数据集上取得的高2.6%和2.0%左右。因此,从识别角度出发进行分析,改进谱减法对声音信号进行处理的效果要优于基本谱减法,与从信号角度出发分析时得出的结论一致。同样的,两个分类器在经过维纳滤波处理后形成的数据集上取得的平均分类精度比在经过改进谱减法处理后形成的数据集上取得的分别高9.5%和3.8%左右,说明从识别角度出发进行分析,维纳滤波对声音信号进行处理的效果要优于改进谱减法。因此,从识别角度出发进行综合分析,维纳滤波的滤波效果最好。
[0075]
我们从信号角度与识别角度进行综合考虑,由信噪比和最小均方误差可得,改进谱减法的滤波效果要优于维纳滤波,但由基于决策树和朴素贝叶斯的分类器取得的分类精度可得,维纳滤波的滤波效果要优于改进谱减法。从图6中可以明显看出,利用维纳滤波处理后的声音信号在开始一段无话帧之前还存在一段噪声。而我们在计算经过维纳滤波处理的声音信号的信噪比和最小均方误差时,是将这段噪声纳入到计算范围的。因此,从信号角度出发,改进谱减法要优于维纳滤波。但从识别角度出发,在提取39维特征时,需要对声音信号进行端点检测。通过设定检测阈值,可以将这段噪声舍弃掉。因此,从识别角度出发,维纳滤波要优于改进谱减法。
[0076]
我们设计matlab软件程序对经过维纳滤波处理后的声音信号中存在的前导噪声进行舍弃处理,并再次计算10段实验用肉鸡声音信号的信噪比和均方根误差。最终得到新的平均信噪比为2.7079,新的均方根误差为0.0858。可以看出,去除前导噪声后计算的信噪
高于改进谱减法。计算的均方根误差虽然大于但是接近于改进谱减法,但是明显小于其他滤波方法。因此,从信号角度与识别角度出发进行综合考虑时,我们可以得出维纳滤波的处理效果最优。更重要的是,本研究的目的是要构建预测性能良好的多分类模型来预测一段肉鸡声音信号中不同的声音类别的数量,以及各声音类别的数量,进而完成肉鸡健康监测。这让我们在进行选择时更加注重识别角度的评价结果,并且维纳滤波在该角度取得了绝对的性能优势。最终确定维纳滤波作为肉鸡声音信号的深度信号滤波方法。
[0077]
2数据集构建
[0078]
机器学习领域中,“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”由此可见,合适的特征和高质量的数据的对于机器学习的重要性,很大程度上特征和数据的质量越好,训练的多分类模型取得的分类精度就越高。具体的,我们从时频域、梅尔频率倒谱系数和稀疏表示三个方面来提取60维语音识别领域常用的特征,形成初步的数据集。我们利用特征标准化与归一化处理方法对初步的数据集进行处理,得到数据分布均衡的数据集。我们对提取的60维特征进行筛选,保留对多分类模型分类精度贡献大的高质量的30维特征,并由从形成高质量的数据集。
[0079]
a.时频域特征
[0080]
时域特征指的是在信号随时间变化的过程中,所具有的一些与时间特性相关的特征。因此,可以从时域上对肉鸡声音信号展开分析。已知声音信号为x(n),经过分帧处理后的第i帧的声音信号为xi(n),l为帧长,fn为总帧数。
[0081]
(1)短时能量用来表征声音信号的能量大小,其定义为:
[0082][0083]
(2)短时平均过零率是指每个帧信号中信号波形穿过横轴(零电平)的次数。其定义为:
[0084][0085]
(3)短时自相关函数用来描述声音信号与其自身在不同时间点的互相关程度,其定义为:
[0086][0087]
式中,k为延迟量。
[0088]
(4)由于自相关计算过程涉及到乘法运算,需要较大的时间开销,因此进一步采用差值计算方法提出了短时平均幅差,其定义为:
[0089][0090]
(5)不同于短时能量的求平方和,本发明还利用求绝对值的短时平均幅度来描述声音信号的能量大小,其定义为:
[0091][0092]
b.频域特征
[0093]
由于肉鸡声音信号实际上是一维时域信号,很难直观看到频率的变化规律。因此,可以考虑使用傅里叶变换将其转换到频域上展开分析。已知声音信号为x(n),经过分帧处理后的第i帧声音信号为xi(n),经fft变换后,n为fft长度。
[0094]
(1)谱熵描述了功率谱和熵率之间的关系。其定义式为:
[0095][0096]
式中,pi(k)为第i帧第k个频率分量对应的概率密度。
[0097]
(2)频谱质心为频率成分的重心,其定义式为:
[0098][0099]
式中,x(f)为信号的频率幅度谱,f1为频谱的上限截止频率,f2为频谱的下限截止频率,从频谱质心上可以看出声音信号的频率范围。
[0100]
(3)均方根频率为对所求的频谱再求取均方根,其定义式为:
[0101][0102]
(4)频率标准差为对所求的频谱再求取方差,其定义式为:
[0103][0104]
式中,s(i)=|x(i)|2,表示信号的能量谱。
[0105]
c.mfcc
[0106]
梅尔频率域考虑了人类听觉系统中耳蜗基底模对频率感知的非线性特征,在低频区域分辨率高而在高频区域分辨率低,是一种简洁的听觉感知域实现方式。我们使用的梅尔频率倒谱系数是从梅尔频率域中提取出来的倒谱参数,即mfcc也考虑到了人类听觉敏感度的特征,它先将线性频谱映射到基于听觉感知的梅尔非线性频谱中,然后再转换到倒谱上。mfcc特征参数提取原理框图如图7所示。
[0107]
取dtc后的第1至13个倒谱系数作为标准的13维mfcc参数,它反应了声音信号的静态特性,声音信号的动态特性可由静态特征的差分来获得,静态特征的一阶差分反映声音信号的变化速度,二阶差分反映声音信号的变化加速度。我们将标准的mfcc参数与一阶差分、二阶差分相结合,共得到39维mfcc特征参数,即39维的mfcc特征。
[0108]
d.稀疏表示
[0109]
我们进一步引入正交匹配追踪算法(omp)。我们再次引入遗传算法对omp算法进行优化,最终形成本发明使用的ga-omp算法。
[0110]
在ga-omp进行信号重构时,为了更好的描述信号的时变特性,通常选用过完备的时频原子字典。由于gabor字典具有较好的时频特性,因此我们选用其作为过完备字典:
[0111][0112]
其中,为高斯窗函数,γ=(s,μ,v,ω)为时频参数,s为伸缩因子,μ为平移因子,v为频率因子,ω为相位因子。
[0113]
时频参数的空间可以离化为γ=(αj,pαjδμ,kα-j
δv,iδω)其中α=2,δμ=1/2,δv=π,δω=π/6,0≤p<n2-j 1
,0≤k<2
j 1
,0≤i≤12,n为每帧的样本数。由于gabor字典具有较好的时频特性,因此我们可以对其时频参数进行特征提取,并由此得到4维的时频特征,称为4维的稀疏表示特征。
[0114]
由于提取特征时需要进行稀疏重构,如果不规定匹配原子的数量,尽管重构后的信号质量有所提升,但对于性能一般的计算机来说,处理时间会比较漫长,所以需要对匹配的原子数量进行规定。经过深度的研究和多次试验验证,确定分别使用30、50和100个原子进行稀疏重构并提取特征,并得到12维的稀疏表示特征。
[0115]
最终,我们从时频域、mfcc和稀疏表示三个方面共确定提取60维特征。表5给出了60维特征的具体描述。表中的“符号表示”代表它们在软件程序中变量的命名。参照2.1.2节中表2所示数据集的构建过程,我们从经过维纳滤波处理后的10段实验用肉鸡声音信号中提取上述60维特征,形成初步的数据集。
[0116]
表5 60维特征的具体描述
[0117]
[0118][0119]
基于数据库的60维特征进行特征选择:
[0120]
