1.本发明属于向量检索领域,具体涉及一种面向近邻图向量检索的向量编码学习方法及装置。
背景技术:
2.随着人工智能的发展,向量检索技术被广泛使用于人脸识别、文件搜索、语音识别、核酸序列检索等应用中。其中基于近邻图的向量检索凭借出色的搜索导航能力,成为当前学术界和工业界的一个研究的热点。
3.然而,随着数据规模的陡增,过高的内存和计算开销对近邻图向量检索的广泛应用提出了挑战。为了解决这个问题,目前一种解决方法是通过向量编码降低向量维度后再进行近邻图向量检索。已有的向量编码方法,如lsh,pq,opq和link&code,采用保值或保序的策略将无损原始向量变为压缩编码,这些方法由于编码过程都没有与近邻图向量检索任务有效结合,因而会大幅降低近邻图向量检索的精度和效率。针对这个问题,本发明面向近邻图向量检索提出一种向量编码学习方法及装置。
技术实现要素:
4.本发明提出了一种面向近邻图向量检索的向量编码学习方法及装置,通过在训练过程中引入近邻图的搜索过程,从而直接优化其检索性能。较之于现有的编码方法,可以更好地适应近邻图向量检索任务,提升搜索精度和搜索效率。本发明能够满足相关应用在大规模场景下的向量检索要求,优化用户的体验。
5.根据本说明书一个或多个实施例的第一个方面,本发明所提出的一种面向近邻图向量检索的向量编码学习方法具体内容如下:
6.(1)获取若干个原始向量;
7.(2)基于若干个所述原始向量构建原始向量近邻图,原始向量近邻图中每个节点对应一条原始向量,边代表原始向量间的近邻关系;
8.(3)加载编码模型,并初始化编码模型参数;
9.(4)使用编码模型生成原始向量对应的过渡编码,使用所述过渡编码对应替换所述原始向量近邻图中的原始向量,从而得到过渡编码近邻图;
10.(5)在过渡编码近邻图上执行近邻搜索,记录并筛取路由数据的集合调整所述编码模型参数;
11.(6)重复步骤(4)到(5),输出最终的压缩编码。
12.步骤(4)所述的过渡编码近邻图使用过渡编码替换了原始向量近邻图中的原始向量,过渡编码近邻图和原始向量近邻图的近邻图相同,原始向量近邻图和过渡编码近邻图的区别在于近邻图节点中对应的数据不同。
13.作为优选,所述步骤(5)中获取路由数据的具体过程为:
14.(5-1)获取训练向量,其中训练向量可以是也可以不是若干个原始向量中的一个;
15.(5-2)通过所述编码模型生成训练向量对应的训练编码作为查询点,查询点根据过渡编码近邻图的入口节点初始化候选节点集,计算候选节点集中每个节点的预测选择概率,并将这些节点标记为未访问状态,其中所述候选节点集的最大容量固定为l;
16.其中,所述预测选择概率是指当前编码模型参数下,给定查询点在基于近邻图的搜索过程中,从候选节点集中选择其中一个节点进行访问的概率;
17.(5-3)从候选节点集中选取预测选择概率最高的未访问状态节vj,使用对组结构的路由数据ψj记录候选节点集和预测选择概率最高的未访问状态节点vj;
18.(5-4)获取节点υj在过渡编码近邻图中的近邻节点集,计算近邻节点集中每个节点对应过渡编码的预测选择概率,并根据预测选择概率更新候选节点集h,标记节点为已访问状态;
19.(5-5)重复步骤(5-3)和(5-4)直到访问到查询点的真实最近邻v
gt
和或候选节点集h中已没有未访问状态的节点,其中,步骤(3)中所述的路由数据构成路由数据的集合ψ,表示为:
20.ψ={ψj|j=1,2,
…
,z}
21.z为整个搜索过程的访问节点的个数。
22.步骤(5)对路由数据的集合ψ中的路由数据进行筛选,根据近邻图搜索过程的阶段性特点,忽略导向优先的路由数据,选取精度优先的路由数据构成训练路由数据集ψ
′
训练编码模型m
ω
,其中训练路由数据集ψ
′
表示为:
23.ψ
′
=(ψj|j=k,k 1,
…
,z}
24.应用步骤(1)-(6)所训练的编码模型m
ω
,将原始向量输入所述编码模型中,得到嵌入了近邻图搜索特征的压缩编码。
25.一种面向近邻图向量检索的向量编码学习方法,其特征在于,所述压缩编码至少包括以下一种:量化编码和哈希编码。
26.作为优选,所述步骤(6)中,结束重复所述步骤(4)到(5)的条件为:训练迭代次数超过固定阈值。
27.作为优选,所述步骤(6)中,结束重复所述步骤(4)到(5)的条件也可以为:编码模型的损失函数计算的损失低于目标值。