在初步数据集中,每个特征对应的特征数据的数值分布是不同的,并且存在较大的差异。如短时自相关函数的数值分布在-0.6至0.6之间,而均方根频率的数值分布在15000至18000之间,它们之间相差了近4000倍。这就带来多分类模型对待不同的特征时厚此薄彼的问题。为了降低特征间数值分布不均衡的影响,选择min-max标准化方法对初步的数据集进行处理。其计算公式为:
[0121]
m=(x-x
min
)/(x
max-x
min
)
[0122]
式中,m是标准化后的特征值,x是标准化前的特征值,x
min
是特征数据中的最小特征值,x
max
是特征数据中的最大特征值。
[0123]
同样选用默认参数配置下的决策树和朴素贝叶斯作为分类器,对标准化处理前后的数据集进行10次预测,预测结果如表6所示。从表中可以看出,基于决策树和朴素贝叶斯
的分类器在min-max标准化处理后的数据集上取得的平均分类精度均高于处理前,分别提高了0.6%和0.95%。
[0124]
表6基于决策树和朴素贝叶斯的分类器在标准化处理前后数据集上取得的分类精度
[0125][0126]
考虑到60维特征不可避免的会带来计算复杂度大的问题,且60维特征中会存在一些对提高多分类模型的分类精度贡献不大的特征,甚至会中和那些表现优异特征的贡献,因此我们采用基于模型的过滤式特征选择方法对60维声音特征进行筛选。
[0127]
因为随机森林本身就具有利用其分类精度作为对特征重要性进行评估的机制,所以我们直接使用它来结合特征重要性,对上述60维特征进行选择。随机森林根据特征重要性进行计算的方式如下:
[0128]
(1)利用袋外数据对随机森林中的每颗决策树计算它的袋外误差,记为err1。
[0129]
(2)对袋外数据中样本的某一特征进行噪声干扰,再对其求取袋外误差,记为err2。
[0130]
(3)假设随机森林中有n棵树,那么这个特征的重要性可表示为:
[0131][0132]
利用这个计算结果作为评判特征的重要性是因为,若某个特征在加入噪声干扰前后的袋外误差相差较大,则说明这个特征的对于样本的分类准确度具有较大影响,也就从侧面说明它的重要程度较高。
[0133]
在得到特征重要性的基础上,特征选择的步骤如下:
[0134]
步骤一:设定最低的特征重要性,作为特征选择过程的终止判断条件;
[0135]
步骤二:计算每一个特征的重要性,并按照降序方式排序;
[0136]
步骤三:设定每次剔除的特征数为1,依据特征的重要性排序,得出本次排序中最
后一个特征,比较它的重要性与步骤一中设定的最低的重要性的大小。如果它的重要性小于最低重要性,则将其剔除,这样就可以得到一个新的特征集。如果它的重要性大于最低重要性,则特征选择过程结束;
[0137]
步骤四:用新的特征集建立新的随机森林,继续计算每个特征的重要性和按照降序方式排序;
[0138]
步骤五:重复步骤二至步骤四,直到步骤三中的判断条件成立,即特征选择过程结束,得到最优特征集。
[0139]
通过设定最低的特征重要性为全部特征的重要性的均值,我们对60维特征的数据集进行特征选择,最终剩余30维特征。它们的具体描述如表7所示。
[0140]
表7保留的30维特征的具体描述
[0141][0142][0143]
值的注意的是,我们可以在60维特征的数据集基础上直接删减得到30维特征的数据集。我们同样利用默认参数配置下的基于决策树和朴素贝叶斯的分类模型,对特征选择前后的30维特征数据集和60维特征数据集分别进行10次预测,得到的预测结果如表8所示。
[0144]
表8基于决策树和朴素贝叶斯的分类器在特征选择前后的数据集上取得的分类精度
[0145][0146]
从表中可以看出,当我们使用基于决策树的分类器进行预测时,无论是单次分类精度,还是平均分类精度,分类器在30维特征形成的数据集上取得的分类精度都要高于在60维特征形成的数据集上取得的。当我们使用基于朴素贝叶斯的分类器进行预测时,分类器在30维特征形成的数据集上取得的平均分类精度同样高于在60维特征形成的数据集上取得的,与前者得出的结论一致。总体来说,基于决策树和朴素贝叶斯的分类器在30维特征形成的数据集上取得的预测精度要比在60维特征形成的数据集上取得的分别高3.1%和0.7%左右。最终,在对初步数据集进行min-max标准化处理的基础上,我们可以确定保留其中的30维特征来构建用于多分类模型训练的高质量的数据集。
[0147]
3多分类模型构建
[0148]
将得到的数据集按照7:3的比例分为训练集和测试集,分别用于多分类模型的训练与优化以及分类性能测试。我们选择机器学习领域常用的几种分类算法,在训练集上训练基于不同分类算法的多分类模型,并在测试集上测试各多分类模型的分类性能。我们选择性能较优者对其进行参数优化,通过网格搜索法寻找最佳的参数组合来使其分类性能达到最佳。
[0149]
前述过程中利用音频信号采集系统采集了10段实验用肉鸡声音信号,并在随后进行深度信号滤波、特征提取、标准化处理和特征提取等处理过程,最终建立了用于构建多分类模型的高质量的数据集。数据集中包含的数据总个数为28891个,其中,20124个数据用于构建训练集,8667个数据用于构建测试集。其具体描述如表9所示。
[0150]
表9数据集的具体描述
[0151][0152]
机器学习中常用的分类算法包括支持向量机、决策树、随机森林、朴素贝叶斯等。我们将上述分类算法带入训练集进行多分类模型的训练,并将训练好的多个多分类模型带入测试集进行预测。为了得到相对准确的预测结果,每个多分类模型同样进行10次预测来减少随机误差影响。
[0153]
表10列出了基于四种分类算法的多分类模型取得的分类精度,所有测试都是在同一台电脑下进行。从分类精度上可以看出,基于随机森林、支持向量机、决策树及朴素贝叶斯的多分类模型取得的分类精度依次递减,分别为90.57%、88.30%、81.29%以及73.74%。其中,基于随机森林的多分类模型取得的分类精度最高。经典的支持向量机主要是针对二分类取得的分类性能稍差一些。基于朴素贝叶斯的多分类模型取得的分类精度最低,这是因为朴素贝叶斯是一种基于特征条件独立假设的分类方法,而我们从肉鸡声音信号中提取的30维特征,在各自的域上都存在一定的联系,所有的特征并不完全独立,因此取得的分类精度较低。
[0154]
表10基于四种分类算法的多分类模型取得的分类精度
[0155][0156][0157]
表11示出了基于四种分类算法的多分类模型对不同声音类别(标签)的查准率、召回率和f1值,可以看出基于随机森林的多分类模型的查准率、召回率和f1值都相对较高,均
达到了84%以上。结合表10和表11的分类预测结果,我们最终确定选用基于随机森林的多分类模型。接下来我们将对选用的多分类模型进一步进行参数优化设计,以期得到一个性能最优的用于肉鸡健康状况监测的多分类模型。
[0158]
表11基于四种分类算法的多分类模型的其他性能度量
[0159][0160]
参数优化:我们主要对随机森林的n_estimators、max_depth和max_features进行参数优化设计。n_estimators是指基分类器决策树的个数。max_depth是指基分类器决策树的最大深度。max_features是指最大的特征数。参数优化较为常见的方法为网格搜索,在指定参数范围后,网格搜索会以遍历所有的参数组合来进行寻优,直到得到最优参数组合。我们得到随机森林的最优参数组合如表12所示。我们将基于随机森林的多分类模型的参数设置为表12中的最优值,并将最优的多分类模型带入测试集进行10次预测。我们同样取这10次测试的平均分类精度与优化前取得的平均分类精度进行对比,如表13所示。可以看出,参数优化设计后的多分类模型取得的平均分类精度为91.14%,相比较于优化前提升了0.6%左右。