28.本发明还提供了一种面向近邻图向量检索的向量编码的装置,包括:
29.原始向量输入模块,用于获取原始向量;
30.近邻图构建模块,用于生成原始向量对应的原始向量近邻图;
31.训练向量输入模块,用于获取训练向量;
32.编码模型训练模块,用于优化编码模型参数以适应近邻图的搜索过程;
33.压缩编码输出模块,用于输出压缩编码。
34.本发明与现有技术相比,有益效果是:
35.本发明提供的一种面向近邻图向量检索的向量编码学习方法及装置在训练过程中直接优化压缩编码结合近邻图后的搜索性能,使得该压缩编码应用于近邻图后在降低开销的同时提升搜索精度和搜索效率。
附图说明
36.图1是本发明根据实施例示出的一种面向近邻图向量检索的向量编码学习方法的流程图;
37.图2是本发明根据实施例示出的一种面向近邻图向量检索的向量编码学习方法的举例流程图;
38.图3是本发明根据实施例示出的一种面向近邻图向量检索的向量编码装置的框图;
具体实施方式
39.为了使本发明的技术方案和优点更加明确,下面将结合附图对本发明作进一步的描述说明。显而易见地,下面描述仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以获得其他实施方式。
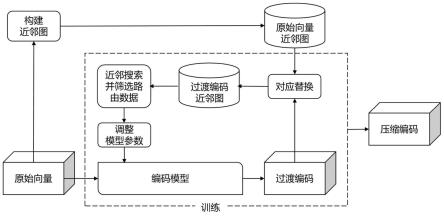
40.图1是本发明向量编码学习方法的流程图,为了进一步举例说明本发明的具体应用执行流程,包含向量编码学习方法的向量编码软件和检索软件流程图如图2所示,一种面向近邻图向量检索的向量编码学习方法主要包括以下步骤:
41.(1)首先获取原始数据,本实施例中原始数据为核酸序列数据;
42.(2)本发明可以应用于任意包含计算能力和存储能力的一台设备或多个设备组成的设备系统中,由于多数人脸识别、核酸序列检索、文件搜索、语音识别等应用所使用的数据库(人脸图像、核酸序列、文件和语音等)的数据规模较大,对于设备或设备系统的存储能力有一定要求,因此本说明书以匹配本实施例中核酸序列数据集的具有适当存储能力的设备举例;此外,由于本发明包含模型学习的步骤,本实施例中的设备具有一定的计算能力;最后,本实施例中的设备具有接收实施例中所举例的核酸序列的能力;
43.(3)获取原始向量,其中原始向量由原始数据通过预模型生成;例如在本实施例中,向量编码软件读取核酸序列数据集,采用k-mer对dna序列进行预处理,并通过countvectorizer向量化,从而生成核酸序列原始向量集,其中,核酸序列原始向量集s抽象表示为:
[0044][0045]
其中,αi为第i个核酸序列原始向量,n为核酸序列原始向量集中核酸序列原始向量的个数,每个核酸序列原始向量均为d
in
维,为核酸序列原始向量对应的数据分布空间;
[0046]
(4)基于原始向量构建原始向量近邻图;在本实施例的向量编码软件中构建的近邻图为hnsw图,hnsw图和核酸序列原始向量集s结合构成原始向量hnsw图;
[0047]
(5)加载编码模型m
ω
,并初始化编码模型参数。在本实施例中向量编码软件采用量化编码,具体地,向量编码软件所包含的编码模型将核酸序列原始向量所在的数据分布空间映射为p个学习空间的乘积,每个学习空间都有一个由p个码字组成的码本,m
ω
抽象表示为:
[0048]mω
=[m1,...,m
p
]
[0049]
其中来自第p个码本下的第e个码字表示为c
pe
。输入核酸序列原始向量集s中的核酸序列原始向量αi,输出核酸序列过渡编码集s
′
中的核酸序列过渡编码βi,其中,s
′
抽象表示为:
[0050][0051]
核酸序列过渡编码βi由p个码字编号组成,抽象表示为:
[0052]
βi={e1,...,e
p
}
[0053]
核酸序列原始向量集s所在数据分布空间和核酸序列过渡编码集s
′
所在数据分布空间的关系为:
[0054][0055]
(6)使用编码模型m
ω
生成核酸序列原始向量对应的核酸序列过渡编码,并将核酸序列过渡编码集s
′
替换原始向量hnsw图中对应的核酸序列原始向量集s,从而得到过渡编码hnsw图i
′
,需要强调的是,过渡编码hnsw图i
′
的近邻图与原始向量hnsw图i相同,区别仅在于节点对应的数据不同;
[0056]
(7)查询点在过渡编码近邻图上执行近邻搜索,记录搜索过程中的路由数据,获取路由数据的具体过程为:
[0057]
(7-1)向量编码软件读取核酸序列训练数据,并将核酸序列训练数据向量化为核酸序列训练向量q,通过编码模型生成核酸序列训练向量对应的核酸序列训练编码q
′
作为模拟查询点,将hnsw图预先规定的一个入口节点添加到最小堆h中,其中最小堆h固定最大容量为l;
[0058]
(7-2)使用对组结构的路由数据ψj记录最小堆h状态,并从最小堆h中选取预测选择概率最高的未访问节点vj,同样保存在路由数据ψj中;其中,预测选择概率表征了当前编码模型参数下,给定查询点在基于近邻图的搜索过程中,从候选节点集中选择其中一个节点进行访问的概率;本实施例中预测选择概率计算过程如下:
[0059][0060][0061]
(7-3)获取节点vj在的近邻节点n(vj),并计算在模拟查询点下,n(vj)对应过渡编码的预测选择概率,更新最小堆h;
[0062]
(7-4)重复步骤(7-3)和(7-4)直到访问到最近邻v
gt
或最小堆h中已没有可访问节点,其中,步骤(7-3)中所述的全部路由数据构成路由数据的集合ψ,其抽象表示为:
[0063]
ψ={ψj|j=1,2,
…
,z}
[0064]
其中,z为整个搜索过程的访问节点的个数;
[0065]
(8)选取部分精度优先的路由数据训练编码模型,对路由数据的集合ψ中的路由数据进行筛选,根据近邻图搜索过程的阶段性特征,忽略导向优先的部分路由数据,选取精度优先的部分路由数据构成训练路由数据集ψ
′
;其中,近邻图搜索过程的阶段性指:根据
对搜索性能的贡献,可以将近邻图向量检索的搜索过程分为两个阶段,初期阶段对搜索精度的影响不大,对搜索效率的影响较大,主要起导向作用,末期访问的节点则相反,以优先确保搜索精度;本实施例中选取第项路由数据至第z项路由数据作为训练路由数据集ψ
′
,其抽象表示为:
[0066][0067]
(9)基于训练路由数据集ψ
′
训练编码模型m
ω
;对于训练路由数据集中每个路由数据ψj,获取所含最小堆h中的所有节点,重新计算模拟查询点对应核酸序列训练向量q和这些节点对应的核酸序列原始向量αi的实际距离dist(q,αi),记录实际距离最小的节点,其中实际距离dist(q,αi)抽象表示为:
[0068][0069]
(10)将训练路由数据集ψ
′
及对应的实际距离最小的节点集输入编码模型m
ω
,优化编码模型,编码模型m
ω
损失函数为:
[0070][0071]
(11)重复步骤(6)到(10),直到损失函数计算的损失小于ω或训练迭代次数大于等于θ,得到最终的核酸序列过渡编码集作为核酸序列压缩编码集,以及hnsw图和编码模型中的码本;
[0072]
(12)在线查询前,检索软件加载码本,并将hnsw图和核酸序列压缩编码集结合构成压缩编码hnsw图;
[0073]
(13)在线查询时,检索软件首先获取核酸序列查询数据;然后将核酸序列查询数据向量化为核酸序列查询向量,并在压缩编码hnsw图上进行近邻搜索,从而返回一定数量的结果r;
[0074]
(14)上述方法在模型训练过程中充分考虑了近邻图的搜索过程,直接优化检索性能,从而在降低开销的同时提升了近邻图的搜索精度和搜索效率;
[0075]
本说明书所示出的一种向量编码装置如图3所示,所述装置输入原始向量,输出对应的向量编码;所述装置包括:
[0076]
原始向量输入模块,用于获取原始向量;
[0077]
近邻图构建模块,用于生成原始向量对应的原始向量近邻图;
[0078]
训练向量输入模块,用于获取训练向量;
[0079]
编码模型训练模块,用于优化编码模型参数以适应近邻图的搜索过程;
[0080]
压缩编码输出模块,用于输出压缩编码。
[0081]
能够理解,由于向量编码装置基本对应于向量编码方法实施例,因此向量编码装置实施例可参见向量编码方法实施例说明。需要说明的是,以上所述的向量编码装置是示意性的,多个模块在物理上可以是也可以不是分离的。对于本领域普通技术人员而言,在不付出创造性劳动的前提下,即可以理解并实施。
[0082]
应当说明的是,以上仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,这些改变也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。