[0161]
表12随机森林的最优参数组合
[0162][0163]
表13参数优化前后的多分类模型取得的分类精度
[0164][0165]
我们训练并优化了基于随机森林的多分类模型,可以将其应用于肉鸡健康监测中。事实上,它仅能实现预测数据集中所有数据的标签,距离实现肉鸡健康监测还有一段距离。这段距离主要体现在对多分类模型给出数据集的预测结果的处理上,以及评价肉鸡群体健康状态的咳嗽率的定义上。
[0166]
多分类模型实际上实现的是对一个待预测数据集中各个数据的标签的预测过程,给出的预测结果也并不是对一段待识别的肉鸡声音信号的识别结果。因此,不管是从预测结果到识别结果,还是待预测数据集到待识别的肉鸡声音信号,中间都需要增加一个处理步骤。这也就是对数据的标签的预测结果的多数表决过程。
[0167]
具体来说,我们在特征提取阶段会对肉鸡声音信号进行端点检测与分帧处理。所以,一段肉鸡声音信号可以处理成按照时间顺序排列的多个声音类别。我们利用端点检测可以获取这段声音信号中每个声音类别的起始帧与终止帧,并将对应的起始帧与终止帧看作一个组合。如,第一个声音类别的起始帧为第10帧,终止帧为第55帧。第二个声音类别的起始帧为67帧,终止帧为第135帧等。这样,通过端点检测获取的起始帧与终止帧的组合的数量就代表了肉鸡声音信号中声音类别的数量。我们通过获取每个组合内包含的帧信号的数量,就可以知道每个声音类别形成的待预测数据的数量。如第一对组合共包含46个帧信号,这表明对应的声音类别可以形成46个待预测数据。第二对组合共包含68个帧信号,这表明对应的声音类别可以形成68个待预测数据。我们应用多分类模型对第一个声音类别形成的46个待预测数据进行预测,可以得到46个预测的标签,也即46个预测结果。我们对这46个预测结果进行多数表决,得出得票数最高的一个标签,将其视为这46个待预测数据的共同标签。这样,根据共同标签我们也就得到了第一个声音类别的具体内容。如,这46个待预测数据的共同标签为“咳嗽声”,我们可以得到第一声音类别是咳嗽声。
[0168]
由此可以看出,对于一段待识别的肉鸡声音信号,我们可以将其处理成按照时间顺序排列的多个起始帧与终止帧的组合。我们获取每个组合内帧信号的个数,并通过提取特征来形成对应数量的待预测的数据。我们同样按照时间顺序将这些待预测的数据进行排列,最终可以形成待预测的数据集。这样,只要知道待识别的声音类别的序号和待预测数据的数量,通过多分类模型预测和多数表决,我们可以获得按照时间顺序排列的多个组合的共同标签,也就是一段待识别肉鸡声音信号中按照时间顺序排列的多个声音类别的识别结
果。至此,我们可以得到一段待识别肉鸡声音信号中声音类别的数量,以及各声音类别的数量。
[0169]
可以通过识别一段时长为5分钟的声音信号中肉鸡群体发出咳嗽声的频率完成肉鸡健康的判断。为了实现同样的肉鸡健康监测效果,我们训练一个多分类模型,量化“肉鸡群体发出咳嗽声的频率”这一判断标准。对于一段待识别的肉鸡声音信号,我们可以识别声音信号中按照时间顺序排列的各个声音类别。咳嗽率定义为声音类别为“咳嗽声”的数量占所有声音类别的数量的比例。由此可以看出,这里的咳嗽率实际上更适合称为一种比率。
[0170]
这样,对于一段待识别的肉鸡声音信号,最终可以计算它的咳嗽率。在此之前,首先需要确定标准的咳嗽率,标准的咳嗽率可以视为一个参照对象。对于任何一段待识别的肉鸡声音信号,我们计算它的咳嗽率,并将其与标准咳嗽率进行对比。根据对比结果来判断这段肉鸡声音信号中咳嗽声的频率是否正常。通过追溯这段声音信号来源的肉鸡圈养区域,可以完成对该区域内肉鸡群体健康的判断。值得说明的是,在不同肉鸡圈养区域内进行多次测试,最终确定标准咳嗽率设定在10%至12%的范围内较为合适。
[0171]
至此,整体功能已经全部完成。在此基础上,给出本发明所提肉鸡健康监测技术的一般程序步骤。
[0172]
步骤一:利用音频信号采集系统采集一段时长为5min的待识别的肉鸡声音信号,并对声音信号进行基于“带通 基本谱减法”的初步信号滤波。
[0173]
步骤二:对声音信号进行基于维纳滤波的深度信号滤波。
[0174]
步骤三:对声音信号进行端点检测和分帧处理,并从每个帧信号中提取30维特征,建立初步的待预测的数据集。
[0175]
步骤四:对初步的数据集进行min-max标准化处理,形成高质量的待预测的数据集。
[0176]
步骤五:应用基于参数优化随机森林的多分类模型对待预测的数据集进行预测,并将预测结果保存为txt文件。
[0177]
步骤六:读取txt文件,完成多数表决和计算咳嗽率。如果事先设置了预警阈值(标准咳嗽率),则将计算的咳嗽率与预警阈值进行对比,判断是否需要弹出窗口进行报警信息提示。
[0178]
为了评估训练好的多分类模型的分类性能,需要确定具体的评估指标。本实施例主要选取了分类精度、查准率、召回率和f值作为评估指标,评价多分类模型在数据集上的分类效果。
[0179]
假设数据集d={(x
(1)
,y
(1)
),
…
,(x
(n)
,y
(n)
)},其对应的真实标签值y
(n)
∈{1,
…
,c},我们用分类器(多分类模型)对数据集中的每一条数据进行预测,得到的预测标签值为分类精度可表示为标签预测正确的数据数占总数据数的比例,即:
[0180][0181]
其中,i(
·
)为指示函数。
[0182]
对于数据集中的各个标签(类别)来说,预测结果的混淆矩阵如表14所示。
[0183]
表14预测结果混淆矩阵
[0184][0185]
如果希望对每个标签都进行性能评估,就需要计算查准率和召回率。查准率,也叫精度或精确率,它表示所有预测为正类的数据中真正的正类所占的比例。其定义为:
[0186][0187]
召回率,也叫查全率,它表示真正的正类数据中预测为正类所占的比例。其定义为:
[0188][0189]
f值是一个综合指标,为查准率和召回率的调和平均。其定义为:
[0190][0191]
其中,β用于平衡查准率和召回率的重要性,=1时的f值称为f1值。
[0192]
同样的,为了评估本发明所提肉鸡健康监测技术对一段待识别肉鸡声音信号的识别效果,也即肉鸡健康监测的预测性能,需要定义新的评估指标。本发明新定义了预测精度来评价本技术对一段待识别肉鸡声音信号的识别效果。
[0193]
假设给定一段待识别的肉鸡声音信号p,这段声音信号中按照时间顺序排列着n个未知的声音类别,分别为ti(i=1,2,3,
…
,n)。当可视化平台对多分类模型给出的预测结果进行多数表决处理后,可以得到这段待识别的肉鸡声音信号中n个未知的声音类别的预测类别,分别表示为:pi(i=1,2,3,
…
,n)。那么,预测精度可表示为类别预测正确的声音类别的个数占声音类别总个数的比例,即:
[0194][0195]
其中,i(
·
)为指示函数。
[0196]
实验验证与分析(test and analysis):
[0197]
利用前面训练阶段确定的模型完成测试阶段的任务。即我们对本发明提出的基于声音特征和随机森林的白羽肉鸡健康监测技术进行整体验证。
[0198]
第一步是利用音频信号采集系统采集一段时长5min的待识别的肉鸡声音信号,并对声音信号进行基于“带通 基本谱减法”的初步信号滤波。我们将该声音信号称为验证用肉鸡声音信号。图8示出了笔者放置在汇兴养殖场内3号养殖大棚的某个肉鸡圈养区域内的音频信号采集系统。音频信号采集系统采集一段对应当前圈养区域的时长为5min的验证用肉鸡声音信号。声音信号最终保存在远程pc端的本地路径下,如图9中红色方框圈出的部分。
[0199]
对于保存的肉鸡声音信号,我们利用matlab对其进行基于维纳滤波的深度信号滤波。进一步的,我们对声音信号进行端点检测和分帧处理,共得到8个起始帧与终止帧的组合。这意味着该段待识别的肉鸡声音信号中包含8个待预测的声音类别。我们从8个组合中包含的每个帧信号中提取30维特征,建立初步的待预测的数据集。紧接着,我们对数据集进行min-max标准化处理。然后,我们利用基于参数优化随机森林的多分类模型来对待预测的数据集进行预测。最后,我们将预测结果导出为txt文件,并在可视化平台读取文件,完成多数表决和计算咳嗽率的过程。表15中给出了8个组合的多数表决过程的具体描述。表中第一列为组合的序号,第二列为组合内包含的帧数,第三至六列给出了多分类模型的预测结果,第七列给出了多数表决的结果。需要说明的是,我们同样邀请经验丰富的养殖人员对该段肉鸡声音信号进行人识别,并在第八列给出了识别结果,我们认定其为真实标签。根据预测精度的定义,我们可以计算本次取得的预测精度为100%。我们将预测结果保存至txt文件中。
[0200]
表15 8个组合的多数表决过程的具体描述
[0201][0202]
我们在可视化平台读取txt文件,将多数表决结果直观的显示在文本框。同时,根据各声音类别的数量和所占比例,可视化平台绘制了饼状图。此时,我们计算得到的咳嗽率为37.5%,比设定的预警阈值10%高出三倍以上,说明当前放置音频信号采集终端的源圈养区域内肉鸡群体的健康状况存在问题。此时,可视化平台也弹出窗口进行预警信息提示,如图9所示。需要说明的是,在肉鸡声音信号采集的过程中,我们邀请经验丰富的养殖人员在源圈养区域进行人工识别。即他们通过耳朵倾听该区域内肉鸡群体发出咳嗽声的频率,给出肉鸡群体健康状况的判断结果。最终,养殖人员给出了与可视化平台一致的判断结果,即源圈养区域内存在患病肉鸡。根据两者的判断结果,养殖人员在源圈养区域内进行排查,最终查找到两只患病的肉鸡。
[0203]
至此,我们完成了本发明提出的基于声音特征和随机森林的肉鸡健康监测技术的一次验证。
[0204]
再次利用音频信号采集系统在不同肉鸡圈养区域采集了10段时长5min的待识别
的肉鸡声音信号,并同样经过初步信号滤波,深度信号滤波、特征提取、min-max标准化处理等步骤,建立10个待预测的数据集。我们应用基于参数优化随机森林的多分类模型在每个数据集上分别进行10次预测,预测结果如表16所示。
[0205]
表16多分类模型进行10次预测的结果
[0206][0207]
从表中可以看出,除了第七段声音信号中有一个呼噜声被误判为咳嗽声,其他均预测正确。经过计算,我们得出本次取得的平均预测精度为98.97%,且未出现将咳嗽声误判为其他声音类别的情况。同样的,在该过程中,我们邀请养殖人员进行人工判断,得出的结论均与可视化平台给出的基本一致。即第2、3、4、5、6、8、9、10段肉鸡声音信号对应的源圈养区域内肉鸡群体的健康状况正常,第1段肉鸡声音信号对应的源圈养区域内肉鸡群体的健康状况异常。可视化平台对于第7段肉鸡声音信号给出了错误的判断结果,这主要是因为错误的将一个呼噜声识别为咳嗽声。实际上,出现将其他声音类别误判为咳嗽声的情况并不可怕,糟糕的是将咳嗽声误判为其他声音类别,这对肉鸡健康监测的根本产生了影响。总而言之,我们希望所提出的肉鸡健康监测技术对咳嗽声是敏感的,哪怕是偶尔的将其他声音类别误判为咳嗽声,但是绝不存在漏判咳嗽声的可能。这有效证明了本发明所提的基于声音特征和随机森林的白羽肉鸡健康监测技术的稳健性。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。